
一种基于时间和标签上下文的协同过滤推荐算法
2015-06-23 13:55:29窦羚源王新华
太原理工大学学报 2015年6期
窦羚源,王新华,2
(1.山东师范大学 信息科学与工程学院,济南 250014;2.山东省分布式计算机软件新技术重点实验室,济南 250014)
一种基于时间和标签上下文的协同过滤推荐算法
窦羚源1,王新华1,2
(1.山东师范大学 信息科学与工程学院,济南 250014;2.山东省分布式计算机软件新技术重点实验室,济南 250014)
针对常规推荐算法数据单一、准确性和可靠性都比较低的问题,提出了将时间和标签上下文信息加入到推荐算法中,以丰富单个用户或商品的信息。利用时间信息挖掘用户间的影响关系,同时利用标签上下文来衡量物品间的关系,最后将用户关系向量和物品关系向量融合到概率矩阵分解模型中。实验结果表明,提出的协同过滤推荐算法能够提高推荐的准确性和精度。
推荐系统;概率矩阵分解;时间上下文;标签上下文
推荐系统因其为用户提供个性化服务的特点,可有效的缓解信息过载等问题。传统的推荐算法大多使用用户-物品的评分信息,一方面存在数据稀疏问题,另一方面在推荐效果上不能令人满意。为此,研究人员将研究方向指向了挖掘其他上下文信息,丰富单个用户-物品评分,一定程度上缓解了数据稀疏的问题。郭磊等[1]提出一种信任关系强度敏感的社会化推荐算法,将社交网络中的信任关系的亲疏程度量化,并将量化值作为用户对项目评分的权重应用到预测评分计算中,而不是采用传统的累加,该文献中提到的方法能够有效的提高预测评分的准确率。邹本友等[2]在基于信任的单一模型基础上,将基于主题的张量分解模型与用户信任关系相结合,动态选择好友推荐。Zhou,et al[3]通过挖掘隐式标签信息来计算用户(物品)的特征向量,通过梯度学习方法来完善基于标签的矩阵分解模型。陈益强等[4]将研究内容锁定在蓝牙信息,提出了一种基于蓝牙动态特征的移动情景感知方法,这种方法也能用在好友推荐情况中,孙克等[5]提出一种面向社会关系的移动用户好友推荐算法。郑志高等[6]将时间上下文考虑到基于最近邻的协同过滤算法中,将用户和物品的相似度进行时间加权以保证TOP-N最近邻数据的有效性。孙光福等[7]提出的基于时序行为的协同过滤推荐算法中,利用用户购买同一物品的先后顺序来定义用户间的影响关系,而且影响关系是有向的,进一步融合到概率矩阵分布模型中进行评分预测及推荐,该方法创新之处是时间戳信息容易获取且用户(项目)间影响关系计算方法简单。国外学者Massa和Avesani在文献[8-9]中提到使用用户间的信任关系矩阵来代替寻找相似用户的过程,并假设信任关系可以在信任网中传播,预测未知信任值,实验结果表明可以有效提高覆盖率。Konstas,et al[10]利用朋友关系和标注关系建立随机游走模型,并成功应用到音乐推荐系统中。Boutemedjet,et al[11]通过分析移动用户访问社交网站的记录,挖掘用户潜在的社会关系来计算用户间的相似度。Jiang,et al[12]提出一种基于社会上下文信息的推荐算法,推荐对象间的内容相似度作为约束,侧重于对不同社会上下文信息建模。
上述方法都在传统的用户-物品评分基础上加入了不同的上下文信息,同时提出了不同的用户(物品)相似度计算方法,取得了一定的推荐效果。
但是,上述工作中的算法只考虑了基于用户或者基于物品来推荐,并没有将两者都考虑到算法中。因此提出一种思路,首先基于时间上下文来计算用户间相似度,得到用户时间特征向量;然后,基于标签上下文衡量物品相似度,得到物品标签特征向量;最后,融合到概率矩阵分解模型中,通过不断优化模型,降低算法的误差率。
1 相关工作
1.1 基于标签上下文的推荐算法
传统的协同过滤算法是基于用户对物品的评分来衡量用户的偏好,将物品推荐给有相同兴趣爱好的用户。由于大型电子商务站点商品项的数量庞大且不断增加,使得用户物品评分矩阵成为高维矩阵,同时用户给予的评分资源很少,导致评分数据稀疏,无法提取标识用户兴趣偏好的特征。社会标签可以实现对信息的分类[13],被用户自由标注资源,通过用户使用的标签记录挖掘用户对资源的喜爱程度。鉴于此,许多学者将标签自由标注的特征作为用户、资源的特征信息,将标签应用到推荐算法来提高推荐质量。文献[14]中提出基于标签计算用户的兴趣爱好相似度,并构建信任网络,使用随机游走算法进行TOP-N推荐,但该算法计算耗时、存在冷启动问题。文献[15]将用户、标签、项目数据用张量表示,并进行高阶奇异分解,有效的改善了数据稀疏问题,提高推荐质量,但还是没有解决计算耗时问题。
1.2 基于时间上下文的推荐算法
随着对推荐系统理论的深入研究,研究者将用户所处的上下文环境(如时间、位置、周围人员、情绪、活动状态、网络条件等等)引入到推荐系统中,进一步提高推荐效果。时间上下文相对容易采集,并且对提高推荐系统的时序多样性具有重要的价值。近年来,时间感知推荐系统成为学术界研究的热点。文献[16]中提出的TimeSVD++算法将时间信息加入到用户(物品)特征向量中,有效解决了兴趣漂移问题。Liang,et al[17]将时间信息作为第3个维度,然后利用张量分解的方式模型化动态变化。Li,et al[18]基于用户兴趣的阶段性差异,提出了跨域协同过滤算法框架。实验结果表明,该算法不仅能够有效的进行推荐,还可以追踪用户的兴趣漂移。
与上述工作不同,笔者通过时间信息来构造用户之间的结构关系,在此基础上进行相似度计算;进而,将此相似度集成到概率矩阵分解算法当中,提出一个全新的推荐框架。
2 算法描述
一种基于时间和标签上下文的协同过滤推荐算法(A collaborative filtering recommendation algorithm based on the context of time and tags,简称TTC-CF)。首先,介绍如何利用用户评分的时间上下文信息挖掘用户间关系,从而确定对用户影响最大的邻居集合;然后介绍如何利用物品和标签信息来挖掘物品间关系,从而确定对物品影响最大的邻居集合;最后介绍如何将邻居集合成功的融合到基于概率矩阵分解的协同过滤算法中。
2.1 基于时间上下文的用户最近邻选择
在传统的协同过滤算法中,核心步骤是用户关系的获取,这一过程大都忽略了用户对物品评分的时间信息。然而这一时间信息可能隐匿着部分相关性,如果利用这一部分规律可能在一定程度上挖掘出用户之间的关系。为此,首先引入了基于时间上下文的用户消费网络图,如图1所示。在网络图G={U,E}中,U是用户集合,用圆圈表示;E是边集合,用带箭头的有向线段表示,N代表边的权重值,“()”表示用户消费的产品数。如果在设定的时间段内(设定为一天,也就是86 400 s)内,Ui和Uj先后对消费物品进行评分,则边Ei→j的权重Ni→j增加1。遍历所有的产品,最终构成用户消费网络图。根据网络图,我们定义用户的影响关系权重如下:

(1)
式中:Ni→j表示用户Ui对用户Uj的影响次数,sum(Ui,Uj)表示用户Ui和用户Uj进行评分的产品总数。例如,在图1中,用户U1对用户U2的影响力W1→2=5/(20+90)=0.05用户U2对用户U1的影响力W2→1=15/(20+90)=0.14.由此,可以看出两个用户之间的影响力是有向的,这与现在的无向计算方法更具合理性。根据影响力的大小可求出TOP-N最近邻,进一步将这些最近邻融合到矩阵分解模型中。

图1 用户消费网络图
2.2 基于标签上下文的物品最近邻选择
现有研究表明,尽管物品会被标注很多的标签,但是经常使用的标签集却是很少。通过本文的实验数据集验证了这点,如图2所示。该图数据来源于本文实验所用的数据集Movielens[19],由于数据量很多,为了图片的直观性,只选取了前10个电影物品,1 128个标签及11 280个物品-标签的关联度数据。从图2中可以看出,物品经常被标注的标签只有很少的一部分。
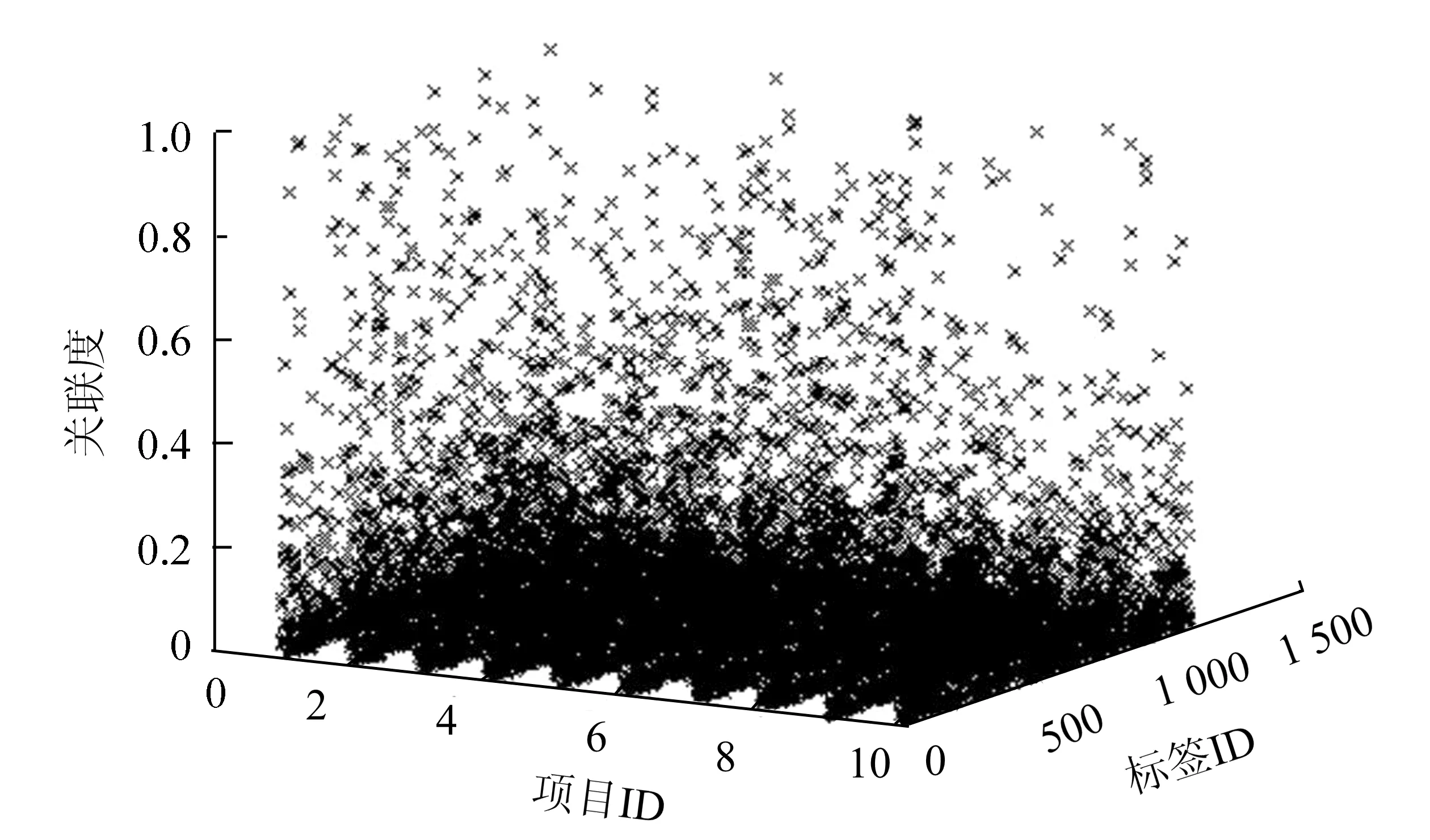
图2 物品常用标签集
通过物品-标签关联度来选择TOP-N常用标签集,然后根据以下计算公式来求物品间相似度,最后求得物品的最近邻。
以物品rj为例,假设物品rj常被标注的标签集合为Ln={l1,l2,…,lk,…,ln},则物品的标签特征向量表示为:
(2)

物品标签相似度是指两个不同的物品之间的标签特征向量的相似程度。本文采用的计算方法是余弦相似度计算。
(3)
通过计算物品标签特征向量之间的相似度,可构造物品标签相似度矩阵Tn×n,用以描述不同物品之间的相似度:
2.3 矩阵分解模型
挖掘出相应的用户(物品)间的影响关系并找到最近邻集合之后,将其应用到矩阵分解模型中。假设Uu和Vr代表某个特定用户u和产品r的K维特征向量。概率矩阵分解模型的推荐算法的核心步骤是学习用户和产品的特征向量。
定义推荐系统中存在N个用户,用户集合U={u1,…,uN};M个物品,物品集合R={r1,…,rM};用户-物品评分矩阵为S=[Su,r]N×M,在这个评分矩阵中,Su,r表示用户u对物品r的评分(比如1-5分)。协同过滤算法是利用概率矩阵分解模型学习用户(物品)的特征向量,然后基于此特征向量预测未知的评分,正态分布正是研究预测值和实际值差异的理论,也是模型建立的理论。正态分布概率密度函数可以表达为
(4)
根据以上定义,已有的评分数据的条件概率定义如下:


(5)



(6)
∑j∈NrTj→rVj.
(7)
式中:Nu和Nr表示用户u和物品r的邻居集合。同时考虑了式(6)和式(7),则条件概率表述如下:

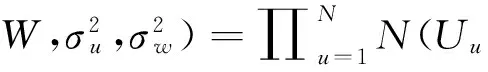
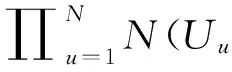
(8)



(9)
过贝叶斯推断,其后验概率如下:
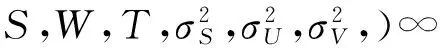


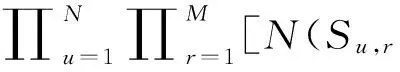



(10)
模型如图3所示:

图3 TTC-CF推荐算法框架
为了求解方便,对式(10)进行对数处理如下:
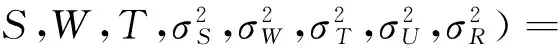
(Uu-∑j∈NuWj→uUj)]-
∑j∈NrTj→rVj)]-

(11)
式中:C是与参数无关的常量;求参数固定时,U,V极大后验概率相当于最小化带正则项的误差平方和函数,用式(12)表示。
+βV2r=1MVrTVr+β
W2u=1N[Uu-j∈NuWj→uUjT
(Uu-j∈NuWj→uUj)]+β
T2r=1MVr-j∈NrTj→rVjTVr-j
∈NrTj→rVj.
(12)

3 TTC-CF算法推荐框架
本算法一共分为4个步骤:
1)读入数据。数据信息包括用户-物品评分信息,评分的时间信息,物品-标签关联度信息。
2)系统将根据读入的用户-物品评分信息构造用户消费网络图,并根据网络图计算对用户影响力大的最近邻。
3)系统根据物品-标签关联信息筛选出物品最常用的标签集,并依据式(2)计算物品标签特征向量,依据式(3)求物品相似度,最终求得对物品影响力大的最近邻。
4)算法将该近邻集合运用到概率矩阵分解模型中,学习出用户的特征向量和物品的特征向量。
5)根据特征向量预测重构评分矩阵,利用该评分矩阵对用户形成相应的推荐。
图3介绍了该算法的具体过程,图中对每个步骤都进行了介绍。在实际的推荐系统中,往往将计算复杂度较高的1-4放在线下处理,通过已有数据,在线下学习用户和产品的特征向量,而线上则通过学习到的特征向量进行推荐。在线上推荐结束之后,系统将用户在线上的行为数据再传输到存储系统,然后根据新的数据更新相应的推荐模型
4 实验结果与分析
首先介绍了实验所用数据集,然后说明评价标准及对比算法,最后给出了TTC-CF算法与其他方法的对比实验结果,并对实验结果进行了相应的分析。
4.1 实验数据集
实验用到的数据集Movielens[15]是由明尼苏达大学的Grouplens研究项目收集,是用于推荐系统比较经典的数据集。本实验选用的是100 kB的数据集,包括943个用户、1 682个电影物品以及用户对电影物品的100 000个评分数据及Unix时间戳。Unix时间戳是指从1970年1月1日开始经过的秒数,标签数据集(Tag Genome)包含1 128个标签信息,所有的数据集存储在Matlab的变量格式中或txt文件中,表1、表2只是截取了前10个数据。实验过程中,将原始数据按80%和20%比例拆分,得到训练集和测试集两部分。

表1 用户-物品评分数据

表2 电影-标签-关联度
4.2 评价标准
为了衡量算法的优劣,需要用合理的评价指标。推荐系统中最常用的评价指标有平均绝对误差(MAE)和均方根误差(RMSE)两类。mae(u)等于目标用户u的评分预测值与测试集中真实评分值偏差绝对值和的平均数,如式(13),

(13)
式中,n为目标用户在测试集中已有的评分个数。
4.3 对比算法
1)传统的基于物品的协同过滤算法(CF),利用用户对物品的评分求用户(物品)之间的相似关系。
2)基于标签信息的协同过滤推荐算法(Tag-CF),利用标签信息来计算用户(物品)之间的相似关系。
3)基于时间上下文的协同过滤推荐算法(Time-context collaborative filtering recommendation algorithm,简称TC-CF),利用时间上下文信息来计算用户(物品)之间的相似度。
4.4 实验结果
4.4.1 参数对算法的影响
在实验中,为了降低模型计算的复杂度,设定βU=βV=0.001,并且假设βW=βT=β.β值可以用来衡量用户(产品)受到其关系信息影响的程度,值越大,代表对算法的作用越大。参考文献[1]和文献[7]中对参数的设置,将β值设定为0.1,0.5,1.5,5,10,20,当特征向量维度K=5时,结果如图4所示,参数取值在5时,算法取得最佳效果。

图4 不同β值下MAE效果比较
4.4.2 不同邻居数目下的各算法的推荐效果比较
实验中分别设定了特征向量维度K=5,10,15,20,25,30,35,40,45,50 .在实验中,算法的其他参数均设置为使算法最优时的相应值,这需要进行大量的重复实验求得。实验结果如图5所示。

图5 不同K值下MAE效果比较
从实验结果可以看出:
1) 随着K的增大,算法的精度都有一定的提高,但K的增大一定程度会增加算法的计算时间。
2) 从图5可以看出,TTC-CF在MAE衡量标准下推荐效果要优于CF,Tag-CF和TC-CF,这说明本文提出的将用户和物品影响关系都考虑在算法中是可行的,比单独考虑一种影响关系推荐效率要高。
3) 实验结果表明,TTC-CF比Tag-CF和TC-CF推荐效果要好,充分说明了本文提出的算法的合理性和有效性。而且时间信息容易获取,标签信息丰富,算法在实际应用中更加广泛。
5 结论
协同过滤推荐算法在解决信息过载问题中取得了较好的效果,TTC-CF算法将时间上下文和标签上下文融合到概率矩阵分解模型中,也取得了不错的效果。文中利用用户消费时间上下文来挖掘用户间的影响关系,并且这种影响关系是双向的。同时,利用物品与标注标签的关联度挖掘物品间的影响关系,最后将用户特征向量和物品特征向量融合到概率矩阵分解模型中,预测用户对物品的评分,为用户推荐物品。通过movielens实验数据集进行实验仿真,实验结果证实了TTC-CF算法的优越性。
[1] 郭磊,马军,陈竹敏.一种信任关系强度敏感的社会化推荐算法[J].计算机研究与发展,2013,50(9):1805-1813.
[2] 邹本友,李翠平,谭力文,等.基于用户信任和张量分解的社会网络推荐[J].软件学报,2014,25(12):2852-2864.
[3] Zhou Tao,Jiang Luoluo,Su Riqi.Effect of initial configuration on network-based recommendation [J].Euro physics Letters,2008,81(5):1-6.
[4] 陈益强,李秋实,刘军发,等.基于蓝牙动态特征的移动情境感知[J].软件学报,2011,22(2):137-146.
[5] 孙克,王新华,窦羚源.面向社会关系的移动用户好友推荐算法[J].山师学报,2015,30(2):11-13.
[6] 郑志高,刘京,王平,等.时间加权不确定近邻协同过滤算法[J].计算机科学,2014,41(8):7-12.
[7] 孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013,24(11):2721-2733.
[8] Massa P,Avensani P.Trust-aware collaborative filtering for recommender systems[C]∥Meersman R,Tari Z eds.On the Move to Meaningful Internet Systems 2004:CoopIS,DOA and ODBASE.Italy:Springer Berlin Heidlberg,2004:492-508.
[9] Massa P,Avesani P.Trust-aware recommender systems[C]∥Proceedings of the 2007 ACM Conference on Recommender Systems.Minneapolis,USA,2007:17-24.
[10] Konstas I,Stathopoulos V,Jose J.On social networks and collaborative recommendation[C]∥Proceedings of the 32ndInternational ACM SIGIR Conference on Research and Development in Information Retrieval.Boston,USA.2009:195-202.
[11] Boutemedjet S,Ziou D.A graphical model for context-aware visual content recommendation [J].IEEE Trans on Multimedia,2008,10(1):52-62.
[12] Jiang M,Cui P,Liu R,et al.Social contextual recommendation[C]∥Proceedings of the 21stACM International Conference on Information and Knowledge Management.Maui,USA,2012:45-54.
[13] RauJer-wei,Huang Jen-wei,Yung Sheng.Improving the quality of tags using stste transition on progressive image search and recommendation systems[C]∥2012 IEEE International Conference on Systems,Man,and Cybernetics.Seoul,2012:3233-3238.
[14] Jin Jian,Chen Qun.A trust-based top-k recommender system using social tagging network[C]∥2012 9th International Conference on Fuzzy Systems and Knowledge Discovery China,2012:1270-1274.
[15] Nanopoulos A,rafailidis D,Symeonidis P,et al.MusicBox:personalized music recommendation based on cubic analysis of social tags[J].IEEE Transaction on Audio,Speech,and Language Processing,2010,18(2):407-412.
[16] Koren Y.Collaborative filtering with temporal dynamics[C]∥Proc of ACM SIGKDD Conf on knowledge Discovery and Data Mining.ACM Press,2009:89-97.
[17] Xiong L,Chen X,Huang TK,et al.Temporal collaborative filtering with Bayesian probabilistic tensor factorization[C]∥Proceedings of SIAM Data Mining,2010:211-222.
[18] Li B,Zhu XQ,Li RJ,et al.Cross-Domain collaborative filtering over time[C]∥In Proc of the 22ndInt’l joint Conf on Artificial Intelligence.IJCAI/AAAI Press,2011.2292-2295.
[19] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:44-69.
(编辑:刘笑达)
A Collaborative Filtering Recommendation Algorithm Basedon the Context of Time and Tags
DOU Lingyuan1,WANG Xinhua1,2
(1.SchoolofInformationScience&Engineering,ShandongNormalUniversity,Jinan250014,China;2.ShandongProvincialKeyLaboratoryforDistributedSoftwareNovelTechnology,Jinan250014,China)
The conventional recommendation algorithms only take the user-item ratings into account.Because of the lack in data type,the accuracy and reliability of the algorithms are relatively low.In this paper we add the time and tag context information to the recommendation algorithm,in order to enrich the individual user or commodity information.The time context is used to mine the influence relationship between users and the tag context is used to measure the relationship between items at the same time.Finally we fuse user relation vector and item relation vector to the probabilistic matrix factorization model.The experimental results show that the proposed collaborative filtering algorithm in this paper can improve the accuracy and precision of recommendation.
recommendation algorithms;probabilistic matrix factorization;time context; tags context
1007-9432(2015)06-0735-06
2015-05-17
山东省优秀中青年科学家科研奖励基金项目:城市车辆无线传感器网络信息感知和分发关键技术研究(2010BSE14022)
窦羚源(1991-),女,山东青岛人,硕士生,主要从事推荐系统、数据挖掘研究,(E-mail)chixieyinghun@163.com, (Tel)13625314974.
王新华,教授,主要从事推荐系统,数据挖掘研究,(E-mail)wangxinhua@sdnu.edu.cn
TP311
A
10.16355/j.cnki.issn1007-9432tyut.2015.06.018
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
保定学院学报(2022年2期)2022-04-07 02:26:50
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
公民与法治(2016年10期)2016-05-17 04:12:58
