
一种基于LDA 的k话题增量训练算法
2015-06-14 07:37:52谢志强
吉林大学学报(工学版) 2015年4期
辛 宇,杨 静,谢志强
(1.哈尔滨工程大学 计算机科学与技术学院,哈尔滨150001;2.哈尔滨理工大学 计算机科学与技术学院,哈尔滨150080)
0 引 言
LDA(Latent dirichlet allocation,LDA)模型是近些年来话题提取的通用模型[1]。目前,话题模型相关的工作大多是对LDA 模型进行修改,或者是将LDA 模型作为整个概率模型的一个部件。在LDA 模型中,假设每个文档的主题概率分布服从Dirichlet分布,并没有对不同主题之间相关性进行刻画。然而,在真实的语料中,不同主题之间存在相关性的现象很普遍[2]。
在面向LDA 模型演化研究方面,2004 年,Blei 等[3]提 出 了 主 题 间 为 树 结 构 的 层 级(Hierarchical LDA)。在该模型中,树中的每个节点代表一个主题,该模型还有一个特点是可以从语料中估计出主题的个数,并与使用LDA 模型在不同主题数下重复实验得到的最佳主题个数一致。Blei等[4-5]于2006年又在层级LDA 的基础上提出了相关主题模型(Correlated topic model,CTM),与LDA 不同的是,CTM 从对数正态分布中对主题概率分布进行采样。Li等[6]针对CTM 只考虑两个主题间关系的不足,提出了PAM 模型(Pachinko allocation model,PAM),该模型的特点是把主题之间的关系表示成一个有向无环图,其中叶子节点是单词,可以看成是由所包含的子节点(主题或单词)构成。之后Mimno等[7]又在PAM 的基础上提出了层级PAM 模型,该模型可以看成是把层级LDA 和PAM 结合起来,使得PAM 模型中的非叶子节点也具有单词的概率分布。Wang等[8]向模型中添加了一个作为观测值的时间随机变量后得到了主题随时间变化的主题模型(Topic over time,TOT),该模型认为主题概率分布受到时间信息的影响,且时间变量服从beta分布。
在面向上下文信息分析的话题提取方面,通常主题模型假设单词序列中的单词是可交换的,即单词的顺序和模型的训练结果无关,在考虑当前节点和其他节点的关系时,就破坏了LDA 的可交 换 性 假 设。Griffiths 等[9]认 为 可 以 通 过HMM 来捕捉句法结构信息,通过LDA 来提示语义关系,并将两者结合在一起提出了HMM-LDA模型。Wallach[10]认为语料库生成过程中,一个单词除了依赖于其对应的主题外还与前一个单词有关,提出超越词袋(Beyond bag-of-words)的主题模型。张晨逸[11]等人提出利用MB-LDA 进行微博主题挖掘,该模型在挖掘出微博主题的同时还可挖掘出联系人关注的主题,并将LDA 模型推广到了社交网络中。韩晓晖[12]等人提出了一种基于LDA 的低质量回贴检测方法,利用检测回贴质量的二元分类性训练SVM 分类器,以区分出质量回贴。
在面向特定任务研究方面,Blei等[13]针对分类问题提出了有监督LDA 模型(Supervised latent dirichlet allocation,sLDA),该模型将训练语料中的文档类别标记为观测值加入LDA 模型,且类别标号服从一个与文档主题概率分布有关的正态线性分布。Steyvers等[14]提出作者主题模型(Author topic,AT),认为每个作者有一个主题概率分布。McCallum 等[15]又在AT 模型的基础上,提出了作者接受者主题模型(Author recipient topic,ART)以判定个人的社会角色。
以上模型的话题个数k 均需预先给定,若要确定最优话题个数k*则需要循环探测,其复杂度过高。文献[5]和文献[7]的实验表明,当k 的个数超过某一数据时,k*的选择开始变得模糊,导致LDA 的最优话题个数选择方法复杂度高且结果不精确。因此,设计一种高效可行的最优话题个数选择方法是LDA 研究的关键问题。本文针对LDA 模型的最优k 值选取问题,提出LDA 话题增量训练算法,并通过对真实数据集的实验分析验证了本文算法对最优k值选取的有效性和可行性。
1 LDA 模型分析
LDA 模型是以单词-话题-参数先验关系构成的3层贝叶斯模型,三者之间的关系表达模型如图1所示,其中M 为语料库中的文档个数,N 为单词表中的单词个数,zdn为文档d中单词n所属话题的概率,θd为文档d中话题zdn分布的先验参数,α为语料库中θ的全局先验参数,β为k×N 单词 -话题概率矩阵,其中k为话题个数,βi,j =p(w =j|z=i)且βi,*=1。根据上述条件概率关系,文档-单词的数学模型可表示为:
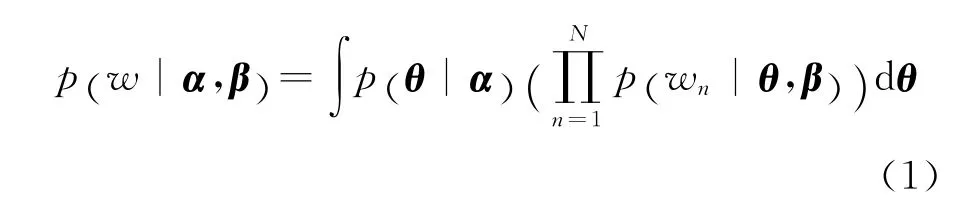
语料库-单词的数学模型可表示为:
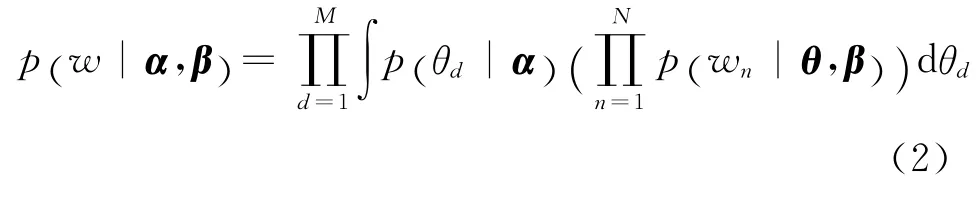

图1 LDA“盘子”模型Fig.1 Plate model of LDA
LDA 的生成模型可假设如下:
(1)p(θ|α)~Dir(α)。其表达式为:
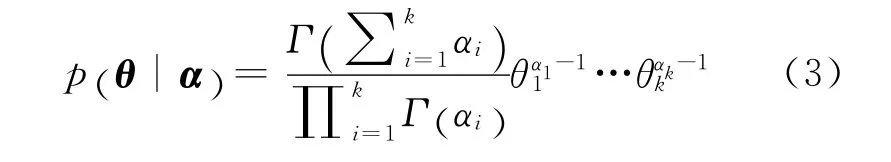
(2)p(z|θ)~Multinomial(θ)。

根据式(3)(4),式(2)可表示为:
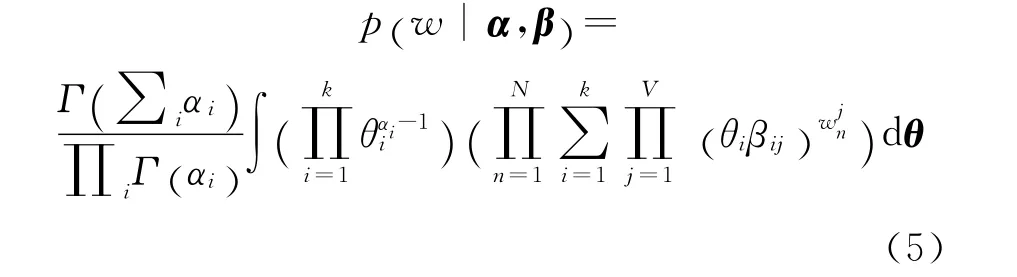
加入文档内部估计参数γ和φ,γ为β 的文档样本估计值,φ 为文档内部话题的后验概率,φi,j=p(z=j|w =i)。
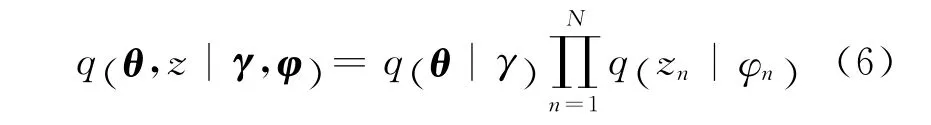
假设γ和φ 相互独立。利用变量β和z 建立文档内部隐含参数的估计模型如下:变分推理以极大化单词-话题分布的似然函数p(w|α,β)为目标,通过在似然函数中加入样本估计参数γ 和φ,实现对全局参数α 和β 的优化。为此,式(5)的似然函数表达式如下:
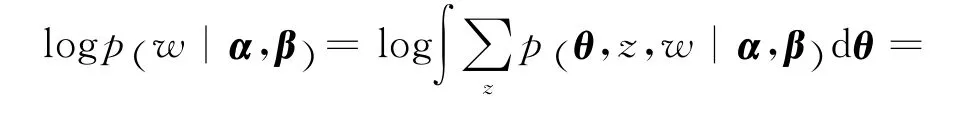

2 LDA 变分推理过程
2.1 建立变分似然函数表达式模型
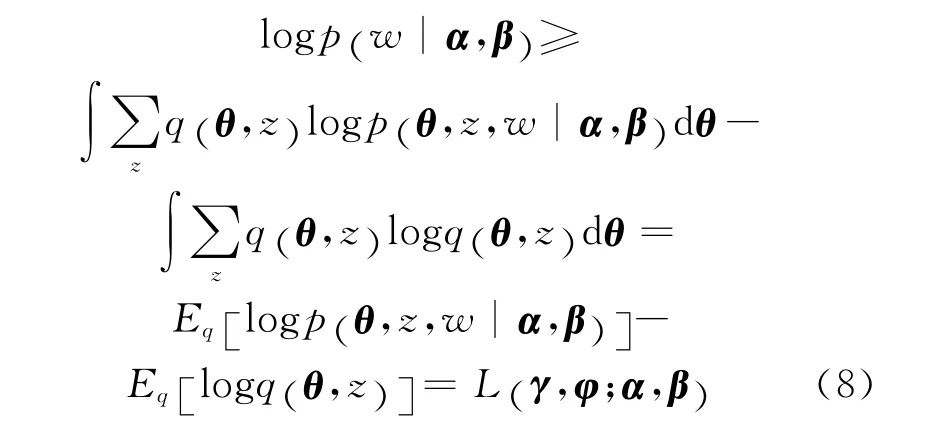
式中:Eq为利用估计参数γ 和φ 计算的期望,由于Dirichlet分布属于一种指数分布族,根据文献[1]可知:
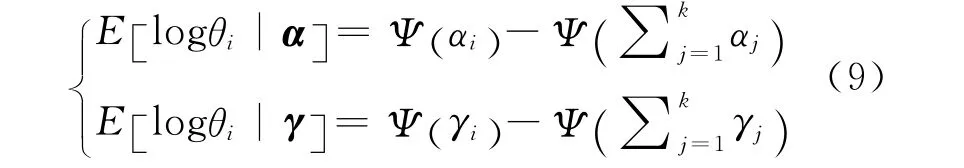
变分推理的优化过程即寻找L(γ,φ;α,β)的极值过程。根据式(8)可得:
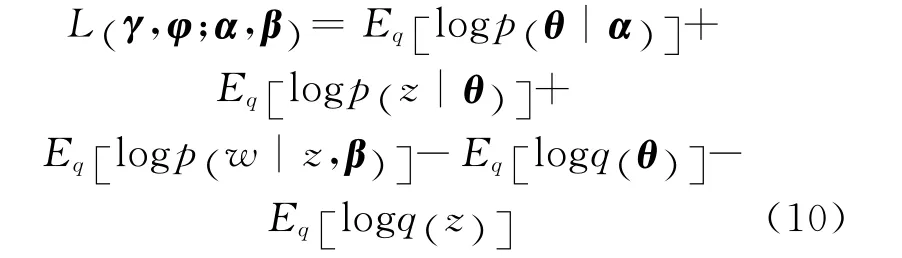
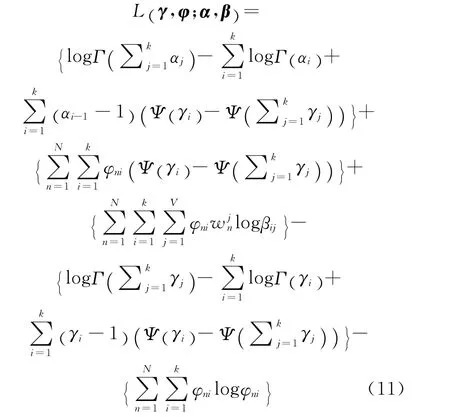
根据式(9)可得:
2.2 变分推理参数关系模型
式(11)包 含 了(α,β,γ,φ)4 个 参 数,其 中利用拉格朗日乘子法对(α,β,γ,φ)进行优化求值可得到如下结果:

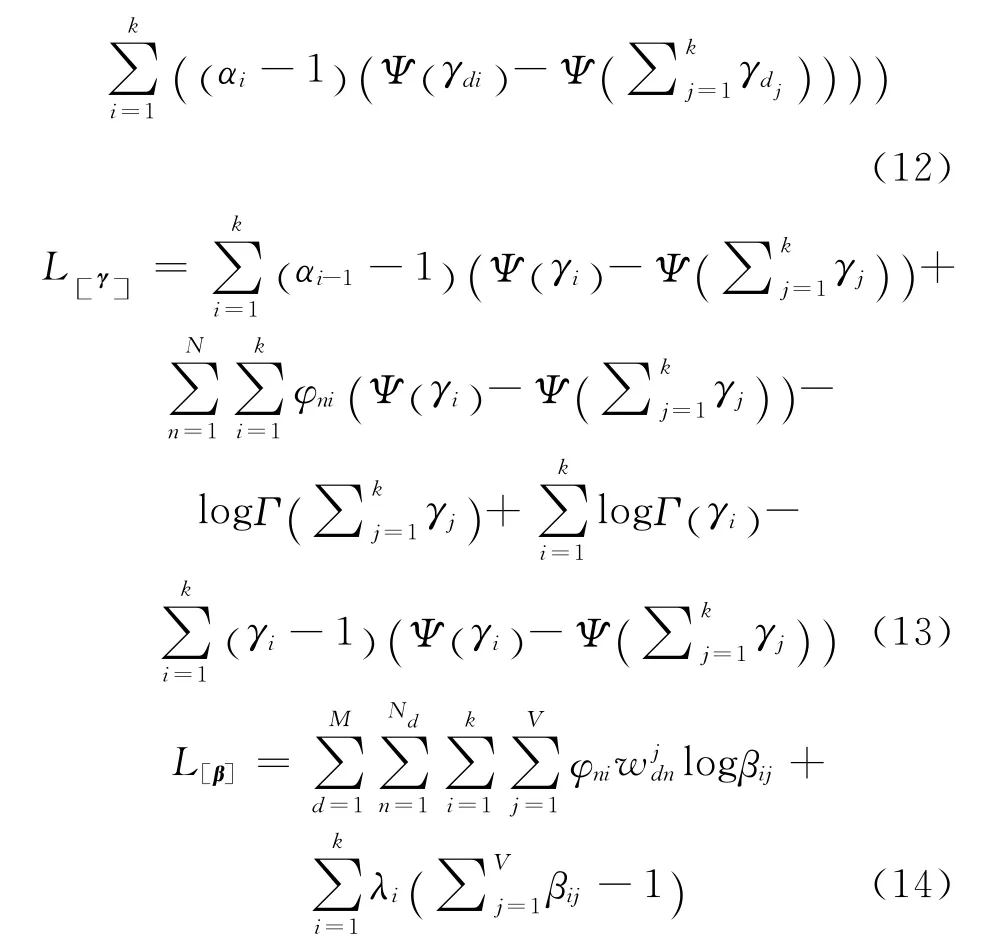
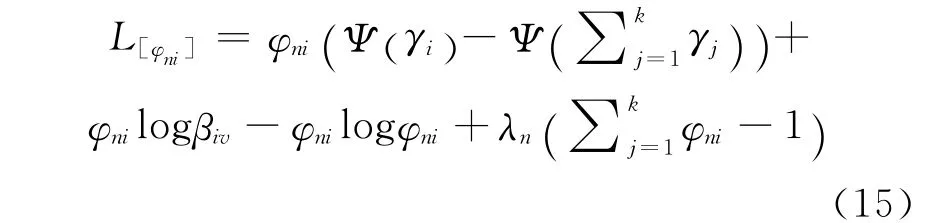
式(12)~(15)分别对(α,β,γ,φ)求零值导数可得到(α,β,γ,φ)的极值关系式如下:
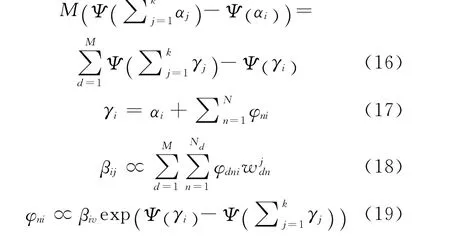
2.3 变分推理运行过程
根据式(16)~(19)变分推理的参数训练过程分为文档内部参数循环训练过程(训练γ,φ)和语料库总体参数训练过程(训练α,β)。文档内部参数循环训练过程是语料库总体参数过程的子过程。图2为训练过程的盘子模型图,其中黄色箭头线表示文档内部参数训练过程,参数γ,φ 根据式(17)和(19)以α,β 为参数进行循环迭代以优化参数γ,φ;棕色箭头表示语料库总体参数训练过程,在语料库内所有文档完成对参数γ,φ 的训练后,根据式(16)和(18)调整全局参数α,β;蓝色箭头表示LDA 模型的似然函数的计算过程。
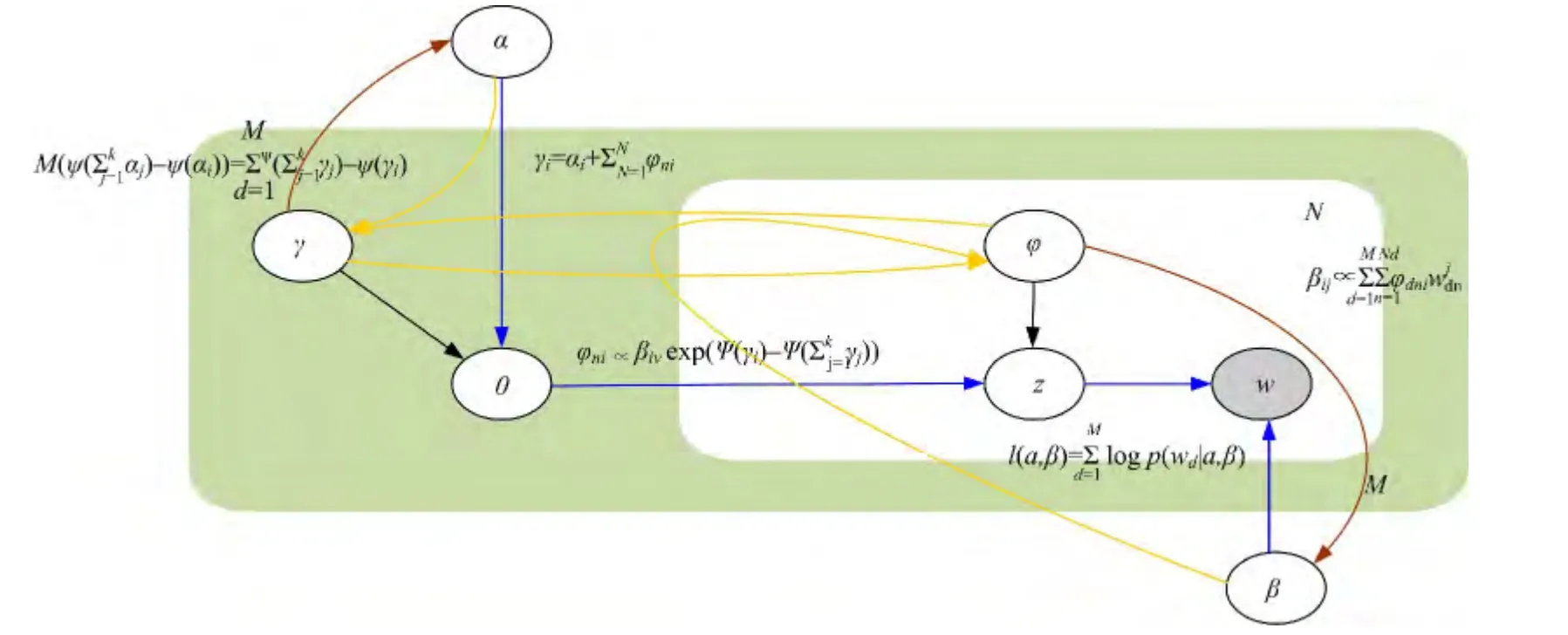
图2 LDA变分推理过程Fig.2 Variational inference process of LDA
3 变分推理优化改进策略
LDA 话题提取存在两方面问题需要改进:
(1)由于LDA 算法在初始运行时需要人为给定话题个数k(较小的整数),k与最佳话题个数k*的偏离度决定了LDA 话题发现的质量,若k<k*会导致话题训练的欠拟合,若k>k*会导致话题训练的过拟合,如何选择k值是LDA 话题发现尚未解决的问题。
(2)LDA 在样本的训练过程中缺少对β 中“模糊单词”(即话题归属不确定的单词)的处理,导致β 矩阵中各话题间的模糊化,并使得后续的训练结果出现相似的话题结果,影响话题分类的有效性。
为说明以上两方面问题,本文统计了CNN网站中的50组话题,建立了50个样本话题,并在每组话题中选择词频最高的5个名词作为样本话题词汇,如表1所示。随机选择2~5组样本话题构成文档,并以1000个随机文档为单位,建立40组语料库。
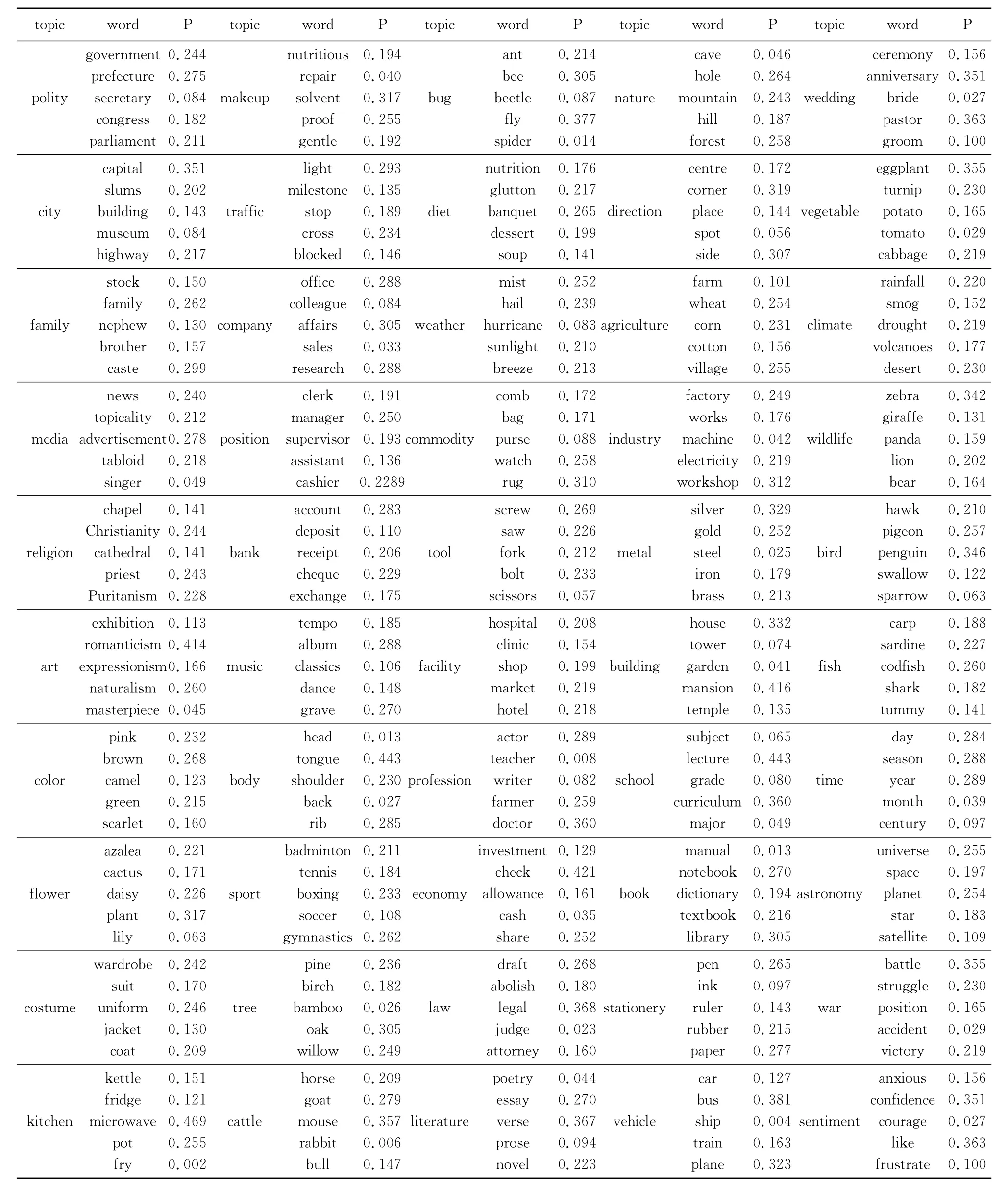
表1 CNN 50个话题的概率表Table 1 50-topics Probability Table of CNN
3.1 likelihood值分析
本文对40 组语料库建立10~70 个话题的LDA 跟踪运算,所得的likelihood值如图3所示,其中横坐标为话题个数,纵坐标为likelihood值。由于本文所建立的40组语料库是50个话题的混合,因此理想状态下50个话题的likelihood值应为极值,且50个话题的各每组样本likelihood值的偏差应该较小。但图3所示的结果说明LDA算法在话题个数大于40时,出现likelihood值的模糊化,无法根据likelihood值判断最优话题个数k*。
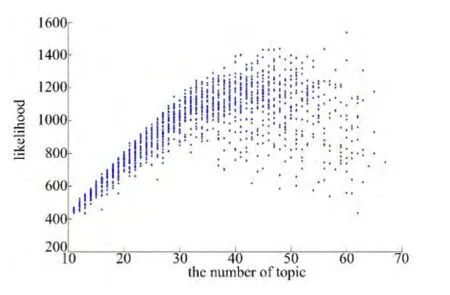
图3 表1数据集likelihood值(话题个数为10~70)Fig.3 Likelihood of the datasets in table 1(the number of topics are 10~70)
3.2 β矩阵分析
本文对第1、8、15、22、29、36 组语料库LDA训练后的β 值进行分析,由于表1数据集中属于同一话题的单词编号邻近,因此属于同一话题的单词在β 矩阵的位置邻近,可将β 矩阵元素中的最大值进行聚类以分析LDA 的分类效果。β矩阵的聚类轮廓图如图4所示,其中x 轴为话题号,y轴为单词号。由于表1数据集中各样本话题单词无重复,因此理想状态下β 矩阵聚类轮廓图的每行每列仅有一个话题聚类簇,从图4中可直观看到语料库中第1、8、15、22组数据的LDA 分析结果较差。
另外,图4中LDA 算法所挖掘出的编号相邻的话题相似度较大,且有效识别个数最多为40(语料库36)。为了提高LDA 的话题精度,降低话题间的相似度,本文提出LDA 话题增量训练算法,在提高话题分类精度的同时增量挖掘优化话题个数k*。
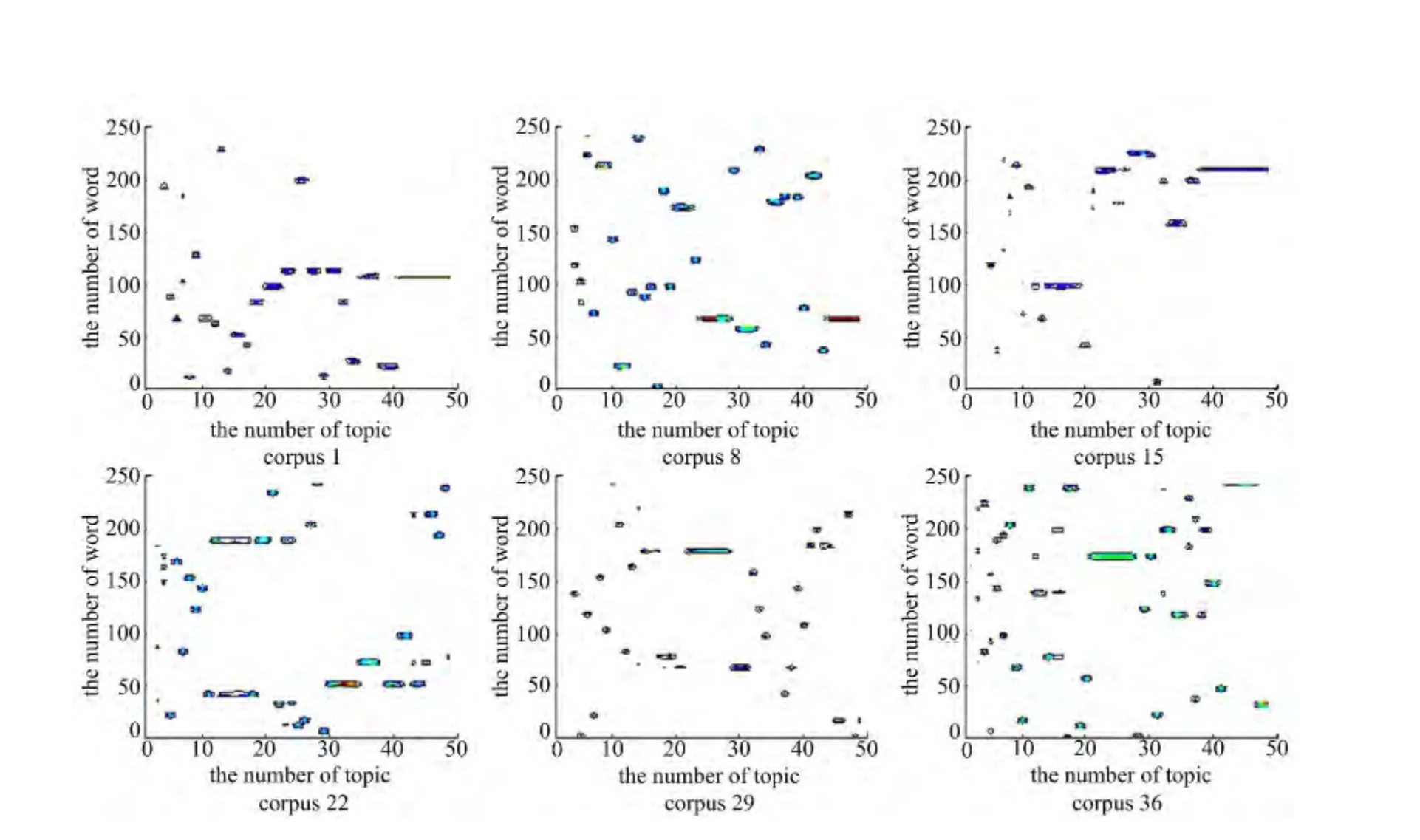
图4 语料库1,8,15,22的β矩阵分析结果Fig.4 βmatrix of corpus 1,8,15,22
3.3 LDA话题增量训练算法
变分推理的执行过程中,以文档内部话题-单词的后验概率φ 作为α 和β 训练的中间变量φi,j=p(z=j|w =i),若话题个数为k(k<k*,k*为最优话题个数),必存在某一单词的话题不确定度较高,即φi,*的熵值entropy(φi,*)较大,其中某一单词wi的熵值表达式为:
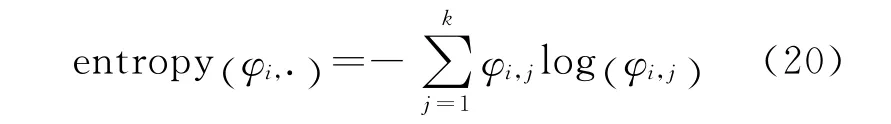
entropy(φi,*)是对单词wi的不确定性度量,entropy(φi,*)越大则wi的不确定性越高,当前的k个话题对wi的划分越不合理。此时,可提取entropy值较大的单词重新组合为一个新的话题,并复用之前的迭代结果。由于话题的增加需要进行一次语料库总体参数训练(增加参数α 和β的维数),为此LDA 话题增量训练算法对参数α和β 的修改如下:
(1)增加β矩阵的维数。引入熵的阈值参数σ,选择entropy(φi,*)大于σ的wi构成新的话题,并将新话题按熵值归一化,加入β矩阵。
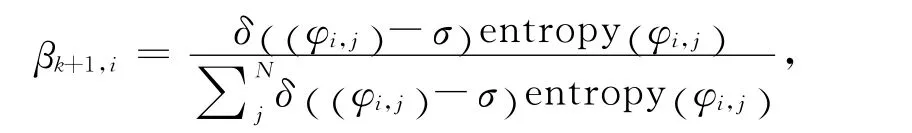
(2)增加α 的维数。以新的β 和α 作为初始参数执行新一次迭代。
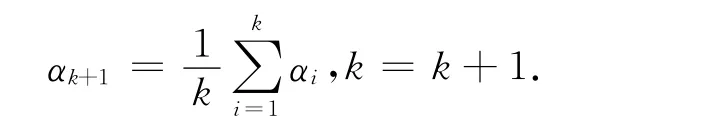
在LDA 的执行过程中,迭代次数越高参数β和α 的训练越充分,为防止LDA 话题增量训练算法在β和α 尚未充分训练的条件下进行φ 的熵值选择,导致LDA 训练不充分而影响话题发现质量,需要在LDA 迭代过程中加入迭代参数c,每进行c次迭代时执行一次LDA 话题增量训练算法。
图5为LDA 话题增量训练算法的参数训练过程,其中绿色箭头为LDA 话题增量训练算法对α 和β 的增量训练过程。
具体的算法描述如下:
功能:利用LDA 话题增量训练算法对训练最优话题个数k*
输入:初始话题个数k
输出:最优话题个数k*及语料库参数α和β


4 实验分析
4.1 CNN 数据集分析
图6为语料库13的LDA 迭代跟踪过程(语料库13 共进行57 次迭代),从中可以直观发现LDA 算法对66~70 号单词“makeup”话题的识别较差,其原因在于LDA 迭代过程中未能在β矩阵中提取“makeup”话题,使得“makeup”单词的话题隶属度相对模糊,影响了β 后序训练过程中对“makeup”话题的识别。
本文利用大量模拟实验验证了LDA 话题增量训练算法参数的有效范围分别为σ =(0 ~1.6),c=(3~12),并在4.3节分析了参数σ和c的最优取值问题,图7为利用本文LDA 话题增量训练算法(以10为初始k值,σ=0.3,c=5)对语料库13的增量迭代过程,该图直观显示了话题个数从10增量训练到50的过程中,话题间的独立逐渐增强,相比于图6中LDA 话题增量训练算法更趋于理想状态。
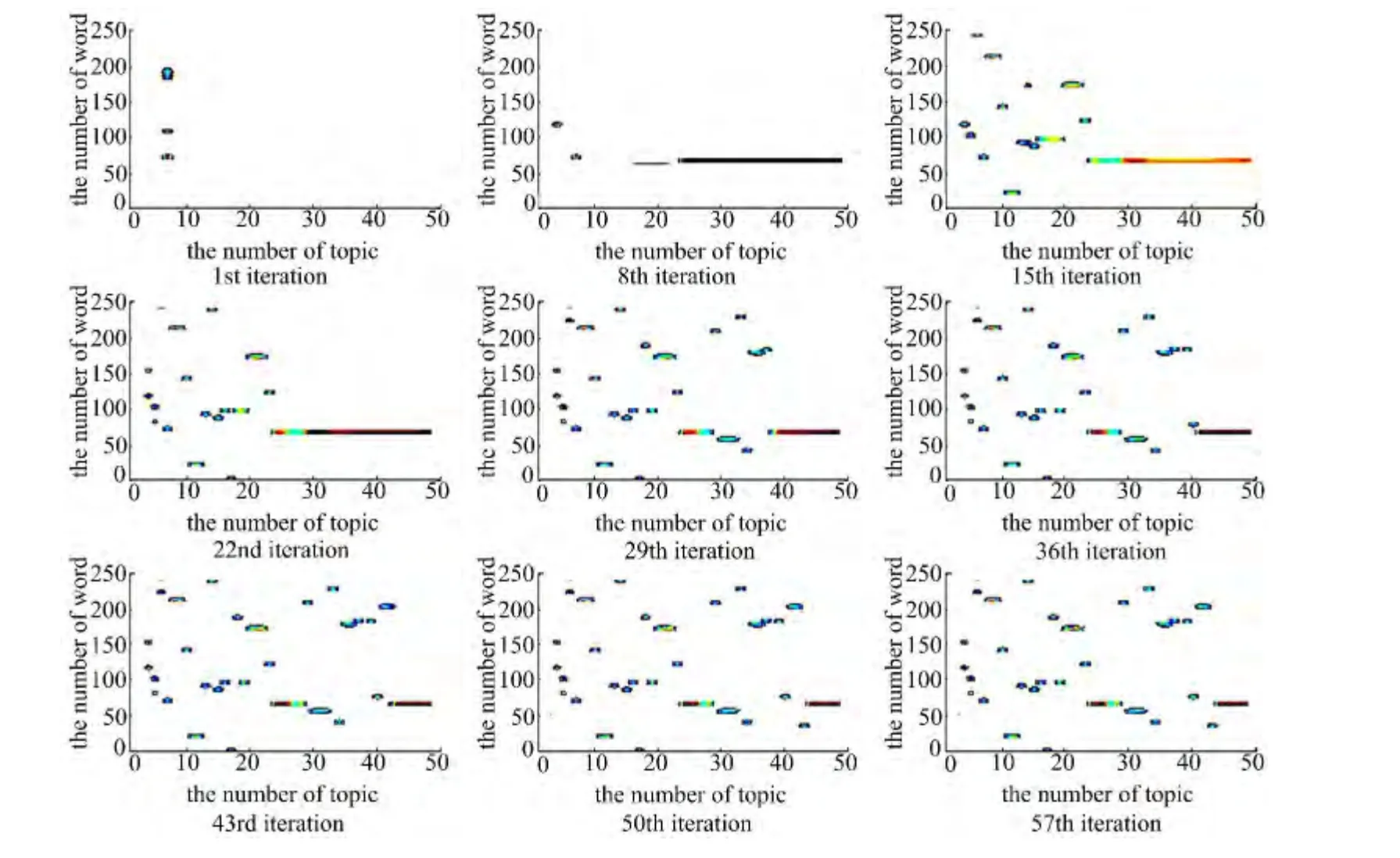
图6 语料库13的LDA迭代跟踪过程Fig.6 LDA iterative tracking process of corpus 13

图7 语料库13的LDA跟踪过程Fig.7 LDA tracking process of corpus 13
图8 为40 组语料库在本文算法下的likelihood值(以10为初始值,σ=0.3,c=5),该图显示了本文算法的最佳话题发现个数集中在40~50之间。
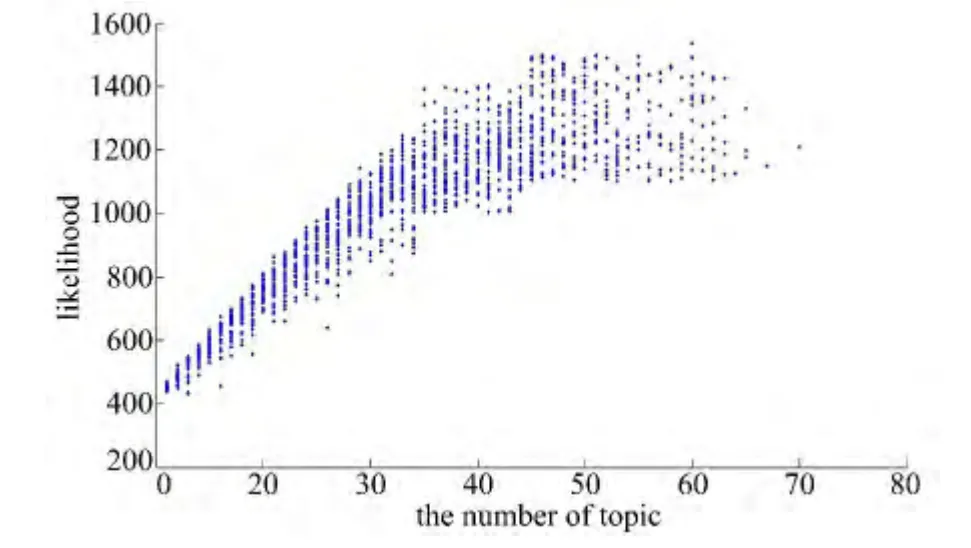
图8 表1数据集LDA话题增量训练算法下的likelihood值Fig.8 Likelihood of the dataset in Table 1by the LDA topic increments training algorithm
4.2 真实数据集对比
在数据集的选择方面,本文采用有明确文档分类的数据集,以分析本文算法对话题个数选取的有效性,本文分别选取了自然语言处理中常用的3组数据集,各数据集的介绍如下:
(1)所选择的数据库包括第36届加拿大国会记事录Aligned Hansards of the 36th Parliament of Canada(AHPC)a卷(共40个议案)和b卷(共40个议案),总单词量约为1 300 000个。将每个议案的章节作为LDA 分析的“文档”,由于同一议案趋近于同一话题,因此该数据集的理想话题个数均为40。
(2)兰卡斯特新闻书籍语料库The Lancaster Newsbooks Corpus,本文算法取其中25 类(500本书)书籍为数据集,以每本书的摘要作LDA 分析的“文档”,由于同一类书籍的新闻话题近似,因此该数据集的理想话题个数为25。
(3)路透社经典文档分类语料库Reuters 21578 Classic text categorization corpus(共50类),以每本书的摘要作LDA 分析的“文档”,该数据集已将各文档进行了分类,因此该数据集的理想话题个数为50。
本文算法对上述数据分别利用LDA 和LDA话题增量训练算法(σ=0.3,c=5)进行40次实验,其对比结果如图9所示,其中蓝色为LDA 算法的分析结果,红色为本文算法的分析结果,从结果可直观判断本文算法的likelihood 高于LDA算法,验证了本文算法的话题分类合理性高于LDA 算法。在话题个数识别方面,各组数据的话题个数分别为40、45、23、55,接近于理想话题个数。

图9 4种语料库likelihood对比图Fig.9 Comparison chart of 4corpuses
4.3 参数σ 和c 分析
本文利用LDA 话题增量训练算法对第36届加拿大国会记事录Aligned Hansards of the 36th Parliament of Canada(AHPC)a卷(共40个议案)作为数据集进行200次迭代,每次迭代进行15次实验,其中参数分别为σ =(0.1∶0.1∶1.5),c=5,每次将话题个数收敛于38~42的结果判定为正确(共有1036次正确分类),其统计直方图如图10(a)所示。以AHPC数据集进行200次迭代,每次迭代进行8次实验,其中参数分别为σ=0.3,c=(3∶1∶10),每次将话题个数收敛于38~42 的结果判定为正确(共有966 次正确分类),其统计直方图如图10(b)所示。通过图10(a)与(b)的分析可知:当σ>1.5时分类的趋于无效,且c 的 最 优 取 值 区 间 为(3,10)。图11 为AHPC的三维stem 图,其中LDA 话题增量训练算法的最优值为σ=0.45,c=6。
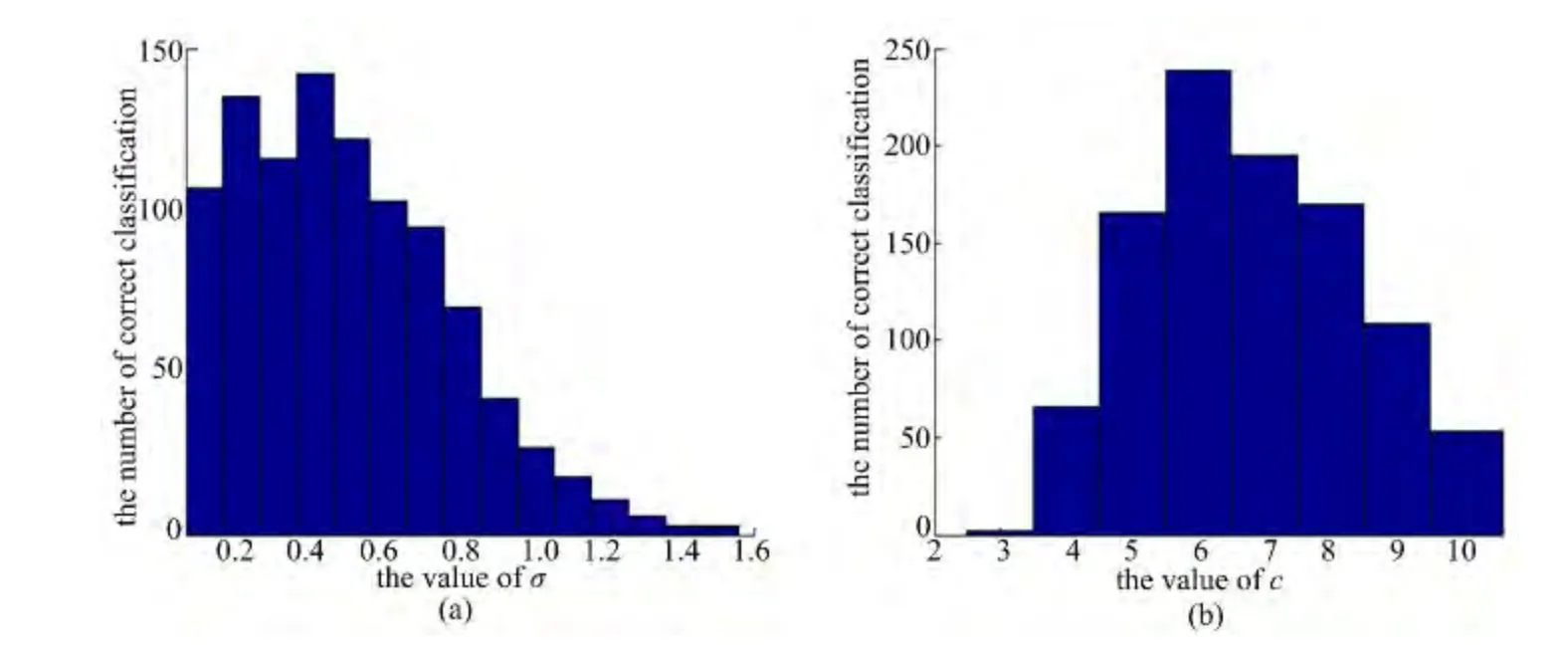
图10 AHPC数据集统计直方图Fig.10 Histogram of AHPC dataset
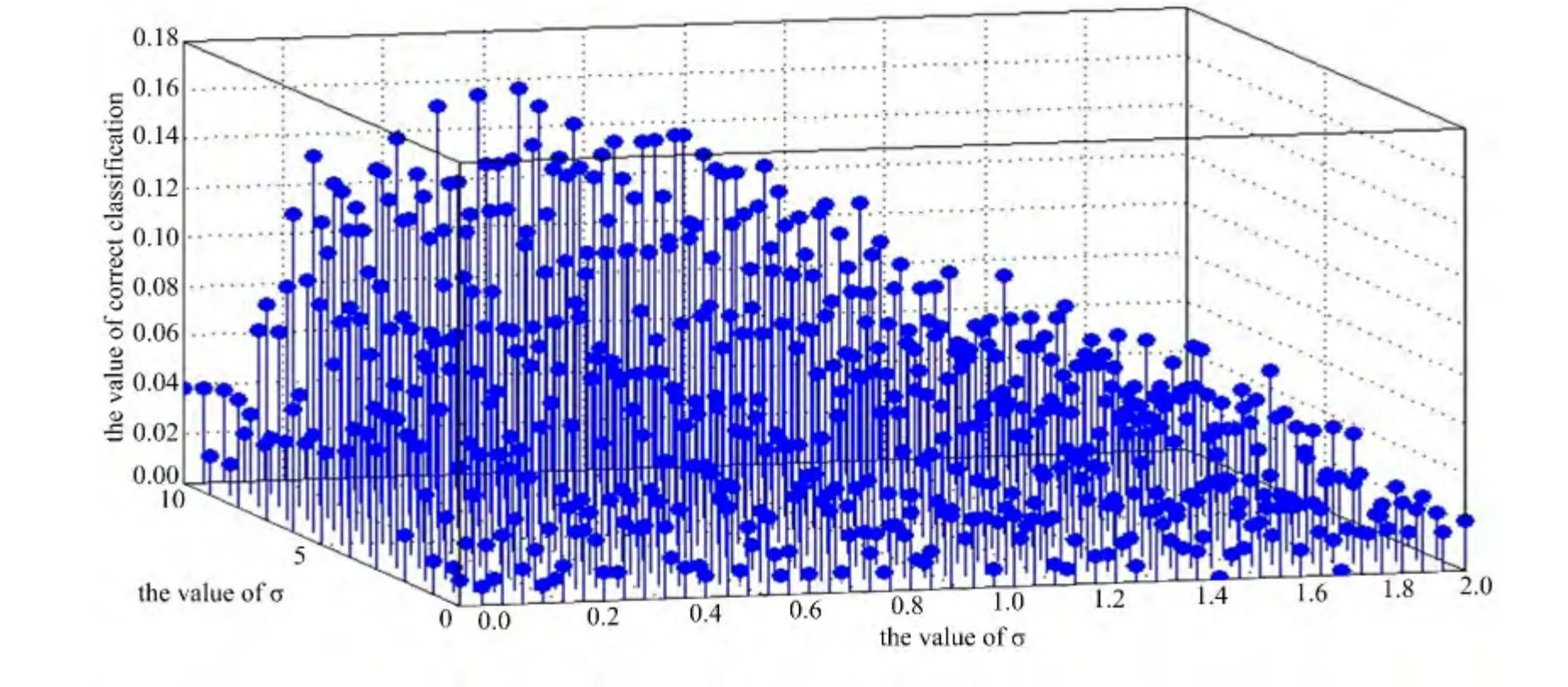
图11 AHPC的三维stem 图Fig.11 3Dstem figure of AHPC
5 结 论
本文利用LDA 话题增量训练算法,创新采用以单词-话题概率熵值作为LDA 迭代过程中模糊单词选择标准,将所选择模糊单词归入新的话题优化LDA 的迭代过程,以提高话题独立性为手段提高各单词的合理化分类;所提出的LDA话题增量训练算法可在实现LDA 话题分类优化的同时对最优话题个数k 进行增量训练,最后通过实验对比验证了本文算法在话题分类合理度likelihood与k自动选择方面的优越性,对深入研究话题分类模型具有一定的理论和实际意义。
[1]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[2]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.Xu Ge,Wang Hou-feng.The development of topic models in natural language processing[J].Chinese Journal of Computers,2011,34(8):1423-1436.
[3]Blei D M,Griffitchs T L,Jordan M I,et al.Hierarchical topic models and the nested Chinese restaurant process[C]∥Advances in Neural Information Processing Systems 16.Cambridge,MA:MIT Press,2004:17-24.
[4]Blei D M,Lafferty J D.Correlated topic models[C]∥Advances in Neural Information Processing Systems 18.Cambridge,MA:MIT Press,2006.
[5]Blei D,Lafferty J.A correlated topic model of science[J].Annals of Applied Statistics,2007,1(1):17-35.
[6]Li W,McCallum A.Pachinko allocation:DAGstructured mixture models of topic correlations[C]∥Proceeding of the ICML.Pittsburgh,Pennsylvania,USA,2006:577-584.
[7]Mimno D,Li W,McCallum A.Mixtures of hierarchical topics with pachinko allocation[C]∥Proceeding of the ICML.Corvllis,Oregon,USA,2007:633-640.
[8]Wang X,McCallum A.Topics over time:a nonmarkov continuous-time model of topical trends[C]∥Proceeding of the Conference on Knowledge Discovery and Data Mining(KDD).Philadelphia,USA,2006:113-120.
[9]Griffiths T L,Steyvers M,Blei D M,et al.Integrating topics and syntax[C]∥Advances in Neural Information Processing Systems 18.Vancouver,Canada,2004.
[10]Wallach H.Topic modeling:beyond bag-of-words[C]∥Proceeding of the 23rd International Conference on Machine Learning.Pittsburgh,Pennsylvania,2006:977-984.
[11]张晨逸,孙建伶,丁轶群.基于MB-LDA 模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.Zhang Chen-yi,Sun Jian-ling,Ding Yi-qun.Topic mining for microblog based on MB-LDA model[J].Journal of Computer Research and Development,2011,48(10):1795-1802.
[12]韩晓晖,马军,邵海敏,等.一种基于LDA 的Web论坛低质量回贴检测方法[J].计算机研究与发展,2012,49(9):1937-1946.Han Xiao-hui,Ma Jun,Shao Hai-min,et al.An LDA based approach to detect the low-quality reply posts in web forums[J].Journal of Computer Research and Development,2012,49(9):1937-1946.
[13]Blei D M,McAuliffe J.Supervised topic models[C]∥Advances in Neural Information Processing Systems(NIPS).Vancouver,Canada,2008.
[14]Steyvers M,Smyth P,Rosen-Zvi M,et al.Probabilistic author-topic models for information discovery[C]∥Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Seattle,Washington,2004:306-315.
[15]McCallum A,Corrada-Emmanuel A,Wang X.The author recipient-topic model for topic and role discovery in social networks:experiments with enron and academic email[R].Technical Report UM-CS-2004-096,2004.
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
电信科学(2016年9期)2016-06-15 20:27:25
语言与翻译(2015年4期)2015-07-18 11:07:45
