
一种多路海量视频流数据并行化处理方法研究
2015-06-05 09:50:59陈文竹陈岳林蔡晓东
电视技术 2015年19期
陈文竹,陈岳林,蔡晓东,王 迪
(桂林电子科技大学,广西 桂林 541004)
一种多路海量视频流数据并行化处理方法研究
陈文竹,陈岳林,蔡晓东,王 迪
(桂林电子科技大学,广西 桂林 541004)
针对视频监控系统中传统的处理方法计算机资源能力不足,无法满足海量高效的视频流数据内容分析的问题,引入Storm并行计算平台,提出了一种弹性的基于多路视频流的并行化处理方法,并通过一种高效的内存共享机制,集成人车分类算法到分布式处理平台,使算法与高性能并行计算资源有效融合。通过对比实验表明,该并行化处理方案高效稳定,集群运行良好,负载均衡,能满足大规模视频流数据处理的需要。
视频流;Storm;内存共享;人车分类;并行计算
智能视频监控[1]是图像处理领域一个重要研究课题,广泛应用于智能交通、智能安防等领域。对摄像头记录的视频数据内容进行智能分析,对其中的行人和车辆等信息进行检测分类,进而实现基于视频内容的检索,在视频监控中具有重要意义。目前有许多有关人车分类算法的研究,文献[2]提出了一种基于多粒度感知SVM的复杂场景人车分类方法,有效避免光照、色彩目标等变化对目标检测分类造成的影响。文献[3]提出了一种基于视频的行人车辆检测与分类方法,解决了目标分割不完整、检测准确率低的问题。文献[4]提出了一种基于运动区域的行人检测与跟踪算法,能够快速准确地对行人进行检测跟踪,然而当视频数据为海量时,计算资源的瓶颈往往限制了算法的应用,基于串行的算法优化无法明显提高海量视频图像处理的高效性,因此有必要引入并行化计算。
基于Hadoop的开源分布式计算架构是当前并行处理平台的代表,文献[5]详细介绍了Hadoop的分布式计算框架。文献[6-7]提出了基于Hadoop的分布式海量视频处理方法,对非结构化视频数据去耦合处理,实现了海量视频的分布式转码。文献[8]提出了一种基于Hadoop的分布式视频离线处理方法,并应用于视频监控系统中。不过Hadoop只适用于海量文件的批处理,数据一次写入多次读取,虽然具有高容错、可扩展、吞吐量大的特性,但是实时响应差且数据处理延迟较长,当处理数据为连续不断的视频流时,Hadoop平台无法满足流式处理的需求。不同于Hadoop的批处理特性,基于内存的Storm[9-10]流式计算平台,数据通过网络直接导入内存,减少了磁盘IO时耗,从根本上提升了海量数据处理的响应能力,为海量视频处理提供了新的途径。
1 相关研究
1.1 Storm简介
Storm是实时的并具备高容错的分布式计算系统,主要由一个主节点(Nimbus)和一群工作节点(Worker)组成,同时每个工作节点上运行一个监督节点(Supervisor),通过Zookeeper进行协调。主节点负责任务分配,并监控状态。监督节点会监听所分配子节点机器的任务状态,根据需要启动/关闭工作进程。
Storm中,各个组件间的消息流动形成逻辑上的拓扑结构,故运行一个实时应用程序通过提交拓扑(Topology)完成。如图1所示,Spout是消息的生产者,负责数据的抓取,从来源处读取数据放入拓扑,然后以元组(Tuple)的形式发送到数据流中,Bolt封装了所有的消息处理逻辑,通过流分组(Stream Grouping)将Spouts与Bolts连接起来。
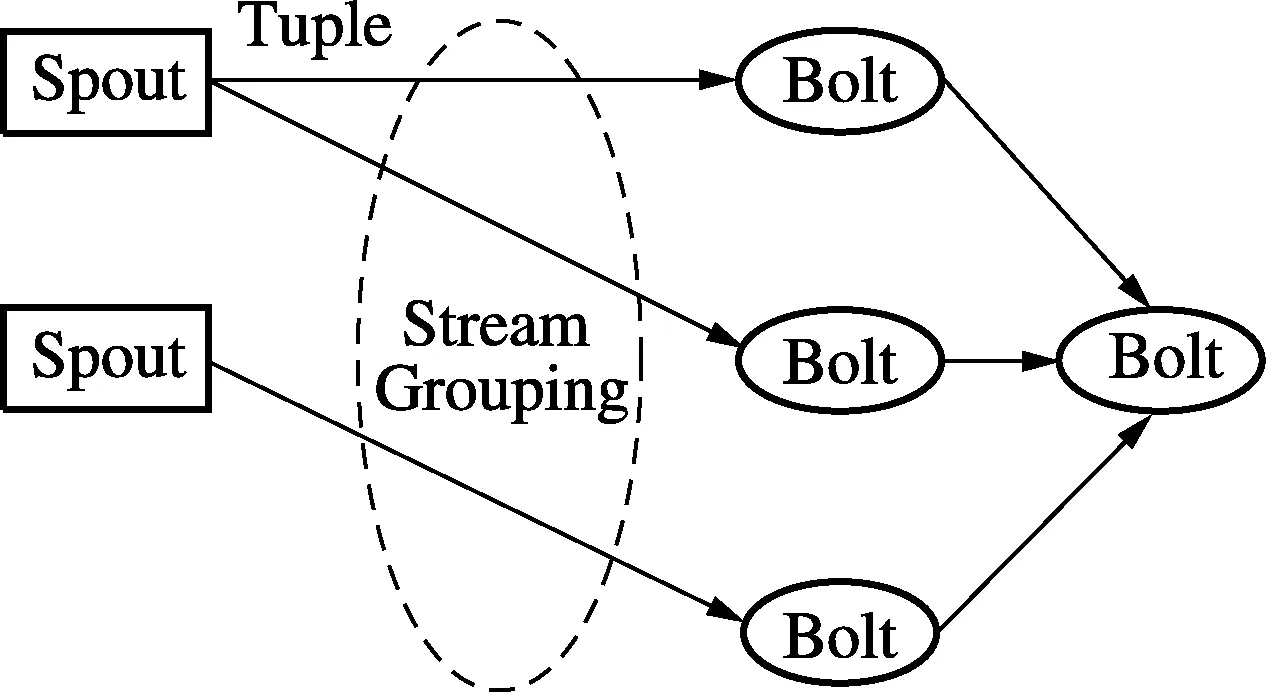
图1 拓扑图
1.2 人车分类
人车分类主要分为4个部分:感兴趣前景区域的提取,目标跟踪预测,特征提取,目标分类。流程如图2所示。前景区域的提取是视频分析的最初阶段,将运动目标从背景中分离,为下一阶段的跟踪与识别做准备。目标跟踪是对场景中的感兴趣目标进行预测与定位,可以更准确地得到目标的运动状态。通过特征提取与目标识别对运动信息进行筛选,对人车信息进行识别。
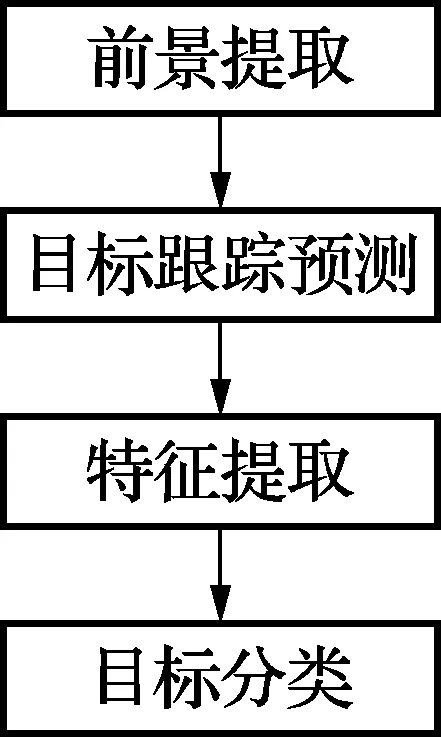
图2 人车分类流程图
在Storm集群中每个处理的元组相互独立,算法的并行实际是基于文件的并行实现。本文使用多帧差分法提取前景区域,卡尔曼滤波实现目标跟踪预测,采用HOG算子与SVM算法实现目标的识别分类,在实现每段视频数据处理完整性的前提下也能准确检测出人车目标。
2 基于Storm的人车分类算法的并行化实现
本文利用Storm并行化处理框架实现基于海量视频流的人车分类,核心思想是将计算任务分配给多个节点,通过任务并行化达到提升性能的目的。主要包括如下步骤:缓存视频流获取、自定义VideoStreamSpout类组件、算法融合。
2.1 缓存视频流获取
远程摄像头捕捉到的视频数据,通过网络传输到本地云平台处理。流媒体在传输的过程中,由于带宽等的影响,不可避免地会出现数据丢失或失序的现象,而且数据采集的速度和数据处理的速度不一定同步,会造成数据堵塞。RTSP[11-12](实时流媒体协议)能够提供可控制的、按需传输的实时数据,监控摄像头产生的视频流通过本地RTSP流转服务器,可以独立实现多路管道中的视频流数据的缓存。
视频流为帧与帧之间连续相关的非结构化数据流,物理分割会造成帧不完整、分割后缺少关键帧(I帧)的问题,因此需要对视频流数据解耦合。提出了一种基于关键帧的视频流缓存方法,如图3所示,视频图像以序列为单位进行组织,一个序列是一段图像编码后的数据流,以关键帧开始到下一个关键帧结束。根据关键帧的位置进行缓存,可以保证所有的缓存块都有必要的帧信息,不会出现缺少关键帧无法解码的问题。
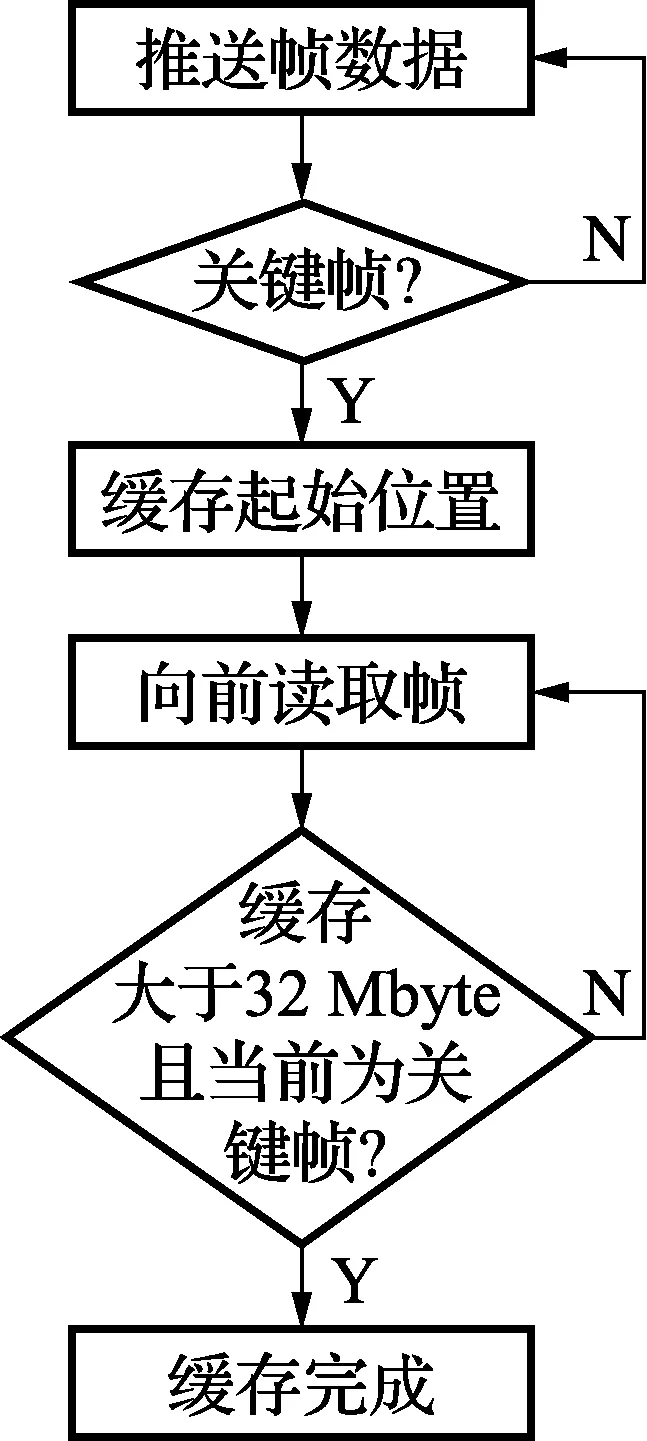
图3 视频流缓存方法
2.2 自定义VideoStreamSpout类组件
自定义VideoStreamSpout类组件,通过继承BaseRichSpout接口实现数据读取,数据读取流程如图4所示。如2.1节所述获取独立的缓存视频流,当缓存流达到元组要求就以队列形式推送。open()方法打开缓存流,将数据封装成一个个Tuple,通过nextTuple()方法不间断发送新的Tuple到消息队列。为保证数据的连续性,每个Tuple会随机分发唯一的ID。拓扑提交后会一直运行直到被手动杀死。
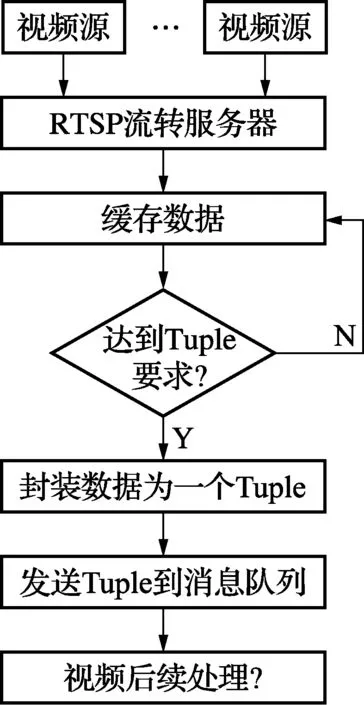
图4 数据读取
此外,Storm在检测到一个元组被成功处理时调用 ack()方法,否则调用fail()方法,这样保证了数据处理的可靠性。
2.3 算法融合
计算任务主要在VideoStreamBolt环节实现,VideoStreamBolt组件与VideoStreamSpout组件之间通过松耦合的管道机制实现流传输,这种调度机制极大提升了并行计算的稳定性和可扩展性。Storm的拓扑结构通过Java语言实现,Java语言因其简单、面向对象、可移植、平台无关等特性,已成为分布式计算领域的主流程序设计语言。影响Java语言算法实现的最大问题是速度,在原始的Java解释器中,C语言的速度是解释过的Java语言的20倍左右,用Java语言来完成对性能敏感的高性能密集计算目前不是最好的选择。
视频的解码及人车分类算法分别使用FFMPEG视频图像编解码库与Opencv开源计算机视觉处理库实现,采用C/C++ 语言编写,在不改变并行结构及算法效率的情况下,Java的JNI(Java Native Interface)接口实现了Java数据与 C++ 本地库的数据交互,但频繁的数据拷贝会大大降低数据传递的效率及稳定性,且当交换数据块较大时,会造成内存泄漏,对计算机内存造成较大损耗。同时频繁的数据拷贝造成算法的延时在流式计算中会产生数据堵塞。本文提出了一种优化的高效并行内存共享机制,可以最大化优化代码的运算速度,具体结构如图5所示。
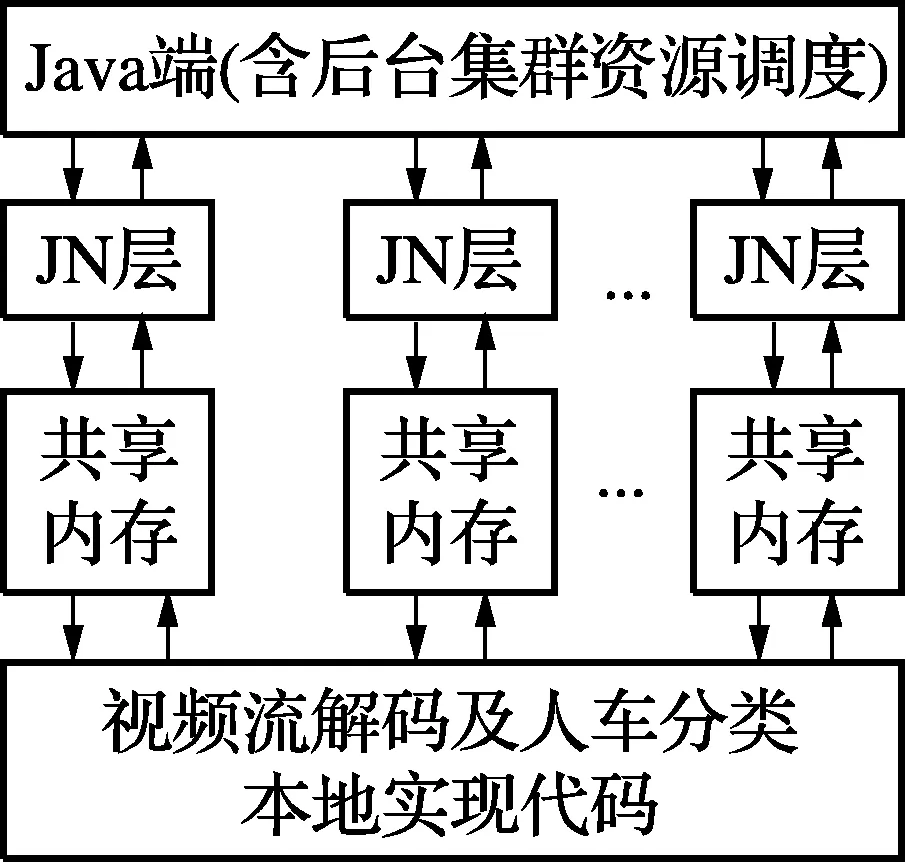
图5 并行内存共享机制
在该机制中,Java端作为程序的起始端,负责任务的分发及资源调度,构建并行计算环境。当有数据交互发生时,Java端开辟堆内存空间与JNI层共享,并将数据信息导入共享内存,通过地址值的传递,实现本地算法与Java端的数据交互,同时,也可以通过并行内存共享机制,将本地算法处理完成后的人车等目标信息导入Java端。在不打破Storm并行计算框架和Java应用程序环境的情况下,通过内存共享机制,Java端与C++本地算法实现端数据同步变化,相比于普通的数组传递,效率更高更快,减少了数据堵塞的产生,且适合长期使用、频繁访问的大块内存的共享。
3 实验与分析
本实验在操作系统为centos6.6的64位华硕服务器下实现,硬件环境如下:CPU为2个6核Intel(R) Xeon(R) CPU E5-2620处理器,内存为64 Gbyte,通过KVM虚拟化技术搭建Storm集群,集群中设置1个Nimbus节点和3个Supervisor节点,网络环境为10.0.0.1网段的局域网。软件环境为apache-storm-0.9.2-incubating。测试视频为编码方式是H.264,像素为1 920×1 080高清视频流数据。
3.1 基于高效内存共享机制的性能分析。
验证内存共享机制的高效性,测试在相同环境下本文方法与基于数组传递的方法处理不同大小的视频数据时耗如表1所示。
表1 内存共性机制高效性分析测试
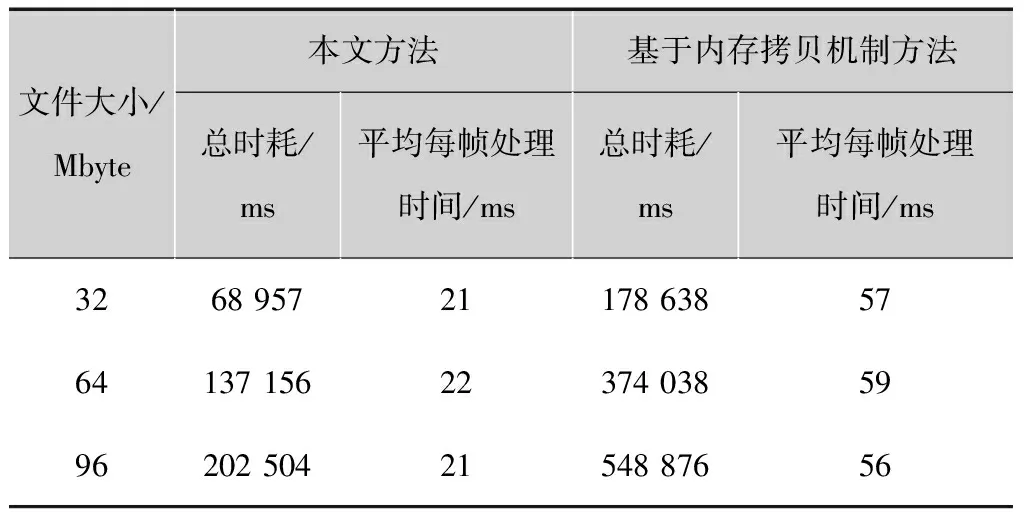
文件大小/Mbyte本文方法基于内存拷贝机制方法总时耗/ms平均每帧处理时间/ms总时耗/ms平均每帧处理时间/ms32689572117863857641371562237403859962025042154887656
从表1可以看出,两种机制分别实现人车分类算法,本文方法明显优于基于内存拷贝机制的方法,且随着数据量的增大,本文方法中每帧视频数据平均处理时间相对稳定,能满足JNI调用本地算法高效性需求。
3.2 Storm集群下视频处理高效性分析
吞吐量指系统单位时间内处理数据的大小,是衡量并行系统实时高效性的重要指标。记录在Storm单机模式与集群模式下,随着数据量的增加,完成视频处理所需时间,对比两种模式下的结果如图6所示。
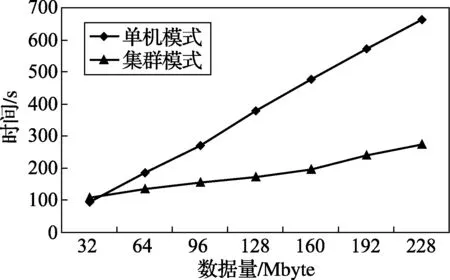
图6 吞吐量分析测试
由图6可知,当视频数据流比较小时,由于任务分发数据传输等都需要耗费一定的计算机资源和时间,单机模式下数据流处理时间低于集群模式的处理时间。但是随着数据流的增大,任务分发所需时间远小于视频处理的时耗,集群模式处理时间明显缩短。
3.3 负载均衡性分析
负载均衡是并行计算中的一项重要指标,数据计算过多分布于同一计算节点,形成数据倾斜,会造成计算资源的浪费,影响集群稳定性。Storm并行框架的数据处理基于内存进行,在任务执行过程中使用nmon工具统计各节点内存使用情况如图7所示。
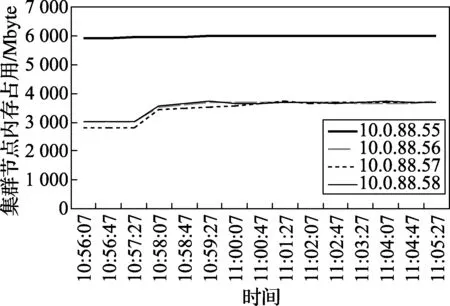
图7 集群内存使用情况
图中IP为10.0.88.55的计算机为Nimbus节点,分配 8 Gbyte 内存空间,其他为工作节点分配4 Gbyte内存空间。Nimbus节点需要分配计算任务并监控集群状态,内存使用率高于工作节点,保持稳定。各工作节点在硬件资源分配相同的条件下,在任务开始阶段内存上升平稳,随后趋于稳定,由此可知各工作节点内存使用率大致相同,没有出现某一节点内存使用过高的情形,说明在任务执行过程中,集群内存使用相对合理,没有出现数据倾斜的情况,负载均衡。
4 结论与展望
针对海量监控视频流数据实时分析的需求,设计了基于多路视频流的并行处理框架,提高了视频流数据处理的效率。其次,通过高效的并行内存共享机制将人车分类算法与Storm实时计算平台融合,解决了算法实现与分布式计算框架互连互通的问题。最后,通过对比实验测试分析,分布式集群能高效地完成视频流数据处理,稳定性良好。
在未来的研究中,对于如何提高人车分类算法的鲁棒性及准确性,以及如何解决由于缓存数据块的独立性造成检测重复目标过多的问题,都有待于进一步解决。
[1] 郑世宝. 智能视频监控技术与应用[J].电视技术,2009,33(1):94-96.
[2] 吴金勇,赵勇,王一科,等. 基于多粒度感知SVM的复杂场景人车分类方法[J].北京大学学报:自然科学版,2013,49(3):404-408.
[3] 杨阳,唐惠明.基于视频的行人车辆检测与分类[J].计算机工程,2014,40(11):135-138.
[4] 姚倩,安世全,姚路. 三帧差法和Mean-shift结合的行人检测与跟踪研究[J].计算机工程与设计,2014,35(1):223-227.
[5] 李建江,崔健,王聃,等. MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[6] KIM M,CUI Yun,HAN Seungho,LEE H K. Towards efficient desion and implementation of a Hadoop-based distributed video transcoding system in cloud computing environment[J].International Journal of Multimedia and Ubiquitous Engineering,2013(2):213-224.
[7] RYU C,LEE D,JANG M,et al. Extensible video processing framework in apache Hadoop[C]//Proc. IEEE International Conference on Cloud Computing Techology and Science.[S.l.]:IEEE Press,2013:305-308.
[8] 高东海,李文生,张海涛. 基于Hadoop的离线视频处理技术研究与实现[J].软件,2013,34(11):5-9.
[9] YANG Wenjie,LIU Xingang,ZHANG Lan. Big data real-time processing based on storm[C]//Proc. 12th IEEE International Conference on Trust,Security and Privacy in Computing and Communications. [S.l.]:IEEE Press,2013:1784-1787.
[10] FRACHTENBERG E,PETRINI F,FERNANDEZ J,et al. STORM:scalable resource management for large-scale parallel computers[J].IEEE Trans.Computers,2006,55(12):1572-1587.
[11] KHAN S Q,GAGLIANELLO R,LUNA M. Experiences with blending HTTP,RTSP,and IMS[J].Communications Magazine,2007,45(3):122-128.
[12] 李校林,刘海波,张杰,等. RTP/RTCP,RTSP在无线视频监控系统的设计与实现[J].电视技术,2011,35(19):89-92.
责任编辑:任健男
Parallel Processing Method for Multiplex Massive Video Streaming
CHEN Wenzhu, CHEN Yuelin, CAI Xiaodong, WANG Di
(GuilinUniversityofElectronicTechnology,GuangxiGuilin541004,China)
For solving the problem of the traditional method can’t apply to analysising massive video streaming contents efficiently in video surveillance, Storm distributed computation platform is introduced, and a flexible parallel processing method is presented to process multi-channel video streaming. A highly efficient mechanism of sharing memory is used to merge pedestrian vehicle classification algorithm with high performance parallel computing resources. The experiment shows that the parallel processing method can not only have the characteristics of stable and efficient, but also the platform works good. It proves that the method suits for large scale video streaming processing.
video streaming; Storm; sharing memory; pedestrian vehicle classification; distributed computing
广西自然科学基金项目(2013GXNSFAA019326)
TN911.7;TP391
A
10.16280/j.videoe.2015.19.028
2015-01-16
【本文献信息】陈文竹,陈岳林,蔡晓东,等.一种多路海量视频流数据并行化处理方法研究[J].电视技术,2015,39(19).
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
无线互联科技(2022年11期)2022-08-18 01:56:42
数字通信世界(2020年11期)2020-12-04 05:24:22
海峡姐妹(2020年8期)2020-08-25 09:30:30
E动时尚·科学工程技术(2019年4期)2019-09-10 16:43:57
当代陕西(2019年14期)2019-08-26 09:42:00
电子制作(2019年10期)2019-06-17 11:45:04
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
办公自动化(2016年13期)2016-08-24 01:47:29
测绘科学与工程(2014年2期)2014-02-27 07:05:49
