
类别误标下证据链推理的群决策分类方法
2015-06-05 15:31:25余海燕
系统工程与电子技术 2015年11期
余海燕,沈 江,徐 曼
(1.天津大学管理与经济学部,天津300072;2.南开大学商学院,天津300071)
类别误标下证据链推理的群决策分类方法
余海燕1,沈 江1,徐 曼2
(1.天津大学管理与经济学部,天津300072;2.南开大学商学院,天津300071)
针对群决策分类中可解释性的推理信息存在类别错误标识的问题,提出了类别误标下证据链推理的群决策分类方法。该方法采用可信度函数的一致性和凸性,以查询案例与证据链之间的属性关联相似度作为群决策信息源的权重,建立了基于证据链推理的混合整数优化模型,实现了决策分类标识能力最大化,同时获取了可解释性最好的证据链集合。该模型考虑了决策类别的错误标识情形,依据可信度序的概念,将推导出的融合可信度作为查询案例推论可解释性的评价标准。通过多源感知数据的诊断实例,说明了该方法的有效性和合理性。
群决策分析;证据链;关联相似度;错误标识;可信度序
0 引 言
群决策分类是指决策者对多属性查询方案依据数据库中的案例和相关领域知识(如规则)等多源信息下的评价值,给出有限个查询问题的分类结果。这类决策问题广泛应用于工程实践中,例如,一组医师提供群决策信息对疾病会诊,可通过信息融合中的知识推理处理积累的证据和实时感知的查询案例,使得医师专注于处理诊断最重要环节。IBM开发的Watson智能机[1],将通过关联患者记录与临床证据,使用多源信息进行群决策等。目前关于多属性群决策分类问题的研究已经成为决策分析领域中的热点[2]。随着日益增长的信息积累、传感器感知的大数据和对新出现案例决策规则知识增长,所面临的多属性群决策分类问题日趋复杂,根据单个证据信息源的案例或规则(虚拟案例)知识很难解释查询问题的所有相关方面,实际决策时往往需要多个决策信息源提供相关知识共同推理[3-4]。
与单个决策信息源的推理问题相比,群决策分类体现在多源决策信息下的推理问题更为复杂。首先,数据库中给出案例或规则的专家们,由于认知经验、从业领域和所站角度不同,各决策者对推理问题的观点存在较大差异,需要按照一定的融合规则综合决策者们的不同看法,并产生群体推理结论。其次,多源信息的可靠性、参考价值不一样,其标识的结论对最终决策结果的影响也会不同,需要在结果中体现各信息源的重要性。因此,研究多源证据信息决策环境下的推理问题具有挑战性和实际价值。
现有的群决策分类方法中推论具有可解释性的方法主要有两类:基于案例推理与基于规则推理。这些方法只需要对案例特征属性或对规则的前件属性进行关联匹配,并不需要提供推理边界等模型参数信息,并且推论具有向前可追溯到证据方案(规则或案例),使得推理结论具有可解释性。从决策信息结构来看,文献[5]提出了基于可转移信度模型的案例推理方法,要求提供最紧密的k个案例信息作为证据,k≥1,拓展了传统的最近邻推理方法的适用性;文献[6]使用可信度函数进行案例推理,将决策概率最高的类作为推理的类别;文献[7]提出了相似度加权频率的案例推理方法,要求提供作为证据的所有案例和标识类别的可信度;文献[8]根据决策者提供的案例评价信息,提出案例信息的多属性推理方法,将可信度作为推理模型的评价标准,推导属性的权重和类别的边界值;文献[9]使用证据推理的规则推断方法,要求决策者提供证据的可信度分布、规则前件属性的精确性等信息,实现以单个独立性规则为证据源的可信度融合;文献[10]提出了基于主成分分析的置信规则库结构学习方法,实现对前提属性过多时的置信规则库规模约简。然而,这些方法主要是针对单决策信息源作为推论的直接推理证据,目前仅有少量文献探讨了群决策环境下的推理问题;尽管如此,群决策环境下多信息源的推理逐渐成为研究的热点,一些文献[8- 11]强调将现有的推理方法拓展至群决策环境的重要性。
现有的针对群决策分类研究中,文献[2]提供了属性权重的反馈模型,研究了针对决策者提供的多源证据信息的推理问题。文献[12]针对多属性群决策中多源信息的实体异构性问题,提出了基于证据链融合推理的群决策方法,构建了半正定矩阵的二次优化模型,共享了群决策专家的经验知识;文献[11]利用鲁棒阈值的知识推理方法,推导出案例和规则的多源信息决策空间的特征值,以确定分类边界参数,然后使用信息融合方法综合这些个体决策信息源所确定的推理结果,从群体决策信息源中推导结果。在数据驱动的群决策分类问题中,错误标识(或错误注释)[13]作为一种输入数据中类别标识的噪声。例如,在决策数据收集过程中,描述数据序列(如基因或心电信号等)的功能进行类别标识(注释)对研究人员实验室调查和计算推理都极为重要,但所用的算法常对这些数据存在错误标识,如将编码为E的信号质量级别极高的数据片段错误标识为编码为A的中等质量的数据[14],或在多源数据监测的预警决策中,将正确报警类(#true alarm)的数据样本标记为错误报警类(#false alarm)。数据标识类别中存在的1%噪声,意味着每一决策推理的每一步中,选择的最近邻证据都有1%的可能与训练样本所预期选择的近邻证据集相反。传统的决策方法,大多针对的是输入数据中属性的噪声,如传感器获取数据的噪声,常使用卡夫曼等方法进行融合估计[15],而本文关注的是历史数据中分类标识的噪声,即决策类别存在错误标识的问题。
虽然先前的研究从不同角度为群决策分类提供了新思路,但也有需要完善之处。从样本误标角度,文献[5]考虑到不确定性类别标识的案例而能解决类别部分已知的情况;文献[7]、文献[9]均使用精确标识的样本,数据库中的证据序列标识是完全确定的,在证据是完全确知的情况下实现证据更新,未考虑样本误标情形。本文考虑了数据库中证据存在错误标识的情形,因此提出了一个类别误标下证据链推理的多属性群决策分类方法。该方法将群决策信息源提供的案例和规则知识组合成关联证据链,并首先使用可信度性质及可信度序概念,将基于证据链推理的多属性群决策分类问题转化为寻找候选证据序列的优化问题。然后使用查询案例与证据链之间的相似度信息和权重信息作为约束,构建基于融合可信度的混合整数优化模型。最后直接利用可信度序关系对查询案例进行推断。
1 问题描述
令(C,R)为命题空间,可信度域R是一个建立在决策事件可能集合C上的布尔代数。证据系列EC为决策者在某时刻提供的证据(链)集合。信息源中第l条证据链[12]Rl表示为
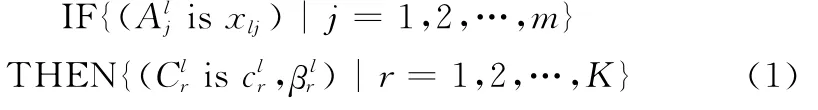
式中,xlj为第j个前件的属性取值;是其第r个类别标识的属性取值;对于二元标识分类,如诊断,K=2为决策者提供的关于类别标识的可信度,既可是数值观测值也可是主观评价值。前件属性之间的逻辑关系可用∧表示“与”。逻辑关系“或”通过前件属性的分解,可转化为仅包括“与”的关系。另外,查询案例记为其对应的观测值向量为 Ui的第r个标识类别的可信度。前件属性权重参数记为wj,δil为Ui与Rl的关联系数。
以文献[15]提供的传感器波形数据ECG V为例,说明类别标识,如图1所示。这里的取值范围为{E,A}。这里的类别标识由PhysioNet研究机构中的多个领域专家提供,对ECG V信号数据在一段时间内的信号质量所做的分类。每个类别标识下方对应的数据为多个属性取值,常通过统计特征值或信号质量指数计算得出,如图1中的虚线框所示。其对应的为主观概率知识,可根据实际给出,这里将其记为:横轴为时间轴,纵轴为波形信号幅度和类别标识。

图1 传感器感知数据的类别标识
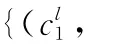
通过案例和规则的信息共享,使用证据链推理,实现群决策分类。由于实际推理问题一般比较复杂,决策者难以给出推理参数的准确值[16]。相比较而言,更实际的做法是选择关联最紧密的证据链,并据此给出针对查询案例的类别标识及其可信度。因此,利用证据链来推测推理参数可以简化决策过程,提高决策效率和品质。另外,考虑到证据信息源可来自不同水平的专家或不同的数据库,对同一个查询案例很难获得一致的推理结果。因此,考虑查询案例在各个标识类别下的可信度分布更符合实际。
基于以上两点考虑,本文扩展了一般的证据推理问题。证据链主要来源于两方面:一方面是决策者历史经验的决策案例;另一方面是领域规则等相关知识(或构造的虚拟案例)。因此,本文的多属性群决策分类的推理主体不限于多决策者,已拓展到多决策信息源。
2 基于证据链推理的群决策方法
为了直接利用证据链信息对查询案例进行推理,并对多决策者提供的评价信息提供一致性分析,首先需要了解基于可信度函数的推理方法的基本性质。
2.1 可信度函数与可信度序关系
可信度函数[17]是一个从R映射到一个封闭实数区间的函数,它关于包含关系单调,下极限在Ø上可达。
定义1令(C,R)为命题空间,证据系列EC⊂R,决策者对R中的元素存在可信度函数β(Rl),简记为βl。其性质包括:

考虑决策者的偏好,将符号型的标识数据与数值型的不确定性推理联系起来,引入可信度序关系,以使用具有一致性的可信度函数实现群决策分类。
定义2[18]命题空间(C,R)中存在可信度函数β,∀∈C,其对应的可信度分别为βr1和βr2。可信度序关系≻满足:

依据定义2可知,基于证据链推理的多属性群决策分类问题,可转化为寻找候选证据序列的优化问题。
2.2 基于证据链推理的混合整数优化模型
传统的基于实例的推理[6],如相似度推理[19]、案例检索[20]等,采用了相似度准则(最近邻法),强调的是案例一对一的属性匹配,将信息匹配取值最高的类别作为推论。但是,实际的决策问题(如医疗诊断)要求决策者提供证据的可信度分布,并将知识库中的这些相关联的特征信息与新案例数据对准、关联,获取最紧密关联的多个证据链作为直接证据源。通过信息共享,进行证据融合和可信度集成,以实现多属性群决策分类。
为了使构造的模型尽可能地接近证据链中的属性信息,需要确定一个合适的目标函数去关联查询案例与候选证据链的属性,评价模型的分类参数值。这里引入相似度来量化它们属性数据之间的关联紧密性。
定义3令为第i查询案例的第j个属性,为第l证据链的第j个属性,wj为这两个数据源信息的权重向量。第l个证据链与查询案例i之间的属性关联的相似度函数为。指数型相似度函数为

为选择与查询案例Ui最紧密关联的证据链Rl,并将其作为直接证据源,令为0-1决策变量,构建基于证据链推理的混合整数优化(mixed integer optimization of ECS-based reasoning,MIOER)模型)如下:


式中,式(4a)为目标函数,反映了推论可信度的一阶差分最大值能使得决策分类标识能力最大化,这一推理模型尽可能使得查询案例的结论远离其分类标识的边界;式(4b)反映了属性关联相似度与推论可信度的关系,以这些不同来源信息的相似度作为群决策信息源的权重,获取查询案例的可信度;式(4c)在证据系列中挑选出与查询案例最紧密关联的证据链;式(4d)表明为0-1决策变量取值为1时,选择对应的证据链取值为0时,不选择对应的证据链,且证据链的取值总数不小于1;式(4e)表明εi为小于1的非负实数,用于控制候选证据链的规模,当εi=0时筛选出的是相似度取最大值的证据链。利用Matlab、C++等软件可求解上述模型,解集为和的值所对应的向量。将=1的证据链,按由大到小的顺序排列,即{Rh|h=h1,h2,…,hq},其中h为序数。
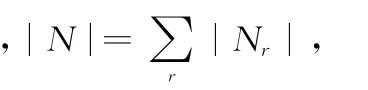
信息熵为

式中,Pr是证据链总体按照Cr划分的概率Pr=|Nr|/|N|。

条件熵为

互信息为

属性权重为
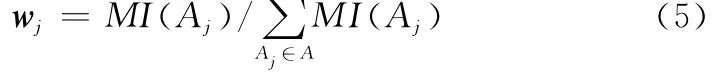
2.3 模型推理必要条件和敏感性分析
针对决策证据类别错误标识的情形,需要分析模型推理的必要条件,以及对证据链类别错误标识情形的敏感性。
定理1假设MIOER)模型的最优解为(δ,为使成立的必要条件是

定义4任意证据链推论的与另一证据链的类别标识的的可信度序关系一致,则满足:当则当,则
定理2设MIOER,)模型最优解为为紧密关联的证据链,的其分类标识能力最显著,即h2,h3)时,查询案例推论的βi与的类别标识的的可信度序关系一致,满足:当


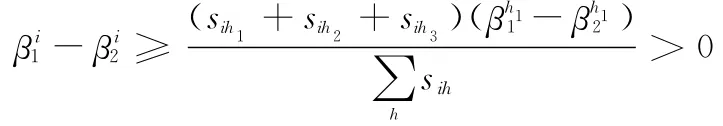

证毕

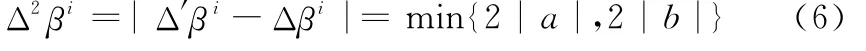
式中
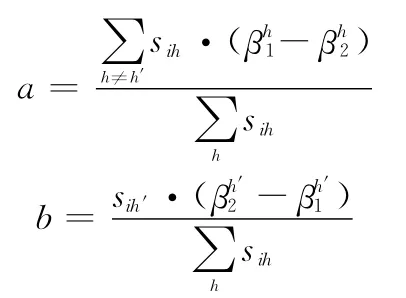
证明设类别被错误标识的紧密关联的证据链为,
因

所以
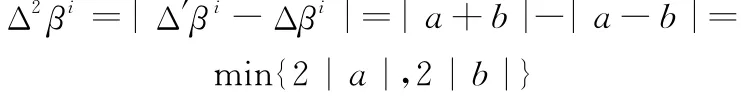
证毕
2.4 结果分析
利用已存储的群决策的证据链,针对有限个查询案例进行推理。获取融合可信度后,需要对模型的推理结果进行分析。


查询案例的结论经由决策者(或更多的领域知识)检验正确后,又可形成新案例或提炼的规则知识,固化、存储到知识库,形成新的关联证据链,以多次利用数据,增加数据驱动决策的知识使用价值,提升群决策分类的推理性能。
3 应用实例
为了说明本文方法的有效性,以Heart样本数据的智能诊断进行决策分析。实验数据使用UCI决策数据库中的Heart(cleveland)数据集[22]。数据集中有一些列所描述的属性值能够很好地推理预测结果的发生。因此决策算法指令集里面常需要使用这些属性数据,进行可解释性的证据推理论证,以找到有实际决策意义的模式。因现无公开数据库提供这类数据[14],为模拟错误标识情形,对数据集的标识类别加入1%的噪声作为错误标识。形成的样本数据包括270例,样本空间中每个样本由多个领域专家根据经验或领域知识给出。这些数据集常用于诊断推理的属性有13个特征信息。这些数据样本被分离为Present和Absent,分别记为C1和C2。
对逻辑布尔型属性和描述型属性进行符号化处理。计算属性的信息熵、条件熵、互信息,进而使用式(5)计算属性权重,获取的特征集合为{Age,Sex,Cp,BP,restECG,Thalach,Exang,Slope,Thal},这9个特征对应的权值向量为[0.074 3,0.010 5,0.234 2,0.011 1,0.035 2,0.103 0,0.157 7,0.143 7,0.230 3],数据集中的其余属性为冗余属性,权重为0。
多源信息生成的证据链ECl实例为

证据链所表示的信息具有特定的意义,这里将其统一视为传感器或虚拟传感器感知的信息,这些观测值数据包括:3个虚拟传感器Αge、Sex和Cp的观测值依次为57、1和2,传感器感知的BP、Restecg、Thalach的观测值为124(mm Hg)、0(正常)、141;虚拟传感器Exang的观测值为0。
传感器感知的Slope观测值为1(向上倾斜),感知的Thal的观测值为7。这些变量的观测值常按照诊断的领域知识或流程路径获取。
利用Matlab求解,数据集样本中的前200个样本作为证据链系列ECs,剩余的70个样本作为查询案例X,获得查询案例与证据链的关联相似度。针对证据链EC1-EC8(横轴)和查询案例X1-X6(纵轴),计算关联相似度,如图2所示。

图2 查询案例与证据链属性关联相似度
在模型求解过程中,对查询案例X1,设定ε1=0.163 0,求解模型获得δ1,1=1,δ1,4=1,δ1,5=1,其余的证据链对应的解为0;对于查询案例X2,设定ε1=0.412 7,求解模型获得δ2,1=1,δ2,4=1,δ2,4=1,其余的证据链对应的解为0。
使用MIOER模型推理X1的结论为:C2≻C1,=34.68%=65.32%。使用文献[5]中的k-NN(k=1)方法,将其最紧密关联的单个证据链作为信息源,则X1推论为C2,且=100%。使用MIOER模型求解部分查询结果,如表1所示。对于输入决策系统中错误标识的实例EC’4,它与EC4的推论可信度恰好相反=100%=0。使用证据链EC1,EC’4和EC5推理得到X’1推论:C1≻C2且=(81.47+85.07)/(81.47+85.07+68.37)=70.90%=29.10%。Δ2β1=|Δ′β1-Δβ1|=11.76%。决策者根据这一值和定理3,判断作用于可信度变化的证据链为EC’4,并据此检验和调整EC’4,直结论得满意结果。对于X2得到类似结论。本方法对决策结果给出对应的可信度,与其他方法(如文献[5]中k-NN(k=1)方法仅给出确切推理的类别结论)相比,针对存在类别误标的多属性群决策分类信息源具有更好的决策鲁棒性。
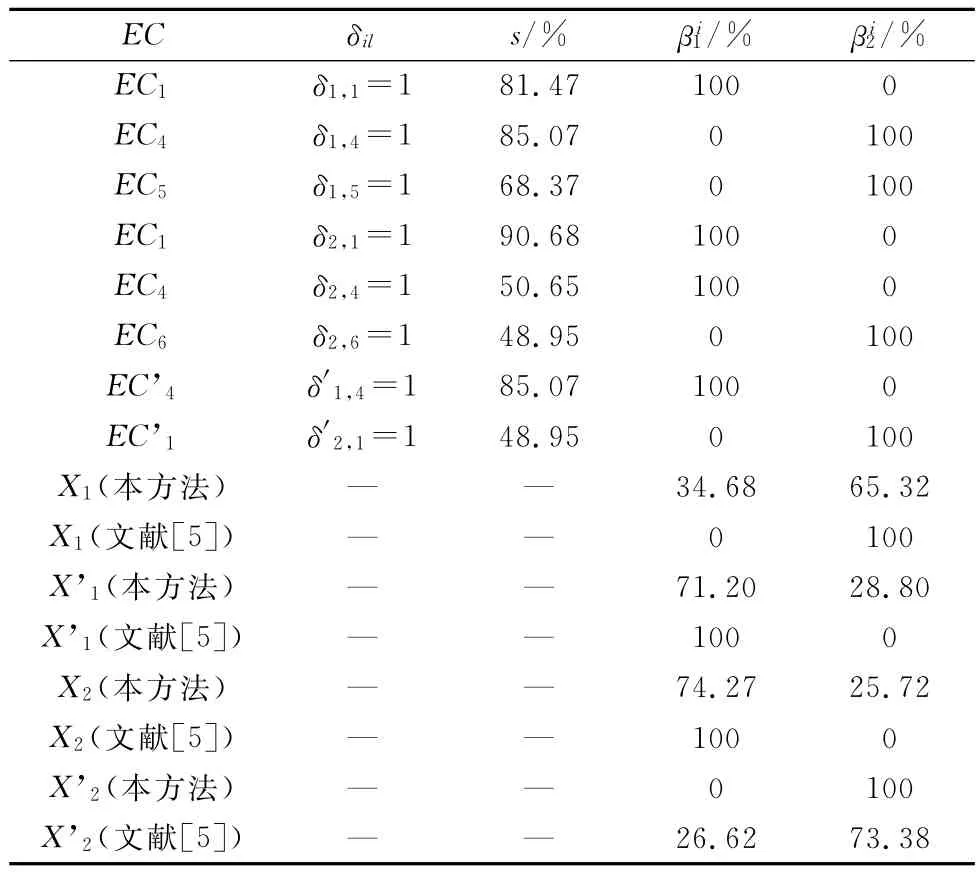
表1 使用MIOER模型求解的部分查询案例
为说明本方法的有效性与优点,进一步从理论上将其与现有的其他证据推理方法比较,如表2所示。

表2 多属性群决策分类推理方法比较
从类别误标角度,文献[5]考虑到不确定性类别标识的案例而能解决类别部分已知的情况,文献[7]、文献[9]均使用精确标识的样本,未考虑样本误标情形,而本方法考虑了证据链的类别误标情形。从决策信息结构来看,文献[9]要求决策者提供证据的可信度分布、规则前件属性的精确性等参数,文献[5]要求提供最紧密的k个案例信息作为证据,k≥1,文献[7]要求提供作为证据的所有案例和标识类别的可信度,本方法依据案例、规则构建证据链及其可信度,以关联最紧密的k个证据链提供决策,k≥3。从考虑群决策的信息源权重角度,文献[5]、文献[7]不考虑信息源权重,文献[9]和本方法考虑信息源权重。从决策规则角度,文献[5]和本文基于可信度序关系的决策规则,文献[7]采用相似度加权频率的决策规则,文献[9]采用基于效用的决策规则。从结论信息的形式,文献[7]和文献[9]给出结论的类别及其可信度或概率,文献[5]将决策概率最高的类作为推论,本文给出结论的可信度序关系。
4 结 论
群决策分类的可解释性推理在工程实践中有着广泛的应用,是一类重要的决策分析问题。决策者依据经验案例、领域规则等知识对多属性决策方案进行类别标识,动态积累决策数据并为后续决策提供证据。在决策过程中,由于单个决策信息源对问题解释的不完整性及其提供的证据信息对查询案例支持程度不同,常常需要多决策数据源共同提供证据,进行信息融合的知识推理。然而,现有的多属性决策推理方法主要集中在对全部正确标识的证据信息进行决策推理,对证据信息误标环境下的推理问题研究不深。为此,本文提出了一个类别误标下证据链推理的多属性群决策分类方法。与已有的多属性群决策分类方法相比,本方法最大特点是直接利用信息多决策证据信息和可信度函数的一致性和凸性进行推理,避免了误标的单决策信息源作为最接近的决策证据而出现错误推理,并不需要设置推理边界参数。另外,本方法在证据链推理过程中最大限度地考虑了各决策证据链信息和决策权重,这主要体现在:①将决策证据链与查询案例之间的关联相似度作为群决策信息源的权重,优化目标使得融合可信度最大程度地满足查询案例的分类标识能力;②在挑选群体证据链集合时,通过混合整数规划模型使得挑选出来的证据链与查询案例的属性信息尽可能的接近。同时,文中还证明了该方法依据可信度序定义的条件,在群决策证据链不少于3个时实现证据链误标下的证据链推理。并通过Heart诊断实例,验证了本方法的有效性和可行性。在本文中,群决策所提供多源证据信息已给出可信度完备的分类标识,并通过互信息方法计算相似度量的权值参数,而没有分析知识库中证据链感知数据的不确定性,以及动态更新策略和模型参数的学习过程,这类问题是进一步拓展研究的有趣方向。
[1]Ferrucci D,Levas A,Bagchi S,et al.Watson:beyond jeopardy![J].Artificial Intelligence,2013,199/200:93- 105.
[2]Fu C,Yang S.An attribute weight based feedback model for multiple attributive group decision analysis problems with group consensus requirements in evidential reasoning context[J].European Journal of Operational Research,2011,212(1):179- 189.
[3]Hoffmann S,Fischbeck P,Krupnick A,et al.Elicitation from large,heterogeneous expert panels:using multiple uncertainty measures to characterize information quality for decision analysis[J].Decision Analysis,2007,4(2):91- 109.
[4]Kumar K A,Singh Y,Sanyal S.Hybrid approach using casebased reasoning and rule-based reasoning for domain independent clinical decision support in ICU[J].Expert Systems with Applications,2009,36(1):65- 71.
[5]Denoeux T.A k-nearest neighbor classification rule based on Dempster-Shafer theory[J].IEEE Trans.on Systems,Man and Cybernetics,1995,25(5):804- 813.
[6]Denoeux T,Smets P.Classification using belief functions:relationship between case-based and model-based approaches[J].IEEE Trans.on Systems,Man,and Cybernetics,Part B:Cybernetics,2006,36(6):1395- 1406.
[7]Billot A,Gilboa I,Samet D.Probabilities as similarity-weighted frequencies[J].Econometrica,2005,73(4):1125- 1136.
[8]Cai F L,Liao X W.Multi-criteria sorting method with uncertinty in assignment examples[J].Systems Engineering-Theory& Practice,2010,30(3):513- 519.(蔡付龄,廖貅武.案例信息不确定下的多属性分类方法[J].系统工程理论与实践,2010,30(3):513- 519.)
[9]Yang J B,Liu J,Wang J,et al.Belief rule-base inference methodology using the evidential reasoning approach-RIMER[J].IEEE Trans.on Systems,Man and Cybernetics,Part A:Systems and Humans,2006,36(2):266- 285.
[10]Chang L L,Li M J,Lu Y J,et al.Structure learning for belief rule base using principal component analysis[J].Systems Engineering-Theory&Practice,2013,33(1):1- 8.(常雷雷,李孟军,鲁延京,等.基于主成分分析的置信规则库结构学习方法[J].系统工程理论与实践,2013,33(1):1- 8.)
[11]Xu M,Yu H,Shen J.New algorithm for CBR-RBR fusion with robust thresholds[J].Chinese Journal of Mechanical Engineering,2012,25(6):1255- 1263.
[12]Shen J,Yu H Y,Xu M.Heterogeneous evidence chains based fusion reasoning for multi-attribute group decision making[J].Acta Automatica Sinica,2015,41(4):832- 842.(沈江,余海燕,徐曼.实体异构性下证据链融合推理的多属性群决策[J].自动化学报,2015,41(4):832- 842.)
[13]Schnoes A M,Brown S D,Dodevski I,et al.Annotation error in public databases:misannotation of molecular function in enzyme superfamilies[J].PLoS Computational Biology,2009,5(12):e1000605.
[14]Clifford G D,Long W J,Moody G B,et al.Robust parameter extraction for decision support using multimodal intensive care data[J].Philosophical Transactions of the Royal Society A:Mathematical,Physical and Engineering Sciences,2009,367:411- 429.
[15]Li Q,Clifford G D.Dynamic time warping and machine learning for signal quality assessment of pulsatile signals[J].Physiological Measurement,2012,33(9):1491- 1501.
[16]Qi L,Wang H P,Xiong W,et al.Track segment association algorithm based on multiple hypothesis models with priori information[J].Systems Engineering and Electronics,2015,37(4):732- 739.(齐林,王海鹏,熊伟,等.基于先验信息的多假设模型中断航迹关联算法[J].系统工程与电子技术,2015,37(4):732- 739.)
[17]Smets P,Kennes R.The transferable belief model[J].Artificial Intelligence,1994,66(2):191- 234.
[18]Wong S K M,Lingras P.Representation of qualitative user preference by quantitative belief functions[J].IEEE Trans.on Knowledge and Data Engineering,1994,6(1):72- 78.
[19]Lehman L,Saeed M,Moody G,et al.Similarity-based searching in multi-parameter time series databases[J].Comput Cardiol,2008,35:653- 656.
[20]Ram A,Santamaría J C.Continuous case-based reasoning[J].Artificial Intelligence,1997,90(12):25- 77.
[21]Xu M,Yu H,Shen J.New approach to eliminate structural redundancy in case resource pools using alpha mutual information[J].Journal of Systems Engineering and Electronics,2013,24(4):768- 777.
[22]Asuncion D N.UCI machine learning repository[EB/OL].[2014- 06- 30].http:∥www.ics.uci.edu/mlearn/MLRepository.html.
ECs-based reasoning for group decision analysis in the mislabeled classification context
YU Hai-yan1,SHEN Jiang1,XU Man2
(1.College of Management and Economics,Tianjin University,Tianjin 300072,China;2.Business School,Nankai University,Tianjin 300071,China)
Considering on the difficulty of interpretable reasoning for group decision in the mislabeled classification context,a method of evidential chains(ECs)-based reasoning for group decision analysis is proposed.Based on the consistency and convexity of the belief function,association similarities between the query case and ECs on their attributes are used as the weights of the multi-source information,and the mixed integer optimization model of ECs-based fusion reasoning is formed to maximize the reasoning performance,achieving the most closely related ECs.For reasoning with the mislabeled instances,this framework facilitates belief preference to induce the conclusion of queries.A diagnostic experiment with multi-source sensory data verifies the efficiency and rationality of the method.
group decision analysis;evidential chains(ECs);association similarity;mislabeled instances;belief preference
TP 273
A
10.3969/j.issn.1001-506X.2015.11.19
余海燕(1987-),男,博士研究生,主要研究方向为证据推理、CBRRBR智能决策。
E-mail:yhy188@tju.edu.cn
沈 江(1957- ),男,教授,博士,主要研究方向为复杂系统理论、决策科学、信息融合。
E-mail:motoshen@163.com
徐 曼(1977- ),女,讲师,博士,主要研究方向为大数据分析、医疗工业工程。
E-mail:twinklexu@163.com
1001-506X(2015)11-2546-08
2014- 07- 30;
2015- 05- 02;网络优先出版日期:2015- 07- 09。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20150709.1649.003.html 20150709
国家自然科学基金(71171143,71201087,71571105);天津市科技支撑计划重点项目(13ZCZDSF01900);中央高校基本科研业务费专项资金(NKZXB1458)资助课题
猜你喜欢
图书馆论坛(2023年2期)2023-03-10 05:46:38
思维与智慧·下半月(2021年11期)2021-11-23 06:32:38
思维与智慧(2021年33期)2021-11-23 03:05:22
活力(2019年19期)2020-01-06 07:35:02
红土地(2016年3期)2017-01-15 13:45:22
幼儿智力世界(2016年6期)2016-05-14 13:50:51
发明与创新(2016年33期)2016-04-16 16:32:25
新校长(2016年8期)2016-01-10 06:43:59
小雪花·初中高分作文(2015年10期)2015-10-24 04:01:58
商事法论集(2014年1期)2014-06-27 01:20:42
