
基于概率修正PLDA的说话人识别系统
2015-06-05 15:30万丽虹洪青阳
天津大学学报(自然科学与工程技术版) 2015年8期
李 琳,万丽虹,洪青阳,张 君,李 明
(1. 厦门大学信息科学与技术学院,厦门 361005;2. 中山大学卡内基梅隆大学联合工程学院,广州 510006)
基于概率修正PLDA的说话人识别系统
李 琳1,万丽虹1,洪青阳1,张 君1,李 明2
(1. 厦门大学信息科学与技术学院,厦门 361005;2. 中山大学卡内基梅隆大学联合工程学院,广州 510006)
为减弱注册语音与测试语音时长不一致对说话人识别性能的负面影响,提出一个概率修正PLDA 建模方法.根据语音时长自适应改变传统PLDA模型中i-vector的概率分布函数,提高PLDA对每个说话人每段语音的时长表征能力,以增强说话人类别的区分度.为验证基于概率修正PLDA模型的有效性,进行了NIST SRE10 corecore 测试集在3种不同时长的评测实验,以及NIST 2014 i-vector machine learning challenge测试任务.结果表明,相较于传统的PLDA训练模型,通过语音时长的约束提高了说话人识别性能.
高斯PLDA;i-vector;语音时长;概率修正;说话人识别
传统说话人识别技术从语音样本提取特征参数,并利用说话人特征的差异性建立分类模型,如高斯混合模型(Gaussian mixture model,GMM)[1],以区分目标说话人和冒充说话人.然而,说话人特征差异性的表征能力受到说话人情绪、背景噪声、语音时长、采集设备等因素的制约,直接影响了现有说话人识别技术的识别效果.
在实际应用中,较频繁出现参考语料与测试语料的录制信道不同和时长不一致的情况.采用Eigenvoice、Eigenchannel、Joint Factor Analysis等说话人-信道联合模型[2-3]对GMM均值超向量进行信道无关的说话人因子分析,一定程度上削弱了信道差异对说话人识别性能的影响.基于i-vector的说话人识别系统[4]使用有害因子投影(nuisance attribute projection,NAP)、线性区分性分析(linear discriminant analysis,LDA)、类内协方差归一化(within-class covariance normalization,WCCN),或概率线性区分性分析(probabilistic linear discriminant analysis,PLDA)[5-6]等区分技术更好地解决了信道不匹配问题.由于时长信息和信道信息、音素信息一样,是随着语音段的录制而存在着,但是传统GMM建模方法一定程度上模糊了每个语音样本的时长信息.虽然完全变化因子i-vector的提取过程考虑了时长的影响,采用了与语音样本帧数的倒数相关的概率分布函数,但单纯使用i-vector作为新型声学特征和PLDA作为区分模型的说话人识别系统在时长不一致及短语音情况下仍会出现明显的性能下降[7].近年来,学者们开始针对时长不一致问题展开一系列的研究. Kenny等[8]将时长信息作为信道信息的附加补偿,在说话人-信道空间建模时多设置了一组表征时长的信道偏移参量,在NIST SRE10 core-core测试中,将EER由6.8%,降为5.9%,,以增加PLDA训练过程中似然函数的计算复杂度为代价,换取识别性能对样本时长的鲁棒性. Hasan等[9]假设样本时长为i-vector变量空间中的加性噪声,提出3种优化方法:①采用同一语料多种时长样本进行PLDA建模;②在分数域构建QMF函数,加入时长信息的调节作用;③使用时长方差规整得到新的i-vector变量.经过NIST SRE12的评测结果分析得到,第2种方法对短语音的识别效果最显著.Kanagasundaram等[10]提出时长方差规整算法(short utterance variance normalization,SUVN),在i-vector特征域中,结合SUVN、LDA以及PLDA等补偿信道差异性和时长变化性.
本文首先将i-vector向量进行白化和归一化处理[11],建立i-vector的标准高斯分布.然后,引入语音样本的时长信息,将其作为每个说话人每个i-vector在PLDA模型中的方差调节因子,描述每个i-vector向量由时长不同而产生的信息熵:样本时长越短,携带的说话人信息越少,偏离高斯分布均值的程度越大.最后,采用最大期望(expectation maximization,EM)算法实现对开发集i-vector向量分布概率函数的最大似然估计,建立起一个受语音时长约束的概率修正PLDA(modified-prior PLDA)模型.本文分别在NIST SRE10 core-core测试集(女性部分)和NIST 2014 i-vector machine learning challenge的评测任务中验证了概率修正PLDA模型的有效性.
1 基线系统
将联合因子分析(JFA)算法中说话人因子分量和信道因子分量同时映射到一个低维空间,使用基于Baum-Welch 统计量对GMM均值超向量进行降维处理得到一个固定长度的完全因子向量i-vector,即每一段语音样本均可表示为一个i-vector.

式中:M为GMM均值超向量;m为一个与说话人和信道无关的均值超矢量;T为低秩的全局差异空间矩阵;x表示一个满足标准正态分布N(0,I)的随机向量,即i-vector.
假设tarx和tstx分别代表目标说话人和测试语音所对应的i-vecor.本文的基线系统将采取余弦距离值(CDS)作为基线系统的决策分数

2 标准高斯PLDA模型
给定一组来自N个说话人的i-vector向量{xij,i=1,…,N, j=1,2,…,Mi}(其中,每个说话人有Mi条语音样本),每个i-vector经过白化和归一化处理,满足标准高斯分布.进一步,将i-vector分解为确定信号和随机噪声,则得到其PLDA模型

式中:μ代表来自开发集所有i-vector向量的均值;iβ是第i个说话人的说话人因子,满足标准正态分布N(0,I);矩阵ϕ是固定维度的说话人子空间;残差ijε包含信道因子,服从均值为0,协方差矩阵为Σ的正态分布.
利用一定规模的语音样本开发集,使用EM算法估计出PLDA参数集{μ,ϕ,Σ}.一般采用对数似然比作为标准高斯PLDA的决策分数

式中:sH表示测试语音来自同一说话人的假设条件;dH表示测试语音来自冒充者的假设条件.
3 时长约束的概率修正PLDA模型
文献[9]中通过分析语音样本所包含的音素(phonemes)统计量与语音时长(5,s,10,s,20,s,40,s和全时长)的关系,发现音素的数量随着语音时长的减小而呈指数递减,而当语音时长增加到一定长度时,如时长在1,min以上,音素的统计量将保持不变.由此可见,语音的时长对说话人识别性能具有不容忽视的影响.对于同一说话人,语音时长越短,对应ivector的PLDA模型将趋向于产生越大的协方差.
3.1 高斯分布函数的修正

考虑语音样本时长的影响力,本文假定公式(3)中的ijε将服从一个新的正态分布式中:Lij代表第i个说话人第j段语音样本的时长,可用帧数表示;α 和λ 为调节参数,刻画语音时长对分布函数的影响程度.
已知开发集中有N个说话人,每个说话人有Mi个语音样本,即i=1,…,N, j=1,2,…,Mi,设定ηij代表i-vector向量的一阶统计量xij-μ,则后验概率P(ηij|βi)为
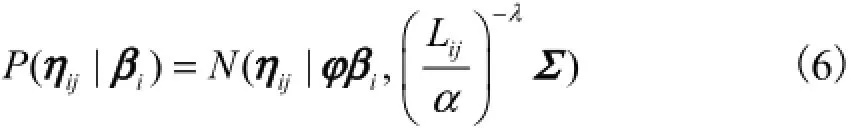
设定Fi是第i个说话人一阶统计量的均值,如下所示:
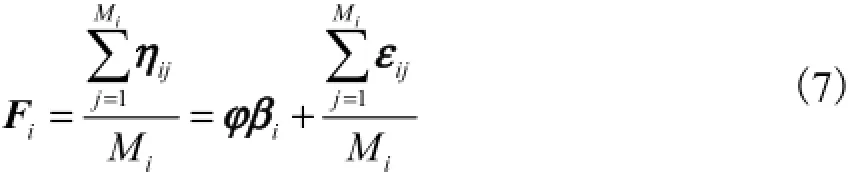

引入中间变量K,即

根据贝叶斯法则,可计算得到后验概率
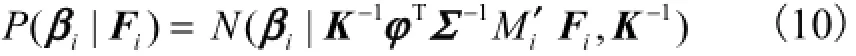
3.2 EM迭代
采用EM算法以估计得到PLDA模型参数,本质上是进行极大似然估计求解含有隐变量的概率模型参数.在每一次迭代中,在E-step先求出给定训练数据下隐变量的期望,然后在M-step将这个期望最大化.通过迭代逐渐收敛,达到局部最优值.
(1) E-step:在给定观测数据和当前参数下对未观测数据βi的条件概率分布P(βi|Fi)的期望值进行估算,即

又由期望相关公式可以得到

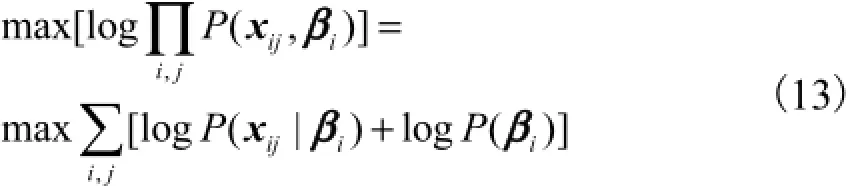
将P( xij|βi)和P(βi)的高斯分布概率密度函数代
入公式(13),再分别对ϕ 和Σ求导,整理得到
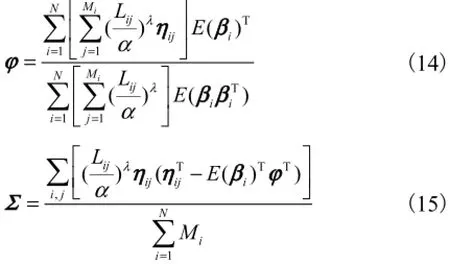
为得到对ϕ 和Σ的最佳估算,需要经过E-step和M-step的不断迭代,当公式(13)计算得到的数值增长速度小于1×10-3,则停止迭代.
4 实验数据分析
4.1 评测数据
本文分别参考ALIZE开发包[12]和文献[11]提供PLDA开源代码,实现了3个说话人识别系统:基于i-vector+CDS的基线系统(简称“基线系统”),ivector+PLDA识别系统(简称“PLDA系统”)和ivector+概率修正 PLDA识别系统(简称“概率修正系统”).采用32维MFCC,训练1,024阶的UBMGMM,i-vector维数为400,PLDA说话人因子维数为120.
为验证本文提出的概率修正PLDA模型的有效性,我们采用NIST SRE10 core-core测试集(女性)和NIST 2014 i-vector machine learning challenge测试集进行识别性能评估.
1) NIST SRE10 core-core测试数据准备
UBM训练数据:NIST2004、2005年女性数据共11,370条语音.
T矩阵训练数据:NIST2004、2005、2006、2008年女性数据共20,348条语音.
PLDA训练数据:与T矩阵训练数据相同语音提取的i-vector.
core-core测试条件:
(1) 模型——NIST SRE10,core女性数据,共训练模型290个;
(2) 测试——NIST SRE10,core女性数据,共提供测试样本357个;
进行确认测试355次,冒认测试15,958次.
2) 时长不匹配评测实验数据准备
将NIST SRE10 core-core测试集中的测试语音分别随机截短至20,s和10,s,对应的UBM、T、PLDA模型、训练模型和测试次数不变.
3) NIST 2014 i-vector machine learning challenge测试数据准备
NIST 2014 i-vector machine learning challenge组委会从历年的NIST SRE数据库中提取600维的ivector数据,分别组成开发集、模型集和测试集.开发集包含4,959个说话人共36,573个i-vector,可用于PLDA模型训练;模型集包含1,306个说话人,每个说话人有5条i-vector;测试集则有9,634个ivector.测试任务分成两个部分:progress测试和evaluation测试.
4.2 调节参数α 和λ 的选择
公式(5)定义了时长约束下的说话人因子分布概率函数,可见,调整α 和λ 的取值,将改变说话人因子的概率分布.
为简化计算复杂度,在本文实验中,α 取开发集所有i-vector的时长均值.确定α 后,再微调λ 的取值,观察系统识别性能,发现当λ 取值在0.4~0.8之间时,说话人识别系统将获得最显著的识别效果.
4.3 性能对比
为验证概率修正 PLDA模型对时长变化的鲁棒性,本文将NIST SRE10 core-core测试集的测试数据进行截短至20,s和10,s,分别进行不同时长的评测任务.本文采用等错率(equal error rate,EER)和最小决策代价函数(minimum decision cost function,minDCF)作为说话人识别系统的评测准则,并对minDCF进行norm规整得到Cnorm[13].
表1和表2分别列出了不同时长情况下,基线系统、PLDA系统和概率修正系统这3个识别系统在NIST SRE10 core-core测试集(女性)上的评测结果.可看到,随着测试语音时长变短后,3种系统的识别性能都有一定幅度的下降,其中,基线系统的识别性能下降最严重,而概率修正系统则表现得相对鲁棒.在同一时长情况下,概率修正系统取得更低的EER值,大部分情况下可以获得更小的minDCF值.只有在时长为10,s的评测任务中,概率修正系统的minDCF值略高于PLDA系统,出现了类似于文献[8]的实验情况,值得进一步研究探讨.
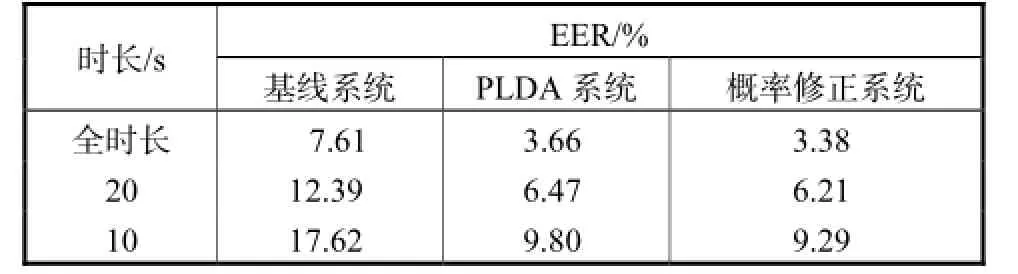
表1 NIST SRE10 core-core评测EER值Tab.1 EER value of NIST SRE10 core-core

表2 NIST SRE10 core-core评测Cnorm值Tab.2 Cnorm value of NIST SRE10 core-core
NIST 2014 i-vector machine learning challenge提供的每个i-vector都包含原始语音的段长信息,有利于应用概率修正系统验证性能.采用EER和minDCF[14]作为说话人识别系统的评测准则.
由表3和表4观察发现,在progress测试任务中,与PLDA系统相比概率修正系统的EER减少了3.67%,minDCF获得3.39%,的改进.在evaluation测试任务中,概率修正系统性能同样取得一定程度的改进.

表3 NIST 2014 i-vector challenge评测EER值Tab.3 EER value of NIST 2014 i-vector challenge

表4 NIST 2014 i-vector challenge评测minDCF值Tab.4minDCF value of NIST minDCF 2014 i-vector challenge
5 结 语
鉴于传统PLDA模型缺乏对时长信息的利用,本文提出一种新的PLDA模型,在标准高斯PLDA建模过程中,利用时长信息控制说话人因子的概率分布参数,从而加强说话人识别系统对时长因素影响的鲁棒性.
[1] Reynolds D,Quatieri T,Dunn R. Speaker verification using adapted Gaussian mixture models[J]. Digital Signal Process,2000,10(1/2/3):19-41.
[2] Kenny P,Boulianne G,Dumouchel P. Eigenvoice modeling with sparse training data[J]. IEEE Trans Speech and Audio Process,2005,13(3):345-354.
[3] Kenny P,Boulianne G,Ouellet P,et al. Joint factor analysis versus eigenchannels in speaker recognition [J]. IEEE Trans on Audio Speech Lang Process,2007,15(4):1435-1447.
[4] Dehak N,Kenny P,Dehak R,et al. Front-end factor analysis for speaker verification[J]. IEEE Trans on Audio Speech Lang Process,2011,19(4):788-798.
[5] Prince S,Elder J. Probabilistic linear discriminant analysis for inferences about identity[C]//Proc Computer Vision. Rio de Janeiro,Brazil,2007:1-8.
[6] Cumani S,Plchot O,Laface P. On the use of i-vector posterior distributions in probabilistic linear discriminant analysis[J]. IEEE Tran on Audio Speech Lang Process,2014,22(4):846-857.
[7] Sarkar A,Matrouf D,Bousquet P,et al. Study of the effect of i-vector modeling on short and mismatch utterance duration for speaker verification[C]// Proc Inter-Speech.Portland,USA,2012:2661-2664.
[8] Kenny P,Stafylakis T,Quellet P,et al. PLDA for speaker verification with utterances of arbitrary duration [C]// Proc Acoustics,Speech and Signal Processing. Vancouver,Canada,2013:7649-7653.
[9] Hasan T,Saeidi R,Hansen J,et al. Duration mismatch compensation for i-vector based speaker recogni tion systems[C]// Proc Acoustics,Speech and Signal Processing. Vancouver,Canada,2013:7663-7667.
[10] Kanagasundaram A,Dean D,Sridharan S,et al. Improving short utterance i-vector speaker verification using utterance variance modeling and compensation techniques[J]. IEEE Trans Speech Communication,2014,59:69-82.
[11] Garcia-Romero D,Espy-Wilson C. Analysis of i-vector length normalization in speaker recognition systems [C]// Proceedings of Interspeech. Florence,Italy,2011:249-252.
[12] ALIZE. ALIZE Project-Open Source Platform for Biometrics Authentification[EB/OL]. http://www.signalprocessingsociety.org/technicalcommittees/list/sl-tc/splnl/2013-05/ALIZE/,2010-04-21.
[13] NIST. The NIST 2010 Speaker Recognition Evaluation Plan[EB/OL]. http://www.itl.nist.gov/iad/mig/tests/spk/ 2010/index.html,2015-02-19.
[14] NIST. The 2013—2014 Speaker Recognition I-Vector Machine Learning Challenge[EB/OL]. https:// ivectorchallenge. nist. gov,2015-02-19.
(责任编辑:金顺爱,王晓燕)
Modified-Prior PLDA Based Speaker Recognition System
Li Lin1,Wan Lihong1,Hong Qingyang1,Zhang Jun1,Li Ming2
(1.School of Information Science and Technology,Xiamen University,Xiamen 361005,China;2.SYSU-CMU Joint Institute of Engineering,Sun Yat-Sen University,Guangzhou 510006,China)
To reduce the negative impact on the performance of speaker recognition systems due to the duration mismatch between enrollment utterance and test utterance,a modified-prior PLDA method is proposed.The probability distribution function of i-vector was modified by incorporating the covariance matrix with duration of each utterance of each speaker during the PLDA training,which further improved the discriminant capability of speaker classification.To evaluate the robustness of the proposed modified-prior PLDA method,extensive experiments were performed on NIST SRE10 core-core task(female part)in duration mismatch conditions and NIST 2014 i-vector machine learning challenge.Experimental results demonstrated that the duration-based modified-prior PLDA method achieved better performance compared with the traditional PLDA.
Gaussian PLDA;i-vector;duration;modified-prior;speaker recognition
TN912.34
A
0493-2137(2015)08-0692-05
10.11784/tdxbz201507031
2015-03-15;
2015-07-09.
国家自然科学基金资助项目(61105026).
李 琳(1982— ),女,博士,副教授,lilin@xmu.edu.cn.
洪青阳,qyhong@xmu.edu.cn.
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25
快乐语文(2021年35期)2022-01-18
火控雷达技术(2021年2期)2021-07-21
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
中国自行车(2018年11期)2018-12-03
北京航空航天大学学报(2017年3期)2017-11-23
摄影之友(影像视觉)(2017年1期)2017-07-18
中国自行车(2017年1期)2017-04-16
制导与引信(2016年3期)2016-03-20
