
一种基于计算听觉场景分析的语音增强算法
2015-06-05 15:30张卫强JohnsonMichael
天津大学学报(自然科学与工程技术版) 2015年8期
张卫强,郭 璁,张 乔,康 健,何 亮,刘 加,Johnson Michael T,
(1. 清华大学电子工程系,北京 100084;2. 马凯特大学电气与计算机工程系,密尔沃基 53233)
一种基于计算听觉场景分析的语音增强算法
张卫强1,郭 璁1,张 乔1,康 健1,何 亮1,刘 加1,Johnson Michael T1,2
(1. 清华大学电子工程系,北京 100084;2. 马凯特大学电气与计算机工程系,密尔沃基 53233)
选取ETSI语音增强系统作为研究对象.该系统使用传统维纳滤波方法,在信噪比较高时降噪性能优秀,但在信噪比较低的情况下,降噪能力弱,对于脉冲噪声无较好抑制.而模拟人耳听觉特性的计算听觉场景分析技术能够比较好地弥补这一缺陷.故在ETSI算法的基础上,结合计算听觉场景分析技术,提出一种新的算法,将维纳滤波器参数估计由原本的Mel域变换到Gammatone域,并进一步利用理想率掩蔽估计对带噪信号进行信噪分离,抑制脉冲噪声.该算法在TIMIT语音库上进行了实验,结果证明,与原算法相比,提出的新算法使听觉质量在低信噪比下提升较大,脉冲噪声抑制亦明显.在低信噪比的情况下,后端语音识别系统的识别率得到提升.
语音增强;计算听觉场景分析;Gammatone滤波器;理想率掩蔽
随着数字信号处理技术的成熟,语音处理领域迅速发展,自动语音识别、语音合成、人机语音交互等技术也日趋普及.作为前端处理模块,语音增强算法的改进可以大大提升整体系统性能.
语音增强算法种类很多,有基于信号级别,例如非负矩阵分解[1]、维纳(Wiener)滤波[2]等方法;还有在特征层面抑制噪声影响,例如在说话人识别中构造对噪声鲁棒的特征[3]进行降噪.而近期比较热门的是基于计算听觉场景分析(computational auditory scene analysis,CASA)[4]的语音增强算法,其模拟人类听觉的生理特性,加入语音时频域的掩码,从带噪语音中尽可能重建出纯净的语音信号,并提高听音感知质量.因为这种类型的算法基于人耳听音感知系统,能够有效地在低信噪比下对于带噪语音进行语音增强.这一技术的发展,对语音识别系统、助听器设计[5]、海底声呐探测[6]等应用都有重要意义.
传统的信号处理多采用梅尔(Mel)滤波器组[7],由于其符合人耳对于频率对数特性,在基于信噪比(SNR)的评价指标下,Mel滤波器有较好的表现.但是其无法模拟耳蜗基底膜对于语音信号的频率分解作用,使之在性能上弱于人耳的听音感知特性.在CASA体系中,使用的是仿人耳听觉特性的伽马通(Gammatone)滤波器组[4],能够对于不同频率的噪声似人耳频响特性一样有效地滤除.同样有所缺陷的是,现有的听觉场景分析算法多采用频域加窗时域合成的方法,不如传统Wiener滤波的输出稳定.所以本文在基线系统上,选取了一种现有的语音增强系统ETSI[8],其本质上是利用Wiener滤波的方式构建有限长单位冲激响应(finite impulse response,FIR)滤波器;然后加入了Gammatone滤波器,旨在用人耳仿真特性增强降噪能力;最后加入了时频域掩码,旨在加强对于脉冲噪声的抑制作用.
本文首先简要介绍了语音增强的研究背景、原有算法及常用评价方式,之后在第1节对ETSI基线系统已有的算法框架进行阐述,第2节给出了在此基础上提出的基于CASA算法的改进方法,然后在第3节将降噪后的语音通过语音增强和语音识别两个平台的评价,给出详细的实验环境和平台参数,对实验结果进行表格绘制和评估分析,最后给出了得到的结论,并对下一步研究方向进行了规划.
1 基于ETSI的基线系统描述
1.1 整体系统
在所有的系统框图中,虚线表示增加或者替换的子模块,黑框内的模块为原本ETSI基线系统.
ETSI系统的整体架构如图1的实线部分,分为2个阶段.
ETSI基线系统采用的降噪算法如下描述.首先在Wiener滤波的部分,采用了2阶段的模式.第1阶段主要进行噪声帧与语音帧的鉴别,如图2实线部分所示,对平均能量、功率谱密度、分帧分频带的短时SNR、Wiener滤波器参数进行了初步的估计,同时对于每一帧粗略地进行语音活动检测(voice activity detection,VAD),然后将滤波器参数通过设计的三角窗频窗函数进行加窗变换到Mel域,再经过IDCT生成时域的FIR滤波器系数,即第1阶段的输出.

图1 系统示意Fig.1 System architecture

图2 第1阶段整体示意Fig.2 System architecture of stage 1
第2阶段利用了第1阶段输出的结果,其绝大多数结构与第1阶段一致,如图3的实线部分,不同的地方在于更为精细地估计了SNR,并且根据区分开的语音帧和噪声帧,分别设计在Mel域的Wiener滤波器增益系数,使用了二次动态自适应的方式降噪,对于噪声帧进行抑制,对于语音帧进行保留.
下面重点介绍基线ETSI系统中几个重要的模块:两阶段Wiener滤波的设计思路,滤波器组参数向Mel域的变换,滤波器组参数增益.
1.2 两阶段Wiener滤波

Wiener滤波用于语音增强算法由来已久,ETSI基线系统将这一传统算法分别运用在两个阶段.第1阶段主要根据式(1)利用当前帧的数据和VAD甄别结果迭代更新噪声帧的功率谱密度.式中:b为子带数,通过FFT计算得到;t为帧数;tn为最后一个非语音帧的帧数;为噪声的功率谱密度;为输入信号的功率谱密度;λNSE为一种噪声功率谱与信号功率谱的加权系数;EPS为一固定常数.
由此可估计出计算滤波器参数所需用到的语音帧信噪比为

再根据式(3)初步估计出线性谱域的Wiener滤波器参数H,并变换到Mel域以滤去人耳不敏感信息.

由于此时第1阶段已对全部信号分析了1遍,可以求得该信号的信噪比上限,以及初步降噪的信号.第2阶段则利用这一结果再次更新噪声的功率谱和信噪比,对滤波器参数重新进行计算,并最终应用在滤波器上,实现噪声抑制.
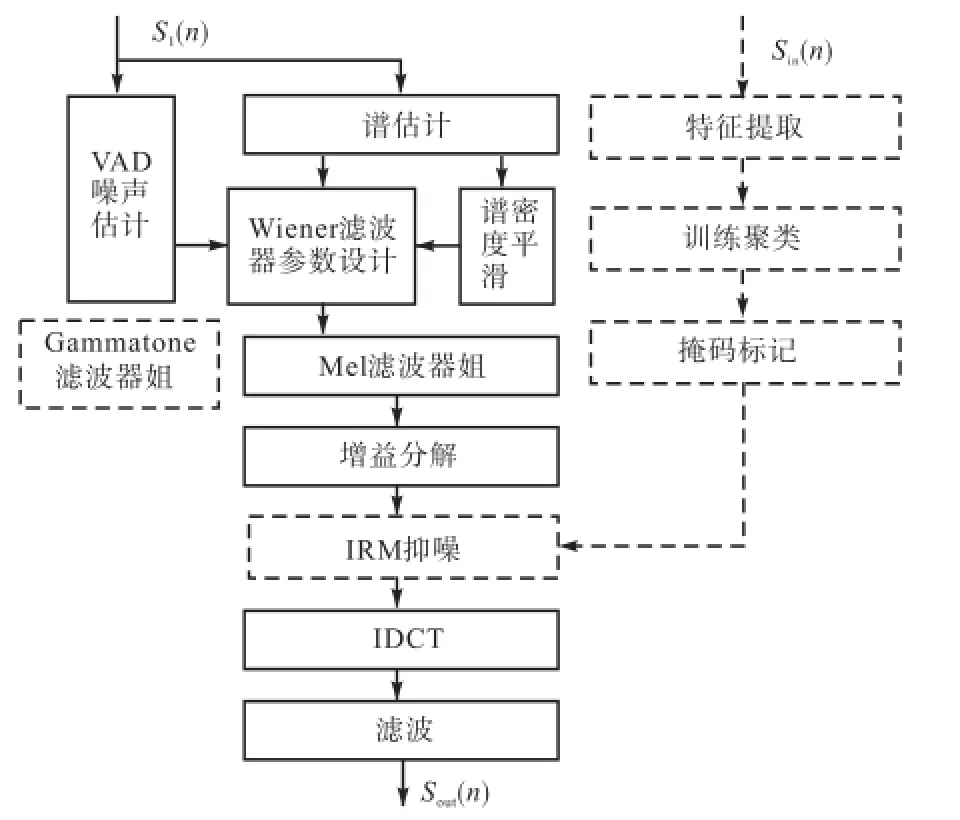
图3 第2阶段以及改进部分整体示意Fig.3 System architectures of stage 2 and the modification part
1.3 滤波器组参数向Mel域的变换
生理学研究表明,声音的频率和人耳感知的音高之间并不是线性关系,而是一条对数曲线,也就是说人耳对不同频段声音的敏感度不同.ETSI基线系统原始算法在线性频域内进行Wiener滤波器参数设计,再将线性频域求得的滤波器参数依式(4)变换到Mel域,即式中:H2_mel(k)为Mel域频标为k频点的值;k为Mel域的频标;i为线性频域的频标;W( k, i)是对滤波器参数进行加权的频窗函数,设计上为多个三角窗;NSPEC为线性频域的离散频率上限.
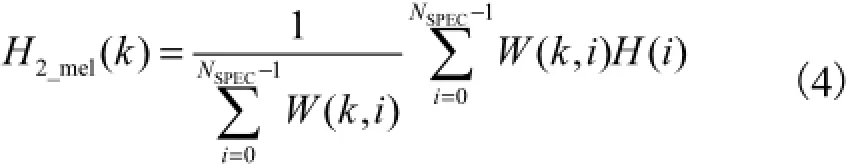
以Mel频谱的线性划分作为所关注频段的中心频率,计算式为
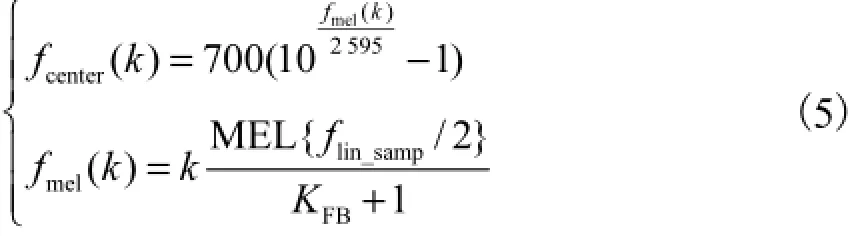
式中:fcenter(k)为变换的中心频率在线性频域的频率值;fmel(k)为变换的中心频率在Mel域的频率值;fcenter(0)=0;fcenter(FFB+1)=flin_samp/2;FFB为其他中心频率的个数,所有三角窗的数量为KFB+2.
这样做可以充分利用人耳听觉曲线的对数特性,比较在线性频域内设计出的滤波器,这样做滤除了人耳不敏感信息.不足之处在于,变换到Mel域的做法无法模拟耳蜗基底膜的频率分解作用,无法做到对不同频率信号基于不同增益的响应.
1.4 滤波器参数增益
系统已在VAD模块通过平均能量和当前帧能量的比较甄别出了语音帧与噪声帧,噪声的抑制则主要来源于在增益分解模块对两种信号施加不同的增益,即
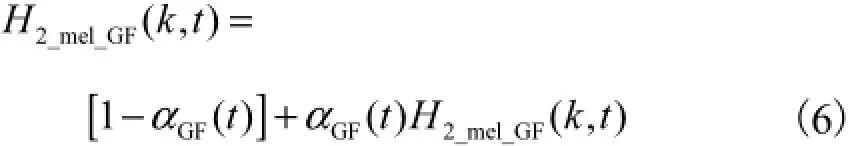
ETSI的实验已经证明,如依式(7)对语音帧和噪声帧分别设定常数增益,则没有考虑到信号的帧间相关性和连续性,去噪效果一般.

因此提出了如式(8)的算法,先对SNR进行平滑和自适应迭代更新,通过SNR的比较更精确地在此甄别语音帧,再迭代自适应地计算增益参数,使帧间过渡更平滑不突兀,既减少了增益参数大幅度阶跃引入的毛刺和噪声,又对噪声帧施加了较大的抑制,最大程度地保留了语音帧的原有信息.为

2 基于CASA算法的改进
加入了CASA算法后的整体框图见图1.首先考虑到Mel域更多地反映人耳对于音高的敏感程度,Gammatone域更能够仿真人耳对于不同频率的频响特性,则首先将其中对滤波器加三角窗频窗的部分(即Mel滤波器组模块)替换为Gammatone频窗函数,将滤波器参数变换到Gammatone域.同时,由于原有基线系统处理方式都较为平滑,处理比较稳定的噪声有优势,处理脉冲噪声可能有所不足,故在第2阶段增益分解的部分之后,引入了IRM抑噪的模块,具体修改内容见图2和图3.下面分别介绍变换到Gammatone域的方式和IRM的引入.
2.1 滤波器组参数向Gammatone域的变换
原有的ETSI系统中使用到的是三角窗进行频域的变换,而在CASA算法中,其核心思想在于人耳具有优秀的语音处理能力,仿真人耳的听觉特性能够提升系统性能.Gammatone滤波器在Johannesma[9]的研究中被用来仿真听觉神经细胞脉冲响应,故选取Gammatone滤波器.这种仿真听觉神经脉冲响应的滤波器,作为替代的频窗函数,将线性频域变换到Gammatone域.笔者认为这种变换能够在低信噪比下更为有效地模拟人耳抑制噪声的作用.
Gammatone滤波器的冲击响应[10]为
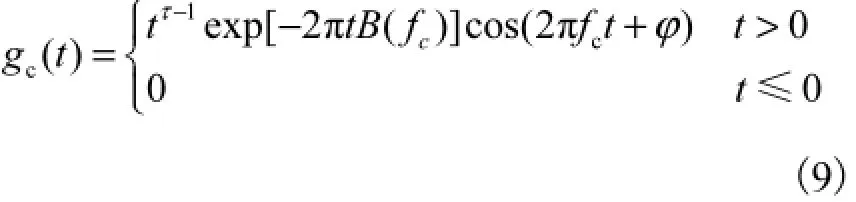
式中:τ为滤波器阶数;cf为滤波器中心频率;ϕ为相位;c()B f为对应中心频率为cf的滤波器的带宽.在本次实验中,笔者使用的是Gammatone滤波器的近似频域响应[11],即

式中f为频标数.当4τ=时,其频响特性与人耳的最为符合.此时的4阶滤波器等效带宽为

从设计上,中心频率按照临界带宽尺度均匀分布,即
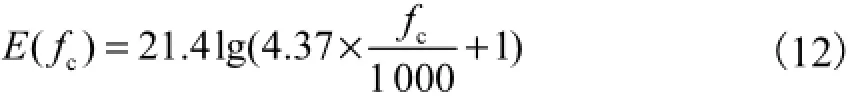
式中c()E f为等效带宽.则替换为Gammatone滤波器之后,Wiener滤波器参数在Gammatone域中可表示

2.2 IRM的引入
CASA算法一般估计一种时频掩蔽来分离噪声与声源,相比较于滤波器而言,时频掩蔽对于脉冲噪声的抑制更为明显,而且对于有谐波特性的噪声也有更好的抑制作用,故笔者选取此模块作为基线系统的补充.
这种掩蔽一般分为理想二进制掩蔽(ideal binary mask,IBM)与理想率掩蔽(ideal ratio mask,IRM).二者表示上都为二维矩阵M={m( f, t )}.对于IBM,m取值为0或1;对于IRM,m取值[0,1].相比较于滤波器,掩蔽(mask)能够更加直接地分离语音帧与噪声帧.但是由于笔者无法在降噪中得到原始语音,故只能估计IBM或IRM.
此处笔者选取的模型是Hu和Wang[12]在2004年提出的,是一种基于Brown等[13]模型并引入高频频子带内幅度调制的算法.与之不同的是,由于笔者后端依旧是一个FIR滤波器,所以笔者使用的是IRM作为掩蔽的输出,即

采用文献[11]提供的算法能够更好地计算{(,)}m f t剥离出语音与噪声,同时,其算法将IRM的计算放在了Gammatone域,所以得到的(,)m f t的物理意义正好与改进后的ETSI系统中Gammatone域的滤波器参数相对应.所以笔者在Gammatone域对于滤波器加窗之后,再通过一次IRM掩蔽,即

3 实验结果
3.1 语音增强测试
本次实验使用的是TIMIT数据库,噪声库选取的是实验室自主采集的公交车(bus)噪声,噪声包括人声、汽车发动机运转的稳定背景噪声,以及汽车启动、刹车、超车等脉冲噪声.笔者使用的是filter_add_ noise开源加噪程序[14]对纯净的TIMIT语音加噪,最终语音的信噪比SNR分别为-5,db、0,db和5,db.评价指标上,因为使用的是CASA的体系,所以笔者以描述听感质量的主观语音质量评估[15](perceptual evaluation of speech quality,PESQ)作为评价指标.
在细节参数上,FFT长度为128,Mel滤波器的上下限截止频率为0~4,000,Hz,Gammatone滤波器的上下限截止频率为80~4,000,Hz,为了增加两种域的对比性,使用的滤波器数量都为25个.3.1.1 IRM对于脉冲噪声抑制的实验
笔者从TIMIT数据集中选取了编号为DR1_FAKS0_SX313.wav的信号,在图4中给出的是0,db信噪比下,其纯净信号、加噪信号和3种降噪信号的时域波形对比.
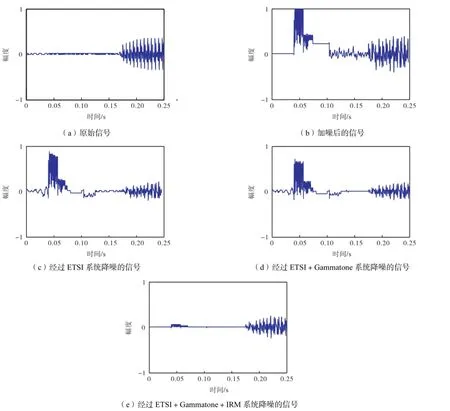
图4 DR1_FAKS0_SX313.wav信号的原始信号、带噪信号和去噪信号的波形对比Fig.4 Comparison between the wave forms of the original signal,noisy signal and the denoised signal of DR1_ FAKS0_ SX313.wav
能够看出,原始语音有1个脉冲噪声.这个脉冲噪声在合成的带噪语音中保留下来.由于原有的2个算法,对于这种短时的脉冲噪声,没有办法将第1.4节中讨论的滤波器参数增益αGF(t)迅速地降低,还维持在一个比较高的αGF(t)下,故这种噪声被保留下来.但是使用了IRM之后,这个脉冲噪声由于没有谐波结构,起止点的检测也发现是非常小,则在IRM中给出的mIRM(k, t)=0.1,脉冲噪声很好地被抑制.
3.1.2 PESQ评价指标的统计数据
TIMIT库实验下的PESQ评价指标的统计数据见表1,此处计算的是有参考语音的PESQ,表中给出的数据为降噪前后的PESQ平均绝对增益.

表1 不同信噪比下不同算法的PESQTab.1PESQ through different algorithms in different SNRs
首先从实际中听感上分析.5,db加噪后可懂度依旧不受到影响,同时原本基线系统的降噪性能就极佳,可以非常有效地去除噪声,只有在个别发声的部分有残留的谐波噪声,3种方法从听感上区别不大.0,db的加噪已经对可懂度有比较大的影响,需要更多次数地听才能够听懂.整体上说,降噪之后,能够感觉到噪声降低明显,可懂度略有提升.3种方法也略微有所区别,与基线系统相比较,加入Gammatone滤波器后的系统,增强后音频的噪声有明显降低,其降低幅度人耳可感受到,可懂度略有提升,加入IRM后的系统音强明显下降,并且噪声抑制度超过前两者,脉冲噪声数极少,虽然噪声几乎听不见,但纯净语音也需要辨识.最后是-5,db加噪,加噪后其本身的可懂度已经非常差,对于未知文本的语音,在这种信噪比下完全无法听懂,对应的降噪结果也十分不理想,从听感上,已经基本无法分辨说话的内容.3种方法中,前两种处理不完全,降噪后的音频仍带有很多的噪声,最后一种方法几乎听不到语音.所以说从听感上,整体系统的能力暂时对于处理0,db以上的带噪语音还是效果明显的,对于0,db以下的噪声音频几乎无作用.Gammatone滤波器改进后的系统从性能上更为优秀,而如第3.1.1节中体现的,IRM由于其抗噪性能太强,不是特别适用于低信噪比下,其对于脉冲噪声的抗噪性会更为优越一些.
从评价指标角度上来说,将Mel域的变换替换为Gammatone域的变换能够提升PESQ,因为其更为符合人耳的听觉特性.而IRM的加入却使得PESQ有所下降.首先从听感上来说,经过IRM处理后的语音普遍的音量都会降低,这一点从式(15)可以看出来.其原因可能是因为IRM使用到onset/offset、谐波频率等检测方式,对于噪声的检测更为严格,使得过分地降噪将语音部分也抑制了很多,使得听感上也有所下降.比较值得关注的地方在于,在0,db信噪比输入的情况,使用Gammatone的方法对于PESQ的提升最大.其原因应该是因为此时Gammatone抗噪性能优于Wiener滤波器抗噪性能,对系统有一个较大补偿.这也与人耳在“鸡尾酒噪声”下的情况相一致,所以说在低信噪比的情况下,使用Gammatone滤波器对于PESQ的提升更为明显.最后则是-5,db的情况.实验数据表明,PESQ几乎没有提升.原因应该是因为在极低信噪比的情况下,语音已经难以分辨,系统是用来仿真人耳的,人耳在这种信噪比下也已经超过了可识别的范围,故系统也难以分辨.
3.2 语音识别测试
语音识别使用到的是TIMIT数据集.由于纯净的语音信号、带噪语音信号与去噪语音信号都包含全部TIMIT数据集,共6,300条,故每一组语音识别实验选取一次全新TIMIT数据集,此组信号所有处理条件一致.对于每一组实验,使用462位说话人训练,并不使用每一位说话人说的SA部分的内容.开发集选取50位说话人,测试集选取24位说话人,与其他TIMIT语音识别系统选取方式基本一致.语音识别后端系统采用神经网络构建,网络层数为4层,每层1,024节点,特征为39维MFCC特征,由5±帧拼接而成;网络使用DBN预训练,使用61×3状态数的Monophone对音素进行标注,评价标准为词错误率(word error rate,WER).
首先,对于纯净语音,WER经过测试为22.86%,远远优于表2的所有数据.对于语音识别的效果来说,高信噪比的情况下,带噪语音的WER将会低于降噪之后的语音.原因是对于神经网络来说,降噪对于其WER的影响不明显[16].从降噪程序之间比较,Gammatone的性能较好,应该是由于其在降噪的同时,保留了更多的语音原本信息,更符合神经网络学习的需要.

表2 不同信噪比下不同算法的识别词错误率Tab.2Recognition WER of the signals through different algorithms in different SNRs
4 结 语
笔者对ETSI的语音增强算法进行了修改.首先,用Gammatone滤波器组替换原有的三角窗滤波器组,在Gammatone域处理Wiener滤波器参数;其次,将IRM作用在Wiener滤波器系数上,对噪声进行二次过滤.结果表明,在语音增强方面,Gammatone滤波器对于语音增强有较大改进效果,在低信噪比时更为明显,IRM对于噪声抑制更强,适合脉冲噪声的抑制,但是两者都不适应超低信噪比的实验环境;改进后的降噪算法与原有算法相比在听感知质量和可懂度上都有提高,加入该前端处理的识别系统,在低信噪比下识别率也有所提升.
参考文献:
[1] Williamson D S,Wang Y,Wang D L. A two-stage approach for improving the perceptual quality of separated speech [C]//2014 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Florence,Italy,2014:7034-7038.
[2] El-Fattah M A A,Dessouky M I,Diab S M,et al. Adaptive wiener filtering approach for speech enhancement [J]. Journal of Ubiquitous Computing and Communication,2008,2(3):23-31.
[3] Liu Y,He L,Liu J. Improved multitaper PNCC feature for robust speaker verification [C]//2014 9th International Symposium on Chinese Spoken Language Processing(ISCSLP). Singapore,2014:168-172.
[4] Brown G J,Wang D L. Speech Enhancement [M]. USA:Springer Berlin Heidelberg,2005.
[5] Wang D L. Time-frequency masking for speech separation and its potential for hearing aid design [J]. Trends in Amplification,2008,12(4):332-353.
[6] 李朝晖,迟惠生. 听觉外周计算模型研究进展 [J].声学学报,2006,31(5):449-465.
Li Zhaohui,Chi Huisheng. Progress in computational modeling of auditory periphery[J]. Acta Acustica,2006,31(5):449-465(in Chinese).
[7] Narayanan A,Wang D L. Ideal ratio mask estimation using deep neural networks for robust speech recognition [C]//2013 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Vancouver,Canada,2013:7092-7096.
[8] ETSI. ES. 202 050 V1. 1. 5 Speech Processing,Transmission and Quality Aspects(STQ),Distributed Speech Recognition(2007)[S]. European Telecommunications Standards Institution,2007.
[9] Johannesma P I M. The pre-response stimulus ensemble of neurons in the cochlear nucleus[C]//Symposium on Hearing Theory. Eindhoven,Holland,1972.
[10] 张卫强,刘 加. 基于听感知特征的语种识别[J]. 清华大学学报:自然科学版,2009,49(1):78-81.
Zhang Weiqiang,Liu Jia. Language identification based on auditory features[J]. Journal of Tsinghua University:Science and Technology,2009,49(1):78-81(in Chinese).
[11] 胡 琦. 基于计算听觉场景分析的单信道语音分离研究[D]. 北京:北京交通大学计算机与信息技术学院,2013.
Hu Qi. Single-Channel Speech Separation Based on Computational Auditory Scene Analysis [D]. Beijing:Institute of Information Science,Beijing Jiaotong University,2013(in Chinese).
[12] Hu G N,Wang D L. Monaural speech segregation based on pitch tracking and amplitude modulation [J]. IEEE Transactions on Neural Networks,2004,15(5):1135-1150.
[13] Brown Guy J,Cooke Martin. Computational auditory scene analysis [J]. Computer Speech & Language,1994,8(4):297-336.
[14] Hirsch H G. FaNT—Filtering and Noise Adding Tool [EB/OL]. http://dnt. kr. hsnr. de/download/ fant_ manual. pdf,2015-01-15.
[15] ITU-T P. 862—2002 Perceptual Evaluation of Speech Quality(PESQ):An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs [S].
[16] Deng L,Li J,Huang J T,et al. Recent advances in deep learning for speech research at Microsoft [C]//2013 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Vancouver,Canada,2013:8604-8608.
(责任编辑:金顺爱)
A Speech Enhancement Algorithm Based on Computational Auditory Scene Analysis
Zhang Weiqiang1,Guo Cong1,Zhang Qiao1,Kang Jian1,He Liang1,Liu Jia1,Johnson Michael T1,2
(1.Department of Electronic Engineering,Tsinghua University,Beijing 100084,China;2.Department of Electrical and Computer Engineering,Marquette University,Milwaukee 53233,USA)
Research on the ETSI speech enhancement system was conducted using traditional Wiener filter for noise reduction, which performed well when signal-noise ratio was high enough. However, when SNR decreased to a certain extent, it failed to suppress pulse noise effectively. Computational auditory scene analysis (CASA) simulating human auditory characteristics could make up for this weakness. Therefore, based on ETSI combined with CASA, a new speech enhancement algorithm was proposed, which performed feature extraction and spectrum estimation in the Gammatone domain rather than the original Mel domain as well as filtered out noise by an ideal ratio mask (IRM). On the noisy subset of the TIMIT corpus, the proposed enhancement achieves higher objective acoustic quality and proven ability to inhibit pulse noise under low SNR conditions compared to the original system. It also obtains an improvement in terms of the reduction of word error rates under low SNR conditions in the back-end speech recognition system.
speech enhancement;computational auditory scene analysis;Gammatone filter;idea ratio mask
TN912.3
A
0493-2137(2015)08-0663-07
10.11784/tdxbz201507029
2015-03-15;
2015-07-13.
国家自然科学基金资助项目(61370034,61273268,61403224).
张卫强(1979— ),男,博士,副研究员.
张卫强,wqzhang@tsinghua.edu.cn.
时间:2015-07-15.
http://www.cnki.net/kcms/detail/12.1127.N.20150715.1655.002.html.
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
成都信息工程大学学报(2021年1期)2021-07-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
雷达学报(2018年3期)2018-07-18
电子制作(2018年1期)2018-04-04
雷达学报(2017年3期)2018-01-19
北京航空航天大学学报(2017年3期)2017-11-23
火控雷达技术(2016年2期)2016-02-06
