
结合SVM和改进证据理论的多信息融合故障诊断
2015-06-04 13:02向阳辉张干清庞佑霞
振动与冲击 2015年13期
向阳辉,张干清,庞佑霞
(长沙学院 机电工程系,长沙 410003)
在故障诊断实践中只有综合合理利用设备多个方面的特征信息进行融合分析,才能实现对设备全面与准确的诊断[1-2]。由于支持向量机(Support Vector Machine,SVM)是基于结构风险最小化原则,具有小样本学习能力和较好的泛化能力[3-4];而证据理论是概率论的推广,具有比概率论更弱的公理体系和更严谨的推理过程,能够更加客观反映事物的不确定性[5-6],因此将SVM和证据理论相结合在多信息融合的故障诊断中进行应用已成为当今研究热点[7-8]。
但由于SVM和证据理论的固有特性,将二者有效结合就必须解决两个关键问题。其一,由于多源信息各特征域参数片面失真或诊断机理不完善等缺陷,常会导致各SVM局部诊断结果冲突明显、合成结论有悖常理[6]。国内外专家学者已提出了众多改进方法,但主要集中在证据合成法则[9-11]、证据距离[6,12]或证据冲突系数[13]等数学层面进行改进,却忽略了特征域和诊断机理的不同,会导致各SVM局部诊断证据对各故障模式诊断的可靠度不同这一事实。其二,SVM一般以{+1,-1}作为输出,这种硬判决输出无法直接得到各SVM局部诊断结果的基本概率分配,严重影响基于SVM的各证据进行组合合成。文献[14-15]提出使用sigmoid函数来估算SVM配对类的概率,较好地解决了二分类SVM基本概率分配的问题,但故障诊断领域是多分类问题,至今没有统一的基本概率分配方法。
本文为了综合合理利用设备多个方面特征信息来提高故障诊断的准确性,着重研究SVM与证据理论相结合必须解决的两个关键问题,通过混淆矩阵获取各SVM局部诊断证据对各故障模式的可靠度,赋予不同的权重系数,同时由各SVM局部诊断硬输出判决矩阵构造出基本概率分配,并对基本概率分配进行加权处理,降低各SVM局部诊断间的冲突,实现SVM和改进证据理论的有效结合,从而提出一种结合SVM和改进证据理论的多信息融合故障诊断方法。最后通过转子实验测试,验证了该方法能够有效提高故障诊断的准确率。
1 SVM及D-S证据理论改进
1.1 SVM 理论
支持向量机(SVM)是建立在统计学习理论和结构风险最小化原理基础上的新型机器学习方法[8],其分类方法的实质就是寻找一个最优分类超平面,使得从这个超平面到两类样本集的距离之和(即分类间隔)最大。
假定2类线性可分样本集 (xi,yi)(xi∈Rd;yi∈{-1,+1};i=1,2,…,n),支持向量机把寻找分类间隔最大的最优超平面问题转化为求解凸二次优化问题:

式中:ω为权重向量;b为偏置;ξ为松弛因子;C为惩罚因子。
当式(1)中 yi[(ω.xi)+b]≥1-ξi的等号成立时,对应的样本称之为支持向量。它是一个由训练样本集的一个子集样本向量构成的展开式。从训练集中得到了描述最优分类超平面的决策函数即支持向量机,它的分类功能由支持向量决定。
对于线性可分问题,求解得到决策函数:

式中:αi为拉氏乘子;k为支持向量数目。
若样本集 (xi,yi)(xi∈Rd;yi∈{-1,+1};i=1,2,…,n)线性不可分,可以通过非线性变换映射到某个高维的特征空间,即用核函数K(x,xi)代替原空间的内积,使得其在该高维空间下线性可分。
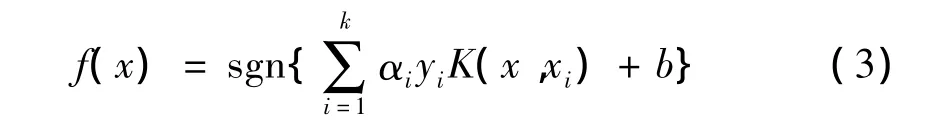
标准SVM解决的是二分类问题,而故障诊断等领域需要解决的是多分类问题。目前已经提出一些有效的多分类支持向量机包括一对多、一对一、有向无环图、二叉树、纠错编码等。
1.2 D-S 证据理论
D-S证据理论基本实质是在同一辨识框架下将多个具体证据组合成一个抽象证据的过程,该抽象证据能够综合多个具体证据的信息,聚焦多个具体证据的共同支持点,从而得到更加合理的结论。
假定某问题的相互独立的所有可能答案的集合为辨识框架 Θ ={A1,A2,…An},Aj称为 Θ 的基元,2Θ为Θ的幂集。如果集函数映射m:2Θ→[0,1]满足
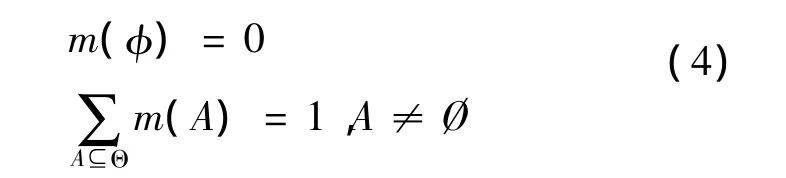
则称该映射m:2Θ→[0,1]为辨识框架Θ上的基本概率分配函数。∀A⊆Θ,m(A)称为A的基本概率分配。对于该辨识框架Θ,则由

所定义的映射Bel:2Θ→[0,1]为辨识框架Θ上的信度函数,映射Pl:2Θ→[0,1]为 Bel的似真度函数。对于∀A⊆Θ,[Bel(A),Pl(A)]称为A的信度区间,信度区间描述了当前证据对命题A所持信任程度的上下限。
当两个证据进行组合,m1和m2是同一辨识框架Θ上的基本概率分配函数,基元分别为E1,E2,…,Ek和F1,F2,…,Fn。若∀A⊆Θ 且:

则合成后的基本概率分配函数m:2Θ→[0,1]为
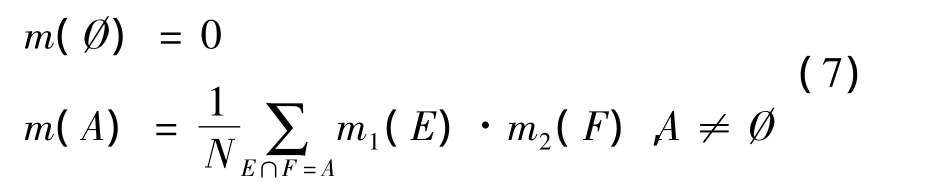
式中:N为规范数,它的作用是把空集上所丢失的信度按比例分配到非空集上,以满足概率分配的要求。N值能够反映证据的冲突程度,证据的冲突越大,N值越小。当N=0时,表明证据完全冲突,合成公式不再适用。
式(7)中的这种组合称为正交和,记为m1⊕m2,并且证据的组合与运算次序无关,因此多个证据组合的计算可以用两个证据组合的计算递推得到

1.3 证据理论的加权改进
证据理论在应用中发现有一个明显的缺陷,就是当证据严重冲突时,证据合成法则不再适用或合成结果不能反映客观事实[6]。证据理论出现这种缺陷,是由于证据合成时将每个证据体都视为同等重要,没有考虑到不同来源的证据对辨识框架中各命题的识别具有不同的可靠性这一事实。为了客观体现各特征域对各故障的诊断具有不同的可靠度,本文基于SVM并结合加权思想,对D-S证据理论进行改进。
对于同一辨识框架Θ,设各证据体对辨识框架中n个命题识别的可靠度为R(A)→[0,1],∀A⊂Θ,则由

所定义的映射W(·)为辨识框架Θ上的权系数分配函数。∀A⊆Θ,W(A)称为证据体对A的权系数分配。式中k≥1,当证据对各命题识别的可靠度这一数据越可靠,k取值越大。证据的权系数W(A)体现了证据对辨识框架中各命题的识别具有不同的可靠度。
为了在证据组合时充分考虑各证据对各命题的权重,对式(4)的基本概率分配函数m:2Θ→[0,1]进行加权处理。∀A⊆Θ,则由
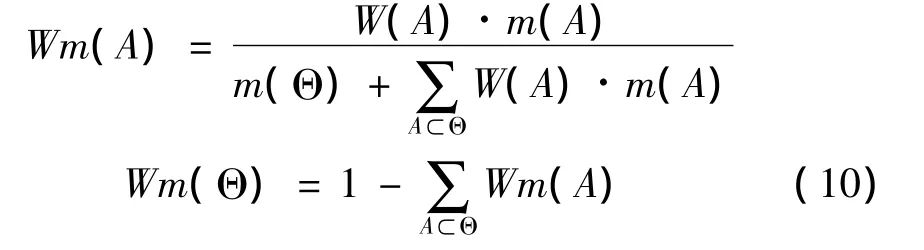
所定义的映射Wm:2Θ→[0,1]为辨识框架Θ上的加权概率分配函数。∀A⊆Θ,Wm(A)称为A的加权概率分配。
多证据的合成法则如式(11),由于对基本概率分配函数进行了加权处理,合理证据得到加强,不合理证据被削弱,证据间冲突显著降低,N值不会趋近于0,因此改进后的证据理论能够更加广泛地满足各种实际应用。
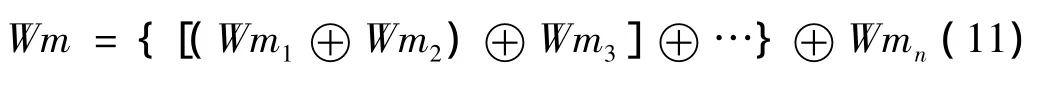
2 结合SVM和改进证据理论的多信息融合故障诊断模型
2.1 多信息融合故障诊断模型的构建
本文结合SVM和改进证据理论的多信息融合故障诊断过程可分为三大步骤:①特征参数提取;②SVM局部初级诊断及其诊断结果分析;③多证据加权融合决策诊断。其应用框架如图1所示。
步骤一特征参数提取:对待诊断目标设备进行信号采集、信号预处理,提取故障特征参数并归类,从而构造出多个证据体特征子空间。每个证据体特征子空间都从一个独立侧面反映了待诊断目标设备的故障状态。
步骤二SVM局部初级诊断及其诊断结果分析:基于各证据体特征子空间搭建相应的SVM局部诊断子模块,并对各SVM局部诊断结果进行分析。

图1 多信息融合故障诊断应用框架Fig.1 The application frame of multi-information fusion fault diagnosis
(1)权重系数的获取:将各故障模式一定数量样本输入到已搭建好的各SVM局部诊断子模块进行故障诊断测试得到各SVM的混淆矩阵,再对混淆矩阵进行分析处理得到各SVM局部诊断证据体对各故障模式诊断结果的可靠度,最后通过式(9)即可获得各证据体对各故障模式的权重系数。在权重系数获取过程中,各SVM局部诊断证据体对各故障模式诊断结果的可靠度分析非常关键,其具体分析过程将在2.2节进行更详细阐述。
(2)基本概率的分配:将一组待诊断信号样本提取后的特征向量输入到已搭建好的各SVM局部诊断子模块获得各SVM证据体对各故障模式的“一对一”多分类SVM判决矩阵,再对判决矩阵进一步分析得到各SVM局部诊断证据体的隶属度,最后由隶属度可以构造得出各证据体对各故障模式的基本概率分配。多分类SVM的基本概率分配是一个难点,其具体分配过程将在2.3节进行更详细阐述。
步骤三多证据加权融合决策诊断:将各证据体对各故障模式的基本概率分配进行加权处理得到各证据体对各故障模式的加权概率分配,并对多个证据体的加权概率分配结果进行加权组合合成,从而得到多个证据加权融合后的最终诊断结论。其诊断决策具体过程和决策规则详见2.4节。
2.2 各局部诊断的可靠度分析
混淆矩阵是故障诊断领域中一种可视化的诊断效果示意图,它描绘了各故障模式样本数据的真实属性和诊断结果类型之间的关系[16],可以用来评价各局部诊断子模块的性能。
假设辨识框架中共有n类故障模式{A1,A2,…,An},各故障模式分别含有Ti(i=1,2,…,n)个故障样本,将这些故障样本输入到已搭建好的各SVM局部诊断子模块进行故障诊断测试得到各SVM对各故障模式诊断的n×n维混淆矩阵CM

其中:元素的行下标为目标的真实属性,列下标为该局部诊断的判断属性,cmij表示第i类故障模式被该局部诊断子模块判断成第j类故障模式的数据占第i类故障模式样本总数的百分率,对角线元素为各故障模式能够被该局部诊断子模块正确判断的百分率,非对角线元素为发生错误判断的百分率。
混淆矩阵的行向量CMi(i=1,2,…,n)为第i类故障模式的对象在进行诊断时对各故障模式的倾向性。不同局部诊断子模块的混淆矩阵代表了该局部诊断对故障模式的诊断能力,即可由该混淆矩阵得出该局部诊断对各故障模式诊断结果的可靠度。
因此该局部诊断对第j类故障模式诊断结果的可靠度Rj可以定义为该局部诊断正确判断为第j类的百分率与该局部诊断判断为第j类的总百分率的比值,即

据此,可以分别计算得出每个局部诊断对各故障模式诊断结果的可靠度。若某个局部诊断对某类故障模式j诊断结果的可靠度Rj越高,则表示如果该局部诊断结果为第j类,则该诊断结果就应越可信,按照式(9)系统赋予它的可靠度加权系数W(Aj)也就越大;反之亦然。
2.3 各SVM的基本概率分配
故障诊断领域要解决的通常都是多分类问题,本文采用“一对一”多分类SVM方法进行处理。假设辨识框架中共有 n类故障模式{A1,A2,…,An},通过“一对一”两两分类方法建立多分类SVM的硬输出判决矩阵SM

F(Ai,Aj)表示故障样本是属于Ai类还是属于Aj类的标准SVM判决的硬输出,判定属于Ai类,则F(Ai,Aj)=+1;判定属于 Aj类,则 F(Ai,Aj)= -1。判决矩阵第1行表示为第A1类与其它类两两分类的SVM硬输出判决结果;判决矩阵第n行表示为第An类与其它类两两分类的SVM硬输出判决结果。
分析判决矩阵SM的第j行向量,可知第Aj类与其它类进行两两分类的总分类次数为(n-1)次;同时第j行判决硬输出为1的次数之和,即第Aj类与其它类进行两两分类时判决属于第Aj类的次数。将判决属于第Aj类的分类次数与第Aj类参与的总分类次数之比定义为第Aj类的隶属度qj
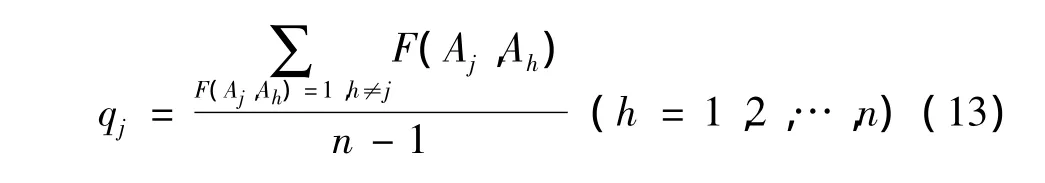
不能确定属于任何一类的隶属度,即不确定的隶属度定义为qΘ

根据“一对一”多分类SVM判决矩阵SM得到各类故障模式的隶属度qj。隶属度qj越大,故障样本属于第Aj类故障模式的可能性应越大,m(Aj)得到的基本概率分配也应越大,可以构造如下公式进行各SVM基本概率分配

式中:M表示SVM多分类的规模,多分类规模越大M值应越大。本文将各类故障模式的隶属度qj之和定义为M。

2.4 基于改进证据理论的融合决策诊断
由本文2.2和2.3节已获得各SVM局部诊断证据对各故障模式的可靠度加权系数W(A)和基本概率分配m(A),根据式(10)对各证据进行加权处理得到各证据的加权概率分配Wm(A);然后再根据式(11)对多个证据的加权概率分配函数进行加权组合合成,计算得到多个证据加权融合后对辨识框架Θ中所有故障模式进行诊断的可信度Wm(Fj)和不确定度Wm(Θ);最后可由以下诊断决策规则判断得出最终的诊断结论Fc:
规则1 Bel(Fc)=max{Bel(Fj),Fj⊆Θ}
规则2 Bel(Fc)-Bel(Fj)>ε;Bel(Fc)>Wm(Θ)
规则3 Wm(Θ)<γ
规则1是诊断的基本条件,即所判定故障模式具有最大的可信度;规则2表明所判定故障模式的可信度必须比其它故障模式的可信度大ε,即占有相当优势;规则3表明不确定度必须小于γ,保证故障样本是充分可判断的。其中ε和γ应根据实际情况确定。
3 实验分析
本文是在转子实验台上分别模拟转子正常、不平衡、不对中、径向碰磨和油膜涡动5种单一工况故障模式的诊断识别研究。因此系统辨识框架为Θ={F1,F2,F3,F4,F5},其中 F1为正常状态,F2为不平衡状态,F3为不对中状态,F4为径向碰磨状态,F5为油膜涡动状态。本实验台转速为1000 r/min,采集系统是基于LabVIEW进行开发,用于采集转子实验台转轴的振动信号。测点布置在轴承座的水平和垂直方向,传感器为Bently 3300XL8mm电涡流传感器,其安装示意如图2所示;采集卡为阿尔泰PCI2006型14位数据采集卡,采样频率为417 Hz。本文为了使得转子实验台模拟的工况更加接近工程应用实际,确保更加有效进行实验分析,所有采集的原始样本数据都加入了占信号幅值13%左右的白噪声信号。
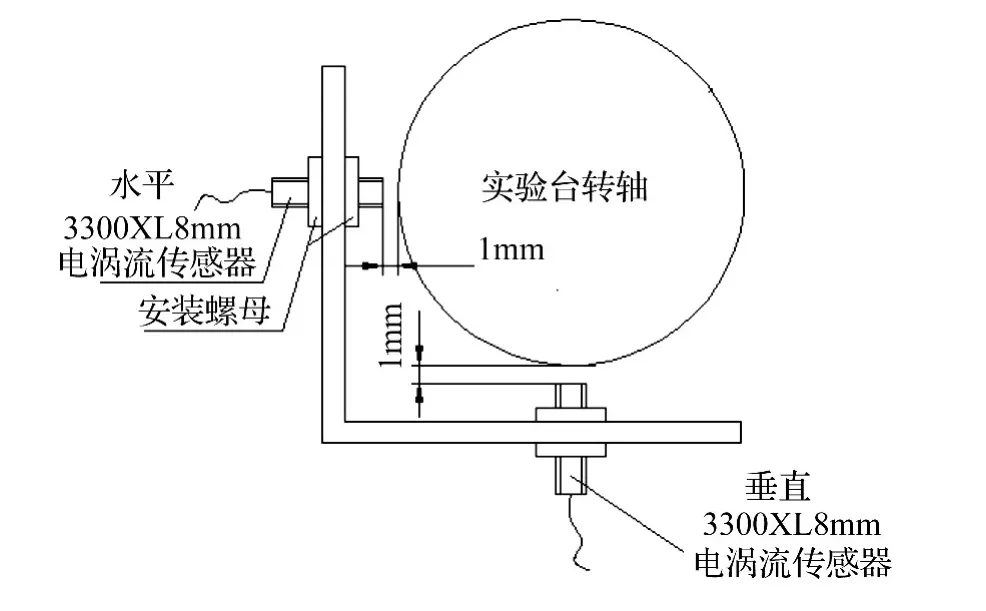
图2 Bently电涡流传感器安装示意图Fig.2 Installation schematic diagram of Bently tortex sensor
分析辨识框架中各故障模式的发生机理,分别从转轴振动信号中提取频域小波能量分析特征向量(E1,E2,…,E6)、时域AR模型自回归参数特征向量(α1,α2,…,α15)和轴心轨迹不变矩特征向量(φ1,φ2,…,φ10)作为该转子实验台的3个独立特征向量子空间,从不同侧面对设备进行局部诊断。
基于频域小波能量分析特征向量搭建SVM进行局部诊断作为证据体1,并选取该转子实验台各故障模式下典型样本各100组进行测试,得到该证据体1的混淆矩阵CM1:

基于时域AR模型自回归参数特征向量搭建SVM进行局部诊断作为证据体2,同样选取该转子实验台各故障模式下典型样本各100组进行测试,得到该证据体2的混淆矩阵CM2:

基于轴心轨迹不变矩特征向量搭建SVM进行局部诊断作为证据体3,同样选取该转子实验台各故障模式下典型样本各100组进行测试,得到该证据体3的混淆矩阵CM3:

对混淆矩阵CM1、CM2和CM3按式(12)进行计算得到上述3个证据体对转子5种故障模式识别的可靠度如表1所示;再将其按照式(9)进行处理,取k=3得到各证据体对各状态模式的加权系数如表2所示。

表1 各证据体识别的可靠度Tab.1 The reliability recognized by each evidence
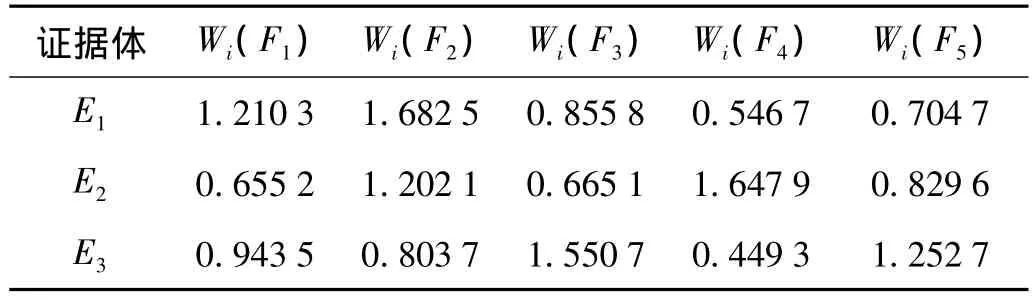
表2 各证据体的加权系数Tab.2 The weighed coefficient of each evidence
现取该转子的一组不平衡状态(F2)信号样本,分别提取其频域、时域和轴心轨迹特征向量,通过上述已搭建好的各单一特征SVM局部诊断获得各证据体对各故障模式的“一对一”多分类SVM判决(投票)结果统计如表3所示;根据式(13)~(16)构造各SVM局部诊断证据体的隶属度如表4、基本概率分配如表5所示;再根据式(10)进行加权处理得到加权概率分配如表6所示;最后根据式(8)、(11)进行多证据的合成运算,传统D-S证据理论融合和加权改进证据理论融合的计算结果对比如表7所示。

表3 “一对一”多分类SVM判决(投票)结果Tab.3 The judgment result by one-to-one multi-classification SVM

表4 各证据体的隶属度Tab.4 The subordinate degree of each evidence

表5 各证据体的基本概率分配Tab.5 The basic probability assign of each evidence

表6 各证据体的加权概率分配Tab.6 The weighed probability assign of each evidence
从表3、表4和表5可以看出,3个SVM单一特征局部诊断证据的判决结论冲突严重,不利于多证据的融合诊断。但从表5、表6对比可以看出,当各证据体被加权处理后,证据 E1对 F2正确识别的可信度从0.4511提升到 0.6499;证据 E3对 F4错误识别的可信度从0.4511下降到0.2640。由此可见,各SVM单一特征局部诊断证据体通过加权处理后正确识别的可信度能够提升,错误识别的可信度能够下降,各证据体间的冲突明显减小,有利于提高多证据融合诊断的准确率。
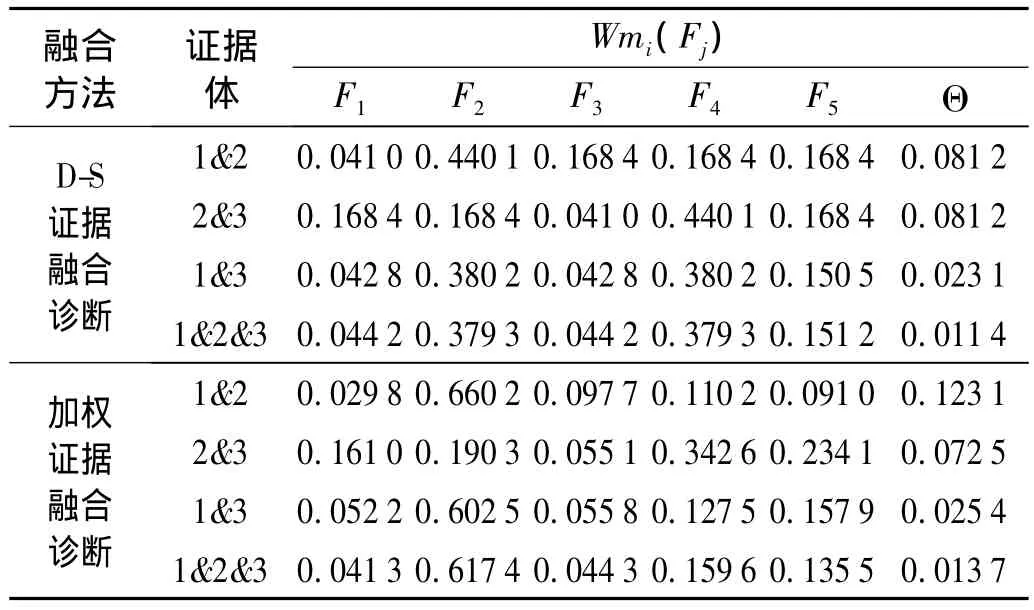
表7 多证据体融合诊断对比Tab.7 The contrast of multi-evidence fusion diagnosis
从表7中可以看出,直接采用传统D-S证据理论进行合成,E1、E2、E3融合后对F2正确识别的可信度和对F4错误识别的可信度都是0.3793,无法对故障模式进行正确诊断;但采用改进后的加权证据理论对多证据体进行加权合成,E1、E2、E3融合后对F2正确识别的可信度从0.3793提升到0.6174,对F4错误识别的可信度从0.3793下降到0.1596,能够正确诊断该故障模式为F2。由此可见,多证据体通过加权合成处理后能够使得正确识别的结论相互加强,错误识别的结论相互削弱,融合诊断后的结果可信度具有更好的峰值性和可分性,从而能够提高故障诊断系统对故障模式的诊断识别能力。
为了评估该融合诊断系统的性能,选取不同故障模式下典型样本各100组分别进行单一特征的SVM故障诊断和多特征融合的SVM-DS故障诊断测试,在相同的决策规则下(ε =0.40,γ =0.20),诊断识别结果对比如表8所示。从表中总识别率比较可知,结合SVM和加权证据理论的多信息融合故障诊断方法确实能够有效提高故障诊断的准确率。

表8 测试样本故障诊断识别结果对比Tab.8 The contrast of fault diagnosis recognition results of the test samples
4 结论
(1)为了解决多证据融合过程中证据严重冲突的问题,本文通过混淆矩阵获取各SVM局部诊断证据对各故障模式的可靠度,从而赋予不同的权重系数,并对证据理论进行加权改进,使正确诊断的可信度能够提升,错误诊断的可信度能够下降,有效降低了证据冲突。
(2)为了解决多分类SVM中基本概率输出难的问题,本文基于“一对一”多分类SVM硬输出判决矩阵提出了一种基本概率分配的构造方法,实现了多分类SVM的基本概率输出,使得SVM和证据理论在故障诊断应用中能够有效结合。
(3)针对如何综合合理利用设备多个方面特征信息来提高故障诊断准确性这一问题,本文结合SVM和改进证据理论,提出了一种多信息融合的故障诊断方法。转子实验台实验结果表明,多个SVM局部诊断证据通过加权融合诊断后能够使得正确识别的结论相互加强,错误识别的结论相互削弱,融合诊断后的结果可信度具有更好的峰值性和可分性,故障诊断的准确率显著提高,充分验证了该多信息融合故障诊断方法的有效性。
[1]胡金海,余治国,翟旭升,等.基于改进D-S证据理论的航空发动机转子故障决策融合诊断研究[J].航空学报,2014,35(2):436-441.HU Jin-hai,YU Zhi-guo,ZHAI Xu-sheng,et al.Research of decision fusion diagnosis of aero-engine rotor fault based on improved D-S theory[J].Acta Aeronautica Et Astronautica Sinica,2014,35(2):436-441.
[2]张恒,赵荣珍.故障特征选择与特征信息融合的加权KPCA 方法研究[J].振动与冲击,2014,33(9):89-93.ZHANG Heng,ZHAO Rong-zhen.Weighted KPCA based on fault feature selection and feature information fusion[J].Journal of Vibration and Shock,2014,33(9):89-93.
[3]蒋玲莉,刘义伦,李学军,等.基于SVM与多振动信息融合的齿轮故障诊断[J].中南大学学报(自然科学版),2010,41(6):2184-2188.JIANG Ling-li ,LIU Yi-lun,LI Xue-jun,et al.Gear fault diagnosis based on SVM and multi-sensor information fusion[J].Journal of Central South University(Science and Technology),2010,41(6):2184-2188.
[4]王维刚,刘占生.多目标粒子群优化的支持向量机及其在齿轮故障诊断中的应用[J].振动工程学报,2013,26(5):743-749.WANG Wei-gang,LIU Zhan-sheng.Support vector machine optimized by multi-objective particle searm and application in gear fault diagnosis[J].Journal of Vibration Engineering,2013,26(5):743-749.
[5]李巍华,张盛刚.基于改进证据理论及多神经网络融合的故障分类[J].机械工程学报,2010,46(9):93-99.LI Wei-hua,ZHANG Sheng-gang.Fault classification based on improved evidence theory and multiple neural network fusion[J].Chinese Journal of Mechanical Engineering,2010,46(9):93-99.
[6]韩德强,杨艺,韩崇昭.DS证据理论研究进展及相关问题探讨[J].控制与决策,2014,29(1):1-8.HAN De-qiang,YANG Yi,HAN Chong-zhao.Advances in DS evidence theory and related discussions[J].Control and Decision,2014,29(1):1-8.
[7]姜万录,吴胜强.基于SVM和证据理论的多数据融合故障诊断方法[J].仪器仪表学报,2010,31(8):1738 -1743.JIAN Wan-lu, WU Sheng-qiang. Multi-data fusion fault diagnosis method based on SVM and evidence theory[J].Chinese Journal of Scientific Instrument,2010,31(8):1738-1743.
[8]车红昆,吕福在,项占琴.多特征SVM-DS融合决策的缺陷识别[J].机械工程学报,2010,46(16):101 -105.CHE Hong-kun ,LÜ Fu-zai ,XIANG Zhan-qin.Defects identification by SVM-DS fusion decision-making with multiple features[J].Journal of Mechanical Engineering,2010,46(16):101-105.
[9]Denoux T.Conjunctive and disjunctive combination of belief functions induced by non distinct bodies of evidence[J].Artificial Intelligence,2008,172(2/3):234 -264.
[10]Chao F,Yang S L.The combination of dependencebased interval-valued evidential reasoning approach with balanced scorecard for performance assessment[J].Expert Systems with Applications,2012,39(3):3717 -3730.
[11]韩东,李洪儒,许葆华.基于广义证据一致量和信息量因子的证据组合规则[J].仪器仪表学报,2010,31(12):2724-2727.HAN Dong,LI Hong-ru,XU Bao-hua.Combination rule of evidence based on general evidence consistency degree and information content factor[J].Chinese Journal of Scientific Instrument,2010,31(12):2724 -2727.
[12]Jousselme A L,Maupin P.Distances in evidence theory:Comprehensive survey and generalizations[J].Int J of Approximate Reasoning,2012,53(2):118-145.
[13]张锟,张昌芳,李杰.基于新冲突度量的属性信息相关算法[J].控制与决策,2011,26(4):601-605.ZHANG Kun, ZHANG Chang-fang, LI Jie. Attribute information correlation algorithm based on new conflict Measure[J].Control and Decision,2011,26(4):601-605.
[14]Platt J.Probabilistic outputs for support vector machines and comparison to regularized likelihood method[C].Advance in Large Margin Classifier,Cambridge:MIT Press,2000:61 -74.
[15]Lin H,Lin C,Weng R C.A note on platt’s probabilistic outputs for support vector machines[J].Machine Learning ,2007,68(3):267-276.
[16]雷蕾,王晓丹,邢雅琼,等.结合SVM和DS证据理论的多极化HRRP分类研究[J].控制与决策,2013,28(6):861-866.LEI Lei,WANG Xiao-dan,XING Ya-qiong,et al.Multipolarized HRRP classification by SVM and DS evidence theory[J].Controland Decision,2013,28(6):861 -866.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
一重技术(2021年5期)2022-01-18
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2016年6期)2016-11-16
