
基于词频的英语词汇学习管理机制的研究
2015-06-01 10:57:12孙风华刘永辉谢红秀
湖南理工学院学报(自然科学版) 2015年4期
孙风华, 刘永辉, 李 玲, 谢红秀
(湖南理工学院 信息中心, 湖南 岳阳 414006)
基于词频的英语词汇学习管理机制的研究
孙风华, 刘永辉, 李 玲, 谢红秀
(湖南理工学院 信息中心, 湖南 岳阳 414006)
通过设计一套以词频为基础的英语词汇学习管理机制, 实现对互联网上的英语学习资源进行分级管理, 并依据一定的策略为学习者个别化的词汇学习需求匹配学习语篇. 该机制通过提高新词汇在语篇中的出现频率, 从而提高词汇学习绩效. 该机制可以为英语词汇学习系统的研发提供理论基础.
词频; 词汇学习; 学习管理
引言
随着互联网的发展, Internet上的信息呈现爆炸式增长, 网络已经成为了我们学习的重要手段和途径.学习者可以轻而易举地从互联网上获取到大量的学习资源, 然而网上冲浪式的学习随意性太强, 对于英语词汇学习来说, 学习者想要从网上海量的信息中萃取到既能保证不至于太难而可理解又不至于太易而能受益的学习资源并非易事.
本研究提出了一套以词频为基础的英语篇章标注机制, 实现对英语学习资源按词汇量进行分级, 并能够将网上的学习资源添加到系统资源库中. 其次就是针对英语学习者词汇掌握状况, 依据一定的规则从学习资源库中为学习者推荐匹配合适的学习资源, 让学习者学习的词汇在目标篇章中反复出现, 从而达到提高英语词汇学习效率的目的.
1 词汇学习管理机制的设计原理
1.1 词汇词频理论及词汇学习顺序
对于系统开发人员来说, 要实现对网络上各类学习资源的管理, 主要的问题在于缺乏一套对资源进行分门别类的“标准”. 对于词汇的学习来说, 词汇不仅是学习者的学习目标, 也是构成所有篇章的基本元素. 英语学习中, 我们通常先学会“people”这样的简单词汇, 后学会“largo”这样的难度大的单词, 其原因并非单词的形式或意义的差别. 对这种现象的解释, 目前国内外一致认同的理论是频率假设, 频率假设认为学习者词汇习得的先后顺序取决于词汇在语言输入中出现频率的高低, 即一般来说在语言输入中出现频率高的词汇学习者先习得[1], 这就是本机制所依赖的第一个基本理论——词汇频率假设理论[1].
随着计算机的发展, 国内外学者对英语中的常用词汇进行了词频数据统计, 其中最具代表性的就是Nation编制的词频表[2], 事实上此词表中单词“people” 在每百万词条中出现2828次, 而单词“largo”仅出现1次. 据此, 本机制首先提取Nation词频表中前1万个高频单词, 然后依次给词表中词汇按照频率从高到低标上序号, 这个序号在词汇学习系统中称之为“词频序数”, 学习者就按照这个序号循序渐进地进行单词学习.
1.2 词汇重复学习次数
研究表明学习者要完成对一个新单词的学习, 需要反复接触才能保证习得效果. 但这个次数是多少?Saragi,Nation & Meister (1978)发现6次接触是习得单词的起码次数; Nagy,Herman& Anderson(1985)计算出一次接触可能习得的机会是0.15, 即6~7次接触才习得这个词; Herman,Anderson,Pearson,&Nagy(1987)统计到需20次接触才习得这个词[3]. 基于此, 要让学习者习得一个词汇, 系统需要让每个单词在目标篇章中“反复出现”6至20次. 考虑到实际学习过程中, 并不能让多个单词的学习次数刚好同时达到20次, 所以在本机制中设计学习者和每个单词“见面”的次数为30次.
1.3 记忆黄金序列
根据艾宾浩斯学习遗忘曲线[4], 人类大脑对新事物的遗忘进程并不是均匀的, 遗忘的发展是“先快后慢”, 而且不同的学习者的遗忘速度也不尽相同, 如图1所示. 直观地讲就是记住一个新单词后, 20分钟后重复一遍, 3小时后再重复一遍, 1天后, 2天后, 5天后, 14天后, 1个月后, 3个月后再分别重复一遍, 最后才能牢牢记住这个单词. 因此系统安排学习者和单词“见面”应该遵照这样的时间序列, 其主要特征表现为时间间隔的不断延长, 这样的时间序列就是记忆黄金序列. 本机制中设计的记忆黄金序列的时间间隔公式为:
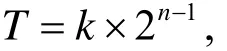
其中n为单词学习的次数1,2,3,…,k表示最小单位学习时间, 默认为1天.
学习过程中用户可以自行调整最小单位学习时间k的值, 如学习者每半天学习一次则设k=0.5天, 三天学习一次则设k=3天. 根据艾宾浩斯理论, 依照记忆黄金序列的学习保持水平如图1中“学习曲线”[5]所示.
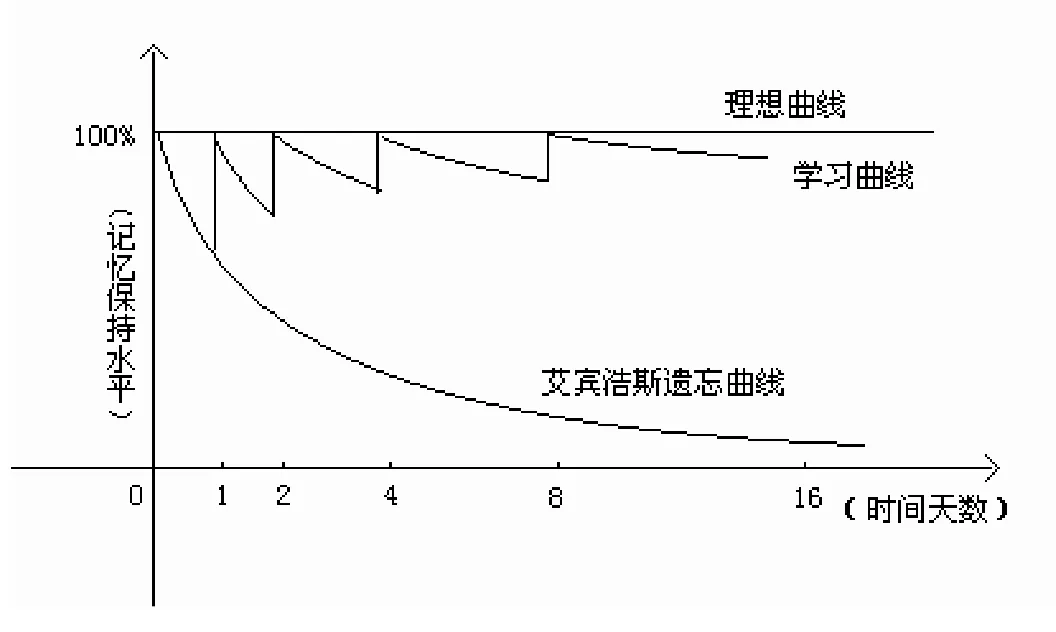
图1 艾宾浩斯遗忘曲线
2 词汇学习管理机制设计
2.1 英语篇章资源的分级和存储
英语学习系统的资源库模块主要实现对英语词汇学习资源的统一管理. 针对网上林林总总、各式各样的英语篇章, 如何划定英语篇章的“词汇级别”和“生词集合”是系统实现所面临的一个重要问题, 本研究按照克拉申输入假说[6]提取篇章中一定量的低频词作为英语篇章的“生词集”.
按照克拉申输入假说, 一篇文章对特定学习者来说含有5%~10%的生词能较好地满足克拉申“理想输入”条件, 也就是说对一个学习者来说, 通过对含有5%~10%的生词的文章进行学习能够达到最为理想的学习效果. 同时按照“频率假说”, 对一般的学习者来说, 篇章中的生词应大致为出现频率最低的那部分词汇, 因此提取篇章中相对最低频的5%~10%的词汇作为篇章的“生词集”可以较好解决此问题.
具体操作方法是: 将篇章输入Frequency[2]软件, 生成篇章所含的全部单词列表, 然后按照词频从 “低到高”进行排序(即按照词频序数逆序排列), 选择前n个(n为文章单词数乘以10%并取整)词汇即作为本篇资源的“生词”集合, 设标注的n个生词“词频序数”的算术平均数为m, 那么本篇章的词汇量级别L的计算公式为:
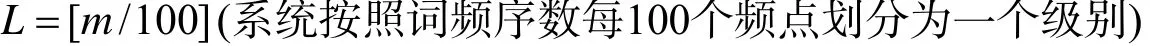
将此n个词汇连接成以逗号分割的字符串, 存储到资源数据表的“new_words”字段, 将资源的词汇量级别L存储到资源数据表的“word_level”字段.
2.2 学习者“词汇学习需求” 的描述
用户的词汇学习不仅要考虑对一个词汇按照黄金记忆序列进行多次学习, 同时为了保证学习的持续性, 还要考虑不断学习新词汇, 那么具体按什么规则来描述每次的“词汇学习需求”呢? 本机制中用集合A表示学习需求, 集合A包含的单词个数a由用户自行设定. 学习者已经掌握的词汇设为集合C(设集合C含有c个单词)则:
(1) 如果词汇数c小于a, 系统从用户词表中尚未学习的单词中依词频序数取出(a-c)个和集合C中没有交集的单词组成集合D, 合并集合C和集合D构成集合A, 即为当前的学习需求;
(2) 如果词汇数c大于a, 则依词频序数从集合C取前a个(频率较高的)词汇构成集合A, 即为当前的学习需求. 集合C中其它词汇的学习时间往后顺延一个单位学习时间.
2.3 学习需求和学习资源的匹配
为了便于说明, 设词汇学习需求的集合A(a=6)为: yard, poverty, compensation, magic, constantly, truly. 则本机制按照以下规则对学习需求和学习资源进行匹配:
(1) 首先在篇章资源库中搜索包含单词yard的篇章, 并将这些资源记录的匹配值置为1, 假设资源编号为1,3,6,10,15的英语篇章含有单词yard, 那么这些篇章学习资源的匹配值等于1;
(2) 同样对单词poverty进行操作: 如果序号为1,3,6,10的英语篇章含有单词poverty, 那么这些篇章学习资源的匹配值在原基础上自增1;
(3) 依次完成其余单词的匹配查询, 然后按照篇章学习资源匹配值从高到低将资源记录进行排序, 如序列为(括号内为篇章学习资源匹配值): 3(6), 10(5), 6(3), 1(1), 则将这些篇章学习资源依序推送给学习者.
2.4 学习信息的收集和反馈
用户发生学习后, 总共将产生三个词汇集合, 用户词汇表词汇集合(图2矩形所示部分)、学习篇章包含的生词集合E以及由学习者标注的未完成学习的生词集合B(即反馈信息的生词集合).
本机制通过比照生词集合B和篇章的生词集合E及“用户词汇表集合A”此三个词汇集合, 划分出三类学习结果如图2所示(图中1, 2, 3分别代表三种不同的学习结果).本机制分别针对每类学习结果执行不同的数据处理方式, 针对每类学习结果(图中1, 2, 3三个区域),分别执行操作如下:

图2 词汇学习结果分类图
(1) 对已掌握的词汇的操作:属于E, 但不属于B, 为学习者已经习得的词汇, 系统根据“词汇学习活动记录”的反馈信息在用户学习过程中添加这些词的学习行为记录, 并依据记忆黄金序列在学习者“词汇学习需求表”中设置该单词下次出现的时间;
(2) 对未掌握的词汇的操作: 属于B, 且属于“用户词汇表”的单词, 系统将这些词的学习记录清空,即认为学习者第一次 “接触”到该词, 并依据记忆黄金序列设置该单词下次出现的时间;
(3) 登记新遇到的生词: 属于B, 但不属于“用户词汇表”的单词, 系统将这些词新增到用户词汇表,并依据记忆黄金序列设置该单词下次呈现的时间.
3 应用系统实现的基本思路
本机制可以应用于个性化词汇学习系统的设计与实现. 通常个性化学习系统需要一个包含海量学习资源的学习资源库和一个能够个性化呈现学习资源, 并反馈有关学习结果信息的个人学习环境(PLE). 那么, 在资源库和学习环境之间需要一种算法完成资源的智能匹配和推送, 本研究的学习管理机制正是为了解决学习资源和学习者学习需求的智能匹配和自动推送的问题. 由于各类学习资源是一种无序和无法量化的劣构资源, 因此传统的教学领域只能依靠老师对学习资源进行人工遴选和推送, 而本机制创造性的利用词频序数对学习资源进行处理, 使得学习资源可以量化、排序和匹配.
3.1 系统总体架构
本研究的词汇学习管理机制, 根据软件工程有关理论及结构化程序设计的思想, 通过对应用系统的功能进行界定和划分, 形成系统总体架构(图3), 主要包括资源管理、学习管理和学习子系统三个部分.

图3 系统结构框图
1. 资源管理模块: 该模块主要实现对英语词汇学习资源的统一管理. 媒体开发人员、资源管理者、教学人员三方共同完成对互联网上各类相关学习资源进行推荐、遴选、入库的工作. 主要工作包括: ①由教学人员推荐、遴选适合词汇学习的相关资源; ②由媒体开发人员提取篇章中的低频词、词组,并标注这些词的详细释义; ③由资源管理人员负责对资源进行索引, 并将“词汇量级别”和篇章所包含的“生词”数据记录在资源库中相应的记录上.
2. 学习管理模块: 该模块主要实现学习资源匹配和推送. 学习者首先设定英语学习者初始学习目标、学习速度等参数, 形成初始的学习需求. 然后一方面系统根据学习需求从资源库匹配学习资源, 另一方面教学人员根据学生特点对资源进行推荐、筛选, 并形成资源推送列表. 学习者根据个人喜好选择一定的资源进入到学习状态. 一次学习活动完成后, 系统根据学习子系统提供的反馈信息, 分类处理学习结果, 更新学习状态参数, 并形成新的学习需求, 然后进入新一轮的学习循环.
3. 学习子系统: 该部分主要实现个性化学习环境, 一般为一个客户端学习软件或一个web用户界面,要能和总系统进行对话. 主要功能包括根据学习者个性特征构建特定的学习界面, 根据用户爱好个性化呈现系统匹配与推送的学习资源, 还具备收集有关学习评价信息的功能, 并能将信息反馈到总系统.
3.2 系统主要数据的存储结构
本系统中的学习资源管理、资源匹配、学习活动管理等功能的实现均离不开数据库的支持, 系统以SQL Server 2005为例, 用以说明数据库的数据表存储结构.
1. “学习资源(Resource) ”表
记录所有的学习资源, 每一个资源为一条记录行. 用于记录学习资源的链接地址、词汇量级别、包含的生词、单词匹配次数等信息. 数据字段及数据类型为: id(int),resource_url(varchar(50)), word_level(int), new_words(ntext), matched_times(int).
2. “用户词汇(User_Vocabulary) ”表
记录用户词汇学习目标的总表, 每行记录一个单词. 记录的信息包括词频序数、单词、该单词已学习次数(默认为0表示未曾学习过)、下次学习时间、单词的30次学习活动记录id(该字段受“学习活动(User_Action) ”表中id字段的外键约束). 数据字段及数据类型为:id(int), word(varchar(50)), learned_ times(int), next_time(datetime), action01(int), action02(int), action03(int)……action30(int).
3. “学习活动(User_Action) ”表
记录每次学习活动中学习的单词、单词出处、学习时间等用户学习的详细信息, 具体包括编号、单词、短语搭配、资源编号、学习时间等信息. 数据字段及数据类型为: id(int), word(varchar(50)), phrase(varchar(MAX), resource_id(int), time(datetime).
4 结语
本文通过引入英语语言学的有关理论成果, 从教育技术与学科整合的视角出发, 运用软件工程的思想方法完成了基于词频理论的英语词汇学习管理机制的构建, 主要论述了篇章学习资源的入库管理、资源的动态匹配、学习反馈等系统基本功能的设计、实现方法.
本研究的主要创新和突破点有:
1. 词汇自然习得顺序: 以词频理论为基础, 打破了按照字母顺序记单词的常规做法, 创造性地按照词汇词频从高到低的顺序让学习者在篇章阅读中习得词汇.
2. 劣构资源管理: 基于词频理论, 本研究提出以篇章中的低频词汇作为篇章的生词集, 按照这个标准, 就可以对网上五花八门的(劣构的)文字材料划分统一级别、实现入库管理.
3. 个性化动态推送: 本机制对学习需求进行了描述, 提出了篇章自动匹配规则, 实现了学习资源的个性化推送; 据系统提供的反馈信息, 可以动态地调整学习内容和学习速度.
本文所述词汇学习管理机制可以直接套用到其它语言学习上, 为语言学习系统的研制提供参考.
[1] 张 伟. 输入频率对二语词汇习得的影响[D]. 南京: 南京师范大学硕士学位论文, 2007
[2] Paul Nation.Resources of Range and Frequency Programs[EB/OL]. http://www.victoria.ac.nz/lals/staff/paul-nation.aspx.2010.
[3] 许 洪, 武 卫. 通过阅读附带学习英语词汇的实证研究[J]. 外国语言文学, 2007, (2)
[4] 百度百科. 艾宾浩斯遗忘曲线[EB/OL]. http://baike.baidu.com/view/931396.htm?fr=ala0_1#1.
[5] 马德高. 全新英语专业四级词汇周计划[M]. 长春: 吉林出版社集团, 外国教育出版公司, 2010
[6] Krashen S. The input hypothesis: issues and implications [M]. New York: Longman,1985
The Research of Word-Frequency-Based English Vocabulary Learning Management Mechanism
SUN Feng-hua, LIU Yong-hui, LI Ling, XIE Hong-xiu
(Information Center, Hunan Institute of Science and Technology, Yueyang 414006, China)
Based on the theory of Word-Frequency, a mechanism of English vocabulary learning management is designed in this paper. The mechanism is to realize the hierarchical management of English learning resources on the Internet, and match texts to assure that these resources can be met individual demand of vocabulary learners according to certain strategies. The mechanism will be to promote efficiency of English vocabulary learning by increasing the frequency that the new words appear in discourse. The mechanism can provide a theoretical basis for the research and development of English vocabulary learning system.
word frequency; vocabulary learning; management of learning
TP312
: A
: 1672-5298(2015)04-0052-05
2015-10-03
湖南理工理工学院校级科研项目(2015Y01); 湖南省教改项目:基于应用型人才培养的大学英语翻译教学信息化的实证研究(湘教通[2015]291号文件)
孙风华(1981− ), 男, 湖南邵阳人, 硕士, 湖南理工学院信息中心讲师. 主要研究方向: 数字化学习
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
新世纪智能(英语备考)(2021年3期)2021-05-21 02:12:50
信息记录材料(2016年4期)2016-03-11 15:22:49
人间(2015年10期)2016-01-09 13:12:54
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
散文百家(2014年11期)2014-08-21 07:16:56
图书馆论坛(2014年8期)2014-03-11 18:47:59
双语时代(2009年10期)2009-11-11 09:17:20
双语时代(2009年8期)2009-09-24 08:51:14
