
一种基于SQL的用户自定义精度的粗糙集属性约简算法
2015-05-30 10:48马凌喻幸
科技创新与应用 2015年16期
关键词:粗糙集
马凌 喻幸

摘 要:将数据库的关系运算运用于粗糙集的属性约简,引入用户自定义精度,改进基于SQL的属性约简算法。仿真实验结果表明,该方法与经典粗糙集相关方法相比,有更高的执行效率和抗噪性,为粗糙集理论更广泛地应用于海量数据的数据挖掘提供了一种方法。
关键词:粗糙集;SQL语言;属性约简
数据库系统具有存储空间利用率高、存取效率高等优点,如果将粗糙集理论中的决策表以关系数据库二维表的形式表示,通过将粗糙集理论中的相关算法嵌入到数据库管理系统中,实现对属性约简算法的改进。在标准SQL语言中,GROUP BY子句可将数据库中二维表的数据按某一列或多列的取值进行分组,值相等的为一组,该操作可对应粗糙集理论中划分等价类。而聚集函数COUNT(*)可统计每组所包含的记录个数,即为粗糙集理论中等价类所包含的对象数目。基于SQL的属性约简算法已有部分学者进行了研究。冯林和李天瑞[1]提出了用SQL语句求数据库中相对核属性、属性约简和值核的算法。田迪和刘建平[2]提出了基于SQL语言的条件信息熵属性约简算法。刘井莲[3]给出了一种基于SQL的屬性约简算法,该算法是从条件属性集做递减,不需要存储中间结果,具有空间复杂度低的优点,同时易于改造成并行算法,能求出所有约简。但该算法缺乏对噪音数据的适应能力,不适应高速公路管理系统中海量数据的数据分析。下面将在讨论这种算法的基础上,提出一种由用户自定义精确度的基于SQL的属性约简算法。
1 理论基础
定义1:一个信息表的知识表达系统可以表示为四元组S=
如果U为一个论域,P为U上的一个属性集合,r∈P,且ind(P-r)=ind(P),则称属性r在P中是不必要的;否则,称r在P中是必要的。去掉不必要的属性不会改变属性集合的分类能力;反之,若去掉一个必要的属性,则一定会改变属性集合的分类能力。
定义2:设U为一个论域,P、Q为U上的两个属性集合,且Q为P的子集,若ind(Q)=ind(P)且Q中没有不必要的属性;则称Q是P的一个约简。如果Q是P的约简,则U中通过P可区分的对象,同样可以用Q来区分。通常P的简化不止一个,P的所有简化族记为RED(P)。
2 属性约简算法
算法1:判断ai是否为符合用户自定义精确度的不必要属性算法
输入:信息系统S=(U,A), accurate,ai。其中,accurate为用户输入的精确度,ai为需要判断的属性。
输出:1(表示该属性为不必要属性)或者0(表示该属性为必要属性)
Step 1:统计S中根据A-{ai}分组后,每组包含的记录个数,生成新表temp。方法如下:
SELECT COUNT( DISTINCT ai) AS NUM
into temp
FROM S
GROUP BY A-{ai}
Step 2:统计表temp中数值为1的记录个数占记录总数的比例Confidence。方法如下:
DECLARE @Confidence decimal(3,2),@ConCount int,@TotalCount int
SELECT @TotalCount=COUNT(*)
FROM temp
SELECT @ConCount=COUNT(*)
FROM temp
WHERE NUM=1
SELECT @ConCount
SET @Confidence=cast(@ConCount as decimal(3,2))/@TotalCount
SELECT @Confidence
Step 3:若Confidence>accurate,输出1,否则,输出0。
由算法1可判断出ai是否为符合用户自定义精确度的不必要属性。如果ai为不必要属性,则继续从A-{ai}中寻找不必要属性,最终得到约简属性集。
算法2 基于SQL的用户自定义精确度的属性约简算法
输入:信息系统S=(U,A), accurate。其中,A=a1,a2,…,an为属性集,accurate为用户输入的精确度。
输出:A所有的属性约简。
Step 1:设初始约简的集合为red=?覬,flag=0;
Step 2:如果i<=n,则根据算法4.3判断ai是否为符合用户自定义精确度的不必要属性。若算法4.3输出1,则flag=1,转到Step 4,若i>n,转Step 5;
Step 3:i=i+1,转到Step 2;
Step 4:A=A-{ai},n=n-1,转Step 2;
Step 5:若flag的值为0,则属性集A为属性约简,将其加入集合red,结束。
3 算法对比
下面通过一个例子来说明文献[4]给出算法的局限性,以及文章提出的用户自定义精确度基于SQL的属性约简算法的有效性。设S=(U,A),其中U={U1,U2,U3,U4,U5,U6,U7,U8},属性集A={a1,a2,a3,a4}。信息系统见表l。
表1 一个信息系统S
根据文献[4]给出的算法,分别计算IsUnnecessary(a2,a3,a4,a1)、IsUnnecessary(a1,a3,a4,a2)、IsUnnecessary(a1,a2,a4,a3)、IsUnnecessary(a1,a2,a3,a4)均得到的结果为false,即所有属性均为必要属性无法实现属性约简。而采用算法2,设用户输入的精度为0.85。运算过程如下:
(1)先根据算法1,计算属性a1的Confidence。
Confidence=0.86>0.85
则属性a1为不必要属性。
(2)根据算法4.3,计算属性a2在属性集A={a2,a3,a4}中的Confidence。
Confidence=0.5<0.85
则属性a2为必要属性。
(3)根据算法4.3,计算属性a3在属性集A={a2,a3,a4}中的Confidence。
Confidence=0.6<0.85
则属性a3为必要属性。
(4)根据算法4.3,计算属性a4在属性集A={a2,a3,a4}中的Confidence。
Confidence=0.25<0.85
则属性a3为必要属性。
(5)通过以上计算,可得到{a2,a3,a4}为该信息系统的一个约简,同理,可得到{a1,a3,a4}也为信息系统的一个约简。
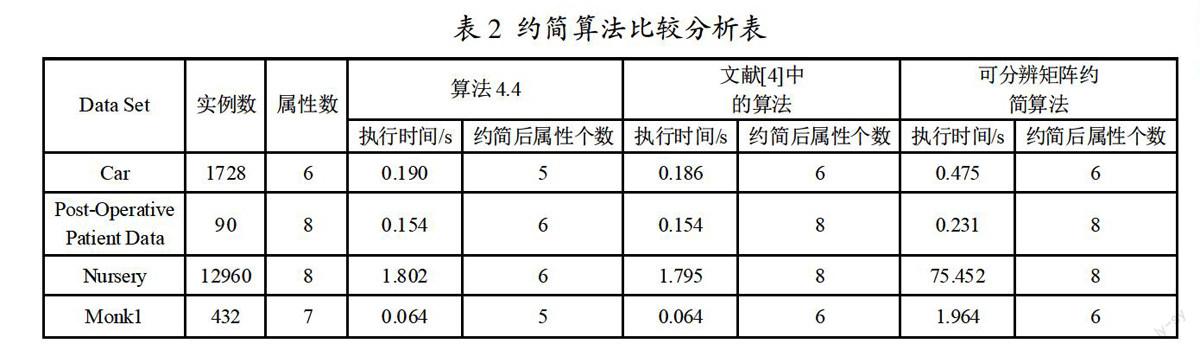
为了验证算法2的有效性,文章从UCI数据集中挑选了4组数据,并和文献[4]给出的算法以及经典的可分辨矩阵约简算法进行了比较,实验环境使用的是Windows 7家庭普通版,CPU双核 1.33GHz,RAM 2.00GB,Java编程,SQL Server 2005为后台数据库。用户自定义精度为0.85,实验结果见表2。
由以上实验结果数据可以看出,算法2比文献[4]中的算法能够更好的进行属性约简,约简后属性的个数更少,适用于海量数据的属性约简。由于算法2需要计算精度,所以相比之下执行时间要长一点。算法2与可分辨矩阵约简算法相比在效率方面具有明显的优势。
4 结束语
文章研究了基于SQL的属性约简算法,发现了算法中存在的问题,提出一种由用户自定义精度的基于SQL的属性约简算法,并通过实验证明该算法的有效性,为海量数据的数据挖掘提供了新的途径。
参考文献
[1]吴学辉.基于粗糙集的决策树算法在高校评教中的应用[D].太原:太原理工大学,2011.
[2]冯林,李天瑞.基于SQL的属性核与约简高效计算方法[J].计算机科学,2010,37(1):236-238.
[3]田迪,劉建平.基于SQL的属性约简算法的改进[J].工业控制计算机,2011,24(6):93-94.
[4]刘井莲.一种基于SQL的属性约简算法[J].科学技术与工程,2010,10(25):6291-6292.
作者简介:马凌(1981-),女,硕士,讲师,主要研究领域为数据挖掘。
喻幸(1981-),男,硕士,主要研究领域为计算机应用技术。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
西南大学学报(自然科学版)(2021年10期)2021-10-21
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
测控技术(2018年11期)2018-12-07
系统管理学报(2018年3期)2018-08-13
成都信息工程大学学报(2017年6期)2017-03-16
厦门大学学报(自然科学版)(2016年6期)2016-12-07
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
