
基于Hadoop分布式缓存的研究与实践
2015-05-30 20:22梁晓杰王绍宇
智能计算机与应用 2015年6期
关键词:分布式
梁晓杰 王绍宇
摘 要 在大规模离线数据的分析场景中,由于元数据库被频繁访问造成的性能瓶颈导致集群计算速度急剧下降。典型的Hadoop平台多基于磁盘进行数据读写,磁盘的读写速度又明显不如内存。针对这种情况,本文基于Hadoop平台,结合对其他分布式缓存的研究,提出了一种新的分布式缓存技术来加快数据的计算速度,从而提高数据的计算时效性。实验结果表明应用于Hadoop的MMap内存模型能极大提升了集群的计算速度。该模型能有效将文件映射到内存区域,减少内核与用户空间来回拷贝数据,同时数据异步式追加方式不会阻塞计算进程,能有效提升集群整体的计算能力。
关键词 Hadoop;分布式;缓存
中图分类号: TP392 文献标识码 A
Abstract In the scene of large-scale offline data analysis, some performance bottlenecks caused by frequent access to the metadata database make a sharp decline in the calculation of the cluster. Typical Hadoop platform is based on disk read and write, while the disk read and write speed is obviously slower than memory. In view of this, based on the Hadoop platform and the research of other distributed caches, this paper presents a new set of distributed cache technology to speed up the data computations, then also to improve the date timeliness. Experimental results show that the MMap memory model applied to Hadoop could greatly improve the computation of the cluster. This model could map the file to the memory area effectively, reduce the kernel and user space to copy data, and the asynchronous type of data append will not block the process, which can effectively improve the computing power of the whole cluster.
Keywords Hadoop ; Distributed ; Cache
0 引 言
国内互联网化的重心从个人扩展到企业与组织,进而推动了企业级“大数据”时代的到来。大规模数据分析无疑成为大数据时代的主要技术挑战之一,不仅表现在传统的企业结构化数据会伴随着时间的变迁而日趋膨胀,而且现代新型电子设备产生的非结构化也将对企业的数据中心基础建设造成巨大的压力。因此大规模数据的计算一方面即对单机服务器的CPU主频、内存容量和I/O吞吐量提出严苛要求,另一方面则对服务器集群在能够存储海量数据的基础上仍要兼具高速计算的能力也表现出了迫切需要。从目前发展趋势看,不出五年内,年产值在上亿元的企业,其数据量的规模必将达到千亿行级。现举一生产中的实例,某快递集团日均订单量是百万级,在站点之间物件的运转即会产生千万级运单,同时也将带来上亿次计费。Hadoop最初是由Doug Cutting受Google公司发表三篇分布式论文的启示而开发面世的分布式系统基础架构。Hadoop框架最核心的设计就是:HDFS和MapReduce[1]。其中,HDFS能部署在廉价的机器集群上,为海量数据提供存储的同时还有效地降低了成本。而MapReduce则借用函数式编程语言的思想,并适用于大规模数据集的并行计算。但是Hadoop早期的设计就是基于多磁盘读写,甚至连一些中间计算结果也要存放在磁盘中。实际上Hadoop平台已经整合有一个分布式缓存工具,名为Hadoop DistributedCache。在节点上执行任一任务之前,DistributedCache都将拷贝缓存的文件到Slave节点。不过这个工具的功能略显低弱,不能用于大规模数据缓存。本文将介绍Hadoop DistributedCache的主要工作原理以及其自身设计上的缺点,然后结合对其他分布式缓存的研究,最后提出一套适用于大规模离线数据分析的分布式缓存技术。
1 相关工作
全峰快递集团有这样一个生产系统,每个月数据库系统会对数据表进行分区,分区名是按照“年份-月份”来相应命名,每个分区表的记录总行数即超过亿级,而由于数据量规模迹近庞大,仅是一次简单的汇总查询(比如查询集团运单月额度),程序就可能需要运行十几分钟才能得到结果。由此可知,簡单查询都要经历长时间的等待,那么稍微复杂查询就可能得不到想要的结果。例如,如果想看到季度的数据统计情况,那就需要重新完成表间合并,也就是将三个数据量非常庞大的月份表顺次查询后得到的数据汇聚到一起。
这个过程需要人工执行命令来开展与完成,可见其中的出错率将会极高。面对大数据的挑战,传统的RDBMS无法胜任大数据分析任务[2]。综上所述,笔者针对这一数据分析系统的现状而提出了在原来数据库应用系统的基础上设计一套数据仓库的解决方案。具体方法是将数据库生产系统的数据进行数据预处理从而分离出来,即ETL[3]。在ETL过程进行的时候,不能过度消耗在线生产数据库的资源。在ETL过程结束之后,必须对数据仓库的数据进行沉淀提炼,建立多维度雪花模型以支持上层应用的快速查询。比如说,生产数据库中存储的是每个快递运单的详细记录,但是数据仓库并不关心详细记录,而是希望能快速查询到所有记录的统计量,例如每天省份之间的运单总量以及运单总金额。在以前的生产数据库中多是用简单的求和函数sum来实现这个需求,但是由于数据量规模太大,一个简单的求和函数运算可能需要十几分钟才能得出结果,并且结果也不能获得有效缓存。所以建立数据仓库是进行大规模数据集计算的基础前提条件。
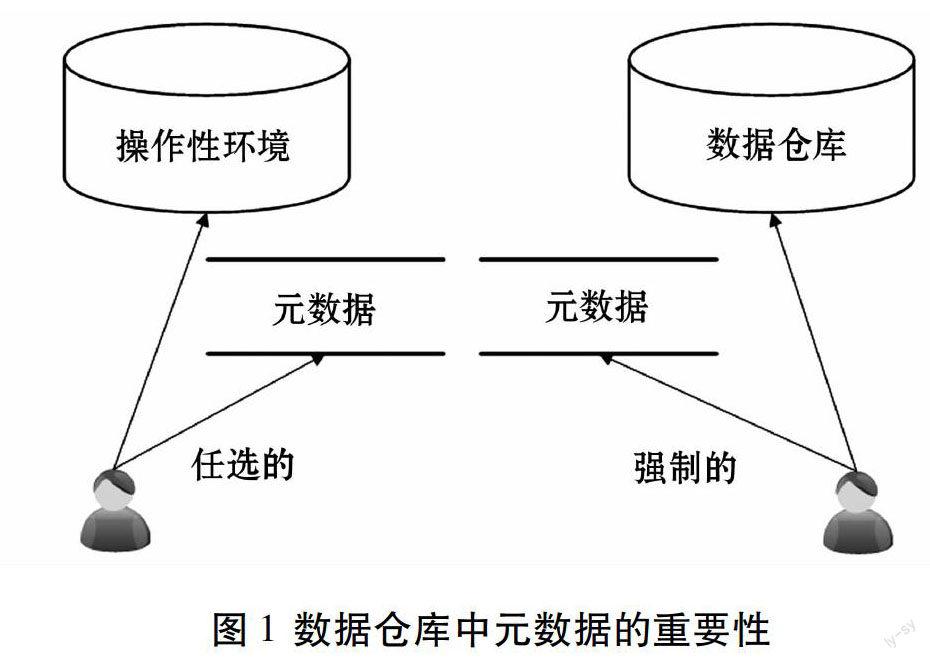
数据仓库中重要一步,就是在OLAP服务器上建立元数据数据库。元数据库和以前所说的数据库不同,主要用于存放元数据,元数据库有很多呈现方式,可以把维度表当成一种元数据。而在典型的hadoop平台上,Master节点的NameNode就是存储元数据的中心地带,JobTracker在进行节点分配计算时,会先从NameNode读取元数据,这些元数据就记录了各个DataNode的实际情况,然后通知TaskTracker去主动联系各个DataNode以读取具体的数据。操作性环境与分析性环境元数据的区别如图1所示[4]。
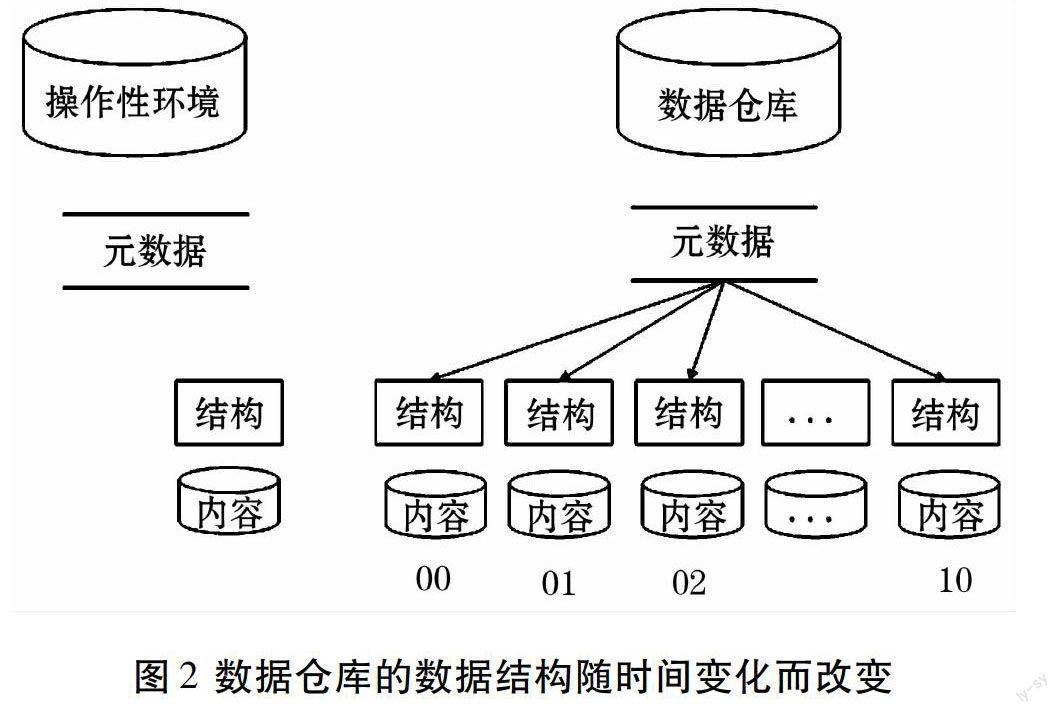
在操作性环境的任何时刻,对数据结构都有且仅有一个正确的定义。但是在数据仓库中,存于此环境中的数据会存在很长一段时间,所以数据结构将发生经常性改变。因此即须管理多种数据结构的定义,而这些变化的数据结构定义将主要由元数据库来维护。如图2所示[4]。近年来关于Hadoop的研究成果大多集中在对Hadoop平台的性能改进上[5],其中频繁提到的就是通过优化HDFS来提高存储性能以及改进算法来提升MR计算性能,这其中都涉及到了元数据的处理,但是却极少突显元数据的重要性。
由上述两点可见,关于元数据的操作横跨整个数据仓库建仓过程,既然元数据在数据仓库中连续访问具有普遍高发性质,所以对连续数据进行有效的存储就成为一个至关重要的因素。而Hadoop平台虽然支持大规模并行计算,但其设计的理念却是基于磁盘IO读写数据。一旦把元数据的块结构放到内存中,那么存储块的所有行则只需要电子时间就能被访问到。
HDCache[6]在HDFS之上设计并实现了一套分布式缓存系统。FlatLFS[7]也研究并开发了一个采用扁平式数据存储方法的轻量级文件系统。不过本文面向的却并非HDFS,而是基于元数据以及中间计算结果的分布式缓存。在计算过程中,计算源数据还是取自HDFS。
2 Hadoop分布式缓存的弊端
Hadoop分布式缓存(DistributedCache)是Hadoop平台内置的一个工具,支持若干文件类型。该工具假设所指定的文件已经存储在HDFS上,并且可被集群中任何机器正常访问得到。Hadoop框架会在TaskTracker节点开始执行任务之前,JobTracker就把所指定的缓存文件复制到该任务节点。在分发了缓存文件之后,TaskTracker会为缓存中的每个文件维护一个计数器。计数器记录着文件被同时使用的任务个数,如果计数器值为0,表明该文件可以从缓存中删除。
显而易见,内置的分布式缓存工具只适用于数据量较小的情况,最常用的场景就是JobTracker到TaskTracker的代碼分发共享。迄至目前,内置的分布式缓存却仍无法解决由于大规模数据量带来的以下问题:
(1)网络资源问题。JobTracker在启动TaskTracker之前,会先从JobTracker分发缓存块到TackTracker。一旦缓存块过大,那么不仅对JobTracker节点造成极大的分发压力,还将严重消耗整个计算集群的网络资源。
(2)缓存共享问题。只要机器的CPU核心数量充足,单机可以运行多个TaskTracker进程。但是基于分布式缓存的进程独占性,所以同一台机器上的TaskTracker不能共享同一份缓存。并且,一般情况下OLAP型分析数据多是只读而不改的,所以一台机器将用多个内存块来分别存储同一份数据,从而形成对集群内存资源的浪费。
3 最优分布式缓存解决方案
常见的开源分布式缓存方案有:Memcache、Redis、Tokyo Cabinet等。其中,Memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick具体实施开发[8]。Redis是一个key-value存储系统[9],和Memcache类似,它支持更多的value类型。
虽然Memcache 与 Redis 在OLTP领域已经有过多个成功的使用案例,但是Memcache与Redis的设计理念却大都面向在线多用户高并发。在OLAP领域,涉及的场景一般是高密度计算类型,所以不要试图将OTAP的一些开源方案应用到OLAP领域。假设每行数据分析都要调用一次http请求去获取数据,那么究其实质,Memcache或者Redis都没有解决上文提到的网络资源问题,却在另一方面增加了网络负担。此时,最优的解决方案就是使用嵌入式读、异步式日志追加的分布式缓存。基于此,Tokyo Cabinet将是一个不错的实现[10],并且还能支持多进程读。另外,其中的网络组件Tokyo Tyrant[11]恰能解决异步增量日志问题,异步增量日志不会给网络带来太大的消耗,因为每台独立机器上都会保留一份数据的拷贝副本。
更进一步地,Hadoop只是需要与Tokyo Cabinet类似的嵌入式多进程读功能,却无需为了加快集群计算速度而引进可能带着不确定因素的组件。其实在Linux环境下,基于MMap机制的共享缓存就是一个有效的解决方案。Linux下常规的文件读写是通过read()跟write()函数实现的、read()接收三个参数:文件fd,读取内容长度count以及内存地址buf,write()函数也与其形式相似。而MMap直接映射文件到进程,用户空间运行的程序就可以通过这段虚拟地址来读写文件,而不再调用read/write函数。
研究知道在Linux内核中,MMap方式与read/write方式访问文件,都必须经过两个缓存:一个是page cache缓存,另一个是buffer cache。MMap更为快速的原因在于其避开了内核与用户空间的数据拷贝。因为read/write方式的基本数据流向是:用户空间先向内核请求内容大小,内核从文件加载内容到缓冲块,再从缓冲块输出至用户空间;写过程也是同一模式。而MMap的数据流向是:用户空间直接读取文件内容,数据不经过内核缓存块。经此理论分析即可得出,MMap读写文件具有明显优势。
4 实验
本文实验使用Dell PowerEdge R910服务器,操作系统是64位的SUSE Linux Enterprise Server 11,Java1.7,Hadoop版本1.2.1,Hive[12]版本0.13.1。数据样本采用的是IBM股票从1991-11-16起到2014-12-31的数据,样本可以用雅虎官网下载得到。
4.1 实验1
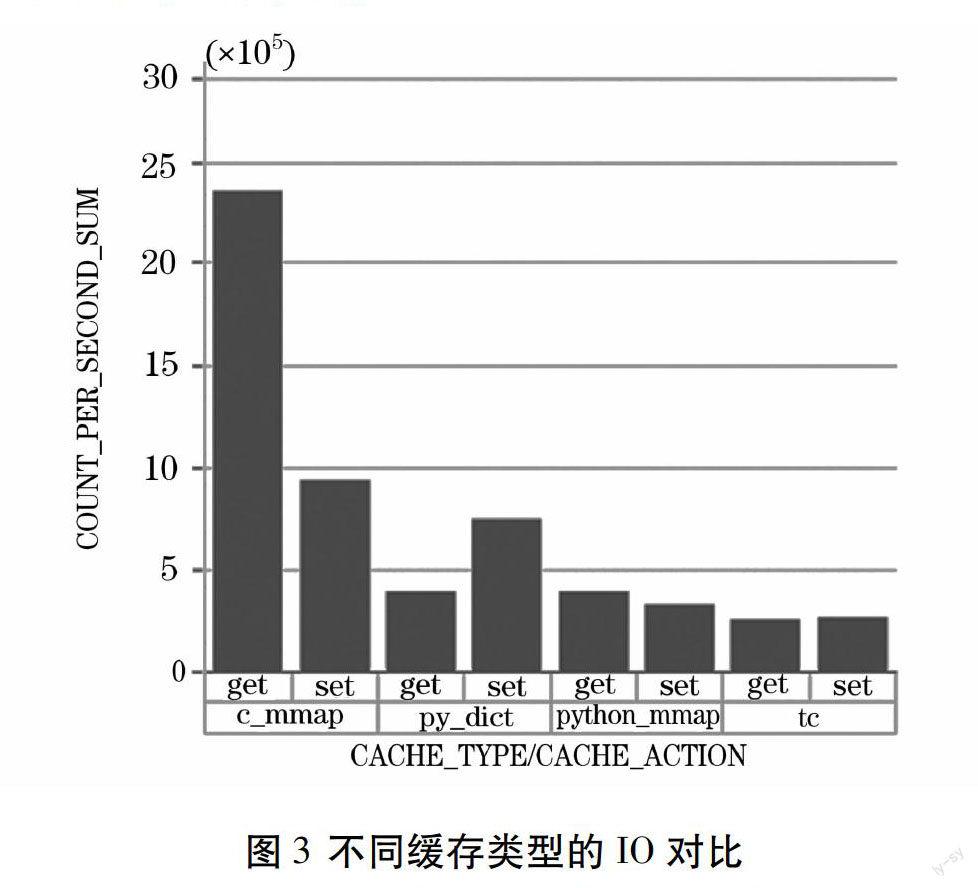
以键值对的形式单线程加载数据,Key的数据长度是1KB,Value的数据长度是4~100KB不等,再用单线程读取缓存中数据。缓存测试指标如表1所示,实验结果如图3所示。
通过图3,可得出以下三个重要结论:
(1)MMap读和写方面都要优于Tokyo Cabinet。
(2)py_dict可视为Hadoop分布式缓存的内置实现,和py_mmap在读方面的性能未见明显差异。另外,py_mmap还可支持多进程读。
(3)在写方面,py_dict优于py_mmap,但是由于py_dict是全缓存替换,而py_mmap只是增量缓存替换,所以实际生产中效率差距并不明显。
4.2 实验2
数据异步式追加主要是通过网络流实现,每条记录key长度是16字节,value长度是100字节[13]。网络吞吐量测试指标如表2所示,实验结果如图4所示。
LMDB是基于MMap实现的一个数据存储引擎,其他四种数据存储引擎都是基于文件存储。通过图4,可得出以下兩个结论:
(1)数据存储引擎在写方面性能相近,只显轻微变化。
(2)基于MMap实现的LMDB在读方面性能要远远优于其他存储引擎。
5 结束语
本文针对分布式缓存技术在Hadoop平台上的实现进行分析与研究。通过研究发现,基于MMap的嵌入式读取、异步式追加的分布式内存模型相比多数分布式缓存模型都具有显著优势,尤其是在处理大规模数据的时候。为此,在深入理解MMap的原理与实现的基础上,本文阐述了MMap分布式缓存模型的简单实现,还对其进行了性能方面的测试。实验结果表明应用于Hadoop的MMap内存模型能极大提升集群的计算速度,这也为今后在Hadoop分布式平台上解决内存问题提供了一个全新的思路。
参 考 文 献
[1] 吴晓婷,刘学超.浅谈Hadoop云计算的认识[J].无线互联科技,2012,(8):45.
[2] 覃雄派,王会举,杜小勇,等.大数据分析——RDMBS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[3] Ferguson M. Offloading and Accelerating Data Warehouse ETL Processing using Hadoop[R]. Wilmslow, UK: Report of Intelligent Business Strategies, 2013.
[4] William H. Inmon. Building the Data Warehouse[M]. Fourth Edition. New York: Wiley Computer Publishing, 2005
[5] 孟小峰,慈祥.大数据管理:概念、 技术与挑战[J].计算机学报,2013,50(1):146-149.
[6] ZHANG Jing, WU Gongqing, HU Xuegang, et al. A distributed cache for Hadoop distributed file system in real-time cloud services, Grid Computing(GRID)[J].ACM/IEEE 13th International Conference, 2012,45(1):12-21
[7] 付松龄,廖湘科,黄辰林,等.FlatLFS:一种面向海量小文件处理优化的轻量级文件系统[J].国防科技大学学报,2013,35(2):120-126.
[8] NISHTALA R, FUGAL H, GRIMM S, et al. Scaling memcache at facebook[C]//Proc of the 10th USENIX Conference on Networked Systems Design and Implementation, Berkeley:USENIX Association, 2013:385-398.
[9] 曾超宇,李金香.Redis在高速缓存系统中的应用[J].微型机与应用,2013,12:11-13.
[10] Tokyo Cabinet: a modern implementation of DBM[EB/OL]. [2015-09-08] http://fallabs.com/tokyocabinet/
[11] Tokyo Tyrant: network interface of Tokyo Cabinet[EB/OL]. [2015-09-08] http://fallabs.com/tokyotyrant/
[12] The Apache Hive[EB/OL]. [2015-09-08] http://hive.apache.org/
[13] In-Memory Microbenchmark[EB/OL].[2015-09-08] http://symas.com/mdb/inmem/
猜你喜欢
能源(2017年7期)2018-01-19
能源(2017年10期)2017-12-20
制导与引信(2017年3期)2017-11-02
能源(2017年5期)2017-07-06
自动化博览(2014年12期)2014-02-28
汽车电器(2014年5期)2014-02-28
