
数据清洗中重复记录清洗算法的研究
2015-05-30 02:05谢文阁等
软件工程 2015年9期
谢文阁等
摘 要:介绍了数据清洗中的SNM算法和全文索引技术,通过引入全文索引技术对SNM算法进行了改进,以此提高了重复记录查找的速度和准确率,从而较好地提升了SNM算法的性能。
关键词:数据清洗;全文索引;重复记录;清洗算法
中图分类号: TM399 文献标识码:A
1 引言(Introduction)
数据清洗(Data Clean)就是将错误的、不一致的、冗余的数据在装入数据仓库之前进行删除或修正,从而保证决策分析时数据的正确性.其主要工作就是从原始数据中检测错误和冲突的数据并消除的过程[1]。此项工作中检查并清除重复记录数据是数据清洗要解决的重要问题之一。重复记录就是指现实世界中同一个实体的不同数据记录,由于表述方式不同或者是因为拼写不同等使得DBMS不能识别它们为重复记录。如果这些记录不去掉,有可能导致数据模型建立的不准确,从而影响以后的数据决策分析。所以,在数据清洗中,检测并清除掉重复记录是非常重要的。
近邻排序算法(Sorted-Neighborhood Method, SNM)是数据清洗过程中的经典算法,而SNM算法却需要对数据集进行先期的排序[2],全文索引是一种特殊的基于标记的功能性索引,两者结合,可以在提高排序速度的同时有效的消除重复记录。
2 SNM算法(SNM algorithm )
SNM算法是当前比较流行的一类匹配与合并算法,而且该算法目前已被一些数据清洗工具所采用。目前采用比较普遍的方法是基于近邻排序算法[3],它的设计步骤可以分为下面三步:
(1)创建排序关键字,即从数据集中抽取记录属性中的一个属性值或者是子集序列的字串作为关键字,为数据记录集中每一条记录计算出关键字的键值。
(2)排序。根据该排序关键字对整个数据记录集进行排序。排序中应尽可能地使可能的重复记录排列到一个邻近的区域内,使得特定的记录可以将进行记录匹配的对象调整到在一定的范围之内。
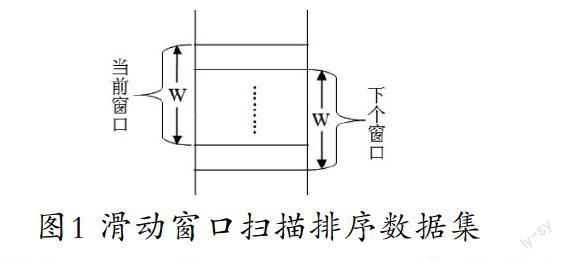
(3)重复检测。排序后,就可以在排序后的数据记录集上滑动固定大小的窗口,滑动时,最先进入窗口内的记录将滑出窗口,最后一条记录的下一条记录将移入窗口,数据记录集中新进入的记录与窗口内的记录进行比较。如果窗口的大小为W条记录,则每条新进入到窗口内的记录就要与先前进入窗口的W-1条记录进行逐一比较,以此来检测重复记录,如不重复,则把此信进入的第W条记录作为下一轮比较对象,以此类推,直到完成所有记录集中记录得比较,如图1所示。
SNM算法采用的滑动窗口比较检测重复记录的方法,每次只比较窗口中的W条记录,采用滑动窗口提高了比较速度,从而有效地提高了匹配效率。但SNM算法也存在一些不足:(1)对排序关键字的依赖性较大。SNM算法检测重复记录的精度某种程度上受到创建的排序关键字的限制,关键字的好坏直接影响了匹配的效率和精度。而且关键字的选取还依赖于应用领域。当选取关键字不当时,就有可能使得本来是重复记录的两条记录在排序后物理位置相距较远,可能永远不会同时位于同一个滑动窗口内,也就不能被识别出是重复记录,即在重复检测时会漏掉很多重复记录。(2)滑动窗口的大小W的选取也不好选择。W较大时比较次数会增多,而有些比较是没有必要的;当W较小时可能又会遗漏匹配;如果记录中各种重复记录聚类差别较大时,W的选取无论是大还是小又都不恰当。
3 全文索引(Full-text index)
所谓全文索引,就是面向全文并提供全文信息的检索技术,它不需要对信息进行标引就可以完成检索,它采取将原文中有意义的字或者词作为检索内容,由其指向原文有关页面或进行链接[4]。基于这种词索引的全文检索主要有以下几步:首先进行汉语自动分词,其次对文档中有意义的词进行倒排索引,在检索时将通过用户输入的检索条件按照匹配机制与词索引库中的信息进行匹配,最后将检索结果返回给用户。
全文索引与普通索引不同之处在于普通索引采取B-tree的结构进行维护,而全文索引是基于标记的功能性索引,由Microsoft SQL Server全文引擎服务创建并维护。全文索引可以快速、灵活地为存储在SQL Server数据库中的文本数据机建立面向关键字查询的索引,它与like语句不同之处是like语句的搜索主要适合字符模式的查询,而全文索引是针对语言的搜索,它根据语言的规则对词和短语进行搜索。所以,在对大量的数据进行查询时,全文索引可以提高查询的性能,对于上百万条记录的数据进行like查询需要几分钟才能得到结果,而全文索引只需几秒钟甚至更少的时间就可以得到结果。
4 重复记录清洗算法的研究(Research of duplicate
records cleaning algorithm)
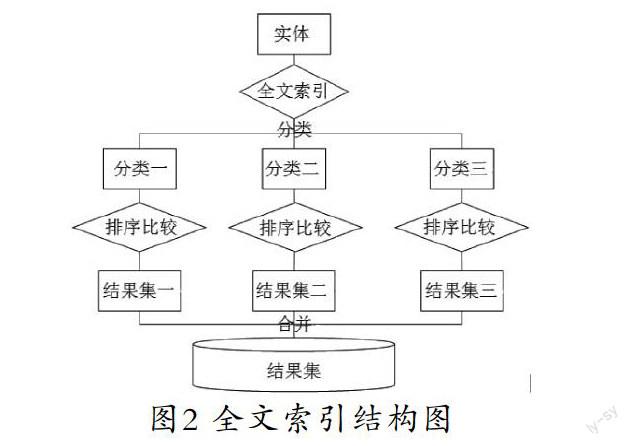
根据前面SNM算法的分析,知道它存在的缺点,就此引入全文索引技术,将全文索引技术与传统的SNM算法相结合,形成一种新的重复记录清洗算法。它的设计思想就是在排序过程中,结合汉语检索方法引入全文索引技术,以此来弥补SNM算法的不足,从而提高排序速度,同时全文索引技术还可以有效的使得重复记录尽可能出现在同一个滑动窗口中,减少重复记录检测的失误,提高检测效率。在进行两条记录的相似度匹配时,还根据元组各不同字段的重视程度的不同设置不同的权值,再与比较相似度阈值进行比较,决定两条记录是否是重复记录。设计思想的具体工作流程请见如图2所示。
基于全文索引的SNM算法中主要功能的伪代码如下:
//检索之前对数据集进行标准化处理的伪代码:
UPDATE [dbo].[TABLENAME]
SET [COLUMN]=STANDARD VALUE
WHERE CONTAINS([COLUMN],UNSTANDARDIZED VALUE)
//标准化处理后再对数据集进行算法处理:
Set w(column1)=column1 weight value;
w(column2)=column2 weight value;……//为每个字段设定权值
Set w=a;threshold=b;
//设定滑动窗口大小为a,
//阈值为bor(int t=w-1;t//数组中第一个记录为array[0]
{Int newtheshold=
(array[t].column1)compare(array[t-w+1].column1)*w(column1)+
(array[t].column2)compare(array[t-w+1].column2)*w(column2)+……
//compare是两个字符串比较函数,相等值为1,否则为0;
//通过权值分配比较两条记录的相似度
If(newtheshold> theshold)
Delete array[t];
//如果记录相似度大于阈值则删除后面的记录
}
对记录比较时对记录集中的滑动窗口的设置过程中,采用算法如下:
SELECT num=COUNT(*)
FROM [dbo].[TABLENAME]
WHERE CONTAINS([COLUMN],array[0].column)
Set w=m;
滑动窗口中记录比较代码
If((array[t].column)compare(array[t-w+1].column)=0)
SELECT n=COUNT(*)
FROM [dbo].[TABLENAME]
WHERE CONTAINS([COLUMN],array[t].column)
Set w=(int)n/num*m;
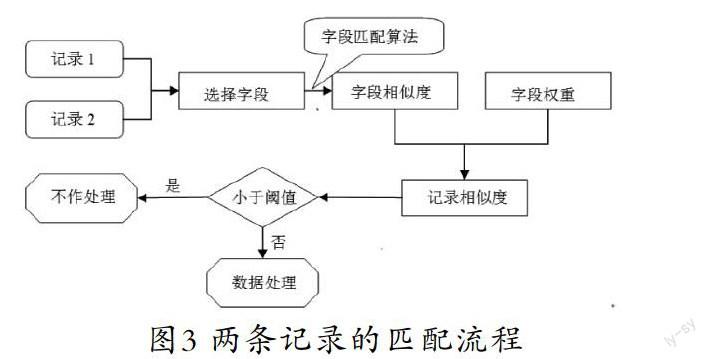
在使用SNM算法对记录进行比较时,两条记录的匹配流程是对不同的字段根据在元组中的重要程度赋予不同的权值,在设定好阈值的基础上,计算每条记录的权值总和,如果总值大于设定的阈值,则作为重复记录处理,否则视为两条记录。具体工作匹配流程如图3所示。
5 结论(Conclusion)
本论文通过在SNM算法中引入全文索引方法,较好的降低了索引处理成本并加快了处理速度,不仅较好的解决了记录排序效率低的问题,同时通过滑动窗口的随时改变,对字段设定不同的权值,将记录的权值的总和与设定的阈值进行相似度检测,在不影响查找重复记录效率的情况下减少了不必要的比较次数,从而更好的提高了算法的效率。
参考文献(References)
[1] 杨辅祥,刘云超,段智华.数据清理综述[J].计算机应用研
究,2004(4):3-5.
[2] 郭文龙.一种改进的相似重复记录检测算法[J].计算机应用与
软件,2014(1):293-295.
[3] 张建中,等.对基于SNM数据清洗算法的优化[J].中南大学学
报,2010(6):2240-2245.
[4] 徐小刚,王俊杰,于玉.全文索引的研究[J].计算机工程,2002
(2):101-103.
作者简介:
谢文阁(1966-),男,本科,教授.研究领域:数据仓库,软件
开发.
佟玉军(1970-),男,本科,副教授.研究领域:算法,数据
挖掘.
贾 丹(1972-),女,硕士,副教授.研究领域:算法,软件
开发.
梅红岩(1978-),女,博士,副教授.研究领域:人工智能,软
件开发.
