
一种用于预估MOCVD工艺结果的改进方法
2015-05-18 01:18:25陈立宁林伯奇胡晓宇
电子工业专用设备 2015年8期
陈立宁,林伯奇,魏 唯,胡晓宇
(中国电子科技集团公司第四十八研究所,湖南长沙410111)
一种用于预估MOCVD工艺结果的改进方法
陈立宁,林伯奇,魏 唯,胡晓宇
(中国电子科技集团公司第四十八研究所,湖南长沙410111)
Apriori算法是关联规则中的一种典型算法。该算法结构简单,以递归统计为基础,采用逐层搜索的方式对大量数据进行提取,挖掘数据记录之间的关联规则。针对Apriori算法产生候选记录集过多的问题,提出了一种改进方法减少候选记录集的组合个数。一项MOCVD工艺包含了流量、压力、温度等多种实时数据,数据量庞大,根据改进方法对MOCVD工艺中所产生的实时数据以及操作记录进行分析、挖掘出这些数据记录之间的关联关系;然后根据MOCVD工艺结果,判断这些关联关系对MOCVD工艺的影响,并作为下一次工艺数据编辑的依据。
Apriori算法;MOCVD;关联规则;候选记录集
随着计算机硬件技术的提高,计算机对数据的处理能力也在日渐提升,加上当前互联网络的发展以及普及,数据信息量在不断上涨,人们已经进入了一个信息爆炸的时代。人们除了利用现有的关系数据库标准查询语句得到一般的、直观的信息外,很多时候因为业务的需求不得不挖掘其内含的、未知的却又实际存在的数据关系,而这些数据关系往往是对业务存在极大价值,也是人们迫切想要知道的信息。对个人尤其是对企业而言,如何从这些海量的数据当中挖掘出潜在的、有用的信息是一个挑战。数据挖掘[1]就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又非常有价值的信息的过程。
一项MOCVD工艺包含了时间、气体流量、气体压力、真空、温度、转速、开关量等多种实时数据。一个典型的工艺一般要进行数个小时,从工艺开始到结束,会产生大量的实时数据以及操作记录。因此,一项工艺运行当中的操作记录,即使在工艺运行过程当中没有出现意外或者报警,在一定程度上也存在参考价值。所以从这些实时现场记录当中,挖掘出其中潜在的关联关系也对下次工艺运行具有一定参考意义。
1 算法相关知识
1.1 Apriori算法思想与原理
Apriori算法采用一种逐层搜索的迭代方法,k项集用于搜索(k+1)项集,来穷尽数据集中的所有频繁项集。算法的主要步骤如下:(用Lk表示k项频繁集,Ck表示k项候选集)
1.1.1 连接步
先找到频繁1项集L1,然后将L1和自身连接产二维候选项集C2,以此类推,通过将Lk-1进行自身连接产生候选k项集,即Ck。
1.1.2 剪枝步
Ck是Lk的超集,Ck的成员既包含频繁项也含有非频繁项,但所有频繁k项集一定都包含在Ck中。对数据库进行扫描,确定Ck中每个候选的计数,从而确定Lk。但是,Ck可能很大,这样所涉及的计算量很大。因此,利用任何非频繁的(k-1)项集都不是频繁k项集的子集这一性质来压缩Ck[7,8]。若候选k项集的(k-1)项子集不在Lk-1中,则该候选项也不可能是频繁的,可以从Ck中删除。
1.2 关联规则和置信度
关联规则和置信度的定义为:令U={I1,I2,I3,...,In-1,In},S(U)表示U的支持度,a是U的一个子集,S(a)表示a的支持度。如果S(U)/S(a)≥最小置信度,那么就存在如下关联规则a->Cs(a),其中Cs(a)为a在U中的补集。S(U)/S(a)的值就是该条规则的置信度。例如,假设U={I1,I3,I4,I6},a= {I4,I6},那么Cs(a)={I1,I3}。
1.3 Apriori算法的缺陷
Apriori算法的基本思路:
第一步:简单统计所有含有一个元素的项目出现频率,并找出那些大于或等于最小支持度的项目集,产生一维频繁项目集。
第二步:循环处理直到未能再产生维数更高的频繁项目集。循环过程是在第k步中,根据k-1步生成的k-1维频繁项集来生成k维候选项目集。
可以看出Apriori算法有以下缺陷:
(1)在每一步产生候选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,如果数据库中拥有上万条甚至几十万条或更多条记录,这种扫描比较将大大增加计算机系统的I/O开销,这种开销随着数据库记录的增加呈几何级数增长。
2 改进算法的设计思想
2.1 动态项集计数
本算法改进的核心思想是:生成k维频繁项集Lk后,在参与生成下一维候选项集前先对Lk中的一维元素进行计数。若它的计数小于k-1的话,说明该元素不是组成Lk+1项目集的元素。因为对一个一维元素而言,要成为k维项目集中的元素的话,该元素在k-1阶频繁项目集中的计数必须大于或等于k-1个,否则不可能生成k维项目集。
2.2 算法的实施过程
本文针对Apriori算法不足之处,通过候选项集计数的方法,统计当前频繁项集中一维元素个数,将不是组成下一维项目集的元素删除,减少项目集的个数。改进算法流程如下:
步骤1:统计所有一维元素出现的次数,保留次数不小于最小支持度的一维元素,生成一维频繁项集L1。
步骤2:通过合并L1中所有一维频繁项,生成二维候选项集,以此类推。通过第(k-1)维频繁项集Lk-1,合并生成k维候选项集Ck。因为最大项目集的子集必为最大项目集。所以在计算Ck中元素支持度时,先删除Ck中所有(k-1)维子集不在Lk-1中的项目集。
步骤3:扫描原始数据库,计算Ck中每个元素在原始数据库中的支持度。然后将统计后的支持度同最小支持度比较,删除那些支持度小于最小支持度的项目,生成k维频繁项集Lk。
步骤4:统计Lk中每个一维元素的个数,若它的计数小于k的话,说明该元素不是组成Lk+1项目集的元素。因为对一个一维元素而言,要成为k维项目集中的元素的话,该元素在k-1阶频繁项目集中的计数必须大于或等于k-1个,否则不可能生成k维项目集。
步骤5:重复步骤2至步骤4的内容,直到不能再生成下一维项目集。
2.3 改进算法伪代码
改进算法生成频繁项集的伪代码如下:

2.4 实例说明
表1表示MOCVD工艺中操作记录所对应的编号,即,I1={第2步,步时间:32->64}。
原始数据库中每条记录中的操作事件是由逗号隔开的,以此为分隔点扫描每条记录中的操作事件,例如:扫描到I1后比较之前扫描到的事件有没有与I1相同的,如果没有就将I1作为一个单独元素对其计数为1;如果相同,就将扫描到I1的计数加1,以此类推,直到扫描完所有的记录中的操作事件就得到了一维候选项集C1,然后将每个元素的支持度(即每个元素出现的次数)与最小支持度比较,得到L1,按照图1说明的过程推导出最大频繁项集。
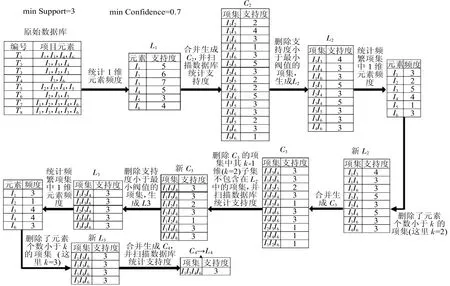
图1 最大频繁项集挖掘过程
图1中所示的最大频繁项集推导过程说明如下:
(1)统计原始数据库中各MOCVD工艺操作事件出现的次数,保留出现次数不小于最小支持度S的操作事件,并记为一维元素,用该一维元素生成一维元素集L1;其中,最小支持度S为3;
(2)将L1中元素两两合并,生成二维候选项目集C2;
(3)计算C2中2维元素在原始数据库中的支持度,删除C2中支持度小于最小支持度的二维元素,生成二维频繁项集L2;
(4)统计L2中一维元素的频度,删除包含频度小于2的一维元素的二维元素,并用剩余的二维元素组成新的频繁项集L2;
(5)将新L2中的二维元素项目两两合并,生成三维候选项目集C3;
(6)计算C3中的三维元素在原始数据库中的支持度,删除支持度小于最小支持度的三维元素,生成频繁项集L3;
(7)统计L3中一维元素的频度,删除L3中包含频度小于3的一维元素的三维元素,生成新的三维频繁项集L3;
(8)将新L3中的三维元素两两合并,生成四维候选项目集C4,由于不能再继续生成下一维候选项集,且C4中元素的支持度大于最小支持度,故C4为L4,即本实施例的最大频繁项集。
由关联规则的定义,根据最大频繁项集,可得到如下关联规则:
(1)I6->I1I3I4置信度:S(I1I3I4I6)/S(I6)=3/4=75%
(2)I1I3->I4I6置信度:S(I1I3I4I6)/S(I1I3)=3/4=75%
(3)I1I4->I3I6置信度:S(I1I3I4I6)/S(I1I4)=3/3=100%
(4)I1I6->I3I4置信度:S(I1I3I4I6)/S(I1I6)=3/3=100%
(5)I3I6->I1I4置信度:S(I1I3I4I6)/S(I3I6)=3/3=100%
(6)I4I6->I1I3置信度:S(I1I3I4I6)/S(I4I6)=3/3=100%
(7)I1I3I4->I6置信度:S(I1I3I4I6)/S(I1I3I4)=3/3=100%
(8)I1I4I6->I3置信度:S(I1I3I4I6)/S(I1I4I6)=3/3=100%
(9)I1I3I6->I4置信度:S(I1I3I4I6)/S(I1I3I6)=3/3=100%
(10)I3I4I6->I1置信度:S(I1I3I4I6)/S(I3I4I6)=3/3=100%
上述规则中,置信度达到100%的,说明工艺人员进行了某些操作后,必定会进行其他的操作,例如:第8条规则中,工艺人员进行了I1I4I6三步操作后,必定会进行I3操作,由于工艺运行中每一步操作都可能对工艺结果造成不同程度的影响,所以从上述规则当中可以认为,置信度达到100%的工艺操作对工艺结果有直接的影响,根据工艺结果的好坏,可以从这些推导出的规则当中总结出:下次工艺时,这样一系列操作是可行的还是需要改进的。
3 实验结果及分析
MOCVD工艺数据一般为以下几种类型:质量流量计数据包括H2、N2、NH3三种载气流量,SiH4(硅烷)流量以及MO源(三甲基铝、三甲基镓、三乙基镓、二茂镁、三甲基铟)的流量;压力控制器数据包括反应室压力、三种载气压力和MO源压力;石墨盘的温度和转速。工艺操作主要就是对上述对象进行设置、更改。而工艺中所有实时数据以及操作记录都是存储在数据物理表中。
改进算法就是以日志表中的操作事件为对象,对每条操作事件进行编号,然后按两两组合的方式合并每条记录,生成高维的数据记录集,然后统计这些数据记录集个数,挖掘出最大频繁项集。记录集的维数就是集合中每个元素包含的操作事件的个数,其中元素相当于前面的操作事件的内容,是一个字符串数据。
本次实验采用C++程序编写,针对数据库这些操作记录进行合并删除,推导出这些记录之间的关联规则。算法实验环境为:CPU:Intel Core Duo T2050@801 MHz/1.60 GHz,内存信息:PC2-5300 DDR2666 MHz双通道1 G,开发环境:VC++.net。实验数据:MOCVD3个月的工艺数据,操作记录约为27 000条。
该算法试验中,在选择不同最小支持度阈值的情况下,测试了改进算法和传统算法在挖掘所有频繁项集所用的时间试验数据如下表2所示。
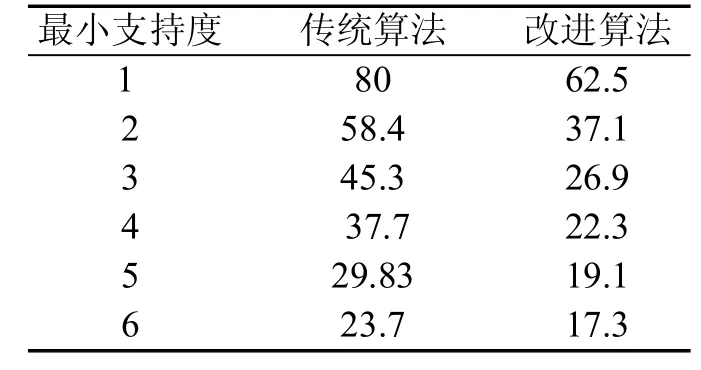
表2 不同最小支持度下算法挖掘所有频繁项集所用时间
根据表2的实验结果将两算法所用的时间绘制成图,如图2所示。
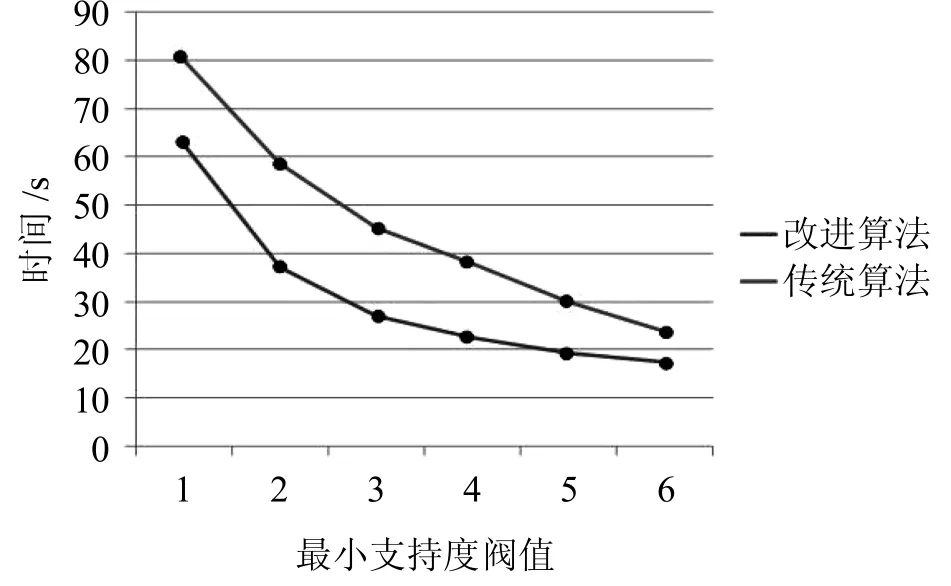
图2 改进算法和传统算法挖掘所有频繁项集所用时间
实验结果显示,本文所提出的改进算法比传统算法在时间上大约优化了10%~20%。因为Apriori算法是利用频繁项集Lk-1项两两相结合产生候选项集Ck,k越大所产生的候选项集的数目就越多,呈指数级增长;其次就是在剪枝步以及计算支持度时需要遍历一次数据库。改进算法生成k维频繁项集后,在两两结合生成k+1维候选项集前,先计算一维元素的频度,删除了不可能构成k+1维候选项集的元素组合,这样在连接步时就大大减少了候选项集的数目,提高了算法效率。但由于在生成候选项集以及计算支持度时仍然要扫描数据库,因此改进算法在效率上还有更多可优化的空间。
4 结 论
本文针对Apriori算法效率上的不足,在其基础上提出了一种改进方法。改进的思想主要是在频繁项集两两结合生成下一维候选项集时,先扫描频繁项集中一维元素的个数,如果一维元素个数小于当前频繁项集的维数,则将包含有该一维元素的元素组合从当前频繁项集中删除,这样就能减少下一维候选项集的个数,因为候选集候选项集元素多是影响算法效率的瓶颈,因此改进算法在时间开销上要优于传统算法。但是改进算法在生成候选项集和计算支持度时仍然要扫描数据库,因此如何采用更好的数据结构或方法,进一步减少数据库的扫描次数,是下一步的研究重点。
[1] 李先通,李建中,高宏.一种高效频繁子图挖掘算法[J].软件学报,2007,18(10):2469-2472.
[2] 王映龙,杨珺,周法国,等.加权最大频繁子图挖掘算法的研究[J].计算机工程与应用,2009,45(20):31-34.
[3] 吴甲,陈峻.一种快速的频繁子图挖掘算法[J].计算机应用,2008,28(10):2533-2534.
[4] 谢均,尚学群,王淼,等.解决数据样本不平衡性的频繁子图挖掘算法[J].计算机工程与应用,2008,44(36):146-147.
[5] InokuchiA,WashioT,MotodaH.Complete mining of frequent patterns from graphs:Mining graph data[J].Machine Learning,2003,50(3):324-340.
[6] 王艳辉,吴斌,王柏.频繁子图挖掘算法综述[J].计算机科学,2005,32(10):193-194.
[7] 白似雪,朱涛,梅君.基于图的Apriori改进算法[J].南昌大学学报,2009,31(1):36-37.
[8] 黄建明,赵文静,王星星.基于十字链表的Apriori改进算法[J].计算机工程,2009,35(2):37-38.
[9] 严蔚敏,吴伟民,著.数据结构[M].北京:清华大学出版社,1996.7:161-166.
Improved Method for Estimating Recipe Results of MOCVD
CHEN Lining,LIN Boqi,WEI Wei,HU Xiaoyu
(The 48th Research Institute of CETC,Changsha 410111,China)
Apriori algorithm is one of the classical algorithms about association rules,which is based on recursion and very simple.This method extracts data by layer-by-layer search and deduces the association rule.An improved method is mentioned to reduce the amount of candidate recordsets in connection with lots of candidate record sets generated by Apriori algorithm.So much real time data like flow,pressure,temperature and so on is available in a MOCVD recipe.The rcipe data is analyzed in a MOCVD recipe with this improved method and the association rule is deduced in this dissertation. This association rule deduced by this method can be used to evaluate a MOCVD recipe and become reference for the next recipe.
Apriori algorithm;MOCVD;Association rule;Candidate record set
TN304.05
:A
:1004-4507(2015)08-0010-06
陈立宁(1984-),男,硕士,主要研究方向为数据库技术、数据挖掘。
2015-06-25
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
中等数学(2020年8期)2020-11-26 08:05:58
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
计算机应用(2018年5期)2018-07-25 07:41:26
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
