
一种改进的维吾尔文图像倾斜校正方法∗
2015-05-16 10:57王剑哈力木拉提买买提艾尔肯赛甫丁程园
新疆大学学报(自然科学版)(中英文) 2015年2期
王剑,哈力木拉提买买提,艾尔肯赛甫丁,程园
(新疆大学信息科学与工程学院多语种信息技术重点实验室,新疆乌鲁木齐830046)
0 引言
文档扫描图像的倾斜校正是文字识别的重要部分.信息时代对计算机自动处理文档的需求越来越迫切,而扫描过程中维吾尔文文档不一定刚好放正,从而或多或少的产生了一定的倾斜,维吾尔文文档的倾斜会严重影响到维文的进一步切分以及特征提龋 最终会影响到维吾尔文的识别准确率,所以维文的预处理倾斜校正至关重要.
检测倾斜角的几种常见方法:基于投影的方法[3],基于投影图的方法是利用投影图的某些特性来进行判断,该方法计算复杂度比较高.基于交叉相关性的方法[5],它是通过对矩阵在竖直方向上作投影,投影图的全局最大值对应于倾斜角,该方法准确率高,但计算量较大.基于Hough转换的方法[4],[6],该方法抗干扰性好,鲁棒性强,但是计算量大,准确率要依赖函数参数的角度分辨率.K-最近邻簇方法[8],该方法计算量也比较大.基于Fourier交换的方法[2],它的计算量非常大,一般很少采用.由于维吾尔文的特征是沿基线前后相连,所以本文采取了基于最小二乘法求基线来测文本行的倾斜角[7],对于整幅文档图像,文章采取了最小面积外接矩形法[1]求整个倾斜角,主要是考虑到它们的准确率和高效性.
1 维吾尔文图像倾斜校正
1.1 基于整幅文档图像的倾斜校正
扫描维吾尔文后得到的是灰度图,有前景和背景,不利于图像的分析.我们先对这样的图像进行二值化处理,得到像素只有0和255的二值图像.二值化处理有灰度阈值变换法,迭代阈值法和大津阈值法.本文采用的是大津阈值法,主要是考虑是这个阈值不用自己设定,而是程序根据需求自定义的,减轻了工作压力.文档图像经过二值化处理后,有的图像需要细化,该操作保持原有笔画连续性,不造成断裂,细化为单线,即比划宽度只有1个bit保持原有拓扑、几何特征,使处理更加方便,也不丢失原有信息.见图1.
文档图像经过二值化细化处理后,然后对整个图像求出它们的倾斜角度,求出倾斜角后就对其进行旋转校正,这里我们采用了最小面积外接矩形法求出倾斜角,最小面积外接矩形法[2],算法思想大致如下:先以P0这个点为基准点求出所有点的极角,按极角进行排序,P0在最前面,设这些点为P[0]···P[n-1].然后建立一个栈,初始P[0],P[1],P[2]进栈,后面点进栈时若栈顶的两个点与它不构成“向左转”的关系,则将栈顶的点出栈,当所有点处理完之后栈中保存的点就是凸形边上的点.最后通过建立的凸多边形寻找给定2D点集的最小面积的包围矩形(图2),矩形信息有最小面积area、长height、宽width、中心点center,以及倾斜角θ等信息.

图1 图像二值化及细化前后对比
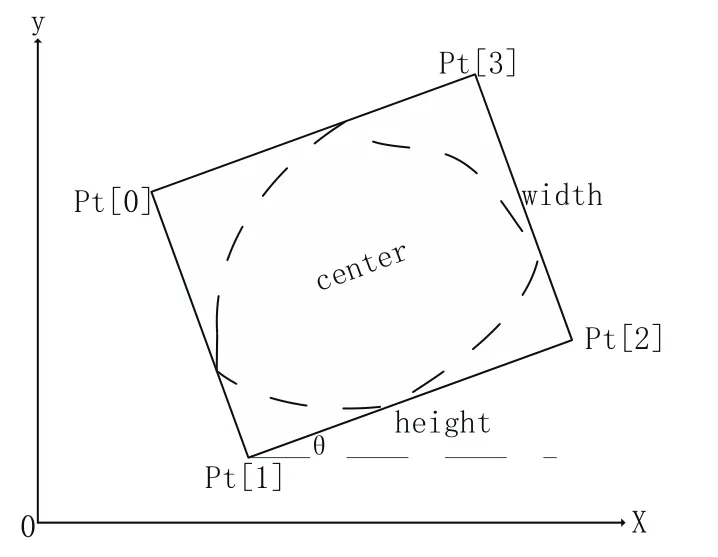
图2 点集生成的凸形及最小面积外接矩形
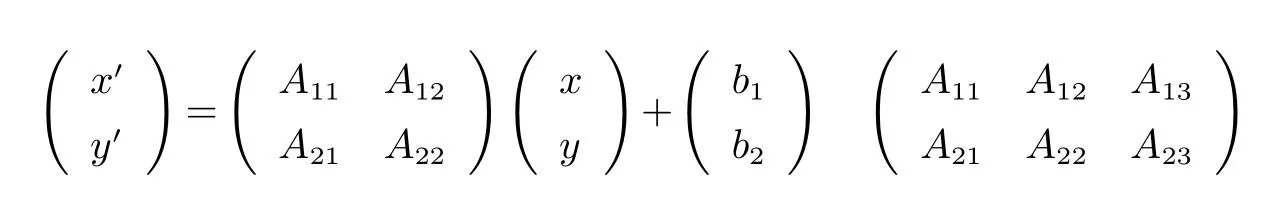
图3 坐标点旋转及变换矩阵
文档图像的倾斜校正如下图所示,这里只整体旋转,并没有每行旋转,本文实现了每行文本的旋转,最后再把每行整合在一起,成一幅新的图像[1].

图4 图像旋转前后对比

图5 一行文本行的图像以及它的水平投影图
1.2 基于文本行的倾斜校正
前面我们求出了整个文档图像的倾斜角,接下来考虑每一行文本的倾斜角.对于给定的一幅扫描图像,当仔细观察,会发现每一行文本之间会有一定的距离;我们首先通过水平投影到最左边的窗口,这样会形成一块一块的投影图,并且之间都有一定的距离,我们记录下每个投影块的起点和终点,最后我们把起点和终点作为提取图像的上下界,而原图像的横向大小作为提取图像的左右界,这样就提出了一个文本行的图像.如图5所示:
本文中讨论的是常规的直线拟合,直线拟合的出现有很多原因,这里选择它,是因为在分析三维点的时候频繁与直线拟合相关.直线拟合一般使用统计的鲁棒算法.曲线拟合中最基本和最常用的是直线拟合.设x和y之间的函数关系由直线方程:

给出.通过测量N组数据(xi,yi),i=1,2······N,其中xi值被认为是准确的,所有的误差在于yi.这里通过最小二乘法把观测数据拟合为直线.
首先我们对直线进行参数的估计,通过最小二乘法进行估计参数时,要求观测值yi的偏差的加权平方和为最小.根据等精度观测值的直线拟合的原理,得到算法公式

通过对参数a(代表a,a1)进行最佳估计,可以使观测值yi的偏差的平方和为最小.这样我们得到下列计算公式
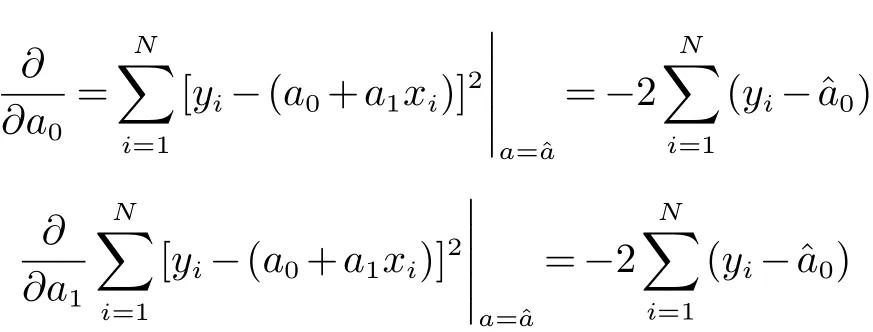
整理简化后得到方程组

通过解方程组即可求得直线参数a和a1的最佳估计值和.即
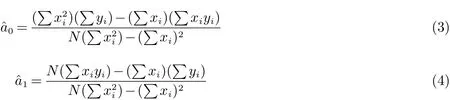
S值是检验直线拟合结果是否合理的重要标志,它是拟合直线的标准偏差,假设平面上作两条与拟合直线平行的直线

则这两条直线包含了全部观测数据点(xi,yi)约68.3%的分布,如图6所示.
通过基线与水平直线的夹角来求得这行本行的倾斜角.如图7所示.
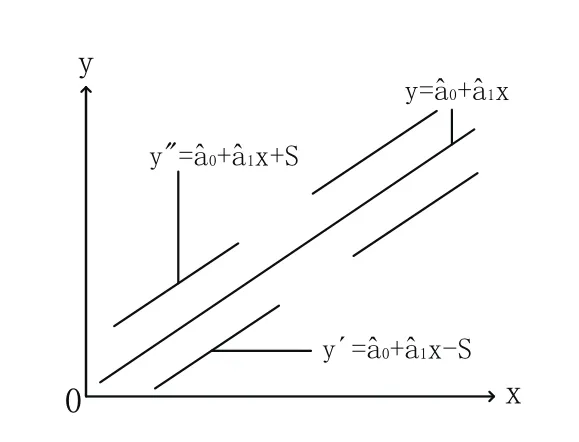
图6 拟合直线两侧数据点的分布

图7 文本行图像直线拟合的基线
1.3 基于文本行的整合
前面已经进行了整幅文档图像的旋转以及对每一行文本的倾斜校正,接下来需要把这些分散的文本行重新整合在一幅图像上,我们先建立一幅和原来图像相同大小的图像,并且全部像素为255,然后记录每个文本行的起始位置和结束位置,在同样的位置把对应的每行文本复制到新图像上,这样就会得到一幅整体和每行文本都进行了倾斜校正的新图像,这在维吾尔文的文字识别工作中占据了很重要的一部分.
2 实验结果及分析
在传统的维吾尔文文本图像的倾斜校正都是整幅图像的校正,但是每行文本行都有自己的角度,我们先对一副图像文本行的一部分进行了简单的统计,如表1所示.
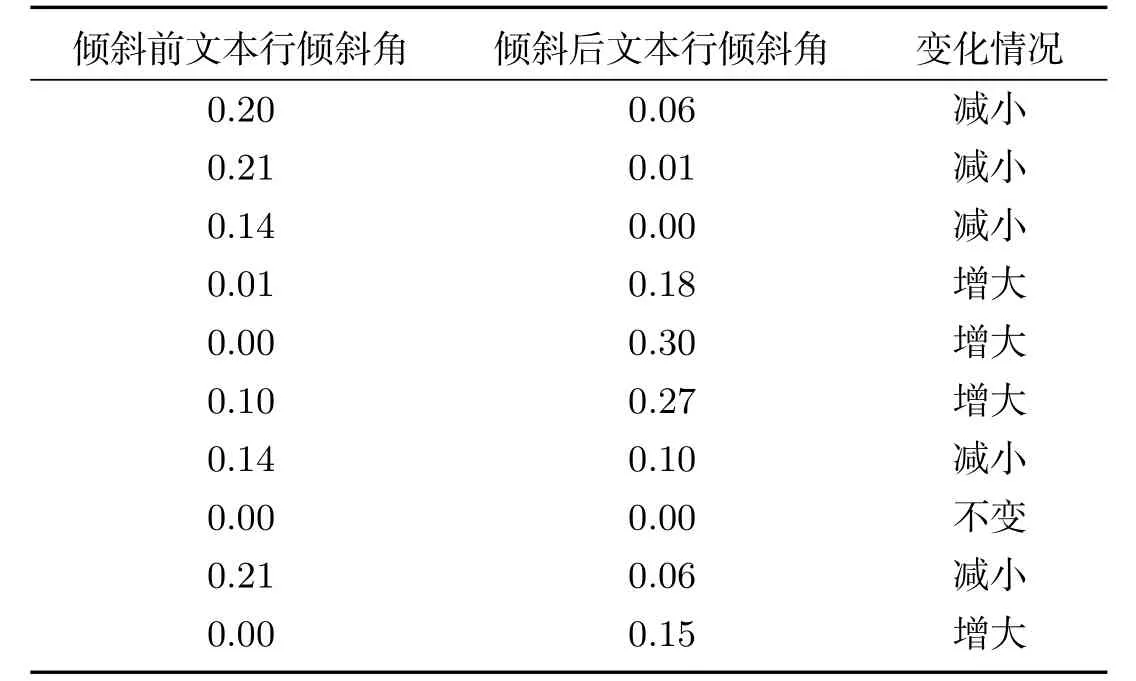
表1 一幅图像倾斜前后的文本行角度变化情况

表2 十幅图像倾斜前后的文本行平均角度变化情况
通过表1,我们发现有些文本行角度(不为0)在校正后会变大,有些文本行角度(不为0)在校正后会变小或者变为零角度,而有些文本行没有倾斜角度(为0)在校正以后有了倾斜角度,并且,我们所不希望出现的文本行角度变大占到了30%左右,这样就达不到我们想要倾斜校正的效果.我们对十幅图像进行统计,分析其中的变化情况,如表2所示.
通过表2,我们发现对整幅图像倾斜校正以后,要是对整幅图像进行处理,一般都有比较好的预期效果,但是单独对每行文本进行处理就没有预期的那种效果,因为校正以后有很大一部分的文本行的角度比原来还要大,这肯定不是我们想要的结果!在这里我们可以通过对图像的感兴趣区域进行预处理,提取出文本图像的每一行文本,对原图像我们可以把所有文本行提取出来,然后分别求出每一文本行的基线,这样就可以得出它的基线角度,然后求所有行的角度平均值.我们计算出了文本行的角度以后,就对其进行校正,直到我们对图像的每一个文本行都进行校正以后,然后把这些文本行重新整合起来成为一幅新的图像,同样这幅图像也有倾斜角,但是大部分都没有,只有少部分图像是有微弱的倾斜,这也在我们能够接受的范围之内.同样我们对十幅图像进行了重新整合以后的信息统计,如表3所示.
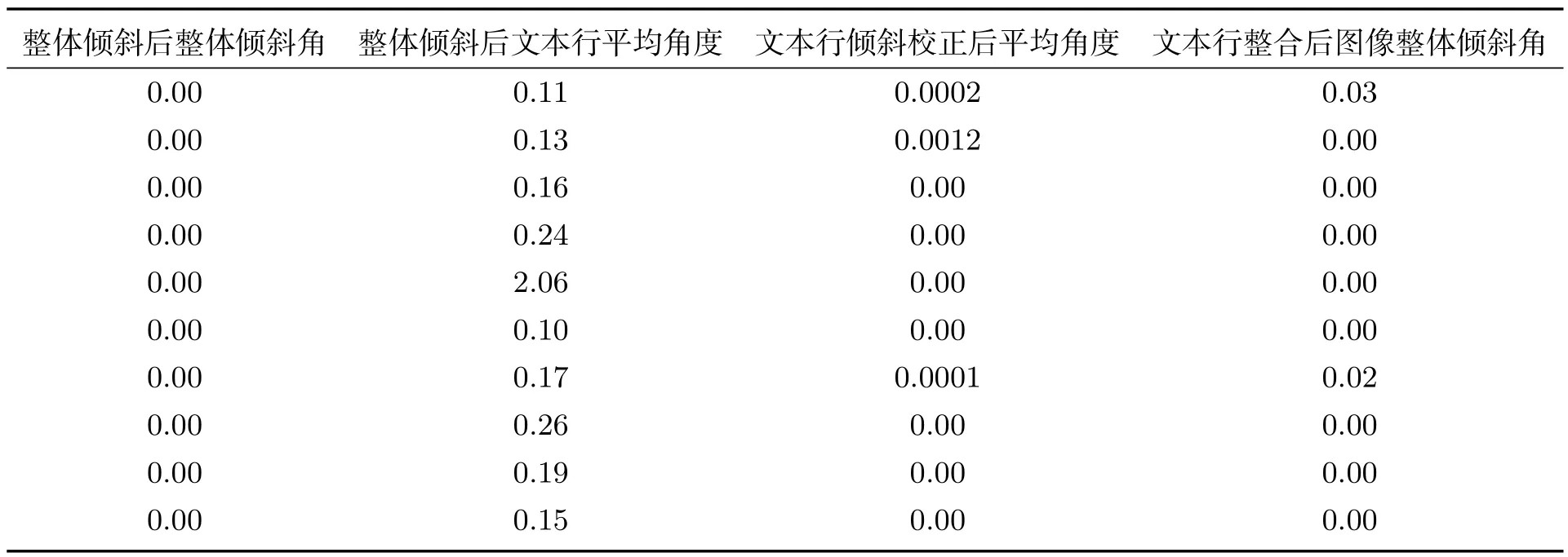
表3 十幅图像通过本文行倾斜校正整合后的信息统计
通过表3,我们发现整合以后的文本行的平均角度已经非常校 即文本行基本被校正,同时整合以后的图像倾斜角也基本为零,即使有角度也是非常小的.这样的图像对我们整个处理以及单独处理都是有帮助的.我们花时间和精力在文本图像预处理上,是因为效果不好的倾斜校正,会使原本没有粘连的字母粘在一起,这对后面的字符的特征提取和切分带来很大的困难,不利于整个系统的完善.最后我们统计了只倾斜校正和先整体后文本行倾斜校正后的字母切分准确率的情况,如表4所示

表4 两种倾斜实验后字母切分率的对比结果
通过表4我们发现,字母切分准确率有了明显的提高,这为后面的字母的特征提取和识别提供很好的铺垫作用,为识别的准确率提供了保证.从图8中可以看出深线的地方表示字母漏切的地方,前面表示整体倾斜的切分图,后面表示整合图的切分图.

图8 部分图像的字母切分对照图
3 结论
本文提出了基于凸多边形的最小面积外接矩形法求整幅图像的倾斜角度,该方法能够检测到比较大的倾斜角,然后利用基线拟合的方法检测到比较小的倾斜角,本文将两者结合,先对整幅图像进行校正,其次对每行本文进行小角度的校正,两者结合以后,对于倾斜的维文文本能得到较好的校正效果,为下步的维文字符的特征提取和切分做好铺垫工作.后期我们进行了测试,实验结果发现在字母切分的准确率上平均提高约5%,最高提高7.08%.
参考文献:
[1]卢蓉,范勇,陈念年,等.一种提取目标图像最小外接矩形的快速算法[J].Computer Engineering,2010,36(21):178-180.
[2]唐群群,艾尔肯,赛甫丁.维吾尔文扫描页的倾斜校正[J].计算机应用研究,2013,30(5):1551-1553.
[3]刘旭,巫玲,陈念年,等.基于光栅投影序列图像融合的倾斜校正算法[J].计算机应用,2013,33(11):3209-3212.
[4]姜文,卢朝阳,李静.基于Hough变换的手写体维文字符倾斜校正算法[J].微型机与应用,2013,32(8):29-31.
[5]巨志勇,王平殿.基于几何约束的文本图像倾斜角检测算法[J].计算机应用研究,2013,30(3):950-952.
[6]于明,李延果,于洋,等.融合Hough与Radon变换的车牌倾斜校正算法[J].控制工程,2013,20(006):1014-1017.
[7]廖晓姣,李英.基于最小二乘和最小投影距离的车牌倾斜校正[J].物联网技术,2012,2(5):34-36.
[8]钟金荣,杜奇才,刘荧,等.特征提取和匹配的图像倾斜校正[J].中国图像图形学报,2013,18(7):738-745.
猜你喜欢
河北理科教学研究(2020年2期)2020-09-11
数学年刊A辑(中文版)(2020年2期)2020-07-25
国学(2020年1期)2020-06-29
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国医学影像学杂志(2018年9期)2018-10-17
北京航空航天大学学报(2017年1期)2017-11-24
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
中学理科·综合版(2008年9期)2008-10-15

- 新疆大学学报(自然科学版)(中英文)的其它文章
- WSNs中基于Chebyshev多项式的可认证密钥协商方案∗
- 新疆双峰驼乳清蛋白组分对人宫颈癌HeLa细胞增殖的抑制作用∗
- 新疆加曼特金矿与斑岩型金矿的对比研究∗
- 具有非倍测度的参数型Marcinkiewicz积分交换子在Hardy空间的估计∗
- Periodic Solution of a Two-species Competitive Model with State-Dependent Impulsive Replenish the Endangered Species∗
- Permanence and Extinction for Nonautonomous SIRS Epidemic Model with Density Dependence∗