
利用聚类分析方法进行模型优选
2015-05-14 03:00:04戴危艳李少华王军宋道万史敬华陈苏
断块油气田 2015年4期
戴危艳,李少华,王军,宋道万,史敬华,陈苏
(1.长江大学地球科学学院,湖北 武汉430100;2.中国石化胜利油田分公司地质研究院,山东 东营 257015)
0 引言
储层随机建模技术产生于20世纪80年代初期,目前在油气田勘探开发实践中的应用越来越广泛。随机建模能够提供多个等概率的模型实现,利用这些实现可以对储层进行不确定性评价[1-2]。而在油藏数值模拟中,考虑到计算成本,通常只能够对有限的几个实现进行模拟计算,故必须从多个模型中优选出1个或几个进行数值模拟研究。常用的随机模型筛选方法有算术平均法、地质模式筛选法、数值模拟法、概率储量法、实验设计、拉丁超立方抽样和排序法[3-6]。算术平均法的原理是将多个实现进行算术平均,将得到的平均模型作为优选模型,其优点是简单快捷,缺点是具有平滑效应,改变了储层非均质性和模型的统计分布特征。地质模式筛选法是通过对比每个模型与地质模式之间的差异,从中选出吻合程度较大的模型,它可以较好地满足地质概念模式,但非常耗时,且受主观因素影响较大。数值模拟法通过流线模拟、历史拟合等方法优选模型,其缺点也是比较耗时。概率储量法、实验设计、拉丁超立方抽样和排序法,都是以地质储量为指标进行模型优选,这些方法不适用于渗透率模型优选。聚类分析方法利用欧氏距离函数所计算的模型之间的差异对模型进行分类,然后从每一类中选出1个或几个模型进行油藏数值模拟。该方法操作简单,容易实现,不仅适用于各类属性(渗透率、孔隙度、含水饱和度等)模型的优选,也适用于相模型的优选。本文以50个渗透率模型为实例进行计算,对比所选模型计算的储量与用蒙特卡洛模拟法得到的P10,P50和P90储量 (即乐观、可能和悲观储量),验证了方法的可行性。
1 聚类分析方法的基本原理
聚类分析方法是通过度量研究对象的某种属性的相似程度,使同一类中样本的相似程度最大,而不同类中样本的相似程度最小,即聚类分析的过程主要依赖于样本之间的特征差异[7-8]。常用的聚类分析方法主要有5大类,即基于划分、基于层次、基于密度、基于网格和基于模型的聚类分析方法[9-10]。
K-means聚类分析方法是目前应用最为广泛的一种基于划分的聚类分析方法。该方法采用误差平方和作为准则函数,处理大数据集的效率较高[11-13]。它需要预先指定聚类个数,通过反复运算,得到最终聚类结果。其核心思想是找出k个聚类中心,使得每一个数据点和与其最近的聚类中心的平方距离和最小。该方法所获得的k个聚类,具有类内的差异较小、而类间的差异较大的特点。
K-means聚类分析方法的一般步骤[14-15]:1)随机指定k个聚类中心。2)计算各模型与k个聚类中心之间的距离。3)将模型分配到离其最近的聚类中心所标明的类。4)重新计算新的k个样本的聚类中心,以每个类的均值作为新的聚类中心点。5)与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,返回步骤2);否则,输出聚类的结果。在实际应用中,由于无法事先确定k取何值时能达到最佳的聚类效果,故本文根据普遍使用的经验规则,将k值的范围限定在2与之间[16](N为数据空间中的所有数据点的个数),然后利用聚类有效性评价指标确定k的具体数值。
2 聚类分析方法优选模型基本步骤
典型的利用聚类分析方法优选模型的过程,主要包括数据准备、计算相似度、特征选择、聚类及对聚类结果进行评估等步骤[17-18]。1)数据准备。随机模拟建立多个三维定量地质模型,统计各个模型中每一网格节点的属性值,并对这些值进行标准化处理。2)模型差异计算。计算每两个模型之间的欧氏距离,得到一个表征各模型之间差异的相异性矩阵。3)降维。对所得到的相异性矩阵进行降维,实现在二维空间中用向量来可视化模型的相似性,从而简化聚类过程。4)模型聚类及优选。确定聚类个数,编写相关代码对模型进行聚类,然后从每一类中选出1个或几个模型,一般选取离聚类中心近的模型。5)结果评估。对比井点属性值直方图与所选模型直方图,看所选模型是否满足地质要求。6)可靠性验证。对比所选模型计算的储量与用P10,P50,P90模型计算的储量,判断所选模型是否具有代表性。
3 实例研究
以WZ油田西区为例。该区纵向上有2套油层,由上至下分属上第三系角尾组二段砂岩和下第三系涠洲组三段砂岩,分别称之为“角二段油层”和“涠三段油层”。其中,角二段油层是主力油层,目前有5口开发水平井,1口裸眼井和1口探井,平均井距为400 m左右。目的层角二段属于滨海相沉积,岩性以长石石英砂岩为主,砂岩粒级多为细砂,在油田范围内厚度为110~130 m。
3.1 模型差异刻画
利用顺序高斯模拟方法随机模拟生成50个渗透率模型,统计各个模型中每一网格节点的渗透率数值据,将整理后的数据导入SPSS软件中。对数据进行标准化处理,然后计算各个模型之间的距离(差异)。常用的计算距离的函数有欧氏距离、马氏距离、明考斯基距离、豪斯多夫距离、基于连通性的距离、基于流线的距离、曼哈顿距离函数等[19-21]。用这些距离函数计算模型之间的差异各有其优缺点。如:马氏距离函数不受量纲的影响,还可以排除变量之间的相关性的干扰,其缺点是夸大了变化微小变量的作用[22];豪斯多夫距离函数比较大的缺陷是对于噪声、孤立点、断点等特殊点敏感,在处理的过程中无法避免这些异常点的发生[23-24]。本文应用欧式距离函数进行计算,其公式为
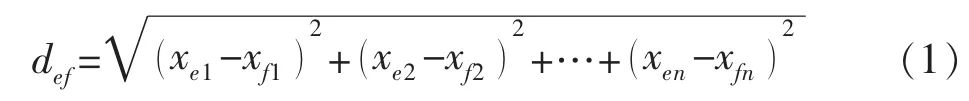
式中:def为 e,f两模型之间的差异;xen和 xfn分别为两模型第n个网格的属性值大小(如渗透率、孔隙度的大小或其他一些特征值的大小);n为网格个数。
应用式(1)计算每两个模型间相对应的每一网格节点渗透率值差的平方和,然后取平方根,得到一个相异性矩阵(见表1)。该矩阵中的数据所表示的是每一点处渗透率模拟结果的差异累加。而在实际的地质研究中,每处渗透率的大小都会直接影响流体的流动方向,所以,用该方法刻画渗透率模型之间的差异更加准确,而根据此差异所选择的模型也更具代表性。
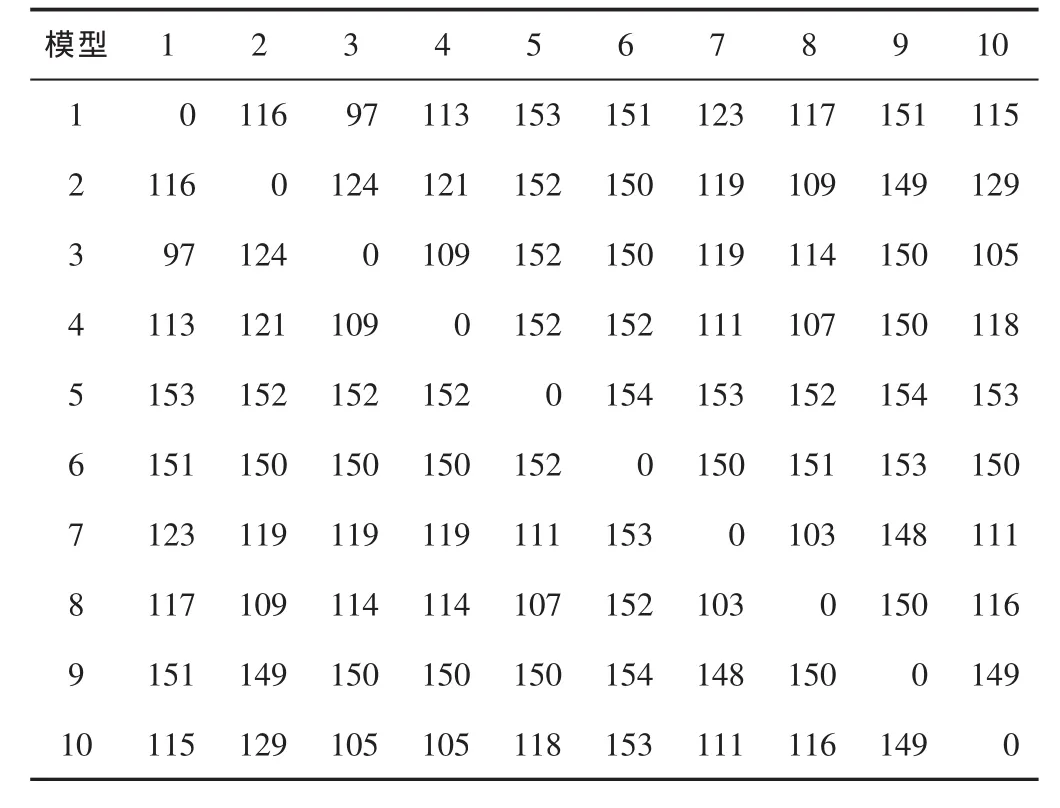
表1 相异性矩阵(部分)
3.2 多维尺度分析
由于高维会使数据之间的区分界限变得模糊,给聚类带来困难,所以,在进行聚类分析前都会对数据进行降维处理,进而实现在二维空间中用向量来可视化物体的相似性[25]。多维尺度分析是一种把高维降为低维,在低维空间展示距离数据结构的多元数据分析技术,简称MDS[26-28]。利用MDS技术提取出各模型在一维度和二维度上的坐标值(见表2)。一维度指渗透率高值偏少—偏多的维度,二维度指渗透率高值偏多—偏少的维度。进行聚类分析时,可直接采用这2列数据。
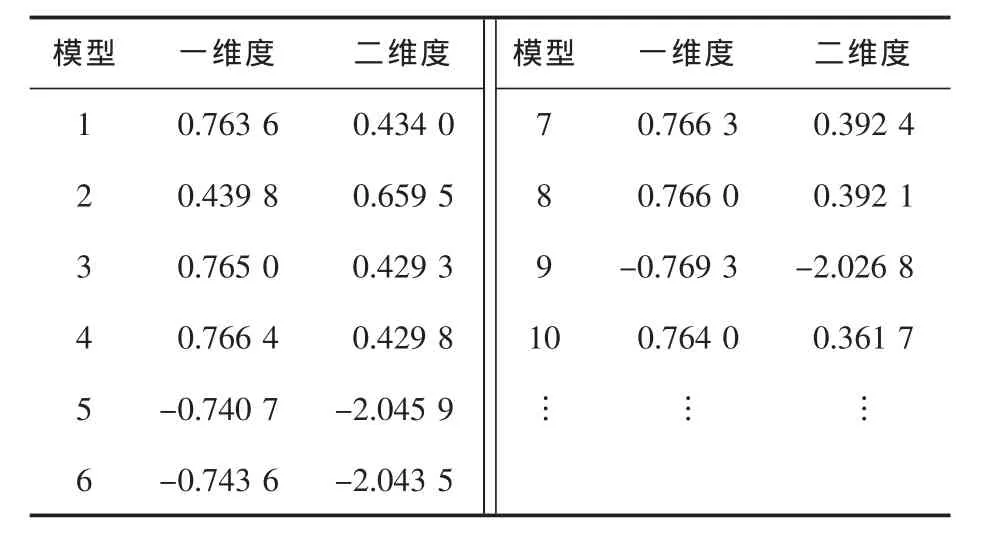
表2 模型在一维度和二维度上的坐标值
3.3 模型聚类
利用各模型在一维度和二维度上的坐标值,运用R语言编写相关代码进行模型聚类研究[29-30]。应用K-means聚类算法对模型进行聚类时,首先要确定聚类的个数k。由于k值的大小应在2与之间,其中N为数据空间中的所有数据点的个数,所以这里的k值大小在2~7。在此区间逐个选取k值进行聚类,得到的结果如图1所示。图中:数据表示各个渗透率模型之间差异的量化值;颜色表示模型类别,不同类别用不同的颜色区分;“△”表示聚类中心;“○”表示渗透率模型。
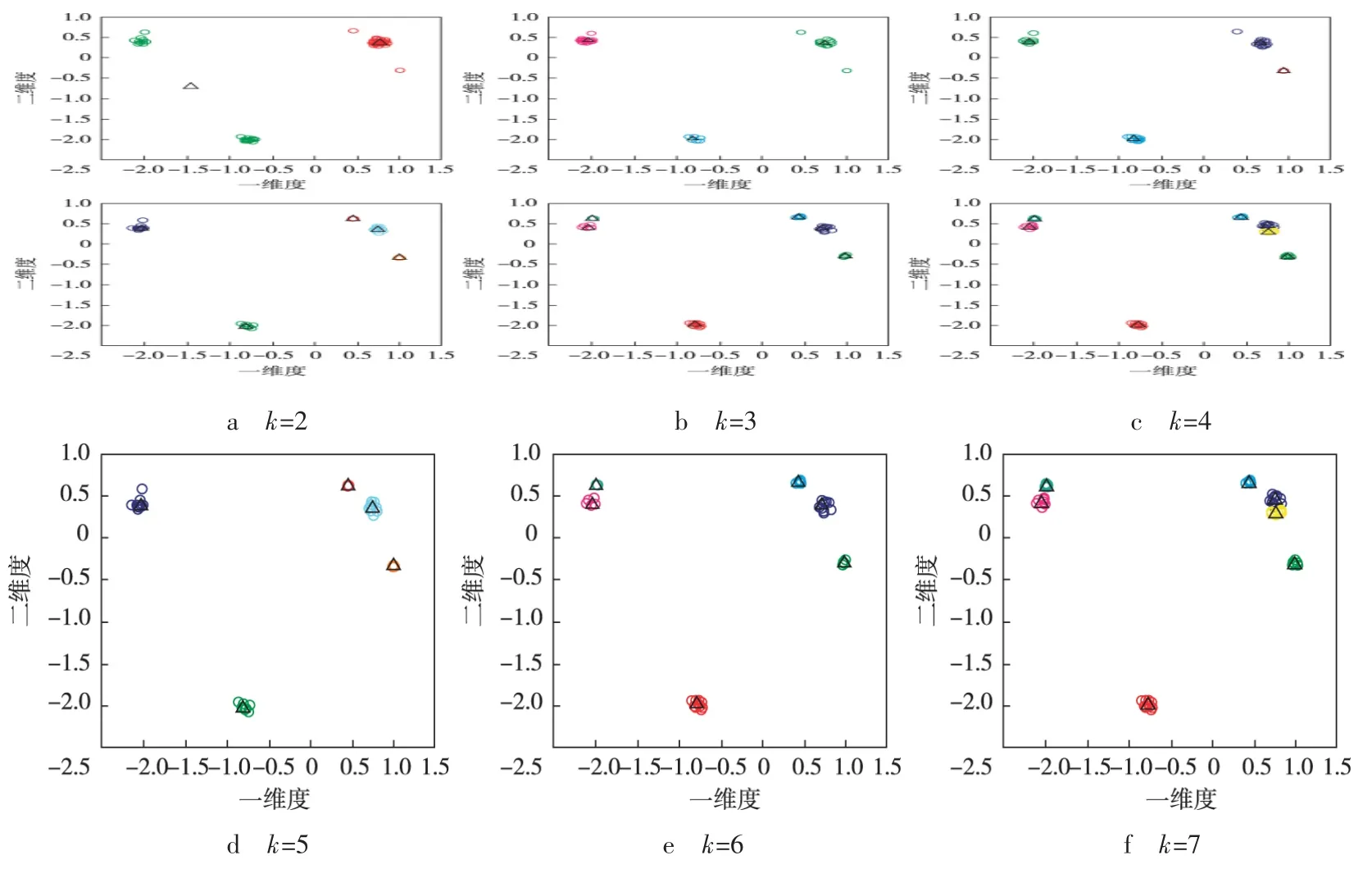
图1 聚类分析结果
一个有效聚类分析的分类结果应达到类内紧密、类间远离。评价聚类分析有效性的指标有Sil指标、DB指标、CH 指标、HS 指标、SB 指标、Dunn 指标等[31]。 本文采用Dunn指标来评价聚类结果的有效性。
Dunn指标使用同类数据类与类之间的最大距离来表示类内相似度,使用不同类数据类与类之间的最小距离来表示类间差异,D指标的取值为二者的商[32]。D越大,表示类与类之间间隔越远,聚类效果越好。其计算公式为
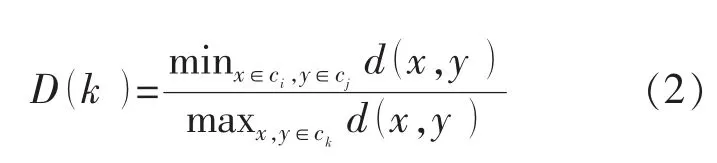
式中:ci为第i类数据;cj为第j类数据;ck为第k类数据;d(x,y)为 2 个数据点之间的距离。
表3是k取不同值时的D值。通过该表分析得出,聚类数为5时的聚类效果最佳。

表3 k取不同值时的D值
3.4 结果分析
利用K-means聚类分析方法,将原始的50个模型分成5大类:第1类模型中,离聚类中心最近的模型是模型15;第2类模型中,离聚类中心最近的模型是模型49;第4类模型中,离聚类中心最近的模型是模型11;第3类和第5类都只有1个模型,分别为模型2和模型34。如图2所示,对比模型15渗透率分布直方图与井点渗透率直方图发现,结果比较相似,说明模拟的结果与地质概念一致。从这5类模型中分别选出1个或几个进行油藏数值模拟,可以在一定程度上避免主观选择模型造成的不确定性,并提高研究的速度。

图2 井点渗透率直方图与模型直方图对比
4 方法可靠性验证
用上述方法可以分别优选出相应的孔隙度、含水饱和度以及NTG模型,从而利用这些模型计算储量。图3是用50组模型计算得到的储量累积概率分布。
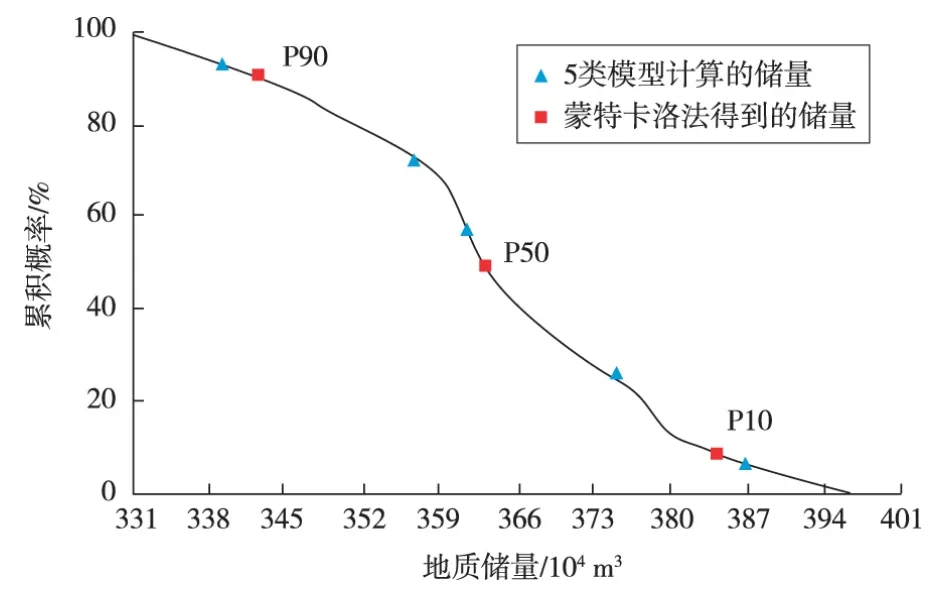
图3 储量累计概率分布
通过对比图3中用蒙特卡洛模拟法得到的P10,P50和P90储量与采用所选5类模型所计算的储量可以看出,用聚类分析的方法所选的模型具有较好的代表性,即原本需要50次模拟才能得到的结果,现在只需5次模拟就能得到,大大减少了模拟的次数。
5 结论
1)K-means聚类分析方法,以模型之间的差异为依据,结合距离函数对模型进行分类,适用于沉积相、孔隙度、渗透率、含水饱和度等各类模型的优选。
2)基于该方法选择的模型具有一定的代表性,避免了主观选择模型造成的不确定性,有效解决了模型数量大时优选具有代表性的模型进行油藏数值模拟的难题。该方法可以大大减少数值模拟的次数,简单且快速有效,实例研究也验证了该方法的可行性。
3)在实际应用中,可选用不同的聚类方法对模型进行聚类,从而选出最佳的模型分类方案。
[1]李少华,张昌民,彭裕林,等.储层不确定性评价[J].西安石油大学学报:自然科学版,2004,19(5):16-24.
[2]Singh V,Hegazy M,Fontanelli L.Assessment of reservoir uncertainties for development evaluation and risk analysis[J].The Leading Edge,2009,28(3):272-282.
[3]White C D,Royer S A.Experimental design as a framework for reservoir studies[J].SPE 79676,2003.
[4]于兴河.油气储层表征与随机建模的发展历程及展望[J].地学前缘,2008,15(1):1-7.
[5]Maschio C,de Carvalho C P V,Schiozer D J.A new methodology to reduce uncertainties in reservoir simulation models using observed data and sampling techniques[J].Journal of Petroleum Science and Engineering,2010,72(1):110-119.
[6]McLennan J A,Deutsch C V.Ranking geostatistical realizations by measures of connectivity[R].SPE 98168,2005.
[7]吴革洪,高才松,刘玉民.聚类分析在油藏分类中的应用[J].断块油气田,2001,8(1):36-37.
[8]霍凯中,赵永军,孙立冬.灰色聚类分析在煤层气选区评价中的应用[J].断块油气田,2007,14(2):14-17.
[9]Bandyopadhyay S ,Coyle E J.An energy efficient hierarchical clustering algorithm for wireless sensor networks[C]//Twenty-Second Annual Joint Conference of the IEEE Computer and Communications.IEEE INFOCOM,2003:1713-1723.
[10]Kriegel H P,Pfeifle M.Density-based clustering of uncertain data[C]//Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining.ACM,2005:672-677.
[11]Kanungo T,Mount D M,Netanyahu N S,et al.An efficient k-means clustering algorithm:Analysis and implementation[J].Pattern Analysis and Machine Intelligence,IEEE Transactions,2002,24(7):881-892.
[12]Hartigan J A,Wong M A.Algorithm AS 136:A K-means clustering algorithm[J].Applied statistics,1979:100-108.
[13]Jain A K,Murty M N,Flynn P J.Data clustering:A review[J].ACM Computing Surveys,1999,51(5):264-525.
[14]Sambasivam S,Theodosopoulos N.Advanced data clustering methods ofmining Web documents[J].Issues in Informing Science and Information Technology,2006(5):565-579.
[15]Caers J.Modeling Uncertainty in the Earth Sciences[J].Bulletin of the American Meteorological Society,2012,93(10):1583.
[16]周世兵,徐振源,唐旭清.K-means算法最佳聚类数确定方法[J].计算机应用,2010,30(8):1995-1998.
[17]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[18]Jain A K,Duin R P W.Statistical pattern recognition:A review[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(1):4-57.
[19]Scheidt C,Caers J.Representing spatial uncertainty using distances and kernels[J].Mathematical Geosciences,2009,41(4):597-419.
[20]Groenen P J F,Jajuga K.Fuzzy clustering with squared Minkowski distances[J].Fuzzy Sets and Systems,2001,120(2):227-237.
[21]Sherwood T,Perelman E,Hamerly G,et al.Automatically characterizing largescaleprogrambehavior[J].ACMSIGARCHComputerArchitecture News,2002,30(5):45-57.
[22]De Maesschalck R,Jouan Rimbaud D,Massart D L.The mahalanobi s distance [J].Chemometrics and intelligent laboratory systems,2000, 50(1):1-18.
[23]Huttenlocher D P,Rucklidge W J.A multi-resolution technique for comparing images using the Hausdorff distance[R].Cornell University,1992.
[24]曹京京.Hansdorff距离的计算原理及其在二维匹配中的应用[D].大连:大连理工大学,2013.
[25]Ding C,He X,Zha H,et al.Adaptive dimension reduction for clustering high dimensional data[C]//Proceedings of International Conference on Data Mining,2002.
[26]Christophe Bécavin,Nicolas Tchitchek,Colette Mintsa-Eya,et al.Improving the efficiency of multidimensional scaling in the analysis of high-dimensional data using singular value decomposition [J].Advance Access publication,2011,27(10):1413-1421.
[27]Kruskal J B.Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis[J].Psychometrika,1964,29(1):1-27.
[28]Mardia K V.Some properties of clasical multi-dimesional scaling[J].Communications in Statistics-Theory and Methods,1978,7 (13):1233-1241.
[29]Ihaka R,Gentleman R.R:a language for data analysis and graphics[J].Journal of Computational and Graphical Statistics,1996,5 (3):299-314.
[30]方匡南.基于数据挖掘的分类和聚类算法研究及R语言实现[D].广州:暨南大学,2007.
[31]Mark Chiang Ming-Tso,Mirkin Boris.Intelligent Choice of the Number of Clusters in K-means Clustering:An Experimental Study with Different Cluster Spreads[J].Journal of Classification,2010,27(1):3-40.
[32]Halkidi M,Batistakis Y,Vazirgiannis M.Clustering validity checking methods:PartⅡ[J].ACM Sigmod Record,2002,31(3):19-27.?
猜你喜欢
河北地质(2023年1期)2023-06-15 02:45:12
矿产勘查(2020年4期)2020-12-28 00:30:08
西南石油大学学报(自然科学版)(2018年6期)2018-12-26 01:00:12
西南石油大学学报(自然科学版)(2018年2期)2018-06-26 06:19:12
西南石油大学学报(自然科学版)(2018年1期)2018-02-10 05:23:30
电子测试(2017年15期)2017-12-18 07:19:27
电测与仪表(2016年12期)2016-04-11 12:25:44
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
断块油气田(2014年5期)2014-03-11 15:33:45
