
连续语音识别前端鲁棒性研究
2015-05-06 02:26曾庆宁黄桂敏
电视技术 2015年24期
胡 丹,曾庆宁,龙 超,黄桂敏
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
连续语音识别前端鲁棒性研究
胡 丹,曾庆宁,龙 超,黄桂敏
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
针对大词汇量连续语音识别中识别率不高的问题,提出了将语音增强级联在识别系统前端,在语音增强中将谱减法和对数最小均方误差算法(logmmse)与用于噪声估计的最小控制递归平均算法(imcra)相结合。识别系统使用Mel频率倒谱系数(MFCC)提取特征,用隐马尔科夫模型(HMM)训练与识别。实验结果表明,该方法最高能使单词识别率提高38.9%,使句子正确率提高21.8%。该方法用于大词汇量连续语音识别是可行有效的。
连续语音识别;语音增强;HMM;imcra;句子正确率
语音识别在通信、家庭服务、汽车电子等众多领域都有广泛应用。观看非母语视频或进行视频会议时,利用语音识别技术为视频自动加载字幕,可以在帮助人们提高听力来理解视频内容的基础上免去繁琐的手动加载字幕工作。识别技术还可以运用到视频终端领域,计算机将人的语音信号经过识别和理解转换成相应的命令,对视频终端进行操作控制,以代替鼠标键盘等手动控制方式,提高用户体验。但语音识别技术也存在一定的不足。识别系统一般是将在安静环境下训练出来的模型应用于含噪的真实环境,真实环境中含有的噪声会使系统的识别性能急剧下降,甚至无法工作,这在大词汇量连续语音识别中更是如此。噪声背景环境中的语音识别技术长期以来一直受到人们的关注,近年来在提高语音识别的抗噪能力方面,很多人做了大量的研究,在识别系统的前段应用语音增强技术抑制背景噪声就是其中的一种[1]。本文研究了一种在大词汇量连续语音识别前端级联一个语音增强系统,增强系统中将语音增强算法与噪声估计算法相结合以达到更好的去噪效果,从而增加识别系统的准确率。
1 语音增强
1.1 谱减算法
谱减算法[2](Spectral Subtraction,SS)的基本原理为,假设噪声为加性噪声,通过从带噪语音谱中减去噪声谱,就可以得到纯净的信号谱,在语音信号的间隙可以对噪声谱进行重新估计和更新。基本框图如图1所示。
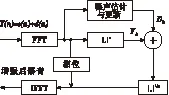
图1 谱减法框图
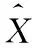
(1)
其中:α,β为参数,一般的谱减算法中α=2,β=1。
1.2 对数最小均方误差
最小均方误差[4](MMSE)是估计幅度和实际幅度均方误差最小的优化估计器,其计算式如式(2)所示
(2)

(3)
通过求解可以得到最优的对数估计器为
(4)
(5)
其中:Yk是含噪语音信号的幅度,先验信噪比为
(6)
后验信噪比λk为
(7)
式中:λX(k)和λd(k)分别为第k个频率点的信号方差和噪声方差。
1.3 改进的最小控制递归平均算法
在含噪语音中,噪声的估计是否准确关系到语音增强算法的性能[6]。如果噪声估计不准确,在谱减算法中会产生残留噪声,在对数最小均方误差算法中会导致先验信噪比估计不准,从而影响其增强效果。
传统的谱减类算法中噪声估计使用的话音活动检测(Voice Activity Detection,VAD)算法一般会从输入信号中提取一些特征(如短时能量,短时过零率),然后与无语音段得到的某个阈值进行比较,判断是否为噪声。
对于大词汇量连续语音识别来说,一个句子中包含多个单词,在每个单词的中间会有无声段的存在,VAD算法就是检测语句中无声段对应于闭塞辅音的闭合期来判断是否为噪声。但是用这种方法进行噪声谱的更新所花的时间远远大于噪声改变的时间,也就是说,噪声更新周期太长而噪声变化太快。所以需要其他更好的噪声估计方法。
噪声对语音频谱的影响在频率上并不是均匀分布的,通过带噪谱的高频区域所提取出的信息可以更可靠地估计和更新噪声谱。所以只要该频带无语音的概率很高或实际信噪比(Signal Noise Rate,SNR)很低,即可估计和更新单个频带的噪声谱,这就是递归平均型噪声估计方法[7]。
IMCRA算法对噪声的估计是通过引入一个条件语音存在概率ρ(k,l),并使用如下的递归平均得到[8]
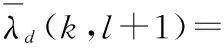
(8)
其中:k为频带序号;l为帧序号;αd(0<αd<1)是一个平滑参数;Y(k,l)为第k个频率带第l点的含噪语音幅度。为了计算式(8)中的条件语音存在概率ρ(k,l),需要进行两次平滑和最小值搜索。
首先进行功率谱的频域平滑
(9)
其中:m为连续帧个数;b(i)为加权因子。
然后对Sf(k,l)做一阶平滑回归
S(k,l)=αsS(k-1,l)+(1+αs)Sf(k,l)
(10)
其中,αs为平滑因子。
最小值搜索得
Smin(k,l)=min{S(k′,l)|k-m+1≤k′≤k}
(11)
最后可以得到语音存在概率的估计为
(12)

2 语音识别
在本文中基线系统为英语大词汇量非特定人隐马尔科夫(Hidden Markov Model,HMM)连续语音识别系统。系统首先由大量的文字生成语音模型,然后提取声学特征,经过Viterbi解码得到识别结果,系统流程图如图2所示。系统中特征提取用的是Mel频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC),采用HMM来训练声学模型。
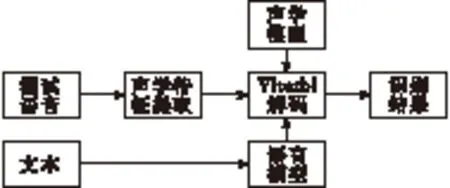
图2 语音识别系统流程图
2.1 MFCC
语音信号经过16 kHz的采样之后经过一个系统函数为H(z)=1-0.97z-1的高通滤波器,这个过程称为预加重,预加重的目的是为了补偿高频分量的损失,提升高频分量。为了将语音信号当作稳态信号来处理,将预加重后的信号进行分帧,再对信号加汉明窗以去除分帧之后的边界效应,减少频域中的泄漏。然后对信号进行快速傅里叶变换(Fast Fourier Transform,FFT),计算每一帧的的能量。把能量谱与Mel滤波器的频率响应相乘并相加。再将其取对数并经过离散余弦变换(Discrete Cosine Transform,DCT)计算12维的Mel倒谱系数,和短时能量谱一起计算其一阶和二阶差分向量,最后得到每一帧的1个39维特征向量。其过程如图3所示[9]。
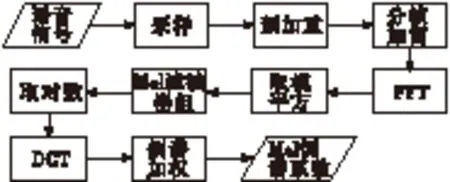
图3 MFCC提取过程
2.2 HMM
隐马尔科夫模型[10]是一种统计模型,它用来描述1个含有隐含未知参数的马尔科夫过程,广泛运用于语音识别中。1个HMM可以由λ=(N,M,π,A,B)来描述,如图4所示。其中N、M分别为马尔科夫链状态数目与观察值数目,π决定产生观测的HMM初始状态。A为状态转移概率矩阵,B为观测值概率矩阵。

图4 HMM组成示意图
HMM语音识别的过程可以分为三部分。首先根据前向后向算法和递推算法对已知模型的输出和初始模型产生输出序列的概率进行计算,然后利用BaumWelch算法和最大似然准则校正模型,最后应用Viterbi算法得到最佳识别结果。
本文使用从左向右单项带自环带跨越拓扑结构的HMM来建模,一个音节就是一个HMM,多个音节的HMM组成一个词的HMM,系统整个模型是由词和静音的HMM组成。
3 实验结果和分析
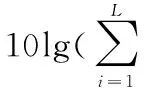
图5a~5d分别为给出了在volvo噪声和machinegun噪声环境下,通过增强算法后再进行语音识别的实验结果。
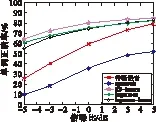
a volvo噪声环境下单词的正确率
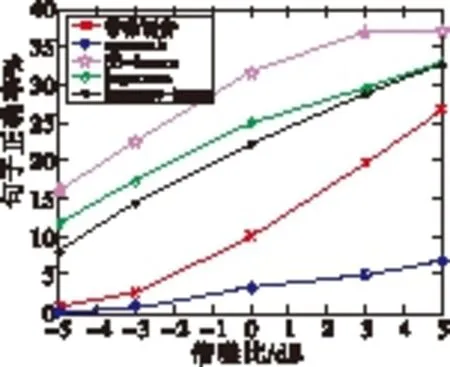
b volvo噪声环境下句子的正确率

c machinegun噪声环境下单词的正确率
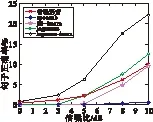
d machinegun噪声环境下句子的正确率图5 噪声背景下的识别结果
图中的“带噪语音”是指叠加噪声后的语音数据未经过增强算法直接识别的结果,“specsub”和“logmmse”为语音数据在识别之前分别经过基本谱减算法和对数最小均方误差算法,“SS_imcra”和“logmmse_imcra”分别是谱减法和对数最小均方误差在噪声估计阶段使用改进的最小递归控制平均算法。
图6a为在volvo噪声环境下应用SS_imcra分别在单词正确率和句子正确率方面提高的百分比,图6b为在machinegun噪声环境下应用logmmse_imcra在单词正确率和句子正确率方面提高的百分比。
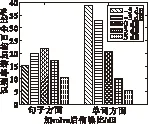
a volvo噪声

b machinegun噪声图 6 不同噪声环境下识别率提高的百分比
表1表明除单独使用谱减法外,其他算法对纯净语音的识别度并没有大的下降,说明语音增强模块并没有降低系统在安静环境下的工作性能。
表1 纯净语音的识别率
%
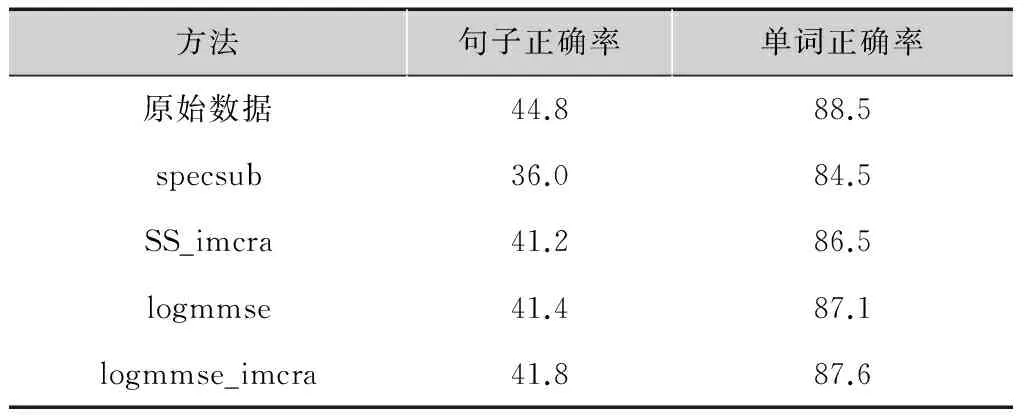
方法句子正确率单词正确率原始数据44.888.5specsub36.084.5SS_imcra41.286.5logmmse41.487.1logmmse_imcra41.887.6
图5a~5d表明并不是所有的语音增强算法都能提高连续语音识别的识别率,实验中增强部分只用传统谱减法时,单词正确率和句子正确率都有一定程度的下降。
实验结果说明:在语音识别中,应对不同种类的噪声环境应在前端应用不同的语音增强算法,例如volvo环境下,在本文的4种增强算法中,SS_imcra能有效地提高识别率,但在machinegun环境下,只有logmmse_imcra有效,其他的反而使识别率下降。
图6表明volvo噪声环境下应用SS_imcra,句子识别率在0 dB时能取得最好效果,但单词识别率在信噪比低时效果更好。machinegun环境下应用logmmse_imcra在句子的正确率方面能取得较好的效果。
4 结论
本文针对噪声环境下大词汇量连续语音识别中识别正确率不高,在语音被识别之前先通过一个语音增强系统。实验表明,不是所有的增强算法应用都能提高识别率,SS_imcra应用到volvo噪声环境下以及logmmse_imcra应用到machinegun环境下在单词和句子水平都能取得很好的效果。
[1] 徐义芳,张金杰,姚开盛,等. 语音增强用于抗噪声语音识别[J]. 清华大学学报:自然科学版,2001(1):41-45.
[2] 万义龙, 张天骐, 王志朝, 等. 基于多频带谱减法的抗噪声语音识别研究[J]. 电视技术, 2013, 37(23):183-187.
[3] LOIZOU P C. Speech enhancement: theory and practice[M]. The Chemical Rubber Company Press, 2013:75-109.
[4] GONZALEZ J, PEINADO A M, Ma N, et al. MMSE-based missing-feature reconstruction with temporal modeling for robust speech recognition[J]. IEEE Trans. Audio, Speech, and Language Processing, 2013, 21(3): 624-635.
[5] LUN D P K, SHEN T W, HO K C. A Novel expectation-maximization framework for speech enhancement in non-stationary noise environments[J]. IEEE/ACM Trans. Audio, Speech, and Language Processing,2014, 22(2): 335-346.
[6] 蔡铁, 唐飞, 龙志军. 采用子带长时信号变化特征的稳健语音活动检测[J]. 电视技术, 2014, 38(19):228-232.
[7] 张东方, 蒋建中, 张连海. 一种改进型 IMCRA 非平稳噪声估计算法[J]. 计算机工程, 2012, 38(13):270-272.
[8] COHEN I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging[J]. IEEE Trans. Speech and Audio Processing, 2003, 11(5): 466-475.
[9] 宋知用. MATLAB在语音信号分析与合成中的应用[M].北京:北京航空航天大学出版社,2013:37-42.
[10] 王炳锡,屈丹,彭煊. 实用语音识别基础[M]. 北京:国防工业出版社,2005:180-192.
胡 丹(1991— ),硕士生,主研语音信号处理;
曾庆宁(1963— ),教授,硕士生导师,主要研究方向为语音信号处理、图像信号处理、阵列信号处理;
龙 超(1966— ),女,高级实验师,主要研究方向为机器人听觉;
黄桂敏(1965— ),教授,博士生导师,主要研究方向为计算机网络。
责任编辑:时 雯
Front-end Robust Study for Continuous Speech Recognition
HU Dan, ZENG Qingning, LONG Chao, HUANG Guimin
(SchoolofInformationandCommunication,GuilinUniversityofElectronicTechnology,GuangxiGuilin541004,China)
For the accuracy rate of large vocabulary continuous speech recognition is low, using a speech enhance system before recognition is proposed. In this system, spectral subtraction and logarithmic minimum mean square error (logmmse) is combined with improved minimum controlled recursive average algorithm (imcra) which for noise estimation. In recognition system, Mel Frequency Cepstral Coefficients (MFCC) is used to extract features and Hidden Markov Model (HMM) is used to training and recognition. Experimental results show that word recognition rate increased by 38.9% and sentence accuracy rate increase by 21.8% due to the use of the method proposed in this paper. The method used for large vocabulary continuous speech recognition is feasible and effective.
continuous speech recognition; speech enhancement; HMM; imcra; sentence correct rate
国家自然科学基金项目(61461011;41201479);广西自然科学基金项目(AA053232;BA118273);桂林电子科技大学研究生科研创新项目(GDYCSZ101456)
TN912.34
A
10.16280/j.videoe.2015.24.010
2015-06-18
【本文献信息】胡丹,曾庆宁,龙超,等.连续语音识别前端鲁棒性研究[J].电视技术,2015,39(24).
猜你喜欢
中华养生保健(2020年7期)2020-11-16
计算机工程(2020年3期)2020-03-19
新世纪智能(英语备考)(2019年10期)2019-12-16
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
科学与财富(2016年21期)2017-03-02
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
中国交通信息化(2016年2期)2016-06-06
