
基于支持向量机的柴油机磨损模式识别方法
2015-05-06 03:11:54杨绍卿王宪成赵文柱
兵器装备工程学报 2015年8期
杨绍卿,王宪成,赵文柱,王 杰
(1.装甲兵工程学院 机械工程系,北京 100072; 2.辽宁石油勘探局振兴公用事业公司,盘锦 124010)
【机械制造与检测技术】
基于支持向量机的柴油机磨损模式识别方法
杨绍卿1,王宪成1,赵文柱1,王 杰2
(1.装甲兵工程学院 机械工程系,北京 100072; 2.辽宁石油勘探局振兴公用事业公司,盘锦 124010)
针对现有柴油机磨损模式判别方法中存在的不足,将支持向量机算法应用到柴油机磨损模式的识别中,建立了基于支持向量机的柴油机磨损模式判断模型,并对部分实验柴油机油液样本进行了评估,并与广义贴近算法、模糊聚类算法和专家评判结果进行了比较,证明了支持向量机能够准确、有效地识别柴油机磨损模式。
支持向量机;磨损模式;柴油机;油液分析
汇集柴油机多种油液并进行分析的油液监测技术是柴油机磨损模式评判和监测的有效手段之一[1],其基本原理为:在柴油机使用过程中,由于各个摩擦副的正常或异常磨损,会产生大量磨损颗粒,磨损颗粒则在润滑过程中被润滑油带走。应用油液监测技术,通过采集、分析润滑油油样,分析其中各类颗粒的浓度,从而利用各类算法对柴油机磨损模式进行识别、分析,并判断其劣化程度。
在众多油液分析方法中,目前主流的方法有基于广义贴近度的模糊识别法[2]、模糊逻辑法[3]、基于证据理论的时域数据融合识别方法[4]等,但这些方法存在计算过程复杂、平滑因子等中间参数不易确定、只能得到局部最优解等一系列问题。
支持向量机是基于结构风险最小化的理论,较好地克服了一般神经网络训练速度较慢的缺点,对解决小样本的模式分类问题具有相当的优势。本研究在柴油机光谱、铁谱监测数据处理的基础上,将支持向量机应用在磨损模式识别中,较好地识别了柴油机磨损模式。
1 磨损模式识别原理
柴油机磨损类型通常可以分为正常磨损、黏着磨损、切削磨损、疲劳磨损和腐蚀磨损5个基本磨损类型[5],其磨损程度可划分为轻微磨损、正常磨损、异常磨损和剧烈磨损4种程度[6]。监测作为摩擦副磨损产物主要载体的润滑油,可由此分析柴油机的磨损类型和磨损程度。对润滑油油样的主要监测指标包括:定量铁谱磨损剧烈程度指数、磨粒数量、大磨粒百分比以及金属元素含量[6]。不同的磨损形式与各个指标存在着复杂的对应关系,各磨损状态之间的划分也具有相当的模糊性。磨损过程十分复杂,磨粒类型、数量与磨损机理之间不可能是唯一的对应关系。
依据柴油机润滑油油样中磨粒的类型与数量,对照该型号发动机磨损模式磨粒标准模型库(表1)[3],可以建模判断发动机的磨损形式。

表1 某型发动机磨损模式磨粒描述标准模型库
根据柴油机磨损特点,对比大量柴油机油样铁谱分析的数据统计,参照基于广义贴近度的模糊识别方法和专家评价法,可将磨粒数量划分为无、少量、中量和大量4个等级(表2),并将磨粒数量等值指标化[7]。其中腐蚀磨粒的量化值为(Dmax-Dmin),无量纲。

表2 定性表达量化指标
传统磨损模式识别主要由人工判断,通常通过对比油样磨粒种类与表1凭借经验识别。利用计算智能识别磨损模式的方法主要包括模糊聚类法、灰色关联分析、人工神经网络、证据理论等,综合对比已建立的磨损模式识别标准库进行自动识别,供发动机磨损模式识别参考。
2 识别模型构建
2.1 支持向量机理论
1963年,贝尔实验室的Vapnik在解决模式识别问题时提出了“支持向量”的方法,支持向量机的基本思想,是从训练集中选择一组样本子集,使得对样本子集的划分等价于对整个数据集的划分,即将低维样本空间通过关系Φ(x)映射到高维空间,实现低维样本的线性可分,同时构造最优分类超平面,实现分类[8]。这组样本子集称为支持向量。
对训练样本集(xi,yi),i=1,…,n,x∈Rd,y∈(1,-1),x为训练样本特征向量,y为类别标号,n为样本数,d为输入维数。线性可分的情况下,在高维空间内,最优分类平面可以表示如下
w·Φ(x)+b=0
(1)
其中:w为分类面的权系数向量;b为分类阈值。
为了避免数值计算,对w和Φ(x)都进行归一化处理,因其分量值都属于{0,1},使得对线性可分的样本集(xi,yi),i=1,…,n,x∈Rd,y∈(1,-1)满足约束条件:
yi·{Φ(x)+b}≥1-ξi,i=0,…,n
(2)
其中,ξi为松弛变量。

有约束条件
(3)
构造拉格朗日函数
(4)
构造核函数C(xi,xj),以用原空间函数表达高维特征空间内的内积运算[8]。
构造满足梅瑟条件[9]的核函数
C(xi,xj)=Φ(xi)·Φ(xj)
(5)
代入式(4),得到
(6)
根据科恩特克[10]条件,由式(2),可得到优化系数αi应满足
αi{yi[w·Φ(x)+b]+ξi-1}=0
(7)
其中非零的αi为原问题中每个与约束条件对应的拉格朗日乘子。问题转化为不等式约束下的二次函数求最值问题,存在唯一解[11]。容易证明,诸解中只有少部分αi不为零,对应的样本为支持向量,从而可以得出最优分类函数:
f(x)=sgn{[w·Φ(x)]+b}
(8)
即
(9)
分类函数f(x)的正负即可判断样本的分类结果。
2.2 特征向量提取
支持向量机是一个二分器,无法进行多类分类。因此,采用支持向量机理论中的有向无环图(Directed Acyclic Graph,DAG)算法[12]构建评估模型。
在多个“一对一”二元子分类器进行组合的过程中,将多个二元分类器组合成一个多元分类器。对于一个m元的问题,DAG共含有m(m-1)/2个节点,对应m(m-1)/2个二元分类器,分布于m层结构中。其拓扑结构如图1所示,顶层只含有1个节点,称为根节点,第二层含有2个节点,依此类推,第i层有i个节点,最底层含有m个叶节点,中间第j层的第i个节点指向第j+1层的第i个和第i+1个节点。
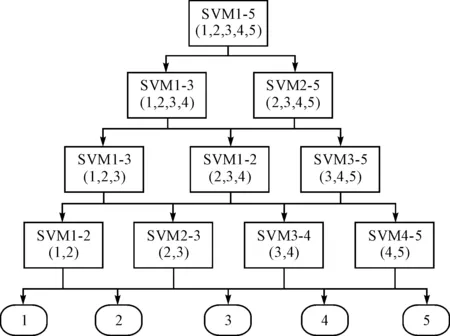
图1 磨损类型的DAG分类模型结构
对于给定的输入样本S,从根节点出发,计算每个节点的决策函数值,若为1,则从右侧进入下一节点,若为-1,则从左侧进入下一节点,以此类推,在最后一层叶节点的输出就表示了输入样本S所属的类别。
对于待验证的油样S1,首先可根据表2将油样中各成分的磨粒数量划分入某一等级,即无、少量、中等和大量4个等级,分别定义为1、2、3、4,以此构成特征向量xi={x1,x2,…,x11},为判断柴油机磨损模式的特征向量。坐标xi分别对应正常磨粒、切削磨粒、疲劳磨粒、球状磨粒、严重滑动磨粒、片状磨粒、红色氧化物磨粒、黑色氧化物磨粒、腐蚀磨粒、非金属磨粒和污染物颗粒数量的等级,构成了训练样本特征向量xi={x1,x2,…,x11}。
2.3 分类算法
在对训练样本进行分类时,需要计算各类之间的分离度。由于各个磨损类型之间磨粒浓度区分存在一定的模糊性,如图2所示,两组类间隔的欧几里得距离相等,但离散度不同,如直接使用欧几里得距离进行分类,很可能会出现分类错误的情况,因此欧几里得距离在油液样本分类中显然不适用。此处采用考虑关联性的类间分离度[12]来评定。
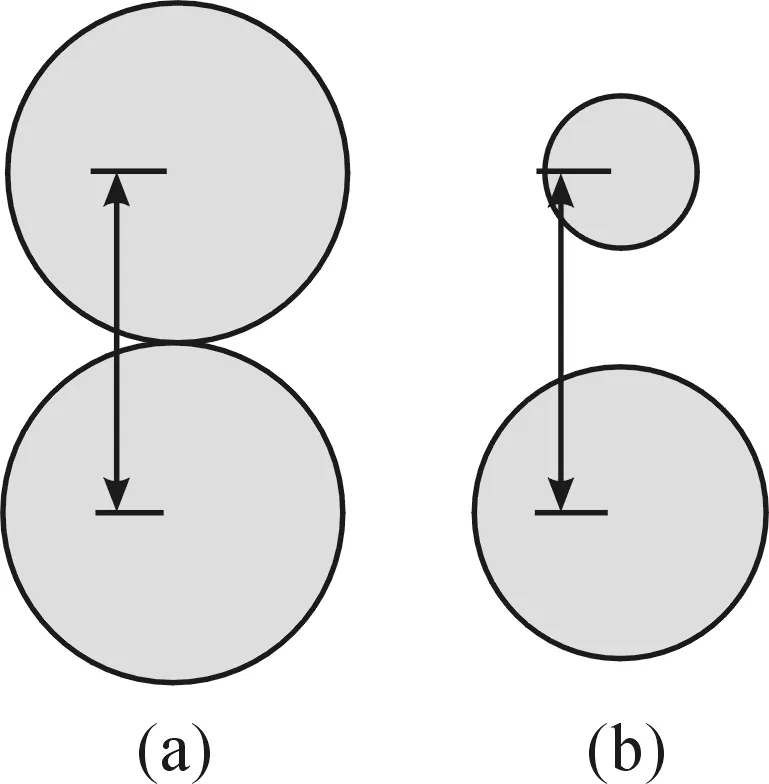
图2 类间分离度示意
假设有i个类别的训练数据x={x1,x2,…,xi},定义第k类和第j类之间的分离度skj为:
(10)
dkj=‖Ck-Cj‖
(11)
(12)

(13)
其中:dkj表示第k类和第j类之间的欧几里得距离;Cm(m=1,2,…,i)表示各类训练样本的均值中心;lm为第m类的样本个数,σm为其标准差。
将类间分离度计算代入磨损类型的DAG分类模型:

3 实例分析
将训练样本带入修正后的DAG分类模型中,就构成了一个11维样本分类问题。样本运行至每一个节点处,都由分类函数判断样本进入的次级节点,最终叶节点的输出即可判断油样S1所属的类,即油液样本所述的磨损类别。
为验证支持向量机方法的准确性,本研究收集了某型柴油机的12份铁谱分析油样[7,13]作为待识别样本(表3)。其样本已分别应用广义贴近度算法、基于BP神经网络的识别算法以及专家评判法进行了分析,最后结果与支持向量机方法相比较。
由表4的结果可以看出,上述支持向量机模型对12份样本进行识别,判断正确11个,基本达到工程应用的要求。
其中6号油样判断错误。由此推断,此支持向量机模型在界定腐蚀磨损和疲劳磨损时可能出现识别错误。
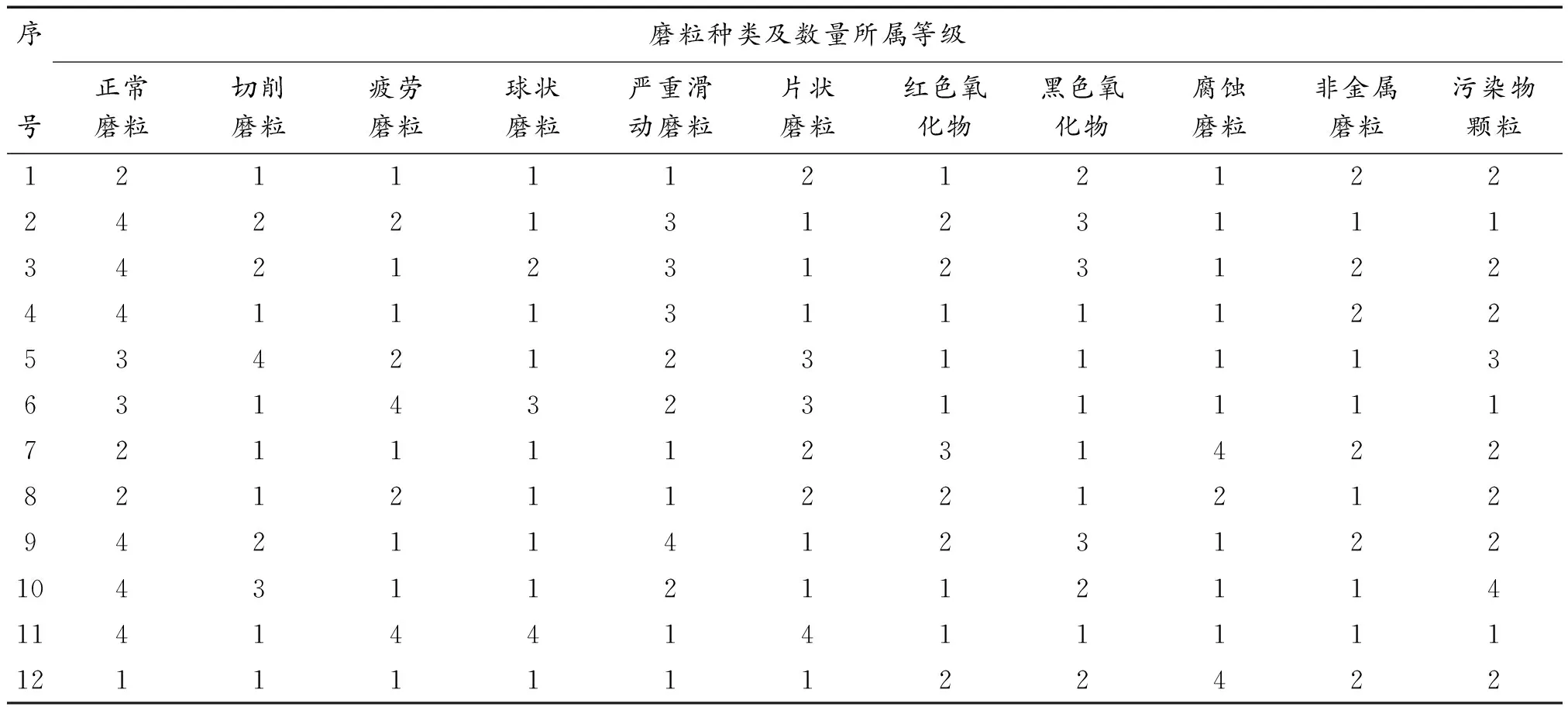
表3 某型柴油机待识别铁谱分析油样
考察出现误差的原因,支持向量机在对样本进行分类时,如果样本位于支持向量机的分类间隔内,则有一定概率出现误判。此时最优分类平面无法分离两个接近的类,导致在叶节点输出出现判断失误。由上述类之间的分离度skj可知,其出现误判的原因可能是腐蚀磨损和疲劳磨损之间的分离度较小。考虑支持向量机本身的性质,现有的解决方法是:① 如果样本数量较少,则由人工来进行修正识别;② 如果样本量较大时,需要在之前修正的基础上,在分离度较低、容易出现误判的两个样本之间,再应用加权算法构造一个新的支持向量机,通过子分类平面先对两个接近的类进行区分,再带入DAG中进行判断,以达到区分两个样本的效果。

表4 磨损模式识别结果
4 结论
支持向量机算法对标准样本量要求较小,判断迅速、准确,能够达到工程运用要求,是识别发动机磨损模式的一种可行方法。
[1] 杨其民.磨粒分析[M].北京:中国铁道出版社, 2002:1-3.
[2] 王琳,刘佐民.发动机排气门失效机理研究的国外概况[J].武汉工业大学学报, 2000,22(5):83-88.
[3] 李晓峰,严新平,史铁林,等.柴油机主要摩擦副磨损型式的识别[J].润滑与密封, 1998, 125(6):24-26.
[4] 严志军,朱新河,程东,等.基于信息融合技术的柴油机磨损模式识别方法[J].大连海事大学学报, 2002,13(2):53-55.
[5] 魏春源.高等内燃机学[M].北京:北京理工大学出版社, 2001:60-62.
[6] 雅克里格.柴油机的机油光谱分析检查[M].北京:中国铁道出版社,1980:18-19.
[7] 严志军,朱新河,贾珊中.基于广义贴进度的船用柴油机磨损模式识别方法[J].润滑与密封,2000(1):5-8.
[8] 于跃.一种基于核聚类的模糊支持向量机方法[J].科技通报,2013,29(10):133-135.
[9] 史忠植.知识发现[M].2版.北京:清华大学出版社,2011.
[10]何学文.基于支持向量机的故障分类器研究[D].长沙:中南大学,2004.
[11]Chrisianini N,Shaw Taylor J.支持向量机导论[M].李国正,王猛,曾华军,等,译.北京:电子工业出版社,2004.
[12]王艳,陈欢欢,沈毅.有向无环图的多类支持向量机分类算法[J].电机与控制学报,2011,15(4):85-89.
[13]李兵,张培林,傅建平.基于加权模糊优选理论的发动机磨损模式识别[J].润滑与密封,2006(5):115-117.
(责任编辑 唐定国)
Wear Mode Recognition Method of Diesel Engines Based on Support Vector Machine
YANG Shao-qing1, WANG Xian-cheng1, ZHAO Wen-zhu1,WANG Jie2
(1.Department of Mechanical Engineering, Academy of Armored Force Engineering, Beijing 100072, China; 2.Liaohe Oil Survey Revitalization of Utility, Panjin 124010, China)
In view of the existing shortcomings on the course of wear mode identifying method on diesel engines, the support vector machine (SVM) algorithm was applied to the wear mode identifying. The recognition mode for the wear of diesel engine which was based on the SVM algorithm was established, and several oil samples of experimental diesel engines were estimated. The result was compared with results of generalized closeness degree algorithm, fuzzy clustering algorithm and expert assessment, and we proved that the wear mode of diesel engine can be effectively and accurately recognized by the SVM method.
SVM; wear mode; diesel engines; oil sample estimation
2015-02-24
杨绍卿(1991—),男,硕士研究生,主要从事柴油机缸套磨损研究;王宪成(1964—),男,博士,教授,主要从事柴油机技术状况系统论证与应用研究。
10.11809/scbgxb2015.08.024
杨绍卿,王宪成,赵文柱,等.基于支持向量机的柴油机磨损模式识别方法[J].四川兵工学报,2015(8):96-99.
format:YANG Shao-qing, WANG Xian-cheng, ZHAO Wen-zhu,et al.Wear Mode Recognition Method of Diesel Engines Based on Support Vector Machine[J].Journal of Sichuan Ordnance,2015(8):96-99.
TK421.2;TJ8
A
1006-0707(2015)08-0096-04
猜你喜欢
润滑与密封(2023年7期)2023-07-28 03:28:24
石油炼制与化工(2022年12期)2022-12-15 11:38:44
西安石油大学学报(自然科学版)(2022年4期)2022-07-28 09:20:44
中国机械工程(2022年2期)2022-01-27 07:53:28
硅酸盐通报(2021年3期)2021-04-18 11:01:42
表面工程与再制造(2019年3期)2019-09-18 01:35:10
石油学报(石油加工)(2019年2期)2019-03-22 06:00:58
制造技术与机床(2017年4期)2017-06-22 11:18:24
电子测试(2017年23期)2017-04-04 05:06:50
智能系统学报(2017年5期)2017-01-22 11:21:30
