
基于选择学习机制的深度图像超分辨率算法
2015-05-05 13:01任晓芳王红梅王爱民
电视技术 2015年17期
任晓芳,王红梅,王爱民,杨 杰
(新疆工程学院 计算机工程系,新疆 乌鲁木齐 830052)
基于选择学习机制的深度图像超分辨率算法
任晓芳,王红梅,王爱民,杨 杰
(新疆工程学院 计算机工程系,新疆 乌鲁木齐 830052)
针对深度图像传感器与彩色图像传感器的空间分辨率较差的问题,提出一种提高深度图像分辨率的算法,不同于传统方法。该算法是基于机器学习的超分辨率选择机制,选择均值型、最大值型和中值型三种滤波器方法作为候选方法。首先运用高分辨率深度图像下采样和高分辨率彩色图像选择最优的滤波器,同时经过特征提取获得特征集;然后,高分辨率深度图像直接通过最优滤波器获得特征集;
深度图像;超分辨率;机器学习;支持向量机;飞行时间
超分辨率技术从提出到发展已近30年,在安防、医学、军事等领域运用广泛,从2D图像到3D图像都有很多经典技术。在3D图像和视频应用中,估计或获取高分辨率深度图像很关键。最近立体匹配技术[1]利用图形硬件和商业深度传感器能实时重建高质量深度图像,例如基于结构光源深度摄像机[2]实时捕捉手势和身体姿势估计高质量深度图像。因为在许多视觉应用中,例如3D重建和多视图呈现,需要彩色图像以及深度图像,因此人们提出了混合相机的结构,它包括立体加深度[3]和颜色加深度[4-5]。其中,颜色加深度由于简单性所以更容易实现。
颜色加深度的一个关键问题是深度传感器与图像传感器相比存在较差的空间分辨率。因此,一种提高深度图像空间分辨率的技术被提出来,即深度图像超分辨率技术。为了实现这个目的,文献[6-9]介绍了各种深度图像超分辨率算法。文献[6]提出了一种局部直方图,该直方图利用相邻颜色和深度像素插值每个像素并且作为概率密度函数(pdf),将最大pdf作为目标深度值。然而,本文发现这样的策略并非总能达到最佳超分辨率性能,因为有时在插值深度边缘会产生伪影。文献[7]是对飞行时间相机获得的深度图像进行超分辨率重建,结合局部和非局部相似性约束,同场景的高分辨率场景彩色图像的自适应权重滤波,虽然取得一定效果,但颜色边缘不一致,而且不具有实时性。文献[8]提出了一种自适应中值滤波器和双边滤波器上采样深度图像,这种方法可以产生不存在纹理复制问题的锐化边缘,但是获取的深度边缘与颜色边缘十分不一致,因为在超分辨率深度图像中没有使用彩色信息。文献[9]讨论了飞行时间相机、基于马尔可夫随机场(MRF)框架的超分辨率技术、最大后验概率(MAP)等超分辨率技术、小波在超分辨率技术的应用等,提出将参数模型融入到正则化约束项对深度图像局部边缘进行约束,该模型是针对彩色图像局部结构特征的深度图像超分辨率。
上述和其他许多深度图像超分辨技术试图找到一个有效的滤波器方案或者联合一些滤波器方法。本文假设没有一种滤波器性能普遍优于其他滤波器,且启发式滤波器组合方法总存在改进空间。从这个观点看,本文超分辨率深度图像采用机器学习技术。由于存在颜色加深度图像数据库[10],因此训练图像由低分辨率(LR)深度图像和与其对应的高分辨率(HR)彩色深度图像对组成。给定训练样本和多个候选滤波器,本文可以观察到哪些滤波器性能最好,哪些因素影响滤波器性能。为了实现这个目的,采用与文献[6]相似方法生成直方图,然后从直方图提取一种频域特征向量,特征向量很好地描述了滤波器选择模式。最终利用训练样本和特征向量训练支持向量机(SVM)分类器。另外本文设计了一种频域特征向量,该向量能明显区分不同特点滤波器。
1 滤波器选择与特征提取
本文假定彩色和深度图像是一致的。当分别使用彩色和深度传感器时,传统解决方案将深度图像像素坐标系转换到彩色图像像素坐标系[6]。因此超分辨率深度图像的问题转换为寻找彩色像素坐标系的深度值。
1.1 候选滤波器
设C和DL分别表示HR彩色图像和与其对应的LR深度图像。映射DL到彩色图像坐标系,获取部分填充深度像素的HR深度图像,表示为D。超分辨率深度图像的目标是对D应用空间不同滤波器,使得D中所有像素有精确的深度值。
许多传统深度上采样算法[6,11]通过下式寻找D中像素p的深度值d
C(q))GD(d-D(q))
(1)
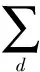
在传统的联合双边均值滤波(JBAF)中[12],使用下式获取深度值
(2)
式中:通过设置σD=0将深度高斯函数变为σ函数。因为JBAF的滤波器系数由像素间的色差决定,因此D的深度边缘可以很好地结合C的彩色边缘。然而,由于在式(1)的和中,小权重细微的影响,D中会出现不必要的模糊。
为了解决JBAF的问题,本文提出了权重滤波器(WMF)[6],定义如下
(3)
即WMF选择最大化权重分布的深度值,因为滤波器中选择非线性操作,可以减少不必要的模糊。然而,WMF获取的深度边缘往往不能准确地与彩色图像边缘对齐。文献[6]发现JBAF和WMF分别在L2范式和L1范式下能有效最小化。
同时,中值滤波器也使用在彩色和深度图像超分辨率中[13]。对不为整数的权重值,通过下式获取中值滤波器
(4)
因为在深度图像滤波器中使用色差,所以本文称这种滤波器为联合双边中值滤波器(JBMF)。
滤波器的选择依赖于权重分布的特点,本文采用基于学习的方法,使用大量数据库训练分类器。将JBAF、WMF和JBMF作为候选滤波器,因为它们存在比较明显的特征。基于学习的框架必要时还包括任何额外滤波器。此外,等式(1)的相同权重用作3个滤波器的权重分布。因为深度高斯函数考虑了深度信号的可用性[6],因此本文实验中JBAF也使用深度高斯函数,其中σD≠0。本文更关心新权重分布的设计。
1.2 特征提取
特征提取在基于学习的算法中扮演很重要的角色。提取的特征要能很容易区分不同特点滤波器。在上小节中,观察到权重分布的变化与滤波器选择有关。为了实现这个目的,从权重分布提取特征向量需要考虑2个方面内容:首先,权重分布的绝对位置不能决定滤波器的选择。例如,从 163~177的非0位置,在这种情况下,JBAF为最佳滤波器,因为无论位置范围向左偏移还是向右偏移,JBAF都没有变化;第二,在权重分布中存在多种分离模式影响滤波器的选择,因此,隔非零值位置对滤波器选择很重要。
考虑上面的2个方面,2种向量vω和vs定义如下
(5)
(6)
为简单起见,从H(p,d)式中忽略像素坐标系p。向量vω和vs分别由对应权重分布的非0值位置的权重值和2个连续非零位置的间隔组成。设N和N-1分别为vω和vs的长度。根据定义的向量vω和vs,每个像素的N种变化依赖于权重分布的稀疏性。因此本文定义固定长度L且更改向量为下式
(7)
k
(8)
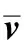
(9)
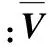
(10)
在基于学习的超分辨率深度图像中使用特征向量V。图1显示了本文频域特征的有效性。红圈、绿叉和蓝点分别表示JBAF、WMF和JBMF的特征向量(原图为彩图)。随机从每个训练集选择100个特征向量,通过LDA获取x轴和y轴组件。根据线性判别分析(LDA)[15],从图中可以看出频域特征与空域特征相比有较好的性能。分类准确性根据SVM训练样本的10折交叉验证衡量。空域和频域特征向量的分类准确率分别为72.4%和80%。
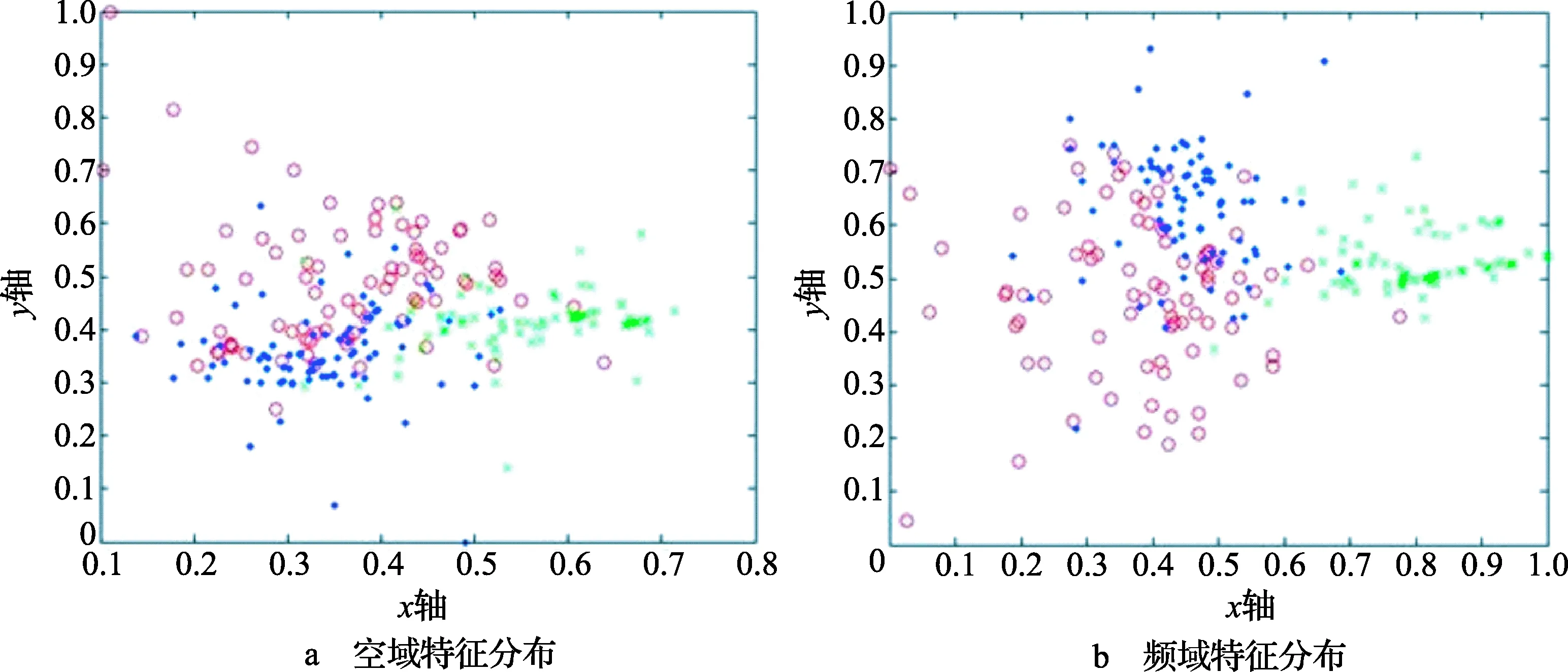
图1 频域特征有效性
2 本文整体构架
本文基于学习的算法由训练阶段和测试阶段组成。图2显示了获取滤波器分类器的训练阶段。给定的HR彩色图像和深度图像对作为训练集,通过HR深度图像下采样获取LR深度图像,然后对HR彩色图像和LR深度图像的所有像素应用JBAF、WMF和JBMF进行插值。因为本文在训练阶段存在真实HR深度图像,所以对每个像素,本文可以检测到哪个滤波器获取的像素深度值与真实值相同。为了联合特征向量,首先生成JBAF、WMF和JBMF的3个空集。如果对于一个像素,一种滤波器的性能超过其他滤波器,将它的特征向量V包含在相应的集合中。

图2 训练阶段流程图
图3显示了获取HR深度图像的测试阶段。当LR深度图像和HR彩色图像作为输入时,LR深度图像首先映射到彩色像素坐标系中。对每个将要插值的像素,从等式(1)获取权重分布。然后从权重分布获取特征向量,如1.2节所示。滤波器分类器最后决定像素需要那种分类器。对所有没有深度值的像素应用以上过程,可以构建HR深度图像。
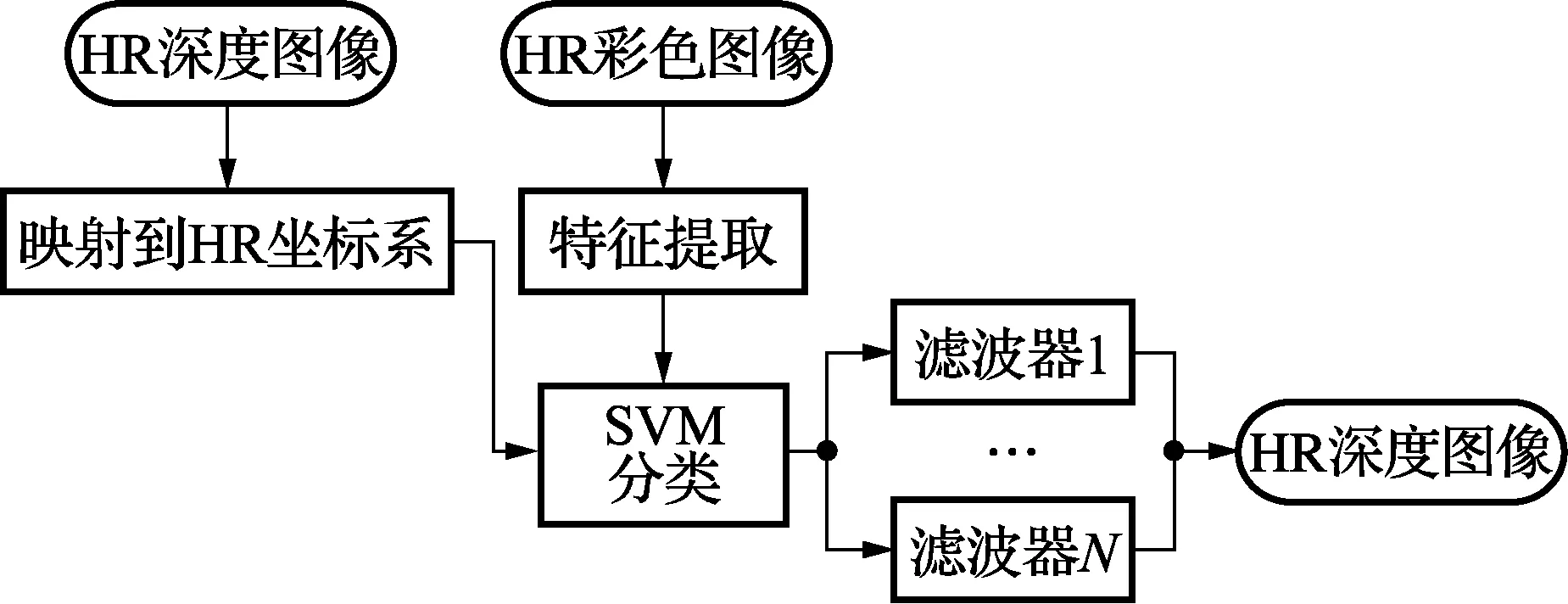
图3 测试阶段流程图
3 实验结果
本文首先在Middlebury 2001 和2003数据库上测量本文算法性能。然后本文将该算法应用于实际环境且定性评价其性能。等式(1)的标准偏差GS,GC,GD分别选择7,6和2.9。文献[6]详细描述了这些参数。
本文算法与其他5种算法做了比较。前三种算法分别为WMF,JBAF和JBMF。第四种算法为基于WMF,JBAF和JBMF中最佳滤波器的方法。更具体地说,最佳滤波器获取的深度值最接近真实HR深度值。本文算法的上限通过这种方法衡量,称之为第四种算法为理想方法。最后,传统超分辨率深度图像的性能,称为广义总变化各向异性(ATGV)算法[16]。该算法也与上面算法相比较,使用作者提供的软件获取实验结果。
图4所示为4个广泛使用的测试图像,这些图像没有包含在训练图像中,且被用来评价本文算法性能。图4c和图4d所示为真实深度图像中一些丢失的像素。这些丢失的像素没有包括在定量评价中[10]。然后对HR深度图像分别使用采样因子为4和8的下采样。此外,噪声LR深度图像也作为输入图像。为了考虑现实环境,本文模拟ToF深度摄像机的噪声模型,该摄像机模型的LR问题比基于结构化光源的深度摄像机更严重。众所周知,ToF深度噪声的标准偏差与图像像素值返回传感器的强度成反比(通常,红外线发射,然后返回)。通过考虑返回光的色度饱和度强度(HIS)颜色空间的彩色图像的强度组件,将噪声强度依赖添加到无噪声深度图像。更具体地说, 对位置为 (x,y) 的每个像素加入标准
偏差为σN(x,y)的高斯噪声,其中σN(x,y)定义如下
(11)
式中:CI(x,y)表示彩色图像中位置为(x,y)的像素在HIS空间的强度值。为了仿真ToF深度摄像机的噪声,给定的差异值首先转换为深度值且将噪声添加到深度空间。然后噪声深度值返回到噪声差异值。微调等式(11)的常数k,使得无噪声和噪声差异图像间的RMSE值近似于5(容忍度为0.01)。

图4 原彩色和深度图像对
表1和表2给出了算法性能的评价结果。统计没有正确匹配的像素数所占的百分比,绝对误差大于一个像素。分别将深度值连续区域和不连续区域的像素作为评价依据。文献[10]介绍了定量评价的细节。实验结果显示本文算法性能优于ATGV和分别使用WMF、JBAF和JBMF算法。特别地,当使用噪声深度图像时,该算法的性能仍然优于这些算法,表明本文滤波器分类器对深度噪声不敏感。然而,仍然存在本文算法和理想算法之间不可忽略的性能差距。本文凭经验发现实验中使用的三种滤波器不能完全可分。特别地,JBAF和JBMF输出的均值和中值常常相似,如图2所示,因此在训练阶段很难将两者完全分开。
表1 无噪声的深度图像被用作输入时,各种超分辨率深度图像算法没有匹配的像素百分比 %
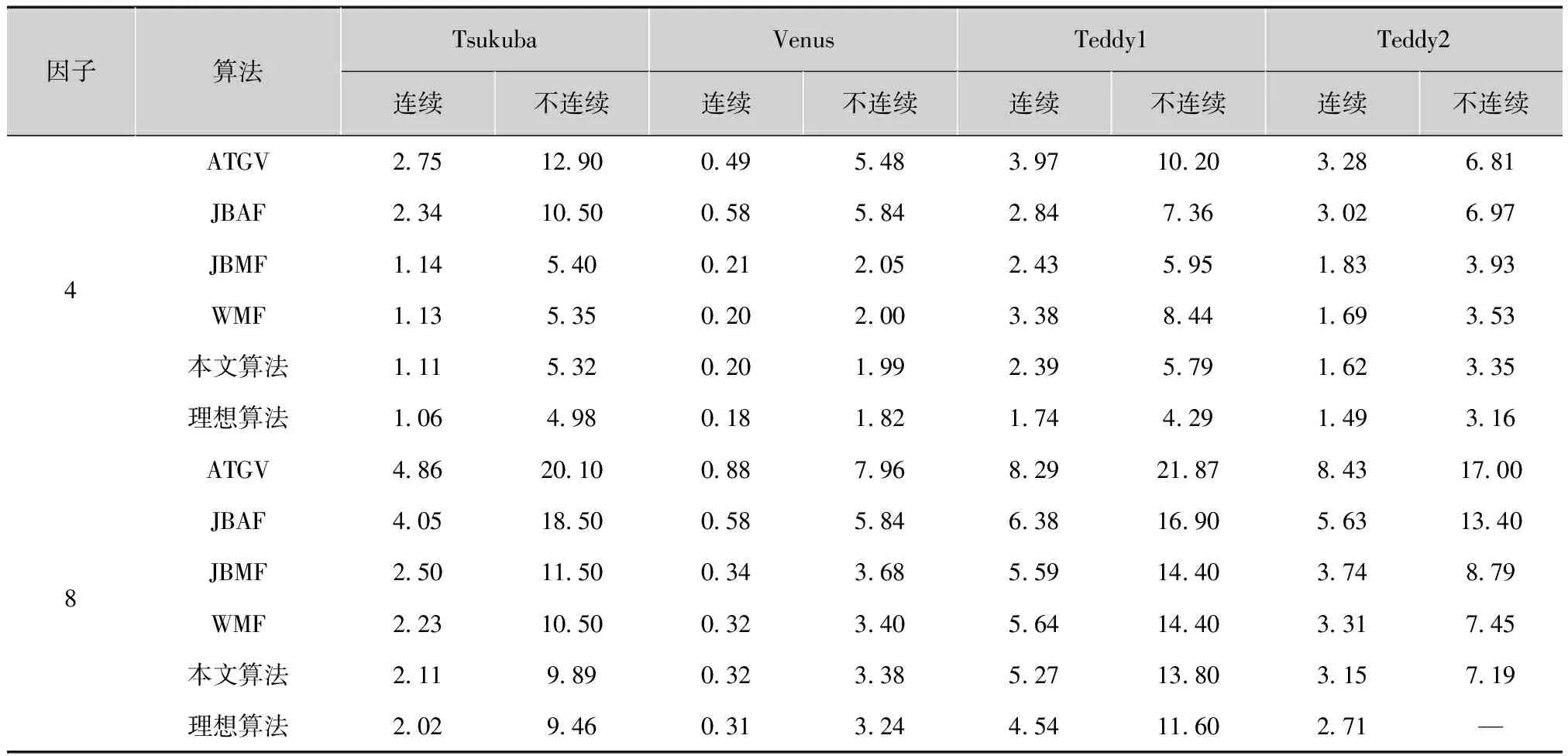
因子算法TsukubaVenusTeddy1Teddy2连续不连续连续不连续连续不连续连续不连续4ATGV27512900495483971020328681JBAF2341050058584284736302697JBMF114540021205243595183393WMF113535020200338844169353本文算法111532020199239579162335理想算法1064980181821744291493168ATGV486201008879682921878431700JBAF405185005858463816905631340JBMF25011500343685591440374879WMF22310500323405641440331745本文算法2119890323385271380315719理想算法2029460313244541160271—
表2 有噪声的深度图像被用作输入时,各种超分辨率深度图像算法没有匹配的像素百分比 %
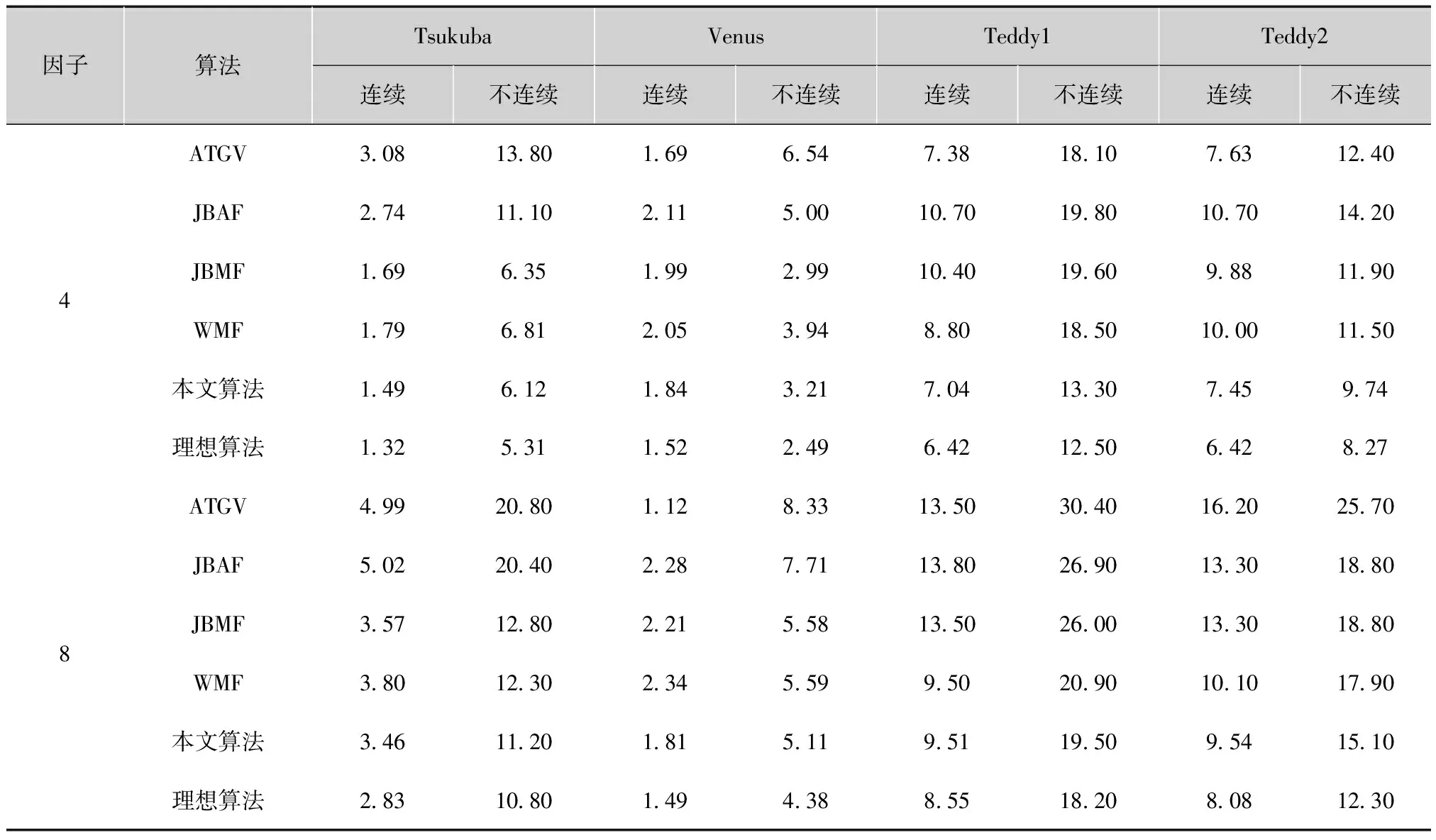
因子算法TsukubaVenusTeddy1Teddy2连续不连续连续不连续连续不连续连续不连续4ATGV308138016965473818107631240JBAF27411102115001070198010701420JBMF169635199299104019609881190WMF179681205394880185010001150本文算法1496121843217041330745974理想算法13253115224964212506428278ATGV49920801128331350304016202570JBAF50220402287711380269013301880JBMF35712802215581350260013301880WMF3801230234559950209010101790本文算法346112018151195119509541510理想算法283108014943885518208081230
图5显示了根据无噪声的LR深度图像重建的HR深度图像。为了可视化,只放大深度不连续区域。从图中可以看出本文算法重构的HR深度图像精度较高。JBAF产生了不必要的模糊,而WMF常常导致边缘附近产生伪影,因为它常常选择最大化权重分布的深度值。通过JBMF获取深度图像的边缘锐化程度位于WMF和ATGV之间。ATGV算法在深度边缘附近也表现出了不可忽视的伪影。图6显示了根据有噪声的LR深度图像重建的HR深度图像。与有噪声区域相比较,所有算法都明显提高了图像深度质量。特别地,ATGV算法表现Venus数据库图像平面更好,但是在Tsukuba和Teddy数据库图像上出现不精确的深度边缘。在总体上,本文算法与其他算法相比产生了比较少的伪影。

图5 HR深度图像的放大,对无噪声深度图像使用采样因子为4的下采样且作为输入

图6 HR深度图像的放大,对有噪声深度图像使用采样因子为4的下采样且作为输入
4 总结与展望
本文提出了一种基于学习的深度图像超分辨率滤波器选择方法。训练分类器使得算法能有效选择每个像素的最佳滤波器。另外本文设计新的频域特征,该特征提高了算法区分不同滤波器方法的能力。使用合成数据库、真彩色和深度图像论证本文算法的有效性,以及对噪声图像的鲁棒性。
由于本文考虑的是超分辨率深度图像而不是超分辨率深度视频。在视频中,超分辨率深度图像的时间一致性需要考虑。因此,提高本文算法的时间一致性来处理超分辨率深度视频将是下一步研究的重点。
[1] KOWALCZUK J, PSOTA E T, PEREZ L C. Real-time stereo matching on CUDA using an iterative refinement method for adaptive support-weight correspondences[J]. IEEE Trans. Circuits and Systems for Video Technology, 2013, 23(1): 94-104.
[2] ZHANG Z. Microsoft kinect sensor and its effect[J].IEEE Multimedia, 2012, 19(2): 4-10.
[3] 赵兴朋. 视频图像2D转3D算法研究及硬件实现[D]. 青岛:中国海洋大学, 2012.
[4] 杨宇翔, 汪增福. 基于彩色图像局部结构特征的深度图超分辨率算法[J]. 模式识别与人工智能, 2013, 21(5) : 245-251.
[5] JUNG S W. Enhancement of image and depth map using adaptive joint trilateral filter[J].IEEE Trans. Circuits and Systems for Video Technology, 2013, 23(2): 258-269.
[6] MIN D, LU J, DO M N. Depth video enhancement based on weighted mode filtering[J]. IEEE Trans. Image Processing, 2012, 21(3): 1176-1190.
[7] 杨宇翔, 曾毓, 何志伟,等. 基于自适应权值滤波的深度图像超分辨率重建[J]. 中国图象图形学报, 2014, 19(8) : 112-118.
[8] OH K J, YEA S, VETRO A, et al. Depth reconstruction filter and down/up sampling for depth coding in 3-D video[J]. IEEE Signal Processing Letters, 2009, 16(9): 747-750.
[9] 杨宇翔. 图像超分辨率重建算法研究[D].合肥:中国科学技术大学, 2013.
[10] SCHARSTEIN D, SZELISKI R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1-3): 7-42.
[11] GARCIA F, MIRBACH B, OTTERSTEN B, et al. Pixel weighted average strategy for depth sensor data fusion[C]//Proc. 17th IEEE International Conference on Image Processing (ICIP), 2010. [S.l.]:IEEE Press, 2010, 34(19) : 2805-2808.
[12] KOPH J, COHEN M F, LISCHINSKI D, et al. Joint bilateral upsampling[C]//Proc. ACM Trans. Graphics (TOG). [S.l.]:ACM, 2007, 26(3): 96-102.
[13] OH K J, YEA S, VETRO A, et al. Depth reconstruction filter and down/up sampling for depth coding in 3-D video[J].IEEE Signal Processing Letters, 2009, 16(9): 747-750.
[14] 琚生根, 周激流, 何坤,等. 频域光照归一化的人脸识别[J].电子科技大学学报, 2009, 28(6) :1021-1025.
[15] 杨健, 杨静宇, 叶晖. Fisher线性鉴别分析的理论研究及其应用[J]. 自动化学报, 2003, 21(4) : 124-130.
[16] FERSTL D, REINBACHER C, RANFTL R, et al. Image guided depth upsampling using anisotropic total generalized variation[C]//Proc. 2013 IEEE International Conference on Computer Vision (ICCV).[S.l.]:IEEE Press, 2013, 24(21): 993-1000.
任晓芳(1979— ),女,硕士,讲师,主要研究领域为多媒体、图像处理等;
王红梅(1982— ),女,硕士,讲师,主要研究领域为多媒体、软件工程;
王爱民(1970— ),女,硕士,副教授,主要研究领域为多媒体、软件工程等;
杨 杰(1968— ),女,副教授,主要研究领域为计算机应用、软件工程等。
责任编辑:任健男
Learning-based Filter Selection Scheme for Depth Image Super Resolution
REN Xiaofang, WANG Hongmei, WANG Aimin, YANG Jie
(DepartmentofComputerEngineering,XinjiangInstituteofEngineering,Urumqi830052,China)
Since the resolution of depth image sensors and color image sensors are very low,an algorithm is proposed to improve resolution. Unlike the traditional methods, this algorithm is based on machine learning and super resolution choosing mechanism. Choose from the mean-type, max-type and median-type filtering. Firstly, the down-sampling of high resolution depth images and high resolution color images are used to obtained the best filter and the feature sets are obtained by feature extraction. Then the feature sets are acquired by the high resolution depth images filtered by the best filter. Finally, filter classifier is got from the feature sets trained by support vector machines. In addition, a new frequency-domain feature vector is designed to enhance the discriminability of the methods. The mixed sets are used in this paper to test the algorithm. Experiments on non-noise and noise images show the effectiveness and robustness. Experiments in true color and depth images of time of fight also indicate that this algorithm is better than traditional methods.
depth image; super resolution; machine learning; support vector machines; time of flight
新疆工程学院基金资助项目(2013xgy141412)
TP391
A
10.16280/j.videoe.2015.17.035
2014-12-20
【本文献信息】任晓芳,王红梅,王爱民,等.基于选择学习机制的深度图像超分辨率算法[J].电视技术,2015,39(17).
最后,这些特征集经过支持向量机(SVM)训练获得滤波器分类器。此外,还提出了一种频域特征向量,用于提高算法识别性能。无噪声和有噪声的深度图像实验验证了算法的有效性和鲁棒性,在真彩色和飞行时间深度图像的实验结果表明,提出算法的性能优于传统算法。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
电子制作(2019年16期)2019-09-27
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
自动化学报(2017年5期)2017-05-14
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
