
基于空时域特征的视觉显著图生成算法
2015-05-05 12:54崔子冠干宗良朱秀昌
电视技术 2015年17期
鲁 雯,崔子冠,干宗良,刘 峰,朱秀昌
(南京邮电大学 江苏省图像处理与图像通信重点实验室,江苏 南京 210003)
基于空时域特征的视觉显著图生成算法
鲁 雯,崔子冠,干宗良,刘 峰,朱秀昌
(南京邮电大学 江苏省图像处理与图像通信重点实验室,江苏 南京 210003)
提出了一种新的计算图像空时域显著图的方法,该算法首先用lucas-kanade金字塔算法求绝对运动矢量,用8参数透视模型计算背景运动矢量,再用二者的差值求时域显著图;然后利用颜色对比度和纹理信息计算空域显著图;最后,融合空时域并设置阈值得到总的图像显著图。实验结果表明,新算法能比已有算法更有效地提取视频图像的显著性区域。
显著图;运动矢量;颜色对比度;纹理
人类视觉系统(Human Visual System)能感知图像的变化,是处理后视频和图像的最终接收器。在一个场景中,人们只对其中一部分视觉场景感兴趣,利用HVS可求出人眼对图像关注度高的区域。基于HVS的显著图可以用在很多领域,例如感兴趣区域视频编码、高性能的视频压缩[1]和目标检测[2]等。
视频序列与静止图像的显著区域不同,人们往往对视频图像中的运动物体更感兴趣,文献[3]把由运动引起的关注定义为时域显著性,大部分对时域显著性的估计通过计算运动对比度[4-6]得到。但这些模型只考虑视频图像中的局部运动信息,没有考虑相机运动。当相机运动,相机引起的背景运动会影响前景物体的运动,导致计算出的显著图不准确。为了解决这个问题,已有一些模型在用运动信息估计时域显著图前,先减去相机的运动矢量[7-11],使得计算出的时域显著图更准确。
除了时域特征外,利用视频图像中的颜色对比度、亮度对比度、纹理掩蔽和方向等低级视觉特征也可求显著图。在所有现存利用低级特征求显著图的方法中,IKN模型[12]最著名并被广泛使用。由于IKN模型提出的用低级视觉特征求图像显著图的思想值得学习,现在有很多模型是在IKN模型上的改进[13-15]。
本文提出了一种新的计算空时域显著图的方法。对比前人的方法,本文方法主要的工作有:1)用lucas-kanade金字塔光流[16]法计算绝对运动矢量替代由H.264解码预测出的运动矢量,用8参数透视模型计算背景运动矢量,并从绝对运动矢量中减去背景运动矢量得到相对运动矢量,从而求得时域显著图。2)定义颜色对比度值,求颜色对比显著图;用prewitt滤波器求图像梯度值,从而求得纹理显著图。3)融合空时域显著图,通过阈值后处理得到最终图像的显著图。
1 总体框架
首先,在一个给定的视频序列中,引进3种类型的运动场,它们分别叫做绝对运动、背景运动和相对运动[10]。绝对运动代表一个视频序列中,前一帧中的像素点与当前帧中对应的像素点之间的绝对空间位移;背景运动和全局运动相似,通常由相机运动产生;而相对运动则是绝对运动和背景运动之间的矢量差,三者的关系如图1所示。
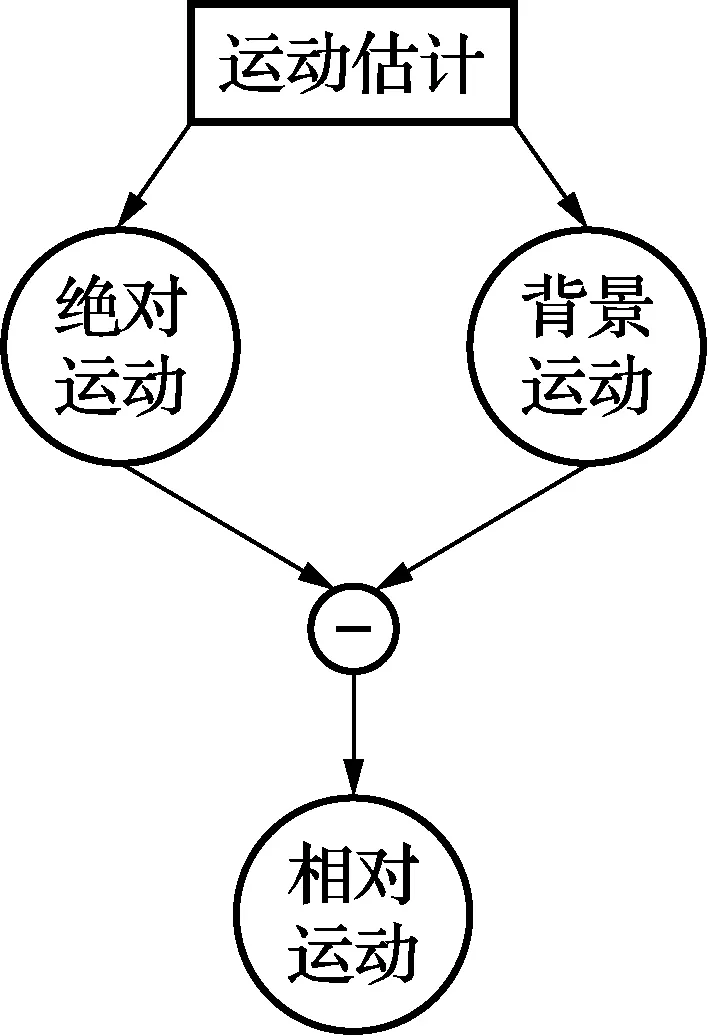
图1 绝对运动、背景运动和相对运动之间的关系
本文算法的流程图如图2所示。首先,输入一个视频序列中的相邻两帧图像,用金字塔光流法求出的这两帧图像的运动矢量,定义为绝对运动矢量;用全局运动估计求相机运动矢量,定义为背景运动矢量;定义绝对运动和背景运动的矢量差为相对运动矢量,并用相对运动矢量求时域显著图。其次,分别求当前帧的颜色对比度显著图和纹理显著图。最后,融合空时域显著图,并对该图做阈值处理,得到最终的显著图。

图2 算法整体框架
2 本文算法
2.1 计算时域显著图
文献[9]通过H.264解码,得到预测的运动矢量值,并将该运动矢量作为初始值带入全局运动估计算法计算背景运动矢量。由于通过H.264解码得到的运动矢量预测值并不准确,导致用该值估计出的背景运动矢量有偏差。为了避免文献[9]算法(该算法后面简称SAVC算法)造成的误差,本文使用金字塔光流法计算绝对运动矢量,求时域显著图的过程如下:
第一阶段,计算相邻两帧的绝对运动矢量前,先把输入的CIF格式图像下采样成1/4 CIF大小的图像以减少计算量。再用lucas-kanade金字塔光流法求出两个相邻帧之间的绝对运动矢量。整个金字塔算法的流程是:首先,计算出金字塔最高级L级图像的光流。然后,计算结果将作为初始像素位移值带入L-1层图像进行计算。通过计算把修正过后的L-1层光流值再带入L-2层中进行计算,这样迭代直至到0层(原始图像),本文定义L=2。
第二阶段,计算背景运动矢量。本文同SAVC算法一样,使用8参数透视模型做全局运动估计。把求出的绝对运动矢量带入8参数透视模型中去,计算出的MVX和MVY为背景运动矢量。从第一阶段求出的绝对运动矢量中减去背景运动矢量MVX,MVY,获得相对运动矢量值,如图3所示。
第三阶段,计算相对运动矢量的大小,并求得时域显著图。将X、Y方向上运动矢量的大小量化成图像的显著值,式(1)为量化公式
(1)
式中:MX,MY分别代表X,Y方向上的相对运动矢量;M0为图像最终显著值。对得到的图像显著值M0矩阵进行均值滤波以减少孤立的噪点。为了方便后续研究,对滤波后的M0矩阵进行张量积运算。求得的强度图矩阵值的范围为0.0(黑)到1.0(白),该强度图即最终的显著图,如图4所示。

图4 视频soccer中第79帧的处理结果
观察图4,其中图4a中运动物体包括图像左边正在走动中的蓝衣运动员以及图像右边正在踢球的红衣运动员。图4b是本文算法时域显著图,图中有两块灰色/白色的显著区域,实验结果显示该算法已经能很好地提取出左边的蓝衣运动员,但是仅能提取一部分右边的红衣运动员。分析实验结果,在图4b中,不仅希望提取图像左边的蓝衣运动员也希望能完整提取图像右边的红衣运动员。下面,将通过分析其他的特征获得更准确的实验结果。通过分析,发现图4b中踢足球的运动员穿着红色的衣服,与周围环境的颜色形成了鲜明的对比,因此可以考虑使用颜色对比度求显著图。另外,也可以通过提取边缘信息,求边缘特征图,下一节将利用颜色对比度和边缘信息求空域显著图。
2.2 计算空域显著图
本节计算空域显著图的过程分两步:
第一步:利用颜色对比度求显著图。首先,定义RG和BY这两个颜色对比度值,如式(3)和式(4)所示,式(2)中y为黄色分量。这样定义的原因是:1)根据Dirk Walther[17]等人的研究,黄色被感知为红色和绿色等份量的重叠,所以在一个RGB像素中所包含的黄色分量的大小应由min(r,g)得出。2)对比Dirk Walther定义的颜色对比度值,本文引入平方运算,拉伸每点颜色对比度值的范围,突出与周围背景颜色形成鲜明对比度的像素点,使颜色特征图的分层更加突出,减少视觉关注区域的冗余。然后,和IKN算法一样对颜色分量进行跨尺度相减和标准化处理,得到颜色显著图。
y=min(r,g)
(2)
(3)
(4)
第二步:求纹理显著图。本文使用梯度的方法[18]来计算图像的边缘。这里使用Prewitt滤波器来计算梯度,Prewitt滤波器垂直和水平方向的模版定义为
(5)
将图像的亮度值与Hx,Hy做卷积得到点(X,Y)的梯度值,如式(6)所示
(6)
式中:I(x,y)代表图像中点(X,Y)的亮度值;符号⊗代表卷积操作。把式(6)中G(x,y)定义为图像中点(X,Y)的边缘显著值,最终得到图像纹理显著图。
2.3 空时域显著图融合
目前,已经有线性和非线性等多种融合多特征显著图的方法,本节使用了一种简单的线性融合方法。融合方法如式(7)所示
γ×Texture_map)
(7)
式中:S_Map为融合后的显著图;Motion_map、Color_map和Texture_map分别代表前面求出的基于运动特征、颜色对比度和纹理特征的显著图;α,β和γ分别代表分配给这3类显著图的权重,一般设置α>1,β>1和γ≤1(α>β>γ)。
图5为空时域显著图融合后的结果。

图5 各个特征显著图及融合后显著图
图5的实验中,分别令α=4,β=3和γ=1。其中图5a为soccer第79帧图像。图5b~5d分别是该帧图像基于运动矢量、颜色对比度和纹理特征的显著图,图5e为融合后的实验结果。从图5e中可以看出本文模型能计算出视觉关注度高的区域,但由于颜色对比度和纹理显著图中提取了一些非关注度高的区域,造成了一些模糊现象。下面通过设置阈值对图5e中的结果做一些后处理,改进结果。如式(8)当像素点的灰度值大于阈值T时,将该点标记为显著点,灰度值小于T时,标记为非显著点
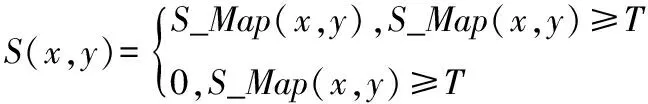
(8)
式中:T代表阈值;S_Map(x, y)表示显著图中点(x, y)的强度值;S(x, y)表示设定阈值后,点(x,y)的显著值。图5f代表阈值处理后的结果,这里T=0.3。对比图5e和图5f可以发现,阈值可以有效减少那些显著值不高的噪点,即关注度不高的阴影部分。由此得出,设定一个合适的阈值,能提高提取显著区域的准确性。
3 实验结果
图6~图9给出本文算法和SAVC算法求显著图的实验结果,其中4个实验视频图像分别为视频akiyo第22帧、paris第39帧、football第79帧和silent第20帧。每个视频图像实验结果中a~e分别代表原始图像、SAVC模型求出的显著图、二值化SAVC显著图、本文算法求出的显著图和二值化本文算法显著图的结果。将显著图二值化的目的是为了视觉上对比方便。其中本文选取的阈值为T=0.3。

图6 akiyo第22帧实验算法对比

图7 paris第39帧实验算法对比

图8 football第79帧实验算法对比

图9 silent第20帧实验算法对比
图6~图9表明SAVC算法在有些视频场景中比较有效,如对视频paris和football求得的结果相对准确,图7b中,该模型求出吸引人注意力的两个人;又如图8b中,该模型求出传球的运动员们。但它并不是对所有视频图像都有效,比如对视频akiyo和silent,SAVC算法并不能很好地提取显著性区域,只能提取显著图的一小块,而不是完整的显著区域。经过分析,笔者发现这是由于SAVC算法对视频图像的运动信息提取较好,能够准确计算出视频图像中的运动显著图。而SAVC算法用近似IKN算法求得的图像空域显著图,效果十分不好,导致该算法对运动剧烈的部分提取较好,而运动较小但同样是视觉关注度高的区域则几乎提取不出来。视频akiyo中运动较剧烈的主要是人脸部分,人的身体部分虽然同属于视觉关注度高的区域但是运动不剧烈;slient中运动较剧烈的主要是人的手臂部分。因此SAVC模型只能提取akiyo的头部运动区域和silent的手部运动区域,而不能计算出完整的显著区域。
本文算法相对于SAVC算法,在效果上有了较大的提高。在时域显著图这块,本文算法在SAVC模型上做了改进,使用金字塔光流法求视频每帧图像的绝对运动矢量信息,计算出的时域显著图很准确。在空域这块,本文利用颜色对比度和纹理信息求出了空域显著图,比SAVC算法中使用近似IKN算法的效果好很多。因此,本文不仅和SAVC算法一样,能准确提取出运动较剧烈的区域,如图7d和图8d所示;也能准确提取出“静止的”显著区域,使得计算出的显著区域更加完整,如图6d和图9d所示。
4 总结
本文提出了一种新的基于空时域的计算视频图像显著图的方法。算法分为3步,首先,利用金字塔光流算法计算绝对运动矢量,估计相机运动产生的背景运动矢量,将背景运动从绝对运动中移除得到相对运动矢量,利用相对运动矢量计算时域显著图。然后,利用颜色对比度和纹理信息求空域显著图。最后,通过将3个特征图像线性融合,得到总的显著图。实验结果显示,无论是视频图像中的运动较剧烈物体,还是有高视觉关注度的非运动物体,算法都能有效地提取图像的显著区域。由于提取准确的视觉显著图对视频编码很有用,算法具有一定的实用价值和应用前景。
[1] LI Zhicheng,QIN Shiyin,ITTI L. Visual attention guided bit allocation in video compression[J]. Image and Vision Computing,2011,29(1):1-14.
[2] ZHANG W. An adaptive computational model for salient object detection[J]. Multimedia, 2010,12(4):300-316.
[3] MAHAPATRA D, WINKLER S, YEN S C. Motion saliency outweighs other low-level features while watching videos[C]//Proc. Electronic Imaging 2008. [S.l.]:International Society for Optics and Photonics,2008:680-689.
[4] LIU D,SHYU M L. Semantic retrieval for videos in non-static background using motion saliency and global features[C]//Proc. 2013 IEEE Seventh International Conference on Semantic Computing(ICSC).[S.l.]:IEEE Press,2013:294-301.
[5] ZHU Y,JACOBSON N,PAN H, et al. Motion-decision based spatiotemporal saliency for video sequences[C]//Proc. 2011 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).[S.l.]:IEEE Press,2011:1333-1336.
[6] HUA Z, XIANG T, YAO W C. A distortion-weighing spatiotemporal visual attention model for video analysis[C]//Proc. 2nd International Congress on Image and Signal Processing, CISP’09. [S.l.]:IEEE Press,2009:1-4.
[7] WU B, XU L, LIU G. A visual attention model for news video[C]//Proc. 2013 IEEE International Symposium on Circuits and Systems(ISCAS). [S.l.]:IEEE Press, 2013: 941-944.
[8] CHEN Y M,BAJIC I V. Motion vector outlier rejection cascade for global motion estimation[J]. Signal Processing Letters,2010,17(2):197-200.
[9] HADIZADEH H,BAJIC I V. Saliency-aware video compression[J]. Image Processing,2014,23(1):19-33.
[10] WANG Z,LI Q. Video quality assessment using a statistical model of human visual speed perception[J]. JOSA,2007,24(12):61-69.
[11] BARRANCO F,DIAZ J,ROS E,et al. Real-time visual saliency architecture for fpga with top-down attention modulation[J]. Industrial Informatics,2014,10(3):1726-1735.
[12] ITTI L,KOCH C,NIEBUR E. A model of saliency-based visual attention for rapid scene analysis[J]. IEEE Trans. Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[13] HAREL J,KOCH C,PERONA P. Graph-based visual saliency[C]//Proc.Advances in Neural Information Processing Systems. [S.l.]:IEEE Press,2006:545-552.
[14] ROSIN P L. A simple method for detecting salient regions[J]. Pattern Recognition, 2009, 42(11): 2363-2371.
[15] BORJI A, ITTI L. State-of-the-art in visual attention modeling[J]. IEEE Trans. Pattern Analysis and Machine Intelligence, 2013, 35(1): 185-207.
[16] LUCAS B D, KANADE T. An iterative image registration technique with an application to stereo vision[C]//Proc. IJCAI 1981. [S.l.]:IEEE Press,1981:674-679.
[17] WALTHER D, CHRISTOF K. Modeling attention to salient proto-objects[J]. Neural Networks,2006,19(9):1395-1407.
[18] XUE W,ZHANG L,MOU X,et al. Gradient magnitude similarity deviation: a highly efficient perceptual image quality index[J]. IEEE Trans. Image Processing, 2014, 23(2): 684-695.
鲁 雯(1990— ),女,硕士生,主研视频图像处理;
崔子冠(1982— ),讲师,主要研究方向视频编码与传输,为本文通讯作者;
干宗良(1979— ),副教授,主要研究方向为图像处理与视频通信;
刘 峰(1964— ),博士生导师,主要研究方向为图像处理与多媒体通信、高速DSP与嵌入式系统;
朱秀昌(1947— ),博士生导师,主要研究方向为图像处理与多媒体通信。
责任编辑:时 雯
Visual Saliency Map Algorithm Using Spatiotemporal Features
LU Wen,CUI Ziguan,GAN Zongliang,LIU Feng,ZHU Xiuchang
(JiangsuProvinceKeyLabonImageProcessing&ImageCommunications,NanjingUniversityofPostsandTelecommunications,Nanjing210003,China)
A new algorithm for computing spatio-temporal saliency maps is proposed in this paper. Firstly, the optical flow vectors of absolute motion is estimated.Then the background motion vectors to obtain the temporal saliency maps is calculated. Secondly, color contrast and texture information is used to calculate the spatial saliency maps. Finally,spatio-temporal saliency maps by fusing spatial and temoral maps is got. Experimental results show a better performance when compared to several state-of-the-art temporal saliency models.
saliency map;motion vectors;color contrast;texture
国家自然科学基金项目(61471201);江苏省自然科学青年基金项目(BK20130867);江苏省高校自然科学研究项目(12KJB510019);江苏省高校自然科学重大项目(13KJA510004);南京邮电大学校科研基金项目(NY212015);南京邮电大学“1311人才计划”资助课题项目
TP751.1
A
10.16280/j.videoe.2015.17.001
2015-01-14
【本文献信息】鲁雯,崔子冠,干宗良,等.基于空时域特征的视觉显著图生成算法[J].电视技术,2015,39(17).
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
测控技术(2018年11期)2018-12-07
河北遥感(2017年2期)2017-08-07
系统工程与电子技术(2016年7期)2016-08-21
衡阳师范学院学报(2016年3期)2016-07-10
现代防御技术(2016年1期)2016-06-01
新高考·高一物理(2016年1期)2016-03-05
