
基于灰关联分析的指标约简与权重分配算法
2015-05-04 08:07:08张恒巍韩继红王晋东
计算机工程与设计 2015年4期
张恒巍,韩继红,张 健,王晋东,寇 广
(信息工程大学,河南 郑州450001)
0 引 言
由于传统粗糙集理论要求数据对象具有离散性和清晰性,但是在现实应用中很多数据具有连续性,因此传统粗糙集理论的使用受到较大的限制。
许菲菲等[1]提出模糊粗糙集模型,设计了一种基于数值优化理论的连续值属性约减方法;王莉等[2]基于模糊决策粗糙集模型,定义高斯核模糊T-等价关系,从模糊隶属度角度给出条件概率,实现对连续型数据的属性约简。上述文献采用对连续数据离散化处理的方法,使粗糙集适用于连续属性约减问题,但是离散化处理会带来属性值数据的失真,造成一定程度的信息损失。胡清华等[3]提出一种构建在实数空间的粗糙集模型,通过对样本数据的粒化处理,在模型中用样本数据的领域关系表示属性之间的关系;宋小威等[4]基于变精度粗糙集模型,根据下近似分布不变性定义了区间约简模型,并给出一种基于有序分辨矩阵的区间约简方法;杜俊慧[5]利用灰色聚类代替粗糙集中的等价关系进行分类,采用F统计量确定灰色聚类的临界值,能够实现对连续值属性的约减;王磊等[6]提出一种基于灰色绝对关联度的属性约简算法,上述方法都未考虑不同属性间的重叠计算问题和信息损失问题。
针对以上问题,本文在灰关联分析的基础上,通过研究不同类型指标之间的关联性,定义了条件指标的重要性测度和条件指标之间的影响力测度,提出了一种基于灰关联分析的指标约简与权重分配算法IRA-GCA (index reduction algorithm based on grey-correlation analysis,IRAGCA)。仿真实验和对比分析结果表明,本文提出的算法具有能够同时处理离散型决策表和连续型决策表、权重分配准确、运算效率高的优点。
1 灰关联分析简介
在粗糙集研究领域中,属性约简是研究的重点和热点之一。本文关注的指标体系构建中的指标约简问题,是属性集约简问题在指标体系领域的具体表现。张任伟等[7]对现有的属性约简算法进行了分析和比较,指出Pawlak约简算法、基于差别矩阵及其改进的约简算法[8,11]都存在较为显著的缺点,在实际使用中限制条件多,实用性较差。启发式约减算法能够根据信息熵[1,13]、属性重要度[12]或差别集[14]等信息进行指标约减,但是存在对启发信息量依赖程度较高的缺点。
灰关联分析作为一种多指标分析方法,根据不同指标的样本数据变化趋势的相似程度来表征指标间的关联程度和相似程度。近一段时期,基于面积的灰关联算法[15]和线性灰关联算法[16]对传统灰关联分析进行了改进和提高,受此启发,针对现有约减算法的不足,本文提出一种基于灰关联分析的指标约减算法。首先给出灰关联分析的过程。
(1)决策数据表建立:决策数据表包含条件指标和决策指标的样本数据,是进行指标约减的基础。
定义1 决策表T:用四元组T=(U,Q,V,f)定义决策表,其中U={x1,x2,…,xm}是决策对象的非空有限集合,Q是指标集,V为指标的值域集,f是U×Q→V的映射。Q=C∪D,其中条件指标集合C= {c1,c2,…,cn}中有n个指标,决策指标D一般只有一个,用d来表示。
(2)数据标准化:由于不同指标的单位和量级不同,不能直接进行比较。因此,在进行灰关联分析之前将指标数据按某种效用函数进行归一化处理。针对收益型数据和代价型数据的归一化处理公式如下。
收益型数据的归一化处理公式

代价型数据的归一化处理公式
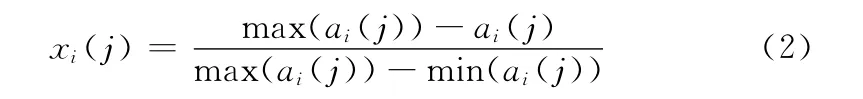
式中:xi(j)——归一化后的指标值。
(3)关联系数和关联度计算
定义2 关联系数ξid(k):设决策表T=(U,Q,V,f),在样本uk中条件指标ci与决策指标d之间的关联系数ξid(k)可定义为

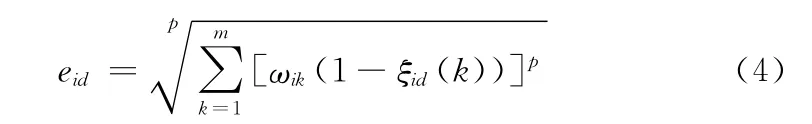
其中,根据样本的重要性,可以定义第i个条件指标值在第k个样本中的权重为ωik。取P=2,采用欧氏距离。
定义3 条件指标关联度γ(ci,d):条件指标ci与决策指标d的灰关联度简称为条件指标关联度γ(ci,d)
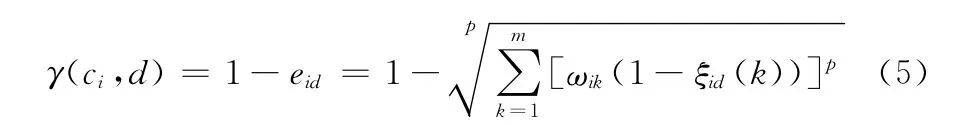
在本文的决策表约简算法中,令P=2,ωi为归一化的等权向量,则式 (5)可以简化为
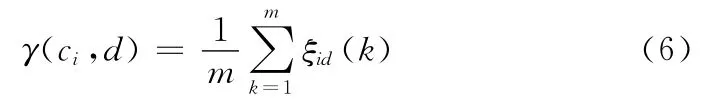
2 条件指标重要度与影响度
指标重要度是条件指标的关键性质,而关联度表征条件指标与决策指标相互影响的程度。一般来说,关联度和重要度具有正相关性,由此定义条件指标的重要度。
定义4 条件指标重要度IMP(ci,d):条件指标ci相对决策指标d的重要度IMP(ci,d)定义为
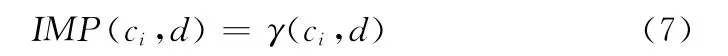
每个条件指标代表系统某一方面的属性。虽然不同指标的描述角度、方式和方法不一样,但是指标之间不是孤立的,存在或强或弱的联系,因此不同指标之间存在重叠的情况[13]。两个条件指标的重叠性越大,则它们对信息系统描述的相似程度就越大。条件指标之间的重叠对指标约简和权重分配的准确性造成了干扰,为消除这种干扰,本文借鉴灰关联分析理论,建立了条件指标影响系数和影响度的概念,用以定量描述指标之间的重叠程度。在此基础上,提出了条件指标的去重叠化方法,设计了指标约简与权重分配算法IRA-GCA,以实现更加准确的指标约简和权重分配。
定义5 条件指标影响系数ηij(k):设决策表T=(U,Q,V,f),在样本uk中条件指标ci对cj的影响系数ηij(k)可定义为
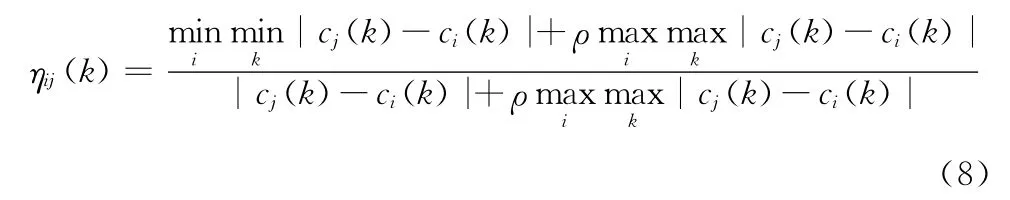
定义6 条件指标影响度κ(ci,cj):定义条件指标ci对cj的影响程度为κ(ci,cj)

式中:κ(ci,cj)代表了条件指标ci对cj的影响程度,说明cj在多大程度上受到ci的影响,0≤κ(ci,cj)≤1。当κ(ci,cj)=0时,说明ci与cj毫不相关,ci对cj不具有任何影响;当κ(ci,cj)=1时,说明ci对cj具有完全程度的影响;当0<κ(ci,cj)<1时,说明ci对cj具有影响,但又不能完全影响cj。同时,κ(ci,cj)不具有对称性,即指标ci对cj的影响程度κ(ci,cj)和cj对ci的影响程度κ(cj,ci)通常不相同,所以一般情况下κ(ci,cj)≠κ(cj,ci)。
借助条件指标影响度的定义,可以定量描述指标之间的重叠关系。不失一般性,设4个条件指标之间的关系如图1所示
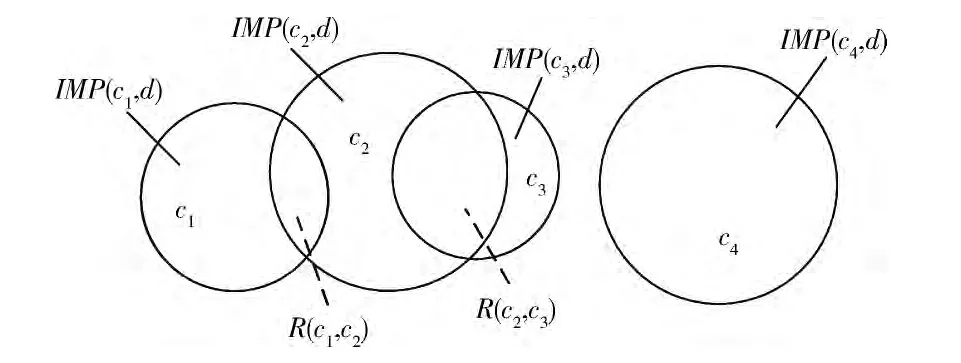
图1 指标重叠关系
我们对条件指标是否重叠提出以下3条判定标准:
(1)两个条件指标完全重叠的判定标准:①两个指标的重要性相同IMP(ci,d)=IMP(cj,d);②指标之间影响度为1。
两个条件指标完全重叠表示这两个指标实际是同一个指标,是对系统同一属性不同角度或方式的表述。此时,两个指标可以看作是一个指标。
(2)两个条件指标完全不重叠的判定标准:指标之间影响度为0。
(3)当两个指标之间既有重叠又未达到完全重叠时,定义指标之间的重叠部分为

一般来说,条件指标的重要度越大,与其它指标的重叠越小,对决策指标的影响就越大;反之,条件指标对决策指标的影响就越小。
3 指标约简与权重分配
3.1 指标去重叠化方法
假设图1中的指标重要度分别为IMP(c1,d)=0.5,IMP(c2,d)=0.7,IMP(c3,d)=0.4,IMP(c4,d)=0.8。可以看出,c1,c2,c3之间有重叠,但不是完全重叠。设c1和c2之间的 影响度 分别是κ(c1,c2)= 0.125和κ(c2,c1)=0.25,c2和c3之间的影响度分别是κ(c2,c3)=0.75和κ(c3,c2)=0.25。指标的重叠部分是指标描述中的冗余信息,去除指标重叠信息的操作称为指标去重叠化。去重叠化的原则为两个有重叠的指标对重叠部分重新分配,可以不失一般性地假设每个指标获得重叠部分的一半。
定义7 条件指标绝对重要度I(ci,d):若两个指标ci和cj之间具有重叠关系,则去重叠化后得到指标绝对重要度I(ci,d)和I(cj,d)分别为
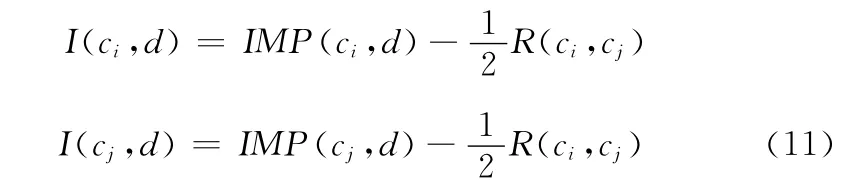
对图1中4个指标去重叠化后,得到I(c1,d)=0.45,I(c2,d)=0.56,I(c3,d)=0.31,I(c4,d)=0.8。可以看出,去重叠化后的指标绝对重要度有所减小,这是由于对指标重要度中的重叠部分进行了重新分配。
定义8 约简阈值t:设定 (0,1)上的实数t为约简阈值,用于判断条件指标ci能否进入约简集。
将条件指标的绝对重要度I(ci,d)与t作比较,若I(ci,d)≥t,认为该条件指标重要,可以进入约简集;若I(ci,d)<t,则认为该条件指标不够重要,不能进入约简集。
根据上述分析可知,对于复杂的指标体系来说,指标之间通常有着某种关联关系,因此指标的重要度IMP(c,d)之间存在重叠,如果直接利用IMP(c,d)进行指标权重的分配,将会影响权重的准确性和合理性。只有从重要度IMP(c,d)中剔除关联影响,得到指标的绝对重要度I(c,d),才能准确描述条件指标独立影响决策指标的程度,依据I(c,d)进行权重分配,更加准确、合理。
定义9 指标权重wi:根据绝对重要度I(ci,d)确定条件指标ci的权重wi
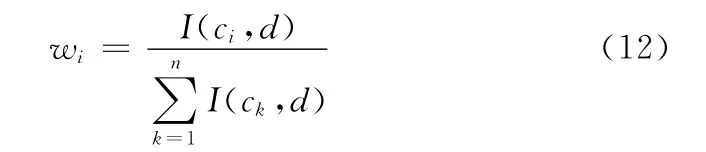
由 此 可 以 得 到 指 标 的 权 重 向 量W = (w1,…,wi,…wn)。
3.2 指标约简与权重分配算法IRA-GCA
依据上述分析和研究,提出基于灰关联分析的指标约简与权重分配算法IRA-GCA。算法以决策表数据为基础,首先依据本文的定义对指标进行去重叠化操作,然后逐次选择最重要的条件指标添加到约简集中,最后对约简指标集中的指标依据绝对重要度进行权重分配。算法的步骤如下所示。
输入:决策表T=(U,Q,V,f);约简阈值t。
输出:约简阈值t下的约简指标集B和权重向量W。
步骤1 对决策表T的数据进行标准化处理;
步骤3 计算条件指标集C中元素之间的重叠部分R(ci,cj);
(1)对条件指标集C中每个指标ci,根据式 (8)和式(9)计算ci对其它条件指标的影响度κ(ci,cj)i,j = 1,2,…,n,i≠j;
(2)对条件指标集C中任意两个指标ci和cj,当κ(ci,cj)=0时,R(ci,cj)=0;当0<κ(ci,cj)<1时,根据式(10)计算R(ci,cj);
步骤4 对条件指标集C中每个指标ci进行去重叠化,根据式 (11)计算指标的绝对重要度I(ci,d);
步骤5 依据指标绝对重要度I(ci,d)对条件指标集C进行约简,构建约简指标集B。若I(ci,d)≥t,则将其选入约简集B;若I(ci,d)<t,则将其去除,不作为约简集B的元素;
步骤6 对约简指标集B的元素,利用指标绝对重要度I(ci,d),根据式 (12)计算指标权重wi;
步骤7 输出约简指标集B和指标权重向量W。
IRA-GCA算法通过完整保留原始数据信息,解得的指标约简集合理性更强。算法的时间复杂度为O(mn2),存储原始数据矩阵是本算法的主要空间消耗。
4 仿真实验与分析
4.1 算法有效性验证
为验证IRA-GCA算法的有效性,选取美国加州大学UCI数据库中的指标数据集进行实验。
实验数据集基本信息见表1。

表1 实验数据集基本信息
同时选择代数约简算法ARA、信息熵约简算法CEBARKCC和基于区分矩阵的约简算法AM-RASR来进行对比实验。实验用计算机配置为Core2处理器,2G内存,操作系统是Windows XP,算法用Matlab2010b实现。设本算法的约简阈值t=0.5,分别对4个数据集做指标约简的结果见表2。
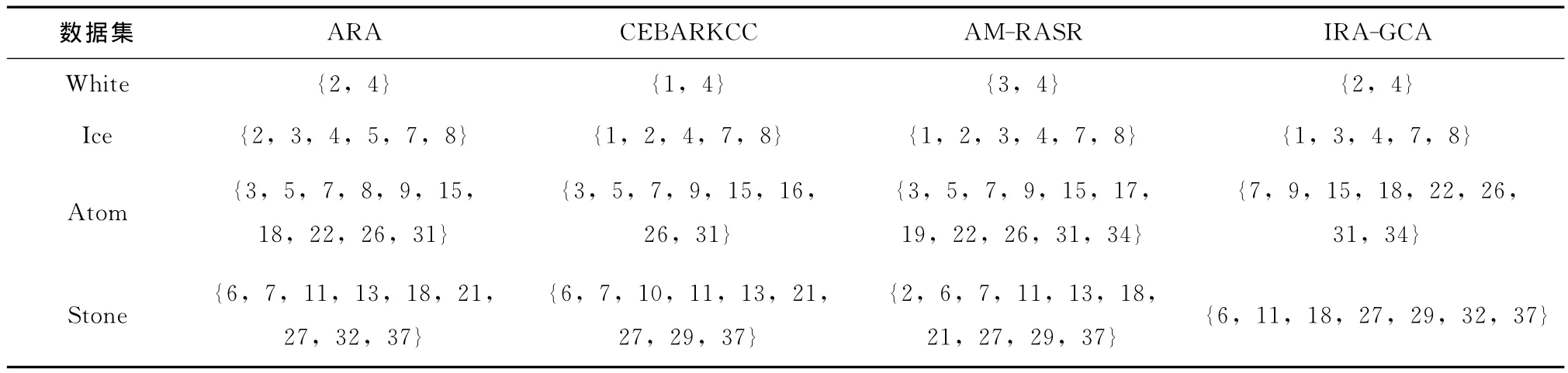
表2 不同算法给出的约简指标集
可以看出,IRA-GCA算法的约简结果在其它算法的结果集中,验证了本算法的有效性。同时,由于约简阈值t=0.5,结果更加精简;在不同的应用中可以通过调整t的取值,灵活适应用户的约减精度。
4.2 算法运行效率分析
从上述实验对象数据集中取前N个对象作为实验样本,N分别为10,20,…,50。设置本算法的约简阈值为0.5,分别运行IRA-GCA算法、ARA算法、CEBARKCC算法和AM-RASR算法,记录算法得到各自约简结果的运行时间,如图2~图5所示。
可以看出,一方面,本文提出的算法IRA-GCA在样本数量较小时优势并不突出,当样本数量增加时IRA-GCA的优势开始显著,求解时间明显较少。另一方面,当条件指标的个数较大时,IRA-GCA的运行时间仍然较少,但与其它算法相比区别不大,图5表明了这一特点。因此,IRA-GCA算法更适合于样本数较多且指标数较少情况下的约简应用。
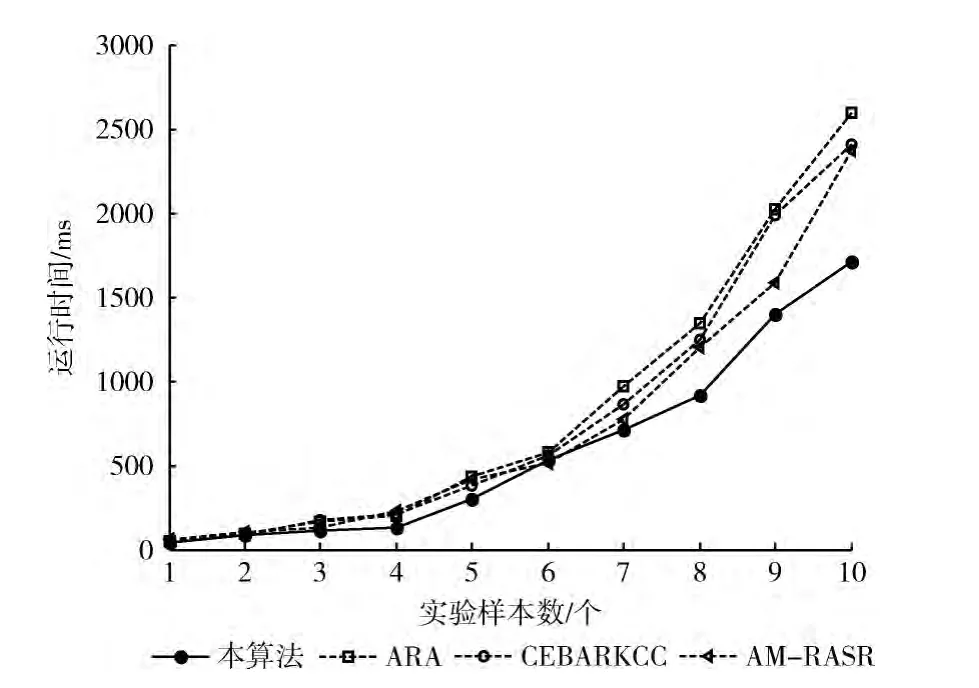
图2 White数据集运行结果
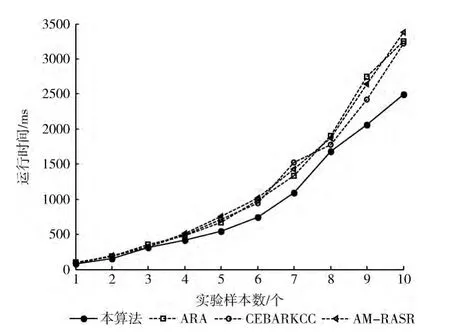
图3 Ice数据集运行结果
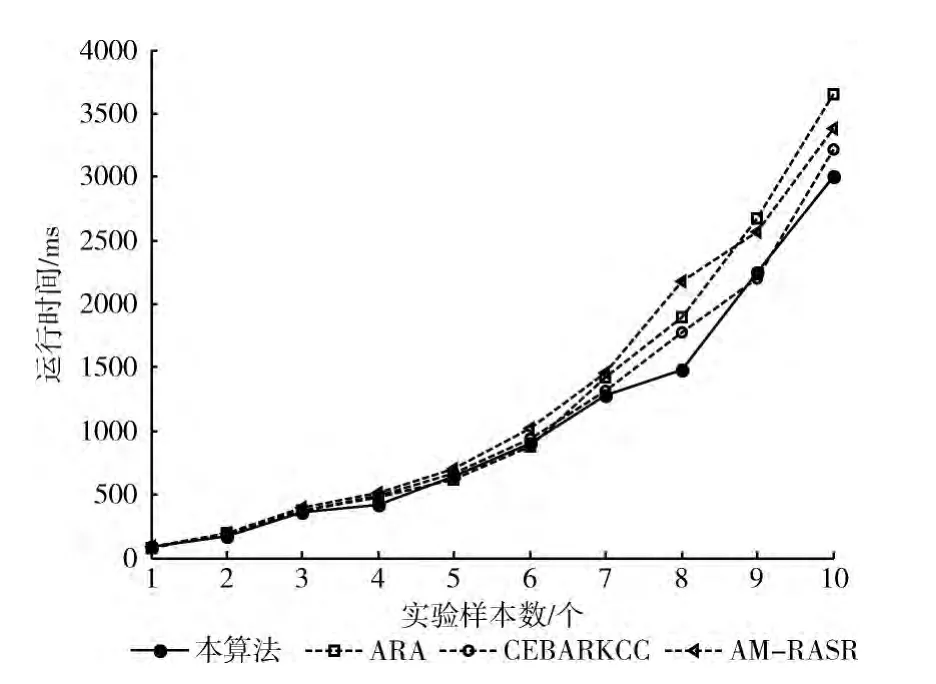
图4 Atom数据集运行结果
5 结束语
本文利用灰关联分析理论量化定义了指标重要度和指标之间的影响度,提出了条件指标去重叠化方法,设计了指标约简与权重分配算法IRA-GCA。与其它算法相比,本文提出的算法具有以下特点和优势:
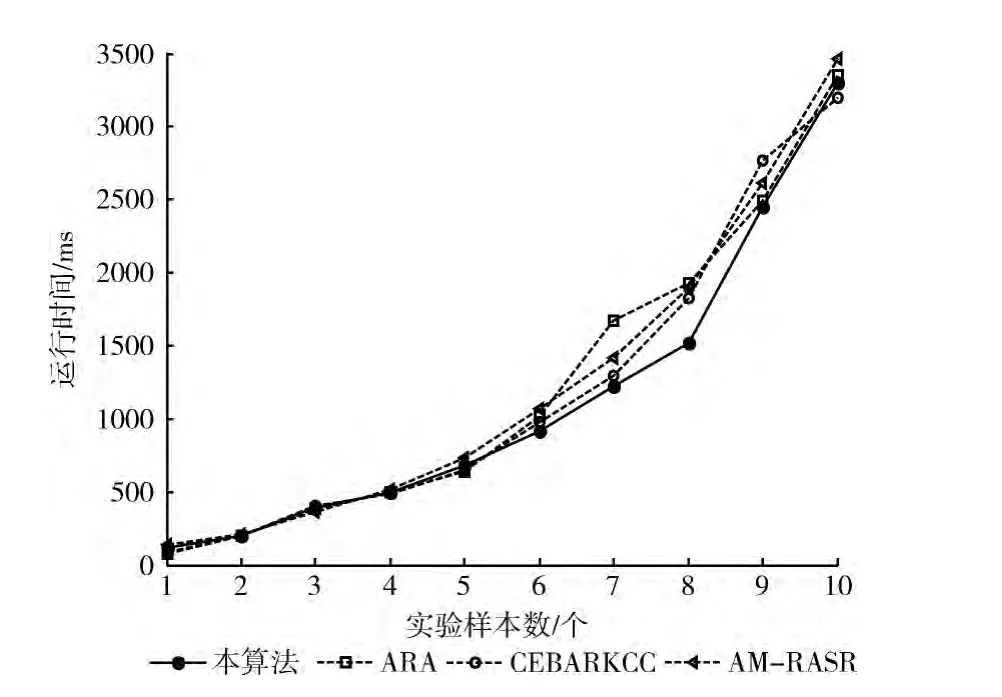
图5 Stone数据集运行结果
(1)算法能够处理离散型决策表和连续型决策表,以及二者同时存在的混合决策表等复杂情况,有效避免了将连续值转化为离散值时的信息损失。
(2)算法对条件指标集进行去重叠化操作,使指标之间相互独立,有效降低了指标之间的关联对约简结果产生的影响。
(3)算法在保持指标约简能力的同时,约简过程更加高效。在样本数目越大的时候本算法优势越显著;而随着指标数目的增加,本算法的优势逐步减弱。所以本算法更适合于大样本空间、小指标空间的情形。
(4)算法利用去重叠化后的条件指标绝对重要度进行权重分配,更加准确合理。
[1]XU Feifei,MIAO Duoqian.Mutual information-based algorithm for fuzzy-rough attribute reduction [J].Journal of Electronics &Information Technology,2008,30 (6):1372-1375(in Chinese).[徐菲菲,苗夺谦.基于互信息的模糊粗糙集属性约简 [J].电子与信息学报,2008,30 (6):1372-1375.]
[2]WANG Li,ZHOU Xianzhong,LI Huaxiong.Fuzzy decisiontheoretic rough set model and its attribute reduction [J].Journal of Shanghai JiaoTong University,2013,47 (7):1032-1035(in Chinese).[王莉,周献中,李华雄.模糊决策粗糙集模型及其属性约简 [J].上海交通大学学报,2013,47(7):1032-1035.]
[3]HU Qinghua,YU Daren.Numerical attribute reduction based on neighborhood granulation and rough approximation [J].Journal of Software,2008,19 (3):640-649 (in Chinese).[胡清华,于达仁.基于邻域粒化和粗糙逼近的数值属性约简[J].软件学报,2008,19 (3):640-649.]
[4]SONG Xiaowei,WANG Jiayang.Research on interval reduction model in variable precision rough set [J].Pattern Recognition and Artificial Intelligence,2013,26 (11):33-40 (in Chinese).[宋小威,王加阳.变精度粗糙集区间约简模型研究 [J].模式识别与人工智能,2013,26 (11):33-40.]
[5] WANG Lei,WANG Jinshan.Variable precision rough set model based on grey absolute correlation degree [J].Journal of Chongqing Institute of Technology,2012,26 (5):123-126(in Chinese).[王磊,王金山.一种基于灰色绝对关联度的变精度粗糙集模型 [J].重庆理工大学学报,2012,26(5):123-126.]
[6]ZHANG Renwei,BAI Xiaoying.Survey of decision table research of attribute reduction [J].Computer Science,2011,38 (11):1-6 (in Chinese). [张任伟,白晓颖.决策表的属性约简算法综述 [J].计算机科学,2011,38 (11):1-6.]
[7]FENG Shaorong,ZHANG Dongzhan.Increment algorithm for attribute reduction based on improvement of discernibility matrix [J].Journal of Shenzhen University (Science &Engineering),2012,29 (5):405-411 (in Chinese).[冯少荣,张东站.基于改进差别矩阵的增量式属性约简算法 [J].深圳大学学报,2012,29 (5):405-411.]
[8]WANG Xizhao,WANG Tingting.An attribute reduction algorithm based on instance selection [J].Journal of Computer Research and Development,2012,49 (11):2305-2310 (in Chinese).[王熙照,王婷婷.基于样例选取的属性约简算法[J].计算机研究与发展,2012,49 (11):2305-2310.]
[9]Sirzat Kahramanli,Mehmet Hacibeyoglu,Ahmet Arslan.Attribute reduction by partitioning the minimized discernibility function [J].International Journal of Innovative Computing,Information and Control,2011,7 (5):2167-2186.
[10]RUN Deqin,LI Keqiu.Soft discernibility matrix and attribute reduction for information systems [J].Journal on Communi-cations,2009,30 (8):45-50 (in Chinese).[闰德勤,李克秋.信息系统属性约简的柔性差别矩阵 [J].通信学报,2009,30 (8):45-50.]
[11]GAO Xuedong,DING Jun.A new attribute algorithm for reduction of information system [J].Systems Engineering Theory and Practice,2007,27 (1):132-136 (in Chinese).[高学东,丁军.一种新的信息系统属性约简算法 [J].系统工程理论与实践,2007,27 (1):132-136.]
[12]Nicol D M,Sanders W H,Tricedi K S.A continuous value attributes reduction algorithm based on gray correlation [J].IEEE Transactions on Dependability and Security,2012,3(1):48-55.
[13]GE Hao,LI Longpeng.Heuristics attribute reduction algorithm based on discernibility set [J].Journal of Chinese Computer Systems,2013,34 (2):380-385 (in Chinese). [葛浩,李龙澍.基于差别集的启发式属性约简算法 [J].小型微型计算机系统,2013,34 (2):380-385.]
[14]WANG Jingcheng,ZHU Wenzhi.Improved algorithm of grey incidence degree based on area [J].Systems Engineering and Electronics,2010,32 (4):777-779 (in Chinese). [王靖程,诸文智.基于面积的改进灰关联度算法 [J].系统工程与电子技术,2010,32 (4):777-779.]
[15]YANG Wenhui,WU Jianhua.A new expression of grey relation coefficient [J].Journal of Hohai University (Natural Sciences),2008,36 (1):40-43 (in Chinese).[杨文慧,吴建华.一种新的灰关联系数表达式 [J].河海大学学报,2008,36 (1):40-43.]
猜你喜欢
舰船电子工程(2022年4期)2022-05-11 09:34:32
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
电测与仪表(2015年13期)2015-04-09 11:57:36
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
河南科技(2014年7期)2014-02-27 14:11:29
