
基于多准则排序融合的特征选择方法
2015-05-04 08:07:36石国良苟先太金炜东
计算机工程与设计 2015年4期
李 晓,石国良,苟先太,金炜东
(西南交通大学 电气工程学院,四川 成都610031)
0 引 言
特征选择是从原始特征中选择出一些最有效特征以降低数据集维度的过程。目前,按照特征选择方法依据是否独立于后续的学习算法,分为Wrapper(包裹)和Filter(过滤)两种方式[1]。Wrapper利用后续学习算法的训练准确率评估特征子集,具有偏差大、计算量大的缺点,不适合大数据集。Filter一般使用评价准则来增强特征与类的相关性、削弱特征之间的相关性,利用训练数据的统计性能评估特征,计算效率较高,能很快地利用评价准则来评价特征的好坏。本文主要涉及基于Filter方式的特征选择方法。基于Filter模式的评价准则包括:Fisher比率[2,3]、Re-liefF[4,5]、马氏距 离[6-8]、 模 糊 熵 方 法[9]、类 间 可 分 性[10]、相关性[11]等。然而,Filter模式的单个评价准则不能全面评价特征子集的好坏,单一的特征评价准则难以全面评估特征的优劣,选择精度较低,有待改进。因此,多准则、多尺度的特征评估方法是目前研究的主要内容。国内外许多学者利用了多种评价准则来进行特征选择算法的研究,并取得了明显的效果。例如,文献 [10]提出基于ReliefF算法、类间可分性及特征相关性的多特征评价准则算法,有效降低特征维度并具有比单准则特征选择方法更高的分类性能;文献 [12]引入多个评价准则进行轮询式选择,突破了目前单个评价准则的局限性,能较快且较好地进行特征选择。因此利用多个准则进行特征评价,并借助于信息融合技术成为实现有效特征选择的一条可行途径。
本文提出了一种基于Fisher比率、ReliefF算法、马氏距离算法的多个评价准则相结合的 “并行”特征选择方法,该方法利用一种加权平均的方法进行排序融合以选取到最优特征子集。针对Ionosphere标准数据集和高铁走行部故障数据集的特点,基于多个准则同时对特征进行评价,实现特征的多个排序,并利用排序融合的方法综合多准则的优点最终得到单一排序结果,有效地进行了特征选择。实验结果表明,相对于单一评价准则的特征选择方法,该方法更有效地降低了特征维数,更好地提高了分类准确率,并提高了分类稳定性。
1 特征选择方法
特征选择是从原始特征中选择出一些最有效特征以降低数据集维度的过程。主要研究从一组原始特征中挑选出一些最有效的特征以达到降低特征空间维数的目的。本文主要涉及基于Filter方式的特征选择方法。
1.1 ReliefF算法
由Kononenko在1994年提出的ReliefF算法是一种改进的Relief算法,是目前最为有效的Filter式特征选择方法之一。ReliefF算法可以解决多类别问题以及回归问题,能够处理噪声、不完整特征以及多类别属性的数据集。该算法的核心思想是:较好的特征可使同类样本接近,使不同类样本远离,通过不断调整权值逐步凸现特征的相关程度。
ReliefF算法公式如下
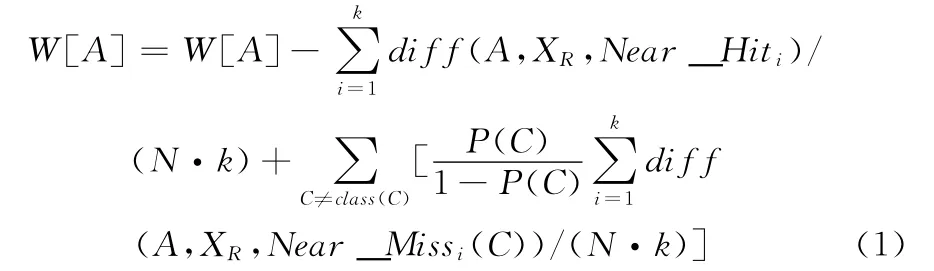
式中:A——特征,W [A]——特征A的权重向量,N——样本数,XR——随机选取的样本点,Near_Hiti——与XR同类的k个最邻近样本中的第i个样本,Near_Missi——与XR异类的k个最近邻样本中的第i个样本,P(C)——C类出现样本的概率。
ReliefF算法适合处理具有大量实例的高维数据集,评估效率高,在噪声过滤方便表现优异。ReliefF算法与Relief算法类似,不管该特征是否和其余特征冗余,只要是和类别相关性高的特征,ReliefF算法均会赋予其较高的权值,因此仍不能去除冗余特征。
1.2 Fisher比率
Fisher比率准则作为一种传统的线性判别方法,在模式识别特征选择领域有广泛的应用,能够有效评估某个特征的有效性。Fisher比率是类间均值方差与类内平均方差的比值。类间距离越大、类内距离越小的特征,其Fisher比率值越大,满足这两个条件的特征子集更为优良,且这样的特征子集可能会带来更高的分类准确率。Fisher比率的计算公式如下[2]

式中:FRi——第i维特征的Fisher比率值;k——类别数;j——第j类特征 (j≤k);Nj为第j类特征向量的个数。xijn——第j类第n个特征向量中的第i维特征;μij=表示第j类中第i维特征的均值;表示第i维特征的总均值。
1.3 马氏距离
马氏距离 (Mahalanobis distance)的定义请参见文献[6],表示数据的协方差距离,它可以有效地计算一个样本和一个样本集 “重心”的最近距离,或者计算两个未知样本集的相似度。本文利用马氏距离的思想,采用中改进了的马氏距离算法,将马氏距离算法作为有效的特征评价准则。马氏距离代表特征集中两个特征子向量之间的可分离性。马氏距离值越大,意味着两个特征向量可分离性越好。
下面简要介绍马氏距离算法:
假设某特征矢量空间,有m维特征,n个样本,样本类别数为C。即样本为 (xa,ya)∈Rm×R1,a∈(1~n),xa为m维特征矢量;ya∈{1,2...C},ya为特征矢量的类别标号。假设X为m×n的特征集合矩阵,每行为含有m维特征的一个样本。
马氏距离公式表示为

其中,特征集第i类样本的样本均值用矩阵表示为(μi)1×m的m维行向量,特征集第j类样本的样本均值用矩阵表示为 (μj)1×m的m 维行向量。i,j∈ (1,C),C 为样本类别数。∑ij为第i类样本与第j类样本所组成的特征矩阵的协方差矩阵。
2 基于排序融合的特征选择
评价准则被视为特征选择中启发式的条件影响因子,由上述介绍可知,不同的评价准则有着各自的优缺点,为了弥补某种评价准则的不足,并使各种评价准则之间做到优势互补,综合利用各种不同条件影响因子,本文提出多准则排序融合的特征选择方法。
首先分别基于ReliefF算法、Fisher比率法、马氏距离法分别对原始特征空间的各个特征进行评估。由于ReliefF算法、Fisher比率、马氏距离均是权值越大,该特征对分类的作用越大,则权值越大的特征排序越靠前。对原始特征空间中各个特征权值的相反数按升序排序,分别依次记排序后每个特征对应的序号

式中XR(k)、XF(k)、XM(k)分别表示 ReliefF算法、Fisher比率法、马氏距离法中,第k个特征的权值在所有m维特征中的排序序号。
按照 “线性求和”规则进行排序融合,即将每个特征在不同评价准则下获取的排序值求和作为融合排序值,从而得到基于上述3种准则的特征综合排序序号,记作

其中
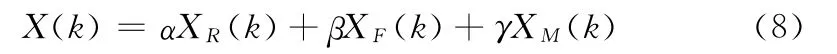
式中:X(k)——在排序融合后第k个特征的权值在所有m个特征中的排序序号。
3 实验与讨论
为了验证本文基于多准则的排序融合的特征选择方法的有效性和优越性,本文针对标准数据集和高速列车转向架故障数据集设计和验证性实验。
3.1 基于Ionosphere数据集的实验
本实验采用UCI的Ionosphere数据集进行实验验证。该数据集包括2个类别,33维有效特征,351个样本。本实验中,分别按上述各评价准则进行实验,其中基于排序融合的特征选则方法采用线性组合的方式,按照式 (8)的加权参数设置为α∶β∶γ=2∶2∶1,得特征子集 (维数为33~1维)。实验采用SVM分类器,从每类样本中随机抽取60%的样本作为训练样本 (第一类135个,第二类75个,合计210个),从每类样本中随机抽取40%的样本作为测试样本 (第一类75个,第二类56个,合计141个),重复进行实验100次,取其均值作为实验结果。实验结果如表1和图1所示。

表1 数据集Ionosphere分类结果
表1和图1的实验结果表明,相比于单准则特征选择法,基于多准则排序融合的特征选择法能有效降低最优特征空间的维数,选取的特征空间具有较高的分类准确率,尤其在特征维数较低的情况下,基于多准则排序融合的特征选择法具有更明显的优势。

图1 各种特征选择方法结果比较
3.2 基于高速列车故障数据的实验
为验证基于多准则排序融合的特征选择方法在高速列车转向架故障仿真数据中的有效性,本文据进行了仿真验证。该实验所用的实验数据是西南交通大学牵引动力国家重点实验室采用动力学仿真分析的多体动力学分析软件包仿真所得,系CRH2型动车组中转向架振动故障的仿真数据。高速列车转向架振动故障数据集中工况类别为:①原车 (无故障);②空气弹簧失气;③横向减震器故障;④抗蛇形减震器故障。高速列车在每种工况下运行速度为120 km/h、140km/h、160km/h、200km/h等,直至列车失稳。列车在每个速度下均运行210s,传感器采样频率为243Hz。
3.2.1 实验设计
在仿真实验中,分别对每个工况类别的原始振动信号数据进行EEMD分解,选取含有主要故障特征的n个本征模态函数 (IMFs),选择第2到10阶IMFs(共9阶IMFs),每隔3s对每阶IMF(729个数据)计算一个模糊熵,由此,每个工况类别得到70个样本 (4个工况类别共计280个样本),每个样本都具有9维EEMD模糊熵特征向量。表2是对高速列车故障特征集合的简单表述。

表2 高速列车故障特征集描述
对每个速度下的特征集合,分别按上述4种基于评价准则的特征选择方法进行仿真实验,其中基于排序融合的特征选则方法采用线性组合的方式,按照式 (8)的加权参数设置为α:β:γ=5∶3∶2,分别得到9~1维的特征子集,分别进行识别率计算实验。采用SVM分类器,从每个工况类别随机选取60% (42个)的样本作为训练样本 (共计168个),同时随机选取40% (28个)的样本作为测试样本(共计112个)。实验重复100次,取其均值作为实验结果。
3.2.2 实验结果与分析
表3~表6分别表示4种不同速度下,上述4种特征选择方法获得的最优特征空间维数、最优特征空间分类准确率、平均分类准确率。图2为基于高速列车运行在140km/h时的故障特征数据集的各特征选择方法的结果比较。图3为不同速度下基于4种特征选择方法获得的最优特征空间的分类准确率对比。

表3 120km/h时速列车故障数据分类结果
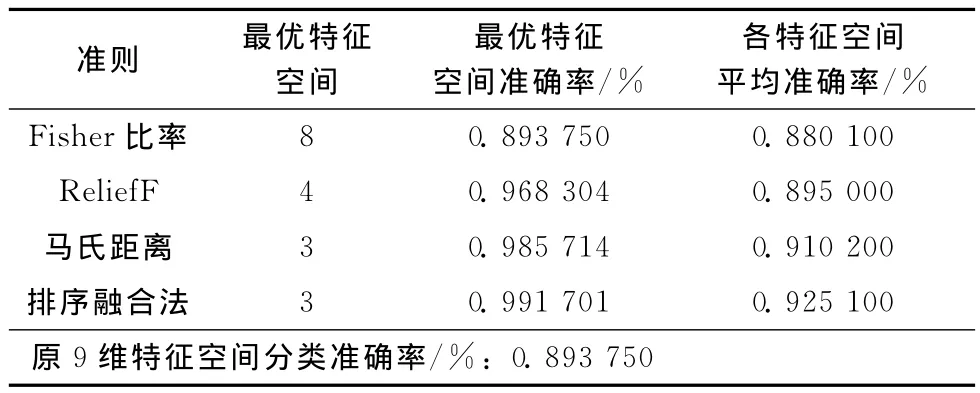
表4 140km/h时速列车故障数据分类结果

表5 160km/h时速列车故障数据分类结果

表6 200km/h时速列车故障数据分类结果

图2 各种特征选择方法比较 (140km/h故障数据集)
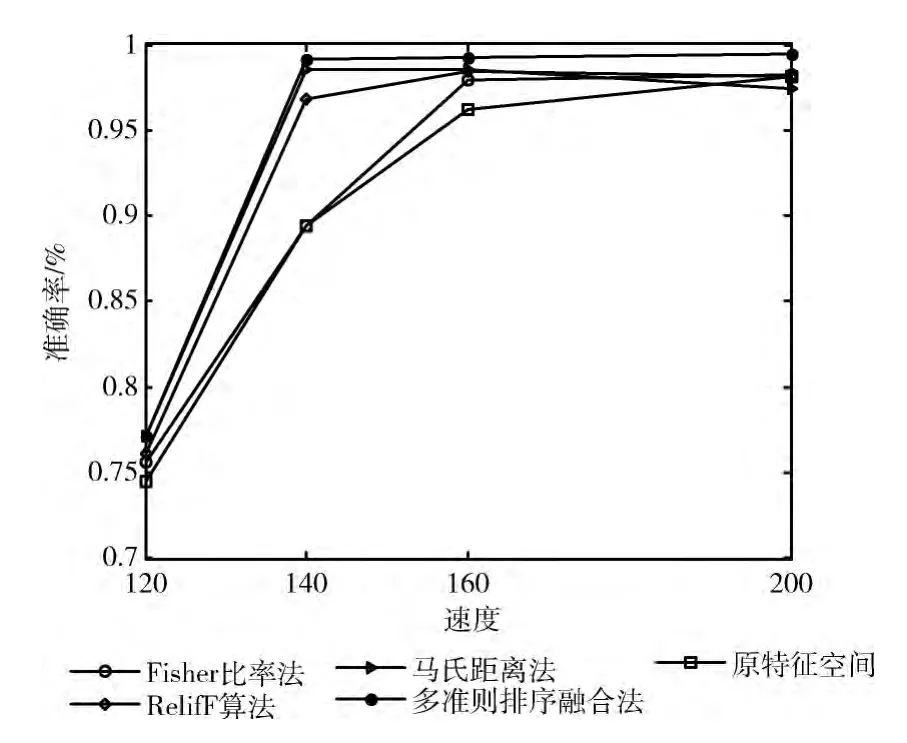
图3 不同速度4种特征选择方法分类准确率对比
表3~表6表明,4种特征选择方法均可有效降低特征空间维数,去除冗余特征,获得最优特征子集,减少计算量。其中,基于多准则排序融合的特征选择方法可将上述4种速度的特征空间分别降为2或3维,且具有较高的分类精度。在分类性能方面,相比于原特征空间的分类准确率,上述4种方法所得特征子集的分类准确率均有所提高,其中尤以多准则排序融合的特征选择法获得的最优特征子集的分类准确率提高最多,在120km/h、140km/h、160km/h、200km/h 速 度 下 分 别 提 高 2.5446%、9.7951%、3.1015%、1.3393%。由图2可知,高速列车运行速度为140km/h时,特征空间维数降低至低维 (5~1维),基于多准则排序融合的特征选择法获得的特征子集在分类性能方面具有明显的优势,其最优特征空间为3维,准确率为99.4643%,高出由其他方法获得的特征子集分类准确率0.6%~8.4%。图3表明,不同速度下,基于多准则排序融合的特征选择法获得的最优特征子集的准确率均高于其他单准则特征选择的最优特征子集分类准确率,这表明多准则排序融合的特征选择法有较好的稳定性。综上,在去除冗余特征和特征子集的分类性能方面,基于多准则排序融合的特征选择法优于单准则特征选择法。
4 结束语
本文提出了一种基于Fisher比率、ReliefF算法、马氏距离算法的多准则排序融合的特征选择方法,使多个特征选择准则实现优势互补,该方法简单方便,可更有效、更合理地进行特征选择。基于Ionosphere标准数据集和高速列车转向架故障数据集的实验结果表明,相比于单准则的特征选择方法,基于多准则排序融合的特征选择方法能更有效地降低特征空间维数,且能有效提高所获得的最优特征空间的准确率。实验证明,该方法具有良好的鲁棒性和优异性。
基于多准则的排序融合的特征选择法,在排序融合时存在参数权重选择的问题,那么如何进行参数的优化选择,如何设计更为合理的无参数权重设置的排序融合是后续研究的重点和难点。
[1]YAO Xu,WANG Xiaodan,ZHANG Yuxi,et al.Summary of feature selection algorithms [J].Control and Decision,2012,27 (2):161-166 (in Chinese).[姚旭,王晓丹,张玉玺,等.特征选择方法综述 [J].控制与决策,2012,27(2):161-166.]
[2]Zabidi A,Mansor W.The effect of F-ratio in the classification of asphyxiate infant cries using multilayer perceptron neural network [C]//EMBS Conference on Biomedical Engineering&Scence,2010:126-129.
[3]GAO Lixin,REN Zhiqiang,ZHANG Jianyu,et al.Rolling bearing fault diagnosis methods based on Fisher ratio and SVM[J].Journal of Beijing University of Technology,2011,37(1):13-18 (in Chinese). [高立新,任志强,张建宇,等.基于Fisher比率与SVM的滚动轴承故障诊断方法 [J].北京工业大学学报,2011,37 (1):13-18.]
[4]BI Kai,ZHOU Wei,JIANG Yujiao,et al.Analysis of alert log in Honeynet based on improved ReliefF [J].Computer Engineer and Design,2011,32 (7):2237-2240 (in Chinese).[毕凯,周炜,蒋玉娇,等.基于改进ReliefF算法Honeynet告警日志分析 [J].计算机工程与设计,2011,32 (7):2237-2240.]
[5]LIAO Kuo,FU Jiansheng,YANG Wanlin.Modified ReliefF algorithm for radar HRRP target recognition [J].Journal of Electronic Measurement and Instrument,2010,24 (9),831-836(in Chinese). [廖阔,付建胜,杨万麟.改进的ReliefF算法用于雷达距离像目标识别 [J].电子测量与仪报,2010,24 (9),831-836.]
[6]ZHAO Xiaoqiang,LI Xiongwei.A fuzzy C-means clustering algorithm based on improved Mahalanobis distance [J].Journal of Central South University (Science and Technology),2013,44 (2):195-198 (in Chinese). [赵小强,李雄伟.基于改进马氏距离的模糊C聚类研究 [J].中南大学学报 (自然科学版),2013,44 (2):195-198.]
[7]ZHANG Guanliang,ZOU Huanxin.Point pattern matching based on Mahalanobis distance weighted graph transformation[J].Journal of Central South University (Science and Technology),2013,44 (2):323-328 (in Chinese).[张官亮,邹焕新.基于改进马氏距离的模糊C聚类研究 [J].中南大学学报 (自然科学版),2013,44 (2):323-328.]
[8]LI Feng,WANG Zhengqun,XU Chunlin,et al.Dimensionality reduction algorithm of local marginal Fisher analysis based on Mahalanobis distance [J].Journal of Computer Applications,2013,33 (7):1930-1934 (in Chinese). [李峰,王正群,徐春林,等.基于马氏距离的局部边界Fisher分析降维算法 [J].计算机应用,2013,33 (7):1930-1934.]
[9]WEI ZY.Fusion in multi-criterion feature ranking [C]//The 10th International Conference on Information Fusion,2007:1-6.
[10]YANG Yi,HAN Deqiang.Study on feature selection based on rank-level fusion [J].Control and Decision,2011,26(3):397-401 (in Chinese). [杨艺,韩德强.基于排序融合的特征选择 [J].控制与决策,2011,26 (3):397-401.]
[11]FENG Y,MAO KZ.Robust feature selection for micro-array data based on multi-criterion fusion [J].IEEE/ACM Transactions on Computational Biology Bio-informatics,2011,8(4):1080-1092.
[12]LI Yongming,ZHANG Sujuan,ZENG Xiaoping,et al.Research of poll mode and multi-criteria feature selection algorithm based on chain-like agent genetic algorithm [J].Journal of System Simulation,2009,21 (7):2010-2017. (in Chinese).[李勇明,张素娟,曾孝平,等.轮询式多准则特征选择 算 法 的 研 究 [J].系 统 仿 真 学 报,2009,21 (7):2010-2017.]
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
数学物理学报(2021年3期)2021-07-19 06:02:44
数学物理学报(2020年6期)2021-01-14 01:00:44
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:50
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
数学物理学报(2018年2期)2018-05-14 07:32:07
儿童绘本(2018年5期)2018-04-12 16:45:32
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
