
一种监督型的连续属性离散化算法的研究
2015-04-25 08:13:06黄巧云
三明学院学报 2015年4期
黄巧云
(福州大学 至诚学院 计算机工程系,福建 福州 350002)
连续型属性离散化问题作为数据预处理中的一种基础核心技术,一直备受关注,探索该问题的有效解决方案是提高数据处理效率的关键研究内容,具有十分重要的现实意义。目前,国内外学者提出了很多方法,比较著名的有:等距离划分方法、信息熵方法,贝叶斯决策法等。但这些方法在本质上都是对属性的硬划分,而现实中事物之间的边界通常是模糊的,因此在划分地过程中如何适当地引入不确定性,使得对连续数据的划分能够与实际的数据分布相符合,是一般的硬划分方法很难做到的。根据上述问题,提出一种监督型的连续属性离散化算法,利用云变换将连续属性的定义域划分为多个基于云的定性概念,以实现定义域区间的粗划分,由于云模型软划分的特性,在定性概念边界的数据存在亦此亦彼性,所以自然地引入了不确定性;接着利用属性对类别的决定作用,通过计算云模型分界处的评价函数来判断其重要性,并决定是否对该区域进行归并处理;最后利用云模型边界数据的模糊性,对边界数据进行自适应调整,最终实现离散化的目的。
1 理论研究
1.1 云模型
设论域U={x1,x2,…,xm},A是关于U上的定性概念,若论域中的元素xi对A的隶属确定度CA(xi)∈[0,1]是一个有稳定倾向随机数,则确定度CA(xi)在论域上的分布称为云模型,简称云[1]。
云的数字特征可以用期望值Ex,熵En和超熵He 3个数值来表示,其中期望值Ex反映模糊概念的信息中心;熵En指云的期望曲线的带宽,是概念模糊度的度量;超熵He反映云的离散程度[1]。如式(1)所示:

1.2 云变换
云变换[2]根据某种规律把任意一个不规则的空间数据分布进行数学变换,生成原子概念的云模型集,使之成为若干个大小不同的云的叠加。每个云代表一个离散的、定性的概念,叠加的云的个数越多,误差越小。即:

其中g(x)为数据分布函数,fi(x)为云模型的期望函数,ci为系数,m为叠加的云的个数,e为误差阈值。
峰值云变换算法[2]认为空间数据分布的局部最高点即数据汇聚中心。根据“高频率元素对定性概念的贡献大于低频率元素对定性概念的贡献启发性”的原理,把它作为概念中心即云模型的数学期望是合理的。峰值越高,表示数据汇聚越多,就应优先考虑其所表示的定性概念,其算法步骤下所示:
Step1:初始化云模型集为空,输入数据分布函数g(x)和误差阈值e。
Step2:判断g(x)的最大值是否超过误差阈值,是则将g(x)的峰值点作为云模型的重心Ex,否则转至步骤5。
Step3:计算用于拟合f(x)的以Ex为期望值的云模型的熵和类型,并将该拟合的云模型加入云模型集。
Step4:计算拟合残差 g(x),转至步骤 2。
Step5:计算各云模型的超熵,输出云模型集。
2 监督型的连续属性离散化算法
在粗糙集理论中,决策表[3]是一类特殊而重要的知识表达系统,它表示当满足某些条件时,应当如何进行决策。通常是由一个四元组S=(U,R,V,f)来表示,其中U为对象的非空有限集合称为论域;R为属性集合;V=∪Vr,Vr是属性r的值域;f:U×R→V为信息函数,它指定了U中每个对象的每个属性值。
在具有连续属性的决策表中,令r∈C为某一连续属性,对其离散化可以看作是根据论域U中的每一个对象在连续属性r上的取值,依据某种准则对论域U进行的一种划分。对于决策表来说,如果条件属性的划分较粗,则可能导致划分后的决策表不相容,如果划分较细,又使得划分后的决策表中含有很多冗余信息,不利于数据约简。又由于现实中事物的边界通常是模糊的,所以对数据的划分过程要适当地引入不确定性,使得对连续数据的划分能够与实际的数据分布相符合。
该算法对决策表中的条件属性是一一进行处理的。首先利用云变换实现属性定义域区间的粗划分;接着通过评价函数计算云模型分界处对分类的重要性,以此决定是否对已划分区域进行归并处理;通过获得划分的云模型集,以实现连续属性离散化目的。
2.1 相关定义
定义1设论域U={u},A1(Ex1,En1,He1)和A2(Ex2,En2,He2)是论域U上的两个相邻的基本云模型.如果 Ex1<Ex2,那么 A1与 A2进行综合得到新的云模型 A3(Ex3,En3,He3):A3=A1∪A2[4]。


信息熵越小,则说明子集所包含对象的类别越一致。当H(x)=0时,子集中对象的决策属性值都相同。
定义3假设X1和X2为两个相邻云模型,其对象的个数分别为和,其中决策属性为i(1,2,…,n)所占的对象个数为ki,则该云模型分界处的评价函数定义为:
当Y值越小,则区间X1和X2合并所引起熵的变化较小,即合并X1和X2可使信息损失较小,合并后的区间中对象类别一致性程度较大。
2.2 算法描述
输入:决策表S=(U,R,V,f),其中R=C∪D为属性集合,论域为U,条件属性集C均为连续属性,决策属性集为D。
输出:离散化后的决策表。
算法步骤:
Step1:根据数据分布,生成每个连续属性的数据分布概率密度函数;
Step2:利用峰值云变换算法,将连续属性数据分布转换为多个云模型表征的定性概念的集合;
Step3:将连续属性映射到概念集中的相应概念上,并对概念集用0,1,2,3,…,进行编码,实现对连续属性初步离散化;
Step4:对论域中的对象,根据云的数字特征,计算它们对各个云模型的隶属度,并进行标识;
Step5:输出离散化后的决策表。
3 仿真实验
3.1 实验数据及参数设置
为了验证所提出的离散化模型有效性,实验数据采用UCI数据库的数据集Iris,该标准数据集被广泛用于对连续属性离散化算法的测试。数据集中共有150条记录,每条记录有5个属性,其中4个连续属性,最后一个用于标识记录的类别。
3.2 实验结果及分析
图1~4为利用云模型对Iris的4个连续属性进行离散化所得到的结果。
由图可知,利用云模型对决策表的连续属性进行软划分,能够较好地反映数据的实际分布情况。由于云模型具有模糊性和不确定性,同样的数值可以得到不同的隶属度,所以在两个概念相交的区域,数值相同的元素,在不同的情况下,可以被划分到不同的概念中,这就实现了对数据的软划分,且离散化结果也与实际数据分布较为符合。

图1 连续属性1离散化结果
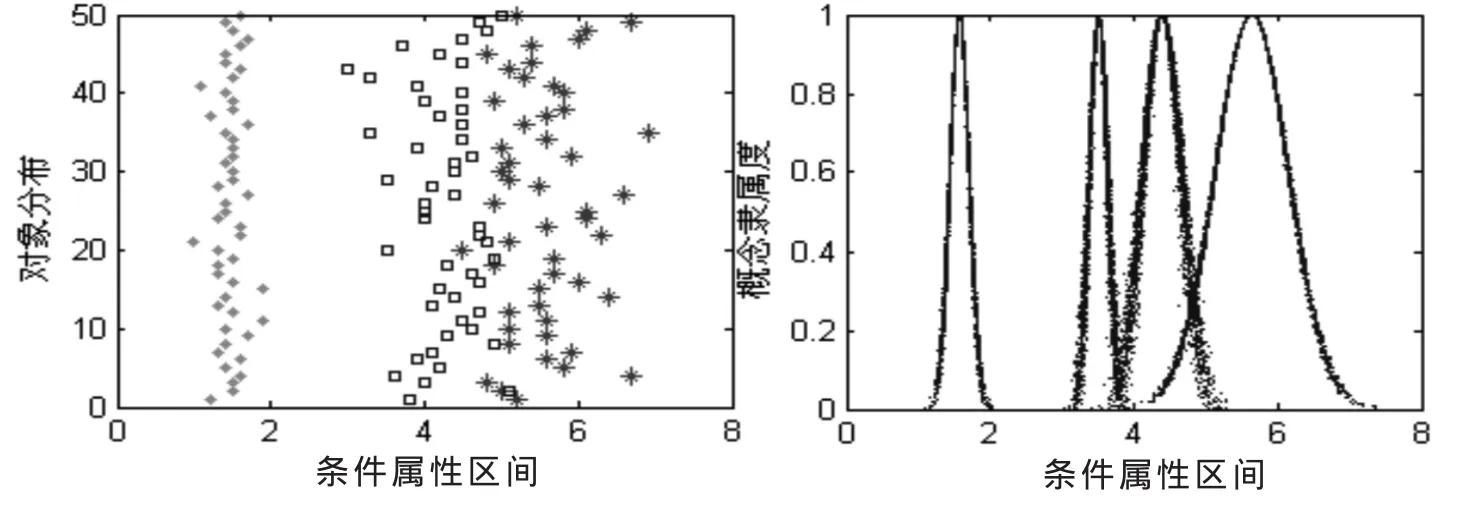
图2 连续属性2离散化结果
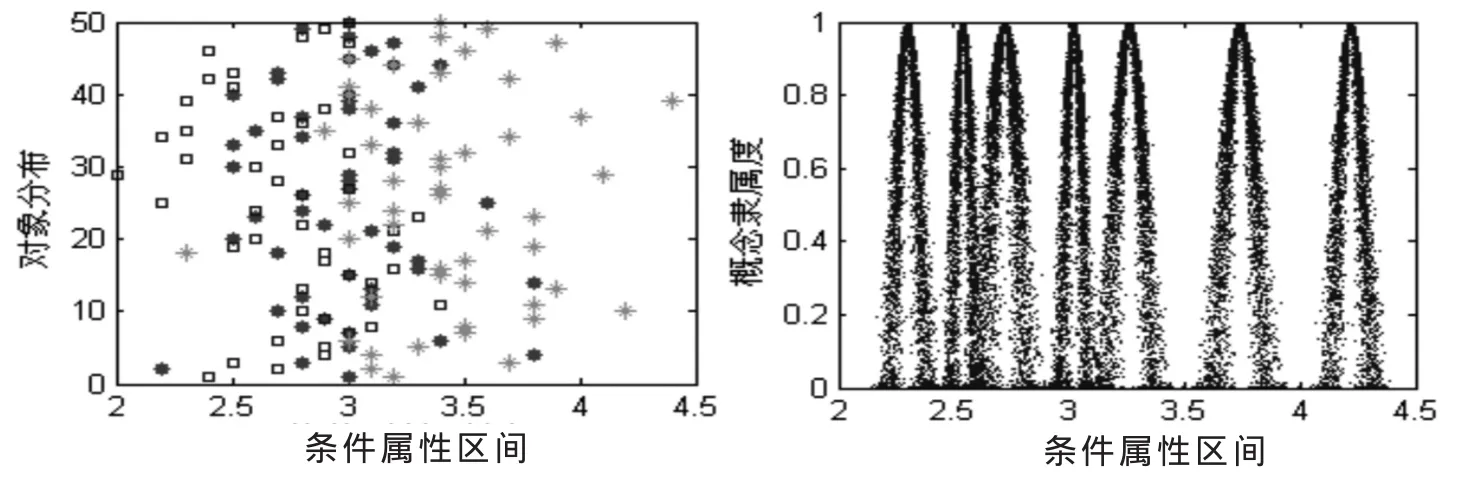
图3 连续属性3离散化结果
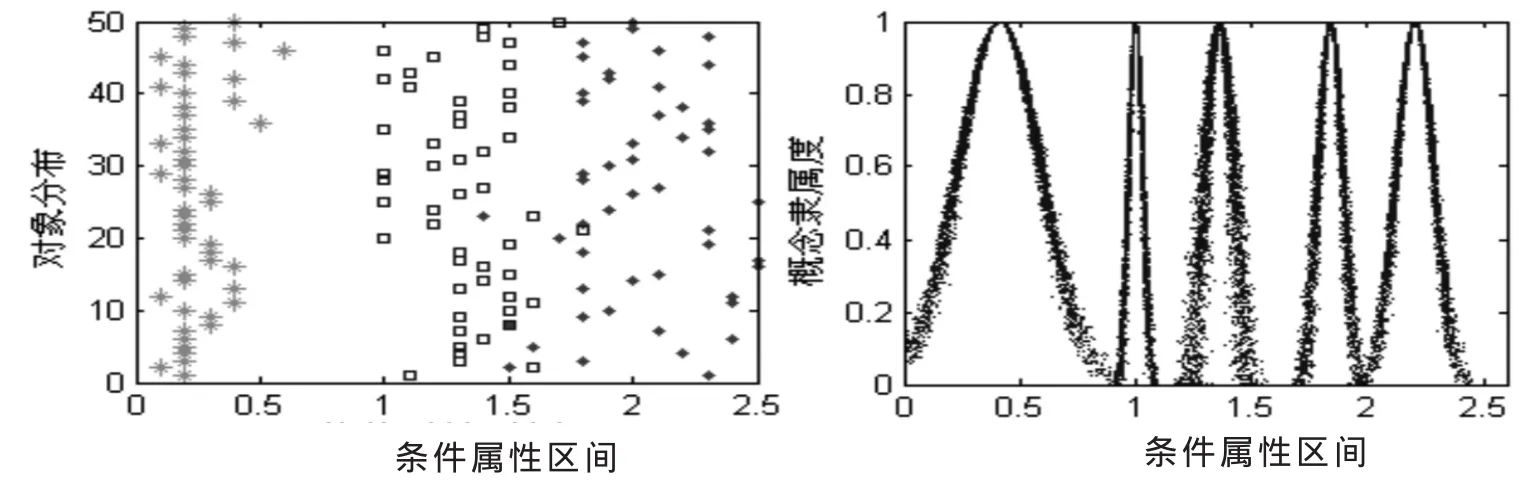
图4 连续属性4离散化结果
由于云模型具有模糊性,可能会造成离散化后的决策表不相容。虽然一般的决策表离散化算法要求离散化后的决策表是相容的,但在实际中,为了使最后获得的决策规则具有更好的适应性和鲁棒性,一般都要适当地引入一定的不确定性,这也符合现实世界中事物存在的本来状态。
3.3 算法改进
在引入不确定性的前提下,为了进一步提高决策表的一致性水平,利用属性对类别的决定作用,通过计算云模型分界处的评价函数,以此决定是否对已划分区域进行归并处理,进一步减少划分的属性区间的个数。
输入:决策属性集D,初始划分的云模型集Cloud,误差阈值e。
输出:离散化后的决策表。
算法步骤:
Step1:根据公式(6),计算每个云模型的信息熵y;
Step2:根据公式 (7),依次计算相邻两个云模型的分界处评价函数Y并进行判断,如果,从Cloud中删除这两个相邻的云模型,并根据公式(3)~(6)计算合并后的云模型,加入至中;
Step3:如果Cloud中每个云模型的对象都有相同的决策属性或者Cloud中云模型的个数已不再发生更改,则转至步骤4;否则转至步骤2;
Step4:依次判断同时位于相邻两个云模型之间的对象,分别计算其隶属于不同云模型情况下的信息熵,并将其划分到信息熵较小的云模型,以进行一种自适应调整;
Step5:输出离散化后的决策表。
为了验证该算法的有效性,对离散化后的数据用Weka数据挖掘工具提供的J-48分类器、IB1分类器和BayesNet分类器进行分类实验,将改进前的算法(Algorithm1)以及改进后的算法(Algorithm2)作为对比。
衡量一个离散化算法的标准,通常从两个方面着手:(1)离散化后的断点数,即基云的个数;(2)离散化后的数据对后续分类算法是否有效。
表1表示在不同算法下的离散化结果,其中Att1,Att2,Att3,Att4分别表示Iris数据集的4个属性;表2表示两种离散化结果在不同分类器下的分类结果。从上表可以看出,在引入不确定性的前提下,利用云模型与信息熵相结合所构成的离散化算法,仍可以得到较高的分类识别率。改进后的离散化算法所得到的基云个数更少,有利于降低数据规模;同时,在不同分类器的作用下,改进后的离散化算法精确度更高,误识率更低。实验结果证明,该监督型的连续属性离散化算法是一种有效的方法。
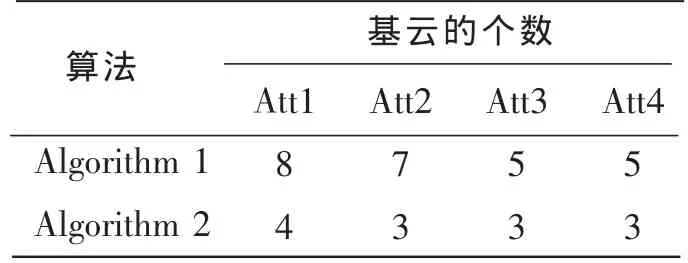
表1 离散化后基云的个数
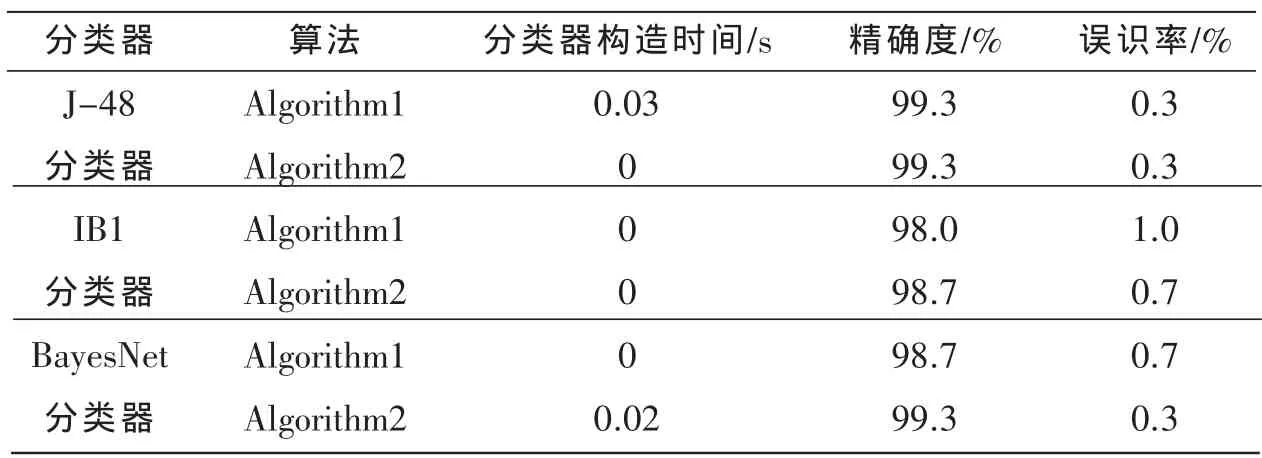
表2 分类测试结果
3.4 算法复杂性分析
假设记录个数为n,仅考虑对一个连续属性进行离散化的复杂性分析。
数据的概率密度函数的生成为O(n);云变换的执行时间为O(m×n),其中m为生成的云模型的个数;信息熵的计算为;O(m)云模型归并的时间为 O(m2);边界数据自适应调整时间 O(n×n×(m-1))。因此,对于一个连续属性离散化的时间复杂度为O(n×n×m),对于一张决策表的离散化时间复杂度为 O(n×n×m×k),k 为条件属性个数。
4 结束语
本文提出的基于监督型的连续属性离散化模型,利用云变化实现属性区间的划分,由于云模型软划分的特性,适当地引入了不确定性,这更加符合实际数据分布和人的思维方式;利用属性对类别的决定作用,对初始划分区域进行归并,能够有效提高信息系统中信息的粒度,并降低数据规模。实验结果表明,该算法具有较少的离散化区间数以及具有较高的分类精度。
[1]李德毅.知识表示中的不确定性[J].中国工程科学,2000,2(10):73-79.
[2]杜鹢,李德毅.基于云模型的概念划分及其在关联采掘上的应用[J].软件学报,2001,12(2):196-203.
[3]刘清.Rough集及 Rough推理[M].北京:科学出版社,2001.
[4]蒋嵘,李德毅,范建华.数值型数据的泛概念树的自动生成方法[J].计算机学报,2000,23(5):470-476.
[5]FAYYAD U M,IRANI K B.On the handling of continuous-valued attributes in decision tree generation [J].Machine Learning, 1992,8(1):87-102.
猜你喜欢
舰船电子工程(2022年4期)2022-05-11 09:34:32
悦游 Condé Nast Traveler(2021年2期)2021-02-04 07:42:10
南方周末(2021-01-28)2021-01-28 11:18:06
硅酸盐通报(2020年12期)2021-01-11 07:19:08
数码设计(2020年16期)2020-12-08 02:12:05
材料工程(2019年1期)2019-01-16 07:00:44
电子技术与软件工程(2016年8期)2016-07-10 08:07:53
中兴通讯技术(2016年2期)2016-03-24 00:14:53
电测与仪表(2015年13期)2015-04-09 11:57:36
北方经贸(2014年8期)2014-09-21 20:32:16
