
一种基于Tri-training的半监督多标记学习文档分类算法
2015-04-25 08:24高嘉伟梁吉业刘杨磊
中文信息学报 2015年1期
高嘉伟,梁吉业,刘杨磊,李 茹
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
一种基于Tri-training的半监督多标记学习文档分类算法
高嘉伟1,2,梁吉业1,2,刘杨磊1,2,李 茹1,2
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
多标记学习主要用于解决因单个样本对应多个概念标记而带来的歧义性问题,而半监督多标记学习是近年来多标记学习任务中的一个新的研究方向,它试图综合利用少量的已标记样本和大量的未标记样本来提高学习性能。为了进一步挖掘未标记样本的信息和价值并将其应用于文档多标记分类问题,该文提出了一种基于Tri-training的半监督多标记学习算法(MKSMLT),该算法首先利用k近邻算法扩充已标记样本集,结合Tri-training算法训练分类器,将多标记学习问题转化为标记排序问题。实验表明,该算法能够有效提高文档分类性能。
半监督学习;多标记学习;文档分类
1 引言
多标记学习(multi-label learning)[1]是近年来机器学习领域中的研究热点问题之一。在多标记学习问题中,一个训练样本可能同时对应多个不同的类别标记,以表达其丰富的语义信息,那么学习的任务是为待分类样本预测其可能对应的类别标记集合。多标记学习问题广泛存在于真实世界中,比如在文档分类任务中,如图1所示的一篇关于“2016年巴西奥运会”的网页文档中,同时拥有“体育”、“志愿者”以及“南美洲”等多个类别标记。
如果每个样本只对应一个类别标记,那么多标记学习问题可以退化为传统的两类或多类学习问题。然而,多标记学习的普适性使得其相对于传统的学习问题更加地复杂并难以解决。当前,多标记学习面临的最大挑战在于标记输出空间过大,即与一个待学习样本相关联的候选类别标记集合的数量将会随着标记空间的增大而成指数规模增加。如何充分利用标记之间的相关性是构造具有强泛化能力多标记学习算法的关键。按照考察标记之间相关性的不同方式, 已有的多标记学习问题求解策略大致分为三类,即“一阶”策略、“二阶”策略和“高阶”策略[2]。

图1 多标记学习网页文档分类示例图
传统的多标记学习通常是在监督意义下考虑的,即要求训练集的所有样本必须是已标记样本。然而,在现实生活中,虽然获取大量的训练样本并不十分困难,但是为这些数据提供准确完备的类别标记却需要耗费大量的时间和人力资源。例如,在上述网页文档分类任务中,现实世界中存在着海量的未标记文档,且每一篇文档可能拥有大量的候选类别标记。如果要完整标注训练集中的每一个样本就意味着需要查看每一篇文档的所有候选类别并逐一标注。当数据规模较大或者候选类别数目较多时,要获得完整类别标记的训练样本集是非常困难的。此时,如果只使用少量已标记样本训练,则得到的模型很难具有较强的泛化能力。而半监督学习能够较好地解决上述问题,它综合利用少量的已标记样本和大量的未标记样本以提高泛化性能[3-4]。因而,融合半监督学习机制的半监督多标记学习方法成为近年来新的研究热点。
2 背景知识
2.1 多标记学习之k近邻算法
2007年,张敏灵等人[5]把传统的k近邻学习算法扩展到多标记学习领域,提出了ML-kNN算法。它对于给定的分类测试样本,首先确定其在训练集中的k个近邻,然后根据挑选出的这些近邻样本的类别标记集合所蕴含的统计信息,利用最大化后验概率准则确定测试样本的标记集合。在若干多标记学习问题上的应用表明,ML-kNN算法的性能,尤其是算法执行效率方面,优于其他一些常用的多标记学习算法。
2.2 多标记学习之文档分类
多标记学习起源于文档分类研究中遇到的歧义性问题[6]。2000年,Schapire等人[7]在MachineLearning上发表文章,提出了一种基于集成学习的BoosTexter方法。该方法是对AdaBoost算法的扩展,它在训练过程中不仅要改变训练样本的权重,同时还要改变类别标记的权重。在此之后,多标记文档分类问题引起了学界的广泛关注。
2001年,Amanda Clare等人[8]通过改变熵的形式,改造了C4.5决策树分类算法,并使其适应多标记数据的处理。2012年,张敏灵[9]提出了一种新型多标记懒惰学习算法。它首先以测试样本为起点,按照不同的类别,对应找出这些测试样本在训练集中近邻样本,然后构造一个标记计数向量,并提交给已训练得到的分类器进行预测。2013年,程圣军等人[10]提出了一种改进的ML-kNN多标记文档分类算法,其中文档相似度利用KL散度的距离来度量,并根据k个近邻样本所属类别的统计信息,通过一种模糊最大化后验概率法则来预测未标记文档的标记集合。
目前关于文档分类的多标记学习主要集中在监督意义下。在现实生活中,为训练集标注正确完备的类别标记需要耗费大量的人力和时间。因此,如果只有少量已标记样本可以利用时,传统的多标记学习算法已不再完全适用。
2.3 半监督多标记学习
近来年,一些学者开始关注半监督多标记学习(semi-supervised multi-label learning)或直推式多标记学习(transductive multi-label learning),并取得了一些研究成果。两者的相同点是学习目的相同,都是希望从大量的未标记样本获取有价值的信息来辅助少量已标记样本的学习。但是二者的基本思想与测试环境却完全不同。直推式学习要求测试样本必须是训练集中的未标记样本,测试环境是相对封闭的;而半监督学习并无此要求,测试样本与训练样本完全无关,测试环境是开放的。
根据如果样本具有较大相似性,那么它们对应的标记集合也可能具有较大相似性的假设,Liu等人[11]于2006年提出了CNMF方法。它通过求解一个带约束的非负矩阵分解问题,在满足上述两种相似性的差值最小的情形下,希望获得的预测样本的标记最优。2008年,Chen等人[12]提出了SMSE方法,它利用样本相似性与标记相似性构图,通过标记传播思想对未标记样本的标记进行预测。2008年,姜远等人[13]提出了直推式多标记学习算法TML,采用随机游走的思想,并将其应用于文档分类问题。针对如果训练样本对应的标记集合中只有小部分拥有标记,或者根本没有任何标记,即多标记学习中的弱标记问题,Sun等人[14]和孔祥南等人[15]于2010年分别提出了WELL方法和TML-WL方法,他们都采用标记传播的思想对缺失标记进行学习。2013年,孔祥南等人[16]同样采用标记传播的思想提出了TRAM算法。它首先将多标记学习任务看作对标记集合进行估计的优化问题,在得出封闭解的基础上,给未标记样本分配其对应的标记。以上方法都是直推式方法,这类方法不能对非测试样本进行预测,具有一定的局限性。2012年,李宇峰等人[17]针对归纳式半监督多标记学习,引入正则项使得相似的样本拥有相似的标记和约束分类器的复杂度,提出了一种正则化方法MASS算法。
但是上述方法都没有考虑到目前半监督学习重要的方法之一的协同训练机制[18]在多标记学习领域的扩展和应用。2013年,刘杨磊等人[19]以协同训练思想为核心,以两两标记之间的关系为出发点,利用Tri-training算法[20]训练分类器,并将多标记学习问题转化为标记排序问题进行求解,提出了半监督多标记学习SMLT算法。从文献[19]中实验部分可以看出,已标记样本集的规模对于最终的分类结果有较大影响。因而当已标记样本集在已经给定的情形下,如何充分利用现有的数据来扩充已标记样本集从而提高多标记学习的分类性能成为本文的研究动机。
3 本文算法
本文提出了一种基于Tri-training的半监督多标记学习算法(MKSMLT),该算法首先利用k近邻算法扩充已标记样本集,并结合Tri-training算法训练得到分类器,将多标记学习问题转化为标记排序问题。
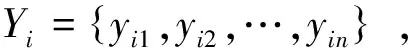
为了能够针对后续分类过程中产生的标记排序结果进行有效客观的分析,并得到最终的预测标记结果,因而在算法的预处理阶段,给所有训练样本xi添加虚拟标记yi0,并把测试样本通过分类算法在虚拟类标记上的得票数作为阈值对标记排序结果进行有效划分。因此,引入虚拟类标记后,涉及到标记的下标都应从0开始。
3.1 算法思想
传统多标记学习无法充分利用大量的未标记样本,仅凭借少量已标记样本训练得到的分类器泛化能力不强。因此,利用协同训练Tri-training算法训练分类器,能够综合利用少量的已标记样本和大量的未标记样本以提高泛化性能。为了进一步挖掘未标记样本的信息和价值,在训练分类器之前首先利用ML-kNN算法对未标记样本集进行预测,然后将预测标记中置信度较高的样本添加至已标记样本集中,以实现对已标记样本集的扩充。
首先,利用ML-kNN算法,将未标记样本集U中满足条件的样本扩充至已标记样本集L中。此时,为了将置信度较高的样本添加至已标记样本集L中得到扩充后的已标记样本集Lnew,需要设置一个阈值th筛选置信度较高的样本。由于不同的数据差别较大,该阈值由经验确定。
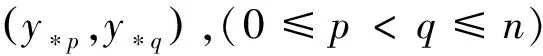
最后,在测试过程中,针对某个测试样本,用学习得到的3个分类器,对其在每一标记进行预测,并统计每个标记所得的票数Rsj,并最终得到该测试样本在所有标记上的一个标记排序结果。在此利用虚拟标记y″s0的得票数Rs0作为划分所取类标记的依据。如果Rsj>Rs0,(j=1,2,…,n),则样本x″s在第j个标记的取值为1,即y″sj=1;否则y″sj=0。这样就可以得出对测试样本的分类结果Y″。
3.2 算法流程
算法流程图如图2所示。
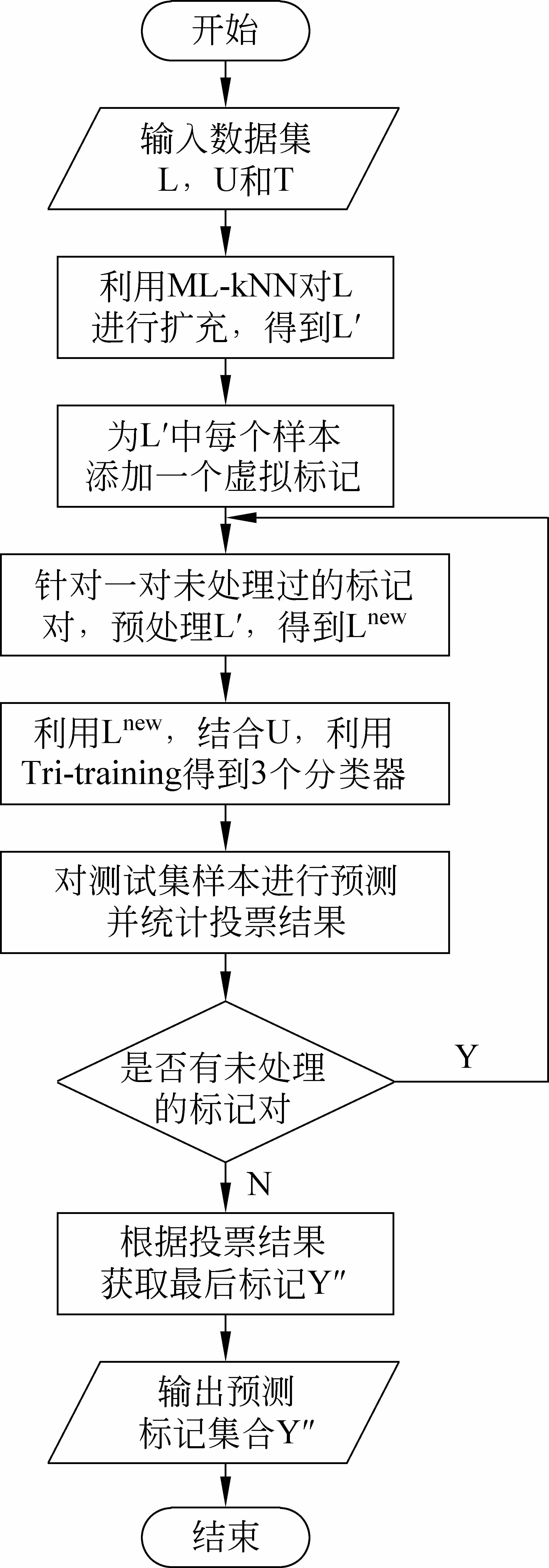
图2 算法流程图
输入:原始已标记样本集L,未标记样本集U,测试集T
输出:测试集T的分类结果Y″
步骤1 初始化用于存放投票数的Rsj和用于临时存放训练样本的集合Vpq,使Rsj=0,(s=1,2,…,w;j=0,1,…,n),Vpq=φ,(0≤p 步骤2 利用ML-kNN算法以及由经验值确定的阈值th对已标记样本集L进行扩充,得到新的已标记样本集L*。其中ML-kNN算法的参数设置为文献[6]中公布的最好参数,即最近邻数k=10,平滑指数smooth=1。 步骤5 利用得到的3个分类器对测试集T中的未标记样本x″s,(s=1,2,…,w)进行预测,得出分类结果rspq并分别统计对应标记获得的投票数。如果rspq=1,则样本x″s属于第p类标记,对应的Rsp自增1;如果rspq=0,则样本x″s属于第q类标记,对应的Rsq自增1。 步骤7 对于测试集T中的未标记样本x″s,如果其在第j个标记上获得的投票数Rsj大于虚拟标记获得的投票数Rs0,即Rsj>Rs0,(j=1,2,…,n),则未标记样本x″s在第j个标记的取值为1,即y″sj=1;否则y″sj=0。最终可以输出测试集的预测标记集合Y″={Y″s,s=1,2,…,w}。 本文实验分为两个部分,一是在各个领域中常用的多标记数据集上的实验对比,二是在网页文档分类领域中的“yahoo.com”数据集上的实验对比。 4.1 在常用多标记数据集上的对比实验 本文分别在emotions、scene、yeast、enron4个常用的多标记数据集[21]上,与多标记学习的多种算法实验对比,其中包括ML-kNN[5]、TRAM[16]以及SMLT[19]。实验数据集的相关信息如表1所示。 表1 实验数据集相关信息 实验选用常用的4种多标记学习评价指标(Hamming Loss,One-Error,Coverage,Ranking Loss)对算法性能进行评估。这4种评价指标的值越小,表明多标记学习算法的分类性能越好[22]。 实验抽取各数据集的90%作为训练样本集(其中10%的训练样本是已标记样本集L,90%的训练样本是未标记样本集U),其余10%的数据为测试样本集T,重复10次统计其平均结果。由于TRAM算法属于直推式方法,不能直接对未见样本进行预测,因而实验中将测试样本T也并入TRAM训练时的未标记样本集U中。TRAM的参数k取值为10。 表2到表5列出了相关实验结果,加粗部分为每个指标上的最佳性能。 表2 数据集yeast上各算法实验结果 续表 表3 数据集emotions上各算法实验结果 表4 数据集scene上各算法实验结果 表5 数据集enron上各算法实验结果 通过分析表2至表5,在以上4个数据集中,本文提出的MKSMLT算法大部分都取得了较好的分类结果,4个评估指标大多优于其他同类算法。 4.2 在文档分类领域中数据集上的对比实验 本文选用了2个“yahoo.com”数据集进行了实验,数据集来自于真实的网页文档。这两个数据集分别对应于yahoo的Business&Economy和Science两个一级类别,每个网页再根据yahoo的二级类别赋予标记。由于每个网页可能同时隶属于多个二级类别,因此,该数据集是较为典型的网页文本分类的多标记数据集。每个数据集都包括2 000个训练样本和3 000个测试样本。 实验同样采用上文所述的Hamming Loss,One-Error,Coverage,Ranking Loss 这4种常用的多标记学习评价指标对算法性能进行评估。 实验将抽取每个数据集2 000个训练样本中的10%为已标记样本集L,其余的90%为未标记样本集U,同时从3 000个测试样本中随机抽取300个样本作为测试集T。实验中TRAM算法设置同上。 表6和表7给出了实验结果,加粗部分为每个指标上的最佳性能。 表6 数据集Business&Economy上各算法实验结果 表7 数据集Science上各算法实验结果 通过分析表6和表7,在两个数据集上,本文提出的MKSMLT算法大部分都取得了较好的分类结果,四个评估指标大多优于其他同类算法。 本文针对广泛存在于现实生活中的半监督多标记学习问题,综合利用少量的已标记样本和大量的未标记样本,充分挖掘未标记样本的信息和价值,首先利用ML-kNN算法扩充已标记样本集,以多标记的“二阶”策略为出发点,结合Tri-training算法训练得到多标记学习分类器,将多标记学习问题转化为标记排序问题求解,并将其应用于文档文类领域。实验结果表明了本文提出算法的有效性。但是,当多标记学习问题中的标记的数量和样本的规模较大时,如何进一步降低算法的计算复杂度以及阈值参数th的选定仍将是需要深入讨论的问题。 [1]TsoumakasG,KatakisI.Multi-labelclassification:Anoverview[J].InternationalJournalofDataWarehousingandMining, 2007,3(3): 1-13. [2]ZhangMinling,ZhangK.Multi-labellearningbyexploitinglabeldependency[C]//Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,Washington,D.C., 2010, 999-1007. [3]ZhuXiaojin.Semi-supervisedLearningLiteratureSurvey[R].MadisonUniversityofWisconsin,2008. [4] 常瑜, 梁吉业, 高嘉伟,等. 一种基于Seeds集和成对约束的半监督聚类算法[J]. 南京大学学报(自然科学版), 2012,48(4): 405-411. [5]ZhangMinling,ZhouZhihua.ML-kNN:Alazylearningapproachtomulti-labellearning[J].PatternRecognition, 2007, 40(7): 2038-2048. [6] 广凯, 潘金贵. 一种基于向量夹角的k近邻多标记文本分类算法[J]. 计算机科学, 2008,35(4): 205-207. [7]RobertE.Schapire,YoramSinger.BoosTexter:aboosting-basedsystemfortextcategorization[J].MachineLearning, 2000, 39(2-3):135-168. [8]AmandaClare,RossD.King.Knowledgediscoveryinmulti-labelphenotypedata[J].LectureNotesinComputerScience, 2001, 2168:42-53. [9] 张敏灵. 一种新型多标记懒惰学习算法[J]. 计算机研究与发展. 2012,49(11):2271-2282. [10] 程圣军, 黄庆成, 刘家锋,等. 一种改进的ML-kNN多标记文档分类方法 [J]. 哈尔滨工业大学学报,2013,45(11): 45-49. [11]LiuYi,JinRong,YangLiu.Semi-supervisedmulti-labellearningbyconstrainednon-negativematrixfactorization[C]//Proceedingsofthe21stNationalConferenceonArtificialIntelligence.MenloPark:AAAI,2006: 421-426. [12]ChenGang,SongYangqiu,WangFei,etal.Semi-supervisedmulti-labellearningbySolvingaSylvesterequation[C]//ProceedingsofSIAMInternationalConferenceonDataMining.LosAlamitos,CA:IEEEComputerSociety, 2008: 410-419. [13] 姜远,佘俏俏,黎铭,等. 一种直推式多标记文档分类方法[J]. 计算机研究与发展,2008,45(11): 1817-1823. [14]SunYuyin,ZhangYin,ZhouZhihua.Multi-labellearningwithweaklabel[C]//Proceedingsofthe24thAAAIConferenceonArtificialIntelligence.MenloPark:AAAI, 2010: 593-598. [15] 孔祥南, 黎铭, 姜远,等. 一种针对弱标记的直推式多标记分类方法[J]. 计算机研究与发展. 2010,47(8):1392-1399. [16]XiangnanKong,MichaelK.Ng,ZhouZhihua.TransductiveMulti-labelLearningviaLabelSetPropagation[J].IEEETransactionsonKnowledgeandDataEngineering, 2013,25(3): 704-719. [17] 李宇峰, 黄圣君, 周志华. 一种基于正则化的半监督多标记学习方法[J]. 计算机研究与发展. 2012,49(6): 1272-1278. [18] 周志华,王珏. 半监督学习中的协同训练算法[M]. 机器学习及其应用.北京:清华大学出版社, 2007: 259-275. [19] 刘杨磊, 梁吉业, 高嘉伟,等. 基于Tri-training的半监督多标记学习算法[J]. 智能系统学报.2013, 8(5):439-445. [20]ZhouZhihua,LiMing.Tri-training:Exploitingunlabeleddatausingthreeclassifiers[J].IEEETransactionsonKnowledgeandDataEngineering, 2005, 17(11): 1529-1541. [21]http://mulan.sourceforge.net/datasets.html[OL]. [22]ZhouZhihua,ZhangMinling,HuangShengjun,etal.Multi-instancemulti-labellearning[J].ArtificialIntelligence, 2012, 176:2291-2320. A Tri-training Based Semi-supervised Multi-label Learning for Text Categorization GAO Jiawei1,2, LIANG Jiye1,2,LIU Yanglei1,2,LI Ru1,2 (1. School of Computer and Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China;2. Key Laboratory of Computational Intelligence and Chinese Information Processing of Ministry of Education, Taiyuan, Shanxi 030006,China) Multi-label learning is proposed to deal with the ambiguity problem in which a single sample is associated with multiple concept labels simultaneously, while the semi-supervised multi-label learning is a new research direction in recent years. To further exploit the information of unlabeled samples, a semi-supervised multi-label learning algorithm based on Tri-training(MKSMLT) is proposed. It adopts ML-kNN algorithm to get more labeled samples, then employs the Tri-training algorithm to use three classifiers to rank the unlabeled samples. Experimental results illustrate that the proposed algorithm can effectively improve the classification performance. semi-supervised learning; multi-label learning; text categorization 高嘉伟(1980—),讲师,博士研究生,主要研究领域为机器学习。E⁃mail:gjw@sxu.edu.cn梁吉业(1962—),博士,教授,博士生导师,主要研究领域为机器学习、计算智能、数据挖掘等。E⁃mail:ljy@sxu.edu.cn刘杨磊(1990—),硕士研究生,主要研究领域为机器学习。E⁃mail:lyl_super@126.com 1003-0077(2015)01-0104-07 2013-03-23 定稿日期: 2014-12-15 国家重点基础研究发展规划(973)前期研究专项(2011CCB311805);国家自然科学基金(61432011,61100058,61202018);山西省科技攻关项目(20110321027-01);山西省科技基础条件平台建设项目(2012091002-0101) TP391 A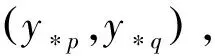
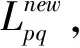
4 实验
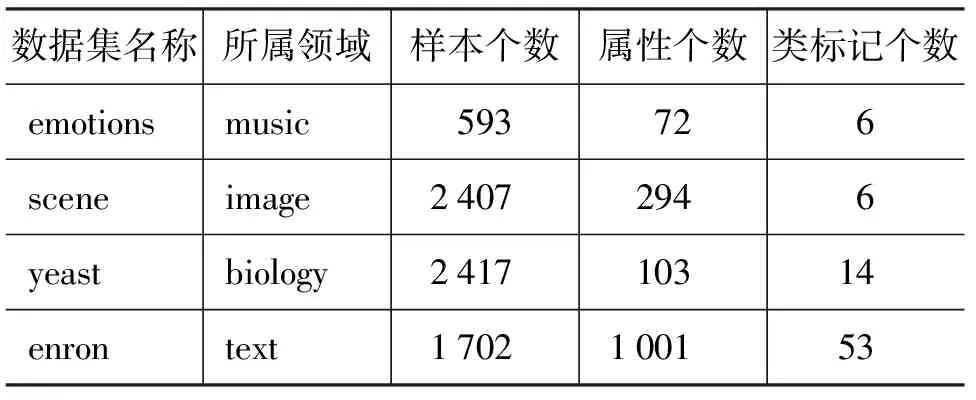
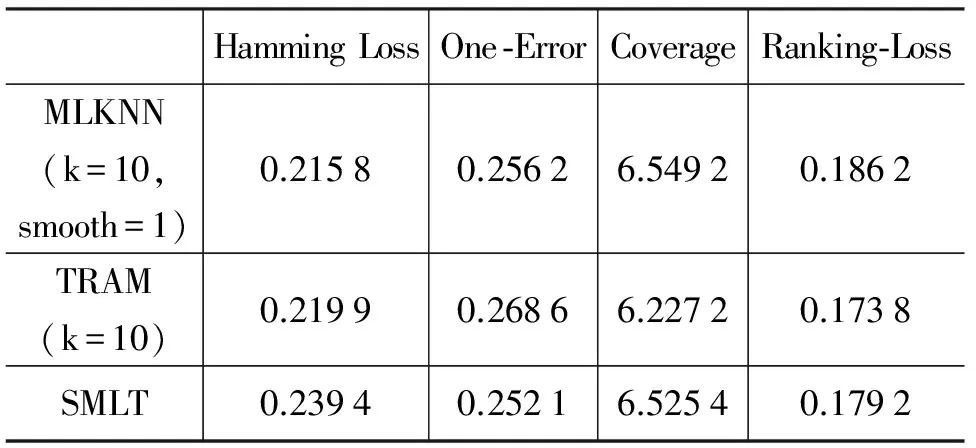

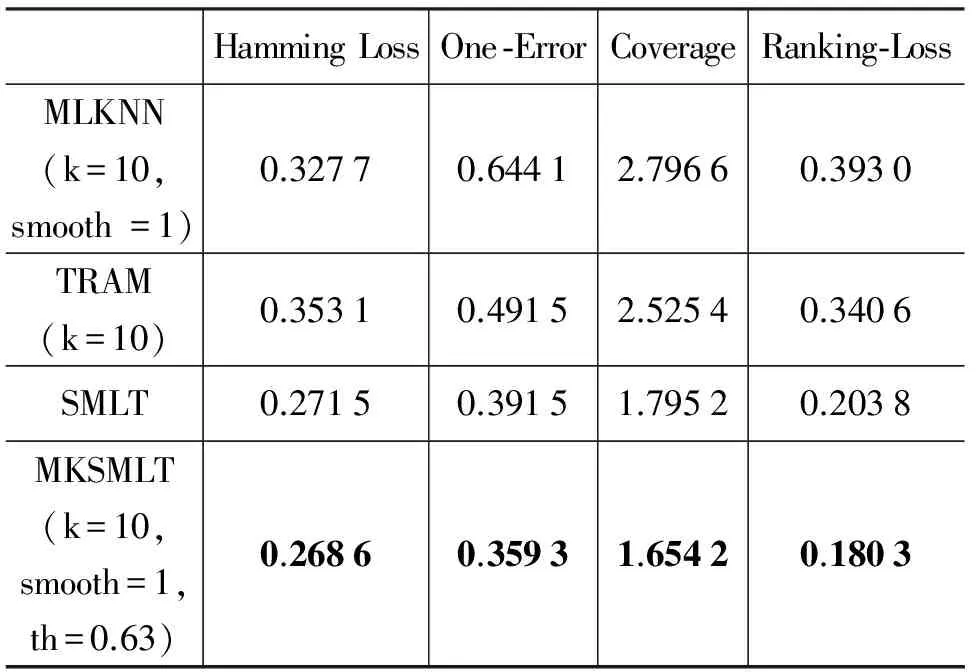
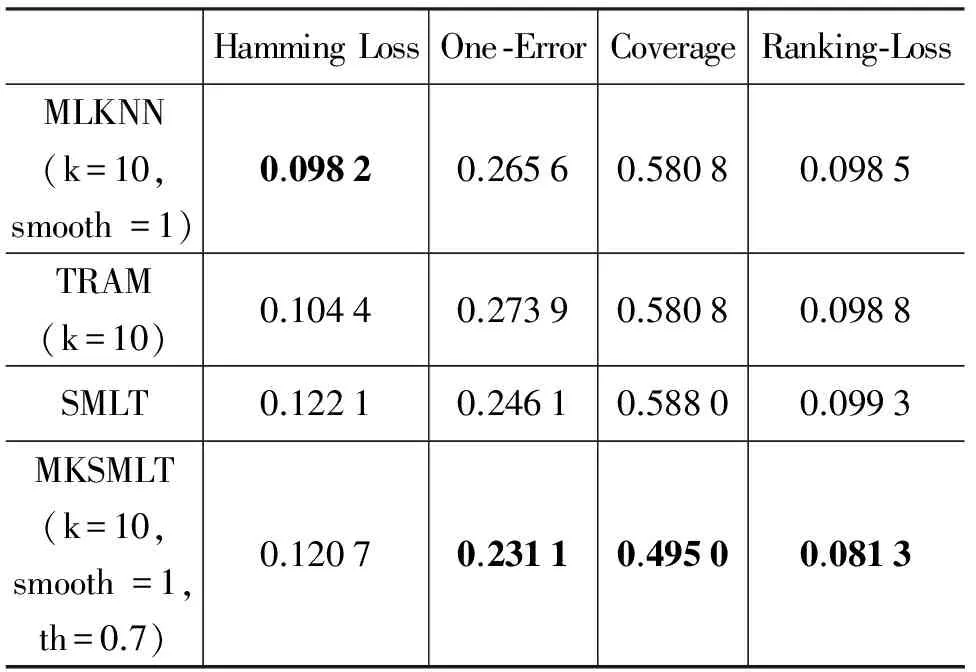
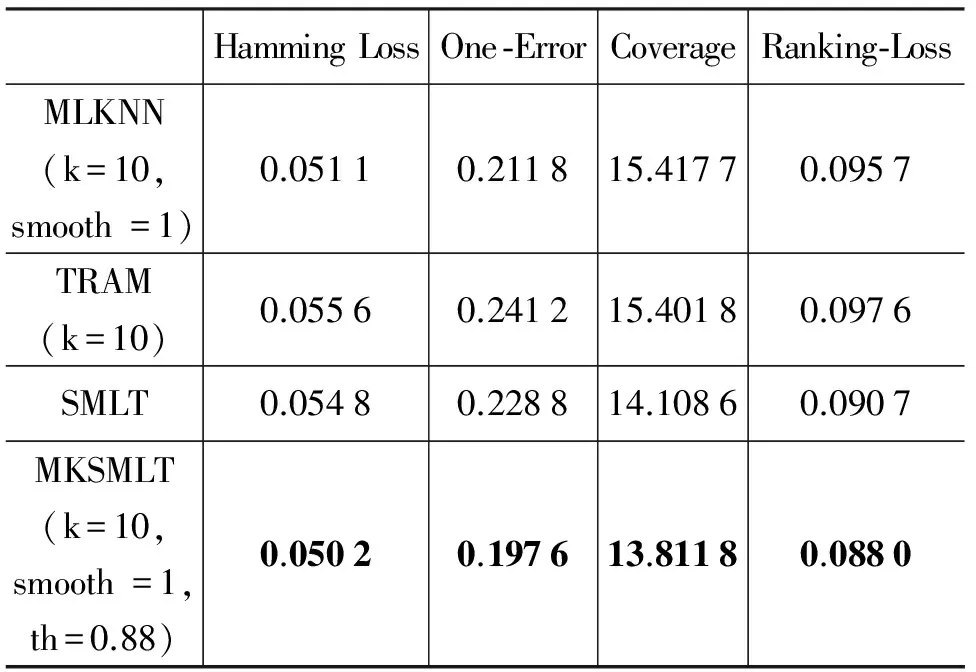
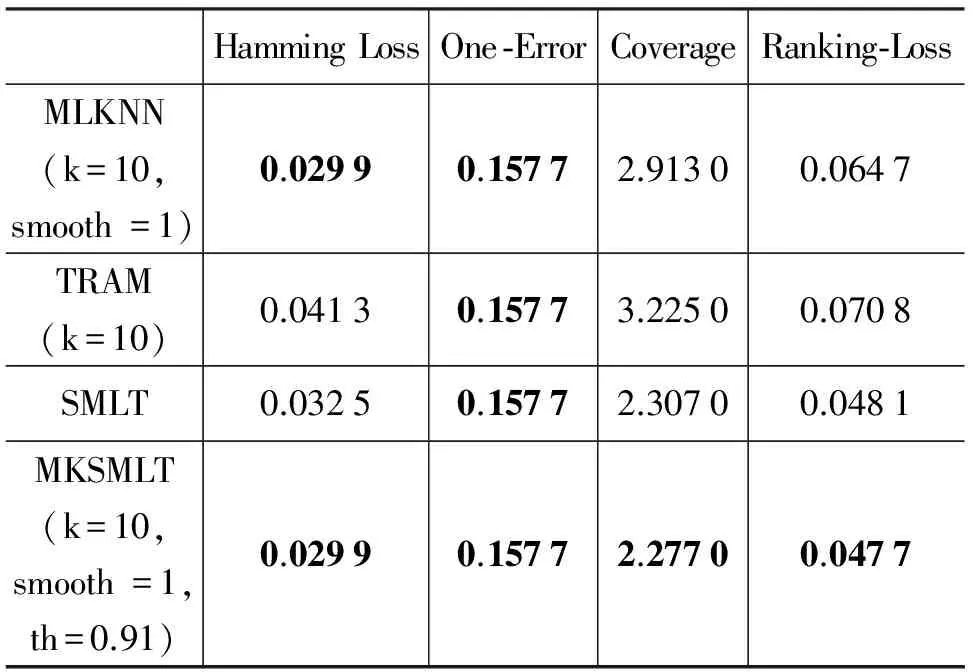
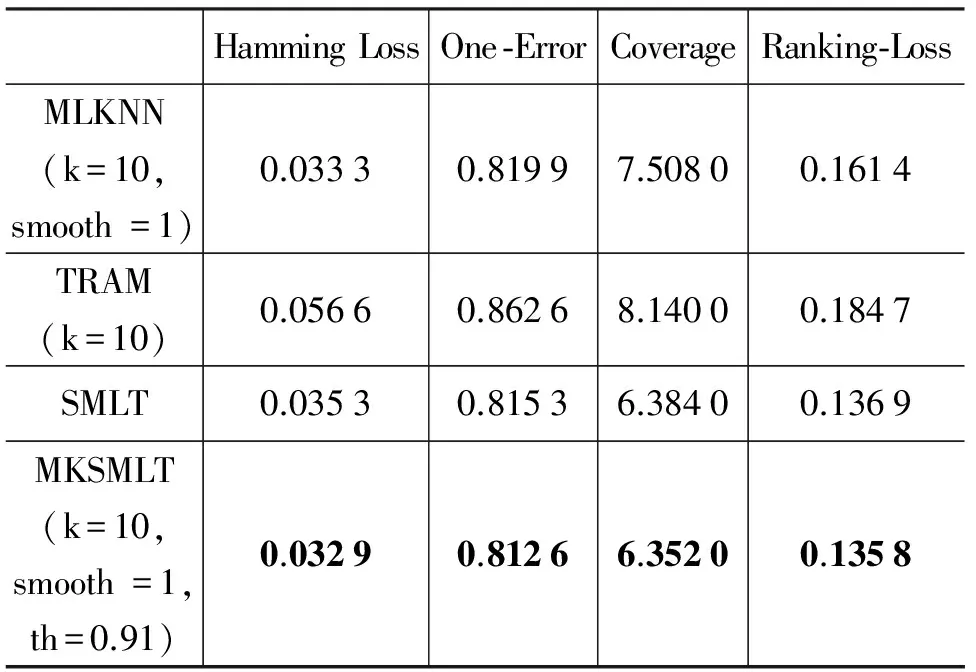
5 总结与展望

猜你喜欢
少儿画王(3-6岁)(2020年4期)2020-09-13
科技创新与应用(2020年6期)2020-02-29
电子技术与软件工程(2019年18期)2019-11-18
中国惯性技术学报(2018年4期)2018-11-08
电子技术与软件工程(2017年14期)2017-09-08
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
微型计算机(2009年4期)2009-12-23
