
基于信息熵和词频分布变化的术语抽取研究
2015-04-25 08:23:58李丽双王意文黄德根
中文信息学报 2015年1期
李丽双,王意文,黄德根
(大连理工大学 计算机学院,辽宁 大连 116023)
基于信息熵和词频分布变化的术语抽取研究
李丽双,王意文,黄德根
(大连理工大学 计算机学院,辽宁 大连 116023)
在分别研究了基于信息熵和基于词频分布变化的术语抽取方法的情况下,该文提出了一种信息熵和词频分布变化相结合的术语抽取方法。信息熵体现了术语的完整性,词频分布变化体现了术语的领域相关性。通过应用信息熵,即将信息熵结合到词频分布变化公式中进行术语抽取,且应用简单语言学规则过滤普通字符串。实验表明,在汽车领域的语料上,应用该方法抽取出1 300个术语,其正确率达到73.7%。结果表明该方法对低频术语有更好的抽取效果,同时抽取出的术语结构更完整。
术语抽取;信息熵;词频分布变化
1 引言
术语是表达特定学科领域的基本概念的语言单元,可以是词或词组。术语的定义并没有统一标准化。冯志伟在《现代术语学引论》[1]中给出了术语的定义,即“通过语音或文字来表达或限定专业概念的约定性符号,可以是词也可以是词组”。 梁爱林[2]指出“术语是指从事特定专业技术学科的人用字、词语或者字母与数码符号等来表示专业领域中的某一个概念”。冯志伟在《现代术语学引论》[1]中研究发现了术语的8大特征: 准确性、单义性、系统性、语言的正确性、简明性、理据性、稳定性、能产性。《中国大百科全书》[3]总结了术语的4个特性: 专业性、科学性、单义性、系统性。
术语是在特定领域中使用的、相对固定的词或短语,是科学研究和知识交流的有力工具。术语具有相对完整的结构和完整的领域意义。术语的自动抽取有利于自然语言处理技术的发展,可以应用于信息处理的多个方面,例如,信息检索、机器翻译、自动索引、知识库构建和信息抽取等领域。由于采用监督式的机器学习方法需要人工标注大量语料,同时人工标注语料很可能产生大量错误和不一致性,所以,当前术语的自动抽取技术主要是基于统计学的方法,并结合语言学规则进行过滤,即采用的是无监督的方法。
目前,国内外很多研究者都对术语的自动抽取技术进行了研究。主要有基于语言学规则的方法,基于统计学的方法以及统计学和规则相结合的方法。其中比较成熟的是统计学和规则相结合的方法。张峰[4]应用互信息计算字符串的内部结合强度,去除大量结构不稳定的候选短语,接着主要应用前缀和后缀信息进一步过滤候选术语,抽取出的术语的F值达到74.97%。梁颖红[5]结合NC-value参数和互信息方法用于识别3个字以上的长术语,获得了82.2%的F值。何婷婷和张勇[6]提出了一种基于质子串分解的术语自动抽取方法,分别处理简单术语和复杂术语,使术语的抽取效果得到提高。游宏梁[7]利用统计指标加权投票方法进行术语自动识别,表明加权投票方法比单一指标的识别效果更好。刘桃[8]提出了一种基于信息熵的领域术语抽取方法,该方法考虑了术语的领域分布特征,并对语料的不平衡性进行了正规化。潘渭[9]提出了使用分类方法进行专业术语定义抽取的方法,该方法将基于实例距离分布信息的过采样方法和随机欠采样方法结合,并使用BRF(Balanced Random Forest)方法来获得C4.5决策树的聚合分类结果,实验表明该方法取得的抽取效果优于仅使用BRF的方法。基于统计的方法所需的领域知识较少,且能应用于多个语种,具有很好的可移植性。但是,统计学方法需要大规模的语料,若语料规模过小则难以获得有效的统计信息,很容易获取到无效的术语,且低频术语通常被过滤掉。为了抽取出低频术语,周浪[10]提出了一种利用术语在语料中词频分布变化程度的统计信息来检测术语的领域相关性的方法,同时结合机器学习的方法获取语言知识,该方法能有效地区分低频术语和高频普通词。但是该方法应用机器学习获取语言知识的过程中需要大量的人工标注或需要有现有术语可供学习,且没有考虑到术语的内部结合强度。本文提出的方法主要是对周浪[10]的方法的改进,即在词频分布方法的基础上结合信息熵方法,在度量术语的领域分布特性的同时度量术语的完整性;同时提出边界判定算法用以进一步判定术语完整性。通过以上改进提高术语抽取效果。
2 术语抽取系统
本文实现的中文术语抽取系统基于语言学规则和统计信息相结合的方法。系统的流程图如图1所示。术语抽取系统主要由3部分组成: 文本切分、基于词频分布和信息熵的候选术语抽取、规则过滤。
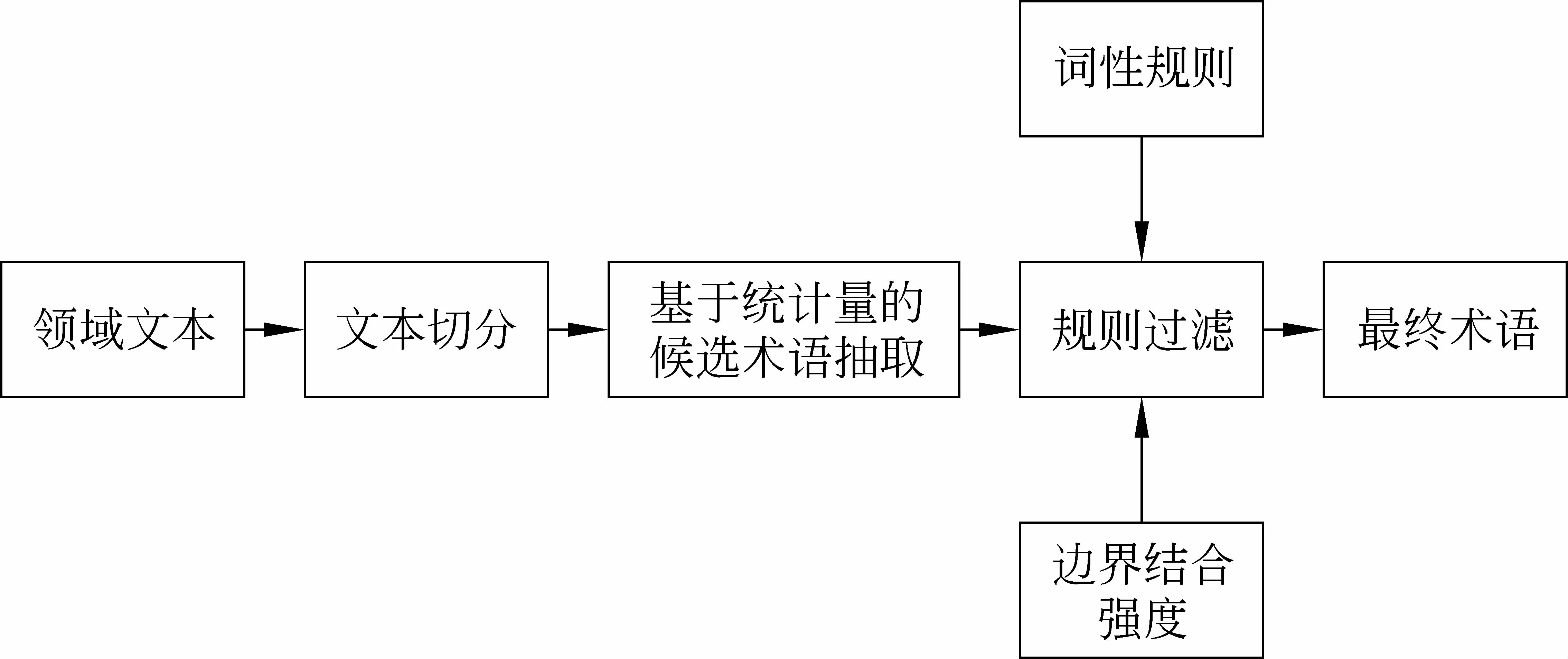
图1 系统结构图
文本切分: 使用Nihao分词系统[11]对语料进行分词处理。该分词系统使用基于字和词的条件随机场(CRFs)的联合解码模型,切分出的词相对较短,有利于召回术语。分词后,用停用词表将文本切分成词串。
统计学抽取候选术语: 对每一个字符串,统计它出现的文档频率,在各个文档中出现的频率,计算频率分布信息。结合字符串的信息熵,计算出字符串的术语领域相关程度和术语完整程度,从而得到候选术语。
规则过滤: 使用词性规则,边界结合强度和是否普通词进行规则过滤,进一步提高术语的抽取结果。
下面将会对以上3部分进行详细描述,并将结果与基于词频分布的方法进行对比,进行结果分析。
3 文本切分
当前没有公开和统一的用于术语抽取方法性能评测的语料,本文使用的语料来源于从“太平洋汽车网”上爬取的394篇网页。为了得到纯文本语料,我们对网页进行预处理,主要是去除html标签。我们发现有些网页有相互引用,为了消除重复内容对抽取效果的影响,我们进行了简单的去重操作。经过以上操作,得到大小为0.817M的汽车纯文本语料,共402 815个字。
对汽车语料进行分词后,应用经过人工收集的停用词,将语料中的每一个句子切分成相对较小的片段。其中,停用词主要包含标点符号、代词、语气词、助词、连词等。这些停用词一般没有特殊的意义,经常搭配别的词构成词或短语,且术语一般不会包含这些词,可以用于切分句子。停用词示例: “啊”、“它”、“以及”、“并且”、“咦”、“大多数”、“及时”、“几乎”、“什么”、“我”、“我们”等。
由于汽车语料中存在英文字母以及英文汽车术语,将英文字母统一转换成半角,有利于术语的抽取。经过观察发现,语料中存在大量的单位计量的短语,如“50千瓦”、“2吨”、“4个”、“100kg”;同时,语料中还有如“如图1”、“图a1”、“2010年”、“约为5.3”的短语。以上这些短语不可能是术语,也不可能构成术语的成分。我们用正则表达式将这些短语去除,将字符串进一步分割,起到相当于停用词的作用。
4 基于统计量的候选术语抽取
基于统计量的方法需要统计每一个字符串的频率信息,若采用一般的字符串比较,则系统的效率很低。本文中应用Pat-tree[12]作为索引结构,对每一个网页对应的文档建立Pat-tree,用于统计字符串的频率信息。
采用基于词的术语抽取,这不仅能减少所要统计的字符串的频率信息,而且能初步过滤掉一些边界不合理的字符串。例如,对于切分后的字符串“点火/线圈/固定”,只需将“点火”、“线圈”、“固定”、“点火线圈”、“线圈固定”、“点火线圈固定”作为候选术语,计算相应的统计量信息。假如以字为单位组合候选术语,则会出现类似“点火线”和“火线圈”这样一些结构不完整的候选术语,这不仅会使精确率下降,而且会降低效率。
4.1 词频分布变化的方法
由于术语具有领域相关性,一个术语在领域间分布不均匀,即一个术语在相关领域内出现频率较高,而在不相关领域内很少出现或几乎不出现。同时,周浪[10]研究表明在同一个领域内的不同场景下(文档中),术语的词频信息分布也有很大差别。因为在不同的场景中,讨论的话题也不同,用到的术语自然也不同。例如,在汽车语料中术语“共轨式喷油系统”总共出现了5次,且只在两个文档中出现,其中一个文档中出现了4次。
术语频率在各个文档间的波动变化可以区分术语和一般词,而样本方差是反映检验样本和总体分布的波动程度的最直接的方法。方差的值越小,表明候选术语在文档间的频率变化越小,是术语的可能性也越小。周浪[10]提出的词频分布公式如式(1):
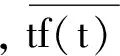
其中M为总的文档数。
4.2 信息熵的方法
信息论中的信息熵表示单个随机变量的不确定性。随机变量越不确定,其熵值越大。当信息熵用于术语抽取时,主要用于计算字符串的边界不确定性。字符串的边界越不确定,信息熵越高,且越可能是一个完整的词。
一般通过计算字符串的左信息熵和右信息熵来衡量字符串的左右边界的不确定性。在汽车语料中,在“底板上只有一根引出线接在点火线圈上,点火线圈中心有磁性棒,高压点火线拧紧在点火线圈的木螺钉上。”中,“点火线圈”出现了3次,它的左邻接字有“在”和“,”,右邻接字有“上”、“中”和“的”。在整个语料中,字符串“点火线圈”总共出现了30次,不同的左邻接字有19个,右邻接字有21个,可见“点火线圈”的左右搭配词都很不固定,因此“点火线圈”很有可能是一个完整的词,进而可能是汽车术语。而在考察“点火线”是否完整词时,我们发现“点火线”在整个语料中出现了33次,其不同的左邻接字有21个,右邻接字只有3个,则“点火线”不适合作为一个完整的词。
左右信息熵的公式[13]如式(4)、式(5)所示。
其中s是候选字符串,ls是s的左邻接字l和s结合所构成的字符串,p(ls|s)表示语料中出现s的情况下,s的左邻接字是l的条件概率。sr是s和s的右邻接字r结合构成的字符串,p(sr|s)表示语料中出现s的前提下,s的右邻接字为r的条件概率。LE(s)为字符串s的左信息熵,RE(s)为字符串s的右信息熵。LE(s)和RE(s)越大,说明左右邻接字越不固定,则s独立成词的可能性越大。为了综合评价s独立成词的可能性,任禾[13]通过给左、右信息熵设定相同的阈值来过滤不能独立成词的候选词。即如式(6)所示。
其中Emin为人工设定的阈值。
4.3 词频分布和信息熵相结合的方法
在基于信息熵的术语抽取方法中,分别为左、右信息熵设定阈值存在局限性。不仅在阈值调节时会比较繁琐,而且也不能很好地处理字符串的左、右信息熵的不平衡。假如字符串的左信息熵较低,同时右信息熵较大,字符串仍有可能是候选术语。例如,术语“共轨系统”的左信息熵为2.09,右信息熵为3.45;术语“油压”的左信息熵为3.53,右信息熵为2.23。在结合左、右信息熵的同时,综合考虑左右信息熵的不平衡性,将得到如下信息熵公式,如式(7)所示。
在基于词频分布的术语抽取方法中,词频分布只考虑了术语的领域相关性,而没有考虑术语是否独立成词,因此很可能会抽取出一些结构不完整的字符串,比如“手动变速箱系统”,而语料中正确的术语应该是“自手动变速箱系统”。词频分布公式中引入了平均词频,但用信息熵代替平均词频能很好地对术语是否独立成词加以判断,由此,得到式(8)。
5 规则过滤
本文使用的规则主要有词性规则、普通词过滤、边界判定是否合理、是否在其他语料中出现次数较多等。只考虑词频大于2的候选术语,且候选术语的长度小于10。使用的词性规则主要是术语词性的组合方式。
所采用的规则说明如下:
(1) 词性规则主要有:
① 术语中不能包含叹词、代词、处所词、状态词;
② 术语不能以助词、连词、后缀开头;
③ 术语不能以前缀、方位词、连词、助词结尾;
④ 术语中必须含有名词、动词或量词成分。这些词性规则是在周浪[10]的词性规则基础上改进的,以符合汽车术语的词性规律。
(2) 由于绝大多数的普通词都不是术语,我们用分词字典构建了一个普通词列表,用于过滤候选术语中的普通词,例如“上课”、“下雨”、“春天”等。
(3) 虽然应用了信息熵,但还是有些候选术语不能独立成词。通过进一步的边界判定进行过滤,算法过程如图2所示。

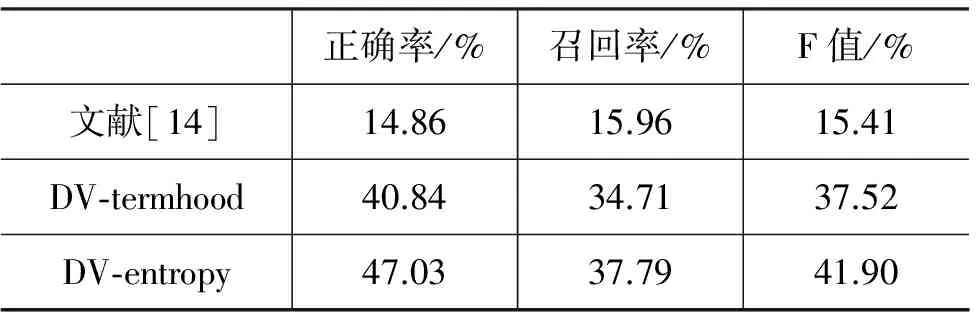
(a)语料经过停用词分割后的字符串集为A;(b)遍历字符串集A,找出包含候选术语s的所有字符串B;(c)对B中每一个字符串分词;(d)ld=0,rd=0,遍历每一个分词后的字符串a1a2a3…an,其中s=ai…aj,计算ai-1ai的互信息值MI(ai-1ai),计算aiai+1的互信息值MI(aiai+1)。若MI(ai-1ai) (4) 应用辅助的计算机语料,若候选术语在计算机语料中的词频超过在汽车语料中的词频的一半,则将候选术语过滤,当然这是在同样规模的语料的情况下。应用计算机辅助语料是为了过滤汽车语料中的部分计算机术语。 为了得到正确率高的术语,我们将规则过滤后的术语按其DV-entropy值从高到低排序。DV-entropy值越高,是术语的可能性也越高。由于本文使用的语料较小,只有0.817M,周浪[10]使用的语料大小为1.27M,他主要评价了前2 000个抽取出的术语,为了与周浪[10]的方法比较,我们只评价前1 300个抽取出的术语。当前,实验结果的评价标准主要是正确率、召回率和F值。 (9) 在使用相同的语言学规则和语料的情况下,表1对比了词频分布变化和改进的方法的术语抽取性能。在抽取相同的数量的术语的前提下,比较术语的正确率、召回率和F值。分别比较了抽取100,200,500,800,1 000,1 300个术语时,两种方法的结果。 表1 词频分布(DV-termhood)和本文方法(DV-entropy)的比较: 使用相同的语言学规则和语料 表1表明随着抽取出的术语数量的增加,术语的正确率在降低,召回率在增加,F值也在增加。从总体上看,在抽取出相同数量的术语时,DV-entropy方法的正确率、召回率和F值都要比DV-termhood高。由于抽取的术语相对于语料含有的术语量较少,DV-entropy和DV-termhood方法的召回率和F值区分不大,我们将进一步分析正确率。由前100个抽取的术语的正确率远高于前1 300个的正确率,可以得出字符串的DV-entropy值越高,则字符串是术语的可能性越大。再者,从0.817M的语料中抽取出1 300个术语,术语相对稀疏,由此可知DV-entropy方法对低频术语具有较好的识别能力。由表1可以看出,改进后的方法比基于词频分布的方法的正确率要高14%~20%。这是因为改进后的方法能很好地判断抽取出的术语是否完整,同时又结合了术语的领域分布不平衡特征。周浪[10]的基于词频分布的方法会抽取出一些在少数文档中出现频率较高的字符串。例如,“公式下”只出现在一个文档中,因而其DV值相对较高,从而引入错误。信息熵可以度量字符串“公式下”的完整性,因此结合信息熵和词频分布变化的方法可以避免类似的错误。 改进后结果得到了提高,但也存在一些错误,例如, 1) 对于文本中那些结构完整,出现频次高的字符串,其信息熵值一般会随着频次的增加而增加。虽然其词频分布变化较小,但最终的DV-entropy值会比较高。如“制动时”的频次为67,信息熵为13.8,其对应的方差值为2.0,最终其DV-entropy值高达27.6,而所用的词性规则不足以过滤它,因此会引入错误。类似的识别的错误串有“汽车设计”、“传递动力”、“总质量”等。 2) 原本属于同一个文档中的内容,经过分页后,会存在于多个网页中,而本文在处理的过程中,并没有将这些网页合并。这会使公式中词频分布变化部分降低方差值,从而降低DV-entropy值。因此,文档分页问题会影响本文提出的方法的性能。在将来的工作中,将针对文档分页问题进行研究,以提高系统性能。 文献[14]结合了互信息、信息熵和C-value的方法,在此基础上使用语言学规则进行过滤。文献[14]中对长度大于3的字符串使用互信息和C-value相结合的方法,对长度小于等于3的使用信息熵和C-value相结合的方法。文献[14]使用的语料和本文所使用的语料完全相同。该语料是从网上爬取的包含汽车术语的语料,经过去除标签和重复页面后,大小为0.817M,字数约为40万字。表2对比了文献[14]的方法和本文方法的术语抽取的结果,可以看出本文方法的F值比文献[14]提高了26.5%。实验表明,本文所使用的DV-entropy方法和规则能有效地提高术语识别效果。简单统计学的方法不能很好地识别低频术语,原因在于汽车语料存在术语稀疏问题,且简单统计学方法不能很好地判断术语的完整性,例如“无触点磁电机”的子串“触点磁电机”和“无触点磁电”会被识别为术语。本文采用的方法则对此进行了有效的改进。 在使用相同的语料和语言学规则的情况下,进一步比较DV-entropy方法和基于词频分布变化(DV-termhood)的方法,表2中列出了基于词频分布变化的统计数据。由表中数据可知,DV-entropy方法的正确率和召回率都要比DV-termhood方法高,从而F值也比DV-termhood方法高4.38%。从总体上来说,DV-entropy和DV-termhood方法的F值都不高,原因在于所使用的语料中只出现一次的术语占所有术语的47.9%,即存在术语稀疏问题。 表2 其他方法和本文方法比较 词频分布变化表示术语的领域相关性,信息熵表示术语的完整性。本文改进了基于词频分布变化的术语抽取方法,在词频分布变化中加入信息熵值,并结合一系列术语的语言学规则,构建了一个术语抽取系统。该方法优于当前用于低频术语识别的基于词频分布的方法,对低频术语有较好的识别能力。为了排除非汽车术语,在下一步工作中,将引入百科语料,同时避免降低系统效率。 [1] 冯志伟. 现代术语学引论[M]. 北京:语文出版社,1997:1-20. [2] 梁爱林.论术语学概念理论的发展[J].术语标准化与信息技术.2003(4):4-10. [3] 胡乔木等人.中国大百科全书[M].语言卷.术语.北京:中国大百科全书出版社,2003. [4] 张锋,许云,侯艳,等.基于互信息的中文术语抽取系统[J].计算机应用研究,2005,22(5): 72-73. [5] 梁颖红,张文静,周德福.基于混合策略的高精度长术语自动抽取[J]. 中文信息学报,2009,23(6):26-30. [6] 何婷婷, 张勇.基于质子串分解的中文术语自动抽取[J].计算机工程,2006,32(23): 188-190. [7] 游宏梁,张巍,沈钧毅,等. 一种基于加权投票的术语自动识别方法[J]. 中文信息学报,2011,25(3): 9-16. [8] 刘桃,刘秉权,徐志明,等.领域术语自动抽取及其在文本分类中的应用[J].电子学报,2007, 35(2): 328-332. [9] 潘渭,顾宏斌. 采用改进重采样和BRF方法的定义抽取研究[J]. 中文信息学报,2011,25(3): 30-37. [10] 周浪,张亮,冯冲等.基于词频分布变化统计的术语抽取方法[J].计算机科学,2009,36(5):177-180. [11] Degen H, Deqin T, Yanyan L. HMM revises low marginal probability by CRF for Chinese word segmentation[C]//Proceedings of CIPS-SIGHAN Joint Conference on Chinese Processing, Beijing, 2010, 216-220. [12] Gaston H G, Ricardo A B, Tim S. New indices for text: pat trees and pat arrays[C]//Information Retrieval Data Structures & Algorithms, 1992:66-82. [13] 任禾,曾隽芳.一种基于信息熵的中文高频词抽取算法[J].中文信息学报.2006,20(5): 40-43. [14] 李丹. 特定领域中文术语抽取[D]. 2011.大连理工大学硕士学位论文. Term Extraction Based on Information Entropy and Word Frequency Distribution Variety LI Lishuang, WANG Yiwen, HUANG Degen (School of Computer Science and Technology, Dalian University of Technology, Dalian Liaoning 116023, China) A term extraction system based on information entropy and word frequency distribution variety is presented. Information entropy can measure the integrality of the terms while word frequency distribution variety can measure the domain relativity of terms. Incorporating with simple linguistic rules as an addition filter,the automatic term extraction system integrates information entropy into word frequency distribution variety formula. Preliminary experiment on the corpus of automotive domain indicates that the precision is 73.7% when 1,300 terms are extracted. The result shows that the proposed approach can effectively recognize the terms with lower frequency and the recognized terms are well of integrality. term extraction; information entropy; word frequency distribution variety 李丽双(1967—),副教授,主要研究领域为自然语言理解、信息抽取与机器翻译。E⁃mail:lils@dlut.edu.cn王意文(1988—),硕士研究生,主要研究领域为信息抽取。E⁃mail:yeevanewong@gmail.com黄德根(1965—),教授,主要研究领域为自然语言理解与机器翻译。E⁃mail:huangdg@dlut.edu.cn 1003-0077(2015)01-0082-06 2012-08-09 定稿日期: 2013-03-11 国家自然科学基金(61173101, 61173100) TP391 A6 实验结果与分析



7 与其他方法比较
8 总结

猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
园林科技(2021年3期)2022-01-19 03:17:48
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
池州学院学报(2015年3期)2016-01-05 01:13:00
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
