
面向微博搜索的时间敏感的排序学习方法
2015-04-21 08:18王书鑫卫冰洁
中文信息学报 2015年4期
王书鑫,卫冰洁,鲁 骁,王 斌
(1. 中国科学院大学 中国科学院计算技术研究所,北京 100190 2. 国家计算机网络应急技术处理协调中心,北京 100029;3. 中国科学院信息工程研究所,北京 100093)
面向微博搜索的时间敏感的排序学习方法
王书鑫1,卫冰洁2,鲁 骁2,王 斌3
(1. 中国科学院大学 中国科学院计算技术研究所,北京 100190 2. 国家计算机网络应急技术处理协调中心,北京 100029;3. 中国科学院信息工程研究所,北京 100093)
近年来微博检索已经成为信息检索领域的研究热点。相关的研究表明,微博检索具有时间敏感性。已有工作根据不同的时间敏感性假设,例如,时间越新文档越相关,或者时间越接近热点时刻文档越相关,得到多种不同的检索模型,都在一定程度上提高了检索效果。但是这些假设主要来自于观察,是一种直观简化的假设,仅能从某个方面反映时间因素影响微博排序的规律。该文验证了微博检索具有复杂的时间敏感特性,直观的简化假设并不能准确地描述这种特性。在此基础上提出了一个利用微博的时间特征和文本特征,通过机器学习的方式来构建一个针对时间敏感的微博检索的排序学习模型(TLTR)。在时间特征上,考察了查询相关的全局时间特征以及查询-文档对的局部时间特征。在TREC Microblog Track 2011-2012数据集上的实验结果表明,TLTR模型优于现有的其他时间敏感的微博排序方法。
时间敏感;排序学习;微博搜索
1 引言
微博作为一种新兴的Web 2.0媒体,使得海量的用户参与到信息的制造、传播和消费过程中。如何从这些具有丰富上下文环境的文档中通过检索满足用户的信息需求,是微博检索亟待解决的问题。微博检索具有和传统Web检索不同的特点: 首先,检索内容不同,例如,微博文本较短、含有主题词和各种表情符号和URL地址等。这些特点使得微博检索可使用的信息更加丰富;其次,微博检索的排序方式不同。由于微博检索中用户查询通常与当前发生的事件有关,因此相对于传统检索查询来说微博查询更具时间敏感性[1]。本文主要针对微博查询的时间敏感性展开研究。
如何将时间信息融合到检索过程中,以往的工作主要集中在以下两个方面[2]: 1)将查询和文档的文本相似性和时间相似性组合成为一个线性模型。2)将查询和文档依据文本内容和时间因素构建为一种新的概率模型,使用这个概率模型来计算查询和文档的相关性。
本文从时间因素影响微博排序的假设出发,对公开的微博检索数据集的查询进行了时间分布的分析,验证了微博查询是一种时间敏感的查询,而且不同的查询,时间因素在其排序过程中影响也不相同,之前直观简化的假设并不能够完整的概括这种规律。本文提出使用排序学习的方法来确定时间因素对微博排序影响的时间敏感的排序学习方法。
本文的主要贡献是: 1)对微博查询的相关文档的时间分布进行了考察,分析了时间因素对微博排序影响的复杂性。2)提出使用查询的时间特征分布的全局特征,如查询文档时间分布熵、查询文档平均时间、查询文档高峰时间,以及查询和文档对的局部特征如时间间隔、时间衰减、距离平均时间、距离高峰时间等特征为时间特征组;3)结合文本特征学习排序模型,并通过实验验证了时间敏感的排序学习方法的有效性。
文章内容结构如下: 第2节介绍相关工作;第3节介绍了微博查询的时间分布的分析和提出TLTR模型;第4节介绍了提出的时间和实体的特征;第5节描述实验设置和结果,最后总结并展望了未来的工作。
2 相关工作
已有的研究工作中,融合时间信息的排序方法有文献[3-4]。在文献[3]中, Li和Croft提出了基于时间先验语言模型。针对给定查询,时间越新的文档应该越相关。通过修改文档的先验P(TD),使得P(TD)是以文档集合中最新时间到文档发布时间的间隔大小衰减的指数分布。该先验可以表示为:
(1)
其中TC表示整个文档集合中最近的时间,TD则表示文档的创建时间。在文献[4]中Efron和Golovchinsky扩展了上面的方法,认为不同查询的指数分布的参数不相同,给出了参数估计的方法,进一步验证了该方法的有效性。
除了上面一般的文档的时序检索模型,也有研究者针对微博这种时间敏感的查询,提出了针对微博检索的时间感知的检索模型。如卫等在文献[5-6]中研究了将微博时间信息融入到排序模型的方法,认为查询时间越靠近查询热门时刻,文档应该更重要。基于这样的假设,文献[6]提出了基于热门时刻的语言模型(HTLM),在MAP和P@30指标上均优于基本查询似然模型和文献[3]所提出模型,验证了基于热门时刻假设的有效性。在文献[7]中,TakiMiyanishi提出利用时间信息来进行查询扩展的工作,将时间波动和Recency信息组合到查询扩展的过程中,从而提高了检索效果。文献[8]研究了一种基于时间密度估计的查询反馈算法在微博检索中的应用。文献[9]则提出了一种时间敏感的概念(concept)感知的查询扩展方法。
排序学习是使用机器学习的理论来构建排序模型的方法,是近年来机器学习理论应用到信息检索领域的重要进展之一。多数优秀的排序学习方法学习如何从查询-文档对中提取的特征中,训练组合成一个判别式模型,对查询和文档的相关性进行判断。排序学习的两个基本特点就是1)基于特征;2)判别式的模型。根据优化目标的不同,排序学习可以分为以下三种主要的方式: 1)Pointwise方式,损失函数主要是优化对于单个文档的预测值和真实值的差。2)Pairwise方式,将排序问题转化预测两对文档之间的顺序问题,一般的Pairwise方式,是对两对文档之间顺序问题做分类,相应的每对文档顺序的分类错误率作为损失函数。3)Listwise方式,一般有两类,一类是针对检索的评价指标比如NDCG做优化。另一类针对非检索评价指标优化,常见的有最小化代理损失函数(SurrogateLossFunction)。本文实验主要使用了经典的基于Pairwise的RankingSVM[10]和基于Listwise的ListNet[11],后者使用的打分函数均为线性。
也有些其他工作[2,12-16]使用LearningtoRank框架来组合微博检索中的多个特征,比如用户权威度、hashtags和转发次数等。文献[15]则认为微博的查询之间并不相同,从而提出一个将一般的排序模型和查询偏向(Query-Biased)的排序模型组合起来的新的排序方法。但是大多数LearningtoRank的方法并没有系统地考虑时间因素对微博排序的影响,因此在微博排序中的时间因素并没有被完全利用。文献[2]提出一种LearningtoRank的方法解决时间敏感的Web检索,但是Web检索和微博检索具有不同的时间敏感性特点,使得针对Web检索的特征并不适用于微博检索。文献[16]在假设用户检索偏向最近和最相关文档的基础上,研究Recency、作者信息等诸多特征,验证了Recency信息在微博检索中的有效性。
综上所述,本文认为时间敏感的微博的检索中,简单直观的假设不能完全概括时间因素对微博检索排序的影响。以往的工作并没有系统的考察时间因素对微博排序学习的影响。本文将验证时间因素影响微博排序的复杂性,并提出使用排序学习的框架去解决时间敏感的微博排序的问题。
3 融合时间信息的微博排序学习方法
本节主要通过微博检索数据集分析微博查询的时间敏感特性,验证时间信息对微博排序的影响是复杂的,难以用一个简化直接的假设进行概括。然后提出使用排序学习框架来组合微博检索中时间特征进行相关度判断的方法。
3.1 微博查询的时间分析
本小节将以TRECMicroblogTrack2011—2012年所发布的110个微博查询标注集合分析微博查询的时间敏感性。微博数据集包含从2011年1月23日到2011年2月7日共17天的数据。将标注答案集合作为查询的相关文档集合,把使用基本检索模型(如查询似然模型)检索得到的前 500篇文档作为伪相关文档集合。为了考察查询对应的相关文档和伪相关文档的时间分布,本文使用与文献[5]相同的方法来观察查询的相关文档时间分布的特性,方法简述如下: 首先将文档集合按照天数划分为17天,然后统计落在每天间隔的文档比率,构成一个文档集合在时间上的概率分布。
为了分析微博查询的时间特性,选取四个不同特点的微博查询为例。分别为: 第17天查询的MB001,对应的查询词是“bbcworldservicestaffcuts”;第10天查询的MB045,对应的查询词是“politicalcampaignsandsocialmedia”;第15天查询的MB060,对应的查询词是“fishingguidebooks”;第17天查询的MB078,对应的查询词是“mcdonaldsfood”。其相关文档和伪相关文档的时间分布图如图1所示。
解读图1的关键是,关注相关文档和伪相关文档时间分布的趋势和在相同时间点相关文档分布比率与伪相关文档分布比率的差距(Gap)。相同的趋势意味着相关文档集合和伪相关文档集合在时间分布上有类似的性质。而差距则意味着,通过检索模型得到的伪相关文档集合需要提高或降低在此时间点的文档的比重,调整召回文档在此时间点的分布概率。子图中,两条时间分布曲线的差距,意味着需要通过将时间因素加入排序模型,使得相关文档和伪相关文档的时间分布趋于一致。这也是对时间敏感的排序模型的直观解释。
从图中可以明显可以看出,1)对于任意给定查询,相关文档和伪相关文档的分布曲线分布趋势比较一致,相关文档集合和伪相关文档集合具有相似的时间特性。2)微博查询相关文档的时间分布曲线不尽相同。对于1),由于给定查询来说,相关文档和伪相关文档具有相似的时间特性,所以对于一个测试集合中查询来说,通过基本的检索模型如查询似然模型得到该查询的伪相关文档集合,其时间特征可以用来近似表征相关文档的时间特征。对于2)来说,从图1可以明显看出,不同查询之间的文档分布不尽相同。
对于查询MB001来说,相关和伪相关文档集合在时间上的分布存在着高峰时期,尤其在第四天,伪相关文档的在高峰时期返回的文档比例显然不足,所以对于基本检索模型返回伪相关文档集来说,应该提高第四天前后文档的返回权重,让高峰时刻的微博的权重更高,排到更高的位置。MB001(“bbcworldservicestaffcuts”)查询的信息需求是,关注在2011年1月底所发生的英国BBC广播电视公司将WorldService中32个世界语言服务中的近1/5关停,并裁员650人的事件的相关信息。当这则新闻发出的时候,大量的关于此事的微博被发送、转发和评论。这解释了第四天相关文档出现高峰的现象。考虑用户的信息需求,用户所关心的显然是此事件相关的信息,所以具有很明确的事件性,应该返回更多高峰时刻附近的文档。
而对于查询MB078,整个相关文档的时间分布比较均匀,和伪相关文档的分布趋势比较符合,但在查询的当天即第17天,相关文档的分布有了突然的提高,但是伪相关文档分布则在17天的返回比率相对不足,这反映了需要提高新文档权重的要求。MB078的查询内容是“mcdonaldsfood”,用户此查询的信息需求是最近的麦当劳食品信息,这就是说用户更偏好新的信息。
而查询MB060,则相关文档和伪相关文档在整个时间分布上比较符合,时间分布也比较均匀,这反映了此查询对时间并不敏感,基于文本相似度的检索模型就能很好地满足用户的信息需求。从另一个角度来看,MB060(“fishingguidebooks”)是一种知识信息的查询,并不具有明显的时间特性。查询MB045,则反映了查询和时间因素更加复杂的关系,没有比较直观的解释。
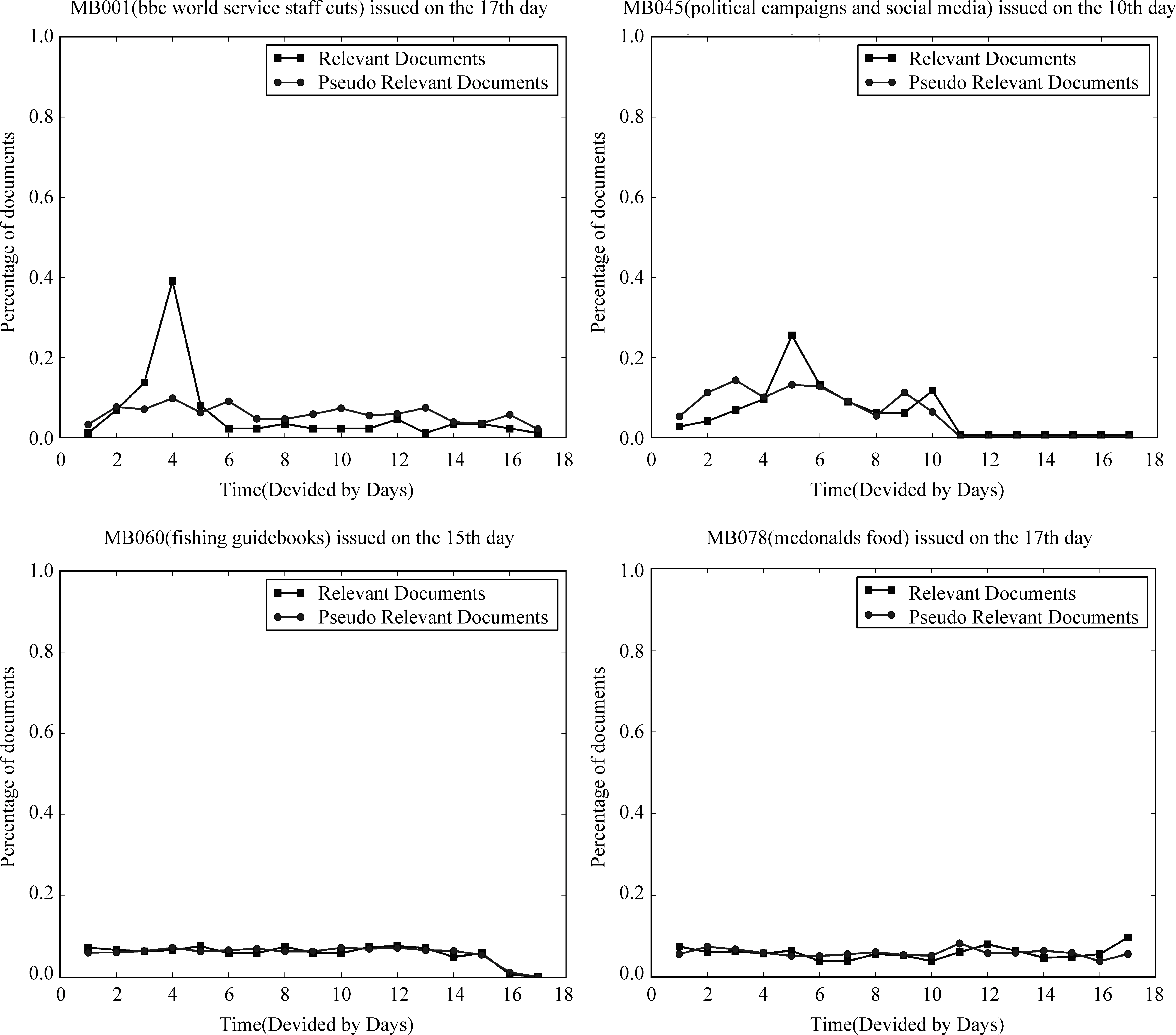
图1 TREC Microblog Track 2011—2012年查询的相关文档时间分布图抽样
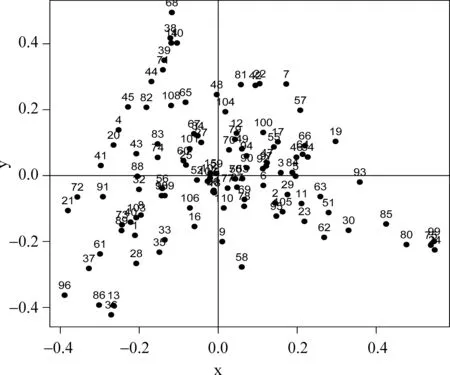
图2 Microblog Track 2011—2012年中所有110个查询的距离分布
进一步地,本文将标注集合的110个查询的时间分布按照KL距离使用多维尺度变换(MDS)技术显示在图2中,从图2中可以看出不同查询的时间分布比较分散,各查询的时间分布并不相同,这说明单一假设的查询时间分布是不准确的。
总结来说,微博检索的信息需求是与时间高度相关的,是一种时间敏感的检索。微博检索的相关文档分布是多样的,时间因素在决定微博检索排序中起到的作用是不尽相同的,很难用一个统一的直观的假设去概括。
对于多特征复杂影响的检索系统,近年来,机器学习和信息检索结合形成的排序学习方法是一个行之有效的解决办法,可以有效地提高检索系统的效果。
3.2 排序学习框架
排序模型一般是在一系列人工标注的查询-文档集合上通过有监督学习(SupervisedLearning)得到的,那么对于线性的打分函数,训练排序模型本质上可以是对某个特征xi决定一个相关系数。对于一个新的文档-查询对(d′,q′)来说,排序模型使用对特征的加权求和来决定文档的相关得分:
(2)
这里N是特征的维度,特征的权重可以直观的显示特征的重要性。如何提取出影响微博排序的时间因素的特征,是排序模型能否有效的关键。
4 特征提取
根据第3节介绍的排序学习的理论,排序学习的基础就是特征的提取,特征提取的好坏是方法成败的关键。针对微博检索来说,所提取的特征主要是以下两大类: 时间特征和实体特征,如表1总结所示。
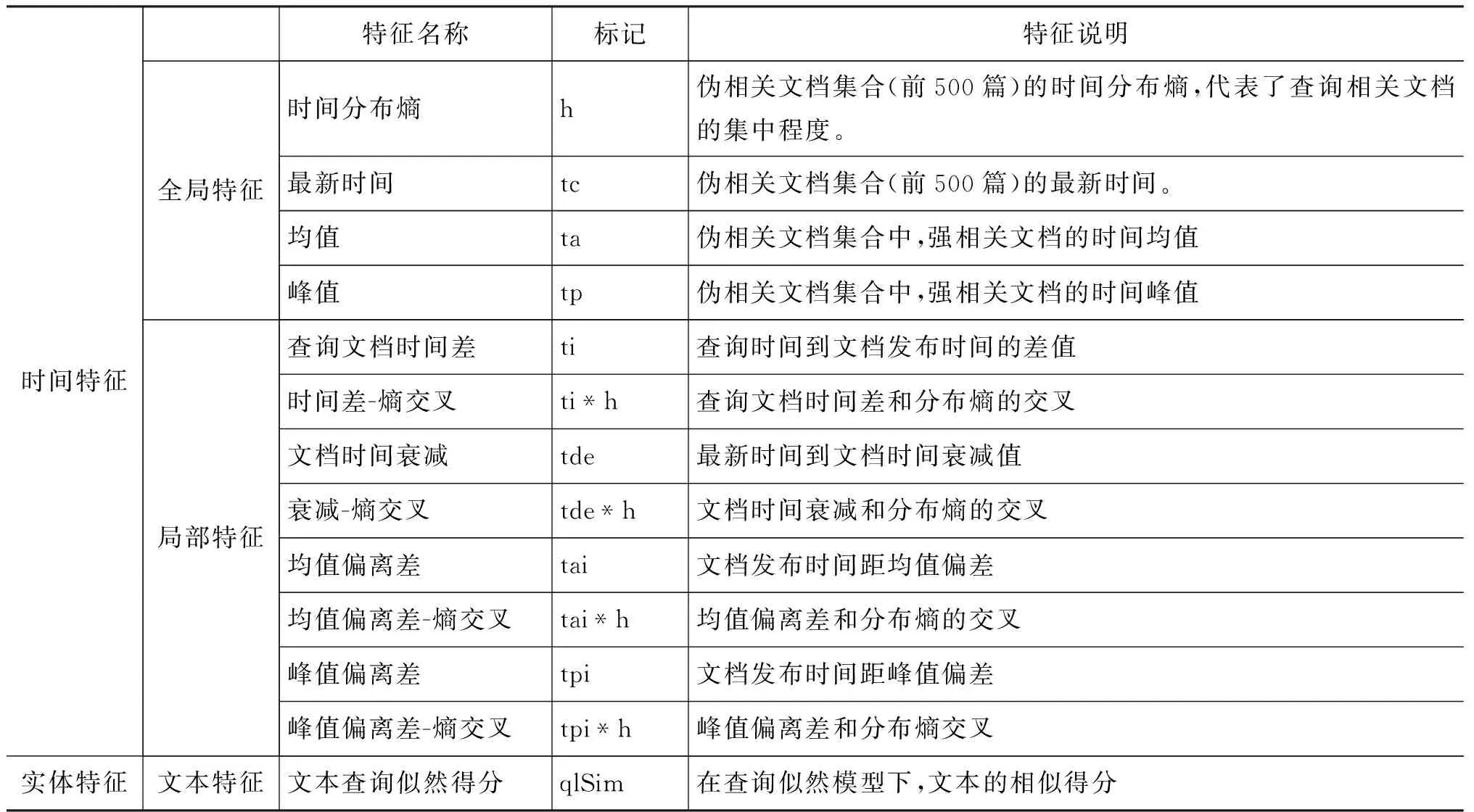
表1 时间敏感的微博检索的特征
4.1 时间特征
在使用排序模型的框架时,一般先使用基本模型得到伪相关文档集合,把伪相关文档集合作为待排序的候选集合,然后对候选集合进行重排序。
对于给定的查询q和候选文档集合D中的候选文档d来说,有些时间特征是只与查询q有关,而与候选文档d的时间特征无关,这类特征,本文称之为全局特征。而另外一些时间特征则与查询q和文档d都有关系,本文称这类特征为局部特征。
4.1.1 全局特征
为了得到查询的全局特征,需要知道查询的相关文档的时间分布特征,而对于一个测试集合中的查询来说,相关文档的分布不可能知道。根据前面的分析和假设: 伪相关文档分布(前500篇)和相关文档分布一致性较好,所以可以使用伪相关文档(前500篇)的特征去近似代替相关文档的总体时间分布特征。
观察图1很容易得出一个特征,就是带有明显事件相关的这类查询的分布相对更加集中些,而没有明显事实相关的查询这分布更加均匀。那么如何衡量分布的集中离散情况呢?这里引入了分布熵的特征:
(3)
这里p(x)(i)代表了文档集合在时间段i的概率。在本文中,使用的是天作为基本的时间段。
均值反应的是整体分布中时间的分布倾向,m表示有文档总数。
(4)
峰值[12]反应了整体分布中最多文档分布的天数,其中c(i)代表了落在时间段i的文档。
(5)
最新时间[10]是指近似相关文档集合中最新的文档时间。
(6)
4.1.2 局部特征:
时间差衡量了查询时间与文档发表时间的差值。定义如下:
(7)
其中tq是查询发生的时间,tdi是文档的时间。ti衡量了查询时间到文档发布时间差。时间衰减定义了查询到文档发布时间的指数衰减[3]。定义如下:
(8)
文档发布时间距离该查询的平均伪相关文档时间为:
(9)
文档发布时间距离该查询热点时刻的时间间隔为:
(10)
th表示该查询所对应的热点时刻。我们通过观察查询得到的伪相关文档和相关文档的分布可以得出,热点时刻分布具有相似性。我们将查询得到的相关文档,按照天数划分,找到该查询所对应的文档分布最多的天数作为热点天数。
在特征的提取和选择过程中,对特征进行交叉组合具有重要的意义,尤其对线性的打分函数有着重要的作用。本文将ti,tde,tai,thi分别和分布熵h进行交叉得到一组新的特征ti*h,tde*h,tai*h,thi*h,如表1所示。
4.2 实体特征
除了使用上面提到的时间特征以外,本文还抽取微博实体特征,目的是衡量查询和微博实体之间的相似度。由于本研究主要是考察微博检索的排序中时间因素的影响,作为对比的其他模型也只能使用相同的文本相似度量。所以本文主要提取了查询似然模型的打分作为文本相似度的度量,即将log (p(Q|MD))记为qlSim。
5 实验及分析
本节将通过实验验证本文所提出的时间敏感的排序学习方法。5.1节描述了实验数据和设置,5.2节展示了实验结果,并对实验结果做了分析说明。
5.1 实验数据和设置
本实验所使用的数据是TREC Microblog Track所发布的2011年1月23日-2011年2月8日共17天的Twitter的数据。去除了非英文的和转发的微博,并对微博内容进行了预处理,比如去除了@信息和网址信息。预处理后的文档集合一共包含9 679 710篇文档。所使用的查询集合是TREC Microblog Track 2011~2012年发布的共110个查询。
本文使用开源的Lemur平台做实验平台,在该平台首先测试了查询似然检索模型(记为QL),并将各查询的前1 500篇文档做为伪相关文档集合,也是后面其他实验的待排序集合。然后测试了Li和Croft的基于时间的语言模型(记为TLM),卫的热点时刻语言模型系列最佳的模型(记为HTLM-AdaptiveMultiML)和本文提出的TLTR模型的对比实验。
本文选择查询似然检索模型作为Baseline,平滑方式选择Jelinek-Mercer。其中实验的所有参数是在P@30指标最优的情况下,使用5折交叉验证的方法选择的。所有参数如表2所示。
本文采用的时间敏感的排序方法主要使用了基于Pairwise的Ranking-SVM和基于ListWise的ListNet。使用TREC Microblog检索常用的两个排序学习框架MAP和P@30作为评价指标。其中P@30反映了检索结果的准确性,MAP衡量了整个检索的结果的质量。

表2 实验最优参数的取值
5.2 实验结果及分析
相关的实验结果如表3所示,我们对本文提出的两个模型TLTR(RankingSVM)和TLTR(ListNet)与基准模型QL进行了Wilcoxon符号秩检验(显著性水平为0.05)。
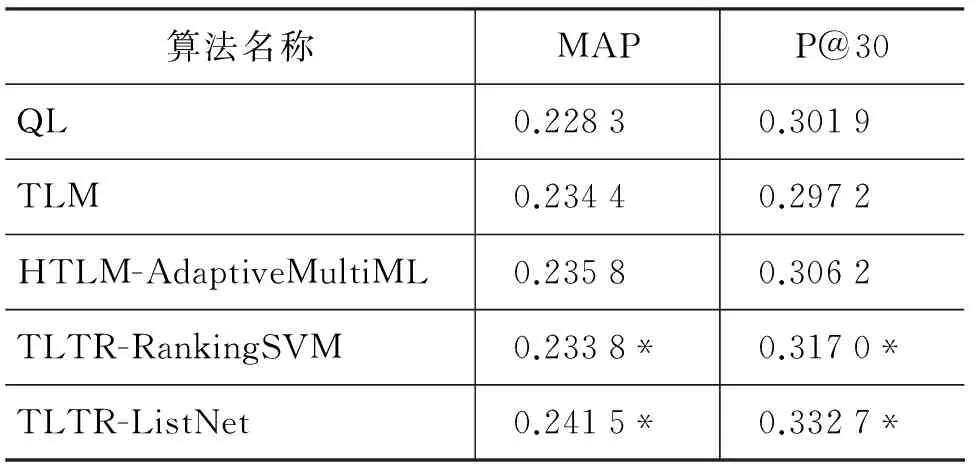
表3 基于时间的排序学习方法的实验结果
从表3中,可以看出融入时间信息到检索过程的TLM、HTLM、TLTR_RankingSVM和TLTR_ListNet,均比基准QL模型无论在MAP还是P@30指标上有提高。以TLM为例,显然融入Recency信息的语言模型使得文档返回质量有所提高,但是由于未正确描述时序影响的规律,P@30这样的指标反而有所下降。这表明在微博检索中,时间信息对排序有作用,但是时间因素对排序的影响是复杂的。
本文提出的TLTR方法在两项指标上比查询似然模型要好,其中效果最好的TLTR(listNet)比基准模型QL在MAP上提高了5.8%, 在P@30指标上提高了10.2%。而且TLTR_ListNet好于基于“时间越新,文档越相关”假设的TLM模型,分别在MAP和P@30上提高了3.0%和11.9%。TLTR_ListNet也好于“越靠近热点时刻,文档越相关”假设的HTLM-AdaptiveMultiML模型,分别在MAP和P@30上提高了2.4%和8.7%。从总的效果提升来看,在指标P@30上比MAP上提升效果更加明显,这说明时间敏感的排序模型排序准确性有很大提高,尤其在真实检索环境中,用户更加关注P@30的指标。
另外基于PairWise的TLTR-RankingSVM 稍逊于基于ListWise的TLTR-ListNet,这与排序学习中一般的Listwise方法考虑了列表整体而比Pointwise和Pairwise的方法效果要好是一致的。
6 总结及未来工作
针对时间敏感的微博查询,如何将微博的时间因素体现在微博检索的排序结果中是本研究的核心问题。在以往的研究中或者将文本相似性和时间相似性加以启发式的组合,或者将时间信息结合在检索的概率模型中,常见的比如定义时间因素为文档的先验。这两种方法都对时间因素影响微博排序的方式做了各种假设: 或者是“时间越新文档越相关”,或者“时间与整个查询的热点时刻越近越相关”。实际上,微博检索中时间因素的影响是比较复杂的,难以用简单直观的假设去具体描述。这就需要我们有一种有力的工具来对时间因素对微博检索的影响建模。本文使用排序学习方法,分析了微博时间检索的影响的不确定性,并且提取了微博查询时间的全局和局部特征,提出了基于时间因素的微博检索排序学习方法,通过在TREC Microblog Track数据集上的实验,证明了本方法的有效性。
在本文的研究过程中,作者也发现了不同类型的微博查询,时间因素对微博排序的影响也不相同,本文提出的各种时间特征也在不同查询中起到了不同的作用。这使得在整体上对特征进行效果分析是不准确或具有误导性的。我们接下来的工作是希望根据不同类型的查询建立一个查询依赖的排序模型,并分析各个时间特征在不同查询的排序中起的作用。对于时间敏感的微博检索也有其他的研究思路,1)在本文中,只使用了文本的发布时间,而实际上,微博中也有指示时间的词语,比如“2日”,“前天”等,这些词语也是对微博的时间的描述,也应该加以考虑。2)在加入时间因素的微博检索的排序学习中,需要进一步挖掘时间特征,或者使用核函数来组合复杂的特征。
[1] Teevan J, Ramage D, Morris M R. TwitterSearch: a comparison of microblog search and web search[C]//Proceedings of the 4th ACM international conference on Web search and data mining. ACM, 2011: 35-44.
[2] Kanhabua N, Nrvåg K. Learning to rank search results for time-sensitive queries[C]//Proceedings of the 21st ACM international conference on information and knowledge management. ACM, 2012: 2463-2466.
[3] Li X, Croft W B. Time-based language models[C]//Proceedings of the 12th international conference on Information and knowledge management. ACM, 2003: 469-475.
[4] Efron M, Golovchinsky G. Estimation methods for ranking recent information[C]//Proceedings of the 34th international ACM SIGIR conference on research and development in Information Retrieval. ACM, 2011: 495-504.
[5] Wei B, Zhang S, Li R, et al. A time-aware language model for microblog retrieval[R]//Report of TREC Microblog Adhoc Track, 2012.
[6] 卫冰洁, 王斌. 面向微博搜索的时间感知的混合语言模型[J]. 计算机学报, 2014, 37(1):229-237.
[7] Miyanishi T, Seki K, Uehara K. Combining recency and topic-dependent temporal variation for microblog search[M]//Advances in Information Retrieval. Springer Berlin Heidelberg, 2013: 331-343.
[8] Efron M, Lin J, He J, et al. Temporal feedback for tweet search with non-parametric density estimation[C]//Proceedings of the 37th international ACM SIGIR conference on research & development in information retrieval. ACM, 2014: 33-42.
[9] Miyanishi T, Seki K, Uehara K. Time-aware latent concept expansion for microblog search[C]//Proceedings of the 8th International AAAI Conference on Weblogs and Social Media. 2014.
[10] Herbrich R, Graepel T, Obermayer K. Large margin rank boundaries for ordinal regression[J]. Advances in neural information processing systems, 1999: 115-132.
[11] Cao Z, Qin T, Liu T Y, et al. Learning to rank: from pairwise approach to listwise approach[C]//Proceedings of the 24th international conference on machine learning. ACM, 2007: 129-136.
[12] Ounis I, Macdonald C, Lin J, et al. Overview of the trec-2011 microblog track[C]//Proceedings of the 20th Text REtrieval Conference. 2011.
[13] Metzler D, Cai C. USC/ISI at TREC 2011: Microblog Track[C]//Proceedings of the TREC. 2011.
[14] Miyanishi T, Okamura N, Liu X, et al. TREC 2011 Microblog Track Experiments at Kobe University[R].
[15] Zhang X, He B, Luo T, et al. Query-biased learning to rank for real-time twitter search[C]//Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, 2012: 1915-1919.
[16] Damak F, Pinel-Sauvagnat K, Boughanem M, et al. Effectiveness of State-of-the-art Features for Microblog Search[C]//Proceedings of the 28th Annual ACM Symposium on Applied Computing. ACM, 2013: 914-919.
Temporal Sensitive Learning to Rank Method for Microblog Search
WANG Shuxin1, WEI Bingjie2, LU Xiao2, WANG Bin3
(1. University of Chinese Academy of Sciences, Institute of Computing Technology, CAS, Beijing 100190, China;2. National Computer Network Emergency Response Technical Team/Coordination Center, Beijing 100029, China;3. Institute of Information Engineering, CAS, Beijing 100093, China)
Microblog search has become a hot research problem in information retrieval area in recent years. Related work shows that most queries in microblog search are time-sensitive. To address this problem, many existing methods were proposed based on different time-sensitive assumptions, such as, “the newer of a document, the more important it is” or “the closer to the peak point a document is, the more important it is”. All these methods have improved retrieval effectiveness somehow. However, it is hard to summarize the temporal role in ranking of microblog search to one straight forward assumption as above. In this paper, our study on temporal distributions of relevant documents of different queries shows the complexity of temporal role in ranking; therefore, simple straight forward assumptions are not accurate. We proposed to use the temporal and entity evidences of query-document pairs to train a time-sensitive learning to rank model to tackle this problem. As for temporal features, both global features of query and local features of query-documents pair are extracted. Experimental results show that TLTR significantly improves the retrieval effectiveness over existing time aware ranking models on TREC Microblog Track 2011—2012 data set.
time-sensitive; learning to rank; microblog search

王书鑫(1985—),博士研究生,主要研究领域为信息检索与数据挖掘。E-mail:wangshuxin@ict.ac.cn卫冰洁(1987—),博士,工程师,主要研究领域为微博检索及数据挖掘。E-mail:weibingjie1986@163.com王斌(1972—),博士,研究员,主要研究领域为信息检索与自然语言处理。E-mail:wangbin@iie.ac.cn
1003-0077(2015)04-0175-08
2014-12-25 定稿日期: 2015-06-18
中国科学院先导专项课题(XDA06030200)
TP391
A
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
小天使·一年级语数英综合(2019年2期)2019-01-10
专利代理(2017年1期)2017-07-21
电脑爱好者(2017年7期)2017-05-06
