
基于多层次语言特征的弱监督评论倾向性分析
2015-04-21 08:17王世泓
中文信息学报 2015年4期
牛 耘,张 黎,王世泓,魏 欧
(南京航空航天大学 计算机科学与技术学院,江苏 南京 210016)
基于多层次语言特征的弱监督评论倾向性分析
牛 耘,张 黎,王世泓,魏 欧
(南京航空航天大学 计算机科学与技术学院,江苏 南京 210016)
该文提出一种基于多层次语言特征的弱监督的情感分析方法, 先以少量情感词构成初始情感词典,用这些种子词汇作引导,根据评论文本在单词、短语及句子级别的语言特征结合上下文挖掘目标文本中潜在的具有情感倾向的词汇/短语。通过自训练不断扩充情感词典,最终得到一个具有领域特征的情感词典,并用所得到的情感词典对目标文本的情感倾向进行判断。与其他方法在同一数据上的结果相比,该方法以很小的词典规模取得了最高的F-score,并且得到的情感词含义明确。方法用于不同领域也取得了较高的精度,表明方法具有较好的领域适应性。
情感分析;多层次语言特征;弱监督算法;情感词典
1 引言
随着互联网对人们的生活习惯和生活方式日益深刻的影响,越来越多的人开始通过网络表达自己的观点。人们通过论坛、博客等网络平台发表自己对商品和服务的看法,这些看法常常带有情感倾向性(表示对该产品或服务的支持或反对)。分析这些评论文本的情感倾向对于总结产品的优点与不足,了解用户需求进行消费市场分析,以及预测未来市场需求,提高商业智能发挥着重要的作用。
情感分析(Sentiment Analysis)的主要任务即为自动识别评论的主观情感倾向性,判定出作者对于所评价事物的态度是积极的还是消极的。情感分析因其广泛的应用价值已成为自然语言处理领域的热点研究方向。
情感分析研究的两种基本策略为基于语料的方法和基于词典的方法。基于语料的方法以监督算法为主[1-6],在训练数据充足时能够取得较高的精度。而基于词典的方法则通常不依赖于特定领域的人工标注语料[7-9],因而对不同领域的适应性较好。采用基于词典的方法进行情感分析需要解决两个核心问题:(1)如何获取高质量的情感词(具有情感倾向的词)形成情感词典;(2)情感分析时如何利用上下文信息作出准确的判断。在网络高度发达的今天,评论领域以及评价对象的多样性决定了很难有一个固定的情感词典能够满足各种需求。动态产生适应领域特点的词典才能更好地应对这种多样性。另外,同一个情感词与不同的上下文结合会表达不同的情感倾向。合理地考虑上下文的影响对于准确判断评论的情感倾向是至关重要的。基于词典的方法需要显式地利用这种影响。因此,如何有效发挥上下文的作用成为基于词典方法的另一个难点。
本文提出一种基于词典的情感分析方法,通过结合上下文信息构造具有领域特征的情感词典,并利用不同层次的语言特征进行中文评论的情感倾向判断。
本方法仅需少量的表达情感的词汇(情感词)构成初始情感词典。然后以这些种子词汇作引导,根据评论文本在单词、短语及句子级别的语言特征,通过一些简单规则描述上下文的作用,进一步挖掘目标文本中潜在的具有情感倾向的词汇/短语。并通过自训练不断扩充情感词典,动态地产生一个具有领域特征的情感词典。然后用所得到的情感词典对目标文本的情感倾向进行判断。在手机数据上的实验表明,本方法取得了高于之前最好结果的F-score。将方法应用于不同领域产品中也取得了较高的精度,表明方法具有较好的领域适应性。并且,算法产生的具有领域特征的情感词典将有助于产品特征的提取和进行针对具体产品特征的评价分析。
2 相关工作
情感分析研究至今已取得了很大的进展。算法方面,基于语料的有监督算法尽管取得了较高的精度,然而其对人工标注数据的依赖给它在不同领域的应用带来困难。因此,基于词典的无监督和弱监督方法也成为情感分析的重要途径。
作为较早期的基于词典的无监督方法,Turney提出了基于PMI-IR算法的语义情感分类思想[7]。分别以正向和负向的两个代表情感词“excellent”和“poor”为种子,根据目标短语与这两个种子词汇之间的互信息来判断该短语的情感倾向,并最终判定出整篇文章的情感倾向。该方法需要大规模语料库的支持。Hu 和 Liu[10]则通过人工方式构建了一个包括30个形容词的初始情感词集合,然后利用这些种子在WordNet中的同义和反义集合来预测更多形容词的情感倾向。Zagibalov和Carroll则提取出文本中的否定副词结构来自动产生种子集合[8]。Ye等针对中文的特点,在PMI-IR方法基础上,探索了中文情感分析理论与方法[11-12]。
另外,一些弱监督算法试图通过结合情感词典与标注语料来弥补二者单独使用的不足。其中有些算法将词典与少量人工标注的评论文本结合起来产生情感倾向的分类器[13-14]。还有一些算法的情感分析过程分为两个阶段,首先利用情感词典完成对评论文本倾向的初始判断,然后利用其中比较可靠的结果来产生新的分类器对初始结果进行修订[15-16]。
与本文最相近的工作为Zagibalov和Carroll提出的弱监督评论分析[8-9]以及Qiu等的自监督模型[15]。这二者工作中也利用自训练方式产生情感词典。然而,二者在产生情感词时均未考虑上下文的影响。并且,在二者的工作中,构成情感词典的词条不是具有明确含义的中文词,而是采用评论文本中n个连续的汉字(不包含标点)。因而生成的词典对于理解应用领域的情感表达方式帮助甚微。与他们不同,本文采用意义明确的中文词作为情感词典的候选词。构建词典时,结合直接影响情感判断的上下文形成最终的情感词。这样产生的情感词典既有助于理解特定领域的情感表达特点,也有助于后续产品特征的提取和进行针对具体产品特征的评价分析。本文还从单词、短语、句子多个层次综合考虑上下文的作用来提高情感倾向判断的精度。
3 方法概述
3.1 主要模块
本文所建立的情感倾向分析模型以少量表达情感的词为种子建立初始情感词典,然后通过自训练,以迭代的方式不断扩充情感词典最终完成对评论文本的情感倾向判断。模型主要包含四个模块: 数据预处理模块,识别候选词/短语模块,情感词典更新模块,和情感倾向分析模块。系统整体结构如图1所示。下面先简要介绍每个模块的主要功能,第4节进行了详细的阐述。
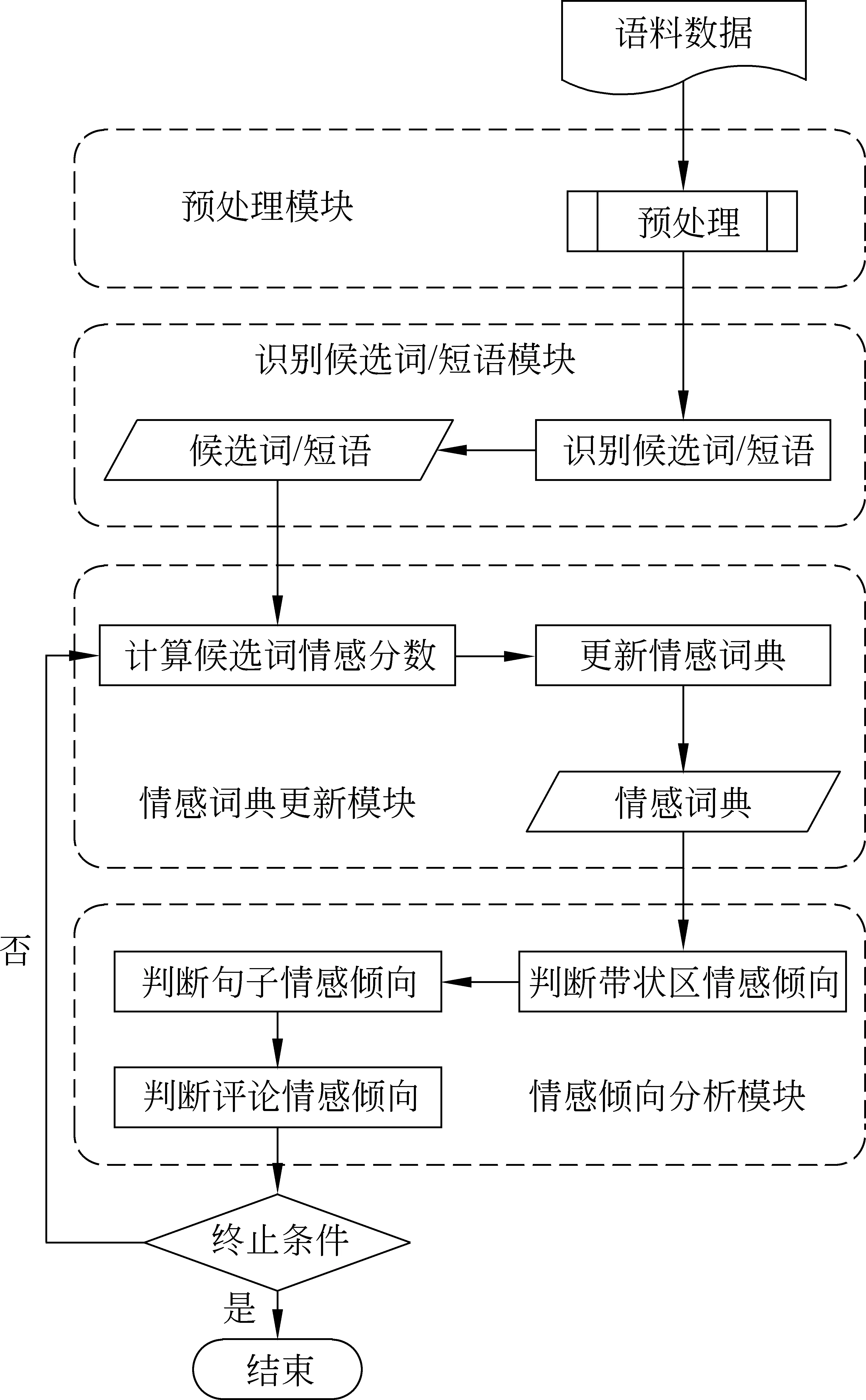
图1 系统结构图
1. 数据预处理。对评论进行分词、词性标注、划分带状区等预处理。
2. 识别候选词/短语。候选词/短语是指可能成为情感词的词/短语。根据候选词提取算法,从评论文本中选择合适的词或短语作为候选词/短语。候选词/短语进一步处理后可产生用于判断情感倾向的情感词。
3. 情感词典更新。单词(短语)根据其表达的情感可分为正向情感词或者负向情感词。情感词典是所有情感词的集合。为了判断一个候选词是否适合作为情感词,首先要计算它的情感分数来衡量该词所表达的主观色彩强度。情感分数绝对值越大表明主观色彩越强。情感色彩强烈的候选词将被选择作为情感词,以迭代的方式更新词典。每次迭代后的词典会用来进行情感倾向判定。
4. 情感倾向分析。首先根据情感词典判断一个句子中的带状区的情感倾向。然后由该句中所有带状区的情感倾向判定出该句子的情感倾向。最后由评论所包含所有句子的情感倾向判定出整篇评论的情感倾向性(积极或消极)。
下面一节对这四个模块进行详细介绍。
4 基于多层次语言特征的评论情感倾向分析
4.1 数据预处理
在预处理阶段,首先用分词工具对评论文本进行分词和词性标注。然后利用评论中的标点符号*所用标点符号包括: 逗号,分号,问号,感叹号,省略号,句号及对应的英语标点。为分隔符将一个句子划分成多个带状区。每个区域为评论分析的最小单位。
4.2 识别候选词/短语
构成评论文本的词中很大一部分并不参与情感的表达(如数词、介词等通常都不表达情感)。如果简单地把评论中的全部词都作为候选词,不仅会因保留大量无情感色彩的词而给后续的情感词识别带来严重的噪音干扰,而且这些无情感色彩的词会严重消耗算法的执行时间而直接影响系统的效率。因此,这里先从评论文本中识别可能表达情感的词和短语作为情感词的候选词。
我们从词性和上下文的作用两个方面提取候选词/短语。不同词性的词在表达情感倾向中的重要性是不同的。我们将词性作为识别候选词的一种依据。另外,同一个词与不同的上下文结合会表达不同的情感倾向,孤立地分析词语的情感倾向性很多时候并不能准确地把握该词在一个具体评论中发挥的作用。因而,在词情感倾向分析的基础上,联合能够对情感倾向产生影响的上下文形成短语,进而对短语的情感倾向作出判断,将有助于整个评论的情感分析。
本文根据评论文本的特点,对词性特征以及上下文特征进行分析来提取候选词/短语。上下文特征包括否定用法特征(分为否定词和“不”短语两种),趋势词特征以及状态词特征。
1. 词性特征
能够表达情感倾向的有形容词、副词、动词、名词等,而数词、连词、介词、量词等含有的情感信息较少。Rebecca[17]通过统计发现含有形容词或者副词的句子表达倾向性的概率达到55.8%,说明形容词和副词是表达情感的重要词语。因此,我们把评论文本中的形容词(如清晰、轻便、不错)和副词(如顺手、刚好、最好)选为候选词。
2. 结合否定词构成候选短语
我们发现一些词本身虽然没有情感色彩,然而与否定词搭配时表现出明显的情感倾向,如表1所示。
常见否定词有:没、没有、避免、免去、不是、不会、不算、不太、无。否定词的词性一般为动词,并和它的宾语(通常是名词)一起表达肯定或否定的态度。注意到与其他网络用语类似,网络评论往往采用比较简洁的语言。表现在否定词作为动词时一般只带有直接宾语,而双宾语的情况比较少见。我们据此制定否定词构成候选短语的规则:当前区域中没有形容词或者副词时,选择否定词和它最近邻名词结合起来,作为一个候选短语。

表1 否定词构成候选短语
3. 由趋势词构成候选短语
有些情况下,情感倾向并非由某个词直接表达,而是通过描述某种变化反映出来。例如,增加正(负)向情感则整体上仍表达正(负)向情感,而若减少正(负)向情感则整体表达了负(正)向情感,如表2中例子所示。增/减趋势词即是表示增加或减少的动词,包括增加、 减少、 防止。

表2 趋势词构成候选短语
一个带状区中增减性词语的词性经常是动词,与最近邻名词结合表达出明显的情感倾向。我们指定趋势词构成候选情感短语的规则为: 当前区域中没有形容词或者副词时,选择趋势词和它的最近邻名词结合起来,作为一个候选短语。
4. 由状态词构成候选短语
有些描述事物状态的形容词和副词本身不表达情感,然而用于特定上下文中与其修饰限制的对象组合起来则表达了鲜明的肯定或否定情感。我们把这些词称为状态词。表3给出了例子。

表3 状态词示例

续表
形容词性的状态词通常修饰的是最近邻的名词。因而,若一个状态词为形容词,则将该状态词与最近邻的名词结合起来,作为一个候选短语。副词性的状态词经常修饰最近邻的形容词。因此,若一个状态词为副词,将它和最近邻的形容词结合起来,作为一个候选短语。
常见状态词如表4所示。

表4 状态词列表
5. “不”构成候选短语
“不”是表达否定,能对评论情感起到反转作用的重要用词。和前述否定词构成候选短语中的否定词不同,“不”一般作为否定副词出现。它常被用来修饰它的右邻接词,对右邻接词的情感倾向起到反转的作用。如表5所示。

表5 “不”对修饰成分的情感倾向反转
基于这种观察,我们将“不”与其否定的对象结合形成候选短语:
1) 如果带状区中出现单独成词的"不"字,取其右邻接词,将两者结合起来作为一个候选短语。
2) 当“不”的右邻接词为前述状态词时,应先提取状态词构成的候选短语,再与“不”结合形成最终的候选短语。
最后,提取在语料中出现两次以上的上述词/短语作为最终的候选词/短语。
4.3 情感词典更新
初始情感词典由所选择的全部种子词汇构成。在第一次迭代中,利用初始情感词典对评论的情感倾向进行判断。然后根据判断的结果对所有候选词/短语的情感分数进行计算,并根据计算结果更新词典。下一次迭代中,更新后的词典被用来进行新一轮的情感倾向判断。如此,随着迭代次数的增加情感词典被不断更新,直至达到迭代终止条件时得到最终版本的词典。词典更新分三个主要步骤完成。
1. 初始情感词典建立
本文提出从情感倾向性和出现频率两个方面来约束种子词汇的选择。首先,一个种子词必须有明确的情感倾向。其次,表达积极情感的种子词汇在评论中的总频率与表达消极情感的种子词汇总频率应该相当。
2. 情感分数计算
对于一个候选词/短语,首先判断它是否表达了某种(正向/负向)情感。具有情感倾向的候选词/短语才会被选作情感词/短语。如果一个词出现在正向(负向)评论中的次数大于它出现在负向(正向)评论中的次数,那么它可能表达正向(负向)情感。在正负评论中出现的频率差别越大,该词的情感色彩越强。 候选词/短语的情感倾向用情感区分度来衡量,如式(1)所示。
(1)
其中,Fp表示该候选词出现在表达正向情感的评论中的频率;Fn表示其出现在表达负向情感的评论中的频率。
Difference的值越大表明候选短语的情感色彩越强。本文设定difference的阈值为1。当difference< 1时,表明该词/短语情感色彩太弱,在识别评论的情感倾向时作用不大,因而不选择作为情感词。否则选择该词/短语为情感词并按如下公式计算其情感分数。
若Fp>Fn,则
(2)
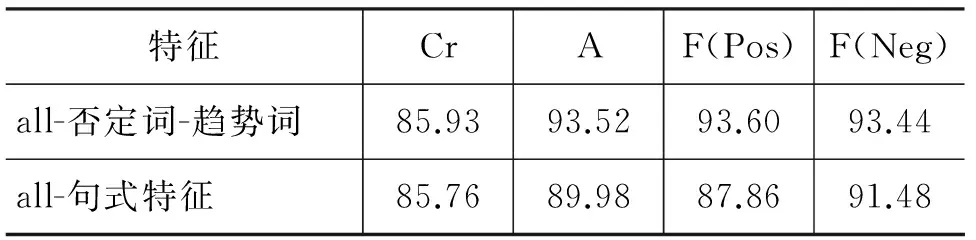
若Fp (3) 3. 情感词典更新 依据候选词/短语的情感区分度difference和情感词/短语的情感分数计算结果,按照以下步骤对情感词典进行更新。 a) 当候选词/短语的difference值满足阈值条件时,候选词/短语成为情感词并计算其情感分数。如果情感词典已包含该情感词,直接更新其情感分数。否则,将该情感词和它的情感分数添加到情感词典。 b) 当候选词/短语的difference值不满足阈值条件时。检查该词/短语是否存在于情感词典中,如果存在则从情感词典中删除该词/短语。 4.4 情感倾向分析 一篇评论的情感倾向取决于它所包含句子的情感倾向,而一个句子的情感倾向又取决于它包含的带状区的情感倾向。 句子分为单句和复句,单句又分为疑问句、感叹句等;复句又分为转折复句、假设复句、条件复句等。由于句式和句型能够直接影响句子的情感表达,本文在判断带状区和句子的情感倾向时进一步考虑了句式和句型特征。下面详细阐述了评论情感倾向的判断过程。 4.4.1 带状区的情感倾向判断 根据带状区中包含的情感词/短语个数判断该区域的情感倾向。如果积极的情感词/短语个数大于消极的情感词/短语个数,则判断该带状区表达积极情感。反之则该区为消极的。若二者数目相同或该区不包含情感词,则该区为中性。特别的,如果带状区中出现以下情况则结合相应规则进行判定。 1. 否定词修饰 虽然在提取候选短语时考虑了否定词的影响,但仍存在否定词未被包含在候选短语中的情况。针对这种情况,在判断带状区的情感倾向时制定如下规则: 没有构成候选情感短语的否定词对其所在带状区域中最近邻的候选情感词起到情感反转作用。 2. 表示希望、愿望的句式 评论中对期望、希望或者愿望的表达常常意味着对目前产品状况的不满意,如表6所示。 表6 表示愿望的句式 常用来表示愿望的句式有: “要是…就好了”、“如果…就好了”,“加入…就好了”、“希望…”“应…”、“应该…”以及“最好…”。 当带状区采用表达愿望的句式时,则不需统计该区内部情感短语的个数,而直接判断整个带状区的情感倾向为消极的。 3. 表示遗憾、失望的句式 以“哪怕”和“宁愿”开头的区域常常表达消极情感。例如, 宁愿拿着1000元的手机+4000元的PDA也不要这破玩意。 哪怕有个MP3功能也算值了。 当带状区采用表达遗憾、失望的句式时,处理方式如下: 对于以“哪怕”或者“宁愿”开头的区域,不需统计该区域内部情感短语的个数,而直接判断整个带状区的情感倾向为消极的。 4.4.2 句子的情感倾向判断 一般情况下,句子的情感倾向取决于该句所包含的所有带状区的情感倾向。当积极带状区个数大于消极带状区域的个数时,判断该句子的情感倾向是积极的;反之该句是消极的。若二者数目相同或句子不包含具有情感倾向的区域,则该句为中性。 一类需要特殊处理的句子是采用转折句型的句子。转折句型包含两个分句,常见句式有: “虽然…但是…”,“…,不过…”。当一个句子是转折句型时,整个句子的情感倾向常常取决于第二个分句,如表7所示。 表7 转折句式 因此,对于转折句型的句子只根据第二个分句所包含的带状区的情感倾向判断该句的情感倾向,即将前述句子判定规则仅用于第二个分句中。 4.4.3 评论的情感倾向判断 一篇评论的情感倾向由其包含的所有句子的情感倾向决定。当表达积极情感的句子的数量大于消极句子的数量时,评论的整体情感倾向是积极的。反之评论是消极的。若两者数目相同,或评论中不包含具有情感倾向的句子时,表示评论的情感倾向是中立的。 4.5 迭代终止条件 当两次迭代后评论情感倾向的变化率低于阈值时终止迭代。 实验中采用中国科学院计算技术研究所的ICTCLAS分词系统[18]对评论文本进行分词及词性标注。 5.1 数据集 第一个测试数据集是IT168网站上对手机产品的评论,包括2 317篇评论*由[6]提供: http://product.it168.com.。其中积极评论和消极评论的数目分别为1 159和1 158篇。为了评估弱监督迭代算法对于不同领域的适应性,本文选取对数码相机的评论作为第二个数据集。本文作者在淘宝网上随机抽取对数码相机的评论并对其情感倾向进行了人工标注。共标注800条评论,其中400篇为正向评论,400篇为负向评论。表8列出了实验数据集。 表8 实验数据集 5.2 手机数据集上的实验结果分析 表9为本文的弱监督迭代算法在手机数据上测试,对于积极评论的判断结果*按照在评论中出现频率相当的情感词作为种子的原则,选择的种子包括: “好”,“差”、“不好”和“不支持”。。 表9 手机积极评论实验结果 No: 迭代次数;Cr: 覆盖率; A: accuracy; P: precision; R: recall; F: F-score; Dict:词典中的情感词数量 表中覆盖率(Cr)是指通过迭代算法判断出积极和消极的评论篇数总和与数据集中评论总数的比值。第一次迭代使用种子词对评论情感倾向进行判断,覆盖率仅达到39.1%。判断的准确率为84.88%,精确率和召回率分别为80.09%和84.96%。随着迭代次数的增加,情感词典不断被扩充,覆盖率随之上升,迭代结束时达到86.28%。从表中可以看到,迭代过程中情感倾向判断的准确率、精确率和召回率都获得了提高,最终取得93.65%的准确率,F-score达到93.61%。 我们将本方法与现有其他方法在上述手机数据集上的结果进行了比较,如表10所示。 表10 方法比较(手机积极评论) 在词典规模上,文献[9]中的词典包括22 530个情感词条。文献[8]和[15]中未提及最终的情感词条数,然而他们采用了与文献[9]完全一样的候选词汇项。注意到文献[15]中仅种子词就有8 937个。而本文方法产生的词典包含759个情感词条,仅为文献[9]的3.4%。利用如此小规模的词典,本方法取得了高于其他方法的F-score。综合来看,本文基于多层次语言特征的弱监督算法以很少的种子词汇作为引导,经过较少的迭代次数取得了最高的精确率、召回率和F-score。 在表10所列的方法中,只有本文采用有明确意义的中文词,并结合上下文产生候选短语,进而得到情感词。其他三种方法所建立的情感词典均只包含词汇项(lexical item)。一个词汇项为不包含标点符号的n个连续汉字。采用这样的词汇项存在两个问题。第一,产生的情感词条很多没有明确的语义,因而很难对理解特定领域的情感表达方式有所帮助。第二,在一篇评论的所有词汇项中,存在着很多无意义的元素。在迭代过程中可被看成是噪音数据,严重影响着整个系统的性能。如表10所示,文献[9]从2 137篇评论中产生的情感词条数为22 530,这些情感词条还只是参与迭代的全部候选词汇项的子集。而候选词的规模直接影响到算法的运行效率。并且,自训练法是从目标文本中生成情感词典,因而随着目标文本数量的增加,候选词规模对算法效率的影响会更加显著。而采用本方法产生的参与整个迭代过程的候选词一共只有1 279个。表11分别列出了词汇项(lexical item)和本文方法产生的最终情感词的例子。从表中可以看出本方法所得到的情感词典更有助于理解领域相关的情感表达方式以及进一步针对产品特征进行更加细致的情感倾向分析。 表11 n-元词汇项与情感词示例 本方法用于手机数据,对消极评论的判断结果如表12所示(由于覆盖率和准确率与表9中相同,这里不再重复)。 表12 手机消极评论实验结果 如表12所示,经过迭代算法最终对于消极评论也取得了与积极评论相当的F-score,为93.68%。 5.3 淘宝数码相机数据集上的实验结果分析 表13和表14分别给出了本文算法在数码相机数据集中积极和消极评论上的实验结果*种子词包括: 不错,清晰,佳,便宜,很快,差,假,坏,不好,高价,失望,模糊。。 表13 数码相机积极评论实验结果 表14 数码相机消极评论实验结果 如表13、14所示,本文方法在数码相机数据上也取得了较高的准确率(89.72%),覆盖率达到88.75%。随着迭代次数的增加,情感词个数逐渐增多。第三次迭代后积极评论和消极评论都取得了最高的F-score。迭代四次后,更多的候选词被判定为负向情感词。负向评论的召回率因此有所上升但其精确率有所下降而导致F-score稍有下降。总体来说,对积极评论和消极评论均取得了较高的F-score。表明方法对不同领域有着较好的适应性。 5.4 不同特征集合的实验结果分析 本文从多个层次提取了语言特征用于识别情感倾向。为进一步了解各种特征在情感识别中的作用,我们对不同特征组合的结果进行了分析。实验表明有些特征,如“状态词”对全局产生影响。如果不考虑 “状态词”特征会导致全部评论被判定为消极。表明由状态词产生的候选短语对于情感识别发挥了重要的作用。而去除“趋势词”和“否定词”以及表达句式的特征都会导致识别精度的降低。相对而言,表达句式的特征的去除使得精度下降更大。表15显示了去除这两组特征后在手机数据上的情感分析结果。 表15 不同特征组合在手机数据上的实验结果 续表 all: 全部特征 F(Pos):积极评论的F-score F(Neg):消极评论的F-score 为了解导致评论的情感倾向误判的主要原因,我们从情感词选择和情感倾向判定规则两个方面对被误判的评论进行了错误分析。分析表明,情感词选择错误主要有两个方面。一是副词的错误较多,很多不带有情感倾向的副词被选作了情感词,例如,“太”,“确实”,“尽量”,“非常”等。在下一步的工作中应考虑对副词进行专门的分类处理。二是有些带有情感倾向的词未被选出,例如,“好听”,“尴尬”,“失真”等。情感倾向判定规则方面,一个重要原因是对否定用法的处理不够全面。评论中表达否定的方式非常多样,给制定全面、准确的否定规则带来困难。一些否定的例子如下: 就不怎么爽了;不能使用;效果不如WAV;就是听不见声;铃声不够大。因而需要制定更细致的规则以适应各种否定的表达方式。 本文提出基于多层次语言特征的弱监督的情感分析方法进行中文评论的情感倾向判断。该方法仅需少量的情感词作引导,根据评论文本在单词、短语及句子级别的语言特征结合上下文动态地产生一个具有领域特征的情感词典。然后用所得到的情感词典对目标文本的情感倾向进行判断。实验结果表明了方法的有效性。与现有其他方法在同一数据上的结果相比,本文方法以很小的词典规模取得了最高的F-score。方法用于不同领域的数据也取得了较高的精度,表明方法具有较好的领域适应性。并且,方法产生的具有领域特征的情感词典有助于进一步提取产品特征和进行针对具体产品特征的评价分析。 目前方法中种子情感词的选择仍需人工干预,下一步的工作将致力于寻找有效的自动选择种子词汇的途径。另外,还将探讨规则中用到的特殊词汇如状态词等的自动获取方法。 [1] Bo Pang, Lilian Lee. A sentiment education: Sentiment analysis using subjectivity summarization based on minimum cuts[C]//Proceedings of the 42nd Meeting of the Association for Computational Linguistics. 2004. [2] H Yu, V Hatzivassiloglou. Towards Answering Opinion Questions: Separating Facts from Opinions and Identifying the Polarity of Opinion Sentences[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing. 2003. [3] Wang S, Manning C D. Baselines and Bigrams: Simple, Good Sentiment and Topic Classification[C]//Proceedings of the 50th Meeting of the Association for Computational Linguistics. 2012: 90-94. [4] 傅向华,刘国,郭岩岩,郭武彪.中文博客多方面话题情感分析研究[J].中文信息学报,2013,27(1): 47-56. [5] 王志昊,王中卿,李寿山,李培峰. 不平衡情感分类中的特征选择方法研究[J]. 中文信息学报,2013,27(4): 113-118. [6] 谢丽星,周明,孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报,2012, 26(1):73-84. [7] Turney P D.Thumbs up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Proceeding of Association for Computational Linguistics 40th Anniversary Meeting. 2002:1417-1424. [8] Zagibalov T, J Carroll. Automatic Seed Word Selection for Unsupervised Sentiment Classification of Chinese Text[C]//Proceedings of Coling-08,2008:1073-1080. [9] Zagibalov T, J Carroll. Unsupervised classification of sentiment and objectivity in Chinese text[C]//Proceedings of the 3rd International Joint Conference on Natural Language Processing (IJCNLP), Hyderabad, India, 2008:304-311. [10] M Hu, B Liu. Mining Opinion Features in Customer Reviews[C]//Proceedings of the Association for the Advancement of Artificial Intelligence(AAAI), 2004:755-760. [11] Ye Q, Lin B, Li Y J. Sentiment Classification for Chinese Reviews: A Comparison between SVM and Semantic Approaches[C]//Proceedings of the 4th International Conference on Machine Learning and Cybernetics ICMLC2005(IEEE). 2005,4(8):2341-2346. [12] Ye Q, Shi W, Li Y J. Sentiment Classification for Movie Reviews in Chinese by Proved Semantic Oriented Approach[C]//Proceedings of the 39th Annual Hawaii International Conference on System Sciences. 2006. [13] Li T, Zhang Y, Sindhwani V. A non-negative matrix tri-factorization approach to sentiment classification with lexical prior knowledge[C]//Proceedings of the joint conference of the annual meeting of the association for computational linguistics and the international joint conference on natural language processing of the asian federation of natural language processing (ACL-IJCNLP). 2009: 244-252. [14] Melville P, Gryc W, Lawrence R D. Sentiment analysis of blogs by combining lexical knowledge with text classification[C]//Proceedings of the 15th ACM SIGKDD conference on knowledge discovery and data mining(KDD). 2009: 1275-1284. [15] Qiu L, Zhang W, Hu C, et al. Selc: A self-supervised model for sentiment classification[C]//Proceeding of the 18th ACM conference on information and knowledge management(CIKM). 2009: 929-936. [16] He Y, Zhou D. Self-training from labeled features for sentiment analysis[J]. Information Processing and Management, 2011, 47: 606-616. [17] Rebecca Bruce, Janyce Wiebe. Recognizing Subjectivity: A Case Study in Manual Tagging[J]. Natural Language Engineering, 1999, 5(2):1-16. [18] 刘群,张华平,俞鸿魁,程学旗.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8):1421-1429. Weakly Supervised Sentiment Analysis Based on Multi-level Linguistic Features NIU Yun, ZHANG Li, WANG Shihong,WEI Ou (School of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics,Nanjing, Jiangsu 210016, China) In this paper, a weakly supervised sentiment analysis approach is proposed. A few words are collected to construct an initial sentiment lexicon. These seed words are used to mine potential sentimental words in the target text. In this process, linguistic features at multi-levels are explored and the role of the context is examined. The lexicon is expanded iteratively, and the final version is applied to classify the sentiment of a target document. Compared to results of previous studies on the same data, this approach achieves the best F-score while the constructed sentiment lexicon is rather small. The experimental results also show that this approach is robust when applied to a texts of different domains. sentiment analysis; linguistic features; weakly-supervised method; sentiment lexicon 牛耘(1974—),博士,副教授,主要研究领域为自然语言处理,情感分析,生物信息文本挖掘。E-mail:yniu@nuaa.edu.cn张黎(1984—),硕士,主要研究领域为自然语言处理,情感分析。E-mail:julianazhang@aliyun.com王世泓(1990—),硕士,主要研究领域为自然语言处理,情感分析。E-mail:wsh_014@nuaa.edu.cn 1003-0077(2015)04-0080-09 2013-07-21 定稿日期: 2013-12-29 国家自然科学基金(61202132);教育部高等学校博士学科点专项基金(20103218120024);中央高校基本科研业务费专项资金(NS2012073) TP391 A

5 实验结果与分析
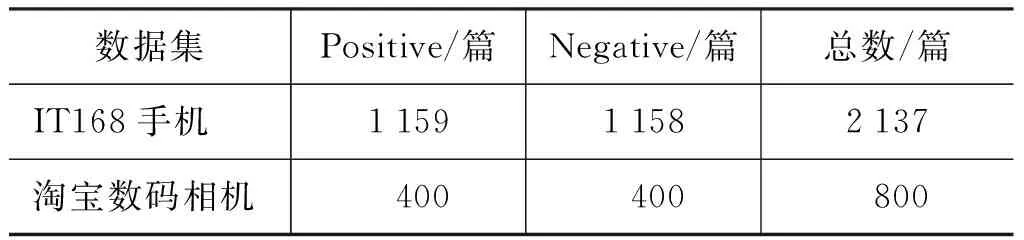

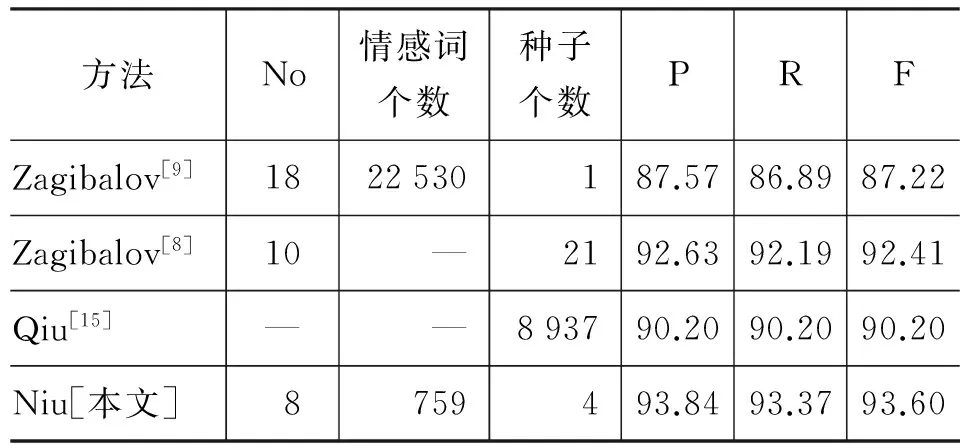

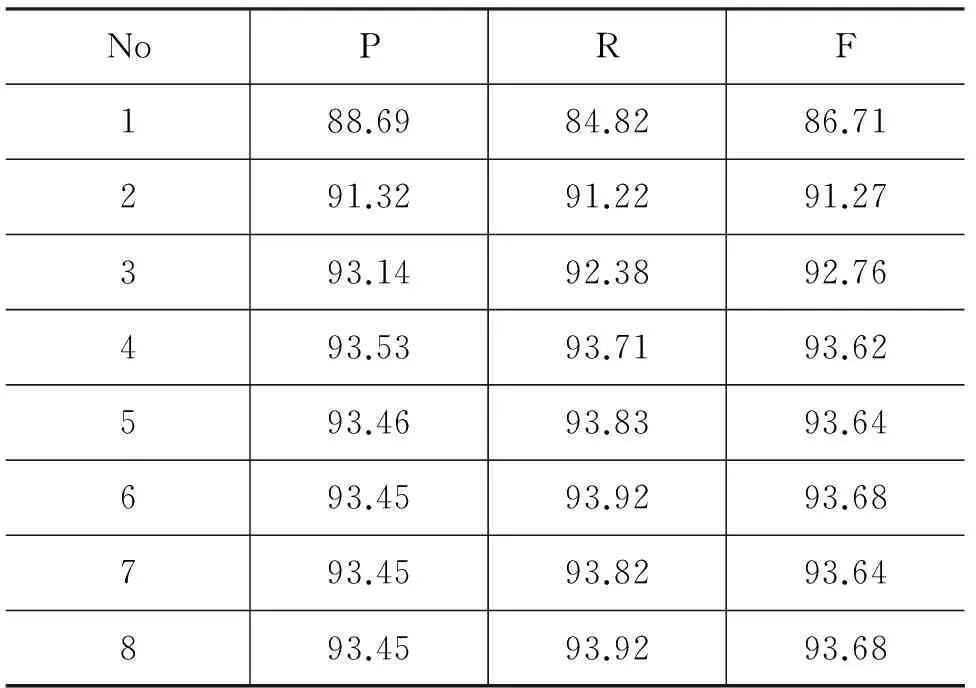



6 总结

猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
当代陕西(2019年10期)2019-06-03
海峡姐妹(2016年2期)2016-02-27
中关村(2014年5期)2014-05-15
阅读(中年级)(2009年11期)2009-04-14
