
基于翻译模型的查询会话检测方法研究
2015-04-21 08:17张振中韩先培
中文信息学报 2015年4期
张振中,孙 乐,韩先培
(中国科学院软件研究所 基础软件中心,北京 100190)
基于翻译模型的查询会话检测方法研究
张振中,孙 乐,韩先培
(中国科学院软件研究所 基础软件中心,北京 100190)
查询会话检测的目的是确定用户为了满足某个特定需求而连续提交的相关查询。查询会话检测对于查询日志分析以及用户行为分析来说是非常有用的。传统的查询会话检测方法大都基于查询词的比较,无法解决词语不匹配问题(vocabulary-mismatch problem)——有些主题相关的查询之间并没有相同的词语。为了解决词语不匹配问题,我们在该文提出了一种基于翻译模型的查询会话检测方法,该方法将词与词之间的关系刻画为词与词之间的翻译概率,这样即使词与词之间没有相同的词语,我们也可以捕捉到它们之间的语义关系。同时,我们也提出了两种从查询日志中估计词翻译概率的方法,第一种方法基于查询的时间间隔,第二种方法基于查询的点击URLs。实验结果证明了该方法的有效性。
查询会话检测;词语不匹配问题;查询日志
1 引言
近年来,大规模网络查询日志的可用为查询日志分析以及用户行为分析提供了新的机会,许多与搜索相关的应用(如查询推荐、查询扩展以及查询理解等)在很大程度上依赖于查询日志挖掘[1-2]。查询会话检测是查询日志挖掘中的一个重要问题,其主要目的是确定用户为了满足某个特定信息需求而连续提交的相关查询[3]。由于其重要性,查询会话检测已经得到学术与工业界的普遍关注[1,4-10]。
由于搜索引擎按照时间顺序记录用户提交的查询,因此查询会话检测可以描述为确定同一用户提交的一系列连续查询的意图边界。图1给出了一个例子,查询被分到三个会话中(虚线表示边界)。
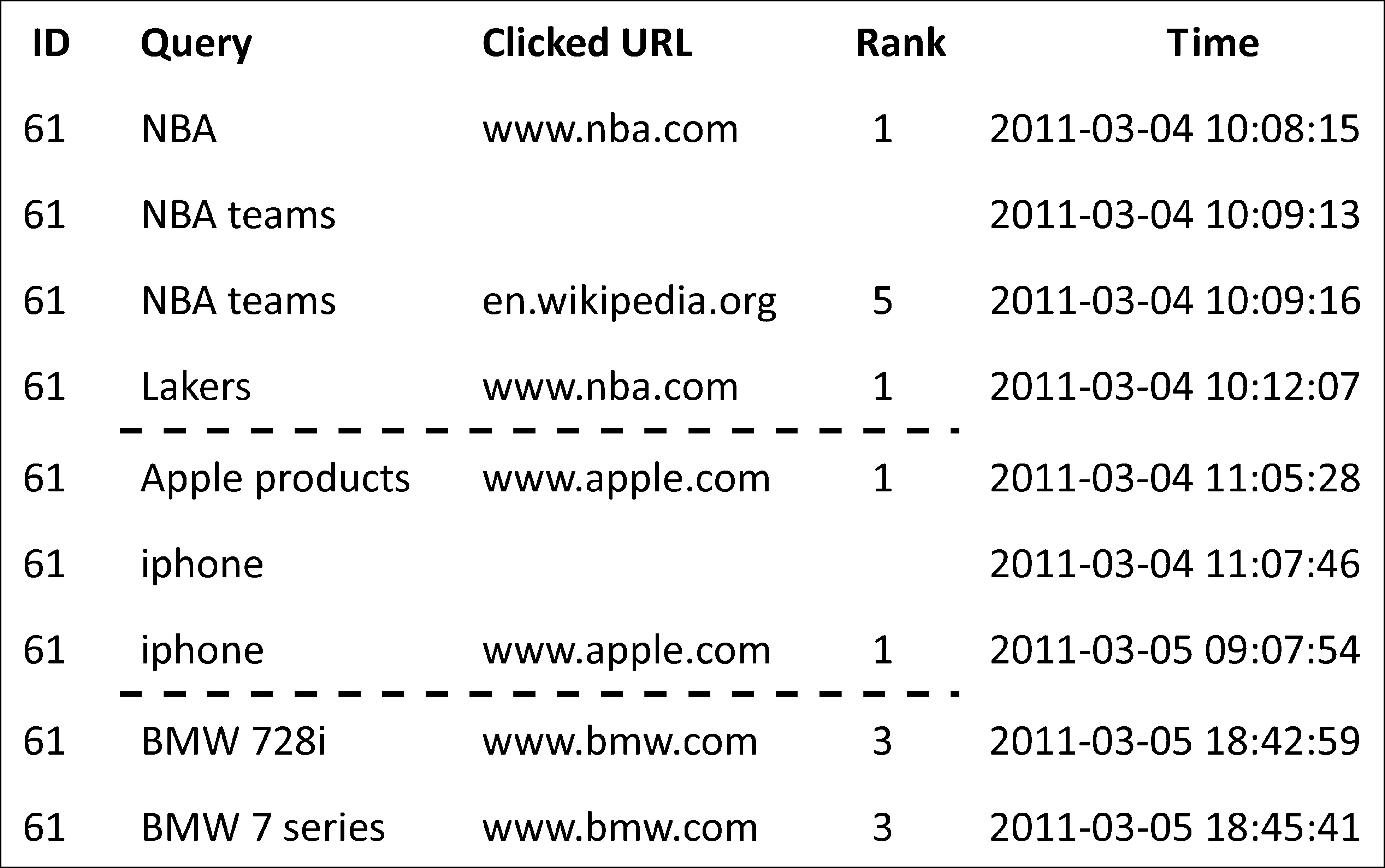
图1 查询会话检测示例
两种线索通常用来检测查询会话的边界: 查询的时间间隔以及查询共享的词语。由于计算查询的时间间隔简单方便,因此出现很多基于时间间隔的查询会话检测方法[5, 8, 11-12]。这类方法通过学习一个时间间隔来判断两个查询是否属于同一个查询会话: 如果两个查询的时间间隔超过给定的阈值,则它们属于不同的会话;反之则属于相同的会话。虽然基于时间间隔的方法快速简便,但这类方法忽略了查询的具体内容,所以通常不能取得很高的准确率[1]。
为了提高准确率,一些方法开始利用查询的具体内容。具体来说就是如果两个查询共享相同的词语则它们属于同一会话[9, 13-14]。例如,图1中的查询“NBA”和“NBA teams”共享相同的词语“NBA”,所以它们属于同一会话。由于考虑了查询的具体内容,这类方法通常比基于时间间隔的方法具有更高的准确率。然而,基于查询内容的方法无法解决词语不匹配问题(vocabulary-mismatch problem)[15]。例如,它们会将图1中的查询“apple products”和“iphone”分到不同的查询会话中,因为这两个查询之间没有相同的词语。为了解决词语不匹配问题,很多方法通过引入外部资源(如搜索结果[12,16]、维基百科[17]等)来扩展查询表示。然而这些基于外部资源的方法依赖于外部资源的质量和覆盖度。例如,维基百科只包含常用的概念,不能对大量的长尾查询进行扩展。利用搜索结果对查询进行扩展则依赖搜索结果的质量,同时需要花费大量的时间进行处理,因此不适合实时应用[7]。
本文提出了一种基于翻译模型的查询会话检测方法,该方法将词与词之间的关系建模成词之间的翻译概率来解决词语不匹配问题。通过这样的方式,即使查询之间不共享相同的词语,也可以通过词之间的翻译概率来确定两个查询是否属于同一会话。例如,我们的方法可以通过翻译概率P(iphone|apple)=0.37确定“iphone”和“apple”属于同一会话。为了获得有助于查询会话检测的词翻译概率,我们提出了两种方法可以有效地从查询日志中抽取训练语料,用来学习词翻译概率。第一种是基于查询时间间隔的方法,另一种是基于查询共同点击URLs的方法。相比维基百科,从查询日志中抽取的训练语料有很高的覆盖性。我们对提出的方法进行了若干实验,实验结果表明我们的方法显著地超过了基线方法。
本文的组织结构如下: 第二节给出了基于翻译模型的查询会话检测方法;第三节介绍如何从查询日志中学习词翻译概率;第四节给出实验结果;第五节对本文进行总结。
2 基于翻译模型的查询会话检测方法
本节将描述基于翻译模型的查询会话检测方法。首先,我们利用两个连续查询间的词汇模式确定它们的关系: (1)重复;(2)泛化;(3)具体;(4)改写;(5)新查询。如果两个查询之间的关系是前四种则将它们归到同一会话中,如果它们的关系是最后一种,则用基于翻译模型的查询会话检测方法进一步分析以判别它们是否属于不同的查询会话。
2.1 基于词汇模式分类的查询会话检测
给定两个连续查询qi和qi+1,我们首先确定它们之间的词汇模式。具体来说,分为以下五种类型。
(1) 重复。第二个查询qi+1和第一个查询qi完全相同,例如,qi=“NBA teams” ,qi+1=“NBA teams”;
(2) 泛化。第二个查询qi+1是第一个查询qi的子集,例如,qi=“NBA teams” ,qi+1=“NBA”;
(3) 具体。第一个查询qi是第二个查询qi+1的子集,例如,qi=“NBA” ,qi+1=“NBA teams”;
(4) 改写。查询qi和qi+1存在相同的词语但是每个查询都包含至少一个词语是另一个查询不包含的,例如,qi=“NBA teams” ,qi+1=“NBA player salary”;
(5) 新查询。查询qi和qi+1的关系不属于以上任何一种则归入新查询关系,例如,两个查询没有相同的词语,如qi=“NBA teams” ,qi+1=“ Lakers”。
直观上,前四类关系强烈提示着两个查询应该属于同一会话,因此我们将处于前四类关系的查询归入同一会话中。图2给出了基于词汇模式的查询会话检测示例,虚线表示查询会话边界。
然而由于词语不匹配问题,基于词汇模式的方法对于新查询关系无法做出判断,因为两个查询处于新查询关系有可能属于同一会话,如“NBA teams”和“Lakers”,也有可能属于不同会话,如“NBA teams”和“Harry Potter”,因此我们需要对处于新查询关系的查询做进一步的分析。针对这一问题,我们提出基于翻译模型的查询会话检测方法,通过查询之间的语义关系来判断处于新查询关系的两个查询是否属于同一会话。
2.2 基于翻译模型的查询会话检测
正如上面描述的那样,由于词语不匹配问题,我们需要更多的信息对处于新查询关系的查询进行分析,判断它们是否属于同一会话。我们将词语不匹配问题建模成词语间的翻译问题,而翻译概率则反映了它们之间语义关系的紧密程度,概率越大说明语义越相关。本文从查询日志中学习词之间的翻译概率,具体细节将在第三节描述。
给定词翻译概率,我们可以通过如下过程计算查询间的翻译概率。假设用户不满意查询qi的搜索结果,并依据如下过程产生查询qi+1。
1) 用户首先依据分布Φ(n|qi)产生查询qi+1的长度n;

依据上面的生成过程,从qi到qi+1的翻译概率P(qi+1|qi)为:
(1)
其中,m是查询qi的长度。式(1)看起来有些繁琐,但经过变换可以写成如下形式:
(2)
其中
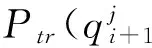
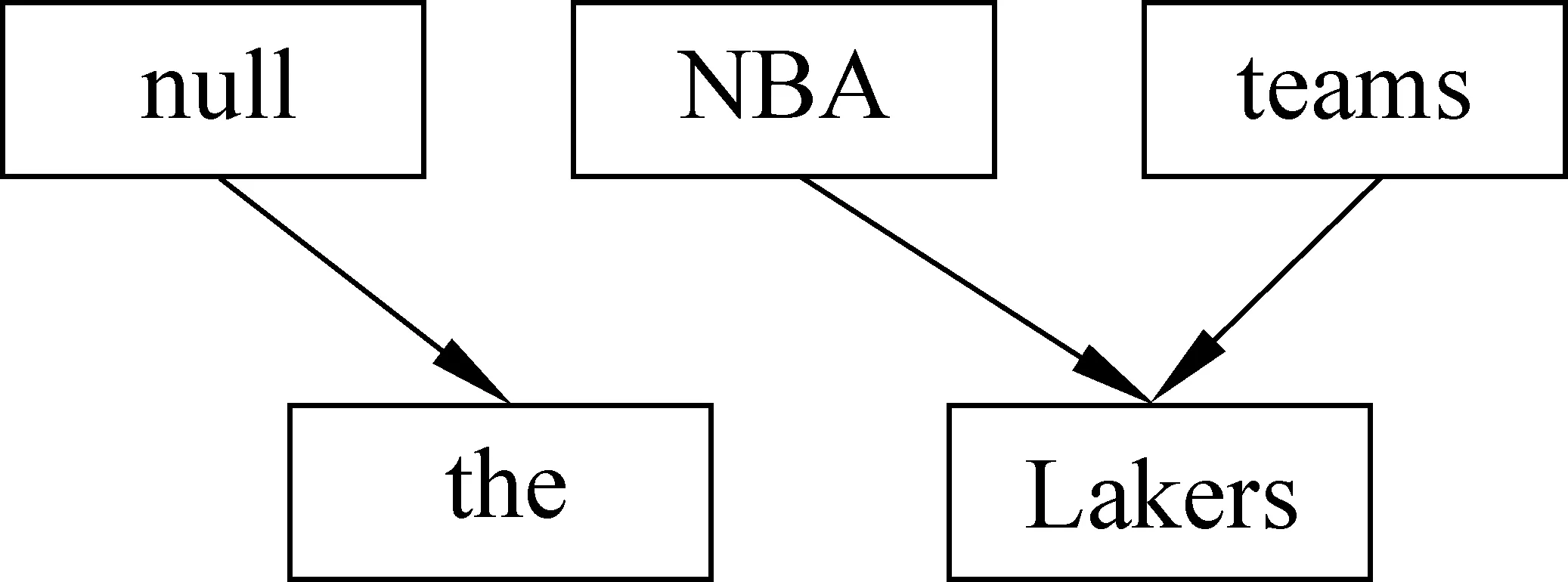
图3 查询“NBA teams”生成“Lakers”的过程
给定查询间的翻译概率,则两个查询之间的语义相关度定义为
(3)
为了计算查询间的语义相关度,我们还需要给出查询qi产生查询qi+1长度n的分布Φ(n|qi)。在本文我们假设该分布是以参数λ(qi)为均值的泊松分布,即
(4)
给定查询间的相关度,我们设定一个阈值θ,如果相关度超过θ则两个查询属于同一会话,否则属于不同会话。算法1给出了基于翻译模型的查询会话检测方法。

Algorithm1TranslationmodelbasedMethodforqueryses-siondetectionInput:twosecutivequeriesqi,qi+1Output:whethertheybelongtothesamesession1.ifpattern(qi,qi+1)isnotallocatedtotheNewpatternthen
3 从查询日志中学习翻译模型
翻译模型的表现很大程度上依赖于参数λ(q)以及词翻译概率Ptr(wj|wi)。如果存在人工标注好的查询会话训练语料,我们就可以直接从训练语料中估计这些参数。然而据我们所知,目前并不存在这样大规模的训练语料。同时人工标注查询会话需要耗费大量的人力物力,代价较大,因此如何自动地构建训练语料至关重要,本节提出两种自动构建训练语料的方法,随后将描述如何利用这些语料训练翻译模型。
3.1 构建训练语料
在本节我们提出两种自动构建训练语料的方法,第一种是基于时间间隔的方法,第二种是基于点击URLs的方法。
3.1.1 基于时间间隔的方法
为了满足同一信息需求,用户通常在短时间内连续提交一系列主题相关的查询[8]。因此我们设定一个时间阈值并利用该阈值进行查询会话检测(即同一用户提交的两个查询间的时间间隔小于给定阈值就认为它们属于同一查询)。我们将属于同一会话的查询对作为训练语料。用这种方法获得的训练语料中存在一定的“噪音”(即主题不相关的查询对,如(NBA, dog health)),但由于查询日志中不同用户提交相同的主题相关的查询对的次数比不相关的要多,所以“噪音”不会影响很大。例如,在查询日志中查询对(NBA, NBA live)的出现次数远多于(NBA, dog health)。为了降低“噪音”的影响,我们把在查询日志中出现频率低于一定阈值(本文设定为5)的查询对从训练语料中去掉。
为了确定一个合适的时间阈值,我们从2006 AOL数据集[19]中随机抽取了1 600个查询对,并人工标注每个查询对是否是同一会话。然后我们找到能使F值最大的时间间隔作为阈值。图4展示了不同时间间隔对应的F值。从图4中可以看到,当时间间隔为20分钟时F值最大,因此我们采用20分钟作为阈值。综上所述,我们从查询日志中抽取同一用户连续提交的时间间隔不超过20分钟并且共现次数超过五次的查询对作为训练数据,一共抽取了1 515 535对,我们把这个训练数据记作Corpus_TG。

图4 使用不同时间间隔的F值
3.1.2 基于点击URLs的方法
第二种构建训练语料的方法基于点击URLs,基本假设是如果两个查询有很多相同的点击URLs,则它们很可能共享相同的查询意图[20]。基于这个假设,我们把查询表示成其点击URLs的向量,然后计算查询间的余弦相似度,对于每个查询挑选相似度最大的前N(本文N=10)个查询并和原查询组成查询对作为训练数据,通过这种方法我们共得到7 153 460个查询对,我们把这个训练数据记作Corpus_CL。
3.2 模型参数估计
使用上面的方法,我们构建了两个训练数据集,每个数据集由若干查询对组成{(qs1,qt1)…(qsN,qtN)}。本小节将描述如何使用训练数据来训练模型参数。
给定训练数据,我们通过最大化下面的对数似然函数来学习参数。
(5)
其中ni是查询qti的长度。我们首先对参数λ(qsi)求导并将结果设为零,得到
(6)
其中δ是克罗内克δ函数(当两个参数相同时值为1否则为0)。从式(6)可以看出,λ(qsi)实际上就是训练数据中紧随查询qsi后面的查询的平均长度。然而训练数据中不能包含所有查询,当测试数据中出现训练数据中不包含的查询时,这个参数就无法用上述公式估计。考虑到用户在连续提交相关的查询时,查询的长度通常不会变化很大,因此在本文中,如果查询qi没有出现在训练数据中,设定λ(qsi)为qsi的长度。由于参数Ptr(t|w)没有封闭解,我们使用EM算法学习参数Ptr(t|w)。表1展示了使用训练语料Corpus_TG和Corpus_CL学习到的词之间的翻译,给定一个源词语,我们依据翻译概率列出了前五个概率最大的目标词语,如表1所示。

表1 词翻译示例
注: 给定源词语,每一列依据翻译概率的大小列出了前5个目标词语,TG和CL分别代表由训练语料Corpus_TG和Corpus_CL学习得到的翻译概率
4 实验分析
4.1 测试数据和对比方法
为了测试提出方法的性能,我们从2006 AOL查询日志中随机抽取179个用户的8 854个查询,并由三位标注者进行人工标注,共得到3 047个查询会话(平均每个会话2.9个查询)。我们使用以下四种方法作为对比方法。
(1) TIME_QSD[5]: TIME_QSD使用时间间隔来检测会话。依据3.1节中的实验,我们使用20分钟作为阈值;
(2) CONTENT_QSD[14]: CONTENT_QSD通过词语比较来检测查询会话,即如果两个查询共享相同的词语则属于同一会话,否则属于不同会话。这个方法等价于我们方法的第一步;
(3) GEOMETRIC_QSD[8]: GEOMETRIC_QSD使用几何插值技术将时间间隔和词语比较结合起来进行会话检测,当前兼顾性能和效率的最好方法之一;
(4) ESA_QSD: ESA_QSD是上述GEOMETRIC_QSD方法的扩展,在进行词语比较的时候,通过ESA模型[21]使用维基百科对查询进行显式语义分析,然后使用几何插值技术将时间间隔、词语比较以及通过ESA得到的语义相关度结合起来进行会话检测。
4.2 评价指标
我们使用文献[6]中的指标来评价提出的方法以及对比方法,这些指标是: ERR、SER以及F-Measure,对于查询会话检测系统来说,F-Measure越高表明系统性能越好,SER和ERR越低说明系统性能越好。
4.3 实验结果
我们使用上述的数据集和评价标准来测试我们的方法和对比方法,其中TRANS_TG表示在训练语料Corpus_TG进行参数训练的方法,TRANS_CL表示在训练语料Corpus_CL进行参数训练的方法。因为我们的方法需要设定相关度阈值θ,我们从数据集中随机抽取10%的数据作为开发集用来确定θ,其余90%的数据作为测试语料。通过在开发集上的实验,对TRANS_TG我们设定θ为0.05,对TRANS_CL设定为0.03。
表2展示了所有方法在ERR 和SER上的得分,表3给出了所有方法在准确率(precision)、召回率(recall)以及F-Measure上的得分。从这些实验结果中我们可以得出以下结论。
1) 相比所有对比方法,我们的方法显著地提升了性能。例如,相比TIME_QSD、CONTENT_QSD、 GEOMETRIC_QSD以及 ESA_QSD,TRANS_TG取得了10.14%、7.28%、3.18%以及2%的SER改善。在ERR以及F-Measure上,我们的方法也超过了对比方法。这表明了我们可以通过词之间的翻译概率来捕捉查询间的关系,同时也表明了我们从查询日志中抽取的训练数据可以有效地估计词翻译概率。
2) 相比CONTENT_QSD方法,我们的方法取得了3.51%的F-Measure提升、5.49%的ERR下降以及7.28%的SER下降。这表明我们的方法通过词翻译概率捕捉查询间的关系在一定程度上可以解决词语不匹配问题。
3) 相比ESA_QSD,我们的方法取得了1.2%的F-Measure提升、1.9%的ERR下降以及2%的SER下降。这表明相比维基百科,从查询日志中学习查询间的关系对会话检测更有效。主要是因为查询中经常包含一些维基百科中没有的词,这种情况ESA模型就无法对其进行映射,而我们的方法从查询日志中直接学习,相比维基百科具有高覆盖性(即ESA无法进行映射的某些长尾查询,我们的方法依然可以通过查询日志学习其翻译概率)。
4) 我们方法的表现在很大程度上依赖于从训练语料中学习的词翻译概率。相比TRANS_CL,TRANS_TG在三个指标上都取得了更好的表现,这表明通过训练数据Corpus_TG学习的词翻译概率更适合会话检测。主要原因是通过时间间隔获得的查询对大部分都是属于同一会话,从我们在测试语料上的实验可以看到通过时间间隔得到的查询对86.23%都属于同一会话,而Corpus_CL通过点击URLs来确定主题相关的查询对,由于点击URLs中存在一部分URLs与多个主题相关(如http://en.wikipedia.org 与体育、音乐、政治等主题都相关),因此通过点击URLs确定的部分查询对主题不相关,这部分“噪音”影响了词翻译概率的学习。
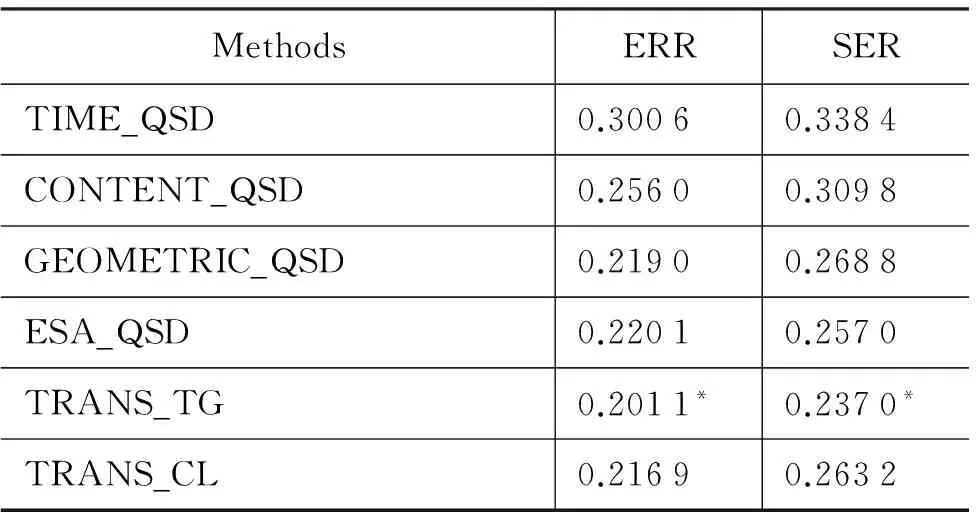
表2 各方法在测试数据上的ERR和SER得分
注: 上标*表示结果在t检验的0.05水平上具有差异性
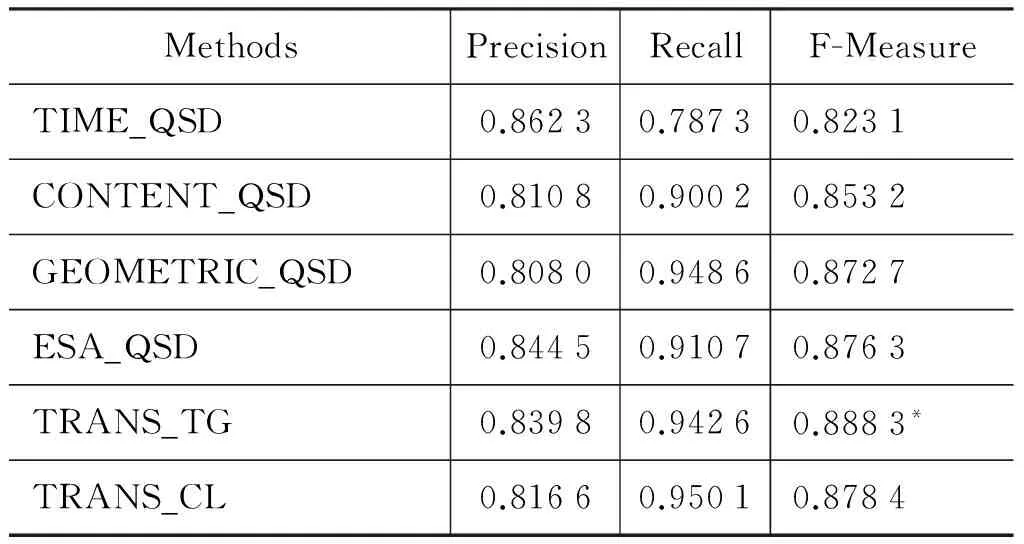
表3 各方法在测试数据上的准确率、召回率以及F值
4.4 时间效率分析
由于查询会话检测的时间效率对于实际应用来说很重要,我们对提出的方法和对比方法进行了效率分析。表4给出了各个方法在桌面电脑上(2.66GHz CPU以及4GB RAM)处理一对查询所需的平均时间。
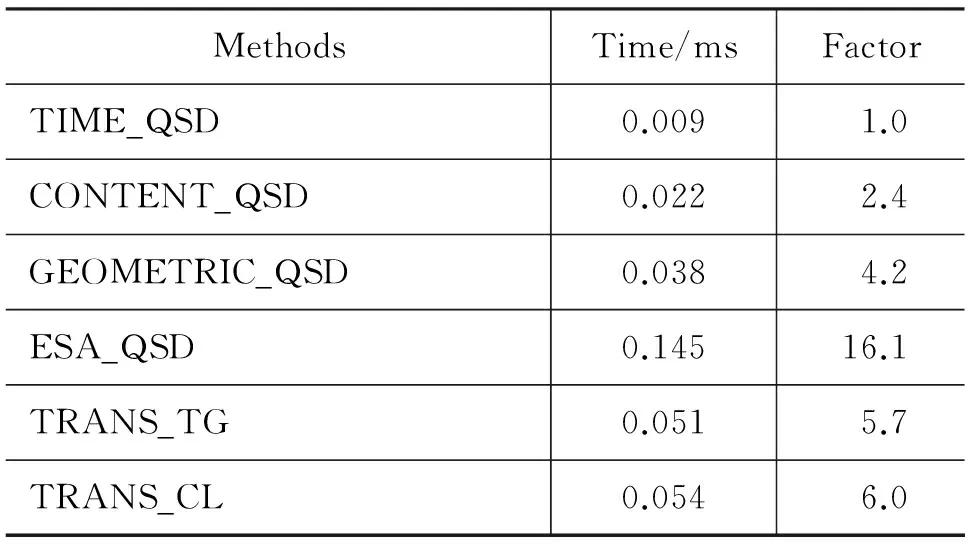
表4 各方法处理一对查询所需的平均时间
从表4可以看出,只使用单个线索的方法(TIME_QSD和CONTENT_QSD)速度最快。由于词翻译概率可以事先线下计算并存储,而且查询比较短,所以我们的方法耗时较少(所用时间是基于时间间隔方法的五倍)。相比而言,ESA_QSD效率最低(所用时间是基于时间间隔方法的16倍),主要原因是将每个词映射到维基百科的概念并在这个巨大的概念空间中计算相似度。
4.5 处理词语不匹配问题的表现
为了检验我们方法解决词语不匹配问题的能力,我们构建了一个新的数据集,该数据集包含450个查询对,每一个查询对中的两个查询属于同一会话但没有相同的词语(如NBA teams和Lakers等),我们把这一个数据集记做VM。我们用这一个数据集对ESA_QSD、TRANS_TG以及TRANS_CL进行测试,使用的评价标准是准确率,计算公式如式(7)所示。
(7)
其中Nmethod是查询会话检测方法确定两个查询属于同一查询会话的查询对数目,N是总共的查询对数目(在我们的测试中N=450)。
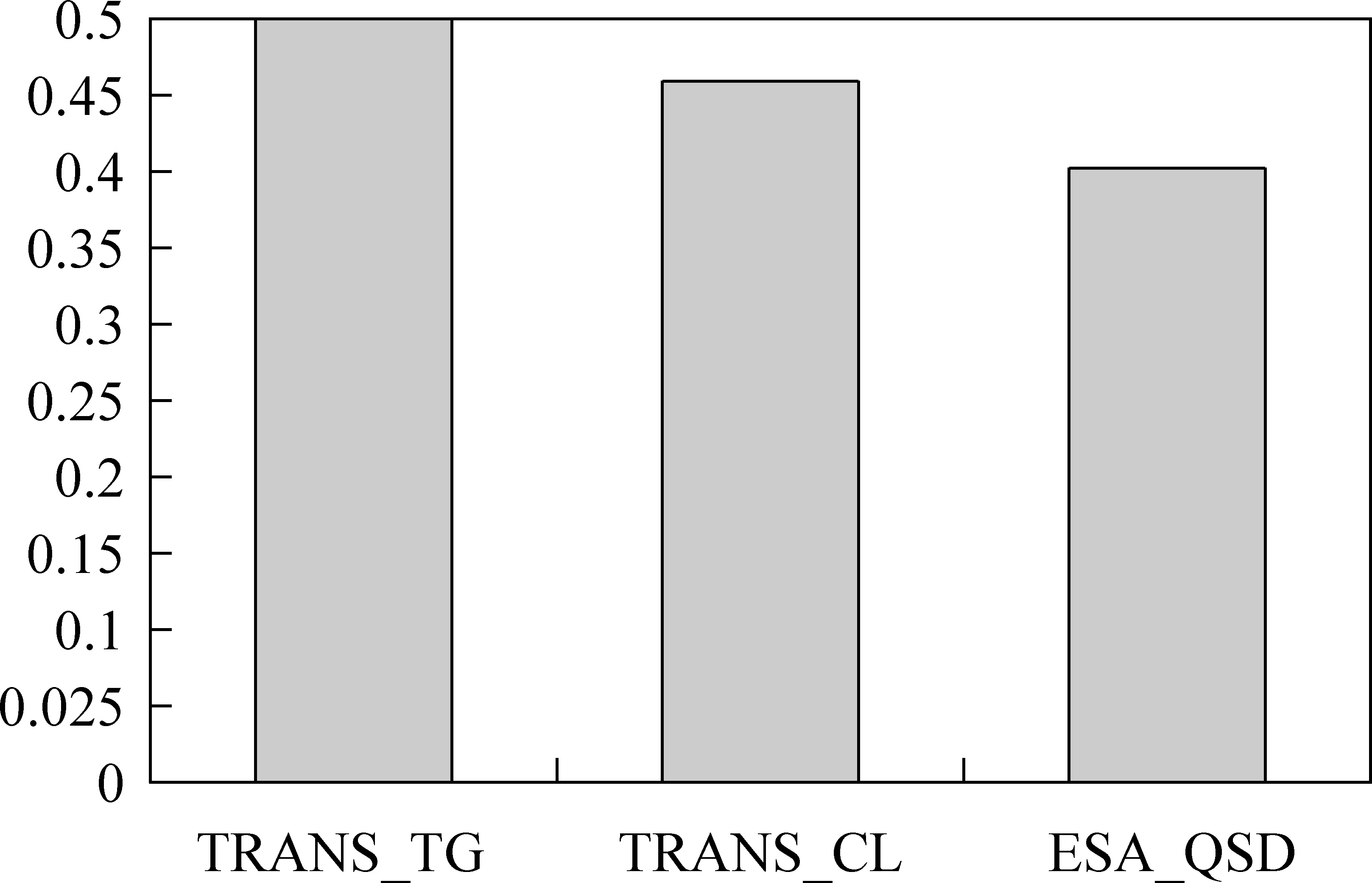
图5 TRANS_TG、 TRANS_CL和ESA_QSD在测试集VM上的准确率
图5给出了三种方法在数据集VM上的准确率。从图5中可以看到,TRANS_TG取得了最好的准确率(0.497 8),相比之下,TRANS_CL和ESA_QSD的准确率分别是0.462 2和0.4。相比ESA_QSD,TRANS_TG取得了9.78%的准确率提升,TRANS_CL取得了6.22%的准确率提升。这些结果表明我们的方法在一定程度上能解决词语不匹配问题,同时在解决词语不匹配问题上比基于维基百科的ESA方法更有效。
5 结论及下一步工作
本文提出一种基于翻译模型的查询会话检测方法,通过将词之间的关系建模成词翻译概率来解决词语不匹配问题。同时我们提出了两种方法从查询日志中学习词翻译概率。实验结果表明基于翻译模型的查询会话检测方法比基线方法显著地提升了会话检测的性能。未来我们将进一步设计能够更好地学习翻译概率的方法,同时我们也准备在模型中引入更多的因素来提升系统的性能。
[1] Rosie Jones, Kristina L.Klinkner. Beyond the Session Timeout: Automatic Hierarchical Segmentation of Search Topics in Query Logs [C]// Proceedings of CIKM2008, 2008: 699-708.
[2] 余慧佳,刘奕群,张敏等.基于大规模日志分析的网络搜索引擎用户行为研究 [J]. 中文信息学报,2007, 21(1): 109-114.
[3] Bernard J. Jansen, Amanda Spink, Chris Blakely, et al. Defining a Session on Web Search Engines [J], Journal of the American Society for Information Science and Technology, 2007, 58(6):862-871.
[4] Paolo Boldi, Francesco Bonchi, Carlos Castillo, et al. The query-flow graph: model and applications [C] // Proceedings of CIKM2008, 2008: 609-618.
[5] Doug Downey, Susan Dumais, Eric Horvitz. Models of searching and browsing: languages, studies, and application [C] // Proceedings of IJCAI, 2007: 2740-2747.
[6] Daniel Gayo-Avello. A survey on session detection methods in query logs and a proposal for future evaluation [J]. Information Sciences, 2009, 179(12):1822-1843.
[7] Matthias Hagen, Benno Stein, Tino Rüb. Query session detection as a cascade [C] // Proceedings of CIKM2011, 2011: 147-152.
[8] Daqing He, Ayse Göker. Detecting session boundaries from Web user logs [C] // Proceedings of the 22nd Annual Colloquium on Information Retrieval Research, 2000: 57-66.
[9] Daqing He, Ayse Göker, David J. Harper. Combining evidence for automatic Web session identification [J], Information Processing and Management, 2002, 38(5):727-742.
[10] 张磊,李亚男,王斌等. 网页搜索引擎查询日志的session划分研究 [J]. 中文信息学报, 2009, 23( 2): 54-61.
[11] Nikolai Buzikashvili, Bernard J. Jansen. Limits of the Web log analysis artifacts [C]//Proceedings of the Workshop on Logging Traces of Web Activity, WWW, 2006.
[12] Filip Radlinski, Thorsten Joachims. Query chains: learning to rank from implicit feedback [C]// Proceedings of KDD, 2005: 239-248.
[13] Tessa Lau, Eric Horvitz. Patterns of search: analyzing and modeling Web query refinement [C]// Proceedings of the Seventh International Conference on User Modeling, 1999: 119-128.
[14] Amanda Spink, Bernard J. Jansen, H. C. Özmutlu. Use of query reformulation and relevance feedback by excite users [J], Internet Research: Electronic Networking Applications and Policy, 2000, 10(4): 317-328.
[15] Girill T R. Online access AIDS for documentation: a bibliographic outline [J]. ACM SIGIR Forum, 1985, 18(2-4):24-27.
[16] Xuehua Shen, Bin Tan, Chengxiang. Zhai. Implicit user modeling for personalized search [C]// Proceedings of CIKM, 2005: 824-831.
[17] Claudio Lucchese, Salvatore Orlando, Raffaele Perego, et al. Identifying task-based sessions in search engine query logs [C]// Proceedings of WSDM, 2011: 277-286.
[18] Craig Silverstein, hannes Marais, Monika Henzinger, et al. Analysis of a very large web search engine query log [J]. In SIGIR Forum, 1999, 33(1):6-12.
[19] Greg Pass, Abdur Chowdhury, Cayley Torgeson. A picture of search [C]// Proceedings of Infoscale, 2006: 1.
[20] Lin Li, Zhenglu Yang, Ling Liu, et al. Query-URL bipartite based approach to personalized query recommendation [C]// Proceedings of AAAI, 2008: 1189-1194.
[21] Evgeniy Gabrilovich, Shaul Markovitch. Computing semantic relatedness using Wikipedia-based explicit semantic analysis [C]//Proceedings of IJCAI, 2007: 1606-1611.

张振中(1983—),博士研究生,主要研究领域为数据挖掘和信息检索。E-mail:zhenzhong@nfs.iscas.ac.cn孙乐(1971—),博士,研究员,主要研究领域为信息检索和自然语言处理。E-mail:sunle@nfs.iscas.ac.cn韩先培(1984—),博士,副研究员,主要研究领域为信息抽取、知识库构建以及自然语言处理。E-mail:xianpei@nfs.iscas.ac.cn
“第十五届少数民族语言文字信息处理学术研讨会”召开
2015年8月13—14日,由中国中文信息学会民族语言文字信息专委会主办,延吉北亚信息技术研究所、中央民族大学、中国朝鲜语信息学会承办的“第十五届少数民族语言文字信息处理学术研讨会”在吉林省延边朝鲜族自治州延吉市召开。
今年适逢中国中文信息学会民族语言文字信息专委会成立暨全国少数民族语言文字信息处理研讨会召开30周年。本届会议得到了中国中文信息学会、教育部语言文字信息管理司、国家民委教科司、国家自然科学基金委员会、内蒙古自治区民委、吉林省民委、延边朝鲜族自治州等主管部门的大力支持,以及中国中文信息学会、延吉北亚信息技术研究所、中央民族大学等单位的真诚赞助!
本次会议共有来自全国各省市自治区的130余位代表参加,是历届“少数民族语言文字信息处理学术研讨会”参与人数最多、投稿数量最多的一次会议。会议有幸邀请到中国工程院倪光南院士、吾守尔院士,中文信息学会理事长李生教授、秘书长孙乐研究员,北京大学俞士汶教授和王厚峰教授、清华大学孙茂松教授,中科院自动化所宗成庆研究员和赵军研究员等众多语言信息处理领域的知名学者,以及上海韬图动漫科技有限公司的李秦女士,他们带来了精彩的特邀报告,对国内民族语言文字信息处理研究及应用起到了很好的引导、规范及示范作用。
本届大会的召开,进一步促进了各民族代表的学术研究和交流,以及民族语言文字信息化的发展,对建立中国少数民族语言资源的“统一规划、统一建设、统一标准、统一平台、资源共享”的机制具有积极的推动作用,对少数民族语言文字信息处理技术的交流与发展具有深远的影响,会议取得了圆满成功。
A Translation Model Based Method for Query Session Detection
ZHANG Zhenzhong, SUN Le, HAN Xianpei
(NFS, Institute of Software Technology, Chinese Academy of Sciences, Beijing 100190, China)
Query session detection is critical for query log analysis and user behavior characterization. It aims at identifying the consecutive queries submitted by a user for the same information need. Traditional query session detection methods are based on lexical comparisons, which often suffer from the vocabulary-mismatch problem(i.e, the topically related queries may not share any common words). To resolve the issue, this paper proposes a translation model based method for query session detection, which can model the relationship between words as word translation probability. In this way our method can capture the relatedness between queries even they do not share any common words. Furthermore, we also propose two approaches for generating training data from web query log for translation probability estimation. The first approach is based on time gap between queries and the second is based on the clicked URLs of queries. Experimental results show that our method can significantly outperform the baselines.
query session detection; vocabulary-mismatch problem; query log
1003-0077(2015)04-0095-08
2014-01-05 定稿日期: 2014-03-12
国家自然科学基金(61433015,61272324),国家高技术研究发展计划项目(2015AA015405)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
华人时刊(2021年13期)2021-11-27
数学小灵通(1-2年级)(2020年11期)2020-12-28
心声歌刊(2020年4期)2020-09-07
小学生学习指导(低年级)(2019年3期)2019-04-22
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
读写算·小学低年级(2014年4期)2014-07-24
外语教学理论与实践(2014年2期)2014-06-21
