
事件关系检测的任务体系概述
2015-04-21 08:29杨雪蓉陈亚东姚建民朱巧明
中文信息学报 2015年4期
杨雪蓉,洪 宇,陈亚东,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
事件关系检测的任务体系概述
杨雪蓉,洪 宇,陈亚东,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
事件关系检测是一项面向文本信息流进行事件关系判定的自然语言处理技术。事件关系检测的核心任务是以事件为基本语义单元,通过分析事件之间的语义关联特征,实现事件逻辑关系的识别与判定,包括关系识别(即识别有无逻辑关系)和关系判定(即判定逻辑关系类型,如“因果”关系)。目前,专门面向事件的逻辑关系分析与处理,尚未形成一套完整的研究体系。针对这一问题,该文借助篇章分析、事件抽取和场景理解等相关领域中的概念与数据资源,尝试建立一套事件关系检测的任务和研究体系,包括任务定义、关系体系划分、语料采集与标注、评价方法等。同时,该文着重分析和对比了事件关系检测与篇章关系检测的差异,并给出了事件关系检测任务的难点与挑战。
事件关系检测;篇章分析;事件;论元;语义关系
1 引言
事件(Event)是由特定人、物、事在特定时间和特定地点相互作用的客观事实,事件的发生具有客观性、真实性等特点。然而,事件的发生往往不是孤立现象,一个事件的发生必然存在与之相关的其它事件,例如与该事件相关的原因事件、结果事件、并发事件等。事件与其相关事件之间相互依存和关联的逻辑形式,称为事件关系(Event Relation)。
事件关系客观存在于事件之间,并且作用于原本孤立的事件集合中。事件关系能将离散于文本中的事件相连接,形成事件关系网络和事件发展的拓扑脉络。从而,分析事件关系对于目前大规模的舆情信息分析与处理具有重要的应用价值,例如,关联事件聚类、新闻事件的关系网络构建,以及突发事件推理与预测等。
本文将“相关事件识别(Event Relevance Identification)”和“事件关系类型判定(Event Relation Type Decision)”统称为事件关系检测(Event Relation Detection),由此,事件关系检测是一种深入判定两两事件之间相关性以及具有何种逻辑关系的任务。目前针对事件关系检测的研究刚刚起步,由于不具有权威的任务定义、事件关系体系以及评测标准,相关探索尚不深入,相应方法也仅仅着眼于某一特定事件关系类型(如“因果”关系)的判定,不具有全面性和普适性。相较而言,自然语言处理领域中的篇章关系检测研究,以论元(即完整的语义单元,如句子)为对象,建立了较为全面的任务体系,其蕴含的概念、关系体系和评价方法也具有普适性,能够有效应用于事件关系检测任务。
然而,事件关系并不等同于篇章关系,篇章关系检测也不能涵盖所有事件关系检测的关键问题。从而,事件关系检测需要一种有针对性的专属的任务和研究体系,而不能将篇章关系检测体系简单移植和并用。
本文基于篇章关系检测的定义及关系体系,定义了事件关系检测任务、评价方法和事件关系体系,该体系将事件关系类型定义为五个大类,12个小类。同时,本文根据定义的事件关系类型构建了面向事件关系检测任务的语料库。此外,本文给出了篇章关系检测与事件关系检测的任务对比,以及事件关系检测的关键问题与挑战。
本文的组织结构如下: 第2节给出相关工作;第3节介绍事件关系检测的任务定义;第4节详细分析事件关系与篇章关系的任务差异,以及事件关系检测的关键问题;第5节介绍本文定义的事件关系体系;第6节阐述语料库的构建方法;第7节简要介绍可行的测试与评价方法;第8节总结全文。
2 相关工作
本节介绍事件关系检测以及篇章关系分析的研究现状。
2.1 事件关系检测相关研究
由于缺少公认的事件关系体系,目前针对事件关系的研究方法主要针对某种特定事件关系类型的判定进行研究,主要的挖掘方法分为模板匹配法和元素分析法,下文分别对这两种方法予以介绍。
模板匹配法
事件关系检测的主要方法之一是借助事件特征的模式匹配,例如,利用事件触发词的关系模式匹配,根据人工定义的模板,对文本中符合模板的事件关系进行抽取。Chklovski[1]等首先定义六种时序关系:“similarity”(时序“相似”关系),“strength”(时序“加强”关系),“antonymy”(时序“相反”关系),“enablement”(时序“支持”关系), “happens”(时序“发生”关系)和“before”(时序“前”关系),再利用人工收集的LSP(Lexcial-Syntactic Pattern,即词-句匹配模板)抽取包含这六种时序关系的“事件对”,并将抽取的结果形成称为“VerbOcean”的知识库。人工定义的事件关系模板往往受数量限制,造成关系检测的低召回率问题。Pantel[2]通过Espresso算法进行自动模板的构建,算法首先给定少量关系实例,通过机器学习方法对现有模板进行迭代扩展,在一定程度上提高了模板匹配方法的召回率。
元素分析法
以事件元素为线索的研究大都继承了Harris[3]的分布假设。Harris假设指出,处在同一上下文环境中的词语具有相同或相似的含义。Lin[4]提出了一种结合Harris分布假设和建立依存树思想的无监督方法,称为DIRT算法。算法将所有事件构造成依存树形式,树中的每条路径表示一个事件,路径的节点表示事件中的词语,若两条路径的词语完全相同,则这两条路径所表示的事件相同或者相似。
3 事件关系检测任务体系
事件关系检测任务包括如下方面: 事件抽取、相关事件识别和事件关系类型判定。其中,该任务的核心部分为: “相关事件识别”和“事件关系类型判定”。即首先获得文本中的“相关事件对”(离散存在于段落或跨篇章),再将得到的“相关事件对”,通过挖掘事件关系线索,实现“相关事件对”关系类型的推理与判定。事件抽取任务则已出现ACE研究体系之内,不作为事件关系检测的核心任务,仅作为研究基础予以提出。下面分别对事件抽取、相关事件识别和事件关系类型判定任务进行详细介绍。
3.1 事件抽取
事件抽取为自动内容抽取(Automatic Content Extraction,ACE)的子任务之一,该任务由美国国家标准技术研究院(NIST)提供较为完备的任务定义和研究体系。事件抽取任务旨在从含有事件信息的非结构化源文本中抽取结构化的事件描述,在自动文摘[9]、自动问答[10]以及信息检索等领域有着广泛的应用。目前,事件抽取已得到国内外广泛的研究[11-12]。事件抽取能够提供事件的基本属性,并建立事件内部各组成成分之间的语义关系,从而塑造事件本质的描述结构。事件抽取是实现关联事件识别和事件关系判定的先决条件,也是事件关系检测的关键问题之一。
3.2 相关事件识别
相关事件识别旨在实现事件逻辑关系的浅层检测,即判断任意事件之间是否存在逻辑相关性,是一种二元关系判断。事件的相关性(Event Relevancy)与事件的相似性(Event Similarity)不同,事件的相关性是指两个事件之间是否存在逻辑关联性,事件的逻辑关联性客观存在于事件中,不因事件文字描述的不同而不同;而事件的相似性侧重识别相同或相似事件的不同文本描述的一致性(同一事件的描述形式多样),即语义相似性,现有文本建模和相似度度量方法,已给出较为有效的处理手段。因此,事件的相关性与事件的相似性的差异,使得仅仅通过两个事件的文字表述方式无法判断逻辑关联与否,需要挖掘更多的外部信息,充分利用外部资源辅助事件关联性的识别。
文本中的事件往往呈现一种离散分布,具有逻辑相关联的事件往往跨句子、跨段落,甚至跨篇章。因此,需要预先对文本篇章中的离散事件集合中,各事件间是否存在逻辑关联性进行识别,例如文本中存在如下三个事件:
Evt1 “本东北地区宫城县北部发生里氏7.9级特大地震”
Evt2 “临时关闭成田机场的跑道”
Evt3 “日本食用牛肉首次检出超标辐射物”
上述三个事件为话题“日本7.9级地震”下描述的事件,而同一话题下的事件并非两两相关。通过相关事件识别,事件Evt1和事件Evt2相关,事件Evt1和事件Evt3相关,而事件Evt2和事件Evt3之间不存在逻辑关系。无关事件的关系判定不仅冗余,并且直接影响判定过程的整体精度,事件关系检测任务首先通过“相关事件识别”识别“相关事件对”,进而只针对“相关事件对”解析其深层次的具体逻辑关系。
3.3 事件关系类型判定
“事件关系类型判定”指对已获得的“相关事件对”判定逻辑关系类型,是一种对事件关系的深层分析和研究。“相关事件识别”仅对事件间是否存在逻辑关系进行识别,这种单一的判断不足以对事件间逻辑关系进行深层分析和研究。事件逻辑关系作为一种客观存在,包含大量不同种类的关系类型,常见的事件关系类型有因果关系、时序关系等。因此,通过对“相关事件对”具体关系类型的判定,进一步对事件关系类型进行分类,能够更准确的挖掘事件发生的规律、特征等,从而更有效的辅助事件演变与发展的推理。
事件关系类型检测研究的首要任务是构建事件关系体系,然而,目前学术界尚未形成统一、完备的事件关系体系。篇章关系分析研究旨在识别和判定一对毗邻“论元对”(具有完整语义的语言单元,如字句,短语等)间的语义关系类型,如“因果关系”、“转折关系”等。本文借鉴篇章关系分析任务中完善的语义关系体系,将事件关系检测任务与篇章关系分析任务类比,制定了一套完整的事件关系体系。同时,根据定义的事件关系体系,标注了事件关系语料库,该部分内容由下文详细阐述。
4 篇章关系检测与事件关系检测的任务对比
本文借鉴篇章关系检测的任务体系,提出事件关系检测研究。本节介绍篇章关系检测任务,并将篇章关系检测与事件关系检测的任务对比,详细分析事件关系与篇章关系的任务差异。同时,提出事件关系检测任务的关键问题。
4.1 简析篇章关系检测任务
篇章关系检测旨在自动检测篇章中相邻片段(子句、句子或段落),即“论元对”的组织结构与逻辑关系。该任务涉及短语、子句、句子等文本片段之间的语义关系研究,通过分析毗连文本区域之间内在的语义联系,构建文本篇章关系结构,进而深入理解篇章语义。
PDTB根据“论元对”是否由显示连接词(如英文中的“because”)衔接,将篇章关系分析分为显式篇章关系和隐式篇章关系。PDTB针对论元定义的语义关系体系分为三层,其中,第一层包含四个大类,即“因果”、“对比”、“扩展”和“时序”四种关系,第二层包含16个子类,第三层包含22个子类型,各子类型均为对上一层关系类型的细化。
4.2 篇章关系检测与事件关系检测的异同
事件是一种人、物、事相互作用的客观事实,诉诸文字后,成为信息传播中可读可解的事件文体(也称“事件体”,本文统称“事件”)。从而,事件的描述必须遵循自然语言的行文规律,如篇章结构、篇章修辞、语法和文法等规律。也因此,事件关系检测与篇章关系检测任务有着一定程度的领域交差性。
然而,“事件关系检测”与“篇章关系检测”又有着明显的差异,下面枚举篇章关系和事件关系的主要差异。
1) 篇章关系检测的对象为两两毗连的论元,即序列“论元对”,而事件往往离散分布,并非绝对相互毗连,例如,序列论元“Arg1: 他病了”、“Arg2: 一天后”、“Arg3: 他康复了”中,按照ACE(Automatic Content Extraction)对事件的定义,Arg1与Arg3为事件(Arg2仅为论元,而非事件),且具有“对比”关系,但因相互并不毗连,从而不属于篇章关系的研究范畴;
2) 篇章关系检测聚焦于独立篇章内部,事件关系则可跨篇章出现,从而只受话题框架约束,而非绝对依存于特定篇章塑造的语言环境(TDT领域,即Topic Detection and Tracking,将相互关联的事件集合统称为话题),例如,事件“国五条出台”(2013年3月1日网易新闻*http://bj.house.163.com/13/0301/19/8OTEFDJF00073SD3.html)和事件“二手房交易井喷”(2013年3月18日网易新闻*http://money.163.com/13/0318/14/8Q8MH47N00253B0H.html)具有“因果”关系,但不局限于孤立的新闻报道之内;
3) 篇章关系往往具有主观性(即人为塑造的关系),而事件关系则注重事实与客观性(即本源的逻辑关系)。
4.3 事件关系检测的关键问题
针对事件关系检测的特性,即事件离散分布、依赖先验相关性、事件关系无直观线索、受逻辑客观性约束等特性,本节给出事件关系检测的如下关键问题。
1) 事件内部属性(包括触发词、事件参与者等)信息能够为事件关系检测提供明确的事件描述,并且,事件属性往往是反映事件外部关系的关键特征。然而,目前ACE领域中,针对事件抽取(包括触发词、事件类型、参与元素及其角色的抽取)尚未达到理想效果,全面支持自动事件关系检测尚有困难。
2) 为了提高事件关系类型判定的准确性,应首先判定两事件是否相关(即事件关系识别)。事件关系识别挖掘事件关联性以及关联推理线索,从而构建事件关联的线索集合,若进一步判定“相关事件对”的关系类型,则需分析和处理已构建的“相关事件对”线索集合,形成关键的关系推理脉络,对事件关系类型进行推理。
3) 事件本身具有离散性、跨篇章性、无显式线索等特征,使得无法直接利用语言学特征支持事件关系的判断。由此,检测事件关系应从统计学角度入手,利用大规模数据识别和挖掘事件关联的线索和脉络,形成基于统计策略的事件关系推理机制;然而,这种机制必然引入大规模数据处理与挖掘,线索挖掘的效率快慢与精度高低都会直接影响事件关系检测的性能;
4) 事件关系检测不能仅仅考虑字面上的语义关系,还应根据统计信息估测关系的逻辑可信性。这一问题在现有的事件关系检测研究中尚未引起重视,相应的逻辑关系样本也尚未构建,无法支持针对事件关系逻辑可信性的机器学习。因此,现阶段仅能依据经验模型和无指导的机器学习模型予以估测。同时,事件隶属的主题框架,有助于识别事件关系的作用域,从而有助于事件关系的深层检测。
5 事件关系体系
本文将篇章关系体系与事件关系进行分析和对比,选取篇章关系体系中能够应用于离散“事件对”的篇章关系类型作为事件关系类型。同时,篇章关系与事件关系的差异性使得篇章关系不能描述完整的事件关系类型,因此,本文借助事件关系实例,人工总结事件关系类型,进一步对事件关系类型进行补充,确保事件关系体系的完整性,由此形成的事件关系体系如表1所示。
本文定义的事件关系体系共分为两层(表1),第一层包含四种主要关系类别: Temporal(时序)、Comparison(比较)、Contingency(偶然)、Expansion(扩展), 第二层为以上关系类型的扩展,共有十种子类型。下面给出主要关系的示例。
5.1 Temporal 时序
“时序关系”是指两个事件通过时序相关联。本文将“时序关系”进一步分为“同步关系”和异步关系,下面分别介绍这两种关系类型。
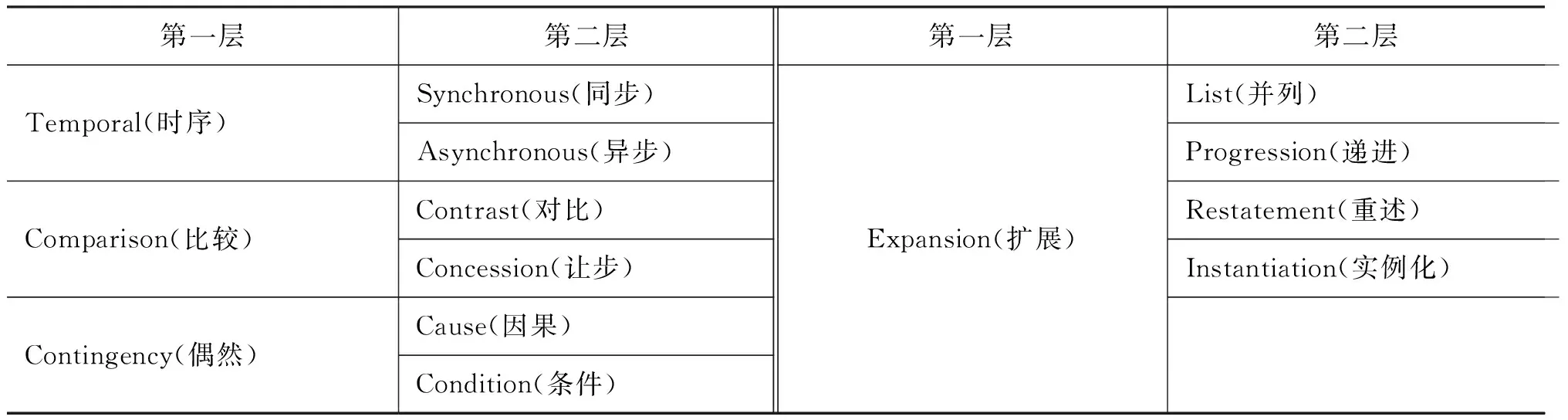
表1 事件关系体系
(1) Synchronous 同步
“同步关系”是指两个相关事件Evt1、Evt2发生的时间存在一定的重合(如下例Evt1和Evt2,以下事件实例均来自FrameNet-1.5,加粗部分为该事件的触发词)。如下例中,事件Evt1与事件Evt2为同时发生的两个事件。
Evt1 “Policealsofindsasecondhouse”
(译文:“警察发现了第二个房子”)
Evt2 “Meantime,analystsatthecrimelabtrytodiscoverwhatthebombwasmadefrom”
(译文:“同时,犯罪实验室的分析师试图发现炸弹的来源”)
(2) Asynchronous 异步
“异步关系”是指两个相关事件发生存在时间的先后顺序。如下例中事件Evt1中“开始(start)”事件的发生先于事件Evt2中“离开(leave)”事件的发生。
Evt1 “Hall’slandmarkvisittoIraqstartedonSundayevening”
(译文:“Hall周日晚上开始对伊拉克进行一个具有里程碑意义的访问”)
Evt2 “U.S.DemocraticPartyCongressmanTonyHalllefthereThursday”
(译文:“美国民主党国会议员托尼·霍尔周四离开了这里”)
5.2 Comparison 比较
“比较关系”的两个事件的发生存在某些差异,并且突出这种差异。根据比较的趋势,本文将“比较关系”进一步划分为“对比关系”和“让步关系”。
(1) Contrast 对比
“对比关系”是指两个不同事件的共同属性具有不同趋势,突出两者的差异。例如下例分别对“营业收入增长(rise)”和“净利息增长(jump)”两个事件的比较。
Evt1 “Operatingrevenuerose69%toA$8.48billionfromA$5.01billion.”
(译文:“营业收入从50.1亿美元增长到84.8亿美元,增长了69%”)
Evt2 “Butthenetinterestbilljumped85%toA$686.7millionfromA$371.1million.”
(译文:“但是,净利息从3.711亿美元达到6.867亿美元,跃升了85%”)
(2) Concession 让步
Evt1 “IransignedtheAdditionalProtocolonNuclearSafeguardson18December2003”
(译文:“伊朗签署附加议定书于2003年12月18日核安全保障”)
Evt2 “Iranfornotprovidingtheagencywithmoretimelyandcomprehensivesupport.”
(译文:“伊朗没有提供该机构更及时和全面的支持”)
5.3 Contingency 偶然
“偶然关系”是指,一个原因事件Evt1的发生,能够对结果事件Evt2产生影响。根据原因事件对结果事件的影响方式不同,将“偶然关系”进一步划分为“因果关系”和“条件关系”。
(1) Cause 因果
“因果关系”的两个事件存在事实性的因果影响。原因事件Evt1是结果事件Evt2的必然条件,结果事件Evt2是原因事件Evt1的必然结果。如下例中,事件Evt2中的“摧毁(destroyed)”事件必然由事件Evt1的“轰炸(bombed)”事件导致,事件Evt1必然导致事件Evt2的发生。
Evt1 “TheybombedtheBogotaofficeslastmonth.”
(译文:“他们上个月轰炸波哥大办公室”)
Evt2 “Thebombdestroyeditscomputerandcausing$2.5millionindamage.”
(译文:“炸弹摧毁了它的计算机,造成250万美元的损失”)
(2) Condition条件
“条件关系”是指两个事件Evt1、Evt2,事件Evt1提出某种条件或场景,事件Evt2说明产生的结果。“条件关系”与“因果关系”的区别在于,“因果关系”中的原因事件为结果事件的必然条件,而“条件关系”中的原因事件为结果事件发生的可能原因之一。
Evt1 “IfthecartelsucceedsinblackmailingtheColombianauthoritiesintonegotiations”
(译文:“如果垄断联盟成功勒索哥伦比亚当局谈判”)
Evt2 “thecartelwillbeincontrolandFidelcanexploithispastrelationshipswiththem”
(译文:“卡特尔将被控制和Fidel可以利用他的过去与它们的关系”)
5.4 Expansion扩展
“扩展关系”的两个事件存在内容上的扩展,推动行文向前和事件的发生。本文将“扩展关系”进一步细分为“并列关系”、“递进关系”、“重述关系”和“实例化关系”。
(1) List并列
“并列关系”的两个事件是同一问题的几个方面,适用于事件的枚举。如下例事件Evt1和事件Evt2分别列举了两个“逮捕(arrest)”事件。
Evt1 “Thisweek,thegovernmentarrestedJoseAbelloSilva”
(译文:“本周,政府逮捕了JoseAbelloSilva”)
Evt2 “Later,anotherhigh-rankingtrafficker,LeonidasVArgas,wasarrested”
(译文:“后来,另一个高排名贩子Leonidas VArgas也被逮捕”)
(2) Progression递进
“递进关系”强调两个事件的连续性,事件Evt1为事件Evt2进一步的发展。如下例中“引渡(extradited)”事件Evt2为“逮捕(arrest)”事件Evt1的进一步发展结果。
Evt1 “Thisweek,thegovernmentarrestedJoseAbelloSilva.”
(译文:“本周,政府逮捕了Jose Abello Silva”)
Evt2 “JoseAbelloSilvawillprobablybeextraditedtotheU.S.fortrial.”
(译文:“JoseAbelloSilva将可能被引渡到美国受审”)
(3) Restatement重述
“重述关系”的两个事件为同一事件的不同表述。如下例中的事件Evt1和事件Evt2均描述“苏联解体(theSovietUnioncollapsed)”事件。
Evt1 “theSovietUnioncollapsed”
(译文:“苏联解体”)
Evt2 “theSovietUnioncollapsedinDecember1991”
(译文:“苏联于1991年12月解体”)
(4) Instantiation实例化
“实例化关系”的两个事件Evt1、Evt2,事件Evt1描述的事件具有更抽象的意义,而事件Evt2描述的事件包含于事件Evt1中,为事件Evt1的一个例子。如下例中,事件Evt1总述“核武器计划(nuclearweaponprogram)”事件,而事件Evt2为“核武器计划”事件的一项具体内容,即实例。
Evt1 “TheSovietnuclearweaponprogram”
(译文:“苏联的核武器计划”)
Evt2 “TheSovietculminatedinasuccessfulatomicbombtestin1949”
(译文:“1949年,苏联以成功原子弹试验达到顶峰”)
6 事件关系语料库构建与分析
本文根据事件关系检测的任务定义以及事件关系的类型体系,以FrameNet-1.5的新闻语料作为数据源,对每篇新闻文本中已标注的事件进行事件关系类型标注,本文标注的事件及其关系以单篇文本为作用域,不涉及跨篇章事件。为验证标注内容的合理性和一致性,本文对标注语料进行kappa值计算,用于对不同标注者标注语料的一致性检验。
6.1 语料选取
FrameNet由美国加州大学伯克利分校构建的基于框架语义学[13](Frame Semantics)的词汇资源,对词语意义和句法结构研究提供一种理论框架,并基于真实语料(新闻语料)进行标注,目前最新版本为FrameNet-1.5。FrameNet用语义框架(Semantic Frame,Frame)描述一个语义场景的一组概念,FrameNet-1.5中共包括1 019个Frame类型。
FrameNet-1.5中定义的框架类型大体分为三类: 事件(Event)、形式(Situation)和事物(Object)。本文将其中描述事件的语义框架称为作为事件框架,并且定义事件框架为所描述事件的事件类型(Event Type),由于FrameNet-1.5未对三类框架区分,本文对FrameNet-1.5中事件Frame进行人工选择,筛选所有标注框架集合中的事件框架,最终得到的事件框架共673种,即包含673种事件类型,确定的事件类型有助于事件关系的标注。因此,本文以FrameNet-1.5作为标注语料,将语料中标注为事件框架的实例作为事件,对其进行事件关系类型的标注。同时,FrameNet定义了更丰富的框架元素类型,平均每个事件框架实例含有两个框架元素,FrameNet共定义了725种框架元素类型,丰富的事件元素类型使得事件关系类型判定更明确。
6.2 事件关系标注
FrameNet-1.5根据定义的框架类型,对78篇新闻语料标注了框架类型、框架核心词以及框架元素,本文针对其中28篇新闻,以已标注的事件框架及框架元素为基础,进一步标注每篇新闻的“相关事件对”及事件关系类型。
FrameNet-1.5对新闻语料中的每个句子,以最细粒度标注其中包含的框架,同时,每个框架标注了该框架的核心词以及框架参与者。本文保留其中标为事件框架的实例,作为事件实例。同时,将事件框架中的框架核心词作为该事件的触发词,而框架元素为该事件的事件参与者。本文以FrameNet-1.5中已标注的离散的事件实例为基础,对其中的事件关系进行人工标注(事件关系类型参照第五节的事件关系体系)。本文的标注工作由两名该领域的研究人员(A1、A2)以及一名专家(B1)制定和完成。标注者将新闻语料中的相关事件以“相关事件对”的形式两两组合,接着对“相关事件对”的事件关系类型予以标注。目前的标注工作共包含1 004个事件,1 049个“相关事件对”及关系类型。本文统计各关系类型在新闻文本中的分布比例,表2为各事件关系类型的分布情况。
对文本的标注结果计算kappa值,度量两名标注者标注语料的一致性。新闻语料的平均kappa值为0.89,整体Kappa值较高,则认为两名标注者标注的语料具有较强的一致性。
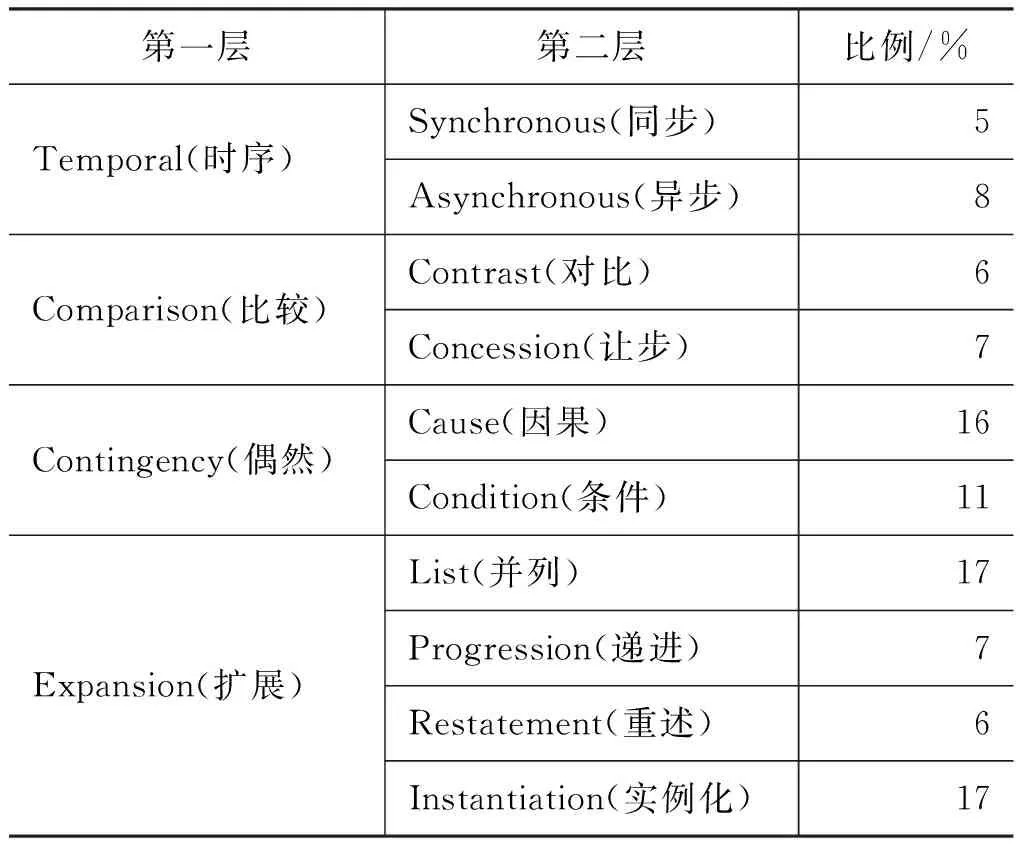
表2 事件关系类型分布
7 评价方法
事件关系检测将离散分布于不同文本中的事件构建“相关事件对”,并且进一步判断两个事件之间具有何种关系。该问题的输入为待测“事件对”,输出为“相关事件对”及其事件关系类型,因此,系统的性能优劣主要取决于识别出的“相关事件对”数目和正确判定关系的“相关事件对”数目。因此,事件关系判定转变为分类问题,即对事件之间属于何种具体关系类型的划分。针对这一分类问题,本文借鉴篇章关系分析研究大多采用的评价指标:Accuracy,具体计算公式如式(1)所示。
(1)
其中,TruePositve表示系统正确判定“相关事件对”以及其事件关系类型的个数,TrueNegative表示系统正确判定“非相关事件对”个数。All则表示待测“事件对”的总数。而针对本文问题,将Accuracy用于多元关系的性能计量,计量过程将True-Negative设置为恒定0值,只检验每个“相关事件对”是否获得正确的关系判定,即只计算TruePositve指标与All的比值,并将其作为准确率。
8 总结
事件关系客观存在于事件之间,具有客观性、逻辑性和规律性等特征。事件关系检测任务旨在自动检测事件间固有的逻辑关系类型。然而,目前专门面向事件的逻辑关系分析与处理,尚未形成一套完整的研究体系。本文通过分析和比较事件关系检测与篇章关系分析的异同点,借助篇章分析、事件抽取和场景理解等相关领域中的概念与数据资源,首次提出了基于篇章关系分析的事件关系检测体系。该体系包括事件关系检测的概念、关系体系以及评价方法等。同时,根据定义的事件关系体系,以Frame-1.5中新闻语料为数据源,对其中已标注的事件进行事件关系类型的标注。今后的工作在完善现有语料的同时,重点研究如何将篇章分析有效运用于事件关系检测任务中,从而形成信息流中事件关系的自动检测,构建事件关系网络以实现事件关系的推理和预测。
[1] T Chklovski, P Pantel. Global path-based refinement of noisy graphs applied to verb semantics[C]//Proceedings of Joint Conference on Natural Language Processing, Jeju Island, Korea, 2005: 792-803.
[2] P Pantel, M Pennacchiotti. Espresso: leveraging generic patterns for automatically harvesting semantic relations[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, Sydney, Australia, 2006: 113-120.
[3] Z S Harris. Mathematical Structure of Language[M]. New York, 1968.
[4] D Lin, P Pantel. Discovery of Inference Rules from Text[C]//Proceeding of the 7th ACM SIGKDD, San Francisco, California, USA, 2001: 323-328.
[5] E Pitler, M Raghupathy, H Mehta, et al. Easily identifiable discourse relations[C]//Proceedings of the 22nd International Conference on the COLING, 2008: 87-90.
[6] P E, R M, N HM, et al. Easily identifiable discourse relations[C]//Proceedings of the 22nd International Conference on Computational Linguistics (COLING 2008), Posters, Manchester, UK, 2008: 87-90.
[7] The Penn Discourse Treebank 2.0 Annotation Manual[R], 2007.
[8] Y Hong, X P Zhou, T T Che,et al. Cross-Argument Inference for Implicit Discourse Relation recognition[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management(CIKM 2012),2012: 295-304.
[9] N Daniel, D Radev, T Allison. Sub-event based multi-document summarization[C]//Proceedings of the Association for Computational Linguistics Morristown, NJ, USA, 2003: 9-16.
[10] H Yang, T S Chua, S G Wang, et al. Structured use of external knowledge for event-based open domain question answering[C]//Proceedings of the 26th Int’l ACM SIGIR Conference, Toronto, Canada, 2003: 33-40.
[11] S A Mirroshandel, G G Sani. Temporal Relations Learning with a Bootstrapped Cross-document Classifier[C]//Proceedings of the 4th International Workshop on Semantic Evaluations, Prague, 2007: 75-80.
[12] Y Hong, J F Zhang, B Ma, et al. Using Cross-Entity Inference to Improve Event Extraction [C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, June, 2011: 19-24.
[13] C J Fillmore.Frame semantics and the nature of language[J].Annals of the New York Academy of Sciences,1976: 20-32.
An Overview of Event Relation Detection System
YANG Xuerong, HONG Yu, CHEN Yadong, YAO Jianmin, ZHU Qiaoming
(Provincial Key Laboratory of Computer Information Processing Technology Soochow University, Suzhou, Jiangsu 215006,China)
Event relation detection is the task to detect the event relation from information stream of texts. Treating the event as the basic semantic unit, the relation type is determined by analyzing the feature of semantic relevancy between events. The event relation detection includes event relation identification (identifying whether the event pair is related or not) and event relation type decision (deciding which relation between relevance events, e.g. cause relation). In this paper, we try to establish a system of event relation detection in light of the concepts and data resources of discourse analysis, event extraction and scene understanding, covering the issues of the task definition, classification system of event types, corpora acquisition and annotations evaluation methodology, etc. Finally, we not only emphasize the analysis and comparison of the difference between event relation detection and discourse relation analysis, but also present the difficulty and challenge of the event relation detection.
event relation detection; discourse relation analysis; event; argument; semantic relation

杨雪蓉(1990—),硕士,主要研究领域为事件关系检测和信息抽取。E-mail:xuerongyang0650@gmail.com洪宇(1978—),博士,副教授,主要研究领域为话题检测、信息检索和信息抽取。E-mail:tianxianer@gmail.com陈亚东(1990—),学士,主要研究领域为信息抽取。E-mail:chinachenyadong@gmail.com
1003-0077(2015)04-0025-08
2013-06-26 定稿日期: 2015-05-28
国家自然科学基金(61003152,61272259,61272260)
TP391
A
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
通信技术(2021年12期)2022-01-25
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年1期)2021-03-29
新世纪智能(数学备考)(2020年11期)2021-01-04
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
燕山大学学报(2015年4期)2015-12-25
新高考·高一物理(2014年1期)2014-09-18
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
