
海量气象数据实时解析与存储系统的设计与实现*
2015-03-19 00:36王若曈黄向东王建民
计算机工程与科学 2015年11期
王若曈,黄向东,张 博,王建民,罗 兵
(1.国家气象中心,北京100081;2,清华大学软件学院,北京100084)
1 引言
实时气象数据种类繁多,并具有非常大的数量和容量,是名副其实的领域大数据。据统计,在天气预报中,服务器每天都要新存储约1 500 万个500KB至10 MB大小不等的数据文件,未来则会达到每天1亿个新文件,日增量50TB 以上,预报员使用这些海量数据时,通常需要达到至少每秒10个文件的连续阅读速度以产生视觉动画效果,方可进行高效率天气预报。
气象数据中很重要的一种数据称为“模式数据”。模式数据是由高性能计算机根据当前天气实况数据通过物理方程计算而成的,模式数据每天计算2~4次或更多次,每次生成大概1 000个物理量从当前时刻至未来240小时时效(或更长)的一系列二进制网格数据,时效通常3小时间隔,每个网格值代表经纬度网格上的一个物理量值,一个文件大小通常在1 MB~2 MB 之间。由于模式物理量多,每天多次起报,预报时效密集,模式种类多,存储时间较长,因此在气象数据中,无论从数据个数还是数据存储量来说,模式数据是比重最大的“大数据”。
根据国家气象中心(中央气象台)的统计,预报员常用的实时气象数据在服务器端的快照平均约等于5千万个,总容量大概为100TB,其中70%为模式数据。
随着气象数据规模的持续高速增长,全国天气预 报 平 台MICAPS(Meteorological Information Comprehensive Analysis Processing System)[1]3.0版自2010年起就开始面临严峻的性能和存储压力。
(1)海量气象数据在解析、写入方面存在挑战。
气象数据对时间、可靠性非常敏感。除模式数据,气象数据还包括卫星、雷达、地面、探空等实况数据。每一个数据对预报的准确率都具有至关重要的作用。因此,任何由于原始数据解析/写入系统故障导致的数据丢失或延迟都是不能容忍的。
(2)海量气象数据的存储面临访问与查询缓慢的问题。
以MICAPS 3.0 为例,目前国内外气象数据存储技术仍多以基于目录树形结构的文件系统进行组织。而传统文件系统往往难以承受每日百万级的文件数量增长,且文件目录的树形结构不能很好地满足预报员对数据进行按序访问的特点,比如按照时间顺序浏览数据。据测量,在现有的基于文件系统的天气预报系统中,当系统存储数据文件个数达到2 000万个时,仅服务器端文件定位时间就要耗时500ms,按序访问时间将更长,无法很好地满足应用需求。传统关系型数据库虽然具有排序和索引能力,但其固定的关系表模式使得系统设计十分复杂,其磁盘存储结构也限制了其有序访问的优化。因此,无论文件系统还是传统数据库技术的存储和查询方式都无法很好地满足气象数据的高性能查询。
图1为气象数据处理流程图,原始数据经采集、分发、解析、存储,最终在预报员工作平台上进行可视化,经过预报员的分析判断,制作天气预报结果,向公众发布。

Figure 1 Meteorological data processing flow图1 气象数据处理流程
为提升海量气象数据的实时处理能力,实现MICAPS客户端对于气象数据更高效的应用,中国自2013年正式启动MICAPS第4版(简称MICAPS 4)的研发工作,其中海量气象数据实时解析与存储系统是MICAPS 4的核心系统之一。该系统必须能够实现海量数据实时、可靠的解析与写入,支撑上百TB 级的数据存储,客户端毫秒级延迟访问以及7*24小时的稳定运行。
目前MICAPS 4 已经投入运行,有力支撑着全国天气预报业务。本文将针对气象数据模型的特点以及用户行为,详细描述MICAPS海量气象数据实时解析与存储系统的设计原理、构架与实现细节。
本文第2节介绍对气象数据解析和存储的相关研究工作;第3节介绍海量气象数据实时解析系统的设计与实现,详细描述了该子系统的所有关键模块及实现原理;第4节介绍基于非关系型分布式Key-Value数据库,以及多维索引数据模型的海量气象数据存储系统的设计实现,该存储系统可以满足全体MICAPS用户毫秒级查询;第5 节实际测量解析系统和存储系统的性能,并加以分析;第6节进行总结。
2 相关工作
在气象数据存储技术领域,当前业界仍以基于传统文件系统的技术为主。
文献[1]描述了针对MICAPS 3.0 客户端进行性能优化的方案,但仅限于客户端图形渲染算法的改进,对于如何提升服务端数据获取性能并没有给出解决方案。
文献[2]指出,由于以气象数据为例的多维数据文件的复杂性和海量性,一般商业数据库的适应性受到很大限制,而文件系统则成为较为经济的存储方法。
文献[3]以天气预报行业为例,提出采用传统文件系统进行多维数据的存储,并在上层使用Samba等协议工具提供远程存取服务。实际应用中使用文件系统时,往往以不同维度作为目录,构建出一个树形结构存储。每种维度作为目录树的一层内部节点,数据文件作为树的叶子节点。为了形成树形结构,需要人为规定数据文件维度的层次关系。这种方式简化了系统设计,对于数据文件的存储交由服务器的文件系统完成。然而由于文件系统本身并不考虑不同文件的逻辑顺序,对于维度的有序访问时,只能通过获取某一目录下所有文件,并进行手动排序,即对叶子节点进行排序。当对其他维度进行排序时,则需要过滤不同中间节点的叶子节点,并进行合并和排序。当文件数量达到百万、千万级时,文件定位的速度将出现显著下降。
文献[4]给出了基于SAN(Storage Area Network)和GPFS(General Parallel File System)的高性能气象数据存储集群架构,能够很好地解决海量存储、容灾备份等特点,然而并未对数据有序获取进行优化。
文献[5]提出了利用NetCDF文件格式进行气象数据的表示和存储,这种方案可以将大量小文件打包为一个大文件,减少了小文件个数。但是,由于NetCDF文件本身并不支持索引在各个维度的按序检索功能,无法满足预报员快速时空翻页的需求。此外,由于依赖传统文件系统,采用了集中式存储,该方案在面对大规模并发访问时也存在性能隐患。
文献[6]提出了针对气象数据的多维数据空间模型,并给出采用基于Key-Value 的存储系统Cassandra对其进行实现的方法。然而文献[6]仅给出了多维数据到Cassandra存储结构的转换指导方法,并未给出确切的Cassandra存储结构,此外,作者并未对数据的操作建立足够的索引,导致部分查询可能存在性能问题。并且文献[6]中并未给出兼容传统文件视图的方法。
非关系型数据库在处理海量数据方面具有较强优 势[7],以Hbase、Cassandra[8]为 代 表 的 基 于Key-Value的存储系统广泛应用于大数据场景。文献[9]提出了基于Cassandra的大规模装备监测数据的存储模式设计,一些弱一致性存储系统[10]也常常用于实现低延迟的存储与读取操作。
在数据的ETL 方面,现有工作往往没有考虑分布式的实现[11,12],并且对非结构化数据的讨论不足。这也导致了现有工作无法很好应用在气象领域。Zhu Y 等人[13]设计了非结构化数据管理系统laUD-MS,该系统对于音视频等数据做了优化,但缺少高效的数据解析模块。有人提出使用MapReduce对文件数据进行解析[14],然而依赖MapReduce的方法无法满足气象数据的时效性。
3 海量气象数据实时解析系统
一个实时解析系统需要具备高吞吐、高容错、高性能、高可扩展性四个要素。本节首先从四个要素介绍解析系统的设计思想,然后详细介绍解析系统各个模块在气象数据实践中的应用。
3.1 设计思想
(1)高吞吐设计。
高吞吐是指解析系统输入数据源数据量大,对于气象数据,海量数据往往集中到达,需要系统解析速度与数据输入速度基本相等。此外,随着业务的发展,需要能够快速地扩充系统的吞吐量。
为此我们采用了P2P 分布式架构。在解析系统中,设置多台工作节点,每台节点仅负责特定种类的数据。当数据到达时,不同数据会选择不同的节点进行解析。一个节点的资源(带宽或者CPU等)达到上限时,加入新的节点进入集群,新节点将接管资源紧张节点的部分数据解析工作。
(2)高容错设计。
高容错是指任意时刻,不允许系统暂停服务的故障。由于数据流式到达,系统宕机将丢失数据。
为防止单点故障,所有服务器节点均采用虚拟化技术,利用IP 地址漂移,具有冗余的物理备份,发生服务器故障时,可以热切换到备份服务器而不影响数据接收。每台解析服务器均采用双网卡,连接到两个内部交换机,从而避免交换机故障。
(3)高性能设计。
高性能设计是指尽可能充分利用系统资源,在给定硬件环境下达到尽可能好的性能。
整个解析流程划分为数据到达、任务分发、数据解析、数据持久化四个阶段,不同的阶段耗时不同,例如,解码任务耗时较久,而数据持久化耗时较短。若简单采用多线程技术进行上述阶段的执行,会由于前一阶段过慢而降低整个系统的性能,或由于前一阶段过快、后一阶段过慢而增加缓存占用。
我们采用了SEDA (Stage Event Driven Architecture)架构,将每个阶段变成异步操作。每个阶段都拥有自己的资源(即线程池),通过调节不同阶段的资源数,可以达到系统资源的最大利用,并使得各个阶段的速度达到平衡。
此外,该架构下可以方便地重新调节各个阶段的资源,使得在数据处理速度发生变化时,系统能够动态保持平衡。
(4)高可扩展性。
由于气象数据种类多变,现有解码模块无法处理新的气象数据类型,因此系统必须在不重启的情况下扩展对于新兴数据的处理能力。
我们采用Java的反射机制,进行解码功能的动态加载。为了降低Java反射机制导致的性能问题,我们采用交互方式进行解码功能的扩展。通过控制程序,JVM 动态加载新的解码实现,并映射该解码器所能处理的数据类型到内存中,当新的数据类型到达时,新的解码器开始工作。
3.2 海量气象数据实时解析系统的设计
图2为MICAPS 4海量气象数据实时解析系统的总体设计,粗箭头代表数据流,描述了原始气象数据接收、解析、写入、存储、客户端访问的全过程,本节将讨论实时解析系统的关键模块。
数据触发器:气象数据国际标准采用FTP 协议传送,但商业化FTP 服务器通常只具备数据接收功能,从而只能通过目录轮询来判断数据是否到达,影响了处理效率。在MICAPS4实时解析系统中,没有采用基于数据时间表的传统轮询策略,而是研制了经扩展的FTP 服务器组件,每一个数据接收完成立即发送消息,保证解析程序的实时处理。
解码执行线程池:数据触发器保证了数据到达即处理,为了不影响新数据接收,解析系统对于数据解析的过程是异步的,这样同一时间内可能会有大量的解析任务并发运行。实时解析系统利用解码执行线程池来保证该过程的稳定、高效。根据处理数据类型的不同,解码执行线程池均被设置了不同的线程数阈值,达到这个阈值后,新任务将等待,避免过度消耗系统资源。对于模式数据,由于GRIB[15]压缩率较高,解码需要消耗很大的内存,因此处理模式的解析服务器线程阈值较小。而处理雷达、卫星的解析服务器,数据量密集,IO 消耗大,而CPU、内存消耗小,为尽快完成数据的写入,在这些服务器上保持了较高的线程数阈值。
解码任务:解码任务对应解码执行线程池中的一个线程,实现对于一个具体气象数据的解析。解析过程需要用到一些算法模块,如GRIB 解码、网格裁剪等,这些算法的调用方式为同步调用。
临时文件数据池:原始数据以及气象算法加工过程中中间结果将在解析服务器上保存一段时间,由文件清除器后台线程定期删除。当存储服务器发生故障时,文件恢复器将这些数据重新加载到解码任务分发器,就可以实现数据快速恢复。
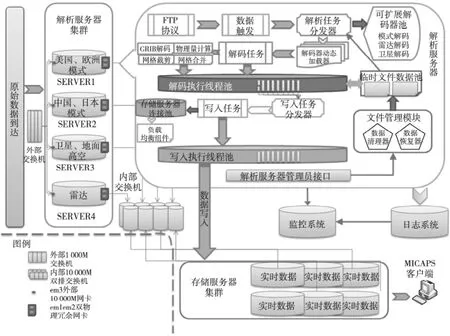
Figure 2 Design of massive data realtime parsing servers图2 海量数据实时解析服务器设计
数据写入:原始数据解析为客户端数据格式后,写入任务分发器将数据派发给写入任务,放入写入执行线程池中向存储服务器写入。写入任务利用存储服务器连接池以及负载均衡组件保证对于每台存储服务器的平衡。由于存储服务器可能出现硬件故障,因此连接池及负载均衡器还具备修复和切换连接的功能。
日志与监控:解析系统在原始数据接收、解码、写入的全过程中,均记录了不同优先级的日志信息,既便于对系统故障的人工诊断,也为监控系统提供了信息。部署在解析服务器上的监控进程定时提取解析日志,向监控服务器汇报解析系统的健康状况。解析进程与监控进程是部署在相同服务器上的两个独立进程,这是为了避免监控系统影响解析系统的性能与稳定性。
4 海量实时气象数据存储系统
本节首先深入分析实时气象数据的多维索引模型与用户行为,然后介绍该模型的实现,以及针对用户行为的模型扩展结构设计与实现,该实现可以高性能满足用户的各种查询需求。
4.1 气象数据多维索引结构与用户行为分析
4.1.1 多维索引空间结构
气象数据是典型的非结构化数据,并且具有多维索引结构和Key-Value特点,每类数据都可以由一个多维索引唯一确定一个数据值,这个数据值可以是一个模式网格,也可以是一个卫星数据等。各类数据的多维索引表示如下:
模式数据:模式名、物理量、层次、起报时间、预报时效,如欧洲模式8日20 点起报,24小时之后(即9日20时)的850百帕全球温度场。
地面数据:观测时间、观测内容的自然语言描述字符串,如5月13日早8点,全国国家站地面观测实况。
高空数据:观测时间、层次、观测内容的自然语言描述字符串,如13日晚8点,850hPa,全国高空填图。
卫星数据:卫星名称、观测时间、通道、投影方式。
雷达数据:雷达ID、观测时间、物理量、仰角、投影方式。
地面、高空、卫星、雷达统称实况数据。
以模式数据为例进行数据模型抽象:
如表1所示,在某模式(Model)数据中,某个具体数据(File)可以通过物理量(Element)、层次(Level)、起报时间(Time)、预报时效(Period)唯一确定。因此,由五个索引可唯一确定一个文件F,即(M,E,L,T,P)→F。

Table 1 Multi-dimensional index structure of model data表1 模式数据多维索引结构
4.1.2 用户行为抽象
预报员常用的操作包括“指定数据”“最新数据检索”“左右翻页”“上下翻页”“目录查看”等操作,占全部操作70%以上。用户必须通过流畅的翻页操作形成的视觉动画效果实现对于未来天气状况的预测。基于气象数据多维索引结构,我们对五种高频率用户行为进行抽象:
(1)“指定数据”,用于直接显示某时间点的气象数据。即指明需要数据的全部多维索引值,直接命中该数据。
(2)“最新数据检索”,即用户希望通过仅部分索引得到相关数据。比如用户不能准确指定最新时间的前提下,希望服务器返回最新观测时间的卫星数据。
(3)“左右翻页”用于快速查看天气状况随时间的演变情况。模式数据的“左右翻页”操作是在保持其他维度索引固定的前提下,对于“预报时效”索引进行双向快速连续变化。实况数据的“左右翻页”操作是保持其他维度索引固定的前提下,对“观测时间”索引进行双向快速连续变化。例如,对(日本模式,相对湿度,850hPa,13日8时起报,3小时时效)右翻页的结果为:(日本模式,相对湿度,850hPa,13日8时起报,6小时时效)。
(4)“上下翻页”用于快速查看天气状况随高度的变化状况。模式数据、高空数据的“上下翻页”操作是保持其他维度索引固定的前提下,对“层次”索引进行双向快速连续变化。例如,对(日本模式,相对湿度,850hPa,13日8时起报,3小时时效)上翻页的结果为:(日本模式,相对湿度,700hPa,13日8时起报,3小时时效)。
(5)“树形检索”,用户多年来一直使用文件系统URL 来进行元数据浏览,查看服务器当前存储了哪些气象数据,该方法方便直观,即使不采用文件系统作为存储,新的存储系统也应保留用户基于目录树的访问行为。
综上所述,实时气象数据模型具有多维度,部分维度有序,部分维度无序的特点。在这种数据上,常用操作包括:在有序维度上按序遍历数据,在无序维度上随机访问数据,并且按序访问保证高性能。
4.2 基于多维索引数据模型的实现
文献[6]提到,Cassandra 是一个基于Key-Value的P2P分布式系统,适合作为多维数据空间结构的实现[6],这同气象数据多维索引键值结构相呼应。同时,在文献[6]中,在海量小文件场景下,对Samba、HDFS、Cassandra等存储方案进行了详细的理论分析和性能对比,并分析了每种方案的应用场景。由于Cassandra在存储具有多维空间特点的海量小数据方面具有显著的优势,因此我们采用Cassandra作为实时气象数据存储的实现方案。
4.2.1 数据表
针对实时气象数据内容存储,我们设计如下Column Family,见表2。
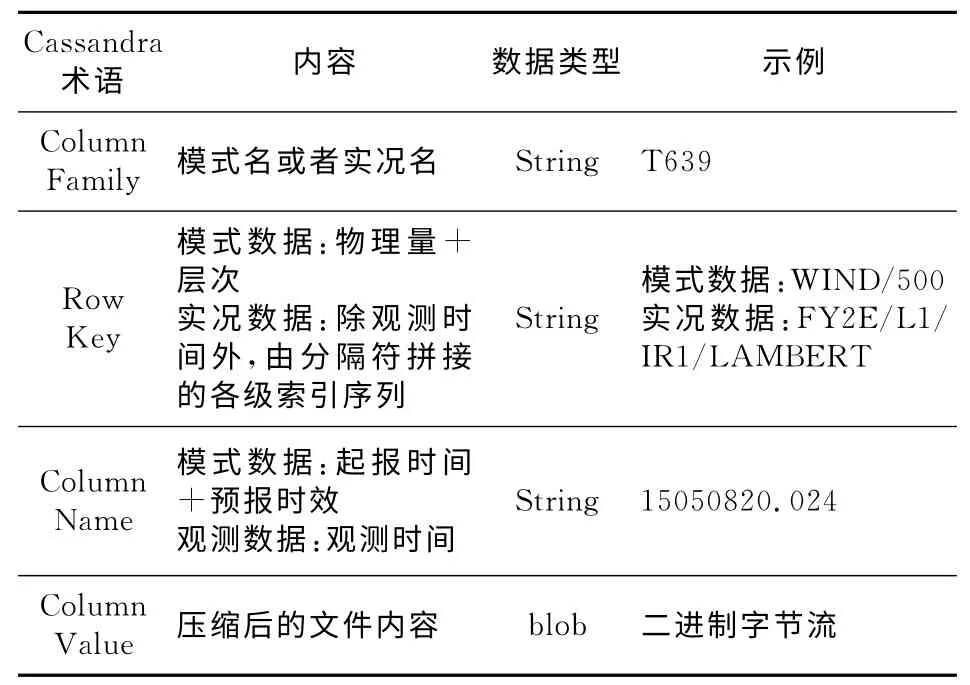
Table 2 Data table表2 数据表
这种数据存储设计支持随机指定数据的读取,还可支持有序访问。例如,在T639模式CF中,当用户查阅WIND 的500hPa层次下15050820 时刻24小时时效的数据后,如果希望查看下一个时效的数据,由于用户并不能确定下一个预报时效的数值,传统文件系统只能进行文件列表获取。而在这种设计中,由于列是按序存储在磁盘上的,在指定了15050820.024列后,利用区间查询,即可找到下一个列:如15050820.027,也可快速命中前一个时效的数据如15050820.021。因此,这种数据库设计是紧密切合左右翻页应用(即有序访问)需求的。
4.2.2 维度索引表
针对其他维度的有序访问,我们通过维度索引表实现,我们设计了如下Column Family,见表3。
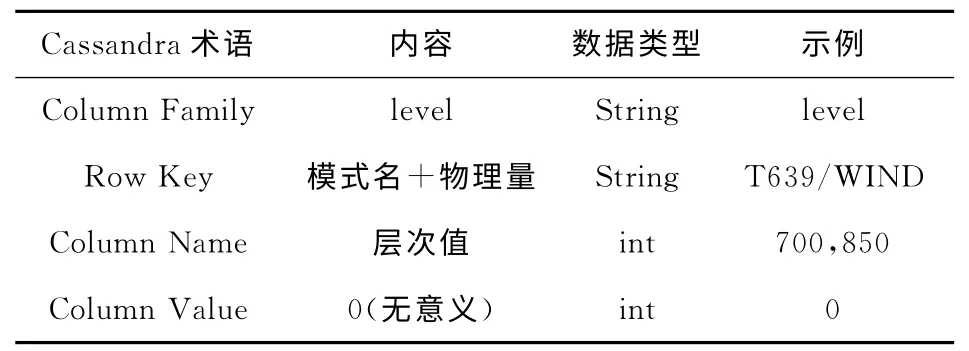
Table 3 Dimension index table表3 维度索引表
利用维度索引表和数据表,可以实现数据的上下快速翻页,比如用户当前正在浏览850hPa的T639风场数据15050820.024,希望切换至上一层(700hPa)相同时间点的数据,则可利用T639/WIND/在列族level 中查找到上一层应为700hPa,进 而 利 用T639/WIND/700/15050820.024在数据表中直接定位所需数据。
4.2.3 最新时刻表
在实时气象数据应用中,用户不能确定当前系统中最新数据的完整名称,因此无法指定确切的数据索引。因此,需要设计一个列族用于存储该信息。Column Family设计如下,见表4。
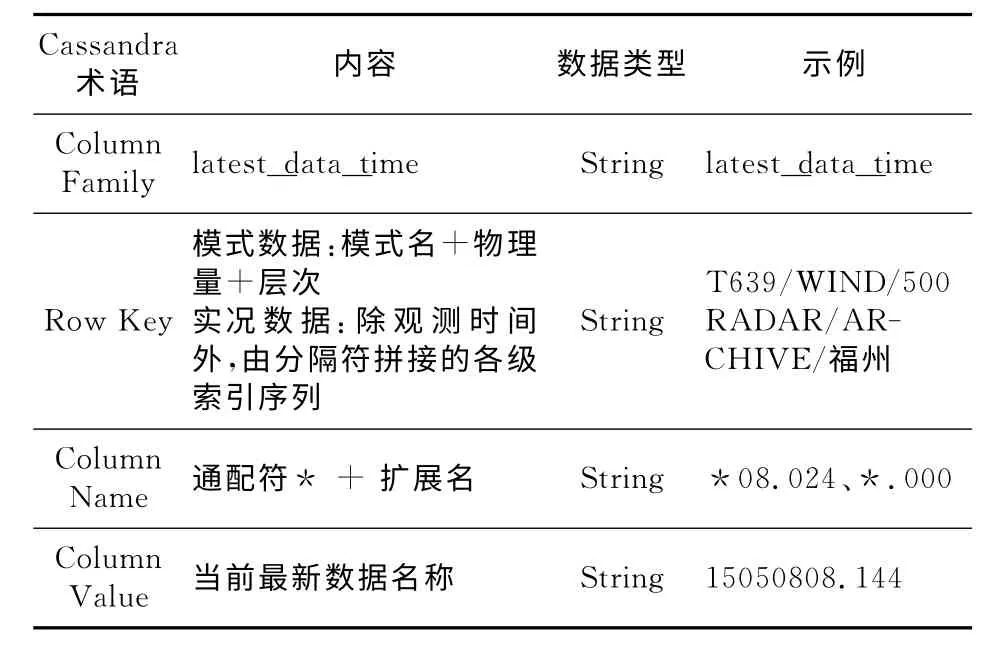
Table 4 Latest data time table表4 最新时刻表
利用最新时刻表,即可实现最新数据的快速模糊查找,例如用户提出请求“T639/WIND/500,*.024”,表示希望获得T639在500hPa风场的最近一次起报的24小时预报时效的数据,利用用户传入的参数,立即可以在列族latest_data_time中找到该数据的准确名称为15050820.024,则用户进一步根据完整索引WIND/500/15050820.024,即可在数据表T639中检索到对应的网格数据。
4.2.4 虚拟文件视图表
在实际生产系统中,新系统往往要兼容旧系统的使用方式。利用Cassandra来对传统文件系统进行改造,极大提升了海量小文件的查询性能,但造成了原始数据的浏览不如文件系统直观,预报员无法通过资源管理器直观看到文件系统的树形目录结构,这样会造成用户不知道服务器存储了哪些数据,进而需要客户端庞大复杂的配置文件才能实现对于服务器的访问。为了解决这个问题,同时为了保留现有用户的使用习惯,我们设计了列族treeview,基于数据库环境,建立模拟文件系统的仿真环境,用户可以直接利用树形控件浏览全部数据,完全像同原有的Samba文件系统交互一样。Column Family设计如下,见表5。
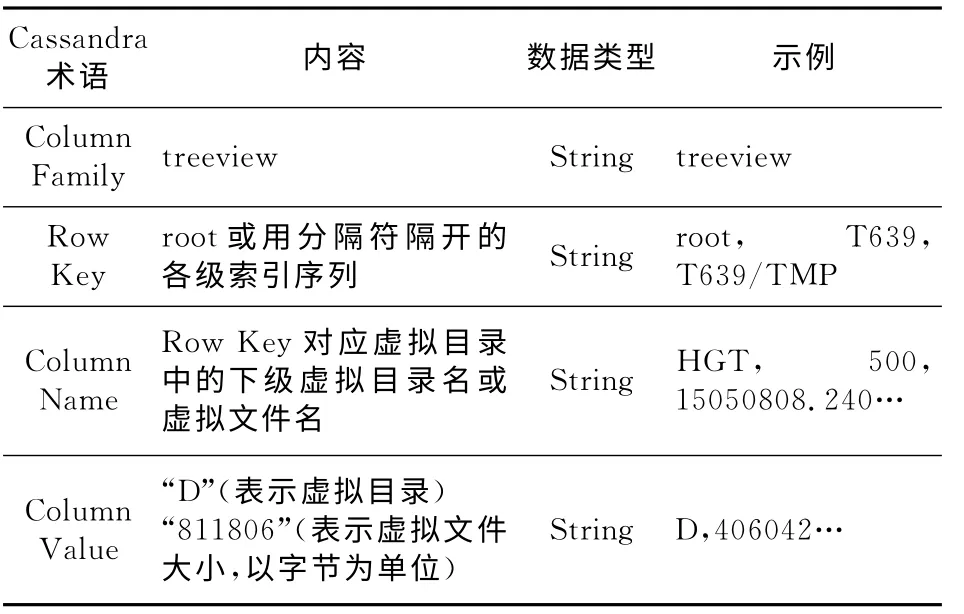
Table 5 View of virtual files表5 虚拟文件视图表
用户首先可以检索到根元素root下全部数据的CF分类,即有几大类气象数据,得到T639,RADAR 等列族,通过T639,可以得到T639下的物理量列表,如温度TMP,高度HGT 等,传入T639/HGT 又可以得到T639高度场有哪些层次,这时可以得到100,200,300,…,850,925,1000等,通过T639/HGT/500可以得到T639 模式500hPa高度场下的全部数据名称,如15050720.000—15050720.240,15050808.000—15050808.240,15050820.000—15050820.240,利用数据名称的完整信息即可在对应的数据表中对该数据内容直接进行检索。
5 海量气象数据实时解析与存储系统性能测量
5.1 海量气象数据处理系统硬件环境
在MICAPS 4 数据环境中,采用机架服务器组成实时解析服务器集群以及分布式数据存储集群,用于海量气象数据的实时解析与存储。各集群以及MICAPS 4客户端均通过千兆网络相连。除外部交换机外,解析集群、存储集群还通过双千兆内部交换机相连,避免集群内部网络数据交换影响外部网络,同时避免交换机单点失效。运行经验表明,数据存储副本数为3时即可获得较优异的访问性能。
MICAPS 4数据环境的网络拓扑结构如图3所示。
数据解析服务器和数据存储服务器的硬件配置信息如表6所示。
5.2 测量结果与分析
首先,我们测量存储集群的访问性能。

Figure 3 MICAPS 4system topology图3 MICAPS 4系统网络拓扑图

Table 6 Hardware configuration表6 硬件配置表
在真实MICAPS 4业务环境下集群的性能测量结果如表7(50并发)和表8(100并发)所示(输出的时间为数据库查询时间+网络传输时间的总和)。可以看到,针对不同类型的数据,不同的并发数,最新时刻表的平均访问时间几乎都在1ms左右,说明随机访问最新数据时,查找最新数据索引值耗时代价相当小,甚至可以忽略。
从读取数据的性能观察,读取时间和单个数据的字节数近似成正比,这说明大量的时间消耗在网络传输上,而数据库查找键值的定位时间很小。欧洲粗网格数据的最高随机读取时间是14.2ms,最低读取时间为3.03ms,除去网络传输时间,说明数据库在模式数据定位过程的时间消耗为10 ms量级,甚至更少。所有数据最高读取时间和平均读取时间差别较大,但最低读取时间和平均读取时间相差较小,说明在第1次读取数据时,由于数据没有被缓存到服务器内存,因此需要通过磁盘读取,速度稍慢,一旦常用数据被缓存进入内存,之后的读取就具备了很高的性能。由于每台服务器内存高达128GB,基本可以满足全部用户常用数据的缓存。
左右翻页操作实际上是针对Cassandra的列进行有序连续读取,从测量数据看,大部分左右翻页时间也消耗在网络传输上,只有极少量(通常是前几次)左右翻页的操作稍慢,平均翻页速度很快。以FY2E 卫星数据为例,即使在最差情况下,也可以保证每秒20 帧卫星数据的读取性能(1000/48.6=20.6),其他数据也可以保证至少5~10帧/秒的左右翻页性能。左右翻页(有序访问)的速度往往是随机访问的1.5倍,这个时间开销集中在有序列的区间查找操作上。
上下翻页(不依赖于Cassandra的有序访问)的时间开销近似等于随机访问时间加上一个很小的常量数值,这也与维度索引表+数据表的实现机制是吻合的。事实上,我们扩充的索引表的性能比Cassandra自身的区间查询性能更好,保证了用户在各个维度各个方向连续读取都具备很好的性能。同时也说明,利用索引表+随机访问,可以实现任意数量有序维度数据的连续访问。
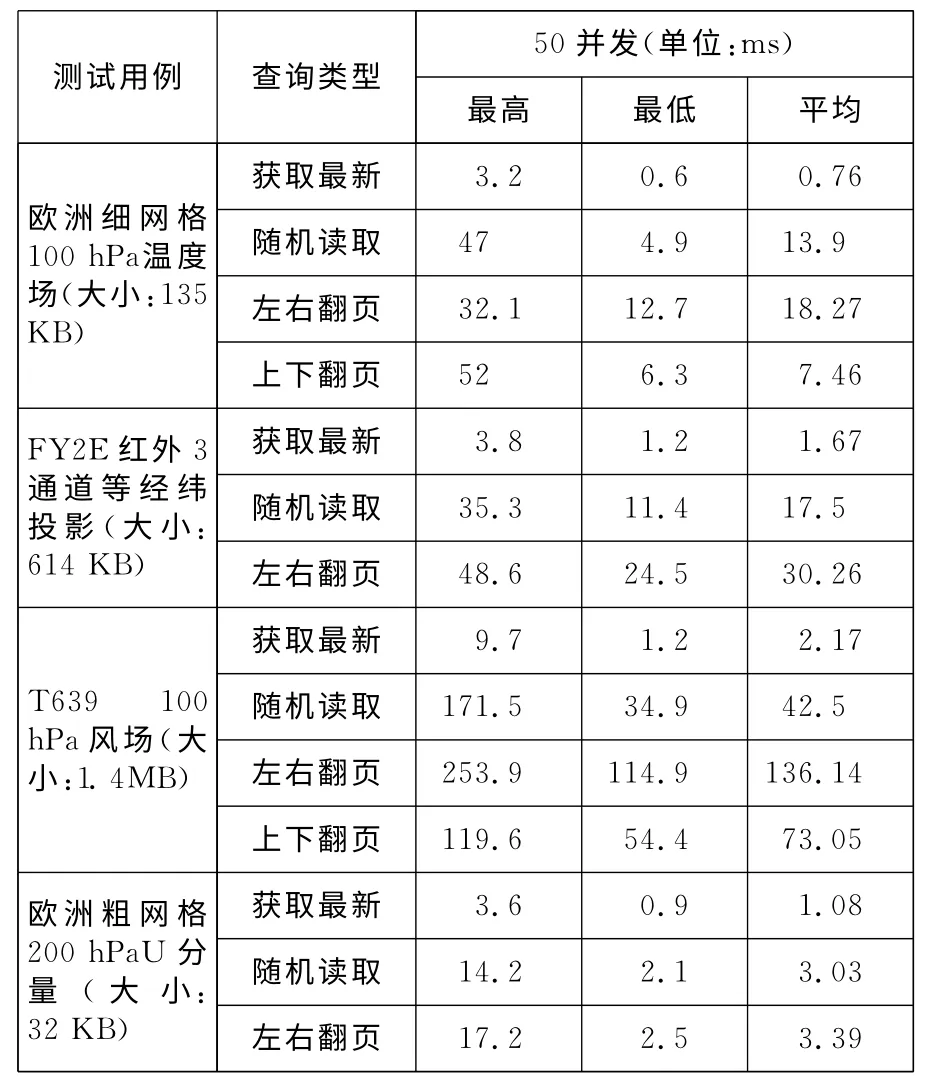
Table 7 Query performance when concurrence number is 50表7 50并发下的查询性能
当并发数在100时,系统并发负载量为50用户的2倍,但是从各类数据不同操作的平均时间来看,没有出现时间消耗翻倍增长的情况,大部分操作的平均时间只是略大于50用户并发时的测量结果,个别操作甚至出现比50用户并发性能更好的情况(如T639风场左右翻页)。从单个T639风场数据大小看,100用户的并发访问需要的网络传输总量已经超过了单台服务器的网络额定带宽,但是由于存储集群副本的存在,并发访问的用户将被分配到不同的协调者节点上,这样就会分担每台服务器的压力,提升用户访问性能,偶尔出现的并发数增加性能提升,可能因为访问请求被分配到负载较轻的节点上,或者协调者节点恰好是数据所在节点,从而避免了集群内部的数据传输。
在具有2 000万个小文件的Samba服务器上进行同样数据的读取和翻页测试,欧洲细网格数据获取最新文件名需要3.4s,随机读取需要0.9s,左右翻页需要4s,上下翻页需要1.5s。这是因为文件系统不具有按序索引的功能,在海量小文件的文件系统中获取文件列表手动排序是非常大的开销。
表9为实时解析系统对Cassandra的写入性能。
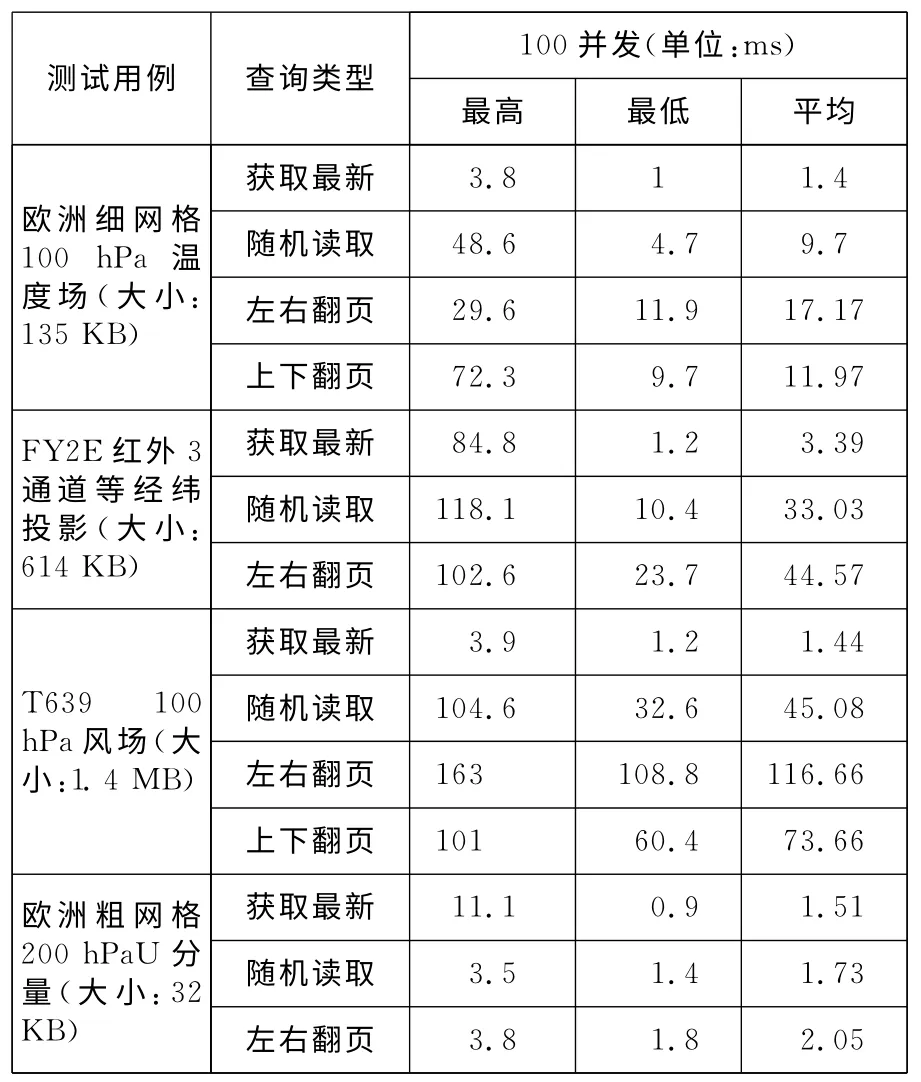
Table 8 Query performance when concurrence number is 100表8 100并发下的查询性能

Table 9 Realtime parsing system performance表9 实时解析系统性能
从表中看出,所有数据到Cassandra的写入速度都较快。模式数据写入速度慢于其他数据,这是因为模式数据GRIB 解压缩耗时较长,生成MICAPS数据格式后才能进行写入。此外,向Cassandra集群写入的数据均为大量的小数据,这也会在一定程度上影响网络总体传输性能。
表10为相同数据集对Samba服务器的写入性能。

Table 10 MICAPS 3.0data parsing and writing performance表10 MICAPS 3.0数据解析与写入性能
可见基于Cassandra的实时解析与存储系统比传统文件系统具有明显的数据写入优势,而且单个数据越小,数据个数越多,优势越明显。这是因为数据库系统由于内核的大量优化,更适合于小数据的写入。
6 结束语
本文讨论了海量气象数据实时解析系统以及基于Cassandra的分布式气象数据存储系统。这两大系统保证了气象数据实时可靠的写入,满足了国家级MICAPS4预报平台用户的高性能数据访问需求。该系统目前7*24小时支撑着全国天气预报业务的正常运行,具有很好的稳定性和扩展性,在实践中得到了充分验证。
[1] Li Yue-an,Cao Li,Gao Song,et al.The current stage and development of MICAPS[J].Meteorological Monthly,2010,36(7):50-55.(in Chinese)
[2] Wang Jing-li,Tan Xiao-guang,Zhang De-zheng,et al.Design and application of data access structure of metropolis meteorological service information system[J].Meteorological Science and Technology,2004,31(6):409-412.(in Chinese)
[3] Qi Gui-bin,Zhou Er-bin,Ju Yang.Using samba service to realize information sharing[J].Heilongjiang Meteorology,2012,28(4):40-41.(in Chinese)
[4] Zhao Chun-yan,Sun Ying-rui,Dong Feng,et al.Application of high performance meteorological data storage cluster and online extension[J].Computing Technology and Automation,2013,32(3):117-121.(in Chinese)
[5] He Zhen-fang,Zhang Yao-nan,Zhao Guo-hui.Storing massive spatio-temporal data using parallel NetCDF[J].E-Science Technology & Application,2012,32(1):54-61.(in Chinese)
[6] Huang Xiang-dong,Wang Jian-min,Ge Si-han,et al.A storage model for large scale multi-dimension data files[C]∥Proc of NDBC,2014:1.(in Chinese)
[7] Sakr S,Liu A,Batista D M.A survey of large scale data management approaches in cloud environments[J].IEEE Communications Surveys Tutorials,2011,13(3):311-336.
[8] Lakshman A,Malik P.Cassandra—A decentralized structured storage system[J].Operating Systems Review,2010,44(2):35.
[9] Zhong Yu,Huang Xiang-dong,Liu Dan.NoSQL storage solution for massive equipment monitoring data management[J].Computer Integrated Manufacturing Systems,2013(12):3008-3016.(in Chinese)
[10] Zhu Y,Yu P S,Wang J.Recods:Replica consistency-ondemand store[C]∥Proc of 2013IEEE 29th International Conference on Data Engineering (ICDE),2013:1360-1363.
[11] Gorawski M,Gorawska A.Research on the stream ETL process[M]∥Beyond Databases,Architectures,and Structures,2014:61-71.
[12] Bansal S K.Towards a semantic extract-transform-load(ETL)framework for big data integration[C]∥Proc of 2014IEEE International Congress on Big Data (BigData Congress),2014:522-529.
[13] Zhu Y,Du N,Tian H,et al.laUD-MS:An extensible system for unstructured data management[C]∥Proc of the 12th International Asia-Pacific Web Conference(APWEB),2010:435-440.
[14] Um J H,Jeong C H,Choi S P,et al.Fast big textual data parsing in distributed and parallel computing environment[M]∥Mobile,Ubiquitous,and Intelligent Computing.2014:267-271.
[15] Manual on Codes-International Codes,Volume I.2:Part B and Part C.[EB/OL].[2015-05-11].http://library.wmo.int.
附中文参考文献:
[1] 李月安,曹莉,高嵩,等.MICAPS预报业务平台现状与发展[J].气象,2010,36(7):50-55.
[2] 王京丽,谭晓光,张德政,等.大城市气象服务信息系统数据存储体系框架设计与实现[J].气象科技,2004,31(6):409-412.
[3] 齐贵滨,周尔滨,鞠洋.利用samba服务实现信息共享[J].黑龙江气象,2012,28(4):40-41.
[4] 赵春燕,孙英锐,董峰,等.高性能气象数据存储集群及在线扩展技术应用[J].计算技术与自动化,2013,32(3):117-121.
[5] 何振芳,张耀南,赵国辉.基于Parallel NetCDF的海量时空数据存储研究[J].科研信息化技术与应用,2012,32(1):54-61.
[6] 黄向东,王建民,葛斯函,等,一种海量多维文件集合的存储模型[C]∥Proc of NDBC 2014,2014:1.
[9] 钟雨,黄向东,刘丹,等.大规模装备监测数据的NoSQL存储方案[J].计算机集成制造系统,2013(12):3008-3016.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
作文周刊·小学一年级版(2022年24期)2022-06-18
内蒙古气象(2021年2期)2021-07-01
动漫界·幼教365(小班)(2020年6期)2020-05-22
当代陕西(2019年14期)2019-08-26
中华家教(2018年7期)2018-08-01
领导决策信息(2018年46期)2018-04-20
发明与创新(2018年19期)2018-04-01
百科探秘·航空航天(2017年11期)2017-12-20
中学数学杂志(初中版)(2016年5期)2016-11-01
