
基于状态机比对的状态机推断方案
2015-03-16 01:16中国联合网络通信有限公司江苏省分公司斌东南大学信息科学与工程学院宋宇波
江苏通信 2015年5期
中国联合网络通信有限公司江苏省分公司 颜 蕾 吴 斌东南大学 信息科学与工程学院 宋宇波
基于状态机比对的状态机推断方案
中国联合网络通信有限公司江苏省分公司 颜 蕾 吴 斌东南大学 信息科学与工程学院 宋宇波
简要介绍了协议逆向工程,提出协议逆向工程状态机推断部分存在的问题(即理想化地认为逆向结果是正确且完整的)。针对发现的问题,结合状态机推断的传统方法,提出状态机比对的解决方案并给出该解决方案的示例。该方案基于状态机状态转换的可比较性,通过用四元组表示状态转换并利用字符串相似度检测的方法对比状态机,获得状态机的原始信息。
协议逆向; 状态机; 状态机比对
1 协议逆向
在对网络协议进行分析的过程中,需要用到各种技术,其中网络协议逆向工程是一门经常被用来逆向分析网络协议流从而获得协议信息的技术。协议逆向工程[1]是指在不依赖协议描述的情况下,通过对协议实体网络数据的输入输出、系统行为和指令执行流程进行监控和分析,从而提取协议格式以及协议状态机信息的过程。网络协议逆向分为两个部分,它们分别是消息格式提取和状态机推断。
消息格式提取是指逆向分析出消息的格式。协议一般是由多个会话组成的分层的结构,每个会话由许多消息序列组成,而消息序列由域组成,域的定义是最小的有一定意义的连续数据序列。大部分协议都包括分隔符、长度域及其目标域、关键词,所以协议格式的推断一般首先提取这三种域,然后再根据它们分离出消息序列的其他域。
网络协议逆向分析的另一个部分是状态机推断[2],传统状态机推断方法一般包括三个步骤,即:
1)利用前期采样到的会话数据,根据会话集构建状态前缀树;
2)根据消息序列的特性对不同的状态机进行标注;
3)使用状态机化简算法合并和化简状态机。
2 问题描述
在前期状态机推断的研究工作中都理想化研究结果,认为利用协议逆向技术推断出的状态机是该协议的完整状态机,但是协议逆向工程推断出的状态机有可能不是协议的原始状态机,因为输入的会话集合可能没有完全遍历协议状态机的各条路径,或者在状态机推断过程中存在某些偏差使得推断的状态机并不是一个完全正确的协议状态机。以这个不完整的甚至带有某些错误的状态机为基础进行后续工作,产生的结果与预期的结果会有偏差。基于以上的原因,协议逆向推断的状态机需要进一步处理以获得完整正确的协议状态机。
3 状态机推断
针对发现的问题,本文提出了状态机比对的思想,比对推断出的状态机与已有状态机,从而获得状态机的完整信息,便
于后续的漏洞挖掘工作的进行。所以本文状态机推断的完整流程为:
1)根据输入的会话集构造状态机的泛化前缀树接收器;
2)使用算法确定报文类型之间的顺序特征,确定先决条件,利用先决条件标注状态;
3)利用DFA(有穷自动机)化简算法化简合并前缀树;
4)利用字符串相似度算法比对推断出的状态机与现有状态机,确定逆向协议状态机的完整信息。
流程图如图1所示。

图1 状态机推断完整流程图
本文忽略状态机推断的其他步骤,着重讨论状态机比对部分。状态机比对是指将推断出的状态机与现有协议的状态机做比对,根据状态机的相似性确定推断出的状态机的所属协议。考虑到状态机整体比较的困难性,那么可以将状态机分作多个元素,取其中的决定性元素作为比对参照物。状态机是由多个状态和状态转换组成的,状态机的状态转换就可以作为比对参照物。利用一些转换将状态转换化为字符串,这样就可以使用字符串序列比对的方法来比对各条状态转换,从而比对各个状态机。字符串比对一般都是利用字符串的相似度作为度量,所以本文的状态机比对以字符串相似度算法为核心。
3.1 最长公共子序列算法
字符串相似度有很多种算法,比如编辑距离算法[3]、最长公共子序列(LCS)算法和贪婪字符串比对算法(GST)等,其中编辑距离算法只能针对顺序的匹配,算法的时间复杂度较大,贪婪算法采用了逐字符比较的方法,算法的时间复杂度也较大。另外这里的字符串比对环境更适合使用LCS算法,所以这里选择LCS算法作为比对算法。

图2 LCS算法流程图
LSC算法是在不改变字符顺序的情况下将两个给定的字符串分别删掉其中的零个或者几个字符,得到长度最大的相同字符序列的算法。也就是说,给定字符串P、T,计算它们的最长公共子序列X。这种算法有多种解析方式,但是一般使用递归的方法,分为自上而下递归与自下而上递归两种,这两种递归方式并没有本质上的差别,本文选用自上而下的递推法,算法具体的步骤描述如下:
1)获得两个字符串的长度L1(S1)和L2(S2),此时如果L1或者L2中任意一个数字为0,则最大公共子串长度为0。
2) L1和L2皆不为零的情况下构造一个矩阵a,其大小为(L1+1)×(L2+1),矩阵的第一行与第一列置零,也就是ai, 0=0,a0, j=0,其中0≤i≤L1,0≤j≤L2。
3)在计算ai, j时的值已经被计算出来了,利用递归式(1)计算矩阵A的每一行每一列的参数,矩阵中最大的一个数值就是最长公共子串的长度,用符号LCS表示,
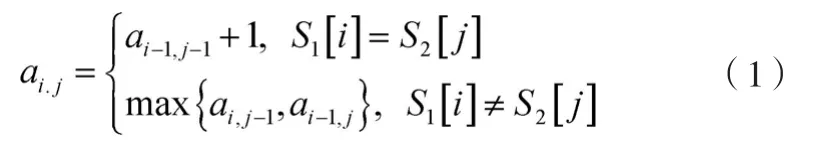
相似度用δ表示,其计算方法如公式(2)所示。
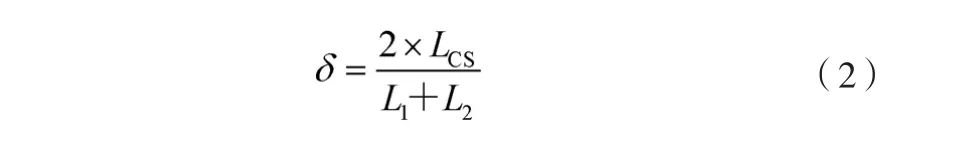
主要的步骤如流程图2所示。
例如计算字符串T=abcdefgh和字符串P=xyzabpd的相似度,根据递归公式构造出的矩阵如图3所示。

根据图3可知最大的公共子序列为X=abd,最大公共子序列长度为3,根据这个长度可以得到两个字符串的相似度为
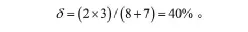
3.2 状态机比对
将协议的状态转换表示为一个四元组 〈初始状态,动作,消息模式,结束状态〉 ,表示为矢量t=〈Si, action, M, Sj〉,其中action有两种:发送(send)和接收(recv),M表示消息的格式,这里为了后续比对的方便,简略地将消息用分隔符和关键词表示,省略掉消息中的其他域。例如一个消息序列是由两个关键词和两个分隔符组成的,那么M为关键词1加分隔符1加关键词2加分隔符2,关键词和分隔符按在消息序列中的顺序排列。整个状态机的状态转换就表示为 〈t1,t2,t3… 〉 ,一个协议的状态机用这种转换方式构成一个转换矩阵。因为根据标记训练集推断出的状态机是完整状态机的一个部分,所以可以从完整状态机矢量矩阵中寻找推断出的状态机矢量,能够寻找到该状态机的矩阵就是该状态机所属的协议。状态转换包括四个参数,这4个参数中有2个可以用来作为比较内容区分转换(因为状态的表述不一定完全相同),那就是action和M。
称协议逆向出来的状态机为协议P的状态机,状态机比对的具体步骤如下:
1)将协议的状态转换按照动作分为send组合recv组,先在recv组别中比对;
2)取协议P状态机中状态转换recv组的一个状态转换ti的消息序列(包含关键词和分隔符),与已知的协议状态转换分在recv组的消息序列做对比,这里使用LCS算法计算相似度,与新推断状态机的状态转换ti相似度最高的协议记为Pn;
3)取新推断状态机的状态转换ti+1,与已知的协议状态转换分在recv组的消息序列做对比,相似度最高的协议若是与Pn相同,记为Pn,否则记为Pn+1;
4) 重复步骤2)和3),直到协议P的recv组中的状态转换比对完毕,然后比对协议P的send组中状态转换,重复步骤2)和3)(将其中的recv替换为send);
5)计算被记录相同协议符号的个数,最多的就是新推断协议状态机所属协议的状态机。
例如表1列出的新推断出的协议状态转换序列与现有协议1和协议2的转换序列,根据LCS算法计算出新推断协议的各条状态转换序列与协议1和协议2的状态转换序列相似度中,与序列AabBc相似度最大的是协议1的AabBFc(91%),与序列Cac相似度最大的是协议2的Cac(100%),与序列DdEc相似度最大的是协议1的DdEc(100%),所以新推断协议与协议1有两条状态转换相似度最大,占新推断协议状态转换的2/3,所以可以确定新推断的协议状态机隶属于协议1的状态机,也就是说协议1是逆向分析的协议。
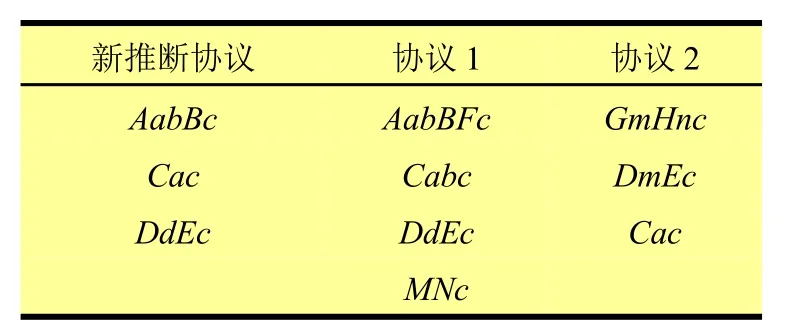
表1 三个协议的序列表示
4 结束语
随着科学技术的发展,网络协议逆向工程的应用将会越来越广泛,因为现代技术的发展更加看重自动化的技术。为了更加深入地对协议进行逆向,就需要解决协议逆向工程中的种种问题,状态机的推断是协议逆向的一大难点,很多研究都规避此类研究,这无助于协议逆向技术的发展。本文针对状态机推断过程中可能出现的理想化问题提出解决方案,其中还存在一些不足,但是相信对未来的协议逆向技术发展会有一些积极的作用。
[1]潘瑶, 吴礼发, 杜有翔, 等. 协议逆向工程研究进展[J]. 计算机应用研究, 2011,28(8): 2 801-2 806.
[2]张钊, 温巧燕, 唐文. 协议规范挖掘研究综述[J]. 计算机工程与应用, 2013,49(9): 1-9.
[3]LEVENSHTEIN V I. Binary codes capable of correcting deletions, insertions and reversals[J]. Soviet physics doklady, 1966,10(8): 707-710.
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
无线互联科技(2020年11期)2020-12-01
北京航空航天大学学报(2019年9期)2019-10-26
燕山大学学报(2014年1期)2014-03-11
应用技术学报(2014年3期)2014-02-28
测绘科学与工程(2013年6期)2013-03-11
网络安全与数据管理(2011年17期)2011-07-25
黑龙江科学(2011年2期)2011-03-14
空间控制技术与应用(2010年5期)2010-12-23
现代电子技术(2009年14期)2009-09-05
