
基于语音转折点检测的改进波形相似叠加时长规整算法
2015-03-07 11:43:27雷颖思
计算机工程 2015年10期
雷颖思,杨 燕
(兰州交通大学电子与信息工程学院,兰州 730070)
基于语音转折点检测的改进波形相似叠加时长规整算法
雷颖思,杨 燕
(兰州交通大学电子与信息工程学院,兰州 730070)
波形相似叠加算法忽略语音本身感知特性,对整段语音统一规整,在采样率较低或规整比例较大时处理效果不佳。为此,通过分析人耳听觉系统的预测特点,提出一种改进的波形相似叠加时长规整算法。采用子带谱熵法检测出语音的转折部分并保持其不变,以保证转折区的语音信息不受损坏,并给出一种局部补偿法以修正整体规整精度。仿真结果表明,该算法在整体规整比例不变的情况下可提高合成语音的自然度。
时长规整算法;波形相似叠加算法;听觉预测;转折点检测;子带谱熵;局部补偿法
DO I:10.3969/j.issn.1000-3428.2015.10.049
1 概述
语音时长规整是对原始语音信号进行时域扩展或压缩的一项技术,目的在于扩展或压缩语音的长度,并且在改变语音速度的同时保持原始语音信号的特性,如基音频率、说话人音色以及语义清晰性等不变[1]。语音时长规整广泛应用于语音压缩、语言教学、影视制作,以及人机交互等领域。例如,在语音通信中,对信号进行不改变易懂性的时域压缩能使之以更小的体积进行网络传输或存储,节省网络带宽或磁盘资源[2];外语教学和残疾人训练中,在保持原有语音特色的前提下对多媒体教学资源播放速度进行有意识的控制,能便于学生掌握发音技巧和练习听力,使残疾人达到更好的训练效果[3];在影视后期制作中,对语音信号进行时长规整,能实现语音与影像的精准同步[4]。 此外,对语音时长规整技术的研究有利于推动人机交互领域的发展[5]。
国内外学者对语音时长规整提出了许多有效的方法,主要分为时域法[6]、频域法[7]和参数法[8]3大
类。频域法和参数法由于参数多、算法复杂,合成语音质量较差且不适合于实时处理[9]。时域规整算法由于具有简单、有效、便于实现等特点应用最为广泛,目前的商业产品也大多数基于时域方法[10]。
时域法基于对语音时域的拼接和合成思想,其中同步波形叠加(Similarity Overlap-and-Add,SOLA)法[6]、波形相似叠加(Waveform Similarity Overlapand-Add,WSOLA)法[11]能在低的计算量下达到较好的合成效果,适合于实时处理系统。但是在采样率较低或规整比例较大时处理效果会明显降低,这是由于算法忽略了语音本身的感知特性,对所有语音采取相同的规整措施。为提高合成语音质量,有学者提出了对语音的分段规整算法[12],在SOLA算法的基础上把语音分解为瞬态成分、稳态成分和安静成分,对不同成分采用不同的规整因子,但由于不同规整因子的引入,对语音的整体比例并不能达到预期要求。文献[13-14]通过Mel倒谱法把语音分为瞬态和暂态,对不同状态的语音采用不同的规整因子,计算量大,且 Mel倒谱法难以选择合适的阈值。
人耳听觉系统是根据转折信息进行听觉预测的,转折区包含的信息对语音信号的感知度有至关重要的作用[15],对整段语音采用统一的规整则忽略了语音信号的感知特性,在压缩时容易丢失转折区的信息,在扩大时容易造成转折区语音的模糊。因此,本文采用保持语音转折区不变的思路来提高WSOLA算法的合成感知度。通过文献[16]提出的谱熵法准确检测出语音的转折部分,在合成时保持其不变,从而提高输出质量,并通过引入局部补偿算法,保证整体规整比例不变。
2 WSOLA算法
SOLA算法和WSOLA算法是时域法中规整效果较好的2种算法,两者都是重叠叠加算法(Overlapand-Add,OLA)的改进。OLA算法把输入语音信号χ以帧长N、帧移S1分解成一系列重叠帧,合成时则把各分解帧以帧移S2进行叠加合成,从而达到改变语音速度的目的。α=S2/S1即为规整因子,α>1时表示对语音进行减速规整,α<1时表示对语音进行加速规整。该算法没有考虑到相邻帧之间的连续性,容易造成基音断裂,合成效果较差。为了解决此问题,SOLA算法在合成时,在理想合成帧移S2的某一邻域内寻找当前分解帧与相邻合成帧的最大相关位置插入分解帧;WSOLA算法则是在原语音信号中,从当前分解帧的某一邻域内寻找同前一合成帧波形最相似的帧,以帧移S2叠加到输出合成信号,从而减小了基音断裂。与SOLA算法相比,WSOLA算法在规整时长精度上更高,其具体算法原理如下:
存在线性映射关系τ(S1·m)=S2·m,其中,m为帧索引。在合成时,第一帧直接写入输出信号,之后的每一步合成时,在原语音信号 S1·m的邻域[-Δmax,Δmax]内寻找与前一合成帧波形最相似的帧,以距离S2叠加到输出信号,如图1所示。

图1 WSOLA算法
相似度 C(m,δ)由归一化的互相关系数来表示:

输出合成语音y(i)即为:

其中,ω(n)为窗函数,本文采用 50%重叠的hamming窗的取值不小于输入语音基音周期的一半,同时,为了防止引入时间回响,Δmax<S1/2。
3 基于谱熵法的语音转折区检测
语音转折点即语音信号中各段落的起始点和终点。检测方法主要可采用基于能量和过零率的检测方法、基于Mel频率的倒谱距离测量方法(Mel Frequency Cepstrum Coefficient,MFCC)以及基于谱熵检测方法。基于短时能量和短时平均过零率的检测法计算简便,但鲁棒性低,当信噪比低时检测效果差;MFCC倒谱距离测量方法检测效果较好,但计算复杂,运算量大,且难以选择合适的阈值。基于谱熵的检测方法检测效果好、鲁棒性高,且计算量较低[17],本文的语音转折点检测采用谱熵法。
由Shannon的信息熵原理,信息量可由事务发生的不确定性,即事务各状态出现的概率来度量。假设信源发出N个符号,它们出现的概率分别为P1,P2,…,PN,那么信息源的熵H(χ)即为:
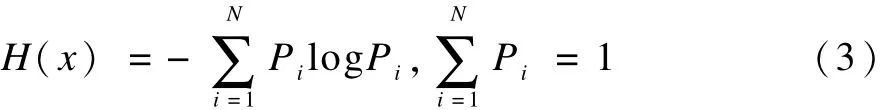
熵反映了信号的平均信息量,由于语音信号为频带受限信号,频率集中在300 Hz~3 400 Hz。在此频带内,语音信号的随机事件多,因此熵值大,噪声在此频带内的熵值则较小,可以通过熵值来判断信号的出现与停止,检测出语音信号的转折区。
由于语音信号是功率信号,具有短时平稳特性,可通过语音信号的短时功率谱来构造语音信息熵。由Wiener-Khinchin定理,平稳随机信号的功率谱密度为其自相关函数的傅里叶变换,语音信号的短时功率谱可转换为其自相关函数的傅里叶变换。基于谱熵的转折点检测流程如图2所示。
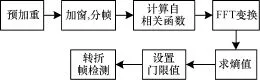
图2 基于谱熵法的语音转折点检测算法流程
设输入信号以hamming窗分帧后的每一帧为χm,共M帧,那么其自相关函数为:

对自相关函数进行K点FFT变换:

每一帧的谱能量为:
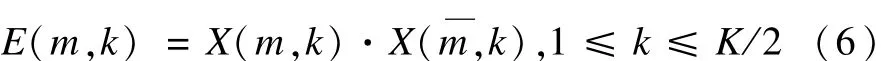
为提高检测鲁棒性及准确性,结合文献[18]的子带谱熵法,将每一帧划分为 Kb个不同的子带,得每一子带的谱熵为:

子带谱能量概率为:

子带功率谱熵即为:

本文Kb子带数取为K/8,通过对H(m)设定一个门限值,即可检测出语音的转折点,本文取为前10帧谱熵的平均值。
图3为对TIM IT语音库中某一条测试语音进行转折点检测和标记的情况。

图3 基于谱熵法的语音转折点检测
4 改进的WSOLA时长规整算法
4.1 局部补偿修正算法
对语音的转折区采取保持不变的策略必然会造成对整段语音的规整比例的偏差。例如,当对语音信号做加速规整时,整体规整时长就会比理想值大;对信号作减速规整时,整体规整时长则会比理想值小。为解决此问题,提出局部补偿修正,在每一步合成时,根据已规整原信号长度和对其规整后的已合成语音长度,重新计算对当前帧的合成帧移。
首先,保持 S1不变,理想规整时长和实际规整时长之间的偏差由时变的S2(m)来逐步补偿。

S2(m)即每一帧合成时重新计算的合成距离S2;XL为合成第m帧时已规整的输入信号长度;YL为已规整输出信号长度;α0为理想规整因子;Nc设定为0.5 s。图4为对TIM IT语音库中一条语音进行1.5倍减速规整时,实际的规整因子随时间变化的情况。

图4 局部补偿算法下时变的规整因子
从图4中可以看出,在语音的转折点,规整因子为1,也就是保持当前帧的不变,在剩余的非转折区,规整因子则在1.5周围波动。
4.2 改进的WSOLA算法流程
通过基于语音转折点的检测及局部补偿修正方法的提出,可得到改进WSOLA语音时长规整算法具体实现流程如图5所示。
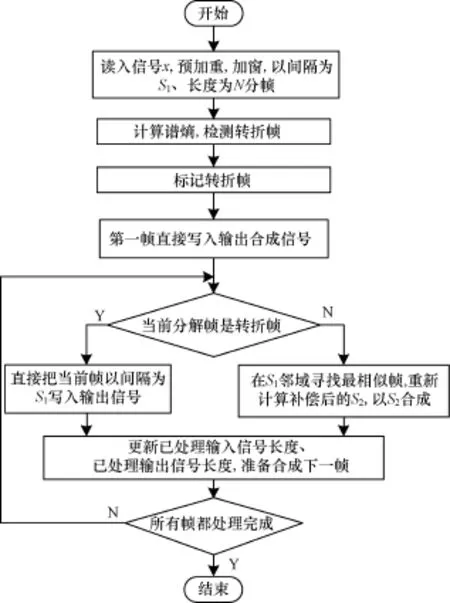
图5 改进WSOLA语音时长规整算法流程
5 实验结果及分析
实验测试英文语音来自TIMIT数据库,中文语音来自北京航空航天大学开放语音库,各随机选取其中的 20条语句作为测试语音,采样率均为16 kHz。规整因子α取0.3,0.5,0.7,0.9,1.5,2.0,
2.5 ,3.0。仿真实验在MatlabR2007b软件中进行。
考虑到语音信号的短时平稳性,在16 kHz采样率下,帧长N取400;Δmax取一个平均基音周期的一半,实验中,男声Δmax取4.5 m s,女声Δmax取2.5 m s。
采用以上参数,在规整因子α为0.3,0.5,0.7,0.9,1.5,2,2.5,3时对分析信号分别用WSOLA算法和本文提出的改进WSOLA算法进行时长规整。
对其中一条测试语句在 α为 0.3分别采用WSOLA算法和本文提出的改进WSOLA算法规整后的时域波形如图6所示,规整后的语谱图如图7所示。
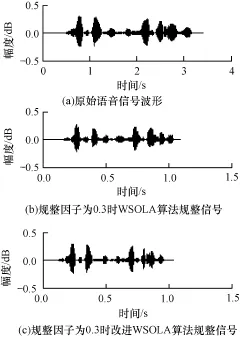
图6 规整因子α=0.3时实验所得波形

图7 规整因子α=0.3时实验所得语谱
由图可看出,改进WSOLA算法合成的波形与原语音更加相似;语谱图上,在α为0.3时,WSOLA算法规整后的语谱图已经模糊,而改进WSOLA算法规整后的语谱图与原信号语谱图更加相似。
对实验中采用WSOLA算法和改进WSOLA算法规整后的输出语音,用主观测评法评价语音质量。在主观评测中,共邀请了50人(25男25女),对在相同规整因子α下分别采用W SOLA算法和改进WSOLA算法规整的40条测试语音,做出规整后合成信号音质较优者的选择。最后,统计出在各不同规整因子下 2种算法的选择比例,结果如表1所示。

表1 主观语音质量选择比例 %
由表1可以看出,改进WSOLA算法在各不同规整因子下的规整语音质量都优于WSOLA算法,尤其是当规整比例较大时,改进WSOLA算法的优势更加明显。
总的来说,由客观规整波形、语谱图分析以及听觉比较可见,改进WSOLA算法合成信号的听觉效果明显优于WSOLA算法合成信号,提高了WSOLA算法的合成感知度。
6 结束语
本文以改善WSOLA算法语音时长规整效果为目的,分析了WSOLA算法在采样率降低或规整比例增大时,处理效果明显降低的原因,给出检测语音转折区部分并保持其不变的步骤,并通过进一步局部补偿修正,保证了语音时长的精确规整,形成了具有较好输出感知效果的改进WSOLA语音时长规整算法。理论分析和实验结果表明,本文提出的改进算法和WSOLA算法相比,既继承了WSOLA算法的低复杂度等优点,又弥补了其在输出语音感知效果不佳方面的不足,在提高语音时长规整质量上具有比较明显的优势。但转折区检测的引入加大了算法的时间复杂度,下一步工作将研究如何降低处理复杂度。
[1] Moulines E,Laroche J.Non-parametric Techniques for Pitch-scale and Time-scale Modification of Speech[J]. Speech Communication,1995,16(2):175-205.
[2] Stylianou Y,Cappé O,Moulines E.Continuous Probabilistic Transform for Voice Conversion[J].IEEE Transactions on Speech and Audio Processing,1998,6(2):131-142.
[3] Nejime Y,Aritsuka T,Imamura T,et al.A Portable Digital Speech-rate Converter for Hearing Impairment[J].IEEE Transactions on Rehabilitation Engineering,1996,4(2):73-83.
[4] Arfib D,Verfaille V.Driving Pitch-shifting and Timescaling Algorithms with Adaptive and Gestural Techniques[C]//Proceedings of the 6th International Conference on Digital Audio Effects.London,UK:[s.n.],2003.
[5] Amatriain X,Bonada J,Loscos A,et al.Content-based Transformations[J].Journal of New Music Research,2003,32(1):95-114.
[6] Roucos S,Wilgus A.High Quality Time-scale Modification for Speech[C]//Proceedings of IEEE International Conference on Acoustics,Speech,and Signal Processing.Washington D.C.,USA:IEEE Press,1985:493-496.
[7] Griffin D,Lim J S.Signal Estimation from Modified Short-time Fourier Transform[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1984,32(2):236-243.
[8] McAulay R,Quatieri T F.Speech Analysis/Synthesis Based on a Sinusoidal Representation[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1986,34(4):744-754.
[9] 叶锡恩,张巧文.基于WSOLA算法的语音时长调整研究[J].科技通报,2005,21(5):593-596.
[10] 周 俊,高 悦,谭 薇,等.语音时长规整技术的研究回溯[J].现代电子技术,2006,29(18):102-105.
[11] Verhelst W,Roelands M.An Overlap-add Technique Based on Waveform Similarity(WSOLA)for High Quality Timescale Modification of Speech[C]//Proceedings of IEEE International Conference on Acoustics,Speech,and Signal Processing.Washington D.C.,USA:IEEE Press,1993:554-557.
[12] 黄 吴,郭 立,李 琳.基于感知敏感成分划分的语音时长规整算法[J].数据采集与处理,2009,23(6):740-745.
[13] 谢贵武,杨继红,肖 勇,等.基于语音分段的自适应时长调整算法[J].军事通信技术,2008,29(2):56-61.
[14] Demol M,Struyve K,Verhelst W,et al.Efficient Nonuniform Time-scaling of Speech with WSOLA for CALL Applications[EB/OL].(2004-07-11).http://academic. research.microsoft.com/Publication/10354418/efficient-nonuniform-time-scaling-of-speech-with-wsola.
[15] Furui S.On the Role of Spectral Transition for Speech Perception[J].The Journal of the Acoustical Society of America,1986,80(4):1016-1025.
[16] Shen Jialin,Hung Jeih-Weih,Fen Qin.Robust Entropybased Endpoint Detection for Speech Recognition in Noisy Environments[C]//Proceedings of the 5th International Conference on Spoken Language Processing.Sydney,Australia:[s.n.],1998:232-235.
[17] 许作辉.基于信息熵的语音端点检测算法研究与实现[D].长春:吉林大学,2012.
[18] Wu Bingfei,Wang Kun-Ching.Robust Endpoint Detection Algorithm Based on the Adaptive Band-partitioning Spectral Entropy in Adverse Environments[J].IEEE Transactions on Speech and Audio Processing,2005,13(5):762-775.
编辑 顾逸斐
Improved Waveform Similarity Overlap-and-Add Time Warping Algorithm Based on Speech Turning Point Detection
LEI Yingsi,YANG Yan
(School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China)
The Waveform Similarity Overlap-and-Add(WSOLA)algorithm neglects the perceptual characteristics of real sound speech signals,and employs uniform time scaling of the entire signal.When sampling rate is low or scaling proportion is large,the scale quality is degraded.Aiming at such problems,an enhanced WSOLA algorithm is proposed through analyzing the acoustic prediction characteristics of human auditory system.This method detects the turning points of the speech using a subband spectrum entropy measure and leaves them intact to ensure the turning points undamaged,while time scaling the remainder of the signal.A local compensate measure is further put forward to correct the whole scale accuracy.Simulation results show that the new algorithm improves the natural degree of the synthetic speech signals with the whole scale proportion unchanged.
time warping algorithm;Waveform Similarity Overlap-and-Add(WSOLA)algorithm;acoustic prediction;turning point detection;subband spectrum entropy;local compensation method
雷颖思,杨 燕.基于语音转折点检测的改进波形相似叠加时长规整算法[J].计算机工程,2015,41(10):260-264.
英文引用格式:Lei Yingsi,Yang Yan.Improved Waveform Similarity Overlap-and-Add Time Warping Algorithm Based on Transition Segment Detection of Speech Signals[J].Computer Engineering,2015,41(10):260-264.
1000-3428(2015)10-0260-05
A
TP301.6
甘肃省科技厅自然科学基金资助项目(1310RJZA050)。
雷颖思(1989-),女,硕士研究生,主研方向:语音信号处理,数字图像处理;杨 燕,副教授、博士。
2014-08-11
2014-09-03E-m ail:0212679@stu.lzjtu.edu.cn
猜你喜欢
文萃报·周二版(2023年23期)2023-06-15 16:26:36
出版人(2023年3期)2023-03-10 06:53:44
中国化工贸易·下旬刊(2019年5期)2019-10-21 03:13:08
测控技术(2018年11期)2018-12-07 05:49:02
佛山陶瓷(2016年11期)2016-12-23 08:50:27
大观(2016年9期)2016-11-16 10:31:30
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
区域经济评论(2016年2期)2016-05-17 05:06:33
西北工业大学学报(2015年4期)2016-01-19 03:31:55
计算机工程(2015年8期)2015-07-03 12:20:34
