
基于置信度代价敏感的支持向量机不均衡数据学习
2015-03-07 11:43:12赵永彬
计算机工程 2015年10期
赵永彬,陈 硕,刘 明,曹 鹏
(1.国网辽宁省电力有限公司信息通信分公司,沈阳 110006;2.中国电力财务有限公司,北京100005;3.东北大学信息科学与工程学院,沈阳 110819)
基于置信度代价敏感的支持向量机不均衡数据学习
赵永彬1,陈 硕1,刘 明2,曹 鹏3
(1.国网辽宁省电力有限公司信息通信分公司,沈阳 110006;2.中国电力财务有限公司,北京100005;3.东北大学信息科学与工程学院,沈阳 110819)
现实世界中广泛存在着很多不均衡的数据,其分类问题是机器学习领域的研究热点。为了提高不均衡数据的分类性能,提出一种基于核空间置信度的代价敏感支持向量机分类算法。通过注入类别错分代价机制,以不均衡数据评价指标作为目标函数,优化错分代价因子,提升少数类样本的识别率。计算类中所有样本在核空间下的类别置信度,从而确定样本对决策分类贡献的重要程度,降低噪音或孤立点对支持向量机的影响。通过大量UCI数据集的实验结果表明,与其他同类算法相比,该算法能更好地提高不均衡数据的分类性能。
机器学习;分类;不均衡数据学习;支持向量机;代价敏感学习
DO I:10.3969/j.issn.1000-3428.2015.10.033
1 概述
在医疗诊断、网络入侵等现实领域中产生了大量类别分布不均衡的数据。由于来自不同类别样本的数量差异性,造成分类模型倾向于多数类的预测而忽略少数类,从而最终影响分类器的分类性能。近年来,不平衡学习问题引起机器学习研究者的广泛关注[1-3],主要提出了数据重采样预处理方法[4-6]和代价敏感策略分类方法[7-9]。 另外,集成学习方法,如Boosting[10]、随机子空间[11],通过与数据采样
以及代价敏感算法相结合,可以提升不均衡数据学习的泛化性。
支持向量机(Support Vector Machine,SVM)是机器学习领域研究热点之一。不均衡数据导致SVM分类平面会向少数类样本偏移[7],造成少数类的精度下降。另外,SVM训练过程中对所有训练样本是平等对待的,这就造成了SVM分类器对噪音和孤立点数据样本极为敏感,进而导致了过拟合的情况发生。解决该问题主要分为2种策略:数据预处理方法[12-13]和模糊支持向量机算法[14-15]。 数据预处理方法主要在分类学习之前对数据进行噪音和孤立点的识别和过滤,模糊支持向量机算法利用模糊技术对训练数据样本建立模糊关系,基于距离的模糊隶属度设计方法,根据样本的位置和贡献为其赋予不同的权重,从而降低噪音和孤立点对分类结果的影响。
为了提高不均衡数据下SVM算法性能,本文提出一种基于核空间置信度的代价敏感支持向量机(Confidence Cost Sensitive Support Vector Machine,CCS-SVM)算法,把不同的错分代价信息融入到分类器训练过程中,以最大化不均衡数据评估指标为优化函数对错分代价因子进行寻优;另外,由于SVM对噪音数据极为敏感,为了减少噪音数据的影响,在核空间下定义样本类别置信度函数,给每个样本不同的权重,并把样本的置信度引入到代价敏感SVM优化问题中,提高SVM分类性能。
2 代价敏感算法
分类问题是数据挖掘和机器学习等领域的重要研究课题之一,传统的分类算法通常以最小化错误率为优化目标。然而在故障诊断、医疗诊断、欺诈检测等领域,不同类型的错误率往往具有不等的代价。
代价敏感的学习方法是在训练过程中为不同的类别注入不同的错分代价参数。不同的代价通常被表示成为一个N×N的错分代价矩阵,其中N是类别的个数。C(i,j)表示将一个j类的对象错分到i类中的代价。表 1列出了二类类别的错分代价矩阵。

表1 错分代价矩阵
3 置信度代价敏感支持向量机
3.1 支持向量机
SVM目的就是找到一个最优超平面,在允许少量样本错分的情况下,使2类的间距最大,以得到最强的泛化能力。SVM求解最优化问题如式(1):

其中,ξi为松弛因子;C为惩罚系数,用来控制错误率与模型复杂性之间的关系。
3.2 改进支持向量机
传统SVM是基于所有类被错分的代价相等,当不同类被错分的代价不等时,使用不同的惩罚参数C+和C-来代替原有的参数C,从而生成代价敏感支持向量机(Cost-Sensitive SVM,CS-SVM),使得分类时针对不同的类采用不同的错分代价提高对少数类样本的识别能力,如图1所示,原始优化目标函数转化为如下目标函数:
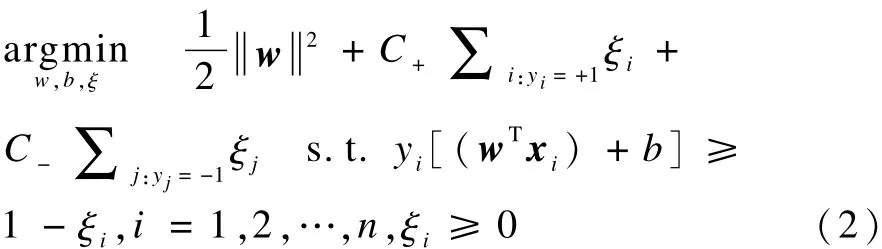
其中,C+和C-分别代表2类样本的错分代价参数。重新对C+和C-进行设置,令C-=C,C+= C×Cf,其中,C为SVM的惩罚参数;Cf为错分代价因子[7]。
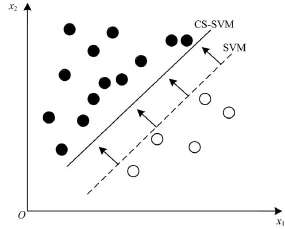
图1 CS-SVM分类决策平面
为了解决SVM对噪音和异常样本的过分敏感问题,需要赋予样本在类内部空间内的类别置信度。SVM的超平面是在核空间下构造的,所以直接在核空间下计算样本对分类性能的权重,定义一种样本类别置信度来描述样本的权重,可以给予不同的样本不同的置信度,从而确定样本在类中的相对重要性,同一类别中样本离类中心越近,类别置信度越
高;反之则越小,从而降低或者忽略了噪音或者孤立点数据对分类的影响,更加准确地构建分类超平面。在核空间中假设映射核函数为 φ(χ),则类中心为Cenφ:

样本χj与类中心Cenφ的核距离为:
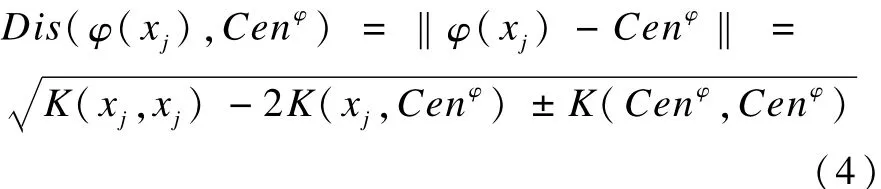
另外,定义最大距离:
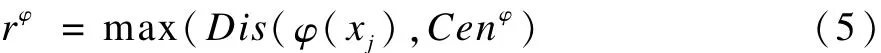
经过归一化后,每个样本χj的类置信度为:

其代表了隶属于某一类的程度,基于核空间置信度直接在核空间内进行计算,可以更加直接准确地获得每个样本的类置信度值。根据样本的核空间置信度,重新定义SVM的目标函数:

利用对偶进行优化,式(7)的对偶问题变为:

Cf对分类起到了重要的作用,为了获取最佳的错分代价因子Cf,以G-mean作为目标函数,对Cf进行评估和优化,来获得最佳的错分代价因子BestCf。G-mean是一种衡量不均衡数据的综合指标[7],由2类准确率ACC+和ACC-构成。利用G-mean指导优化,可以提高少数类精度的同时,并不会严重破坏多数类的分类精度。G-mean定义如下:
CCS-SVM算法详细步骤如下:
输入 训练子集TrSet,验证子集ValSet,惩罚参数C,递增步长μ

输出 分类模型CCS-SVM

CalculateConfDataSet算法详细步骤如下:
输入 数据集DataSet
输出 置信度数据集ConfDataSet

根据式(4)计算样本 xj与所属类别的类中心 Cenφ的距离Disj
根据式(6)获得每个样本的置信度conf(xj)

根据式(3)计算核空间下的类中心Cen+φ和Cen-φ
4 实验评估
为了对算法进行评估验证,选取10组UCI公开数据集,数据特征信息如表2所示。

表2 实验数据集
为了评估CCS-SVM的分类性能,分别采用如下方法进行对比验证,包括重采样算法:升采样算法SMOTE[5],基于Boosting架构的RAMOBoost组合采样算法[6];代价敏感组合分类算法:未经优化的CS-SVM,基于组合分类器的代价敏感分类算法的BCS-SVM[10]。其中,BCS-SVM利用Boosting集成学习架构,并引入不同的错分代价因子提高不均衡数据分类性能,集成分类中基分类器个数设为 50。
另外,也与基于核空间隶属度的模糊 SVM方法FSVM[14]进行对比。SVM模型均选择径向基核函数作为核函数,其中参数 γ设为1,并且模型参数C设为10。CS-SVM和BCS-SVM算法中的错分代价因子Cf设为2类样本的数量比例。对于2种升采样算法,采样数量设为2类数量的差。
从表3可以看出,CCS-SVM算法的G-mean性能要优于其他方法。为了更全面评估算法的性能,另外选取AUC(Area Under the ROC Curve)对算法进行评估。由于ROC曲线作为分类器评估的可视化技术得到了广泛应用,ROC曲线越靠近左上方,表示对应的分类器的辨别能力越强[1]。AUC能以定量的方式表示 ROC曲线对应的分类器性能,AUC分类结果如表4所示。通过对多种算法的G-mean和AUC性能比较发现,CCS-SVM算法在多数数据集中都优于其他的采样算法和代价敏感算法,说明通过优化错分代价因子可以获得较好的分类标准,降低SVM对不均衡分布的敏感性;同时利用置信度可以减弱噪音和异常数据对分类平面的影响。

表3 多种不均衡数据分类算法的G-mean比较

表4 多种不均衡数据分类算法的AUC比较
从表3和表4的结果中也可以看出,虽然2种升采样算法对数据进行了均衡化处理,但新增的采样数据对于最终的分类模型不一定有效。相对于采样算法的随机性,CCS-SVM算法没有对数据进行处理和改变,性能相对稳定。另外,实验也证明了对于代价敏感学习算法,对错分代价参数的优化至关重要,设置的不合理不但不会提高分类性能,反而会使多数类准确率的降低程度大于少数类的提升程度,最终导致整体性能下降,如数据集Pima和Vehicle。对于高特征维度的不均衡数据集,本文算法也获得了更好的分类性能。
5 结束语
为提高不均衡数据的SVM性能,本文提出一种基于核空间置信度的代价敏感支持向量机算法,通过优化G-mean构造不均衡数据的最佳分类SVM模型。另外,在核空间下定义样本类别置信度函数,计算每个样本不同的权重,并把样本的置信度引入到代价敏感SVM优化问题中,提高了SVM的分类性能。下一步工作是研究如何将算法扩展到高维不均衡数据的学习中。
[1] He Haibo,Garcia E A.Learning from Imbalanced Data[J].IEEE Transactions on Know ledge and Data Engineering,2009,21(9):1263-1284.
[2] 叶志飞,文益民,吕宝粮.不平衡分类问题研究综述[J].智能系统学报,2009,4(2):148-156.
[3] 张银峰,郭华平,职为梅.一种面向不平衡数据分类的组合剪枝方法[J].计算机工程,2014,40(6):157-161.
[4] 曹 鹏,栗 伟,赵大哲.面向不均衡数据集的ARSGOS算法[J].小型微型计算机系统,2014,35(4):818-823.
[5] Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:Synthetic Minority Over-sampling Technique[J].Journal of Artificial Intelligence Research,2002,16:321-357.
[6] Chen Shen.He Haibo,Garcia E A.RAMO Boost:Ranked Minority Oversampling in Boosting[J].IEEE Transac-tions on Neural Networks,2010,21(10):1624-1642.
[7] Cao Peng,Zhao Dazhe,Zaiane O.An Optimized Cost-sensitive SVM for Imbalanced Data Learning[C]// Proceedings of the 17th Pacific-Asia Conference on Know ledge Discovery and Data Mining.Gold Coast,Australia:[s.n.],2013:280-292.
[8] Zhou Zhihua,Liu Xuying.Training Cost-sensitive Neural Networks with Methods Addressing the Class Im balance Problem[J].IEEE Transactions on Know ledge and Data Engineering,2006,18(1):63-77.
[9] Masnadi H,Vasconcelos N,Iranmehr A.Cost-sensitive Support Vector Machines[J].Journal of Machine Learning Research,2015,1(1):1-26.
[10] Wang B X,Japkowicz N.Boosting Support Vector Machines for Im balanced Data Sets[J].Know ledge and Information System s,2010,25(1):1-20.
[11] Cao Peng,Zhao Dazhe,Zaiane O.Hybrid Probabilistic Sampling with Random Subspace for Imbalanced Data Learning[J].Intelligent Data Analysis,2014,18(6):1089-1108.
[12] Thongkam J,Xu Guandong,Zhang Yanchun,et al. Support Vector Machine for Outlier Detection in Breast Cancer Survivability Prediction[C]//Proceedings of Asia-Pacific Web Conference.Berlin,Germ any:Springer,2008:99-109.
[13] Debruyne M.An Outlier Map for Support Vector Machine Classification[J].Annals of Applied Statistics,2009,3(4):1566-1580.
[14] Batuwita R,Palade V.FSVM-CIL:Fuzzy Support Vector Machines for Class Imbalance Learning[J].IEEE Transactions on Fuzzy System s,2010,18(3):558-571.
[15] 刘三阳,杜 喆.一种改进的模糊支持向量机算法[J].智能系统学报,2007,2(3):30-33.
编辑 顾逸斐
Imbalanced Data Learning for Support Vector Machine Based on Confidence Cost Sensitivity
ZHAO Yongbin1,CHEN Shuo1,LIU Ming2,CAO Peng3
(1.Information and Communication Branch of State Grid Liaoning Electric Power Supply Co.,Ltd.,Shenyang 110006,China;2.China Electric Power Finance Co.,Ltd.,Beijing 100005,China;3.College of Information Science and Engineering,Northeastern University,Shenyang 110819,China)
Imbalanced data classification problem is one of the main research field of machine learning in the real world.In order to im prove the classification performance of Support Vector Machine(SVM),a kernel space confidence based cost SVM is proposed.It can improve the accuracy of minority class by injecting the strategy of misclassification cost into training.Using the imbalanced data evaluation metric as the objective function,the method optimizes the misclassification cost parameter,so as to improve the accuracy of minority class.Moreover,the weight of each instance for decision classification contribution can be obtained by calculating the class confidence on the kernel space,so as to decrease the effect of noisy and outlier instances for SVM.Experimental results show that the proposed algorithm provides a very competitive solution to other existing methods for combating imbalanced classification problem s.
machine learning;classification;imbalanced data learning;Support Vector Machine(SVM);cost sensitive learning
赵永彬,陈 硕,刘 明,等.基于置信度代价敏感的支持向量机不均衡数据学习[J].计算机工程,2015,41(10):177-180,185.
英文引用格式:Zhao Yongbin,Chen Shuo,Liu Ming,et al.Imbalanced Data Learning for Support Vector Machine Based on Confidence Cost Sensitivity[J].Computer Engineering,2015,41(10):177-180,185.
1000-3428(2015)10-0177-04
A
TP18
国家自然科学基金资助项目(61302012);中央高校基本科研业务费专项基金资助项目(N140403004)。
赵永彬(1975-),男,高级工程师、硕士,主研方向:人工智能,智能电网;陈 硕,工程师、博士;刘 明,高级会计师、硕士;曹 鹏,讲师、博士。
2015-04-27
2015-06-09E-mail:neu-cp@163.com
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
计算机应用(2018年5期)2018-07-25 07:41:26
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
新校长(2016年8期)2016-01-10 06:43:59
轴承(2015年2期)2015-07-25 03:51:04
中学生(2015年12期)2015-03-01 03:43:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
