
一种基于Q学习的网络接入控制算法
2015-03-07 11:42冯陈伟
计算机工程 2015年10期
冯陈伟,张 璘
(厦门理工学院光电与通信工程学院,福建 厦门361024)
一种基于Q学习的网络接入控制算法
冯陈伟,张 璘
(厦门理工学院光电与通信工程学院,福建 厦门361024)
下一代无线网络是多种无线接入技术共存的异构网络,要充分利用各种无线网络的资源,需要实现异构网络的融合,但网络融合却面临异构网络环境下的接入请求控制问题。为此,在长期演进、无线局域网、设备直连构成的无线异构网络下,提出一种异构网络接入控制算法。根据不同的业务类型、终端移动性及网络负载状态,利用匹配系数所构成的回报函数,反映网络对相应业务及移动性的贡献程度,通过Q学习算法选择合适的网络接入方式。仿真结果表明,该算法具有高效的在线学习能力,能够有效提升网络在频谱效用和阻塞率方面的性能,实现自主的无线资源管理。
异构无线网络;接入控制;长期演进;设备直连;Q学习;资源管理;阻塞率;频谱效用
DO I:10.3969/j.issn.1000-3428.2015.10.019
1 概述
随着无线通信技术的发展,各种无线接入技术将在未来的通信环境中共存。由于不同网络的重叠覆盖、不同的业务需求以及互补的技术特点,协调异构无线网络资源就变得尤为重要。许多联合无线资源管理(Joint Radio Resource Management,JRRM)[1]的方法被提出,用于实现负载平衡和异构网络选择[2]。然而,许多现有的算法有的不能自主地进行网络接入,有的不能动态地适应变化的无线网络环境。网络应根据实际环境情况进行自主学习,并不断修改其策略实现网络资源的自我管理。
强化学习(Reinforcement Learning,RL)[3]是学习代理通过与环境互动进行学习的算法。RL的目标是学习在每个状态采取何种动作来最大化一个特定的指标。学习代理通过反复与控制环境进行交互,通过奖励来评价其性能,从而达到一个最优决策。RL广泛应用于机器人和自动控制[4],同时因其灵活性和自适应性也被引入到无线通信系统的资源管理[5-8]。Q学习是 RL的一种方法,利用学习代理逐步构建一个 Q函数,试图估计未来折扣代价以便于学习代理在当前状态采取一定动作。目前,已有文献将 Q学习应用于异构无线网络的选择中。文献[9-10]研究了用于网络接入控制的联合Q学习算法,但算法并未对所接入的业务属性进行区分。文献[11]讨论了基于 Q学习的资源自主联合管理算法,虽然考虑了业务属性但却没有考虑终端移动性的差异。文献[12]区分了业务类型和移动性,但效用函数没能反映带宽的影响,且未将Q学习算法与其他算法进行对比,没有体现出Q学习算法的优势。文献[13]提出了由蜂窝和femtocell网络构成的异构网络的基于Q学习的网络选择方案,将位于不同服务区域的用户网络选择建模成一个动态演化博弈过程,利用 Q学习算法获得均衡来实现网络选择。
针对以上问题,本文提出一种改进的基于Q学习的联合异构无线网络接入控制算法,引入设备直连(Device-to-Device,D2D)[14]通信模式,并根据业务类型、终端移动性和网络负载状态选择合适的网络接入。
2 Q学习算法模型
在RL系统中,具有学习能力的机器或各种系统都称为学习代理。学习代理通过与控制环境的反复交互学习来获取一个优化的控制策略。以这样的方式从环境获得强化信号(回报函数),从而使得评估的性能最大化[15]。
基本的RL模型组成如下:
(1)当前的环境状态集合S={s1,s2,…,sm};
(2)学习代理的动作集合A={a1,a2,…,an};
(3)回报函数r;
(4)学习代理的策略π:S→A。
这些要素之间的关系如图1所示[16]。 每一次迭代,学习代理获得环境状态s,并根据当前所选择的策略选择动作 a,此动作将在后续影响环境。环境在受到动作 a的作用后将会变为新的环境状态s′,环境同时也产生强化信号 r并且反馈给学习代理。
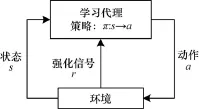
图1 RL的基本模型
学习代理根据强化信号 r更新策略,并继续新的一次迭代过程。通过不断尝试,RL最终将会找到每个状态对应的最佳策略 π*(s)∈A,从而最大化期望的长期累积回报,如式(1)所示:
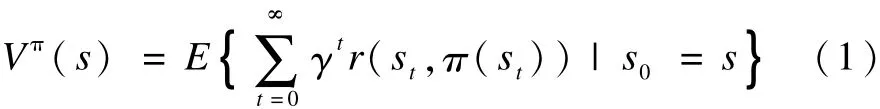
其中,γ∈(0,1)表示折扣因子,体现了未来回报相对于当前回报的重要程度。根据Bellman最优准则,式(1)最大值为:

其中,R(s,a)表示 r(st,at)的数学期望;Ps,s′(a)是状态s在动作a作用下到达状态s′的转移概率;Q学习是RL的一种方法,其优势在于能够在R(s,a)和Ps,s′(a)未知的情况下,利用Q值迭代最终找出最优的策略π*。
将策略π下的状态与动作(s,a)映射为一个Q值,如式(3)所示:

由式(2)和式(3)得到:
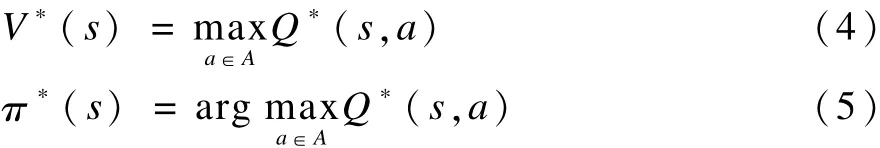
为了获得Q*(s,a),Q学习通过迭代的方式在每一个t升级Q值,如式(6)所示:

其中,α∈[0,1)为学习率。当 t→∞,若 α能以某种方式逐渐减小为 0,则 Qt(s,a)将收敛于最优值Q*(s,a),利用式(1)便获得最优策略π*[17]。
3 基于Q学习的接入选择算法
3.1 系统模型
系统模型是由LTE、W LAN以及D2D构成的异构无线网络。LTE与WLAN是目前主流的网络架构,并首次将5G的关键技术D2D模式引入,提出下一代的异构网络的模型,如图2所示。
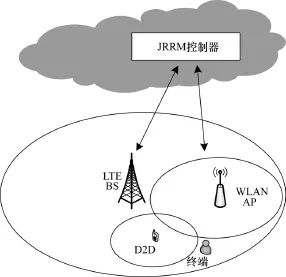
图2 异构网络模型
D2D是在蜂窝网络控制下的用户间直连通信方式,由蜂窝网络进行信令控制,业务传输在 D2D用户间直接进行,不但可以为核心网络进行分流,还具有传输速率高、延迟低等优点。当用户终端在D2D设备覆盖范围内,并且可以与D2D设备直接通信或是利用D2D设备作为中继进行间接通信时,用户终端选择D2D将很大程度提升网络性能。模型中只考虑2种类型的业务,语音业务与数据业务。LTE,WLAN与D2D有着不同的特点,WLAN网络更适合高带宽的数据业务,LTE网络由于其实时性与连续性的特点更适合语音业务,D2D网络由于是直连通信方式,适合所有业务。然而,从终端移动性的角度考虑,LTE网络更适合高速移动终端,WLAN网络更适合低速移动或固定终端,而D2D网络由于其覆盖范围最小,只适合固定终端。
结合以上模型,系统中的JRRM控制器利用Q学习算法,根据终端访问的业务类型、终端移动性、网络负载以及是否为D2D模式等条件,选择合适的网络进行接入。
3.2 问题映射
在将Q学习算法应用于无线异构网络选择前,需要将系统状态、动作和回报等因素映射到实际的接入模型中,具体的映射过程如下所述:
(1)状态集合S
所考虑的系统状态包括模型中所有网络的负载条件、业务请求类型、终端移动性。当LTE,WLAN,D2D网络的负载条件一样,也可能因为业务请求类型与终端移动性的不同而导致所选择接入的网络不同。将状态集合定义如下:

其中,ν表示业务请求类型,只考虑语音业务与数据业务,用1与2分别表示2种业务类型;m表示终端移动性,将其简化为2种状态,静止和运动,分别用1和2表示;l表示系统中的网络负载条件,即每个网络中已使用资源与总资源的比例。为降低系统运算复杂度,将l量化成若干个等级来构造Q值表。
一系列离散的会话到达或是结束事件都会影响网络状态,但是JRRM控制器在会话结束时不进行任何操作,只有在会话到达时才进行接入请求处理,因此,状态集合指的是会话到达时的状态,此时才启用Q学习算法进行网络接入选择。
(2)动作集合A
在无线异构网络中,JRRM控制器作为学习代理,根据状态和学习经验,为终端选择适当的网络接入。根据模型,考虑3个网络组成的无线异构网络,即LTE,WLAN与D2D网络,因此,动作集合定义为:

其中,1表示选择LTE网络;2表示选择W LAN网络;3表示选择D2D网络。
(3)回报函数r
回报r(s,a)是用于评估在某个状态 s下,会话请求被接入后所产生的即时回报。由于业务请求类型、终端移动性等因素,不同的网络接入选择将会对系统性能产生不同的影响,如果业务请求类型与终端移动性匹配所选择的网络,则累积频谱效用将最大,否则它将会更小。同时,为了平衡网络负载状态,将回报函数定义如下:

其中,η(ν,k)表示业务请求类型ν与接入网络k的匹配系数;η(m,k)表示终端移动状态m与接入网络k的匹配系数;β表示负载因子,表示所选择网络中的剩余资源与总资源的比例。具体值将在仿真部分说明。
式(9)可以简单地描述如下:如果所选择网络能更好地匹配业务请求类型和终端移动性,则获得匹配值将会较大,否则获得的匹配值将较小。
然而仅仅最大化匹配值可能会导致资源利用的严重不平衡,特别是当特定会话连续到达网络时。因此,JRRM控制器将根据负载因子β及时引导请求会话接入至低负载网络,即负载因子 β具有一定的负载均衡作用。
同时,为了评价网络性能,体现服务用户所获得的收益,定义比例公平的累积频谱效用UPf,即:
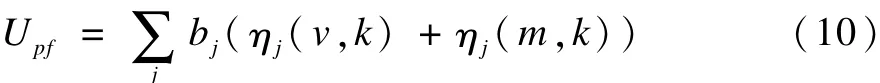
其中,bj是为会话j所分配的带宽。
3.3 算法实现流程
在综合考虑了网络的负载条件、业务类型以及终端移动性后,将 Q学习算法应用于无线异构的接入选择中。基于在线学习的 Q学习算法包含2个方面。
(1)策略更新:为了学习最优决策,每一次迭代,学习代理以ε的概率随机选择一个网络,以(1-ε)的概率选择当前状态下Q值最大的网络。
(2)Q值更新:采用查找表的方式获得每个状态下各个动作的 Q值,并选择最大 Q值的网络,当迁移到下一个状态时,Q值根据式(6)进行更新。
算法的实现步骤如下:
(1)初始化。将Q值表中的Q值都初始化为0,初始化折扣因子 γ、初始学习率 α0、初始探索概率 ε0。
(2)获取当前状态 s。当新的会话到达时,JRRM控制器收集相关状态信息,包括当前每个网络已使用的资源比例、业务请求类型、请求带宽、终端移动性以及是否具有D2D模式等。
(3)选择动作 a。根据当前状态下各动作对应的Qt(s,a),基于ε贪婪策略选择一个动作执行,即选择哪一个网络接入。
(4)根据式(9)获得回报r与下一状态s′。如果会话接入请求被网络拒绝,r值为0。
(5)根据式(6)更新Qt(s,a)。
(6)更新参数。每一次迭代后,为了满足收敛要求,需要对学习率α和探索概率ε进行更新。这2个参数在学习过程中,利用反比例函数规律逐渐减小为0。
(7)返回步骤(2)。
4 仿真结果及分析
在仿真模型中考虑新会话的发起以及业务请求发生在重叠区域。每个会话到达的时间间隔服从均值为20 s的指数分布,业务持续时间服从均值为80 s的指数分布,同时终端以概率P具有D2D通信模式。通过改变用户强度系数u来模拟网络的繁忙程度,用户强度系数越大,则网络接入数越多。业务只考虑语音业务与数据业务,且语音业务的带宽请求为1个~2个资源块,数据业务的带宽请求为3个~5个资源块,网络负载l被均匀量化成10个等级。其他仿真参数见表1,其他参数中,折扣因子γ=0.8,初始学习率α0=0.5,初始探索概率ε0=0.5,D2D通信概率P=匹配系数的相对大小反映了网络对相应业务及移动性的贡献程度。

表1 仿真参数设置
仿真首先评估基于Q学习的JRRM算法(Q-learning Algorithm,QLA)的阻塞率与频谱效用。作为比较,还仿真了未使用强化学习的基于负载均衡的JRRM算法(Load Balancing Algorithm,LBA)和未考虑JRRM概念的随机接入算法(Random Access Algorithm,RAA)。
图3与图4给出了3种算法的阻塞率和累积频谱效用随用户强度系数变化的情况。
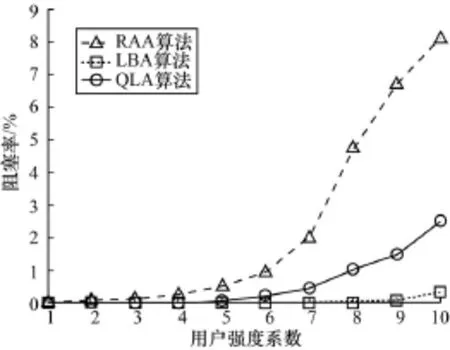
图3 阻塞率随用户强度系数变化的比较

图4 累积频谱效用随用户强度系数变化的比较
从图3可以看出,随着用户强度系数变大,网络逐渐变为繁忙,使得阻塞率逐渐变大,因此3个算法阻塞率的趋势均一样。RAA算法阻塞率最大,因为网络可用资源这一状态没有被考虑,网络选择非常盲目,很可能选择一个满负载网络进行接入,从而导致阻塞概率增加。利用LBA算法,则会话请求总是接入到低负载网络,这样每一个网络都不容易出现饱和现象,大大降低网络的阻塞率,因此,网络的阻塞率是3个算法中最小的。QLA算法考虑了网络负载状态这一参数,即考虑不同网络间的负载均衡,还兼顾网络对业务以及移动性的匹配性,网络阻塞率
介于RAA算法与LBA算法之间。
从图4可以看出,随着用户强度系数变大,接入网络的呼叫总数也将增大。根据累积频谱效用的定义,网络将累积接入呼叫所产生的效益,使得累积频谱效用逐渐变大,因此,3种算法累积频谱效用的趋势均一样。从获取的累积频谱效用来看,QLA算法的性能要高于RAA算法与LBA算法,这是因为累积频谱效用函数包含的匹配系数反映了网络对相应业务及移动性的贡献度程度,基于QLA算法的会话考虑不同业务类型和终端移动类型匹配系数的相对大小,将接入适当的网络从而合理利用系统资源。虽然LBA算法的阻塞率低于QLA算法,但是LBA算法忽略了业务类型和终端移动性带来的网络性能影响,从而导致累积频谱效用比QLA算法低。RAA算法是3种算法中性能最差的,一方面与LBA算法一样,都未考虑匹配性问题,另一方面是高阻塞率使得被阻塞的会话对累积频谱效用贡献为0,从而影响了累积频谱效用,使得RAA算法的累积频谱效用低于LBA算法。
图5和图6显示了固定业务强度下,每种算法的阻塞率和累积频谱效用随时间变化的情况。

图5 阻塞率随时间变化的比较

图6 累积频谱效用随时间变化的比较
图5显示了QLA算法在学习前后阻塞率收敛的变化情况,可以很清楚地看到RAA算法与LBA算法的阻塞率基本保持稳定。QLA算法尽管起始阶段由于“盲目”探索,其性能较差,但随着时间推移,通过学习,阻塞率逐渐减小,并收敛到一个最小值,这也证明QLA算法具有很好的在线学习能力。
图6显示了累积频谱效用随时间变化趋势的比较情况。虽然QLA算法的累积频谱效用在初始阶段与其他 2个算法基本一样,但随着时间的推移,QLA算法的性能差异逐渐显现。通过在线学习,系统可以有效地利用已学习到的经验来指导后续的策略选择,从而获得性能的提升。
当存在 D2D网络,并且终端是静止时,由于D2D网络在用于接入时对业务不进行区分,无论是语音业务还是数据业务,终端都接入 D2D网络,D2D网络对语音业务与数据业务的贡献度一样,因此图7与图8只比较3种算法在LTE网络与W LAN网络中对业务分布的影响。图7的负载差指的是语音和数据负载比例之差。图8的负载差指的是静止业务与移动业务负载比例之差。从图7与图8中可以看出,当采用RAA算法和LBA算法时,LTE与WLAN网络中语音和数据负载比例之差以及静止业务和移动业务负载比例之差虽然具有一定的随机性,但均在以内,都不能较好地区分业务。QLA算法使资源得到了优化的配置,LTE中的语音业务以及移动性业务的比例均远高于数据业务及静止业务;相反地,W LAN中的业务与其相反。这样能使不同接入网充分发挥其技术优势,从而提高系统的总体收益。

图7 LTE与WLAN网络中负载比例之差1

图8 LTE与WLAN网络中负载比例之差2
5 结束语
在LTE,WLAN,D2D构成的无线异构网络下,本文提出基于 Q学习的异构无线网络接入选择算
法。综合考虑网络负载条件、终端业务类型、终端移动性等因素,根据网络特性,利用Q学习算法合理地为每个到达的会话选择合适的网络进行接入。仿真结果表明,与RAA算法以及LBA算法相比,QLA算法能在保证低呼叫阻塞率的同时,获得更好的资源配置和更高的累积频谱效用,同时用户感知性能也通过学习收敛过程得以增强。但由于网络负载条件被简单量化为10个等级,一定程度影响了系统状态的准确性,下一步需要在充分考虑状态准确性的同时降低系统复杂度,从而提高运行效率。
[1] Luo Jijun,Mukerjee R,Dillinger M,et al.Investigation of Radio Resource Scheduling in WLANs Coupled with 3G Cellular Network[J].IEEE Communications Magazine,2003,41(6):108-115.
[2] Song Qingyang,Jamalipour A.Network Selection in an Integrated Wireless LAN and UMTS Environment Using Mathematical Modeling and Computing Techniques[J]. IEEE Wireless Communications,2005,12(3):42-48.
[3] Barto A G.Reinforcement Learning:An Introduction[M]. Cambridge,USA:MIT press,1998.
[4] Kaelbling L P,Littman M L,Moore A W.ReinforcementLearning:A Survey[J].Journal of Artificial Intelligence Research,1996,9(1):99-137.
[5] Nie Junhong,Haykin S.A Q-learning-based Dynamic Channel Assignment Technique for Mobile Communication Systems[J].IEEE Transactions on Vehicular Technology,1999,48(5):1676-1687.
[6] Senouci S M,Beylot A L,Pujolle G.CallAdmission Control in Cellular Networks:A Reinforcement Learning Solution[J].International Journal of Network Management,2004,14(2):89-103.
[7] Haddad M,Altman Z,Elayoubi S E,et al.A Nashstackelberg Fuzzy Q-learning Decision Approach in Heterogeneous Cognitive Networks[C]//Proceedings of Global Telecommunications Conference.Washington D.C., USA:IEEE Press,2010:1-6.
[8] Simsek M,Czylwik A.Decentralized Q-learning of LTE-femtocells for Interference Reduction in Heterogeneous Networks Using Cooperation[C]//Proceedings of International ITG Workshop on Smart Antennas. Washington D.C.,USA:IEEE Press,2012:86-91.
[9] Saker L,Ben Jemaa S,Elayoubi S E.Q-learning for Joint Access Decision in Heterogeneous Networks[C]// Proceedings of Wireless Communications and Networking Conference.Washington D.C.,USA:IEEE Press,2009:1-5.
[10] Tabrizi H,Farhadi G,Cioffi J.DynamicHandoff Decision in Heterogeneous Wireless System s:Q-learning Approach[C]//Proceedings of IEEE International Conference on Communications.Washington D.C.,USA:IEEE Press,2012:3217-3222.
[11] 张永靖,冯志勇,张 平.基于Q学习的自主联合无线资源管理算法[J].电子与信息学报,2008,30(3):676-680.
[12] Zhao Yanqing,Zhou Weifeng,Zhu Qi.Q-learning Based Heterogeneous Network Selection Algorithm[J].Journal of Computer Applications,2012,127(2):471-477.
[13] Tan Xu,Luan Xi,Cheng Yuxin,et al.Cell Selection in Two-tier Femtocell Networks Using Q-learning Algorithm[C]//Proceedings of the 16th International Conference on Advanced Communication Technology. Washington D.C.,USA:IEEE Press,2014:1031-1035.
[14] Doppler K,Rinne M,Wijting C,et al.Device-to-Device Communication as an Underlay to LTE-advanced Networks[J].IEEE Communications Magazine,2009,47(12):42-49.
[15] Barto A G,Bradtke S J,Singh S P.Learning to Act Using Real-time Dynamic Programming[J].Artificial Intelligence,1995,72(1):81-138.
[16] Watkins C J C H,Dayan P.Q-learning[J].Machine-Learning,1992,8(3/4):279-292.
[17] 叶培智.异构无线网络接入选择算法的研究[D].厦门:厦门大学,2013.
编辑 顾逸斐
A Network Access Control Algorithm Based on Q-learning
FENG Chenwei,ZHANG Lin
(School of Opto-electronic and Communication Engineering,Xiamen University of Technology,Xiamen 361024,China)
The next generation wireless network is the heterogeneous network of coexistence of a variety of wireless access technology.In order to make full use of the resources of all kinds of wireless network,the integration of heterogeneous network is necessary.However,when it comes to the heterogeneous network integration,the call request access control problem comes.In wireless heterogeneous network composing of Long Term Evolution(LTE),Wireless Local Area Network(W LAN)and Device-to-Device(D2D),an algorithm is presented for heterogeneous wireless network selection.The proposed algorithm based on Q-learning can select the appropriate network for access according to different traffic types,terminal mobility and network load status by using the return function com posing of matching coefficient reflecting the network contribution,the corresponding traffic and mobility.Simulation results show that the proposed algorithm has an efficient learning ability to achieve autonomous radio resource management,which effectively improves the spectrum utility and reduces the blocking probability.
heterogeneous wireless network;access control;Long Term Evolution(LTE);Device-to-Device(D2D);Q-learning;resource management;block probability;spectrum utility
冯陈伟,张 璘.一种基于Q学习的网络接入控制算法[J].计算机工程,2015,41(10):99-104.
英文引用格式:Feng Chenwei,Zhang Lin.A Network Access Control Algorithm Based on Q-learning[J].Computer Engineering,2015,41(10):99-104.
1000-3428(2015)10-0099-06
A
TP393
国家自然科学基金青年基金资助项目(61202013);福建省自然科学基金资助项目“多载波通信强非线性射频功放数字预失真算法与实现研究”(2015J01670);福建省中青年教师教育科研A类基金资助项目“基于蜂窝 D2D异构网络的无线资源管理技术研究”(JA 14233)。
冯陈伟(1981-),男,讲师、硕士,主研方向:下一代无线通信技术;张 璘,讲师、硕士。
2015-03-25
2015-05-14E-m ail:chevyphone@163.com
猜你喜欢
小学教学研究(2022年5期)2022-04-28
国际太空(2021年11期)2022-01-19
少儿美术(2019年7期)2019-12-14
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
中国塑料(2016年9期)2016-06-13
通信电源技术(2016年6期)2016-04-20
华东理工大学学报(自然科学版)(2015年3期)2015-11-07
现代农业(2015年5期)2015-02-28
现代农业(2015年5期)2015-02-28
