
神经网络和模板匹配在自动打分系统中的应用
2015-02-24 05:14徐富新黄玉秀
计算机工程与应用 2015年5期
徐富新,王 晶,黄玉秀,王 洲
中南大学 物理与电子学院,长沙 410083
1 引言
随着计算机和信息技术的快速发展,数据的计算处理技术突飞猛进,手工输入数据的速度和准确度显然已经不能够满足需要,这样就促使自动识别技术快速发展。对于数据内容有杂物或者印刷质量不好的数据,字符特征的提取成了关键点,而特征提取的好坏直接影响到识别率的高低[1]。传统模式识别方法的发展遇到了前所未有的困难,而神经网络的并行性、容错能力和学习性能,使它在解决识别问题上不再拘泥于选取特征参数,而对综合的输入模式进行训练和识别,针对字符的平移、旋转和尺度变化,可以通过构造具有不变性结构的网络模型,或者用神经网络提取字符的不变性特征及BP学习算法,利用图像识别原理,将需要识别的数据先转化为图像文件,对图像处理、进一步识别出结果并输出,就显得灵活方便[2-3]。
目前,实验报告一般采用等级评分制度,比如采用1~5五个等级,当这五个等级不够用的时候会在数字后面加上一个加号“+”或减号“-”表示优于或次于该成绩,如4+、5-,故本文将系统加以改进,使其能识别扩展等级这样的数字字符。
2 系统整体设计
从过去实验报告成绩录入效率低的角度出发,本课题在系统的总体结构设计上,首先采用图像处理将采集到的字符图片特征提取出来[4],然后利用改进神经网络算法将字符识别出来,并验证它的可执行性。该系统主界面是采用基于MFC的Visual C++面向对象化编程语言编写的。该自动打分系统的整体设计框架见图1。
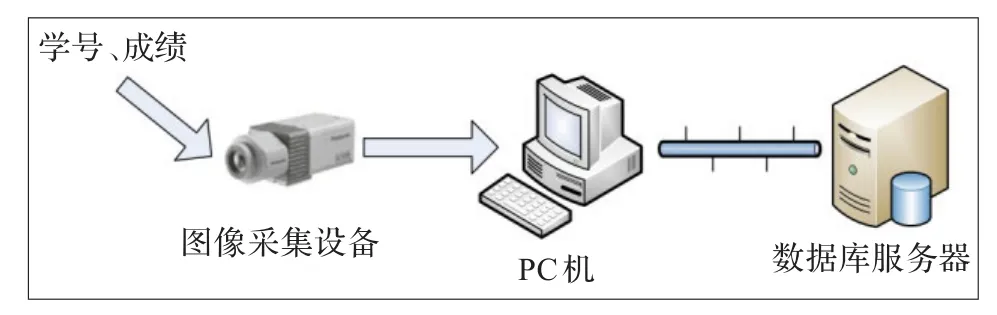
图1 系统整体设计框图
图片采集可以利用扫描仪、照相机、CCD摄像机等电子设备将识别的数据转换成图像文件,本实验中利用CCD摄像机将成绩报告输入到电脑中。首先下载安装CCD摄像机驱动,装好后用USB数据线将CCD摄像机连接到电脑,将实验报告朝下放在CCD摄像机上,点击“CCD摄像机和照相机向导”,文件格式选择.bmp,选择图片保存位置,便可得到报告成绩的图片。实验报告中学号、成绩的每个字符大小长8 mm,宽5 mm。
该自动打分系统的实现过程分两部分,图像预处理和数字字符识别模块。先是对图片进行预处理,然后对提取出来的数字、字符特征进行识别,输出识别结果并保存到数据库,此部分主要在VC++6.0软件上实现。
3 图像预处理
获取的成绩报告图片处理的总体流程框图如图2。
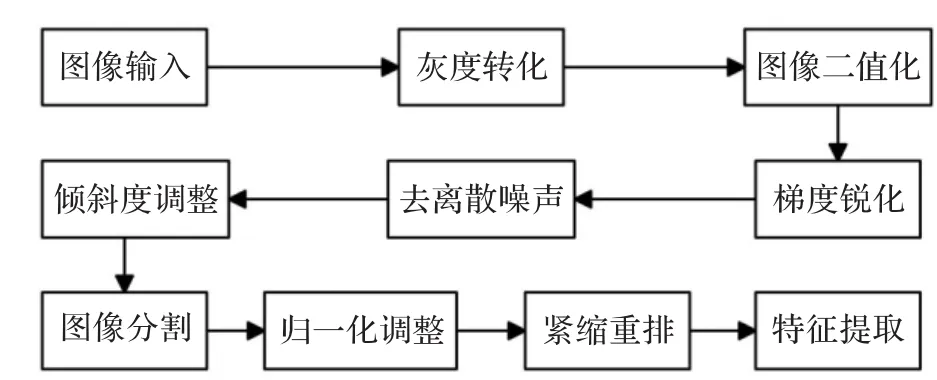
图2 图像处理总流程框图
3.1 图像二值化
该识别系统是针对实验报告成绩识别的设计。识别前,先要对图片二值化处理[5],本系统采用给定阈值法,设置图像处理的固定阈值为128(取0~255的中间值),逐行扫描图片中各点像素值,大于固定阈值的将其强制设定为255,小于固定阈值的将其强制设定为0。
3.2 去离散噪声
在实验报告扫描或者传输过程中会出现一些杂乱的离散点,可能是由于仪器等原因造成的。这些离散点并不是所需要的数据信息,并且会妨碍对数据信息的提取,所以要进行去噪声处理。在本系统中,直接扫描图片中离散的黑点,逐行逐列扫描整个图像,当扫描到黑点时,就判断它与周围黑点的连接关系,如果与它连接的周围的黑点的个数大于特定数值时,就判定它不是离散点,否则就判定它是离散点。如果检测到离散点就删除,也就是将其像素值强制赋值为255,即白色。
3.3 图像分割
从实验报告上获取的图片是关于学号和成绩,是一串的数字字符,这样不利于分别对每个数字字符进行特征值提取。当把每个数字字符都分割[4]成单独的图片后,提取其特征值就是该数字字符的特征值信息。首先从上往下逐行扫描,当遇到黑点时,把此行定为字符大致顶端。说大致是因为并不是所有字符的上端都在同一水平线上。再从图片底部逐行向上扫描,当遇到黑点时,将此行定为字符的大致底端。第二步是在确定的大致顶部和底部之间,逐列从左往右搜索。当搜索到黑点时,将此列作为该字符的左端;继续向右搜索,当扫描到某一列没有黑点时,将前一列作为该字符的右端。重复上述搜索过程,直到搜索到最后一个字符的右端。接下来是确定每个字符确切的上下边缘,方法类似以上搜索过程,在每个字符已经确定的左右边缘内,从上往下逐行扫描,当遇到黑点时,将此行作为该字符的确切上边缘;同样从下往上逐行扫描,当扫描到黑点时,将此行作为该字符的确定下边缘。重复上述步骤,直到找到所有字符的确切上下边缘。到此为止,已经扫描出了每个字符相对确定的上下左右边缘,为了不至于损坏字符边缘的像素值,需要将各边缘分别向外扩一个像素点作为各字符新的边缘。
图3是进行字符分割后的图片,处理后的图片中,在分割后的字符周围加上了蓝色的外框,主要是为了方便观察,其不影响之后其他的图像处理过程。

图3 字符分割后处理后的字符
3.4 归一化调整
实验报告中的学号和成绩均为手写字符,可能有大有小,分割之后虽然确定了其边界,但大小依然不一。由于数据结构不一样,使得特征值提取就不能够统一。将图片中各像素值按一定的比例关系插值映射到新的图像中去。新图像的尺寸是统一确定的尺寸,新图像的尺寸可以根据自己的需要来设定。
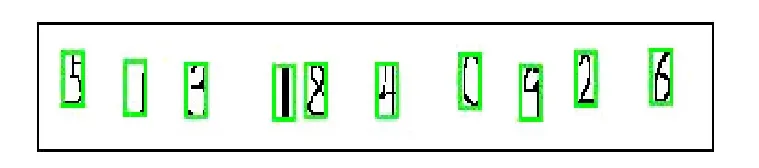
图4 标准归一化处理后的字符
3.5 特征提取
本系统中采用的是逐像素特征提取法,这种方法比较简单且运行速度快,就是对图像逐行逐列进行扫描,当扫描到黑点时就记录该点像素值为1,当扫描到白点时就记录该点像素值为0。直到扫描完整个图像,就统计完了所有的特征值,特征值数量与图像中像素点数量相同,扫描结果存储在一个二维数组中,便可得到所需要的数字图像特征。
4 成绩识别及存储
本文采用了BP神经网络识别和模块识别两种识别方式。
4.1 BP神经网络识别
BP神经网络也即反向传播神经网络,它是多层网络[6],一般至少有3个层,一个输入层、一个输出层、一个或多个隐含层,它主要包括信号正向传播和误差信号反向传播两部分,正向传播:输入信号从输入层经过隐含层传向输出层,此过程中网络权值固定不变,当期望输出值与网络系统输出值差别较大时,进入误差的反向传播阶段;反向传播:输入层向隐含层再向输入层传输误差信息并调整网络权值,反复反馈调整,使输出层输出逐渐逼近期望输出值[7]。
4.1.1 BP算法的改进
(1)信号正向传播过程
设输入层、隐含层和输出层结点数分别为m、n和l,则感知器的输出为:

其中netk为输出层第k个神经元的输入加权和[8]。
那么,当网络的输出与期望输出不相等时,及存在输出误差,则定义网路的第k个输出神经元的误差函数Ek为:

其中dk为第k个神经元期望的输出结果。
网络的能量函数(总的输出误差)为:

(2)误差反向传播过程
利用误差反馈,通过调整权值和阈值,使网络在能量达到最小时趋于稳定状态[9]。
根据前面推导,能量函数和输出层之间权值关系为:
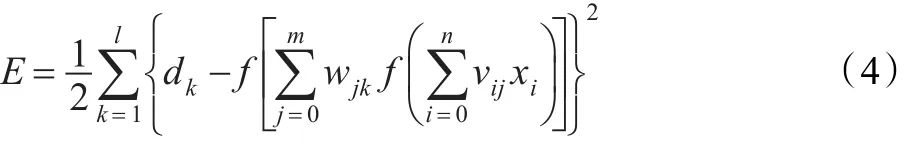
可见能量函数E是各层权值wjk和wij的函数,调整权值即可改变误差E,使用梯度下降法对其进行调整,取常数η(0<η<1)为调整的步长,及网络训练中的学习速率,则可以得到网络权值的调整量:
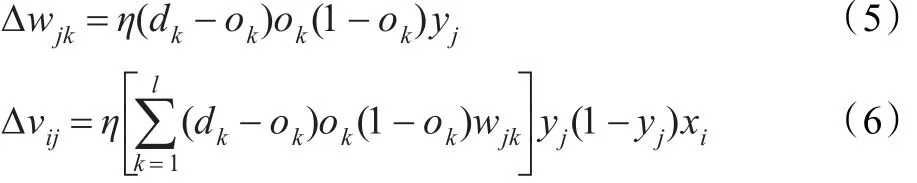
其中δk表示输出层的误差,δj表示隐含层的误差。
(3)加动量项
在修正网络权值时,不仅考虑误差在梯度上的作用,而且考虑在误差曲面上变化趋势的影响,标准BP算法在权值调整中,只按t时刻误差的梯度方向调整[10],而没有考虑t时刻以前的梯度方向,从而常使训练过程发生振荡,收敛变慢。为提高网络的训练速度,可以在权值调整公式中增加一动量项。

式中,α称为动量系数,一般有0<α<1。从前一次权值调整中取出一部分叠加到本次调整量中,α影响这个调整量的大小,对于t时刻的调整起到阻尼的作用。
4.1.2 手写数字及“+-”字符的识别
BP神经网络数字识别的实现主要包括样本训练、字符特征输入以及识别等过程,首先输入一个样本参数,让网络系统学习并记忆数据信息中各特征值。样本的选择要有代表性,在程序中采用样本图片的形式,训练完后即可用它对数字及字符进行识别。
其具体流程如图5所示。

图5 BP神经网络数字识别过程流程图
4.2 模板匹配识别
模板匹配法是图像识别中最具有代表性的方法之一。本文为待识别的样品提取25个特征值[11],输送到分类器跟已有的标准模板特征值进行比较,用最小距离法判定所属类。这种最小距离是依据近邻原则,是依据同类物体在空间中具有聚类特性的原理进行区分的[12],是一种最简捷的分类方法。
4.2.1 图像的最短距离法
利用图像之间的最短距离作为判别函数的原理为:对于一个待识别的样本X=(a1,a2,…,an),计算X与训练集中某样本Xj(0<j<m,m为训练集中的样本个数)之间的距离:

待计算完所有的样品和模板的距离后,找出最小的距离值所对应的模板类别,样本所属的类别判别为此类别。
对于加减号“+-”的识别,根据计算的特征值,首先判断是否存在加减符号,当最后一个字符的左右边界相差不超过1的时候,程序判断为缺省加减符号。若是存在加减符号,判断特征值是是否大于0.3,若大于0.3,符号判别为加号,反之判断为减号[13]。
系统分类器所使用的训练集特征库,是通过数字模板添加功能建立的。这也意味着,系统的训练集特征库是可增加的,并不是一成不变的。一般样品库的个数为特征数的5~10倍,这里特征总数为5×5=25,每一种数字就需要至少75个标准样品,可想而知数目已经不少了。如果N值过小,不利于不同物体间的区别。样品的处理方法和实际应用是一样的,先定位字符的上下左右边界,再对此范围进行5×5的分割,计算小范围黑色像素所占的比值[14]。
程序首先获取需要添加模板的数字,然后判断该数字是否已经拥有250个样品了,如果是则放弃添加样本,否则在该数字已有样本数目加1,然后把该字符的25个特征值增加到数字对应的位置。
4.2.2 图像显示与抓取的软件实现
在进行此功能模块开发时,第一步创建一个视频预览窗口。在创建视频捕捉窗口之后,将其显示在系统人机交互界面的对话框中的适当位置。先在对话框中预放置一个图片控件,调整其大小和位置,然后将视频捕捉窗口放置在该控件的位置处[15]。
对于视频帧的截取,将数据拷贝到剪贴板上,再通过DIB(Device Independent Bitmap)操作获取内存中图像数据首地址,进行后续的图像数据处理。系统中显示的效果如图6所示。
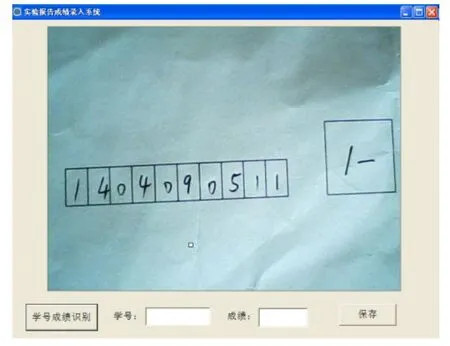
图6 图像采集效果
4.3 系统测试及两种方法识别结果的比较
经过实验可以看到,BP神经网络和模板匹配两种方法的字符识别系统都可以对数字及加减号“+-”进行正确识别。识别效果如图7所示,识别结果在图下方的学号、成绩栏给出。

图7 系统识别的实现图
随机选取了5 000份实验报告进行检测,无论是学号的识别还是成绩的识别,利用神经网络识别正确率高达99.3%,且识别一份成绩报告需30 s左右,使用同一样本,而模块匹配识别的在保证正确率91.4%的基础上,从图像采集到识别结果的显示大约使用时间3 s,较神经网络速度提到了10倍。另一方面,人工输入一份实验报告成绩至少需要1 min,而可见实验报告自动打分系统,大幅提高了数据输入的工作效率和准确率,具有一定的实用性。
4.4 学号成绩的存储
设置两个字段studentnumber和score,分别代表学号和成绩,然后在操作系统中创建要使用的ODBC数据源,在程序中添加与此数据库相关联的MFC ODBC类,调用CRecordView类的AddNew成员函数把学号与成绩增加到记录中。如图8,即是识别结果的保存。
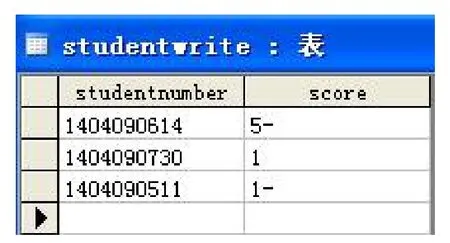
图8 识别结果的保存
5 总结
本文中设计的系统是针对实验报告中手写学号和成绩字符的识别,设计过程先对获取的实验报告字符图片进行一系列的预处理,然后用BP神经网络和模板匹配方法对其进行识别,最后对设计好的系统进行实验。在整个系统的设计以及实现过程中,识别图像预处理和识别的方法在现阶段无论是原理还是实现都已经很成熟了,字符的定位是最关键的一步,也是最难的一步。本文所用的字符定位起始位置修改参数是经过多次实验得出来的,符合大部分拍摄情况实验结果表明,该识别系统已经能在很大程度上进行手写数字和简单字符的识别,识别率比较高,相对手动输入成绩速度有了很大的提高。该自动成绩录入系统经验证已经可以应用到高校实验室的试用阶段。
[1]苏彦华.Visual C++数字图像识别技术典型案例[M].北京:人民邮电出版社,2004.
[2]马耀名,黄敏.基于BP神经网络的数字识别研究[J].信息技术,2007(4):87-88.
[3]杜选,高明峰.人工神经网络在数字识别中的应用[J].计算机系统应用,2007(2):21-22.
[4]周妮娜,王敏,黄心汉,等.车牌字符识别的预处理算法[J].计算机工程与应用,2003,39(15):220-221.
[5]朱小燕,史一凡,马少平.手写体字符识别研究[J].模式识别与人工智能,2000,13(2):174-180.
[6]王春,刘波,周新志.采用BP神经网络的车牌字符识别方法研究[J].中国测试技术,2005,31(1):26-28.
[7]武强,童学锋,季隽.基于人工神经网络的数字字符识别[J].计算机工程,2003(14):174-180.
[8]汤茂斌,谢渝平,李就好.基于神经网络算法的字符识别方法研究[J].微电子学与计算机,2009,26(8):91-93.
[9]杨庆雄.基于神经网络的字符识别研究[J].信息技术,2005(4):92-96.
[10]陈蕾,黄贤武,仲兴荣,等.基于改进BP算法的数字字符识别[J].微电子学与计算机,2004,21(12):127-130.
[11]顾晨勤,葛万成.基于模板匹配算法的字符识别研究[J].通信技术,2009,42(3):220-222.
[12]王军,王员云.基于模板匹配的联机手写数字识别[J].现代计算机,2008,25(3).
[13]荆钟,何明.基于最小错误率的贝叶斯决策在手写英文字母分类识别中的应用[J].辽宁工业大学学报,2009.
[14]汤群芳,俞斌.基于神经网络和DSP技术的离线数字识别系统[J].电子测试,2009,12(6):16-20.
[15]杨淑莹.图像模式识别:VC++技术实现[M].北京:清华大学出版社,2005.
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
小雪花·初中高分作文(2019年2期)2019-06-27
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
赤峰学院学报·自然科学版(2017年24期)2018-01-02
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
科技视界(2015年31期)2015-11-09
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
