
位图连接索引服务机制研究
2015-02-24 05:13张延松苏明川王方舟
计算机工程与应用 2015年5期
张延松 ,苏明川 ,张 宇 ,王方舟
1.中国人民大学 信息学院,北京 100872
2.中国人民大学 中国调查与数据中心,北京 100872
1 引言
随着多核处理器和大内存计算机平台的普及,内存正在取代磁盘成为新的高性能计算存储设备。内存数据库MonetDB[1]以内存列存储和cache优化的列代数优化技术成为内存分析型数据库的代表技术,其产品VectorWise[2-3]也成为高性能内存分析处理技术的代表产品,并在TPC-H[4]测试中获得集中式处理的最高性能。SAP HANA[5]以高性能内存分析处理技术迅速获得了市场认可,占据了实时分析处理的高端市场。传统的数据库厂商,如Oracle也推出了基于内存处理的ExaData X3[6]数据库一体机,以大容量的PCI-e闪存卡作为大容量高性能存储,消除磁盘I/O。
内存数据库已成为重要的实时分析处理平台,相对于当前主流的多核处理器和协处理器,内存仍然是一种访问延迟较高的存储设备,同时,内存访问带宽也是内存数据库的性能瓶颈之一,需要内存数据库中高效的索引机制来提高数据访问效率和充分利用内存带宽。
连接索引[7-8]是数据仓库中一种有效的提高表间连接效率的索引技术,它将表之间的连接关系([rowid:rowid])记录下来,可以对连接表按连接索引中的记录物理地址直接访问。Oracle进一步实现了位图连接索引[9],为指定连接表上的列成员建立连接索引,用位图指示当前列成员在连接表上的位置,从而用高效的位图索引扫描来代替大数据表上代价巨大的顺序扫描。在行存储磁盘数据库中,位图连接索引的存储空间开销和位图处理开销都很小,而在列存储内存数据库中,多个维表属性上的位图连接索引需要较大的内存存储开销,而且索引运算的代价不容忽视,内存位图运算的CPU代价较大,位图连接索引的整体效率受到较大影响。
虽然位图连接索引在提高表扫描效率和降低多表连接代价方面具有重要的作用,但磁盘数据库中的位图连接索引直接应用于内存数据库会产生较大的索引存储开销和位图计算开销,降低索引的综合性能。同时,位图连接索引是为查询中频繁访问属性中的每一个成员建立一个连接位图,通常优先为低势集的频繁访问属性建立位图连接索引以降低索引存储开销。但低势集属性连接位图的选择率较低,索引访问效率降低;而高势集属性成员低选择率的连接位图虽然提高了索引访问效率,但索引的存储开销消耗了大量宝贵的内存资源。另一方面,数据仓库多维数据模型的特点使数据库中存在大量不同属性上的位图连接索引,复杂查询往往涉及到多个索引之间的位图操作,增加了查询优化的复杂度。值得注意的是,频繁属性中存在大量非频繁访问成员而非频繁属性中也存在着部分频繁访问成员,而当前以属性为粒度的位图连接索引机制无法在内存容量约束的前提下更好地发挥位图连接索引的效率。
同时,随着多核处理器和协处理器的发展,索引的性能不仅仅取决于存储器的性能和存储访问模型,还取决于计算平台的并行计算模型。例如位图连接索引中经常执行多个位图之间的位图AND操作,对于多核CPU而言,位图访问和位运算需要较高的CPU cycle,而对于协处理器(如GPU)而言,位运算的效率极高。索引的性能不仅要考虑cache-conscious的存储访问算法,而更应该考虑processor-conscious的索引运算技术。索引管理需要决定什么时候,为谁,在什么地方,创建什么样的索引,索引的计算采用什么方式,索引计算的场地在哪里,索引计算的结果如何传递给下一级操作符,索引的更新如何触发,在处理器缓存-内存-磁盘多级存储结构中索引如何从同构的存储模型扩展为异构存储模型等问题。索引管理本身已是一个独立的系统级优化问题,而且位图连接索引具有与数据库系统相独立的输入(SQL命令参数)和输出(位图),因此将索引从数据库内置的数据结构抽取到数据库外层作为松耦合的索引服务能够降低数据库优化器的负担并更加独立地面向新的硬件平台(如协处理器)或存储技术(如内存云技术)而优化。
本文所提出的位图连接索引服务机制是在传统的位图连接索引的基础上设计独立于数据库的索引服务层,根据多维数据集的特性以关键字为粒度为数据库建立统一的位图连接索引,通过查询日志上的统计或数据挖掘方法按内存空间约束建立基于关键字的TOPK位图连接索引,在不同的索引更新窗口内根据关键字加权频度更新TOPK连接位图,以保证位图连接索引在给定内存存储空间中的使用效率最大化。在索引运算性能方面,通过多核处理器并行位图索引计算,GPU并行位图索引计算以及内存云位图索引计算等不同的计算平台灵活地为位图连接索引提供更高性能的支持。本文的主要贡献体现在三个方面:
(1)松耦合的自管理位图连接索引
位图连接索引的管理不再是由数据库管理员根据经验进行管理,而是通过查询负载监视和分析模块通过特定的策略提供自适应的索引管理机制。
(2)基于关键字的TOPK位图连接索引机制
内存数据库要求索引具有更高的内存空间敏感性,提出了基于关键字的TOPK位图连接索引来实现指定内存索引空间配额下的细粒度索引管理。
(3)处理器敏感的位图连接索引技术
内存大数据集上的位图连接索引涉及很多超长(数亿位)位图之间的位操作,位图索引运算同样成为内存数据库的性能约束。通过引入多核处理器平台、众核协处理器平台以及内存云平台使位图运算性能通过处理器平台的支持而提升。
2 相关工作
分析型数据库通常采用多维存储模型,即典型的星形模型或雪花形模型。数量众多但数据量较小的维表和位于模式中心的大事实表构成一个多维数据模型:事实表通过外键与维表连接,通过维表上属性定义的层次来描绘多维数据空间上的多维数据分析处理任务。多维查询中的谓词主要用于维表上层次的选择,而查询处理的代价主要集中于大事实表与数量众多维表之间的连接操作,因此索引的主要作用不是加速较小维表上的检索性能,而是要加速维表与事实表之间的连接操作性能。
连接索引[10]是一种面向连接关系的索引结构,它通过预连接将连接表中相应记录对应的地址记录在索引中,当再次执行表连接操作时,可以根据连接索引中的地址对直接访问两个表中具有连接关系的数据,可以看作是物化视图的一种索引表示方法。Oracle的位图连接索引(Bitmap join index)通过位图方式为维表中与事实表连接的字段成员建立连接映射位图,维成员通过与事实表等长的位图记录了其与事实表连接的位置关系,查询可以通过匹配的位图索引直接获得事实表的位置关系,并通过位图与rowid的转换获得事实表连接匹配记录的物理地址,实现在事实表上的直接访问,消除连接代价并减少大事实表扫描代价。位图连接索引可以建立在多个维表和多个维属性上,提供灵活高效的连接优化技术。位图连接索引提供了性能和灵活性两方面的支持:多表之间的复杂连接操作可以通过抽取出谓词对应的列成员位图直接获得在较大的连接表上的连接位置,将I/O代价巨大的大表扫描转换为高效率的按位置访问,极大降低了连接操作中的大表扫描代价;连接索引的输出是标准的位图,从而为用户自定义索引提供了底层支持。内存列存储数据库通常采用内存数组数据结构,位图可以直接映射为列的物理地址,从而使位图连接索引中的位图能够与列建立直接地址映射关系,提高索引访问性能。MonetDB的列代数在执行列连接时生成物化的列间连接索引,记录两个列之间连接记录的OID地址关系,多列连接操作转换为连接索引之间的连接关系。Invisible-join[11]将列间连接索引进一步优化存储为位图,列间连接索引的连接操作转换为多个位图之间的位操作,从而用更加适合现代处理器SIMD计算模式的位图操作替代星形连接操作。
由于多维分析查询主要是基于多维数据立方体的维层次进行的上卷、下钻、切片和切块等操作,维表上的层次属性是多维分析查询中高频访问的字段,因此这些维属性列上的连接索引能够极大地优化星形连接代价。但是位图连接索引是以属性列为单位创建,默认地为属性中所有成员建立连接位图,要求创建位图连接索引的属性是低势集列,即成员数量相对较少。
位图连接索引成为数据仓库星形模型或雪花状模型上一种简单而高效的索引技术,但位图连接索引的存储和更新代价较大,选择和创建索引成为位图连接索引的一个关键技术问题。文献[12-13]首先通过数据挖掘技术对索引候选空间进行剪枝,降低候选索引的优化空间,然后采用贪心算法选择出能够满足空间约束的执行代价最低的候选索引属性。文献[14]采用更加精确的频繁项集数据挖掘技术从给定负载中确定候选索引属性集,通过建立代价模型评估索引创建的代价与性能收益。文献[15]采用最大频繁项集数据挖掘技术进行索引候选属性剪枝,并在访问频率基础上扩展了更多的参数以提高索引候选属性选择的准确性。
数据仓库应用中事实表数据量非常大,分析型内存数据库应用中需要尽可能地提高昂贵内存的利用率,最小化索引等辅助数据的内存空间开销。查询中涉及的维成员往往较为分散,为多个维属性列创建位图连接索引将产生巨大的索引存储开销,而且维属性列成员中只有部分成员属于频繁访问成员,以维属性列为对象的位图连接索引创建方法在索引空间消耗和效率方面还存在着较大的问题,传统的以属性为粒度的索引管理机制难以满足内存数据库存储空间精细化管理的需求。
相对于磁盘数据库,内存数据库索引的CPU运算代价占比较高,因此提高索引运算性能是提高索引可用性的保证。相对于当前较少核数的多核处理器,GPU拥有更高的内存位宽与带宽,其相对较小的高带宽显存(最大6 GB),难以存储大量的原始数据但适合存储较小的索引数据。GDB[16]提出了GPU与CPU混合平台上的关系操作实现技术,GPU上的关系操作性能必须通过并行处理性能和数据在内存和GPU之间的传输代价综合计算。文献[17]测试了多种内存与GPU之间的传输技术,提出了小表驻留GPU内存的外键连接技术,但大表连接属性的数据传输延迟仍然是GPU关系操作的重要性能瓶颈。当前GPU上的优化技术主要集中在关系操作的实现技术上,尤其以星形连接操作为优化的核心问题,但对多维模型上最重要的位图连接索引方面的研究相对较少。位图连接索引计算简单,输出数据为单一位图,GPU有限的内存和强大的并行处理能力使其成为位图连接索引管理和运算的最佳平台。
3 基于关键字的TOP K位图连接索引
3.1 系统架构
图1所示的基于关键字的TOPK位图连接索引查询处理技术将整个查询处理过程分为两个阶段:索引处理和基于位图过滤的查询处理。索引处理是根据用户查询输入的SQL命令独立进行索引计算,如:


框图中where表达式中的c_region和AMERICAN合起来是一个查询关键字,表示在维表customer的c_region字段中值为AMERICAN的成员与事实表具有连接关系。同理,多个谓词表达式分别表示不同维表上不同字段中的成员与事实表具有的连接关系。完成此查询最直接最高效的方法是在查询负载中找到使用频率最高的查询关键字并为这些关键字建立位图连接索引,通过对用户输入的查询命令的解析,以关键字为单位检索是否存在对应的连接位图,然后在选定的位图上执行位AND运算,生成具有全局连接作用的过滤位图来过滤事实表,并根据位图连接索引来剪裁SQL命令中不再需要的连接操作,减少参与实际连接操作的记录数量。索引处理阶段是一个独立的过程,可以将该索引机制作为独立的功能模块附加在数据库之外作为独立的索引服务层,如图1中虚线框部分可以作为独立于数据库之外的索引服务。在基于位图过滤的查询处理阶段,索引生成的过滤位图用于在事实表上进行连接记录筛选,并且根据使用的索引位图将用户原始输入的查询Q优化为查询Q'。在Q'中,如果谓词关键字存在连接位图并且对应维表属性没有出现在分组属性中,如s_region=’AMERICAN’AND(p_mfgr=’MFGR#1’OR p_mfgr=’MFGR#2’)谓词关键字存在连接位图,则索引所生成的过滤位图隐含了事实表与维表supplier和part的连接关系,查询Q'中可以将lineorder与supplier表和part表的连接操作进行剪枝,在缩减事实表扫描代价的基础上将表连接的数量减少到两个。优化后的查询Q'如下所示:

查询优化器设计的难点在于集成了新的索引结构后的代价模型,而在本文中位图操作的代价已知,过滤位图上的选择率为精确值,数据库系统在原有的代价优化模型基础上只要简单增加基于位图的扫描优化即可集成本文的索引技术。
传统的基于属性而创建的位图连接索引在面临存储空间约束时难以有效解决频繁访问属性中非频繁访问属性成员索引利用率低的问题和高势集或非频繁访问属性中频繁访问成员的索引难以创建问题;在面临计算代价估算时难以评估新的存储或处理技术对局部性能优化所产生的收益,如引入SSD存储或GPU等新型硬件存储和加速位图索引计算性能。
本文所采用的关键字位图连接索引是一个数据库对象上的细粒度关键字索引,在索引空间配额的约束下能够根据独立的统计或数据挖掘算法选择TOPK关键字作为索引成员,最大化索引效率。同时,由于索引管理和处理的独立性,索引与不同存储和处理器相结合时的性能可以通过独立的代价模型与数据库自身的代价模型相结合,优化基于索引的查询处理。
3.2 关键字位图连接索引模块功能
图1所示的查询关键字管理模块负责对查询关键字进行监视,具体功能包括从查询中抽取出谓词关键字,记录关键字访问日志,并根据关键字访问日志或关键字访问频率等数据通过统计分析方法确定高频访问关键字,为创建基于关键字的位图连接索引提供候选关键字集。
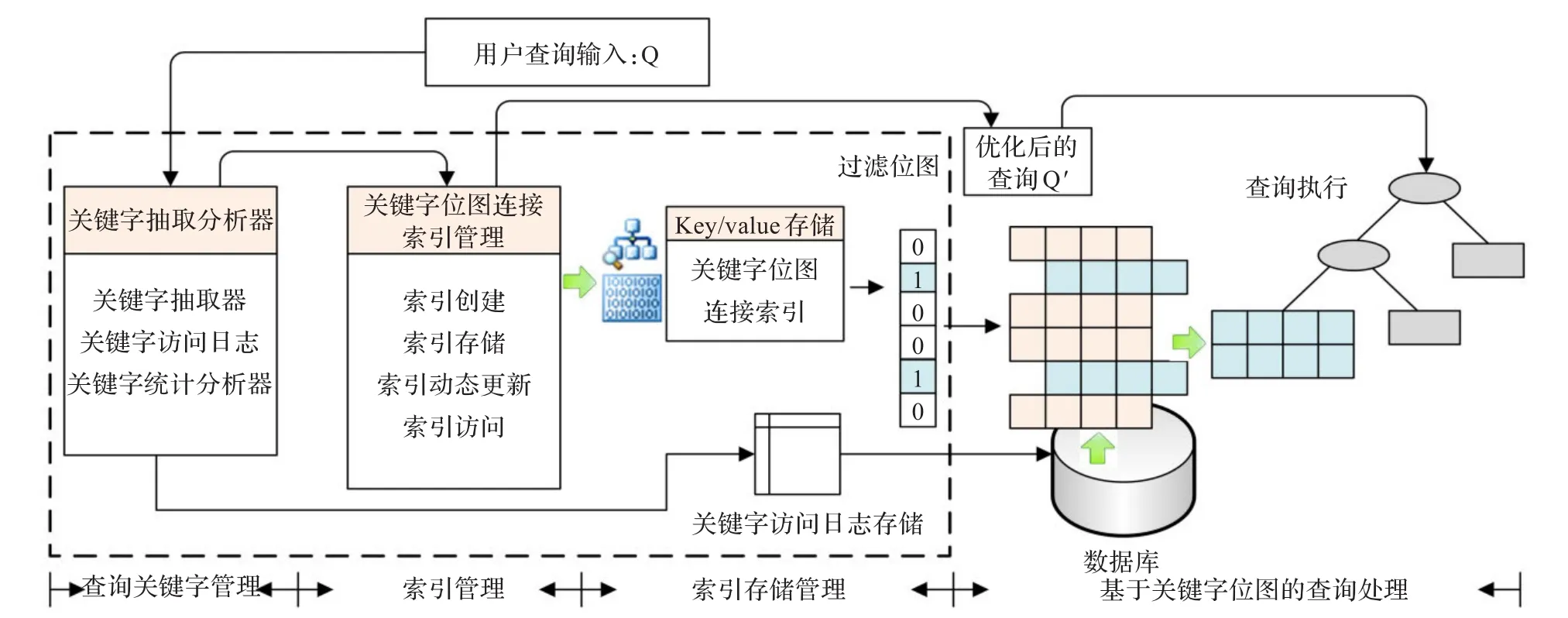
图1 基于关键字的位图连接索引查询优化技术
本文所述关键字指查询中where子句对应的谓词表达式,包括等值谓词表达式和范围谓词表达式,抽象为统一关键字(uniform keyword),具体形式为:表名(前缀)_属性名_操作符_关键字序列,如:
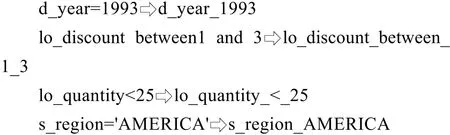
通过统一关键字命名规则,查询关键字为数据库级的全局索引成员,不需要为不同的维表属性独立创建位图连接索引,简化索引结构。
在从查询中抽取出关键字之后,可以将关键字相关信息记录到关键字访问日志中,访问日志可以采用数据库表存储或磁盘日志文件存储。关键字访问日志记录了关键字相关的各种信息,包括关键字名称、时间戳、访问计数等信息,可以周期性地通过统计方法或数据挖掘算法计算出系统TOPK个高频访问关键字候选集。如采用固定时间窗口统计方法可以汇总出各时间段内关键字访问次数,然后通过公式:
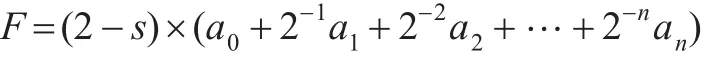
计算出各关键字加权访问频率。其中ai表示每个时间窗口内关键字的访问次数,a0+2-1a1+2-2a2+…+2-nan表示按窗口时间顺序访问频率影响递减策略的加权计算方法,(2-s)则通过关键字选择率s增加影响因子,如选择率为10%的关键字加权值为1.9,选择率为50%的关键字加权值为1.5,优先选择低选择率的高频关键字来加速索引性能。同样可以对关键字访问日志采用数据挖掘方法分析关键字之间的关联访问关系和通过贪心算法计算全局最优TOPK关键字,提高关键字位图连接索引的全局使用效率。本文中主要提出了基于关键字的TOPK位图连接索引服务机制,TOPK关键字选择算法并不作为本文的主要内容。通过查询关键字日志机制记录了查询中的关键字信息,可以在实际应用中增加不同的TOPK关键字挖掘算法来提高索引效率。
3.3 关键字位图连接索引管理模块功能
该模块负责位图索引的创建、存储、更新和访问。本文所述关键字位图连接索引不是为指定的属性列创建位图连接索引,本文所指索引关键字分布在不同表的不同属性中,因此可以集中地批量为离散的关键字创建位图连接索引,也可以将关键字位图连接索引的创建附加在相近的查询处理过程中增量式创建。关键字位图连接索引可以看作是<keyword,bitmap>数据对,可以存储于内存存储结构中,如内存哈希表中,也可以存储于独立的key/value存储引擎,如memcached、Redis等,形成外置的索引存储。基于key/value存储的索引甚至可以与数据库服务器不在相同的节点上或扩展到集群上以提高索引存储能力。与数据库内置的索引结构相比,索引存储代价约束可以进一步放松。索引的动态更新以TOPK关键字加权访问频率的更新计算为基础,确保TOPK个索引收益最大的关键字位图在内存存储。对于TOPK关键字候选集中被替换出的位图,可以根据应用的需求,存储于磁盘存储设备上形成二级索引存储结构,提高已生成连接位图的利用率。与传统的索引技术不同,本文考虑到协处理器内存-内存-外存三级存储层次,TOPK关键字位图连接索引可以进一步扩展为TOPK/M/N模型,其中K<M<N,K、M、N分别表示协处理器内存分配的连接位图配额、内存连接位图配额,外存连接位图配额。TOPN个连接位图被系统根据查询关键字访问频度模型创建,在N个高频关键字中,TOPK个关键字连接位图存储于协处理器内存,第K+1到第M个关键字连接位图存储于内存,最后N-K-M个关键字连接位图存储于外存,即TOPK关键字连接位图索引采用的是三级存储模型。在关键字连接位图更新时,位图在不同的存储层次中升级或降级,直至最终被淘汰。
当用户提出查询请求时,以SQL命令为输入,经关键字位图连接索引处理,输出连接过滤位图。如图2所示,SQL命令中where子句中的谓词按统一关键字命名规则被抽取为关键字,按关键字名称在key/value关键字位图连接索引中检索,当检索到非空位图时,将其抽取出按SQL命令中的谓词表达式转换为位图操作。
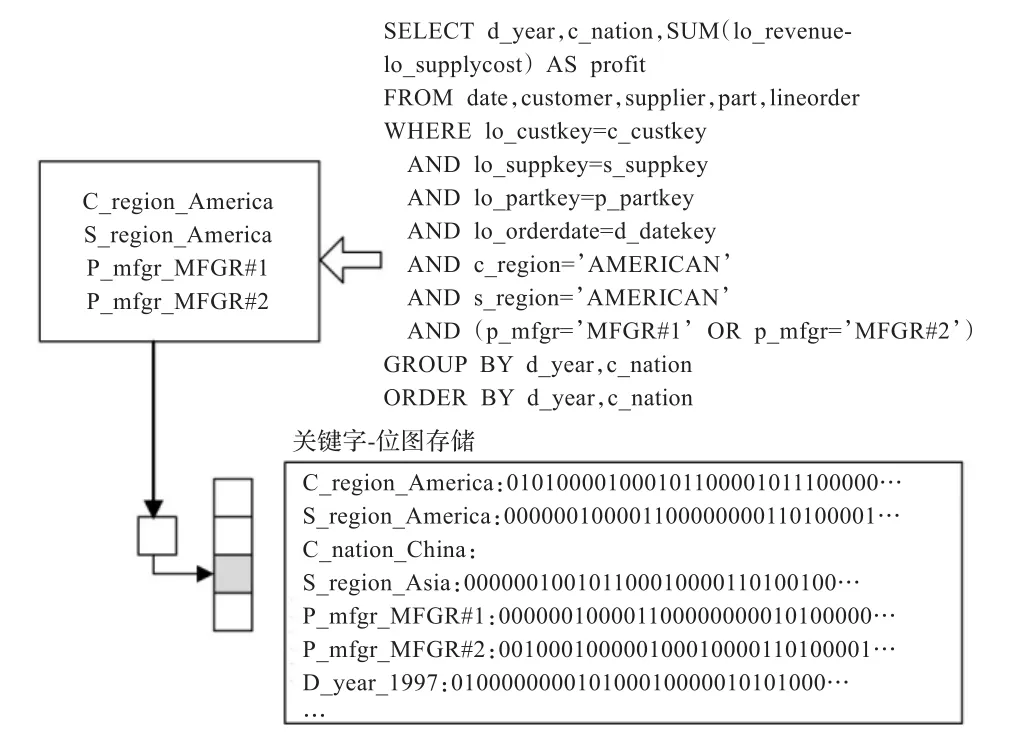
图2 SQL命令关键字位图检索
关键字位图操作对应查询连接树的剪枝或连接操作的约简。当查询中某个维表上所有谓词关键字都存在连接位图且不包含分组属性时,如查询示例中part表和supplier表上的谓词关键字,连接位图的位操作代表了事实表与该维表的连接关系,查询计划中的连接操作可以消除。通过查询关键字位图的检索生成对查询连接操作剪枝后的新查询Q',进而生成原查询的新的执行计划。当查询中同一维表存在多个谓词关键字但在索引中只检索到部分连接位图时,对于AND连接的多个位图通过与操作生成事实表过滤位图,减少连接操作中事实表候选连接记录的数量;当OR表达式中关键字对应的位图不完整时,检索到的关键字连接位图不被使用。将查询中的谓词操作转换为关键字位图操作树,独立于数据库通过关键字检索和树形位图操作生成查询过滤位图,然后将查询过滤位图作为数据库大表的附加过滤器。数据库只需要提供一个位图接口,接收外置索引传递的过滤位图并优化表扫描操作。
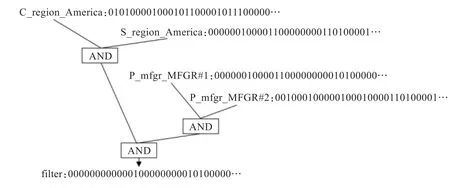
图3 关键字位图操作树
3.4 关键字位图连接索引的自管理
关键字位图连接索引的自管理性表现在如下几个方面:
(1)索引效率自管理
关键字位图索引解决了以属性为粒度创建位图连接索引时,20%位图连接索引属性中20%高频关键字和80%非位图连接索引属性中20%高频关键字的统一索引问题。通过细粒度关键字更好地提高索引效率,通过统一的索引存储优化多个索引的存储和管理开销。
(2)索引空间自适应
在分析型内存数据库应用中,大表上的索引需要巨大的空间开销,对于内存数据库而言,内存每单位存储价格仍然远远高于其他存储设备,因此索引需要自动适应内存空间约束。关键字位图连接索引中的位图长度固定,索引大小取决于关键字的数量,因此可以根据索引的空间约束确定TOPK个关键字连接位图,并且通过实时或周期性的关键字加权访问频率计算更新候选关键字集,动态更新关键字位图。
(3)索引平台自管理
一种新的索引进入数据库系统是一件非常复杂的系统工程,一种索引服务于多种数据库系统将产生较高的重复开发成本。因此,索引独立于数据库成为一种服务是索引平台适应性的表现。基于内存key/value的存储使关键字位图连接索引不仅能够服务于指定数据库,还可以作为集群的共享索引存储,通过内存云扩展索引存储能力。在进一步的研究中,可以将关键字位图操作下压到内存云中计算。如图4左侧虚线框所示,naïve的关键字位图连接索引只利用内存云存储连接位图,而查询关键字检索到的位图需要抽取到索引客户端进行位图操作;可以将关键位图连接索引的位图操作集成进内存云,使其成为一个索引服务,减少位图网络访问代价。
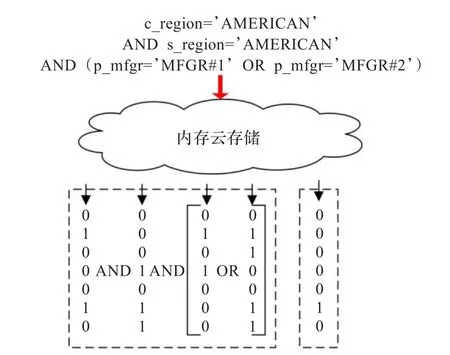
图4 云计算关键字位图连接索引
4 实验与性能分析
4.1 实验设计
关键字位图连接索引可以有多种实现方案,在实验中重点关注位图连接索引对查询性能的优化作用,包括位图操作的代价和位图索引对性能的提升。在实验中模拟了查询命中不同数量索引位图的场景,分别测试了位图操作代价、基于过滤位图的连接代价和查询总时间。
基于关键字位图连接索引的查询优化性能由内存查询处理算法效率和连接过滤位图的选择率决定。DDTA-JOIN[18]是一种基于列存储的星形模型查询算法,与开源内存数据库MonetDB及VectorWise具有类似的性能。在其基础上实现了TOPK关键字位图连接索引,用于分析测试连接索引对多维查询处理性能的优化效率。索引采用内存哈希表方式存储,测试关键字位图连接索引对内存数据库的性能加速作用。
4.2 实验环境
在一台HP ProLiant BL460c G7服务器上完成性能测试,服务器硬件配置为:两个至强6核处理器E5645@2.40 GHz,24物理线程,48 GB内存,300 GB硬盘。操作系统为ubuntu-11.10-server-amd64,gcc版本4.3.4。
使用100 GB(SF=100)SSB数据集,事实表记录600 037 902条。完整地执行SSB的13个测试查询,并与代表性的内存数据库VectorWise(http://www.tpc.org/tpch/default.asp)进行性能对比测试,VectorWise目前还不支持位图连接索引。
图5显示了VectorWise、DDTA-JOIN算法和基于位图连接索引的DDTA-JOIN(简称BJI DDTA-JOIN)算法在13个测试查询上的执行时间。从总体性能来看,DDTA-JOIN平均查询执行时间为VectorWise的49.8%,在关键字位图连接索引的支持下,查询性能进一步提升,平均查询执行时间为VectorWise的24.8%,即位图连接索引能够将查询处理性能提高一倍。对于低选择率的查询,位图连接索引的加速作用尤其突出。
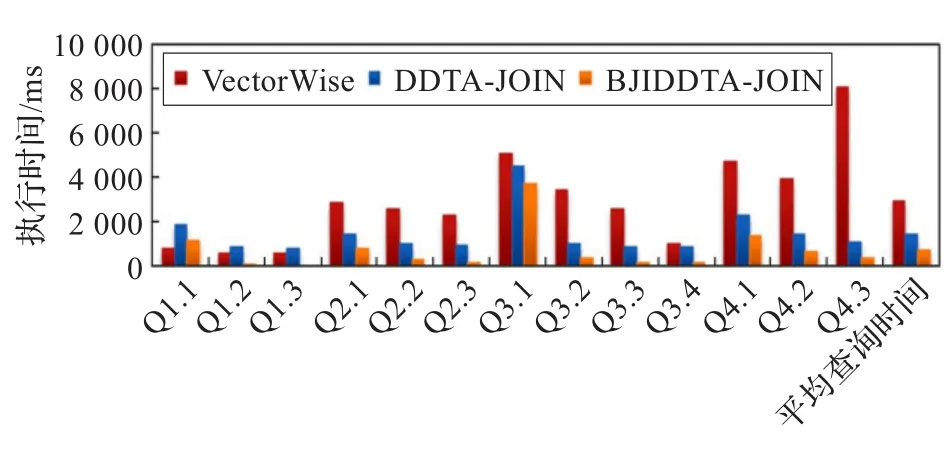
图5 内存数据库SSB性能对比测试
考虑到关键字位图索引存在查询关键字“命中率”以及优化使用TOPK关键字位图的问题,将关键字位图按选择率进行排序,分别选择1、2、3、4个关键字位图进行索引连接优化。表1为使用不同数量关键字位图查询处理时索引阶段位图合并时间和基于位图过滤的查询处理时间,查询总时间为前二者之和。位图合并代价相对稳定:2个位图合并时间约150 ms,3个位图约200 ms,4个位图(Q4.2)约250 ms。基于位图过滤的查询执行时间随位图数量增多(选择率降低)而减少,从总体性能来看,只使用一个位图时查询平均时间略有增长,使用多个位图时查询时间不断降低。
表2列出了查询中位图索引计算占查询处理总时间的比例和在位图连接索引支持下平均查询性能提升的比例。在CPU中,大数据下的位图计算对CPU资源的消耗较高,位图之间的逻辑运算占查询总时间的平均比例随着位图数量的增长而快速增长,在低选择率查询中,如Q2.3、Q3.3、Q3.4中,位图运算代价超过90%。
使用一块中等配置的GPU显卡作为位图连接索引处理器。显卡型号为GeForce 610M,支持CUDA 2.1,配置有1 GB DDR-3内存,48个CUDA计算核心,显卡主频为1.48 GHz,每个线程块支持1 024个线程,GPU与内存之间的PCI-e通道传输速度约为2.5 GB/s。表3给出了GPU进行位图运算和连接过滤位图传回内存的总代价。GPU上的位图运算性能远远超过多核处理器,位图运算达到微秒级,加上压缩的连接过滤图传输代价,平均GPU位图连接索引处理代价也不超过10 ms,远远低于多核处理器上几百到上千毫秒的位图索引运算时间。引入GPU能够极大地提升位图连接索引的性能,索引性能需要通过硬件进行提升。
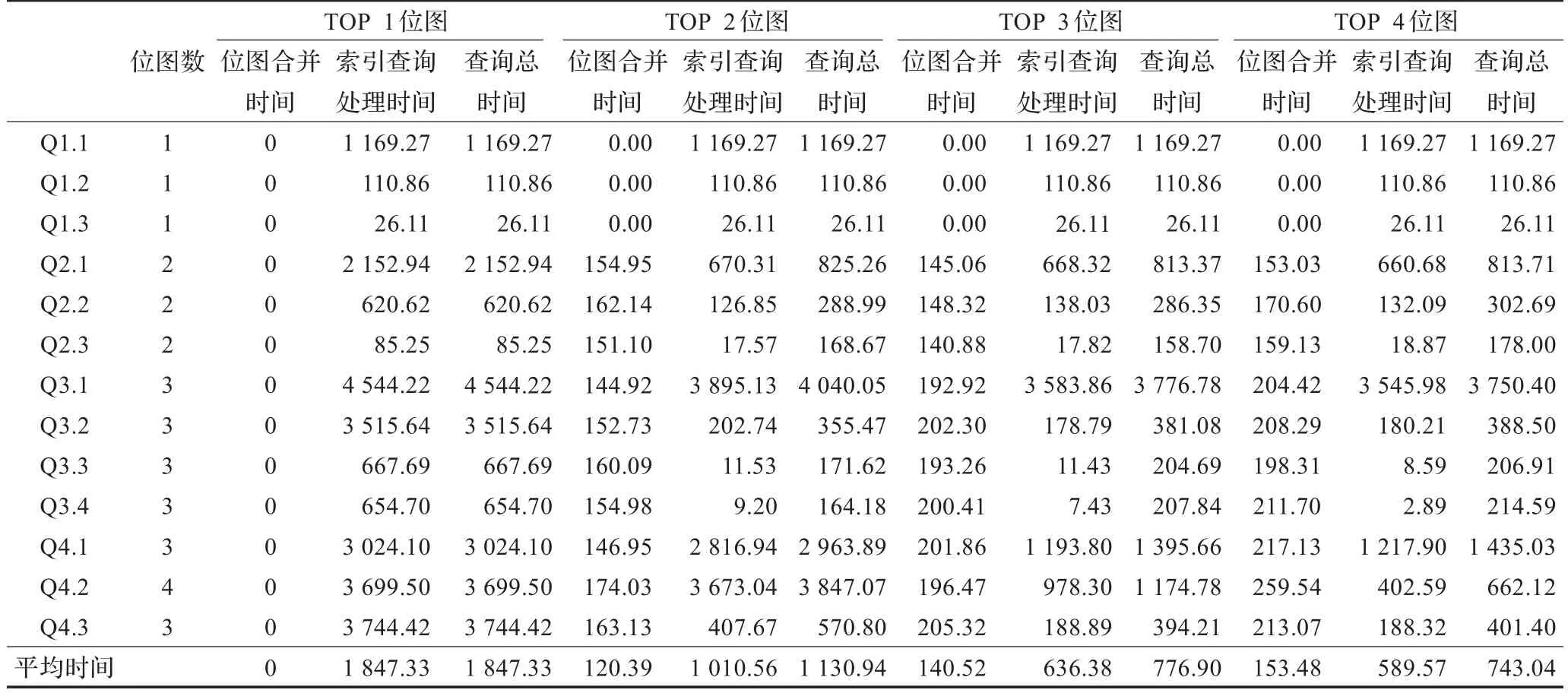
表1 TOP K索引关键字位图连接索引查询优化测试 ms
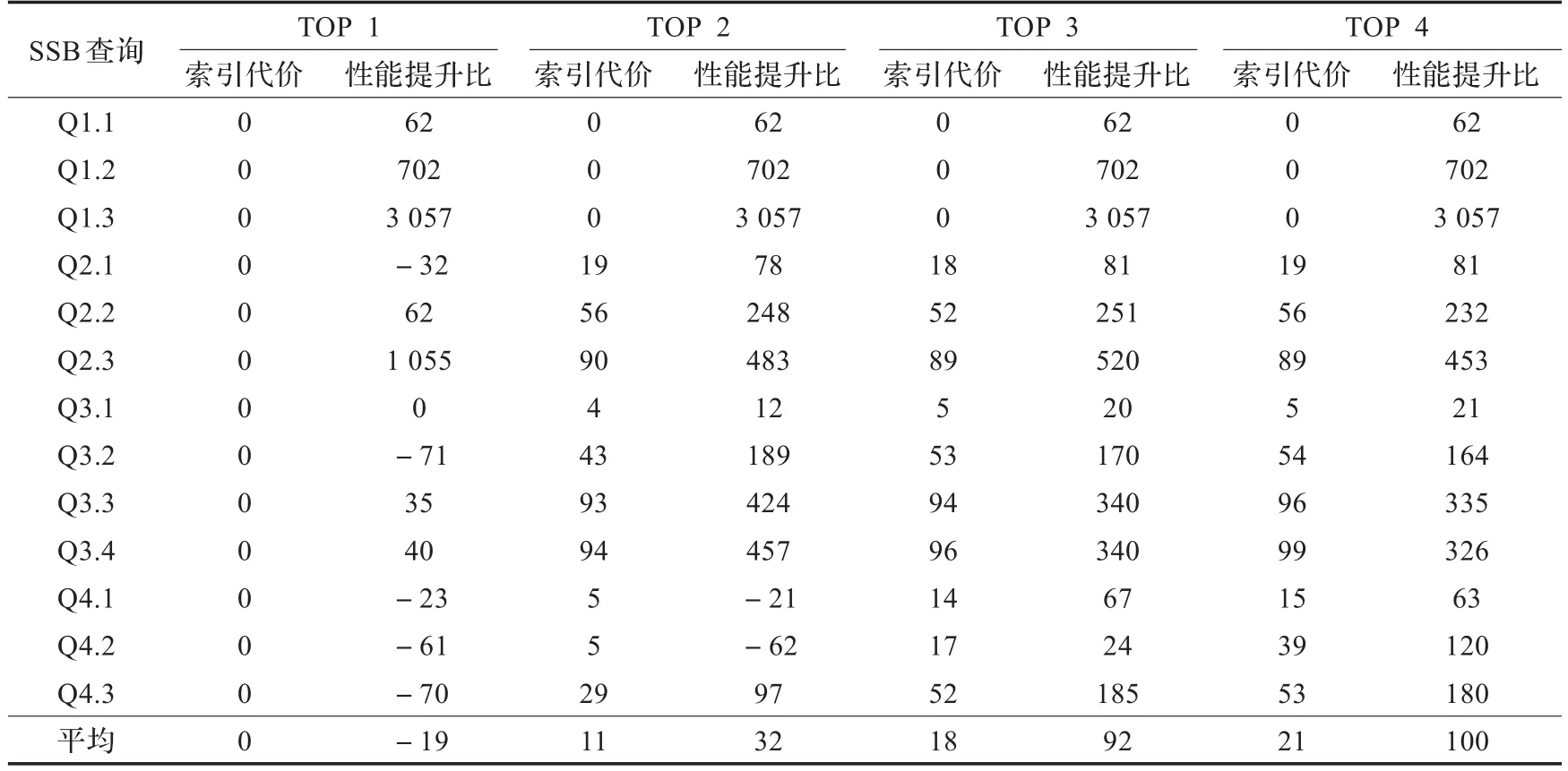
表2 位图计算代价与性能提升收益 %
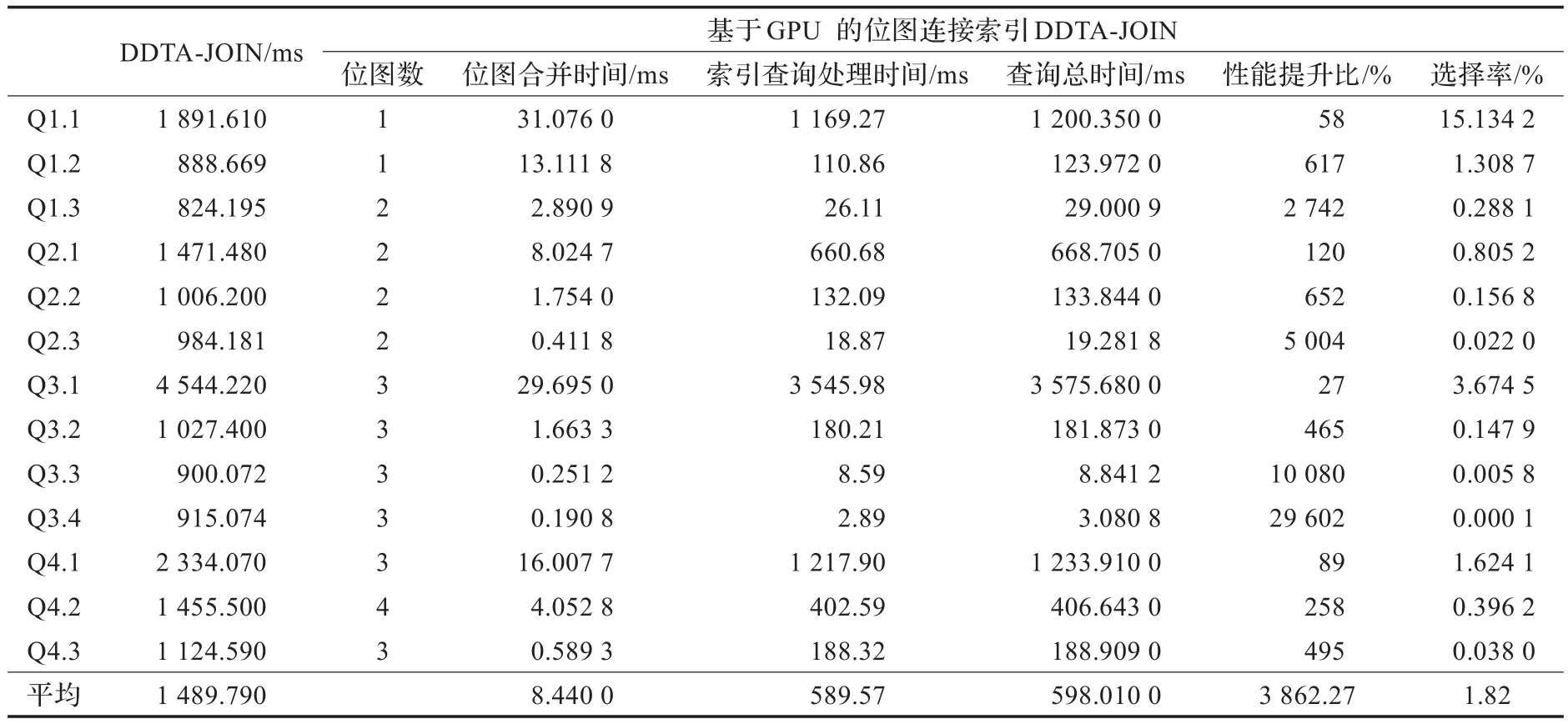
表3 基于GPU的位图计算代价与性能提升收益
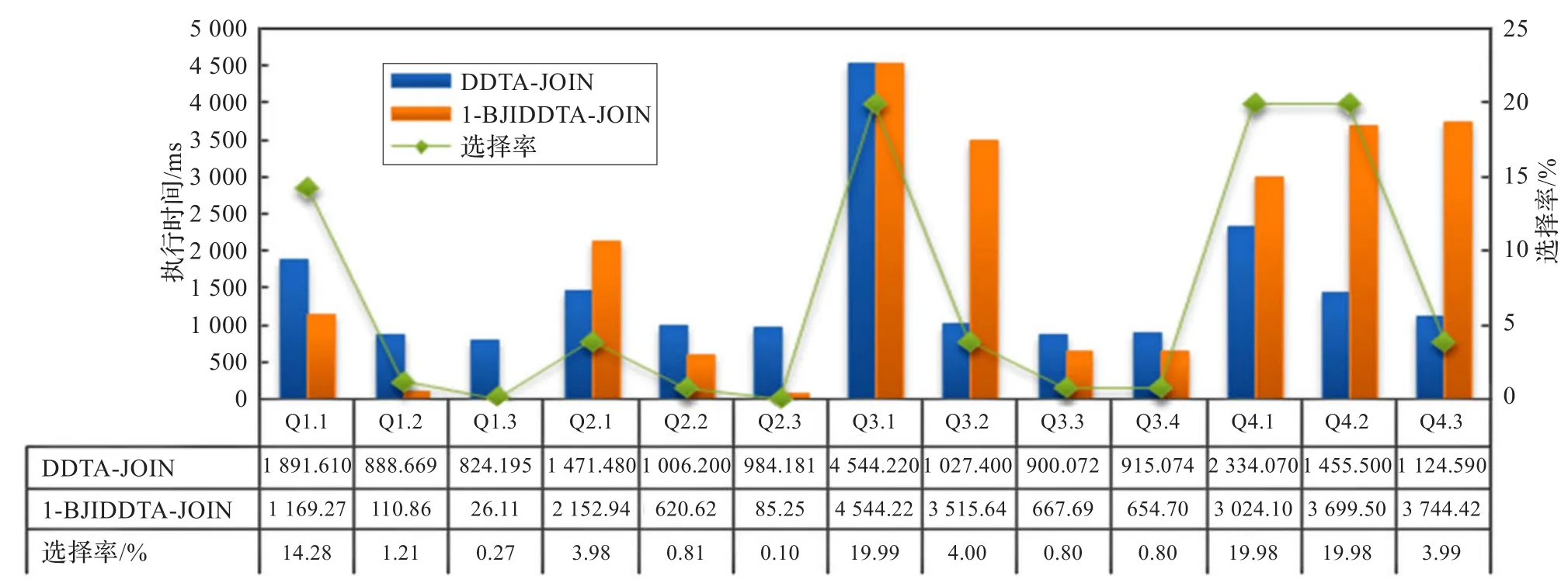
图6 基于单位图过滤的查询性能分析
图6分析了使用一个索引位图时的查询性能。Q1.x查询在事实表上有多个谓词条件,增加过滤位图后使事实表记录访问和计算代价大大降低,因此过滤位图对性能的加速作用明显。其他查询中事实表上没有过滤条件,增加过滤位图相当于附加了额外的判断代价。对于列顺序访问而言,cache line宽度为64 Byte,外键宽度为4 Byte,当选择率低于1/16时,才会对cache line访问效率有较大的影响,因此当位图选择率较高时性能反而有损失。图中观察到,选择率低于0.8%的位图才产生性能收益,可以将0.8%作为关键字选择的一个约束条件。
5 结束语
索引是提升数据库性能的重要手段,但在内存数据库中,索引本身的运算代价同样成为数据库整体性能的瓶颈。索引性能的提升不仅取决于存储平台,还取决于计算平台,索引不再是一个平面结构而是一个层次结构,即索引的存储与处理分布在协处理器内存-内存-外存三级存储,因此需要一个更加灵活独立的索引管理机制。
本文将位图连接索引从数据库中剥离出来构建独立的位图连接索引服务,通过对查询日志的挖掘和各级存储空间的约束构造基于关键字的TOPK位图连接索引机制,独立完成索引的维护、更新和索引运算,通过连接过滤位图和查询改写建立索引服务与数据库之间的松耦合服务层次,为数据库提供独立的索引服务,降低数据库系统在扩展索引结构时的系统升级代价;同时,这种独立的索引服务机制有利于索引充分利用各种新型先进硬件平台以提高索引和数据库的整体性能。
[1]BonczP A,KerstenM L,ManegoldS.Breakingthe memory wall in MonetDB[J].Commun ACM,2008,51(12):77-85.
[2]Zukowski M,van de Wiel M,Boncz P A.Vectorwise:a vectorized analytical DBMS[C]//ICDE,2012:1349-1350.
[3]ZukowskiM,BonczP A.Vectorwise:beyondcolumn stores[J].IEEE Data Eng Bull,2012,35(1):21-27.
[4]TPC[EB/OL].[2013-03-11].http://www.tpc.org/tpch/results/tpch_perf_results.asp?resulttype=noncluster&version=2%¤cyID=0.
[5]Färber F,Cha S K,Primsch J,et al.SAP HANA database:data management for modern business applications[J].SIGMOD Record,2011,40(4):45-51.
[6]ExaData X3[EB/OL].[2013-03-11].http://www.oracle.com/us/products/database/exadata-db-machine-x3-2-1851253.pdf.
[7]Li Zhe,Ross K A.Fast joins using join indices[J].VLDB J,1999,8(1):1-24.
[8]O'Neil P E,Graefe G.Multi-table joins through bitmapped join indices[J].SIGMOD Record,1995,24(3):8-11.
[9]Oracle9/data warehousing guide[EB/OL].[2013-03-11].http://docs.oracle.com/cd/B10500_01/server.920/a96520/indexes.htm.
[10]Valduriez P.Join indices[J].ACM Transon Database Syst,1987,12(2):218-246.
[11]Abadi D J,MaddenS,Hachem N.Column-stores vs.row-stores:how different are they really?[C]//SIGMOD Conference,2008:967-980.
[12]Bellatreche L,Missaoui R,Necir H,et al.Selection and pruning algorithms for bitmap index selection problem using data mining[C]//DaWaK,2007:221-230.
[13]Bellatreche L,Missaoui R,Necir H,et al.A data mining approach for selecting bitmap join indices[J].JCSE,2007,1(2):177-194.
[14]Aouiche K,Darmont J,Boussaid O,et al.Automatic selection ofbitmap join indexesin data warehouses[C]//DaWaK’05,2005:64-73.
[15]Necir H.A data mining approach for efficient selection bitmap join index[J].IJDMMM,2010,2(3):238-251.
[16]He Bingsheng,Lu Mian,Yang Ke,et al.Relational query coprocessing on graphics processors[J].ACM Trans on Database Syst,2009,34(4).
[17]Pirk H,Manegold S,Kersten M.Accelerating foreign-key joins using asymmetric memory channels[C]//Proceedings of International Conference on Very Large Data Bases 2011(VLDB),2011:585-597.
[18]张延松,焦敏,王占伟,等.海量数据分析的One-size-fits-all OLAP技术[J].计算机学报,2011(10):1936-1947.
猜你喜欢
上海农业科技(2022年2期)2022-05-13
华人时刊(2022年1期)2022-04-26
动漫界·幼教365(大班)(2019年10期)2019-10-28
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
农业知识(2016年46期)2017-01-13
中学生(2015年12期)2015-03-01
右江民族医学院学报(2012年4期)2012-01-26
环球时报(2009-11-25)2009-11-25
作文大王·中高年级(2008年12期)2008-12-19
