
基于LapSVM的物流编号图像自动识别算法
2015-02-18 09:31:46曹炯清
物流技术 2015年3期
曹炯清
(贵州电子信息职业技术学院 计算机科学系,贵州 凯里 556000)
1 引言
随着物流需求的快速增长,物流企业的信息管理技术也需要不断的提高。信息化管理需要记录货物各个时期的信息,还要对货物进行跟踪。传统的物流信息管理是以手工录入为主,速度慢、效率低,不利于物流管理。如何快速实现自动识别和信息获取是目前物流企业所关注的重点之一。
目前,条形码识别和射频识别相继出现,成为提高物流管理效率的主要方法。条形码技术是通过快递员对货物标签上的条形码进行扫描,以获取相应的货物信息,这是目前最主要的物流编号识别方法[1]。该方式成本低,方便易行,但是也存在着诸多缺陷,如条形码的信息容量小,信息单一,需要人工干预,识别的距离短等。而射频识别技术利用一个相当于内存卡和发射器的芯片,该芯片记录了产品的信息,能够通过非接触进行识别[2]。该方法具有快速扫描、数据记忆容量大和安全等特点,但是投入成本高。
在物流运输过程中,许多物流企业主要通过识别货物的物流编号来实现对货物的提取、分析和配送工作[3],同时该编号还能记录货物的运输状态,便于企业和客户对货物进行跟踪和查询,所以有越来越多的物流企业开始重视物流编号在物流管理和运作中的作用。若能够自动识别物流编号,同样可以高效地获取到货物的运输信息。
2 基于图像处理的物流编号识别过程
基于图像处理的物流编号识别算法首先需要进行图像采集,以获取物流订单的编号。当传感器检测到有货物进入拍摄区域时,则给采集设备发信号,设备接受到信号后,对货物进行拍照,获取到物流编号图像,如图1所示。接着以采集得到的图像为基础,对其进行图像预处理,如图像去噪和二值化,之后对处理过的图像上的数字字符进行分割,将连续的字符图像切分成为单个字符图像。然后,对分割后的各个数字字符图像进行特征提取,将提取出的特征向量作为输入,用来训练SVM分类器,训练好分类器之后,可以使用该分类器对新输入的数字字符进行分类识别,得到物流编号信息。整个过程可以自动进行,减少人工的干预。

图1 物流编号示意图
该算法过程主要包括图像采集,图像预处理,数字字符分割,字符特征提取,分类器训练与识别,其流程图如图2所示。
2.1 物流编号图像预处理
在图像的采集和传输过程中,由于受到采集设备的影响或者环境的变化,图像会出现噪声干扰的情况,图像预处理阶段能够有效地消除噪声的影响,恢复出有效的信息,增强信息识别的可靠性。预处理过程包括图像去噪和图像二值化。
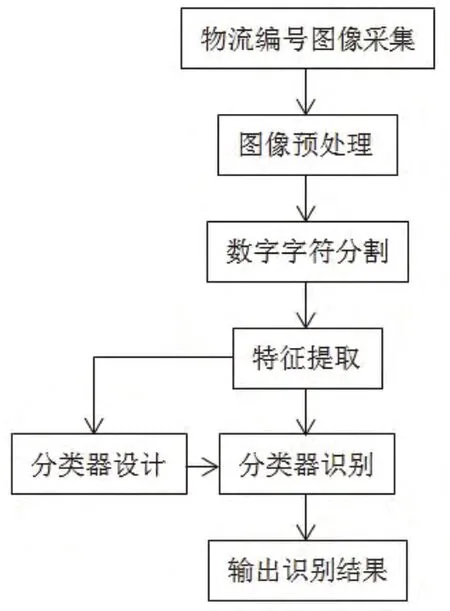
图2 基于图像处理的物流编号识别算法流程图
图像去噪就是要将图像包含的各种噪声滤除掉,中值滤波是一种常用的非线性滤波方法,该方法用某像素的相邻像素区域的灰度中值替代该像素的灰度值,主要作用就是将一些与周围领域像素值相差较大的像素灰度值改为与邻域像素值接近的灰度值,从而去除一些过亮或过暗的像素。中值滤波简单易行,能够有效保留图像的边缘信息,同时起到去除噪声的作用,该算法的步骤如下:
(1)使用一个3×3的模板,沿着行或列的方向移动;(2)每次移动后,对模板内的像素区域进行排序;(3)用排序后得到的中值作为模板中心像素的灰度值。
为了使后续的数字字符分割和单个字符识别有效进行,在对图像进行去噪之后需要进行二值化处理。图像二值化的实质就是阈值分割,首先要选定一个合适的阈值,将图像中的每一个像素点与设定的阈值进行对比,如果小于该阈值,则用0(黑色)来代替原始的像素灰度值;反之,如果大于该阈值,则用255(白色)进行替代。该方法的公式表述如下:

其中,T为预先设定的阈值,f(x,y)为去噪后的物流编号图像,g(x,y)为二值化后的物流编号图像。二值化后的图像只有黑白两种颜色,能够有效地区分出背景和图像的目标,本文中使用白色背景,黑色数字。
2.2 数字字符分割
数字字符分割就是将如图1中的整个字符图像中的每一个字符分割出来,形成单一的数字图像,如果字符分割得不够准确,对后续的特征提取和识别会有很大的影响。快递单上的物流编号中的数字大小一致,在一定程度上降低了分割的难度。
字符分割的算法有很多种,最常用的办法就是通过连通域进行分割。通常情况下,每一个数字都能够构成一个连通域,只要能够找到这个连通域的行与列的起点和终点位置,就可以确定数字的最小矩形,从而实现数字字符的分割。
由于图像采集时照相距离的不同导致拍摄到的数字图片大小不同,因此对分割后的图像进行大小归一化,使这些数字图像成为大小一致的尺寸,利于特征提取时的标准一致。在进行大小归一化的过程中,不能改变数字的拓扑结构,最大程度的减小数字字符的失真,确保识别的正确率。
令v(x,y)为原始图像,v′(x′,y′)为归一化后的图像,两者坐标的映射关系为;

其中,width、width'分别为归一化前后的图像宽度,height、height′分别为归一化前后的图像高度,同时,归一化后(x′,y′)处的灰度值v′(x′,y′)与v(x,y)相等。可以看出,归一化后的点可能为原图像的浮点数处,需要通过插值算法计算其像素值,此处通过双线性插值法将图像归一化为同一尺寸。
2.3 编号特征提取
所谓的识别过程,重要就是依据特征进行判断,故在此之前,需要对数字符号特征进行提取,得到特征向量,然后在特征空间中采取相应的算法对待识别目标的特征进行判别,实现识别的目的。良好的特征应该具备以下几点要求:
(1)可区分性:同类目标的特征向量相似,不同类别的特征向量差异显著;(2)可靠性:所用的特征易于提取,并且具有一定的抗干扰能力和鲁棒性;(3)独立性:各个特征之间彼此不相关,具有独立性;(4)数量少:特征向量的维度往往对分类器的计算复杂度有很大的影响,所以需要提取能够保证分类最少的特征数。
本文使用的是粗网格特征,该特征属于局部特征,又称为局部灰度特征。首先将数字字符图像划分为n×n个网格(如8×8),统计每个网格内目标像素(黑色像素)的数量,得到一个n2维的组网格特征向量,该特征向量表示目标像素在网格中的多少,能够很好的反映出数字的整体结构分布情况,提取出的特征用于后面的识别分类过程。
3 基于LapSVM的物流编号识别算法
3.1 SVM原理简介
支持向量机(Support Vector Machines,SVM)是于1995 年由Vapnik 等人提出的一种机器学习方法,该方法是由统计学习方法发展而来,目的是在训练样本集中找到一个最优超平面,能够将两类样本正确地分开并且使得分类间隔最大。SVM能够解决非线性、小样本和高维数据等问题,并能够推广到函数拟合等机器学习的问题当中,近年来得到广泛的关注与应用,如车牌字符识别[4-5]。
(1)线性可分的情况。如果两类样本可以通过一个线性函数完全分开,则将这些样本称为线性可分的,反之,不能够由一个线性函数分开的样本成为线性不可分的。图3给出线性可分与线性不可分的简单实例。
假设有一个线性可分的样本数据集{ }( )xi,yi,i=1,…,n,样本向量x∈Rd,类标签y∈{ }+1,-1 ,通常+1 为正例,-1 为反例。对样本进行分类就是要确定能使得分类间隔最大化的超平面,设其方程为:

由点到面的距离公式可以得到样本x与超平面间的距离,对f(x)进行归一化使得两类样本中距离超平面最近的样本满足|f(x)|=1,此时最近样本到分类边界的距离为:

图3 线性可分与线性不可分

分类间隔就等于2 ‖w‖,则使得间隔最大与使‖w‖(或‖w‖2)最小等价,对于所有样本分类正确时还需要满足一定的约束条件,则有:
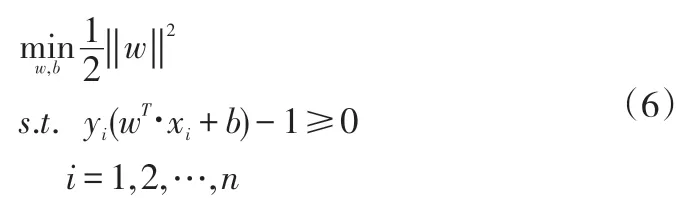
所求的分类面就是最优超平面,那些使式(6)等号成立的样本成为支持向量。图4给出最优分类面的示意图。

图4 最优分类面的示意图
根据拉格朗日乘数法可以得到以下的函数

其中,αi>0 为拉格朗日系数。函数L(w,b,α)分别对w和b求偏导数,令其为零,可以得到下面的形式:

则可以得到最终的优化问题:
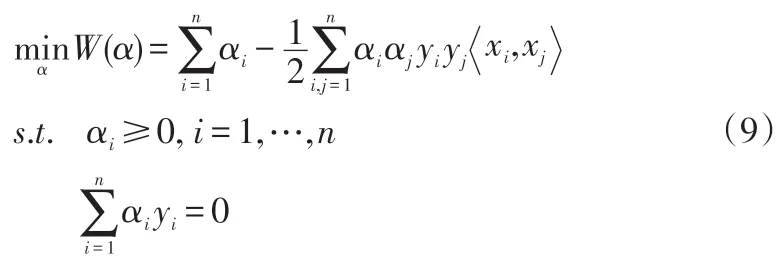
通过求解(9)可以得到最优解α*,再根据α*求得w*和b*,并可以得到最优分类判别函数

将测试样本x代入判别函数中就可以得到分类的结果。
(2)线性不可分的情况。在样本集为线性不可分时,引入松弛变量ξi≥0,允许某些样本点的函数间隔小于1,即在最大分隔区域内,此时得到新的目标函数以及相应的约束条件
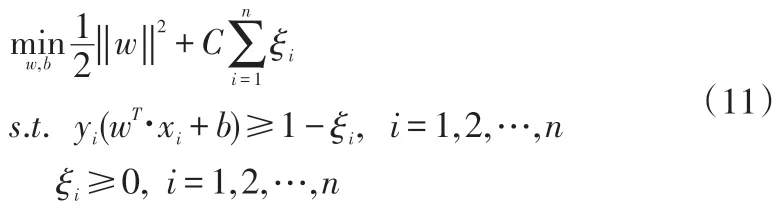
其中,C为惩罚参数,相应的最终优化问题为
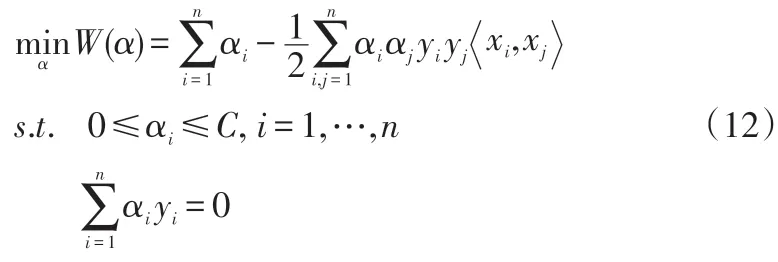
同样在求得α*、w*和b*后可以得到与式(10)形式相同的判别函数。
(3)核函数。核函数的引入能够解决低维空间的线性不可分问题,且在变换到高维空间后,并不需要知道变换的具体形式,因为判别函数中只包括内积运算,所以只需要定义变换后的内积运算。统计学习理论中指出,只要核函数K(x,y)满足Mercer 条件就可以作为某变换空间中的内积进行使用,也就是最优判别函数表示为:
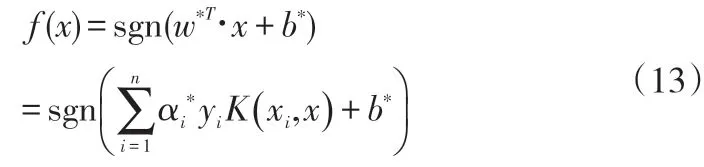
常用的核函数有以下几种:
(1)线性核函数:

(2)多项式核函数:

(3)高斯核函数:

(4)Sigmoid核函数:

支持向量机先通过非线性变换将输入数据集投影到高维空间中,再在这个高维空间内对最优线性分类面进行求解,此过程中不需要知道非线性变换的具体形式,只需知道核函数即可。
3.2 基于LapSVM的多分类算法
SVM 模型能够获得较高的识别,但是需要较多的训练样本。半监督学习是最近机器学习中的一个热点,它能同时利用标记样本与未标记样本的信息,在极少标记样本的情况下,获得准确的识别结果。其原理如下:首先用未标记样本构造一个Laplacian正则项:

其中cij代表样本xi,xj的相似程度。将公式(18)加入(9),得到:

这就构成了LapSVM分类器。
SVM 的提出是用于解决二分类问题,而物流编号识别属于多分类问题。目前,使用SVM进行多分类的方法主要有:一对一(One against one)、一对多(One against the others)和SVM决策树法(SVM decision tree)。由于一对多算法简单且易实现,所以本文选用一对多方法进行物流编号的识别。
一对多方法就是将某一类的样本与其它剩余类别的样本划为两个类别,在这两类中构建超平面,在这种分类算法中,需要构建多个SVM 分类器,每一个分类器用于将某一类与其他类进行分类,将多分类问题转换为多个二分类问题。
物流编号识别当中的数字为0-9,共有10个类别,故需要构造10个SVM分类器。训练之前,需先提取数字字符的粗网格特征,用于训练分类器。在训练第i 个分类器时,将属于该类的样本标记为+1,不属于该类的样本标记为-1。训练时需先选定核函数K(x,y)和惩罚参数C,将训练样本代入SVM 算法中,得到相应的判别函数f(x)。进行数字字符识别时,将提取得到的特征向量输入到每一个分类器当中,循环检查每个分类器的输出。当某个分类器的输出为1时,则输入的数字字符属于该类别;若所有输出均为-1,则拒绝识别该数字。在识别过程中遇到多个分类器输出为1时,则该数字属于第一个输出为1的分类器的类别。
在每类标记样本取成不同数目的情况下,测试SVM 和LapSVM 对1 000 个物流编号图像的识别结果,得到结果见表1。
从结果可以看出:在极少标记样本的情况下,LapSVM 能够取得准确的识别,识别正确率远高于SVM。
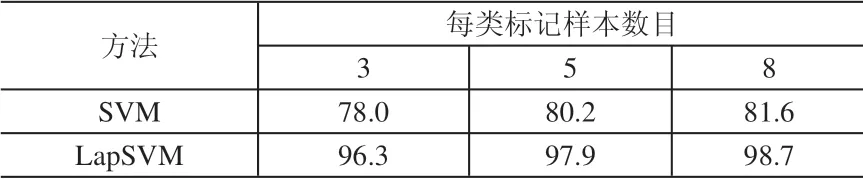
表1 物流编号图像识别正确率(%)
4 结论
物流编号中包含了货物的运输信息,便于客户和企业对货物进行跟踪,本文提出的基于图像处理的物流编号识别算法,对采集到的物流编号图像进行预处理和数字字符分割,对分割后的各个图像提取特征,获得特征向量,用于训练LapSVM分类器,使用训练好的分类器进行编号的分类与识别。该算法简洁高效,能够降低人工干预,提高自动识别效率。
[1]杨长勇.条形码技术在物流生产过程中应用探索[J].信息通信,2011,(3):68-69.
[2]谢勇,王红卫,李再进.基于电子标签的物流路径跟踪系统研究[J].物流技术,2005,(12):27-30.
[3]黄孝平,林雯.基于计算机视觉图像的物流编号智能识别技术[J].网络与信息化,2013,32(3):449-451.
[4]高珊,刘万春,朱玉文.基于SVM的车牌字符分割和识别方法[J].微电子学与计算机,2005,22(6):34-36.
[5]王晓光,王晓华.一种基于SVM的车牌汉字的有效识别方法[J].计算机工程与应用,2004,(24):208-209.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
电脑爱好者(2022年15期)2022-05-30 01:29:23
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
