
基于Hadoop的抄袭检测的源检索方法研究
2015-02-18 03:52:01王素红宁慧王明星徐丽
应用科技 2015年6期
王素红,宁慧,王明星,徐丽
哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001
基于Hadoop的抄袭检测的源检索方法研究
王素红,宁慧,王明星,徐丽
哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001
摘要:随着科学技术的发展和互联网的普及,网络给人们带来便利的同时,也给抄袭剽窃提供了机会,现在抄袭检测已经成为一个重要的研究课题。本文分析了传统抄袭检测系统源检索模块的优缺点,结合分布式系统的特点,提出基于索引分片的源检索体系结构,在大规模数据集上进行抄袭检测研究,以便快速的检测出可疑文档的备选文集。通过实验证明,基于索引分片的源检索结构能够应对大规模数据集的处理要求,有效的提高了源检索阶段的时间性能,同时也保证了抄袭检测系统的可靠性。
关键词:抄袭;抄袭检测;大规模数据集;源检索;Hadoop 分布式源检索模块的主要功能是对大规模备选文档数据集批量的构建索引和接收查询进行分布式检索,最后返回候选文档集。从功能上能看出,分布式源检索模块包括2个子模块:索引更新模块和检索模块,如图1所示。 检索模块接收查询,将查询请求发送到索引库中进行分布式查询,检索接口返回的是候选文档集[11]。

宁慧(1964-),女,副教授,硕士生导师.
随着互联网的发展,大量有价值的学术论文以及资料被发布在网络上的同时,也为文本抄袭提供了便利。文本抄袭是指抄袭者将他人的作品没有修改或者做出少量修改后使用而不做引用说明的行为。抄袭检测是指人们利用计算机各方面的研究技术,检测数字产品是否复制其他数字产品的过程。当前的抄袭检测系统存在很多问题。大规模备选文档数据集上的抄袭检测系统研究尚不成熟。随着抄袭检测的备选文档数据集的迅速增长,基于单机的抄袭检测系统已经无法满足大规模数据集的存储需求和计算力需求,如何使抄袭检测系统能够适应大规模数据集,从大规模数据集中获取与可疑文本相似的抄袭片段,有待进一步研究。
针对以上问题,文中提出了基于Hadoop[1]的抄袭检测方法,使得抄袭检测系统在数据存储和计算资源上能够应对大规模的备选文档数据集。
1相关技术介绍
1.1Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以HDFS[2]和MapReduce[3]为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统;MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Apache Hadoop的流行与大数据处理的兴起关系密切。众所周知,现代社会的信息量增长速度极快,这些信息里又积累着大量的数据,其中包括个人数据和工业数据。预计到2020年,每年产生的数字信息将会有超过1/3的内容驻留在云平台中或借助云平台处理。人们需要对这些数据进行分析和处理,以获取更多有价值的信息。为了高效地存储、管理和分析这些数据,可以选用Hadoop系统,它在处理这类问题时,采用了分布式存储方式,提高了读写速度,并扩大了存储容量。采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效。与此同时,Hadoop还采用存储冗余数据的方式保证了数据的安全性。
1.2 实验评测方法
该实验所使用的评价函数是信息检索领域常用评价函数,分别为精确率(precision),召回率(recall)和F1值[4]。在抄袭检测的源检索阶段主要使用这3个评测指标来进行评测。精确率是用来衡量检索出来的数据的准确性,计算方法是正确的结果数与检索返回的总数目的比值。召回率是用来衡量可以成功检索到相关文本的可能性,计算方法是检索到的正确的数据个数与标准答案所提供的总的相关个数的比值。F1值可以平衡地反映召回率与准确率。F1值的公式如式(1)所示:
(1)
式中:R是召回率:
(2)
其中:P 是精确率:
(3)
其中:TP是指系统检索到的相关文档;FP是指系统未检索到的相关文档数;FN是系统检索到的不相关的文档数;F1值是调和函数,用于平衡召回率和精确率的值,是系统的最终评价指标。
2源检索模块研究
2.1基于索引分片的源检索研究
文中提出基于索引分片的源检索模块结构。分布式检索的基础是分布式索引[5],即逻辑索引被划分成很多子索引,且这些子索引部署在不同的服务器上[6],利用Hadoop可以实现分布式检索模块[7]。
该检索模块充分地利用了基于Hadoop的分布式集群所提供的存储能力、计算能力,并且保证了源检索模块的高可靠性。
基于索引分片[8]的源检索模块结构也把备选文档数据集的逻辑索引划分成多个子索引,每个子索引会有多个副本索引,所有的副本索引会被部署在Hadoop分布式集群的源检索服务器上。在文中采用Apache Zookeeper集群协调和管理分布式集群。

图1 基于索引分片的源检索模块
2.2索引更新模块
索引更新模块接收备选文档数据集,批量构建索引并部署到分布式集群中,将索引存储在源检索服务器上。集群中每个源检索服务器可以包含多个处理单元,每个处理单元能独立的提供索引更新或检索功能[9]。索引更新模块负责增量索引、文档的删除等。
源检索模块索引更新流程如下:
1)客户端把需要索引更新的数据提交到服务器集群,集群中与逻辑索引相关的任一副本索引节点都有可能接收到更新请求。
2)如果该副本索引节点不是对应的子索引的主节点,它就会把更新请求转发给和自己是同一子索引上的主节点。
3)主节点把备选文档数据的更新请求转发给同一子索引的所有其他副本索引节点,所有节点都要执行更新请求。
4)如果备选文档数据的更新请求基于转发规则并不属于当前子索引,主节点会把它转交给相应的子索引的主节点。
5)对应的主节点会把备选文档数据的更新请求转发给该子索引的所有其他副本索引节点,所有的副本索引节点都需要执行更新请求。
分布式源检索模块中的子索引主节点接收到备选文档集数据的更新请求后,必须确定当前更新请求属于逻辑索引的哪个子索引。在基于索引分片的源检索模块中,负责分布式更新逻辑处理中的是一个Hash算法[10],由此来决定更新记录具体分配到哪个子索引。算法代码如下所示。
private int hash(AddUpdateCommandcmd) {
String hashableId = cmd.getHashableId();
return Hash.murmurhash3_x86_32(hashableId, 0, hashableId.length(), 0);
}
private int hash(DeleteUpdateCommandcmd) {
return Hash.murmurhash3_x86_32(cmd.getId(), 0, cmd.getId().length(), 0);
}
其中cmd.getHashableId()方法返回的是备选文档集数据的主键的值,通过其hash值定位更新到哪个子索引。
2.3检索模块
源检索模块会把逻辑索引划分成多个子索引,客户端向源检索服务器集群中包含这个逻辑索引的任意源检索服务器发出检索请求此请求会被处理成多个子查询分发到逻辑索引的各个子索引节点上。多个子索引源检索服务器的检索结果返回给最初的服务器汇总后,将检索结果返回给客户端。
源检索模块的分布式检索流程如下:
1)客户端向分布式源检索服务器集群发送检索请求,含有该逻辑索引的任意源检索服务器都有可能接收到该请求,源检索服务器的内部处理逻辑会把查询请求转发到一个其他的副本索引节点。
2)这个副本索引节点启动源检索分布式查询,根据子索引的个数,将查询转化为多个子查询并把每个子查询定位到对应子索引的任意一个副本索引节点上。
3)接受检索请求的副本索引节点返回各自的查询结果。
4)最初的源检索服务器节点合并这些子查询,并把最终结果返回给客户端。
在分布式源检索模块检索时,多个查询在分布式索引中并行地进行检索,减少了串行检索的时间。
3实验设计与实验结果分析
3.1实验设计
PAN@CLEF2012国际评测训练数据集涵盖了较为常见的多类抄袭案件:no obfuscation、artificial low、artificial high、simulated paraphrase和translation 5大类。本实验采用Pan2012的训练数据集,参考文档是4 210篇,可疑文档是1 804篇。实验的第一部分,针对每一种可疑文档抄袭类型,随机地选择20篇可疑文档,总共20×5篇可疑文档,与4 210篇参考文档一起,作为本章的实验数据的一部分,验证基于索引分片的源检索模块的性能。
实验分为备选文档集索引的创建、可疑文档文本预处理、检索相关文档和性能评测4个步骤:
1)备选文档集索引的创建
对于训练数据集中的参考文档集,按自然片段建立索引。当文档集很大时,可以利用MapReduce计算框架批量构建索引方法创建索引。
2)可疑文档文本预处理
对可疑文档进行预处理,包括停用词的移除、大小写字母转化和词干提取。
3)检索相关文档
在源检索模块的检索阶段,文中在不同结构的源检索模块上进行测试。首先将索引部署在基于单机索引的源检索模块上,调整检索的各项阈值,如提交查询个数的阈值,使源检索模块的性能达到最优。其次,扩展源检索模块的数据节点为4、5、6,将索引部署到基于索引分片的源检索模块上,调节数据参数使分布式源检索模块的性能达到基于单机的源检索模块的水平。返回各种情况下性能指标、时间开销等。
4)性能评测
根据1.2节中提出的评测方法,对获得的相关文档进行评测。
本实验基于Pan@CLEF2012的评测标准和指标,测试在Hadoop分布式平台上,基于索引分片的源检索模块在训练数据集上的性能表现。实验还测试了基于索引分片的源检索模块结构与基于单机的源检索模块结构,在处理大规模备选文档数据集上的时间效率对比。
3.2实验结果与分析
实验的第1部分,不同的源检索模块体系结构得到实验结果如表1所示,参加对比的源检索模块结构分别是基于单机索引的源检索模块结构和基于索引分片的源检索模块结构,分布式环境下的数据节点分别扩展为4、5、6台源检测服务器。表1中展示了6种数据集下的源检索结果,分别是数据集1(no obfuscation)、数据集2(artificial low)、数据集3(artificial high)、数据集4(simulated paraphrase)和数据集5(translation),以及将所有数据合并后的总的数据集数据6(All Data)。表1中的F1值是指最终的系统对比指标,R指的是召回率,P指的是精确率。

表1 不同源检索模块结构检索的实验结果
由于表1所示的检索结果中R和P的值太小,将其放大100倍。在实验中,基于单机的源检索模块结构的各个阈值经过调节后,F1值在各个数据集可以达到最优。由表1的实验结果可知,基于索引分片的源检索模块的各项阈值经过调节后,在不同规模集群的F1值性能也可以达到基于单机索引的源检索模块的水平。
由表1中的检索结果可以看出,对于相同的数据集,基于索引分片的源检索模块结构的F1值可以达到基于单机索引的源检索模块结构的最优性能;同一种源检索结构在不同的数据集,性能效果也是不一样的。因此,在Pan@CLEF2012的训练数据集上,基于索引分片的源检索模块可以达到基于单机索引的源检索的最优性能。该实验主要考察了4种不同的源检索结构的模块的性能指标,由实验结果可知,基于索引分片的源检索模块可以达到基于单机索引的源检索结构模块的最优性能。实验证明在基于Hadoop分布式平台上,基于索引分片的源检索体系结构在性能上可以应用于抄袭检测系统上。
在实验的第2部分中,实验数据使用ClueWeb09[12]的英文文档作为备选文档集。实验中随机选择若干篇英文文档组成5个不同规模的数据集,和实验第一部分的All Data一起组成本实验的6个数据集,测试在大规模备选文档集上4个源检索模块的时间效率。实验数据集信息如表2所示。
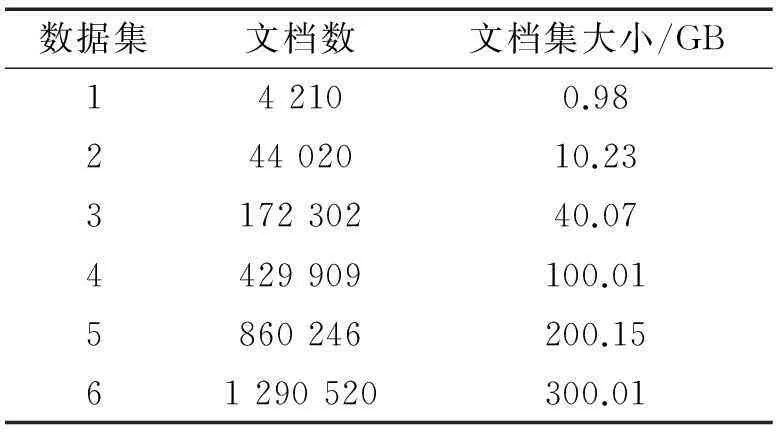
表2 较大规模的备选文档集数据
表2中数据1为第一部分实验的All Data数据集。本实验用第一部分在数据6上获得的源检索模块参数模型来测试时间效率。首先需要将这些数据在基于单机的源检索模块和基于索引分片的源检索模块(分别扩展为4~6台源检索服务器)上创建备选文档集数据的索引;其次在训练数据集可疑文档中随机选取100篇作为查询。测试结果如表3。

表3 源检索模块时间测试结果
实验证明了在Hadoop分布式平台上,基于索引分片的源检索模块可以应对抄袭检测系统中大规模数据集的问题。
4结束语
针对当前的抄袭检测系统无法处理大规模备选文档数据集的问题,本文提出了基于索引分片的源检索结构。实验结果表明,基于索引分片的源检索模块在精确性、召回率、F1值等性能指标上可以达到基于单机的源检索模块的性能水平,在性能上满足抄袭检索系统的要求。随着备选文档数据集规模的增大,基于索引分片的源检索模块的时间开销增长速度相对比较平稳,这说明了基于索引分片的源检索模块通过扩展集群规模在处理大规模数据集时完全有效。
参考文献:
[1]Hadoop.Apache Hadoop[EB/OL]. [2011-12-27]. http://hadoop.apache.org.
[2]BORTHAKUR D. The hadoop distributed file system: Architecture and design[Z]. Hadoop Project Website, 2007: 1-10.
[3]DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. In Proceedings of Operating Systems Design and Implementation (OSDI), San Francisco,USA,2004, 51(1):107-113.
[4]POTTHAST M, GOLLUB T, HAGEN M, et al. Overview of the 4th International Competition on Plagiarism Detection[C]//CLEF 2012 Conference and Labs of the Evaluation Forum. Rome, Italy, 2012: 1-9.
[5]XU Jinxi, CALLAN J. Effective retrieval with distributed collections[C]//Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA, 1998: 112-120.
[6]ICHIKAWA Y, UEHARA M. Distributed search engine for an IaaS based cloud[C]// 2011 International Conference on Broadband and Wireless Computing, Communication and Applications (BWCCA). Washington D C, USA, 2011: 34-39.
[7]封俊. 基于Hadoop的分布式搜索引擎研究与实现[D]. 太原: 太原理工大学, 2010: 35-53.
[8]苏宇. 基于Hadoop的分布式全文检索及相关技术研究[D]. 合肥: 中国科学技术大学, 2014: 22-38.
[9]PARO A. ElasticSearch cookbook[M]. Bermingham: Packt Publishing Ltd, 2013: 5-25.
[10]吴炜, 苏永红, 李瑞轩, 等. 基于DHT的分布式索引技术研究与实现[J]. 计算机科学, 2010, 37(2): 65-70.
[11]吴雪琴, 舒晓苓. 基于云计算的大数据信息检索技术研究[J]. 电脑知识与技术, 2014, 10(10): 2388-2390.
[12] Lemur. ClueWeb[EB/OL]. [2009-2-24]. http://lemurproject.org.
网络出版地址:http://www.cnki.net/kcms/detail/23.1191.U.20151206.1018.016.html
Research on the source retrieval method of
plagiarism detection based on Hadoop
WANG Suhong, NING Hui, WANG Mingxing, XU Li
Department of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China
Abstract:With the development of science and technology and the popularity of Internet, the network has brought us convenience, as well as the opportunity for plagiarism. Plagiarism detection has become an important research subject. By analyzing the advantages and disadvantages of source retrieval of the traditional plagiarism detection system, in combination with characteristics of the distributed system, this paper proposes a source retrieval system structure based on the index slice, so as to retrieve candidate documents from massive data sets. Experimental results show that, the source retrieval structure based on the index slice can deal with massive data set. It can effectively improve time performance of source retrieval, and also guarantee the reliability of the plagiarism detection system.
Keywords:plagiarism; plagiarism detection; massive data sets; source retrieval; Hadoop
通信作者:宁慧,E-mail:ninghui@hrbeu.edu.cn.
作者简介:王素红(1986-),女,硕士研究生;
基金项目:国家自然科学基金资助项目(61201084).
收稿日期:2015-03-27.网络出版日期:2015-12-06.
中图分类号:TP311
文献标志码:A
文章编号:1009-671X(2015)06-067-05
doi:10.11991/yykj.201503030
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
中国新闻周刊(2021年26期)2021-07-27 04:02:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
火控雷达技术(2018年4期)2019-01-15 05:07:22
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
雷达与对抗(2015年3期)2015-12-09 02:38:50
