
一种采用双向有序链表存储的动态编码位图索引方法
2015-02-15 11:08:02王书海刘桂兰綦朝晖
石家庄铁道大学学报(自然科学版) 2015年2期
王书海, 刘桂兰, 綦朝晖
(1.石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043;(2.河北省大型结构健康诊断与控制实验室,河北 石家庄 050043)
0 引言
数据量的快速增长对数据检索效率提出了新的挑战。索引被证明是用于提高数据检索效率的关键技术,而位图索引依据其独特的位向量编码方式,在数据检索中得到广泛使用。位图索引按其编码处理方式可分为简单位图索引和编码位图索引。
简单位图索引依据其简单的编码方式即位向量,使其可以充分利用计算机逻辑运算的能力。简单位图索引中属性值的编码位数和属性基数有直接的关系,存储空间和查询时间都与基数成正比[1-2]。同时也可以看出其弊端,当属性基数很大时,位串就会比较长,在时间和空间上开销都会很大。针对该问题学者们提出了很多数据压缩技术,诸如WAH、BBC、分段编码,以及将WAH 和分段编码相结合的方法等[3-5]。但压缩率与0和1位串的连续分布性有直接关系,并没有使编码空间得到充分的利用。
编码位图索引是通过对简单位图索引位串中只有一个1、多个0的情况进行改进,其位数等于先对属性的基数进行对数运算,然后将其向上取整的结果[6-7]。现有的编码位图索引方式是采用对属性进行静态的编码,这样在使用数据表之前,属性所有取值情况的编码值都已经存在,并且在修改数据表时,即使没有某属性值也会为其分配编码值,在一定程度上浪费了存储空间。另外,目前已有的编码位图索引技术大都是基于B+树建立的索引存储结构[8-9]。B+树凭借其平衡的数据结构使其在查找过程中可以充分利用二分查找的方式提高其检索效率,从而得到了大家的认同。但在B+树结构中除了含关键字信息外,还增加了非叶子节点中的索引信息。当查询数据时,即使非叶子节点的关键值等于查找值,也必须搜索到叶子节点才完成检索操作。例如Value从1到10,节点长度为3的B+树的组织结构如图1所示。

图1 基于u检验方法的状态检修流程图
从图1可以看出,使用B+树结构存储数据,不仅需要存储所有数据节点,同时增加了标识数据最值的边节点。
本文提出一种新的双向有序链表存储的动态编码位图索引方法(BLS-DEBI,Dynamic Encoding Bitmap Index by Bi-ordered List Storage)。该方法在索引存储结构上,采用双向有序链表结构存储索引以节约存储空间,在位图编码方式上,采用动态编码的方式对位图索引进行编码以减少编码位串长度。
1 动态编码位图索引方法
1.1 基本原理
采用双向链表存储的动态编码位图索引方法指的是对建。立索引的属性采用动态编码的方式赋予编码值,并将其存储在映射表中。同时,使用双向有序链表存储索引及其物理位置的对应关系。通过该方法,在很大程度上改善了简单位图索引空间利用率不足的问题。同时由于编码仍采用二进制编码的方式,仍可利用计算机逻辑运算的优势。
动态编码位图索引。映射表初始状态为空,随着数据元组的插入,需要建立索引的属性列F 取值情况增多。在维护属性列F索引信息时,根据刚插入的记录在属性F 上的投影V(F),首先遍历映射表,查看是否已有V(F)对应的编码值,若不存在,则需要判断属性值增加前和增加后标识位长度是否相同,如果相同则直接将映射表中最后元组的编码值二进制表示加1即为新编码值,否则首先在已有的编码值前加0以保证编码位数相同,再将映射表中最后元组的编码值二进制表示加1的结果赋予新的元组编码值,并将V(F)和编码值对应关系添加到映射表中。
采用双向有序链表存储编码值。在最初状态,数据表为空,此时链表也为空。随着数据元组的插入,需要建立索引的属性列F 取值情况增多。在维护属性列F 索引信息时,根据刚插入的记录在属性F 上的投影V(F),首先遍历映射表,查看是否已有V(F)对应的编码值,如果已经存在,则查询链表,找到对应编码值,直接将其物理位置标识(如主键)记录到对应节点内。否则需要首先在映射表中增加新编码值,同时在链表中新增节点,存储索引值和元组的对应关系。具体操作见例1。
例1:假设存在一个学生基本信息表T(学号,性别,省份)。不失一般性现分别对性别、省份列建立位图索引。设属性的基数用C(属性名)表示,编码需要的位数用L(属性名)表示。
现针对省份信息建立索引。目前中国省份属性共有34个不同值,如果采用简单位图索引需要34位位串表示,若采用静态编码位图索引,则默认每个属性值需要log234=6位位串,索引压缩率为34/6。若采用BLS-DEBI的方式,则仅需要log2Dis(F)位位串,其中Dis(F)表示表中已有的属性列F(这里F代表省份)取值的无重复个数,Dis(F)的最大取值为属性F 的所有取值情况C(F)。存储结构如图2所示。将属性基数和位串位长度建立函数关系,简单位图索引可表示为L(F)=mC(F)(m 表示编码压缩率,0<m≤1)的形式。编码位图索引可简单的表示为L(F)=m log2C(F)(m 表示编码压缩率,0<m≤1)的形式,如图3所示。
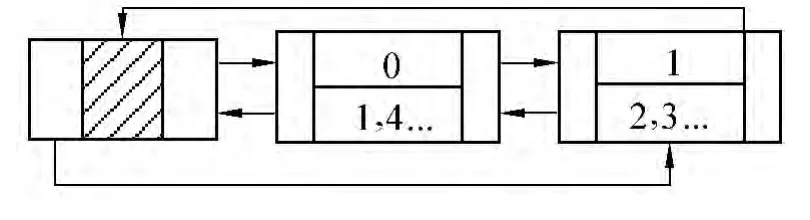
图2 存储省份属性使用的双向有序链表结构
由图2,图3可知,①采用双向有序链表存储索引,查询操作只需在链表结构中利用二分查找法搜索即可得到满足条件元组的主键值;②编码位图索引所需位串长度L(B)比简单位图所需位串的长度L(S)小(且BLS-DEBI所需位串长度的最大值为静态编码位图索引所需要的位串长度)。假设某数据表中元组总数为n,则若使用BLS-DEBI,整个数据表可以节省空间大于等于n(L(S)-L(B));③随着属性基数值的增大,编码位图索引位串长度的变化率远小于简单位图索引位串长度的变化率。
1.2 BLS-DEBI的使用范围
假设某数据表中元组总数为n,现要为属性F 建立索引。属性F 共有m 种取值可能(即属性F 的基数为m),磁盘每页存储数据量的大小为p,B+树的阶数为m2。若要在该属性上建立简单位图索引,则需要存储空间;若建立B+树索引,则需要存储空间若采用静态编码位图索引,则需要存储空间其中log2m表示每个编码的长度;若采用BLS-DEBI所需要的存储空间小于等于采用静态编码位图索引所需要的存储空间。将简单位图索引所需空间和编码位图索引所需空间比较得知,S3要远小于S1,尤其是在数据量较大的情况下。
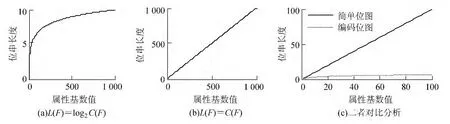
图3 两种位图索引增长率的比较
现假设磁盘页大小p=4K,B+树的阶数m2=512,则计算出当n>log2m ×m÷90时,B+树所需存储空间比编码位图索引所需的存储空间多。通常认为,需要使用编码位图建立索引的数据表,其元组数量n要远大于m。
2 BLS-DEBI的创建
BLS-DEBI主要由两部分构成,一部分是用于存储实际属性值和编码值对应关系的映射表,另一部分是用于存储索引编码值和数据表记录对应关系的链表。所以在创建BLS-DEBI时,需要对这两部分都进行考虑。
例2:关于学生基本信息表的假设同例1。设现在共有5条元组信息,其中RId表示对应元组所在的行号RowId,E_Sex、E_Prov不是表中属性,而是分别对性别和省份信息根据编码位图索引的规则生成的相应元组信息的编码值。现假设学生基本信息表如表1所示。
针对性别属性列,若采用简单位图索引则可将性别为男和女分别编码为0和1;针对省份属性列可编码为河北(00)、湖北(01)、山东(10)、北京(11)。
针对省份属性信息建立的BLS-DEBI存储结构如图4所示。
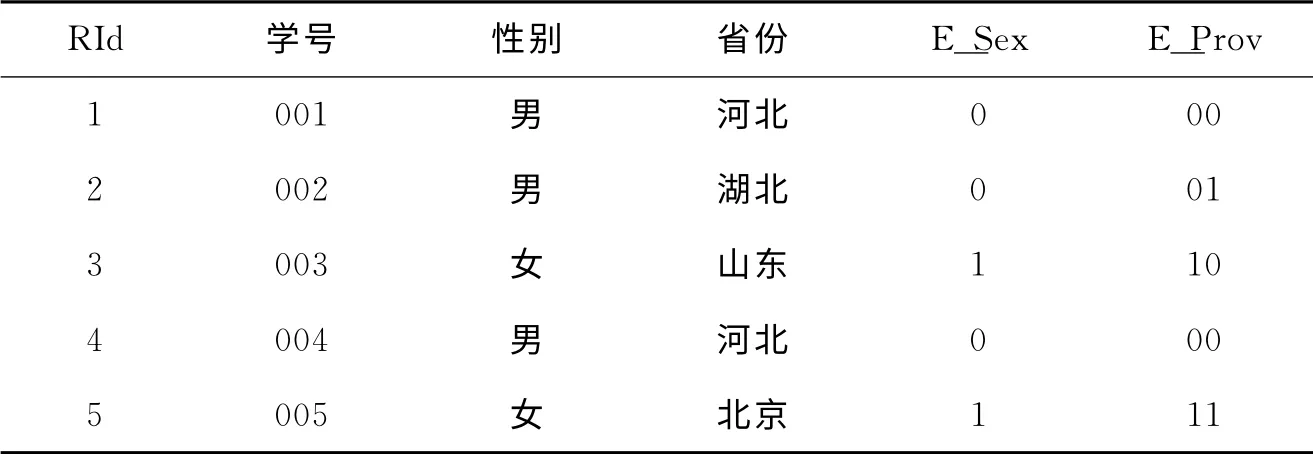
表1 学生基本信息表

图4 存储省份属性索引使用的双向有序链表结构
3 BLS-DEBI的基本操作
3.1 元组插入
当有新数据需要插入时,首先遍历已有的映射表,看该值是否已经存在对应的编码。若存在,则在编码的对应节点中添加该条元组对应的RowId,否则计算编码值的位数是否需要改变,如果不需要,则将插入数据对应的属性值插入映射表并分配剩余的编码值,否则需要为已编码的值前面增加一位0,最后增加相应的数据项即可。
3.2 元组删除
当删除满足给定条件的元组时,需要首先遍历映射表以确认是否需要更新映射表中的元组信息。当映射表中除了被删除元组的某属性取值外,仍有其余元组在该属性上的取值等于被删除属性值,则映射表只需删除该元组的RowId,同时在数据表中删除该元组信息即可。否则需要同时更新映射表和数据表。具体执行流程如算法1所示。
算法1:编码位图索引情况下元组删除算法。
输入:用户在某属性F 上的查询条件;
输出:删除是否成功的状态值。
0-表示删除失败;
1-表示删除成功;
2-不存在满足条件的删除元组。
算法步骤:
Step1.数据表接收到删除请求Con(F);
Step2.在内存中查询映射表,搜索Con(F)对应的编码Ceb,若未查询到满足条件的元组值,直接返回2,表示不存在满足条件的删除元组信息,否则依次执行Step3-8;
Step3.根据在Step2中生成的条件编码位串Ceb按照相应的规则搜索双向有序链表,返回对应节点记录的所有满足条件的RowId;
Step4.在映射表中删除RowId信息;
Step5.如果对应链表节点值为空,同时删除该链表节点,同时修改前后节点的指针指向;
Step6.检查是否需要更新映射表,若需要同时更新编码值;
Step7.根据Step3中获得的RowId到数据表定位实际数据并删除;
Step8.若Step7未出现异常信息,向用户返回1,否则向用户返回0。
3.3 元组更新
根据是否更新主键可以将元组更新操作分为两类:一类是含主键属性的更新。处理该类更新操作时,首先按照元组删除的步骤执行一次数据删除,之后按照元组插入的步骤执行一次数据插入,从而达到元组更新的目的。另一类是更新列不包含主键属性的更新。该类更新又可以细分为更新属性包含建立编码位图索引列和更新属性不含已经建立编码位图索引列。当更新属性不包含已建立编码位图索引列时,直接依据元组的主键更新相应属性值即可。当更新属性包含建立编码位图索引的列时,首先需要根据删除的相应操作更新映射表以及链表结构,然后根据插入的相应操作再次更新映射表和链表结构。
3.4 效率
从以上对数据的插入、删除和更新的处理来看,由于位图索引一般应用在属性基数有限的情况下,而插入、删除和更新操作只是相对于属性的不同取值情况进行处理,所以编码位图索引处理时间可以看做与基数相关的一个常数,而与数据表中数据量的大小无关。
4 BLS-DEBI检索算法
4.1 针对单个属性上的检索算法
在单个属性上查询时,首先根据用户的查询条件遍历映射表,获取查询条件对应的编码值。然后根据获取的查询条件编码值在存储索引的链表结构中用二分查找的算法通过二进制的逻辑异或运算,获取满足条件的元组标识信息。最后根据获取的元组标识信息到数据表直接获取用户需要的信息。
算法2:针对单个属性情况下的检索算法。
输入:用户在某属性F 上的查询条件Con(F);输出:满足用户查询条件的数据集。
算法步骤:
Step1.数据表接收到查询请求Con(F);
Step2.在内存中查询映射表,搜索Con(F)对应的编码Ceb,若没有查询到相应元组,则直接返回空集,否则依次执行Step3-6;
Step3.根据在Step2中查询到的条件编码位图Ceb按照相应的规则搜索有序链表结构;
Step4.返回链表中对应节点保存的所有满足条件的RowIds;
Step5.根据Step4中返回的RowIds去数据表中定位元组的详细信息;
Step6.将数据集返回给用户。
4.2 针对多个属性的检索算法
在多个属性上查询时,首先将查询条件分解成多个针对单个属性的查询条件,针对每个属性依次执行针对单个属性情况下的检索算法,最终得到的结果集即为满足用户要求的信息。
算法3:针对多个属性情况下的检索算法。
输入:用户在多个属性上的查询条件Con(F);
输出:满足用户查询条件的数据集。
本实验通过查阅文献发现,豆蔻、白术的挥发性成分,丹参的脂溶性成分、水溶性酚酸类成分,大黄的蒽醌类化合物及其衍生物,炙甘草的三萜类、黄酮类和多糖类成分,山药的多糖、氨基酸、微量元素等成分,均具有改善肾功能、调节胃肠功能、改善微循环、免疫调节和抗炎作用,因此,根据各味药所含成分的水溶性及相关药理作用,实验设计了3种工艺路线,以此筛选JYP的最佳制备工艺。
算法步骤:
Step1.数据表接收到查询请求Con(F);
Step2.将查询条件Con(F)进行分解,使每个Con(Fi)(0<i<n+1,i默认值为1)对应数据表中已经建立编码位图索引的一个属性;
Step3.在内存中查询映射表,搜索Con(Fi)对应的编码Ceb,若没有查询到元组信息则直接向用户返回空集,否则依次执行Step4-6;
Step4.根据在Step3中生成的条件编码位串Ceb按照二叉查找法搜索有序链表,通过逻辑运算判断是否满足查询条件,获取满足条件的链表节点;
Step5.获取链表对应节点中存储的所有RowId;
Step6.如果i=n则将最终获取的数据集返回给用户,否则i=i+1,返回继续执行Step3。
5 实验分析
5.1 实验环境
由于现有Oracle数据库已经集成B+树索引和基本位图索引,所以本实验是在一台Windows Server操作系统、装有Oracle 9i的PC 上完成的。本文算法是在Oracle存储过程开发环境下实现、通过Microsoft Visual Studio 2010开发的Browser-Server程序调用测试的。
为了使实验结果更具科学性,本实验采取单一变量原则,主要包括以下几组实验:
(1)在12.8万条数据情况下,分别采用全表扫描、B+树索引、简单位图索引、BLS-DEBI 4种算法进行检索;
(2)在102.2万条数据情况下,分别采用全表扫描、B+树索引、简单位图索引、BLS-DEBI 4种算法进行检索;
(3)在1 000万条数据情况下,分别采用全表扫描、B+树索引、简单位图索引、BLS-DEBI 4种算法进行检索。
5.2 实验结果对比分析
对比实验是在3组相同数据量的情况下通过改变索引类型进行实现的。从表2可以看出,当数据量在10万左右时采用B+树索引、简单位图索引和BLS-DEBI进行检索时间不相上下,并且三者相对于直接遍历数据表得到查询结果的全表扫描,速度提升了近20多倍。从表2中可以看出,随着数据量的增长,尤其是当数据集达到千万级别时,采用B+树查询所用的时间快速增长,而采用简单位图索引和BLSDEBI所用查询时间增长较缓慢,从简单位图索引检索时间和BLS-DEBI检索时间数据可以清晰的看出:采用BLS-DEBI较简单位图索引更有优势。

表2 不同索引在不同数据量下检索时间结果 ms
6 结语
在分析简单位图索引的优势和不足以及编码位图索引的优势的情况下,说明静态编码位图索引以属性基数对数的压缩率减少了索引的存储空间,而采用BLS-DEBI的方式,将进一步减少编码位图索引所需要的位串长度,并通过数学函数的形式直观的体现出编码索引的压缩率。同时由于采用双向有序链表的索引存储结构加快了数据检索的效率,并节省了存储索引所需空间。最后通过实验证明BLS-DEBI较B+树索引、简单位图索引在数据检索方面具有一定的优势。
[1]孟必平,王腾蛟,李红燕,等.分片位图索引:一种适用于云数据管理的辅助索引机制[J].计算机学报,2012,35(11):2306-2316.
[2]Ni Z,Guo J,Wang L,et al.An efficient method for improving query efficiency in data warehouse[J].Journal of Software(1796217X),2011,6(5):857-865.
[3]Wu Y,Shou L D,Chen G.CB-LSH:An efficient LSH indexing algorithm based on compressed bitmap[J].Journal of Zhejiang University.Engineering Science,2012,46(3):376-385.
[4]Lu P,Wu S,Shou L,et al.An efficient and compact indexing scheme for large-scale data store[C]//Data Engineering(ICDE),IEEE Computer Society Washington,DC,USA Ⓒ2005,2013 IEEE29th International Conference on.IEEE.[S.l.]:[s.n.],2013:326-337.
[5]Lemire D,Kaser O,Aouiche K.Sorting improves word-aligned bitmap indexes[J].Data & Knowledge Engineering,2010,69(1):3-28.
[6]Wen Y,Chen M,Lu G,et al.A characteristic bitmap coding method for vector elements based on self-adaptive gridding[J].International Journal of Geographical Information Science,2013,27(10):1939-1959.
[7]郭欢,叶小平,汤庸,等.基于时态编码和线序划分的时态XML 索引[J].软件学报,2012,23(8):2042-2057.
[8]Bin H,Yuxing P.An efficient two-level bitmap index for cloud data management[C]//Communication Software and Networks(ICCSN),IEEE Computer Society Washington,DC,USA Ⓒ2005,2011 IEEE3rd International Conference on.IEEE.[S.l.]:[s.n.],2011:509-513.
[9]胡廷波,钟俊.基于分簇的B+树数据库索引优化算法[J].计算机应用,2013,33(9):2474-2476.
猜你喜欢
电脑报(2021年14期)2021-06-28 10:46:22
党员生活(2020年2期)2020-04-17 09:56:30
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
计算机与生活(2019年5期)2019-07-18 01:08:56
第二课堂(课外活动版)(2019年12期)2019-02-10 03:59:37
铁道通信信号(2018年10期)2018-12-06 09:34:56
成都信息工程大学学报(2018年1期)2018-05-31 08:40:25
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
中国石油企业(2014年4期)2014-11-30 06:13:06
电测与仪表(2014年1期)2014-04-04 12:00:22
