
基于名人面孔视觉特征和语义信息的视觉统计学习*
2015-02-05 22:18唐溢张智君曾玫媚黄可刘炜赵亚军
心理学报 2015年7期
唐溢张智君曾玫媚黄可刘炜赵亚军
(1浙江大学心理与行为科学系,杭州310028)(2云南民族大学教育学院,昆明650504)(3西南民族大学社会学与心理学学院,成都610041)
1 前言
在日常生活中,人类除了加工事物的视觉特征(如颜色和形状等)和语义信息(如名称)外,还对事物间的时空规律(如时间顺序或空间位置信息)特别敏感。例如,当我们对一个新环境(如陌生的超市或城市)进行短期的熟悉后,就能自动习得场景中事物间的时空关系。有研究者认为,人们之所以能够自动加工场景中的规律信息,是因为统计学习(statistical learning)能力在其中发挥了重要的作用(Turk-Browne,Scholl,Chun,&Johnson,2009)。
统计学习就是个体自觉地运算刺激间的转接概率(transitional probabilities,TP)掌握统计规律的过程(Fiser&Aslin,2001)。该概念最初由Saffran,Aslin和Newport(1996)在研究婴儿的语言习得时提出,他们给婴儿呈现由无意义音节组成的刺激序列。这些音节每三个构成一个三联体(triplet),三联体内每个音节的时间顺序固定不变,而各个三联体之间的时间顺序变化(如pa-bi-ku/go-la-tu/da-ro-pi/pabi-ku/da-ro-pi…)。更具体地说,在整个序列中,每个音节出现的频次相同,而刺激之间的转接概率不同。转接概率的运算方式为TP=P(XY)/P(X),其中X和Y为刺激元素,P(XY)为整个刺激序列中XY组合出现的频率,P(X)为X出现的频率(Miller&Selfridge,1950),即三联体内部元素间的转接概率为1,而三联体之间元素的转接概率小于1。结果发现,在两分多钟的学习(听觉呈现)后,婴儿能明显地分辨出呈现过的三联体(如pa-bi-ku)与未呈现过的三联体(如pa-la-pi)或偶尔呈现的三联体(如bi-ku-da)。他们认为,婴儿是通过“统计运算”(statistical computation)音节间的转接概率而习得语言规律的(Saffran et al.,1996)。随后,一些研究者在成人的视觉通道中也发现了类似的统计学习能力(Fiser&Aslin,2001,2002),并将其称为“视觉统计学习”(visual statistical learning,VSL)。他们给被试呈现图形序列,该序列内的各个图片在空间位置(Fiser&Aslin,2001)或时间顺序(Fiser&Aslin,2002)上隐含统计规律,但被试事先并不知道该规律。经过一定时间的熟悉后,要求被试完成二选一迫选任务,即每次先后呈现两个结构(如三联体),其中一个为熟悉结构,另一个为熟悉元素组成的伪结构,要求被试确定哪个结构更熟悉,即在熟悉阶段出现过。结果显示,被试对熟悉结构的熟悉性判断显著高于伪结构。
以往研究发现,这种统计学习机制在知觉和认知技能中广泛存在,如因果结构知觉(Sobel,Tenenbaum,&Gopnik,2004)、动作学习(Baldwin,Anderrson,Saffran,&Meyer,2008)、视觉加工(Brady&Oliva,2008;Fiser&Aslin,2001,2002;Kirkham,Slemmer,&Johnson,2002;Yuille&Kersten,2006)和语言学习(Conway,Bauernschmidt,Huang,&Pisoni,2010;Goldwater,Griffiths,&Johnson,2009)。另外,被试在统计学习过程中并没有意识到材料之间存在统计结构(Brady&Oliva,2008;Turk-Browne,Junge,&Scholl,2005),即他们只能从肯定例证(positive instances)中进行学习,而不可能采用分析加工或假设验证的策略(Perruchet&Pacton,2006)。基于此,研究者认为统计学习具有自动化(Fiser&Aslin,2001,2002;Saffran et al.,1996;Turk-Browne et al.,2005)和无意识(Fiser&Aslin,2001)等特点。
由于内隐学习(implicit learning)和统计学习范式均不告知被试学习任务,即内隐学习也具有无意识特点(Willingham,Nissen,&Bullemer,1989),因此,有研究者认为,统计学习和内隐学习是一种现象的两种不同形式(Perruchet&Pacton,2006)。甚至有研究者直接使用内隐统计学习(implicit statistical learning)概念来统和它们(Conway&Christiansen,2006)。不过,也有研究者认为,被试在内隐学习范式下习得的是规则(rule),而这种规则与具体刺激无关(Marcus,Vijayan,Bandi Rao,&Vishton,1999)。如果该假设成立,则内隐学习与统计学习是不同的现象,因为统计学习是被试通过统计运算刺激之间转接概率来习得刺激间的统计规律关系,转接概率与每个刺激直接相关。
对时间顺序结构的视觉统计学习能力非常重要,它有利于人们掌握事物发生的顺序规律。近年来,许多研究者对个体在视觉统计学习中能基于哪些特征进行统计运算非常关注,结果发现人类不仅能基于视觉特征(Fiser&Aslin,2002;Turk-Browne,Isola,Scholl,&Treat,2008;Turk-Browne et al.,2005),还能基于抽象语义信息(Brady&Oliva,2008;Otsuka,Nishiyama,Nakahara,&Kawaguchi,2013)加工时间顺序结构。不过,基于这些特征对时间顺序结构的视觉统计学习效果到底是精确的(specific),还是灵活的(flexible),以往的研究结果并不一致(Turk-Browne&Scholl,2009;Otsuka et al.,2013)。也就是说,在视觉统计学习中,被试能基于哪些特征对统计规律进行何种程度的加工,依然是关注的焦点。
有研究者认为,个体的视觉统计学习是基于客体发生的,视觉特征信息是否起作用取决于个体如何定义“客体”(Turk-Browne et al.,2008)。他们给被试呈现带有颜色的隐含时间顺序结构的无意义图形序列(如A-B-C),要求被试在被动观看后完成二选一迫选任务,即判断(A-B-C vs.A-E-I)哪一个在熟悉阶段出现过。结果发现:当图形的颜色在测试阶段与熟悉阶段中保持一致时,被试表现出明显的视觉统计学习效果,而当测试阶段图形的颜色变为单色(即只保留形状)或只呈现颜色块(即消除形状)时,视觉统计学习的效果变弱或消失;当图形某一视觉特征(颜色或形状)的变化在熟悉阶段具有规律性,且测试阶段只对该视觉特征进行测试时,视觉统计学习效果又重新出现(Turk-Browne et al.,2008)。
另外,有研究者认为,个体还可以基于类别(语义)信息进行视觉统计学习(Brady&Oliva,2008)。他们采用自然场景(如森林、建筑、客厅等)探讨了个体是否可以基于类别(语义)信息进行视觉统计学习。在熟悉阶段,给被试呈现1000张图片,每张图片呈现300 ms,图片之间的间隔700 ms,要求被试探测重复出现的图片(无关任务)。在测试阶段,要求被试完成图片三联体二选一迫选任务。与先前的实验不同,该实验中每个三联体内部固定位置所呈现的图片属于某一类客体(如桥梁,包括水泥结构、钢材结构、木质结构等),而非特定客体。结果显示,被试能以类别信息判断三联体的熟悉性,表明个体在熟悉阶段能根据抽象的语义信息来加工时间顺序结构,即被试能基于类别(语义)信息进行视觉统计学习(Brady&Oliva,2008)。但是,该研究不能排除被试的类别统计学习是基于同类场景中固有特征的可能性。对此,有研究者在熟悉阶段呈现客体图片,而在测试阶段呈现客体图片或客体名称。结果发现,被试对视觉特征(客体图片)顺序三联体的熟悉性判断均显著高于随机水平,对视觉特征倒序三联体的熟悉性判断为随机水平,而对客体语义信息(客体名称)顺序三联体和倒序三联体的熟悉性判断均显著高于随机水平。根据这一结果,他们认为,对客体视觉特征和语义信息的加工是两个平行的过程:个体在提取视觉特征时间顺序的同时,形成了不具有时间规律信息的语义组块(Otsuka et al.,2013)。
以往研究者一般采用倒序三联体测试方式来检验视觉统计学习的灵活性(Turk-Browne&Scholl,2009;Otsuka et al.,2013)。他们在熟悉阶段给被试呈现隐含时间顺序结构(如A-B-C)的刺激序列,而在测试阶段分别呈现顺序三联体(A-B-C vs.A-E-I)和倒序三联体(C-B-A vs.IEA),让被试分别做熟悉性判断。他们认为,顺序三联体测试反映被试对转换概率的统计学习,而倒序三联体测试则反映被试基于该具体特征表征时间顺序结构的灵活性。也就是说,如果被试对顺序三联体(如A-B-C)的熟悉性判断显著高于随机水平,而对倒序三联体(如C-B-A)的熟悉性判断为随机水平,则表明被试基于该特征的视觉统计学习是精细的;而若对倒序三联体(如C-B-A)的熟悉性判断也显著高于随机水平,则表明被试基于该特征的视觉统计学习具有灵活性,即被试基于该特征的统计运算结果并不是基于精确的时间顺序信息进行的(Turk-Browne&Scholl,2009)。
有研究发现,被试基于视觉特征和语义信息的视觉统计学习效果的灵活性会受其他因素的影响。例如,Turk-Browne和Scholl(2009)发现,如果在熟悉阶段呈现隐含时间顺序结构(如A-B-C)的无意义图形序列,则被试在测试阶段会将顺序三联体(如A-B-C)和倒序三联体(如C-B-A)均显著判断为熟悉三联体,但当测试情景改为比较顺序三联体和倒序三联体(A-B-C vs.C-B-A)的熟悉性时,则被试会显著地将顺序三联体判断为熟悉三联体。该现象也存在于基于客体语义信息的视觉统计学习中(Otsuka et al.,2013)。这表明,被试基于视觉特征和语义信息的视觉统计学习存在灵活性,而这种灵活性受测试情景的影响。但是,Otsuka等(2013)却发现,当刺激材料包含语义信息的场景和类别客体时,被试基于视觉特征的统计运算表现出精确加工的特点,即抽象语义信息会易化基于视觉特征的视觉统计学习效果。他们进一步提出,个体之所以表现出灵活的视觉统计学习效果,是对统计结构进行组块加工(chunk)的结果,因为在组块中元素间的时间顺序信息或空间位置信息具有不确定性(Otsuka et al.,2013)。
Otsuka等(2013)所使用的实验材料为类别语义信息(类别名称,common name),与之相对应的是特定语义信息(特定名称,proper name)(比如,建筑物名,人名等)。有研究表明,个体对两类语义信息的加工是分离的过程(Martins&Farrajota,2006),但也有研究发现人类对两者的加工存在关联(Joassin,Meert,Campanella,&Bruyer,2007)。Otsuka等人(2013)考察了基于类别语义信息的视觉统计学效果,而基于特定语义信息的视觉统计学习效果到底是如何,还并未有相关的研究。
基于上述分析,本研究将进一步检验视觉特征与语义信息的视觉统计学习在多大程度上能够精确加工时间顺序结构。
以上这些研究考察了人类对非社交主体(如无意义图形、场景、类别客体等)的统计运算能力,而对社交主体(如人脸面孔)的统计运算能力到底如何,目前并未有直接的研究。作为社会性动物,人类与同类打交道的机会最频繁,很多时候需要在非面对面的情况下掌握其他个体的信息,因此拥有自动将人脸面孔与其特定名称联系起来的能力(Alvarez,Novo,&Fernandez,2009)。人类对面孔的加工也比类别客体加工更深刻,如面孔(尤其是名人)比客体更能吸引人类的注意(Langton,Law,Burton,&Scweinberger,2008;Theeuwes&van der Stigchel,2006)。ERPs研究表明,在视觉特征加工阶段个体对面孔的加工比客体更精细,能诱发更大的N170成分(Guillaumea et al.,2009)。个体对熟悉面孔的语义启动也比客体更充分,能诱发更显著的N250成分(Pickering&Schweinberger,2003)。名人面孔会导致更活跃的N400(Saavedra,Iglesias,&Olivares,2010;Wiese&Schweinberger,2011;Rugg&Curran,2007;Germain-Mondona,Silvert,&Izaute,2011)和P600(Saavedra et al.,2010),而这些脑电成分主要与语义信息加工有关。以上研究表明,个体对人脸面孔(特别是名人面孔)本身及其语义信息的加工更精细。但是,也有研究表明,被试加工特定名称(如面孔名字)比类别名称(如袋鼠等)更困难(Ahmed,Arnold,Thompson,Graham,&Hodges,2008;Bredart,1993;Evrard,2002;Semenza,2006),如Evrard(2002)的研究发现,被试命名面孔名字时需要更长的时间,他认为这是因为命名面孔名字需要更复杂和更多的认知资源。因此,与基于客体语义信息的统计加工相比,基于人类面孔语义信息的统计加工可能存在两种情况:精确的统计运算或组块的统计运算。
鉴于此,本研究将采用人脸面孔和面孔名字作为实验材料,考察被试基于面孔视觉特征与语义信息的视觉统计学习。
需要指出的是,先前研究发现,当被试基于同一实验材料的不同特征进行视觉统计学习时,其视觉统计学习效果往往不同(Otsuka et al.,2013;Turk-Browne et al.,2008)。但是,这些研究并没有探讨被试基于这些特征进行视觉统计学习的时间特点及其差异。研究表明,负责面孔视觉特征(Sergent,Ohta,&McDonald,1992;Kanwisher,McDermott,&Chun,1997;Campanella et al.,2001)及其名字(Damasio,Grabowski,Tranel,Hichwa,&Damasio,1996;Gorno-Tempini et al.,1998)加工的脑区是分离的。同时,以往研究者采用ERPs技术对面孔加工的阶段进行了具体的分析(Alvarez et al.,2009),发现面孔语义加工发生在视觉特征加工的基础之上(Bruce&Young,1986;Burton,Bruce,&Johnson,1990),面孔视觉特征加工在刺激呈现170~200 ms左右就已完成(Bentin&Deouell,2000),而面孔语义信息加工则需要更长的时间。有研究者认为,面孔语义信息的加工发生于450~650 ms(N400成分)(Huddy,Schweinberger,Jentzsch,&Burton,2003);也有研究者发现,被试对面孔语义信息的加工发生于550~750 ms(Diaz,Lindin,Galdo-Alvarez,Facal,&Juncos-Rabadan,2007);Alvarez等人(2009)则认为,面孔语义信息的加工发生于450~750 ms之间。
因此,本研究还将通过调节面孔图片的呈现时间,考察被试基于面孔视觉特征和语义信息进行统计运算的时间特征。
总之,本研究以名人面孔为实验材料,采用语义测试(Otsuka et al.,2013)和倒序三联体(Turk-Browne&Scholl,2009)测试的视觉统计实验范式,考察人类基于面孔视觉特征和语义信息进行视觉统计学习的特点。另外,本研究还采用倒置面孔呈现范式,深入探究视觉统计学习中的面孔特性。以往研究表明,倒置会破坏面孔结构信息的加工,而不会破坏特征信息的加工(Freire,Lee,&Symons,2000;Webster&MacLeod,2011)。因此,如果个体基于正立面孔与倒置面孔视觉特征的视觉统计学习存在显著差异,则说明基于视觉特征的视觉统计学习存在面孔特性,即基于面孔视觉特征的视觉统计学习并非一般视觉特征的统计学习;反之,则基于视觉特征的视觉统计学习不存在面孔特性。因此,本研究包含了以下5项实验:实验1与实验2分别采用图片和名字三联体为测试材料,检验人类是否能基于面孔语义信息进行视觉统计学习;实验3A和3B采用倒序三联体(如C-B-A)测试方式进一步探讨基于名人面孔视觉特征和语义信息进行视觉统计学习的灵活性,分析视觉统计学习中被试对面孔视觉特征和语义信息的加工特点。实验4A和4B则通过操纵图片呈现时间(由实验3的1000 ms缩减到700 ms)考察个体基于面孔语义信息的统计加工过程是与语义加工同时发生,还是发生在语义信息加工之后,从而探讨视觉统计学习中个体基于视觉特征和语义信息的统计规律提取机制。实验5在实验4的基础上,采用倒置面孔呈现范式,验证基于名人面孔视觉特征的视觉统计学习是否具有面孔特异性。综合先前的研究成果,我们假设:在实验1与实验2中,被试基于面孔视觉特征与语义信息的视觉统计学习效果显著,表现为对熟悉(视觉特征和语义信息)三联体的熟悉性判断都显著高于随机水平;在实验3A和3B中,被试基于面孔视觉特征和语义信息的视觉统计学习均能精确加工时间顺序结构,表现为对熟悉(视觉特征和语义信息)三联体的熟悉性判断都显著高于随机水平,而对倒序(视觉特征和语义信息)三联体的熟悉性判断都为随机水平;在实验4A中,被试基于面孔视觉特征的视觉统计学习不会受图片呈现时间调整的影响,表现与实验3A相同,而在实验4B中,基于语义信息的视觉统计学习能力减弱或消失,表现为对顺序和倒序语义三联体的熟悉性判断均显著高于随机水平或者表现为随机水平。在实验5中,被试基于正立面孔的视觉统计学习效果将显著高于倒置面孔视觉特征的视觉统计学习效果。
2 实验1基于名人面孔的视觉统计学习
探讨个体是否能对名人面孔进行视觉统计学习。
2.1 方法
2.1.1 被试
15名某大学本科生或研究生(6名男生,9名女生)为被试,均没有参加过其他相关实验。他们的年龄在19~24岁之间,均为右利手,视力或矫正视力正常,无色盲、色弱。他们自愿参加实验,实验结束后获得学分或一定的报酬。
2.1.2 装置与材料
实验装置为一台PentiumⅣPC电脑,Dell 17英寸纯平显示器,分辨率为1024×768,刷新率为85 Hz,屏幕背景为灰色。被试距离屏幕的距离为70 cm。
实验材料为12张名人面孔,均来自网络图片。所有面孔的高度在6.56°~7.04°之间,宽度在4.92°~5.41°之间,呈现在屏幕中央,均进行去色处理,直视被试。具体见图1。

图1 实验1采用的材料(名人面孔及名字)
2.1.3 设计与程序
在实验开始之前,所有被试都需要完成名人面孔熟悉程度的测试,即在电脑屏幕中央呈现名人的面孔,要求被试快速说出面孔对应的名字。如果被试不能一次性成功报告所有面孔的名字,则将不参与正式实验。
正式实验与先前研究(Turk-Browne et al.,2008;Otsuka et al.,2013)相同,也包括两个阶段:熟悉阶段与测试阶段。
熟悉阶段:在屏幕中央呈现面孔图片序列,每张面孔每次呈现300 ms,两张面孔之间间隔700 ms。12张面孔组成4个三联体,每个三联体重复96次,总共呈现1152个面孔刺激。三联体内部的图片位置固定,且顺序总是一致的(如A-B-C,J-K-L)。4个三联体在整个实验过程中随机出现并遵循以下规则:同一三联体不连续重复(如A-B-C-A-B-C)且两个三联体也不连续重复(如A-B-C-G-H-I-A-B-C-G-H-I)。在面孔呈现过程中,三联体首或尾的图片随机插入重复图片(如A-B-C-C-G-H-I或A-B-C-G-G-H-I),这样的重复在整个过程中随机出现96次,该操作不会影响三联体结构的完整,且有助于防止被试对三联体结构信息进行外显学习(Otsuka et al.,2013)。具体见图2A。在熟悉阶段,被试从事与学习无关的任务,即准确且快速地对重复出现的面孔进行按键反应。具体地说,当后一面孔图片与前一面孔图片相同时,按“空格”键进行反应。该任务可以很好地阻止被试对图片的顺序结构进行外显学习(Turk-Browne et al.,2005)和被动观看(Brady&Oliva,2008)。需特别强调的是,在整个实验过程中都不会告诉被试与图片呈现结构有关的任何信息。此外,在正式实验(熟悉阶段)开始之前,让被试完成6个试次的重复探测任务作为练习,练习所使用的实验材料不在正式实验中出现。熟悉阶段大约持续20 min。

图2 实验1熟悉阶段(A)和测试阶段(B)的刺激示例(C为实验2测试阶段的刺激)
测试阶段:在熟悉阶段结束后,立即让被试进行二选一迫选测试。具体地说,先在屏幕中央呈现白色“+”(0.8°×0.8°),持续1000 ms,然后连续呈现两个三联体(1个试次),其中每个图片的呈现时间为300 ms,两个图片之间的间隔为700 ms,两个三联体之间的间隔为1000 ms。在每个试次中,一个三联体的图片顺序是熟悉阶段出现过的(如A-B-C),另一个为伪三联体,它的图片来自熟悉阶段的图片,但不是出现过的三联体(如A-E-I)。在6张图片呈现后,屏幕中央出现一个小红点(0.5°×0.5°),要求被试判断两个三联体中哪一个是熟悉阶段出现过的,如果是前一个三联体,按数字“1”键,反之按“2”键,小红点直到被试按键反应后才会消失。具体见图2B。每个三联体(A-B-C,D-E-F,G-H-I,J-K-L)都与每个伪三联体(A-E-I,D-H-L,G-K-C,J-B-F)匹配两次,前后顺序随机平衡,总共测试32次。该阶段大约持续5 min。
将被试在测试阶段判断三联体熟悉性的正确率作为视觉统计学习的指标。
在实验结束后,询问被试是否知道实验目的及是否在熟悉阶段探测到图片呈现的规律。
2.2 结果
实验结果的统计指标均参照Otsuka等人(2013)采用的方法进行计算。
熟悉阶段的结果表明,被试对重复目标的平均探测概率为94.06%(SE
=1.14%)。这表明,被试能将注意集中到图片重复探测任务上。事后询问表明,被试不能报告出完整的三联体和实验目的。测试阶段的结果为,被试对熟悉三联体的熟悉性辨识率(72.29%)显著高于随机水平,t
(14)=5.89,p
<0.001,d
=1.52,表明被试能明显区分伪三联体与熟悉三联体。该结果与先前无意义图形(Turk-Browne et al.,2005)、真实场景(如森林、建筑、客厅等)(Brady&Oliva,2008)及客体(Otsuka et al.,2013)的视觉统计学习研究一致,说明被试可以基于熟悉面孔进行视觉统计学习。3 实验2基于名人面孔语义信息的视觉统计学习
实验1的结果表明,被试可以基于熟悉面孔进行视觉统计学习。但是,个体到底是基于面孔视觉特征信息还是基于语义信息(如名字)进行视觉统计学习的,实验1并不能给出明确的答案。先前研究表明,个体不仅可以基于客体的视觉特征信息(如形状)(Turk-Browne et al.,2008),也可以基于客体的语义信息(如类别)进行视觉统计学习(Brady&Oliva,2008;Otsuka et al.,2013)。因此,在实验2中,在熟悉阶段仍呈现名人面孔,但在测试阶段却以与名人面孔对应的真实名字作为测试材料(Otsuka et al.,2013),考察个体能否基于面孔语义信息进行视觉统计学习。如果被试能基于名人面孔语义信息进行视觉统计学习,那么在测试阶段将能区分名字熟悉三联体(如A-B-C)与伪三联体(如A-E-I)。
3.1 方法
3.1.1 被试
15名某大学本科生或研究生(6名男生,9名女生)作为被试,均没有参加过实验1。他们的年龄在18~24岁之间,均没有参加过其他相关实验。他们均为右利手,视力或矫正视力正常,无色盲、色弱。他们均自愿参加实验,实验结束后获得学分或一定的报酬。
3.1.2 材料
熟悉阶段完全与实验1相同,而测试阶段的刺激变为与面孔对应的人名(Otsuka et al.,2013)。名字最多三个汉字,字体为微软雅黑(1.31°×1.31°),颜色为白色,字间距离为0.5°。名字的视角宽度和面孔宽度一致(图2C)。
3.1.3 设计与程序
除测试阶段的材料改为与面孔对应的名字外,其他程序均与实验1相同。
整个实验持续大约25 min。
3.2 结果
被试均成功完成熟悉阶段的重复图片探测任务,重复目标的平均探测概率为94.68%(SE
=1.41%)。视觉统计学习的效果显著,对熟悉三联体的辨识率(62.08%)显著高于随机水平,t
(14)=4.35,p
<0.01,d
=1.12。该结果与先前以客体为实验材料的实验结果一致(Otsuka et al.,2013),说明个体也能基于名人面孔的语义信息进行视觉统计学习。4 实验3基于面孔视觉特征和语义信息进行视觉统计学习的精确性
实验1表明被试能够基于名人面孔进行视觉统计学习,实验2则进一步说明被试能够基于名人面孔语义信息进行视觉统计学习。Turk-Browne等人(2009)的研究表明,倒序三联体(如C-B-A)的测试方式能有效地揭示被试基于某一特征对时间顺序结构进行统计运算的精确性。Otsuka等人(2013)采用该范式发现,被试基于客体语义信息表征时间顺序结构时出现组块现象(Otsuka et al.,2013)。基于此,实验3A与3B分别以面孔视觉特征和语义信息作为测试材料,利用顺序和倒序三联体相结合的测试方式(Turk-Browne et al.,2009),比较被试基于面孔视觉特征和语义信息进行视觉统计加工的特点。如果被试对顺序视觉特征和顺序语义三联体(如A-B-C)的熟悉度判断均显著高于随机水平(50%),而对倒序视觉特征和倒序语义三联体(如C-B-A)的熟悉度判断均呈随机水平,则说明被试在视觉统计学习中能同时基于面孔视觉特征和语义信息精确地加工时间顺序结构。
4.1 方法
4.1.1 被试
某大学本科生或研究生参与本实验。其中,实验3A共14名被试(5男,9女),年龄为19~26岁;实验3B共15名被试(7男,8女),年龄为18~26,均没有参加过实验3A。他们均为右利手,视力或矫正视力正常,无色盲、色弱。他们自愿参加实验,实验结束后获得学分或一定的报酬。
4.1.2 材料
除测试阶段三联体内部图片或名字的顺序发生变化外,其余都分别与实验1或2相同。
4.1.3 设计与程序
熟悉阶段与实验1相同。
测试阶段的三联体内部顺序包括两种情况:一半与熟悉阶段一致(如A-B-C,D-E-F,G-H-I和J-K-L,见图2B、2C),一半与熟悉阶段相反(如C-B-A,F-E-D,I-H-G和L-K-J,见图3)。为了平衡顺序效应,与倒序三联体匹配的伪三联体也为倒序(如I-E-A,L-H-D,C-K-G和F-B-J)。每个三联体(包括正序三联体和倒序三联体)分别与对应的4个伪三联体匹配一次,一共32个试次。具体示例见图3。
实验3A和实验3B均持续大约25 min。

图3 实验3熟悉阶段(A)和测试阶段倒序三联体刺激示例(B视觉刺激、C语义刺激)
4.2 结果
被试能成功完成熟悉阶段的重复图片探测任务。其中,实验3A中重复目标的平均探测概率为93.02%(SE
=1.22%);实验3B中重复目标的平均探测概率为94.32%(SE
=1.40%)。实验3A中,被试对名人面孔的视觉统计学习效果显著:在顺序三联体测试条件下,被试对熟悉三联体的辨识率(75.00%)显著高于随机水平,t
(13)=6.19,p
<0.001,d
=0.99,与实验1的结果无显著差异,t
(27)=–0.49,p
>0.05,d
=0.19;而在倒序三联体测试条件下,被试对倒序三联体的熟悉性辨识率(54.46%)为随机水平,t
(13)=1.51,p
>0.05,d
=0.40。实验3B的被试对面孔名字的视觉统计学习效果同样显著:在顺序三联体测试条件下,被试对熟悉三联体的辨识率(66.25%)显著高于随机水平,t
(14)=4.33,p
<0.01,d
=1.12,与实验2的结果也无差异,t
(28)=0.89,p
>0.05,d
=0.34;而在倒序三联体测试条件下,被试对倒序三联体的熟悉性辨识率(49.58%)为随机水平,t
(14)=–0.19,p
>0.05,d
=1.15。具体结果的比较见图4。
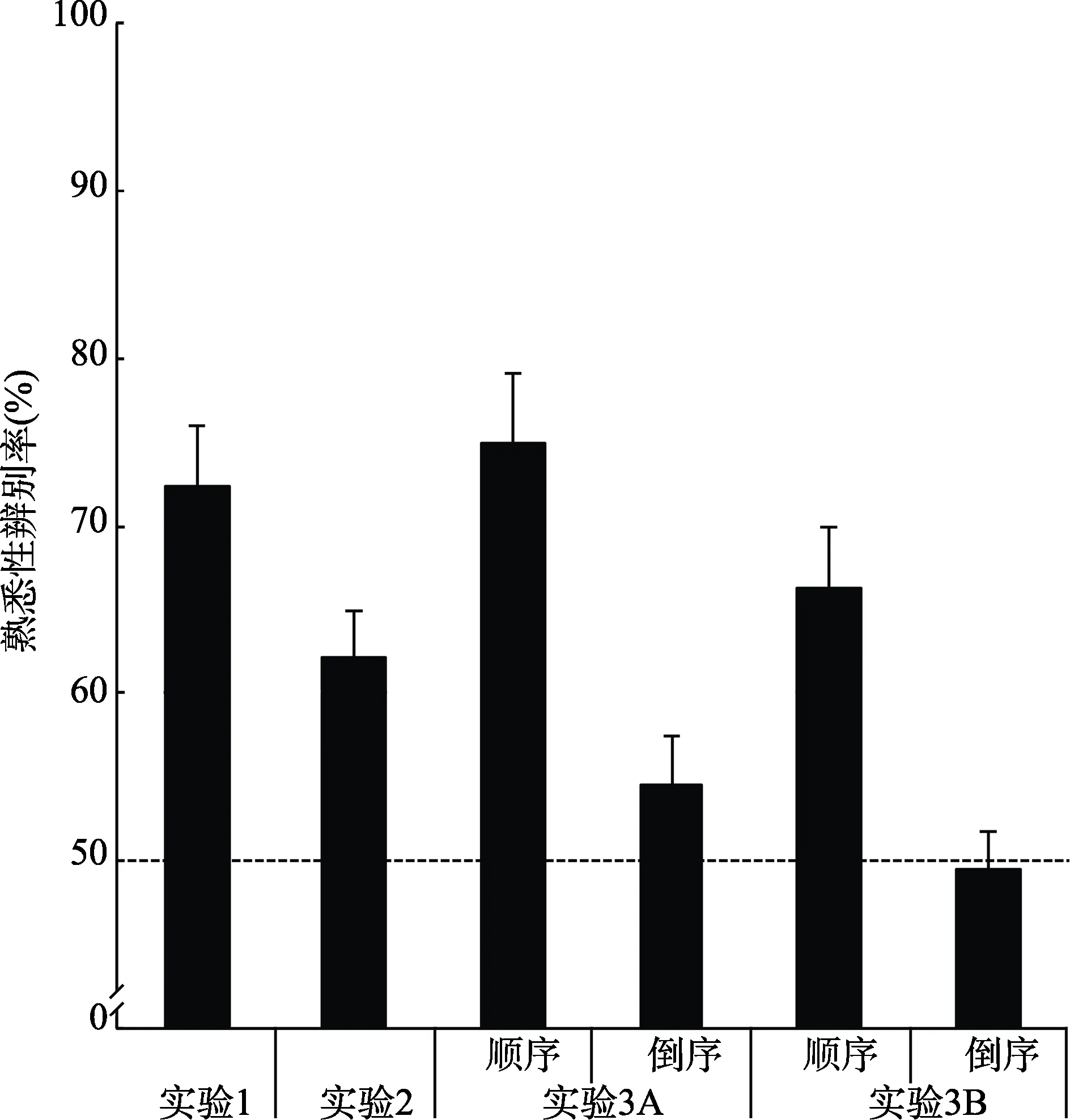
图4 实验1、实验2和实验3测试阶段三联体熟悉性判断情况比较
4.3 讨论
实验3结果支持被试能够同时基于面孔视觉特征和语义信息进行可靠的视觉统计学习的假设。以面孔图片为测试材料的实验结果(实验3A)与先前关于客体的研究(Otsuka et al.,2013)一致,即被试能基于视觉特征精确地运算面孔间的时间顺序结构。而以面孔语义信息为测试材料的实验结果(实验3B)则表明,个体也能精确地基于面孔语义信息对时间顺序结构进行加工,这与Otsuka等人(2013)以客体语义信息为材料的研究结果不一致。这说明,虽然被试可基于刺激的视觉特征和语义信息对时间顺序结构进行精确加工,但基于语义信息的统计加工会受刺激材料社会属性的影响,即个体能精确加工基于面孔语义信息的时间顺序结构(实验3B),而对基于客体语义信息的时间顺序结构只能进行组块加工(Otsuka et al.,2013)。
5 实验4基于面孔视觉特征与语义信息的统计运算的差异
实验3B的结果发现,个体能够基于面孔的语义信息精确加工时间顺序结构,结合Otsuka等人(2013)的研究结果,提示在视觉统计学习中,被试对名人面孔语义信息的视觉统计学习更加深刻。
同时,Otsuka等人(2013)认为,基于客体视觉特征和语义信息的视觉统计学习是两个独立的过程,即对它们的时间顺序信息加工存在差异。而实验3的结果却表明,名人面孔视觉特征与语义信息之间的关系不同于客体,个体对名人面孔视觉特征与语义信息的加工可能并不是独立进行的。
对此,实验4通过调整图片呈现方式来探讨视觉统计学习中名人面孔视觉特征与语义信息加工之间的关系。先前研究表明,面孔语义加工发生在视觉特征加工的基础之上(Bruce&Young,1986;Burton et al.,1990),采用ERPs技术对面孔加工阶段的分析发现,面孔视觉特征加工在刺激呈现170~200 ms左右就已完成(Bentin&Deouell,2000),而面孔语义信息的加工时间因任务不同而发生变化,Huddy等人(2003)认为面孔名字加工发生于450~550 ms之间,而Diaz等人(2007)的研究中则显示面孔语义加工发生于550 ms之后,Alvarez等人(2009)则认为,面孔语义信息的加工发生于450~750 ms之间。综合来看,面孔语义信息加工与面孔特征加工之间的时间延迟大概为300 ms。基于此,我们将熟悉阶段的图片间隔时间由实验3的700 ms调整为400 ms,这种控制不仅可以考察基于面孔语义信息进行统计运算发生的时间条件,还能揭示基于名人面孔视觉特征与语义信息的统计加工的机制差异。我们假设:如果在此情景下个体对名人面孔语义信息的视觉统计学习表现出“组块”现象,或视觉统计完全消失,则说明被试对名人面孔语义信息的视觉统计加工发生在语义信息加工完成之后;如果被试对名人面孔语义信息的视觉统计学习与实验3B完全相同,则说明对名人面孔语义信息的视觉统计加工与语义信息加工同时进行。
5.1 方法
5.1.1 被试
均为某大学本科生或研究生。其中,实验4A共14名被试(4男,10女),年龄为18~26岁;实验4B共14名被试(7男,7女),年龄为19~25,均没有参加过实验4A。被试均为右利手,视力或矫正视力正常,无色盲、色弱。他们自愿参加实验,实验结束后获得学分或一定报酬。
5.1.2 材料
实验的面孔与名字材料均与实验3相同。
5.1.3 设计与程序
除了面孔(或名字)间隔时间改为400 ms外,熟悉阶段与测试阶段的程序均与实验3相同。
5.2 结果
被试能成功完成熟悉阶段的重复图片探测任务。其中,实验4A中重复目标的平均探测概率为91.13%(SE
=1.21%);实验4B中重复目标的平均探测概率为90.09%(SE
=1.34%)。实验4A的被试对面孔图片的视觉统计学习效果非常显著:在顺序三联体测试条件下,被试对熟悉三联体的辨识率(65.63%)显著高于随机水平,t
(13)=5.11,p
<0.001,d
=1.37,与实验3A顺序三联体测试条件下熟悉三联体的辨识率无显著差异,t
(26)=1.85,p
>0.05,d
=0.73;在倒序三联体测试条件下,被试对倒序三联体熟悉性辨识率(52.23%)为随机水平,t
(13)=0.79,p
>0.05,d
=1.16,与实验3A倒序三联体测试条件的情况相同。实验4B的被试对面孔名字的视觉统计学习效果不显著:在顺序三联体测试条件下,被试对熟悉三联体辨识率(51.34%)为随机水平,t
(13)=0.38,p
>0.05,d
=0.87,与实验3B顺序三联体测试条件下熟悉三联体的辨识率有显著差异,t
(27)=2.90,p
<0.01,d
=1.12;在倒序三联体测试条件下,被试对倒序三联体的熟悉性辨识率(49.11%)为随机水平,t
(13)=–0.26,p
>0.05,d
=0.70,与实验3B倒序三联体测试条件的情况相同。具体见图6。
5.3 讨论
实验4A与实验3A结果一致,表明被试基于面孔视觉特征的视觉统计学习发生在刺激出现的700 ms之内;而实验4B中基于面孔语义信息的视觉统计学习效果消失,表明基于面孔语义信息的视觉统计学习发生于刺激出现的700 ms之后。这些结果提示:基于面孔视觉特征和语义信息视觉统计学习是分离的;与面孔视觉特征加工相比,个体基于面孔语义信息的统计运算需要更长的时间。同时也说明,至少在基于语义信息的视觉统计学习中,规律提取过程发生在特征加工完成之后。
6 实验5视觉统计学习中的面孔特异性
实验4的结果发现,当名人面孔呈现时间缩短后,个体基于面孔语义信息的视觉统计学习效果消失,而基于面孔视觉特征的视觉统计学习效果依然显著。有研究者认为,实验4的面孔图片均带有发型,而发型差异是非常明显的物理特征差异,它可能会干扰和增强面孔视觉统计学习效果。同时,即使发型不会干扰面孔视觉统计学习,实验4也并不能确定基于名人面孔视觉特征的视觉统计学习是否与基于一般视觉特征(物理特征)的视觉统计学习相同,也就是说,个体基于名人面孔视觉特征的视觉统计学习可能并不存在面孔特异性。因此,为了深入考察视觉统计学习中视觉特征加工的面孔特性,实验5采用去除发型后的名人面孔为实验材料,设置两种面孔呈现方式(正立、倒置),通过比较被试基于正立面孔与倒置面孔的视觉统计学习效果,来探讨面孔特征视觉统计学习的特异性。如果基于正立面孔的视觉统计学习效果显著高于基于倒立面孔的视觉统计学习效果,说明基于面孔视觉特征的视觉统计学习存在面孔特异性;如果基于正立面孔与基于倒置面孔的视觉统计学习效果无显著差异,则说明基于面孔视觉特征的视觉统计学习不存在面孔特性。
6.1 方法
6.1.1 被试
均为某大学本科生或研究生。其中,正立实验共14名被试(6男,8女),年龄为18~24岁;倒置面孔实验共14名被试(7男,7女),年龄为19~24岁,均没有参加过正立面孔实验。被试均为右利手,视力或矫正视力正常,无色盲、色弱。他们自愿参加实验,实验结束后获得一定报酬。
6.1.2 材料
除了去除面孔的发型外,实验5的面孔均与实验4相同。正立面孔图片垂直旋转形成倒置面孔图片。(见图5)
6.1.3 设计与程序
除了采用倒置面孔外,熟悉阶段与测试阶段的程序均与实验4A相同。
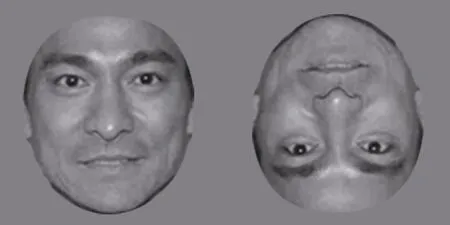
图5 实验5面孔图片示例
6.2 结果
被试能成功完成熟悉阶段的重复图片探测任务。其中,正立面孔重复目标的平均探测概率为90.10%(SE
=1.11%);倒置面孔重复目标的平均探测概率为88.62%(SE
=1.36%)。被试基于正立面孔图片的视觉统计学习效果显著高于基于倒置面孔图片的视觉统计学习效果:t
(26)=2.09,p
<0.05,d
=1.39。被试基于正立面孔的视觉统计学习效果非常显著:对熟悉三联体的辨识率(66.07%)显著高于随机水平,t
(13)=4.93,p
<0.001,d
=1.34,对倒序三联体的熟悉性辨识率(53.13%)为随机水平,t
(13)=1.29,p
>0.05,d
=0.34;被试基于倒置面孔图片的视觉统计学习效果显著:对熟悉三联体的辨识率(57.14%)高于随机水平,t
(13)=2.58,p
<0.05,d
=0.69;对倒序三联体的辨识率(49.11%)为随机水平,t
(13)=–0.25,p
>0.05,d
=0.07。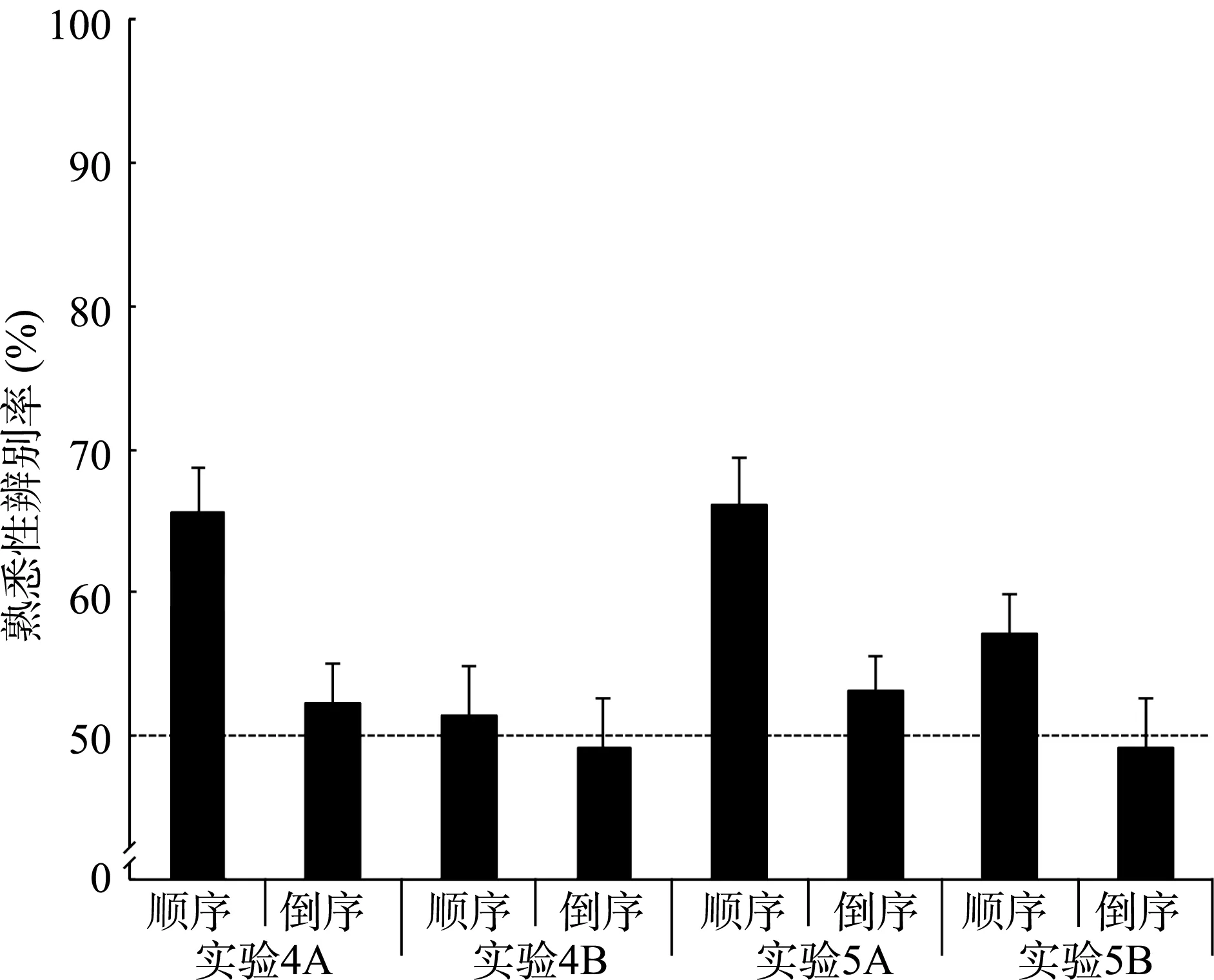
图6 实验4和实验5测试阶段三联体熟悉性判断情况
6.3 讨论
实验5中基于倒置面孔的视觉统计学习效果与正立面孔视觉统计学习效果差异显著,表明基于名人面孔视觉特征的视觉统计学习不同于基于一般视觉特征的视觉统计学习,即基于名人面孔视觉特征的视觉统计学习存在面孔特异性。这些结果提示:基于名人面孔视觉特征的视觉统计学习是区别于一般物理特征统计学习的。
7 总讨论
本研究探讨了个体基于面孔视觉特征和语义信息进行视觉统计学习的特点。实验1和2考察个体能否基于名人面孔的视觉特征和语义信息进行视觉统计学习,结果与真实场景(Brady&Oliva,2008)和客体(Otsuka et al.,2013)的视觉统计学习一致,即个体能基于面孔的视觉特征和语义信息进行视觉统计学习。实验3A和3B利用倒序三联体处理范式,考察基于面孔视觉特征和语义信息进行统计运算的精确性,结果显示个体能基于名人面孔视觉特征和语义信息对时间顺序结构进行精确运算。实验4A和4B通过调整图片呈现时间,探讨视觉统计学习中基于面孔视觉特征和语义信息提取统计规律的机制,结果在缩减图片呈现时间(由1000 ms缩短到700 ms)后,被试丧失了基于面孔语义信息进行视觉统计学习的能力,提示基于名人面孔视觉特征和语义信息的视觉统计学习可能是两个分离的过程,基于语义信息的视觉统计学习比基于视觉特征的统计学习需要更长时间。同时也表明,至少在基于语义信息的视觉统计学习中,规律提取过程发生在特征加工完成之后。实验5利用倒置面孔呈现范式,考察基于面孔视觉特征的视觉统计学习是否具有面孔特异性,结果显示个体基于名人面孔视觉特征的视觉统计学习不同于基于一般视觉特征的视觉统计学习。
7.1 统计计算与组块加工
在视觉统计学习中,个体(基于视觉特征和语义信息)对时间顺序结构的统计运算效果并不总是精确的。当统计材料为无意义图形时,被试基于视觉特征对时间顺序结构的统计运算表现出组块现象(Turk-Browne&Scholl,2009);同时,基于客体语义信息的统计运算也表现出组块加工的特点(Otsuka et al.,2013)。不过,以上这些组块现象均会受测试情景的影响,当测试情景要求被试判断时间顺序结构(如A-B-C)与组块结构(如C-B-A)的熟悉性时,被试表现出时间顺序结构精确加工的特点(Turk-Browne&Scholl,2009;Otsuka et al.,2013)。而当实验材料为带有语义信息客体(Otsuka et al.,2013)时,被试基于视觉特征的统计学习则直接表现出精确加工的特点。本研究(实验3)发现,当实验材料为名人面孔时,被试能同时基于面孔视觉特征和语义信息对时间顺序结构进行精确的统计运算,而并没有出现组块现象。综上,我们认为,在视觉统计学习中,个体能够同时基于刺激的视觉特征和语义信息进行精确的统计运算,而这种统计运算能力的实现与刺激材料本身的特性和场景信息有关。
Perruchet和Pacton(2006)认为,时间规律与组块之间存在三种可能的关系。第一,统计运算(statistical computation)与组块加工是独立进行的。Meulemans与van Der Linden(2003)也对该观点进行了阐述,他们基于遗忘症病人的研究提出,组块是意识的产物,而统计运算则对内隐任务的贡献更大。当然,也有研究者提出了不同的解释(Kinder&Shanks,2003;Shanks,Channon,Wilkinson,&Curran,2006)。第二,统计运算与组块加工是两个连续的阶段,即组块是由统计运算推导的结果。有研究者将该解释应用于听觉(Saffran,2001)和视觉(Fiser&Aslin,2005)的统计学习。第三,只存在组块过程,对统计结构的加工是该过程的副产物。其中,组块竞争模型(competitive chunking model)(Servan-Schreiber&Anderson,1990)和剖析器模型(PARSER model)(Perruchet&Vinter,2002)支持第三种观点。例如,剖析器模型认为,由于我们的注意资源有限,因此我们对输入信息的组块是基于随机模式发生的,所形成的组块也会因为联结记忆规则而在随后被遗忘或者被强化。
结合先前的研究(Brady&Oliva,2008;Otsuka et al.,2013;Turk-Browne&Scholl,2009),本研究倾向于支持第二种解释。当面临新情境(测试阶段)时,人类需要基于先前的统计运算结果进行推导,来判断新情景中的结构是否为熟悉的统计结构。也就是说,被试在熟悉阶段基于统计运算推导出统计结构,而该统计结构可能是精确的时间顺序结构,也可能是灵活的组块。当新情景中需要被试对时间顺序结构进行辨别时,他们的辨别结果就可能呈现组块现象。比如,有研究者发现,在熟悉阶段呈现隐含时间顺序结构(如ABC)的刺激序列,当测试情景为倒序三联体对伪三联体(如CBA vs.IEA)时,被试表现出组块现象;当测试情景为倒序三联体对顺序三联体(如CBA vs.ABC)时,组块现象消失(Turk-Browne&Scholl,2009;Otsuka et al.,2013)。以上研究中,被试的统计运算过程并未发生变化,而测试情景的不同诱发不同的统计运算结果,说明组块与统计运算加工直接相关,而并不是两个独立的加工机制。本研究(实验4B)的结果显示,当被试没能完成统计运算任务时,也不会发生组块现象。综合以上结果,我们认为,组块是基于统计运算进行推导的结果,而测试的情景信息、材料的名称属性等因素会影响被试的统计运算能力。
有研究者使用功能性核磁共振成像(fMRI)发现,统计运算的组块现象可能是统计运算所形成的抽象信息所导致的。大脑中存在与视觉统计学习密切相关的脑区:尾叶(caudate)和海马回(hippocampus)。海马回的参与表明个体生成了更抽象的知识信息以便适用于更广泛的新情境,而尾叶的参与则使知识以客体的具体视觉特征方式保存下来,从而可以精确再现所加工的情境(Turk-Browne et al.,2009)。
7.2 面孔视觉特征与语义加工
本研究熟悉阶段只呈现面孔图片,而在测试阶段呈现名人面孔图片(实验1、3A)或面孔名字(实验2、3B),结果个体基于名人面孔视觉特征与语义信息的视觉统计学习效果具有一致性,这说明人类会自动将人脸面孔与其特定名称联系起来(Alvarez et al.,2009),且能直接利用名称信息进行规律加工。不过,先前研究者认为,面孔视觉特征与语义信息加工并不是同时完成的(Alvarez et al.,2009;Bruce&Young,1986),因此,我们设计了实验4来考察视觉统计学习中面孔视觉特征与语义信息的加工特点,结果发现当面孔呈现时间缩短(1000 ms缩短至700 ms)后,被试能保持基于面孔视觉特征的统计学习能力(实验4A),且基于面孔特征的视觉统计学习显著优于基于一般物理特征的视觉统计学习(实验5),但基于面孔语义信息的视觉统计学习能力消失,说明基于面孔语义信息的视觉统计学习需要更多的加工时间。Bruce和Young(1986)认为,面孔加工可分为轮廓加工(structural coding)、面孔识别(face recognition units,FRUs)、身份识别(person identity nodes,PINs)和语义加工(name generation)等4个阶段,其中语义加工发生在轮廓加工的基础之上(Bruce&Young,1986;Burton et al.,1990)。有研究者利用ERPs技术对面孔加工的阶段进行了具体的分析(Alvarez,et al.,2009),认为面孔视觉特征的加工在刺激呈现170 ms左右就已完成(Bentin&Deouell,2000),而直到刺激呈现750 ms左右才完成面孔语义信息的加工(Diaz et al.,2007)。因此,本研究的结果也支持了语义加工比视觉特征加工需要更长时间的观点。
Otsuka等人(2013)认为,被试基于客体视觉特征和语义信息的视觉统计学习是两个平行的过程,在基于视觉特征提取时间顺序的同时形成了不具有时间规律信息的语义组块。结合本研究实验3和实验4的结果,我们认为,被试基于名人面孔视觉特征和语义信息的视觉统计加工是分离的,基于面孔语义信息的视觉统计学习需要更多的加工时间。这两个过程到底是平行加工的,还是序列加工的?由于在实验4B中未检验被试对语义信息的加工情况,因此本研究并不能给出直接判断。不过,结合Alvarez等人(2009)关于面孔名称的研究可以推知,被试在实验4B中应该完成了面孔语义信息的加工,只是未能加工面孔名称之间的统计关系。由此,我们猜想,个体基于面孔特征的统计运算过程可能与面孔语义信息加工同时进行,即被试基于面孔视觉特征和语义信息的视觉统计学习也是两个平行的过程。当然,这还需要更多的研究进行论证,我们实验的熟悉阶段只呈现面孔图片来启动面孔名字,先前研究发现,涉及面孔图片加工(Campanella et al.,2001;Kanwisher et al.,1997;Sergent et al.,1992)与面孔名字加工(Damasioetal.,1996;Gorno-Tempini et al.,1998)的脑区是分离的。同时,基于面孔图片的启动结果和基于面孔名字的启动结果也存在差异(Joassin et al.,2007)。因此,以后的研究可以采用在熟悉阶段只呈现面孔语义信息(名字)的方式,深入探究基于面孔视觉特征和面孔语义信息的视觉统计学习之间的相互关系。实验4的图片呈现时间较实验3减少了300 ms,基于面孔视觉特征信息的视觉统计学习效果无显著变化,而基于面孔语义信息的视觉统计学习效果消失,表明基于面孔视觉特征的视觉统计学习时间要求少于700 ms,而基于名人面孔语义信息的视觉统计学习的时间要求在700~1000 ms之间。先前研究也表明,统计运算的时间要求会因为统计学习效果而发生变化(Abla&Okanoya,2009)。本研究未能对基于面孔不同特征的统计运算时间进行精确地控制,因此,需要以后更多的研究来继续探讨基于不同特征的统计学习发生的时间要求。
Brady与Oliva(2008)认为,利用抽象类别信息可以减少统计学习中需要提取和储存的信息量,从而更轻松地习得统计规律。有研究者认为,研究中基于语义信息的测试结果(实验2和3B)提示:被试基于面孔图片的测试实验结果(实验1和3A)可能获得来自面孔语义信息的促进作用。我们在实验4缩短熟悉阶段面孔呈现时间,结果发现基于面孔语义信息的视觉统计学习效果消失,但基于面孔视觉特征信息的视觉统计学习效果并没有显著降低,这在一定程度上说明基于面孔语义信息与面孔特征信息的视觉统计学习是两个分离的过程,即面孔语义信息并不会影响面孔视觉(轮廓)特征的加工(Bentin&Deouell,2000)。不过,这还不能完全排除被试在面孔图片较长呈现时间条件下(实验1和3A)利用语义信息促进基于面孔视觉特征的视觉统计学习的可能。因此,以后的研究可以采用其他的手段(比如在面孔呈现过程中,通过双任务范式抑制被试的面孔命名过程),进一步探讨面孔语义信息在基于面孔视觉特征的视觉统计学习中是否起作用。我们的实验(3B)发现个体能基于面孔语义信息对时间顺序结构进行精确加工,这与Otsuka等人(2013)(实验2B)以客体语义信息为测试材料的研究结果不一致。我们认为,这种差异可能是由客体名称与面孔名称加工的差异导致的。面孔名称与面孔的关系具有唯一性,而客体名称则代表某一类客体。Joassin等人(2007)发现,与客体名称与客体本身的匹配相比,被试更容易完成面孔名称与面孔本身的匹配任务。在视觉统计学习范式中,熟悉阶段以(客体或面孔)图片的方式呈现统计结构,被试基于图片生成语义信息,因此,对图片与名称之间匹配关系的加工程度将影响个体基于名称进行统计结构判断的结果。也就是说,当刺激材料为拥有语义信息的熟悉事物时,被试能基于语义信息加工时间顺序结构,不过其加工的效果将受刺激材料语义属性的影响,即当语义信息为特定名称(如面孔名称)时,基于语义信息对时间顺序结构的加工是精确的,而当语义信息为类别名称(如客体名称)时,基于客体语义信息的时间顺序结构加工则表现出组块现象。以后的研究可进一步考察个体基于其他具有特定名称的非社交主体(如建筑物)进行的视觉统计学习。
8 结论
本研究获得以下结论:(1)个体能同时基于名人面孔的视觉特和语义信息进行精确的视觉统计学习;(2)基于名人面孔视觉特征和语义信息对时间顺序结构进行统计运算的结果具有一致的精确性;(3)基于面孔视觉特征的视觉统计学习表现出显著的面孔特性,即个体基于面孔视觉特征的视觉统计学习不同于基于一般物理特征的视觉统计学习;(4)基于名人面孔视觉特征信息与语义信息的视觉统计学习过程是分离的,统计运算过程发生在面孔特征加工完成之后,基于语义信息的视觉统计学习需要更多的加工时间。
Abla,D.,&Okanoya,K.(2009).Visual statistical learning of shape sequences:An ERP study.Neuroscience Research,64
,185–190.Ahmed,S.,Arnold,R.,Thompson,S.A.,Graham,K.S.,&Hodges,J.R.(2008)Naming of objects,faces and buildings in mild cognitive impairment.Cortex,44
,746–752.Álvarez,S.G.,Novo,M.L.,&Fernández,F.D.(2009).Naming faces:A multidisciplinary and integrated review.Psicothema,21
,521–527.Baldwin,D.,Anderrson,A.,Saffran,J.,&Meyer,M.(2008).Segmenting dynamic human action via statistical structure.Cognition,106
,1382–1407.Bentin,S.,&Deouell,L.Y.(2000).Structural encoding and identification in face processing:ERP evidence for separate mechanisms.Cognitive Neuropsychology,17
,35–54.Brady,T.F.,&Oliva,A.(2008).Statistical learning using real-world scenes:Extracting categorical regularities without conscious intent.Psychological Science,19
,678–685.Bredart,S.(1993).Retrieval failures in face naming.Memory,1
,351–366.Bruce,V.,&Young,A.(1986).Understanding face recognition.British Journal of Psychology,77
,305–327.Burton,A.M.,Bruce,V.,&Johnson,R.A.(1990).Understanding face recognition with an interactive activation model.British Journal of Psychology,81
,361–380.Campanella,S.,Joassin,F.,Rossion,B.,De Volder,A.G.,Bruyer,R.,&Crommelinck,M.(2001).Association of the distinct visual representations of faces and names:A PET activation study.NeuroImage,14
,873–882.Conway,C.M.,Bauernschmidt,A.,Huang,S.S.,&Pisoni,D.B.(2010).Implicit statistical learning in language processing:Word predictability is the key.Cognition,114
,356–371.Conway,C.M.,&Christiansen,M.H.(2006).Statistical learning within and between modalities:Pitting abstract against stimulus-specific representations.Psychological Science,17
,905–912.Damasio,H.,Grabowski,T.J.,Tranel,D.,Hichwa,R.D.,&Damasio,A.R.(1996).A neural basis for lexical retrieval.Nature,380
,499–505.Diaz,F.,Lindín,M.,Galdo-Alvarez,S.,Facal,D.,&Juncos-Rabadán,O.(2007).An event-related potentials study of face identification and naming:The tip-of-the-tongue state.Psychophysiology,44
,50–68.Evrard,M.(2002).Ageing and lexical access to common and proper names in picture naming.Brain Language,81
,174–179.Fiser,J.,&Aslin,R.N.(2001).Unsupervised statistical learning of higher-order spatial structures from visual scenes.Psychological Science,12
,499–504.Fiser,J.,&Aslin,R.N.(2002).Statistical learning of higher-order temporal structure from visual shape sequences.Journal of Experimental Psychology:Learning,Memory,and Cognition,28
,458–467.Fiser,J.,&Aslin,R.N.(2005).Encoding multi-element scenes:Statistical learning of visual features hierarchies.Journal of Experimental Psychology:General,134
,521–537.Freire,A.,Lee,K.,&Symons,L.A.(2000).The face-inversion effect as a deficit in the encoding of configural information:Direct evidence.Perception,29
,159–170.Germain-Mondona,V.,Silvert,L.,&Izaute,M.(2011).N400 modulation by categorical or associative interference in a famous face naming task.Neuroscience Letters,501
,188–192.Goldwater,S.,Griffiths,T.L.,&Johnson,M.(2009).A Bayesian framework for word segmentation:Exploring the effects of context.Cognition,112,
21–54.Gorno-Tempini,M.L.,Price,C.J.,Josephs,O.,Vandenberghe,R.,Cappa,S.F.,Kappur,N.,&Frackowiak,R.S.J.(1998).The neural systems sustaining face and proper name processing.Brain,121
,2103–2118.Guillaumea,C.,Guillery-Girard,B.,Chaby,L.,Lebreton,K.,Hugueville,L.,Eustache,F.,&Fiori,N.(2009).The time course of repetition effects for familiar faces and objects:An ERP study.Brain Research,1248
,149–161.Huddy,V.,Schweinberger,S.R.,Jentzsch,I.,&Burton,A.M.(2003).Matching faces for semantic information and names:An event-related brain potentials study.Cognitive Brain Research,17
,314–326.Joassin,F.,Meert,G.,Campanella,S.,&Bruyer,R.(2007).The associative processes involved in faces-proper names versus-animals-common names binding:A comparative ERP study.Biological Psychology,75
,286–299Kanwisher,N.,McDermott,J.,&Chun,M.M.(1997).The fusiform face area:a module in human extrastriate cortex specialized for face perception.The Journal of Neuroscience,17
,4302–4311.Kinder,A.,&Shanks,D.R.(2003).Neuropsychological dissociations between priming and recognition:A single-system connectionist account.Psychological Review,110
,728–744.Kirkham,N.Z.,Slemmer,J.A.,&Johnson,S.P.(2002).Visual statistical learning in infancy: Evidence for a domain general learning mechanism.Cognition,83
,35–42.Langton,S.R.H.,Law,A.S.,Burton,A.M.,&Scweinberger,S.R.(2008).Attention capture by faces.Cognition,107
,330–342.Marcus,G.F.,Vijayan,S.,Bandi Rao,S.,Vishton,P.M.(1999).Rule learning by seven-month-old infants.Science,283
,77–80.Martins,I.P.,&Farrajota,L.(2006).Proper and common names:A double dissociation.Neuropsychologia,45
,1744–1756.Meulemans,T.,&van der Linden,M.(2003).Implicit learning of complex information in amnesia.Brain and Cognition,52
,250–257.Miller,G.A.,&Selfridge,J.A.(1950).Verbal context and the recall of meaningful material.American Journal of Psychology,63
,176–185.Otsuka,S.,Nishiyama,M.,Nakahara,F.,&Kawaguchi,J.(2013).Visual statistical learning based on the perceptual and semantic information of objects.Journal of Experimental Psychology:Learning,Memory,and Cognition,39
,196–207.Perruchet,P.,&Pacton,S.(2006).Implicit learning and statistical learning: One phenomenon, two approaches.Trends in Cognitive Sciences,10
,233–238.Perruchet,P.,&Vinter,A.(2002).The self-organizing consciousness.Behavioral and Brain Sciences,25
,297–330.Pickering,E.C.,&Schweinberger,S.R.(2003).N200,N250r,and N400 event-related brain potentials reveal three loci of repetition priming for familiar names.Journal of Experimental Psychology:Learning,Memory,and Cognition,29
,1298–1311.Rugg,M.D.,&Curran,T.(2007).Event-related potentials and recognition memory.Trendsin Cognitive Science,11
,251–257.Saavedra,C.,Iglesias,J.,&Olivares,E.I.(2010).Eventrelated potential elicited by the explicit and implicit processing of familiarity in faces.Clinical EEG and Neuroscience,41
,24–31.Saffran,J.R.(2001).Words in a sea of sounds:The output of infant statistical learning.Cognition,81
,149–169.Saffran,J.R.,Aslin,R.N.,&Newport,E.L.(1996).Statistical learning by 8-month-old infants.Science,274
,1926–1928.Semenza,C.(2006).Retrieval pathways for common and proper names.Cortex,42
,884–891.Sergent,J.,Ohta,S.,&McDonald,B.(1992).Functional neuroanatomy of face and object processing.Brain,115
,15–36.Servan-Schreiber,D.,&Anderson,J.R.(1990).Learning artificial grammars with competitive chunking.Journal of Experimental Psychology:Learning,Memory,and Cognition,16
,592–608.Shanks,D.R.,Channon,S.,Wilkinson,L.,&Curran,H.V.(2006).Disruption of sequential priming in organic and pharmacological amnesia:A role for the medial temporal lobes in implicit contextual learning.Neuropsychopharmacology,31
,1768–1776.Sobel,D.M.,Tenenbaum,J.B.,&Gopnik,A.(2004).Children’s causal inferences from indirect evidence:Backwards blocking and Bayesian reasoning in preschoolers.Cognition,28
,303–333.Theeuwes,J.,&van der Stigchel,S.(2006).Faces capture attention:Evidence from inhibition of return.Visual Cognition,13
,657–665.Turk-Browne,N.B.,Isola,P.J.,Scholl,B.J.,&Treat,T.A.(2008).Multidimensional visual statistical learning.Journal of Experimental Psychology:Learning,Memory,and Cognition,34
,399–407.Turk-Browne,N.B.,Junge,J.A.,&Scholl,B.J.(2005).The automaticity of visual statistical learning.Journal of Experimental Psychology:General,134
,552–564.Turk-Browne,N.B.,&Scholl,B.J.(2009).Flexible visual statistical learning:Transfer across space and time.Journal of Experimental Psychology:Human Perception and Performance,35
,195–202.Turk-Browne,N.B.,Scholl,B.J.,Chun,M.M.,&Johnson,M.K.(2009).Neural evidence of statistical learning:Efficient detection of visual regularities without awareness.Journal of Cognitive Neuroscience,21
,1934–1945.Webster,M.A.,&MacLeod,D.I.(2011).Visual adaptation and face perception.Philosophical Transactions of the Royal Society B:Biological Sciences,366
,1702–1725.Wiese,H.,&Schweinberger,S.R.(2011).Accessing semantic person knowledge: Temporal dynamics of nonstrategic categorical and associative priming.Journal of Cognitive Neuroscience,23
,447–459.Willingham,D.B.,Nissen,M.J.,&Bullemer P.(1989).On the development of procedural knowledge.Journal of Experimental Psychology:Learning,Memory,and Cognition,15
,1047–1060.Yuille,A.,&Kersten,D.(2006).Vision as Bayesian inference:Analysis by synthesis.Trends in Cognitive Science,10
,301–308.猜你喜欢
辽河(2022年4期)2022-06-09
东疆学刊(2022年2期)2022-04-22
小学生作文辅导·下旬刊(2020年5期)2020-07-23
智慧少年·故事叮当(2020年2期)2020-03-08
中学课程辅导·教师通讯(2020年22期)2020-02-04
人与自然(2019年4期)2019-07-26
中学生英语·外语教学与研究(2017年4期)2017-04-14
小学生时代·综合版(2009年11期)2009-12-29
当代贵州(2009年8期)2009-05-31
