
基于决策列表的中文同音词自动识别与校对
2015-01-29 02:57:20石敏高尚
电子设计工程 2015年9期
石敏,高尚
(江苏科技大学 计算机科学与工程学院,江苏 镇江212003)
中文文本校对[1-3]是自然语言理解领域的一个重要并具有挑战性的课题。尤其是随着现代信息处理技术的发展,计算机渐渐替代了传统文本工作,文本错误有随之越来越多。人工校对已无法满足需求时,文本自动校对的研究应运而生,具有深远意义。20世纪60年代,国外就开展了英文文本的自动校对研究[4],并取得可观的成果。从20世纪90年代开始,国内才开展了对中文文本的自动校对研究[5-7],中文输入不像英文直接输入到计算机,而是采用某种输入法,但凡能输入到计算机中的汉字都是存在于汉字库中的,所以中文错误只有“真词错误”。在这些错误中,同音词错误占很大比例,尤其是在拼音输入法下,人们很容易不小心将某个词写成它的同音词。
本文的工作就是校对文本时出现了同音词,即这个词是同音词混淆集中的词,判断这个同音词是否出错,如果出错正确的词应该是什么。如“我接收了他的建议”,要判断出其中的“接收”是错误的,并且能找出对应正确的“接受”。由于本文只是对同音词查错纠错,并且只是同音词混淆集中的词,所以纠错候选象是一组同音词,通过统计词的2元特征和上下文语境结合一定的计算公式来计算这个句子对哪个词的支持度高,这就是决策列表。
1 决策列表的构建
决策列表[8]的构建分为以下几个步骤,文章中结合2元模型[9]特征和上下文语境特征,因此需要的资源有同音词混淆集,2元模型,上下文语境。
Step1同音词混淆集
文章中我们整理出最容易出错的1 000对同音词组,文中只研究2、3字同音词,单字词和多字词不考虑,列出一部分如表1所示。

表1 同音词混淆集Tab.1 Homophone confusion set
Step2训练2元模型和上下文语境
我们需要大量的语料来训练词的2元模型和上下文语境特征,训练好的资源作为接下来所有判断的依据。
2元模型:即中心词词wi的前一个词和后一个词同现的频次,即

其中,Frq1,Frq2 为频次。
本文摘录4G大小的人民日报作为训练语料,最后统计出的2元模型如表2所示。

表2 训练2元模型Tab.2 2-gram model of words
上下文语境:即中心词前后最近的k个词,k为窗口大小,同2元模型一样,统计2元组以及出现次数,例如:句子2——“今日习主席接受了奥巴马总统的邀请,并于下个月访问美国”,统计“接受”窗口为3的上下文语境:

其中,Frq3,Frq4,Frq5,Frq6 为频次。
经过大量语料训练最后统计出的上下文语境模型如表3所示。
Step3提取待校对文本中同音词的2元特征和上下文特征ei

表3 上下文语境Tab.3 Context of words
这部分的工作是针对待校对文本的,文章中用到的所有测试文本都是经过分词的。校对文本时,首先找到同音词,然后提取同音词的2元特征和上下文,根据训练好的2元模型和上下文语境,找到这些特征2元组的出现频次。需要注意的是,像“的”“了”等词对区分一对同音词几乎没有什么作用,这样的词称停用词,统计时我们不考虑停用词。文章中用到的停用词资源是哈工大的停用词表,包括了最常见的504个停用字词。
例如:句子3——我今天接收了她的邀请明天去参加她的生日party。
其中“接收”是同音词,提取“接收”的2元特征和上下文特征 ei:
2元特征:今天,“了”是停用词,因此不考虑。
窗口为4的上下文特征:我,她,接受
Step4计算提取的特征对同音词的支持度sup
sup

其中

说明:frq(wi,ei)是从 Step2中训练好的模型查找出的 2元组
经过 Step3,Step4得到表 4,表 5:

表4 特征2元组频次Tab.4 Frequency of 2-gram feature
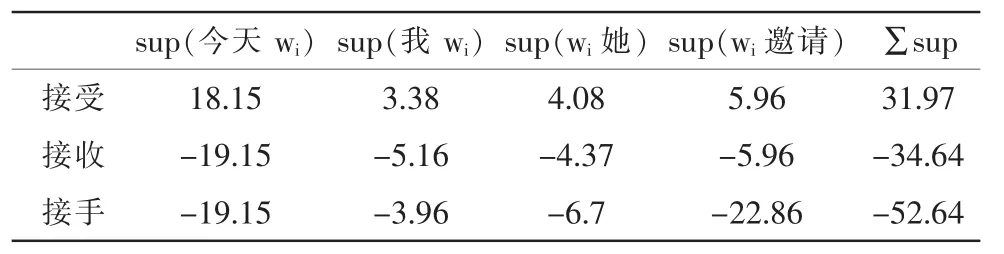
表5 决策列表Tab.5 Decision list
决策列表就是各特征以及整个句子对同音词的支持度,从表5的最后一列中可以看出,sup(接受)>sup>(接收)>sup(接手)所以句子3中的“接收”是错误的,应该改为“接受”。校对后句子为“我 今天 <接收|接受>了 她 的 邀请 明天 去参加 她 的 生日 party。”这样就完成了句子3的查错和纠错。
2 实验结果及分析和改进
2.1 实验结果
首先选取了最常见的易出错的20组同音词构成实验的同音词混淆集,从百度上摘录包含这些同音词的2 000条正确句子,手工将一部分正确的词改错成它的同音词,这样构成了测试集。通过实验,文本总共错误800处,程序召回659处,其中正确召回599处,正确纠正570处,召回率达74.88%,准确率90.9%,纠错率95.16%。
2.2 实验结果分析
本实验系统中,试验结果的好坏与一些因素有关,如:
1)分词的准确度
由于本实验是通过大规模语料统计模型都是在分词的基础上进行的,因此分词的准确度对实验结果有影响,但是到目前的分词方法都不能达到100%的准确度。另外,由于中文本身的复杂性,语料涉及的领域广泛,分词过程中难免会碰到词典的未登陆词,对分词及最终结果都有影响。
2)数据稀疏性
本实验中的决策列表构建依据是大规模语料训练出来2元模型和上下文语境,所用的大规模语料有限,数据稀疏在所难免。这样导致很多2元组的出现频次为0,会影响到实验结果。
2.3 实验改进
实验中通过观察中间结果,发现那些未召回的错误80%以上都是由于数据稀疏导致的,例如:句子4——半晌,她 转身 进去 抱 杯子 了。 实验发现,2元组<进去 杯子><进去 被子><抱 杯子><抱 被子>的出现频次均为0,因此系统无法将这类错误召回。
改进思路是通过同义词聚类。举个例子,假设模型中<接受 采访>频次为0,那么就找“采访”的同义词“访问”等,也就是计算时我们可以用<接受 访问>的频次代替,如果有多个同义词,则频次相加作为原2元组<接受 采访>的频次。实验室需要用到同义词聚类表,这里用的是哈工大信息检索研究室同义词词林扩展版,例如其中一条数据“Bp07B01=杯 杯子 盅 盅子 盏”,Bp07B01是这条数据的编码,后面是一组同义词,当程序发现2元组<抱 杯子>的频次为0时,我们可以做这样的替代 Frq(抱 杯子)=Frq(抱 杯)+Frq(抱 盅)+Frq(抱盅子)+Frq(抱 盏),对于“被子”做同样的处理,最终实验结果表明能正确召回这个错误。
经过上述的改进,程序召回680处,其中正确召回628处,正确纠正599处,召回率=78.5%,比原实验结果有所改善。
3 结束语
本文对汉语文本校对中的同音词错误进行自动查错和纠错,首先通过大批语料统计同音词的2元模型和上下文语境,然后在校对文本时提取同音词的2元和上下文特征,构建决策列表,通过比较特征支持度,最后判断是否出错并找到最合适的进行替换。由于数据稀疏,还加入同义词聚类[10]说进行改进,最后取得比较好的实验结果。今后考虑加入词性和远距离搭配,进一步改进实验,提高系统性能。
[1]李晶皎,张莉,姚天顺.汉语语音理解中自动纠错系统的研究[J].软件学报,1999,10(4):377-381.LI Jing-jiao,ZHANG Li,YAO Tian-shun.Research on automatic checking and confirming correction for chinese speech understanding[J].Journal of Software,1999,10(4):377-381.
[2]吴岩,李秀坤,刘挺,等.中文自动校对系统的研究与实现[J].哈尔滨工业大学学报,2001(2):60-64.WU Yan,LI Xiu-kun,LIU Ting,et al.Research and implementation of chinese text automatic system[J].Journal of Harbin Institute of Technology,2001(2):60-64.
[3]张磊,周明,黄昌宁,等.中文文本自动校对[J].语言文字应用,2001,2(1) :19-25.ZHaNG Lei,ZHOU Ming,HUANG Chang-ning,et al.Automatic detection and correction of typed errors in chinese text[J].Applied Linguistics,2001,2(1):19-25.
[4]Kukich K.Techniques for automatically correcting words in text[J].ACM Computing Surveys,1992,24(4):377-439.
[5]刘挺,施洪滨.中文计算机辅助校对系统原理[J].中文信息,1997(2):21-22.LIU Ting,SHI Hong-bin.Principle of chinese computer aided detection and correction system[J].Chinese Information,1997(2):21-22.
[6]邱超捷,宋柔.大规模语料库中词语接续对的统计与分析[A].第四届计算语言学会议论文集(语言工程)[C]//北京:清华大学出版社,1997.
[7]郭志立.中文校对系统中的修改建议提供算法;第四届计算语言学会议论文集(语言工程)[C]//北京:清华大学出版社,1997.325-330.
[8]Hiroyuki Shinnou.Detection of Japanese Homophone Errors by a Decision List Including a Written Word as a Default Evidence[C]//Proceedings of EACL’99,180-187.
[9]张仰森,丁冰青.基于二元接续关系检查的字词级自动查错方法[J].中文信息学报,2001,15(3):36-43.ZHANG Yang-sen,DIng Bing-qing.Automatic errors detecting of chinese texts based oil the bi-neighborship[J].Chinese Information Technology,2001,15(3):36-43.
[10]罗智勇,宋柔.相似词及其在计算机辅助校对系统中的应用[C]//全国第八届计算语言学联合学术会议(JSCL-2005)论文集.南京;2005.
猜你喜欢
电脑报(2021年14期)2021-06-28 10:46:22
智富时代(2019年6期)2019-07-24 10:33:16
计算机与生活(2019年5期)2019-07-18 01:08:56
意林图解作文(小学版)(2018年11期)2018-12-01 03:03:34
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
山西青年(2017年15期)2017-01-30 15:56:04
高中生·天天向上(2016年9期)2016-11-22 09:10:34
人间(2016年29期)2016-11-10 12:38:13
电信科学(2013年10期)2013-08-10 03:41:54
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
