
一种基于语言模型的微博检索技术
2015-01-29 02:57:14王菁菁
电子设计工程 2015年9期
潘 超,王菁菁
(厦门大学 信息科学与技术学院,福建 厦门 361005)
伴随着社交网络应用的出现和发展,微博以其平台开放、内容简洁和操作方便等特性,迅速发展成为近年来一个重要的社会媒体。通过微博这个平台,人们可以获得真实事件的第一手报道、分享信息并且表达自己独特的观点,参与话题讨论等。迅速地,微博聚集了数以万计的用户,并成为宝贵的资源并吸引了大量的科学研究,包括微博检索[1]、热点话题识别[2]和摘要生成技术[3]。
然而,与传统的文本不同,微博文本有其独特的特性:首先,微博文本内容限制140个字符,因此,微博文本比较简短并出现了缩略语和新词等;其次,微博文本可以包含特殊的标签,例如标签“@”,标签后面加上用户名可以让对方收到提醒,对方通过链接,可以查看你的微博,再如标签“#”表示特定的讨论话题;如果有限的字符无法完整地表达观点,用户可以嵌入外部链接、视频或图片等。
M.Efron[4]提出利用微博文本中的标签来扩展检索,M.Efron和 G.Golovchinsky[5]第一次提出了利用微博的时效性,目的是为了使近期发表的微博拥有更高的相关性,X.Li[6]基于时间的模型中,赋予每条微博先验概率,代表每条微博的“新鲜度”。R.Jones[7]在整个生命周期内为每个查询构造时间分布。然而,这些工作都没有系统地将微博的特性融合到模型中。
因此,本文基于语言模型并融合微博文本的特性,提出一种动态伪相关反馈模型(DPRF)。在给定查询事件的情况下检索相关微博,通过假设伪相关反馈的先验概率是依赖于一个给定的查询事件的发生周期和暴发周期,DPRF在每一个事件暴发周期内挑选出代表性的关键词来扩展原始的查询,从而能有效的代表原始查询,提高检索的准确率。实验结果表明,该方法能提高和改善微博检索的性能。
1 检索模型
1.1 语言模型
现代信息检索中,语言模型方法在整个语料C的所有词汇W上对每条微博d估计其概率分布θd,对每个查询Q建模θQ,根据每条微博与查询的似然值计算相关性得分,进而对结果排序。传统的方法是计算从查询生成文档的概率,本文利用通过计算查询与文档之间的KL散度进行排序,如公式(1):

其中,P(w|θQ)=,tf表示词频,在查询扩展方法中,我们计算 P(w|θQ′)。
然而,原始的查询通常长度较短且所表达的意思模糊,并不能完全覆盖潜在的信息需求。为了增强查询的表达能力,我们利用查询扩展技术生成新的高质量查询Q′,来替代原来的查询Q。在伪相关反馈方式中,假设通过原始查询Q得到的前N个微博文档d+其分布记作θF,我们简单地使用线性的方式将原始查询与θF相结合,如公式(2):
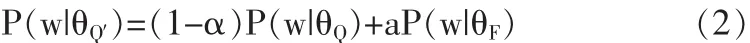
其中,参数α来控制新旧查询之间的相关度。
接下来,阐述θF的推导。对于θF,相关性模型近似地把每个伪相关文档看成查询模型的一个抽样。因此,相关性模型方法将θF上词的分布定义为伪相关方式生成的词的似然,如公式(3):
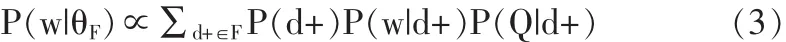
其中,P(Q|d+)=∏q∈QP(q|d+)
1.2 动态伪相关反馈
在传统的伪相关反馈技术中,先验概率P(d+)通常为均匀分布。然而,这样的假设在即时传播媒如微博,并不能够成立。例如“药家鑫事件”,从事件曝光、药家鑫依法被捕,案件开审,一审判决,二审判决、执行死刑、最后引发社会评论,整个事件可以看成许多不同的阶段,各个阶段对应事件的不同进展和微博平台上讨论的爆发时段。我们首先假设前N个相关微博文档d+的先验概率仅依赖于它们到对应暴发时间段中心的距离td+。用φ={φ1……φX}表示某个查询事件对应的K个暴发时间段,我们提出3种不同的概率函数来拟合暴发时间段的分布,这些概率函数采用不同的机制对暴发时间段的有效范围、衰减系数和偏度进行建模。
1)多重高斯分布
假设其先验概率是正态分布,每个暴发时间段的中心位置为其峰值位置。一条微博可能受到多个暴发时间的影响,并且在暴发时间段前与后的影响是对称的,如公式(4):

其中,参数σ是控制暴发点的影响范围。
2)近邻多项式
假设一条微博只受1个暴发时间的影响,且在暴发时间段前与后的影响是对称的。对每一个微博文档d+,选取到最近暴发时间点的最小距离,如公式(5):

其中,r(d+,Øk)某条微博文档 d+到某一暴发时间点的最小距离,参数σ是控制暴发点的影响范围。
3)倾斜线线
假设一条微博只受1个暴发时间的影响,且在暴发时间段前与后的影响是不对称的,向前影响只影响到某个范围。利用每个暴发时段的界限,如果文档d+在某个暴发时段内,则

否则,计算文档d+离最近的在它之前的暴发时段的距离l,则

其中,参数σ是控制暴发点的影响范围,K表示暴发时间段的个数。
2 实验结果与分析
本实验的数据集来自新浪微博,我们使用新浪微博提供的API随机选择某一用户,迭代地获取它的粉丝与微博,从2009年8月14日到2012年5月28日共爬取30 198 929条微博,包括回复与转发的微博,并且含有其它国家的字符,具体数据见表1。
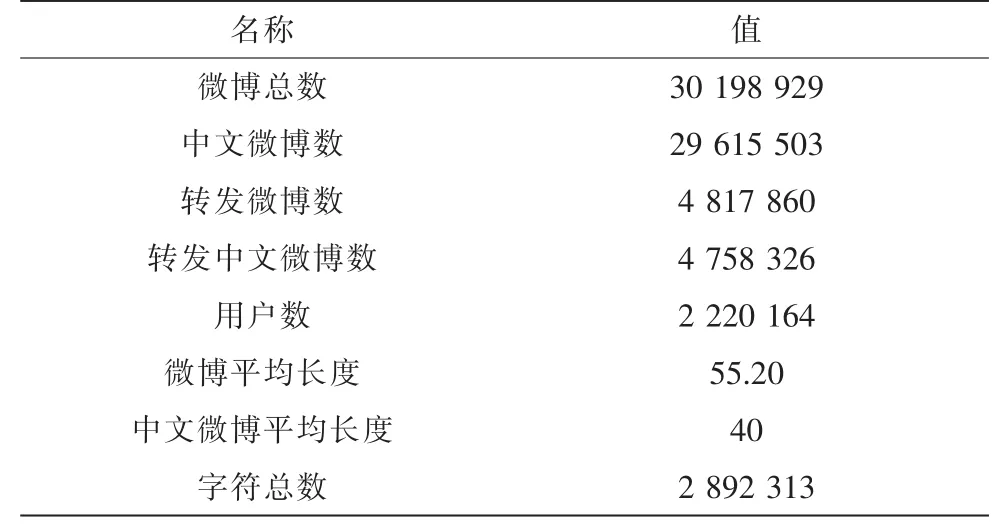
表1 数据集统计Tab.1 The statistic of dataset
我们对提出的查询扩展模型进行了验证,在本次实验中,我们使用了4个基本检索模型,3个伪相关反馈模型和本文提出的动态伪相关反馈模型进行对比:
1)Lucene:使用 Lucene 进行检索;
2)PL2:Terrier提供的一种语言模型;
3)KLJM:计算文档与查询的KL散度,使用JM平滑防止未出现的词项使得分为零,模型中的参数设置为0.5。
4)RLM:一种融合时间特征的语言模型,主要目的为给每条微博文档添加先验概率,使得较近期出现的微博获得较高的计算得分。
5)Rocchio:一种伪相关反馈查询扩展方法,使用Rocchio公式。本文使用RLM的结果列表作为候选集。
6)Bo1:Terrier提供的伪相关反馈模型,使用PL2的结果列表作为候选集。
7)KL:Terrier提供的伪相关反馈模型。
8)DPRF:本文提出的动态伪相关反馈模型。
如表2所示,与传统的自然语言文本相比,微博具有自身独特的特性,在语言模型中融合微博的这些特性能够提高微博的检索性能。同时,由于原始查询语义表达的有限,查询扩展方案能够有效的进行补充,因此,PRF方法在原有的检索模型上有一定的提升。而DPRF进一步结合了微博的特性,极大地提高了微博检索的性能。
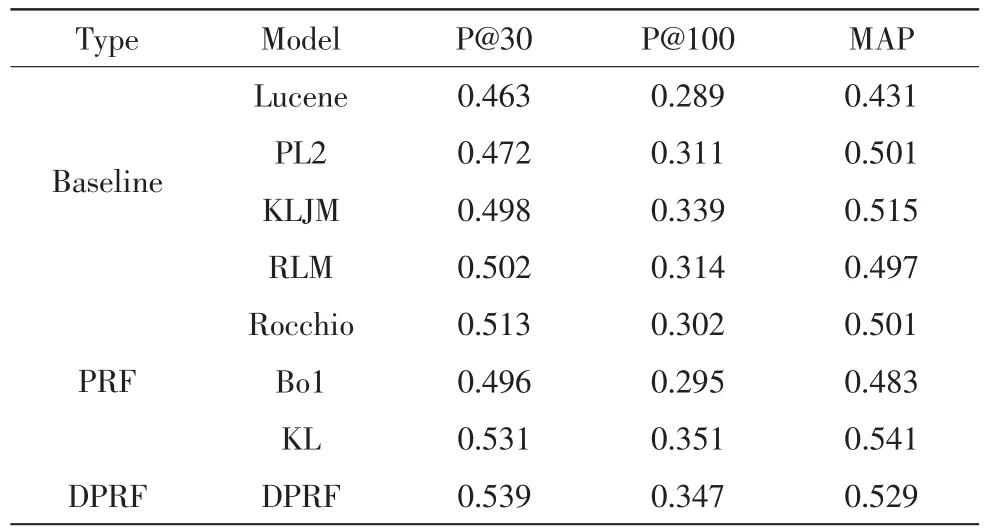
表2 不同检索模型的实验结果Tab.2 Results of different retrieval model
3 结束语
文中融合了微博自身所具有的独特特性,结合事件微博具有一定的暴发时间周期,提出动态伪相关反馈模型,实验证明该模型在原有的基础提高了检索效果。信息检索技术在传统的文本上拥有成熟的技术,而微博文本作为互联网时代的产物,给检索研究工作带来了新的挑战。在未来的工作中,笔者将进一步挖掘微博的特性,提出更加有效的模型提高微博检索的性能。
[1]Efron M.Information search and retrieval in microblogs[J].J.Am.Soc.Inf.Sci.Technol.,2011,62:996-1008.
[2]Mathioudakis M,Koudas N.Twitermonitor:trend detection over the twitter stream[J].In Proceedings of SIGMOD,2010:1155-1158.
[3]Takamura H,Yokono H,Okumura M.Summarizing a document stream[J].In Proceedings of ECIR,2011:177-188.
[4]Efron M.Hashtag retrieval in a microblogging environment[J].In Proceedings of SIGIR,2010:787-788.
[5]Efron M,Golovchinsky G.Estimation methods for ranking recentinformation[J].In Proceedingsof SIGIR,2011:495-504.
[6]Li X,Croft W B.Time-based language models[J].In Proceedings of CIKM,2003:469-475.
[7]Jones R,Diaz F.Temporal profiles of queries[J].ACM Trans.Inf.Syst.,25,2007.
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
中国新闻周刊(2021年26期)2021-07-27 04:02:12
今日农业(2020年13期)2020-08-24 07:35:24
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
意林(2017年8期)2017-05-02 17:40:37
信息安全研究(2016年4期)2016-12-01 06:06:54
校园英语·下旬(2016年2期)2016-03-18 10:23:20
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
医学研究杂志(2015年5期)2015-06-10 06:43:26
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
