
XML 文档到关系型数据库的模型映射方法
2015-01-15 05:51沈艳霞
服装学报 2015年5期
史 涛, 沈艳霞
(江南大学 电气自动化研究所,江苏 无锡214122)
XML 凭借其独立于平台、可扩展性和自描述性等特性[1]广泛应用于异构数据集成系统的设计中,实现不同数据源之间的信息交换和共享[2]。随着XML 应用的不断深入,在诸多领域都产生了海量的XML 数据,如何高效地存储这些XML 数据已成为值得研究的重要课题[3]。现阶段,关系型数据库仍然是企业应用最广泛的数据库,基于此,实现XML与关系型数据库的数据交换对企业数据集成平台的设计具有现实意义。
将XML 文档中的数据有效且精确地分解到关系型数据库中,要求采用强健且无缝的映射方法。在映射过程中,XML 文档中节点关系的完整保存更有利于精确地实现用户检索过程。用户检索可以分为两种方式,即全文本检索和结构检索[4]。全文本检索只包含关键字检索,没有具体的限制条件,是使用最普遍的检索方式,其特点是简单方便,缺点是检索结果不精确,效率较低。结构检索包含多个限制条件,能够返回更精确的答案。显然为了在关系型数据库中得到更为精确的查询结果,结构检索方式是不错的选择。
目前,国内外学者对映射技术的研究已经取得了一定进展。文献[5]提出的边缘(Edge)方法是最简单直接的方法,主要思路是使用整数标记节点,使用XML 文档中的元素名标记边缘这两种形式将整个XML 文档存储在单个关系型表格中,这种方法只适用于简单的XML 文档,而针对复杂组合的XML 文档可能出现“超出表格大小”的错误。与Edge 方法相比,属性[5](Attribute)方法根据XML文档中的元素名称创建足够多的表格来进行存储。这种方法虽然适用于具有复杂结构的XML 文档,但是过多的表格会消耗资源和机器内存。文献[6]提出的DTD 方法在XML 文档中元素出现频率的基础上映射XML 数据,允许更少的空间消耗、简单的表格模式和有效的表格映射机制,但该方法只适用于XML 文档模式由DTD 表示的情况,具有局限性。文献[7]中用来存储XML 文档结构的是编码字符串的大文本字段,这种方法降低了维持XML 文档结构的代价,但却提高了查询XML 文档的难度。文献[8]提出一种新的基于模式的方案,其利用分离和连接的操作符来构成模式及其相应的数据元素,易于呈现复杂的映射请求。文献[9]提出一种数据模型,通过同时表示数据视图和结构视图的方式来改写XML 文档,进而实现XML 文档的映射过程。上述两种映射方法的设计都基于XML 模式,无法支持动态的XML 数据存储。
综上所述,很多现存的映射技术在实现结构化检索的前提下,往往会消耗更多的资源和内存,如文献[5,7];还有一些映射方案,如文献[6,8-9],虽然能够实现高效的结构化查询,但需要考虑XML 文档的模式,只支持静态的XML 数据存储,无法应用在XML 模式不断变化的情况。
文中提出一种从XML 文档到关系型数据库的高效映射方案,利用特殊的标记节点方法,通过遍历XML 文档对节点进行编码,有效获取节点关系,实现了高效的结构化查询。该映射方法不仅实现了高效的结构化查询检索方式,同时不需要考虑XML文档的具体模式,支持任何格式良好的XML 数据的动态存储。文中将该方法与现有的3 种存储XML 文档方法,即Edge、Attribute 以及DTD,在存储空间、映射时间和检索时间3 个方面进行比较。
1 理论概述
1.1 XML 数据模型
一个定义良好的数据库系统的基础在于具有定义良好的数据模型。XML 数据模型一般被简化为标记树或者直观显示的图表,其中携带着表示结构数据和属性值的元素。XML 具有多种不同的数据模型,其中Xpath1.0 和DOM 模型都将XML 文档转换为树结构。Xquery 1.0 和Xpath 2.0 模型使用7 种节点将XML 文档转换成图表[10]。文中采用DOM 模型,具体考虑XML 文档中4 种类型的节点,分别为根节点、元素节点、文本节点和属性节点[11]。图1 是一个XML 文档的具体实例和通过DOM 模型解析得到的XML 树结构,实例中包含上文提到的4 种节点类型。
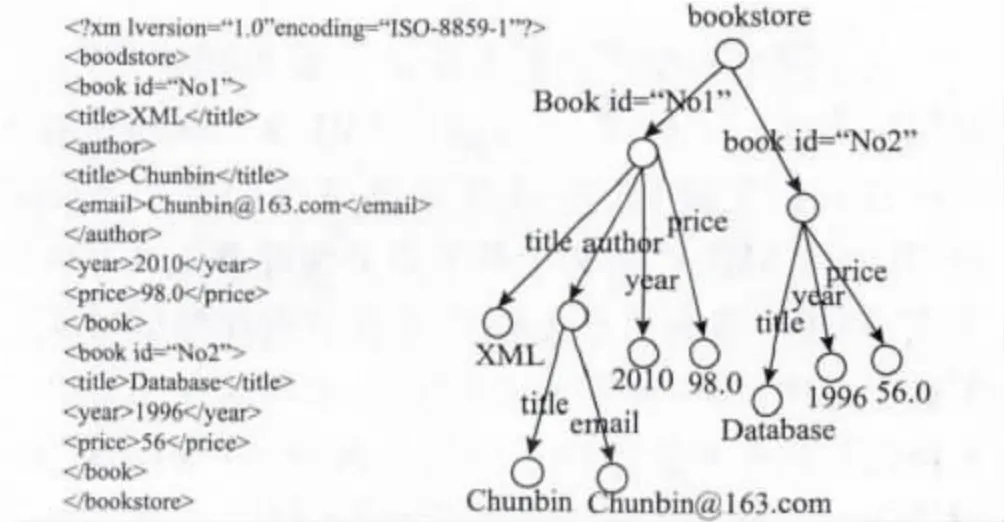
图1 XML 文档实例Fig.1 XML documents instance
1.2 XML 节点关系
图2 显示的是在XML 文档中节点的4 种主要关系类型,分别为:a:父-子关系;b:祖先-子代关系;c:同胞关系;d:层级信息[12]。这些信息在映射过程需要被保存下来,满足检索用户的查询需要。
文中在文献[13]提出的连续性标记模式方法的基础上,提出一种标记节点的方法。该方法能够保存节点间的关系信息,有效支持结构化的查询检索方式。也就是,每个节点将被标记为形如(1,np,n),其中:1.XML 树种节点的层级;n.该节点相对于同胞的位置,称为节点的区域标记。np. 父节点的区域标记;可以推断,对于根节点nr,因为没有父节点,可以被标记为(0,NULL,1),具体实例如图3所示。

图3 标记解释Fig.3 Expalanation of nodes
2 具体算法设计
文中提出的模式映射方法的主要思路是:首先利用特有的标记形式,通过遍历XML 文档树对所有节点进行标记编码,有效获取各节点间的关系信息;其次将XML 树结构中的节点分为叶节点和非叶节点,创建对应的两个表格将所有节点存储到关系型数据库中。具体流程如图4 所示。其中标记节点和表格映射两个步骤作用于映射过程中,查询检索步骤用于对存储在关系型数据库中的XML 文档进行查询检索。算法的具体设计思路在下文详细说明。
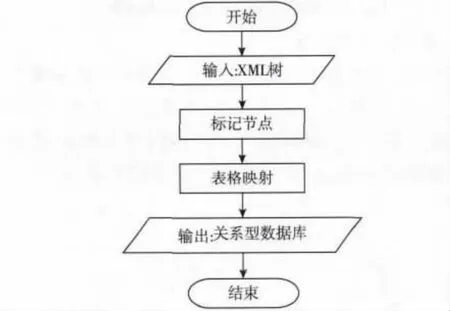
图4 算法流程Fig.4 Flowchart of the algorithm
2.1 步骤1:标记节点
步骤1 的具体算法(标记节点)实现如下所示。
步骤1)标记节点:
1)输入:XML 树,Τ
2)输出:标记的XML 节点,η
3)int level = 0
4)function labelNode(document)
5)if(ηr= = root node in Τ)
6)then label forηr(level,NULL,sn = 1)
7)level ++
8)for each child node ofηr,ηc(i)do{
9)label for nodeηc(i)(level,np= 1,n = 1)
10)getCNodes(ηc(i),n,level)
11)n ++
12)i ++
13)}//endfor
14)}//endfunction
15)
16)function getCNodes(ηc(i),npc,levelchild)
17){levelchild ++
18)for each child node ofηc(i),ηnextc(i)do{
19)label for nodeηnextc(i)(levelchild,np= npc,n =1)
20)getCNodes(ηnextc(i),n,levelchild)
21)getValue(ηnextc(i),n,levelchild)
22)n ++
23)i ++
24)}//endfor
25)}//endfunction
26)
27)function getValue(ηnextc(i),npleaf,levelleaf){
28)levelleaf ++
29)for each child node ofηnextc(i),ηleaf(i)do{
30)label for nodeηleaf(i)(levelleaf,np= npleaf,n =1)
31)}//endfor
32)}//endfunction
步骤1 中,每个节点都被特定的标记模式所标记,形 如(l,np,n)。XML 文 档,即 步 骤1 中 的document 能够被XML 解析器解析出所有节点,具体实现为步骤1 中的第4 行。函数labelNode()标记出根节点ηr。因为根节点没有父节点,所以如步骤1 中第6 行所示,np被标记成NULL。根节点的子节点,即ηc(i),通过函数getCNodes()标记,具体实现如步骤1 的16 ~25 行。当增加XML 节点的层级时,每一个子节点都被递归地送入函数getCNodes()生成随后的子节点,递归函数的结束条件为levelchild 等于层数。叶节点的标记由函数getValue()实现,即步骤1中的27 ~32 行。
2.2 步骤2:表格映射
步骤1 中输出的信息将被映射到两张表格,分别为内部节点表格inNodeTable 和外部节点表格exNodeTable。内部节点表格存储的是非叶节点,即内部节点;外部节点表格存储的是叶节点,即外部节点。
下面介绍两个表格的具体字段:
inNodeTable(nodeID,pName,cName,level,lParent,selfLabel):
(a)nodeID:存储在内部节点表格中的节点唯一识别编号
(b)pName:存储父节点的元素名
(c)cName:节点名称
(d)level:层级
(e)lParent:节点的父节点的nodeID
(f)selfLabel:节点所在层级的区域标签
exNodeTable(nodeID,level,pName,selfLabel,lParent,value):
(a)nodeID:存储在外部节点表格中的节点唯一识别编号
(b)level:存储节点在XML 文档中的层级
(c)pName:存储父节点的元素名
(d)selfLabel:节点所在层级的区域标签
(e)lParent:存储在内部表格中的父节点的nodeID
(f)value:存储节点的值
步骤2 实现的是节点到表格的映射过程。下文采用和步骤1 同样的方法对XML 文档进行递归遍历。从步骤1 推导出的节点标签,即层级(1),区域标签(n),父标签(np)将被分别映射到level,selfLabel 和lParent 三列当中。具体算法实现步骤如下所示。
步骤2:映射XML 节点到关系型数据库:
1)function createTable(){
2)long timeBefore = System.currentTimeMillis();
3)connect to the database
4)}
5)
6)// 插入根节点
7)function rootN(Doucument doc){
8)insert into inNodeTable(pName,cName,level,selflabel,lParent)values(NULL,root.getNode Name(),level,n,’NULL’)
9)// 插入第1 层的节点
10)insert into inNodeTable (pName,cName,level,selflabel,lParent)values(cNode.getParentNode( ).getNodeName( ),cNode.getNodeName(),level,n,nodeID)
11)}
12)
13)// 插入其他非叶节点
14)function child(ηnextc(i)){
15)insert into inNodeTable (pName,cName,level, selflabel,lParent)values(cN.getParentNode( ). getNodeName( ),cN.getNodeName(),level,n,nodeID)
16)child(ηnextc(i))
17)// 插入叶节点
18)leafNode(ηnextc(i))
19)}
20)
21)function leafNode(ηnextc(i)){
22)insert into exNodeTable (level,selfLabel,lParent,value)values(level,n,nodeID,cData.getNodeValue())
23)}
24)long timeAfter = System.currentTimeMillis();
25)Time taken to map = timeAfter-timeBefore
2.3 步骤3:查询检索
步骤3 描述的是查询检索过程。如果查询条件包括一个关键词以及节点间关系的组合,在外部节点表格中检索lParent 字段,该字段决定了内部节点表格中父-子关系或者祖先-子代关系,如步骤3 中5 ~7 行所示;如果是结构查询,那么将在内部节点表格中使用lParent 字段值进行搜索查询如步骤3中8 ~11 行所示。
步骤3:在关系型数据库中进行查询检索过程:
1)输入:查询条件,例如元素名,值或者节点间各种关系的组合
2)输出:从数据库返回的结果集
3)v:= 节点文本值
4)e:= 节点间关系组合的元素名
5)if(input = = v)
6)then criteria of the query is value = v from exNodeTable
7)endif
8)if(input = = e)
9)if(e = = parent-child relationship)&&
(e = = ancestor-descendant relationship)&&
(e = = leaf node)
10)then trace the node from exNodeTable to inNo deTable by matching lParent from exNodeTable to nodeID in inNodeTable
11)endif
12)if((e = = parent-child relationship)&&
(e = = ancestor-descendant relationship)&&
(e!= leaf node))
13)then trace the node in inNodeTable
14) only match lParent and nodeID in inNode Table
15)endif
16)endif
图5 描述了利用步骤3 对于文中之前提到的节点间4 种主要关系的检索过程。由此可以在关系数据库中实现对XML 文档中各节点的检索。
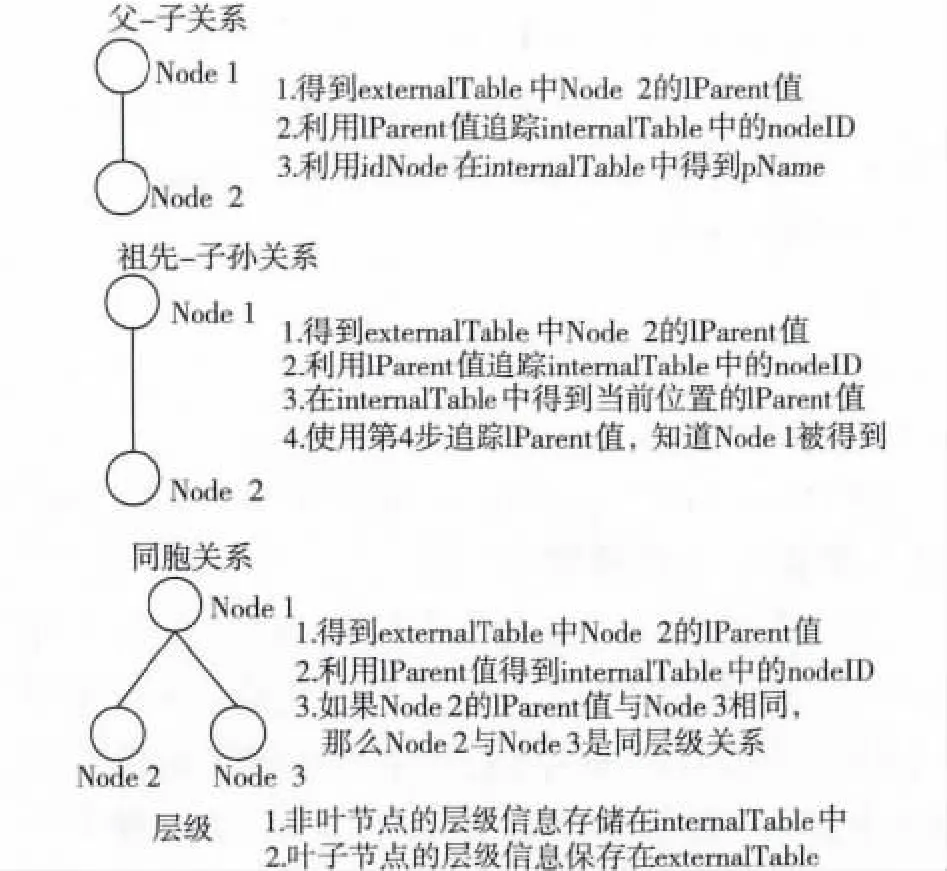
图5 4 种节点关系的检索过程Fig.5 Search of four node relations
3 实验评估
为了验证提出的模式映射方法的有效性,将文中所提方法与现有的3 种映射方法,即基于边缘、基于属性和关系型DTD 3 种方法进行比较。评价指标分别为:将XML 文档映射到关系型数据库的时间;映射过程完成后的存储时间;从关系型数据表中执行查询的时间。
文中数据源来自于 Washington UW Repository[14]下 载 所 得 的Digital Bibliography &Library Project(DBLP)数据集大小为0.67G。实验的测试平台是Altova Spy 和Microsoft Visual Studio 2010 标准环境,采用文档对象模型DOM 对XML 进行解析处理,将Microsoft SQL server2008 作为关系型数据库服务器,C#作为算法编程语言。其中记录的时间由5 组连续执行的平均值确定,以求数据更为准确。
3.1 XML 数据映射到关系型数据库
第1 个实验用于测量将XML 数据映射到关系型数据库的时间,其结果如图6 所示。在映射过程中一共包含3 个步骤,分别为数据库创建、表格创建以及加载XML 数据。

图6 映射时间Fig.6 Time of mapping
由图6 可知,通过文中方法得到的映射时间为37 254 ms,而关系型DTD 和基于属性的方法映射时间分别为62 150 ms 和49 987 ms,后两者时间明显大于文中方法。其主要原因是关系型DTD 和属性两种方法分别根据元素重复出现的频率和独立元素的个数生成相应数量的表格,导致创建表格和数据加载这两个环节的时间过长。相比之下,文中的方法只包含两个表格来有效地存储XML 数据,表现最好。
3.2 关系型数据库存储容量
第2 个实验评估通过边缘、属性、DTD 和文中所提方法将XML 数据映射到数据库之后,存储数据的容量大小比较。图7 显示了评估结果。

图7 存储空间Fig.7 Space of storage
由图7 可知,基于属性和关系型DTD 方法所消耗的存储容量分别为698 MB 和608 MB,利用的空间较高,原因是基于属性方法根据XML 文档中独立元素的个数创建相应多的表格,而关系型DTD 方法根据文档中元素重复出现的频率同样创建相应多的表格,两者创建更多的表格数,导致空间占有更大。基于边缘的映射方法存储容量为585 MB,相比前两种方法占有的空间更少,原因是该方法将整个XML 文档都存储在一个表格中。同理,文中方法创建两个表格来存储XML 文档,消耗的存储空间较少。
3.3 查询过程
第3 个实验对数据库中存储的数据集的查询时间进行评估。实验分别选用不同存储容量的源数据,采用目前较为复杂的查询方法——twig 对数据集进行查询。具体实验结果如表1 所示。

表1 查询检索时间对比Tab.1 Time comparison in terms of query
由表1 得出,针对4 种存储容量不同的元数据,基于边缘和属性两种方法在进行twig 查询时都耗费更多的时间。相对而言,关系型DTD 方法是一种更好的方法,因为其在处理简单的结构化XML 树时具有优势,但是在处理结构不完整的XML 数据时其表现差于文中所提出的方法。造成这种差异的主要原因是DTD 映射模式创建了大量表格,导致节点关系之间出现大量连接。显然,文中所提出的映射方法不存在上述情况,相比较其他方法,其在查询过程中表现出了更高的效率。
4 结 语
XML 文档要求强健无缝的映射方法来实现将数据有效且精确地存储到关系型数据库中。一种好的映射方法应该保存XML 树结构中的4 种主要关系,分别为父-子,祖先-子代,同胞以及XML 的层级,有效支持结构化的查询检索。文中提出的映射方案利用特殊的标记节点方法,在映射过程中保存节点之间的关系,高效实现了结构化检索。实验结果表明,文中所提出的方法具有以下几个特点:(1)在数据库存储和数据加载方面表现坚固;(2)支持结构化检索;(3)不受模式限制,支持任何格式良好的XML 文档;(4)相比较基于边缘、属性和关系型DTD 等现有方法,映射效果更理想。
[1]Femau H.Learning XML grammars[C]//7th International Conference,MLDM 2011.New York:[s.n.],2001,1:73-87.
[2]袁景凌,徐丽丽,苗连超.基于XML 的虚拟法异构数据集成方法研究[J].计算机应用研究,2009,26(1):172-174.
YUAN Jingling,XU Lili,MIAO Lianchao.Research on virtual approach about heterogeneous data integration based on XML[J].Application Research of Computers,2009,26(1):172-174.(in Chinese)
[3]Haw S C,Lee C S,Node labeling schemes in XML query optimization:a survey and trends[J].IETE Technical Review,2009,26(2):88-99.
[4]曹兰英,严义,邬惠峰.基于模式匹配的XML 自动转换技术[J].计算机工程与应用,2012,48(25):72-76.
CAO Lanying,YAN Yi,WU Huifeng. Automating XML document transformations based on schema matching[J]. Computer Engineering and Applications,2012,48(25):72-76.(in Chinese)
[5]Florescu D,Kossmann D.Storing and querying XML data using an RDBMS[J].IEEE Data Engineering Bulletin,1999,22(3):27-34.
[6]Shanmugasundaram J,Shekita E,Kiernan J,et al.A general technique for querying XML documents using a relational database systems[EB/OL].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.118.6801.
[7]耿飚,宋余庆,粱成全,等.XML 文档到关系数据库映射方法的研[J].计算机应用研究,2010,27(3):951-954.
[8]LI Xuhui,ZHU Shanfeng,LIU Mengchi,et al.Presenting XML schema mapping with conjunctive-disjunctive views[J].Web-Age Information Management Lecture Notes in Computer Science,2013,7923:105-110.
[9]Eun-Young Kim,Se-Hak Chun.New database mapping schema for XML document in electronic commerce[J]. Multimedia and Ubiquitous Engineering,2013,240:353-358.
[10]Clark J,Derose S. XML path language(Xpath)version 1. 0[EB/OL]. W3C Recommendation. http://www. w3. org/TR/xpath,1999.
[11]QIN Jie,ZHAO Shumei,YANG Shuqiang,et al.Efficient storing well-formed XML documents using RDBMS[C]//International Conference on Services Systems and Services Management.Chongqing:IEEE,2005,2:1075-1080.
[12]Edith Cohen,Haim Kaplan,Tova Milo.Labeling dynamic XML trees[J].Siam Journal on Computing,2002,39(5):271-281.
[13]Gabillon A,Fansi M.A persistent Labeling scheme for XML and tree database[C]//Signal-Image Technology and Internet-Based Systems,2005,1:110-115.
[14]Dan Sucin. XML data repository[EB/OL]. (2001-11-09)[2014-01-20]. http://www. cs. washington. edu/research/xmldatasets/www/repository.html.
猜你喜欢
现代临床医学(2022年5期)2022-09-28
客联(2022年3期)2022-05-31
现代临床医学(2022年1期)2022-02-12
中国新闻周刊(2021年26期)2021-07-27
文化创新比较研究(2020年13期)2020-01-01
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
中国医药科学(2013年16期)2013-12-20
质量与标准化(2010年5期)2010-05-03
