
智能电网中基于数据挖掘技术的可再生能源消费预测建模
2015-01-14 07:29侯晨伟谢云芳
科技视界 2015年11期
侯晨伟 谢云芳 温 鹏
(河北农业大学机电工程学院,河北 保定071001)
1 数据挖掘理论
数据挖掘就是从海量的数据中提取隐含在其中,人们事先未知的但又是潜在有用的信息和知识,并将其表示成最终能被人理解的模式的高级过程[1-2]。数据挖掘技术从一开始就是面向应用的,不仅是面向特定数据库的简单检索查询调用,还要对这些数据进行微观、中观乃至宏观的统计、分析、综合和推理,来指导实际问题的求解。同时还可以通过发现事件间的相互关联,对未来的活动进行预测。比如通过对空间负荷的预测,可以了解待研究地区未来的电力负荷增长走向,及其连带一系列的社会问题如城市电网规划、各类建筑用地及居民安置规划等[3]。数据挖掘的数据包括数据仓库、数据库或其它数据源。所有的数据都需要再次进行选择。
1.1 数据挖掘的分类
(1)根据挖掘的数据库类型分类:每一类数据库系统可能需要自己的数据挖掘技术。
(2)根据挖掘的知识类型分类:即根据数据挖掘的功能分类,如特征化、区分、关联和相关分析、分类、预测、聚类、离群点分析和演变分析。一个综合的数据挖掘系统通常提供多种 和/或集成的数据挖掘功能。
(3)根据所用的技术类型分类:这些技术可以根据用户交互程度,或所用的数据分析方法描述。
(4)根据应用分类:不同的应用通常需要集成对于该应用特别有效的方法[1]。
1.2 数据挖掘的步骤
(1)数据收集。从数据库中获取基本分析所需的数据。指标数量越多,归纳研究越易发现存在的潜在规律。但若过多,符合条件的样本就会减少,从而影响预测效果。
(2)数据预处理。包括消除噪声、推导计算缺值数据、消除重复记录等。可通过专用软件的频率分析来实现。如果同一个变量的缺失值很多,可以丢掉这个变量。
(3)数据转换。主要目的是削减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据挖掘时要考虑的特征或变量个数。主要有零维特征法和全维特征法。
(4)数据挖掘。先确定挖掘的任务或目的,如数据分类、聚类、关联规则发现或序列模式发现等。再决定使用什么样的挖掘算法。算法的选择有两个考虑因素:一是数据的特点;二是要根据用户或实际运行系统的要求。最后实施数据挖掘操作,获取有用的模式。
(5)结果的解释和评估。目的是剔除冗余或无关的模式;根据需要转换成可视模式;若不满足用户要求,则退回到发现过程的前面阶段重来。
2 智能电网数据的特点
(1)实时性高。电力系统每时每刻都在产生大量的数据,包括反映一次运行状态的各种数据。
(2)数据量大。除实时数据外,各种在线离线分析计算程序也会产生大量的数据。
(3)数据格式多样。数据可能存储于各种关系型数据库、文本文件和二进制文件中,这些数据源往往彼此独立,难以实现数据共享,导致大量数据冗余和不一致。
(4)历史数据极具价值。电力系统是个连续系统,它在某时刻的运行状态将会影响随后的状态或者趋势。对历史数据的妥善保存和深入分析势在必行。
3 可再生能源消费预测建模
智能电网的一个重要组成部分就是各种可再生能源。风力发电、太阳能光伏发电、生物质发电、潮汐能发电、地热能发电等等,且各类可再生能源的发电成本、电能质量及在电网中占的比重都不同。为了深入研究可再生能源的使用情况,对2001~2010年连续十年内某地区电力用户消费的可再生能源类型进行统计,对各种可再生能源类型进行编码:A=太阳能,B=风能,C=其他清洁能源。将电力用户从原始数据库中抽取出来,并编上号(1-N)。按年份进行升序排列,组成表1。
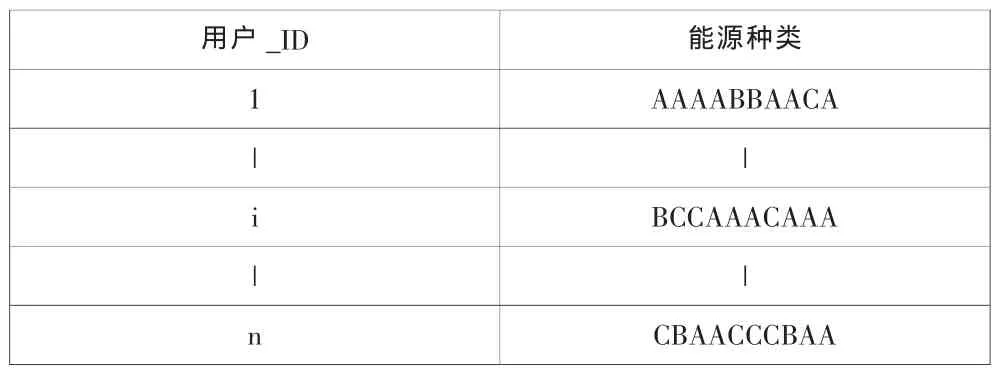
表1 特征信息库
由相对年份来标识交易,用户号来标识用户属性,则R[X][Y]唯一标识了X号用户在Y+2009年主要使用的可再生能源类型。这里提出的N阶转移矩阵的数学基础是马尔科夫链。算法的前提是:交易是历史相关的,其考虑程度由N决定,N阶矩阵意味着考虑前N年的交易历史。对于具有相同的前N年历史记录的用户群G1和具有相同前N-1年和今年的历史记录的用户群G2,若G1的前N年历史记录与G2的前N-1年和今年的历史记录相匹配,则G1在今年对能源类型的选择分布成为G2在明年对能源类型的选择的概率分布。
定义S(n,STRING)函数为以第n年结尾的R[X]的子串与STRING相匹配的用户数。如S(8,AAA)是指第6、7、8年的消费的主要可再生能源类型为风能的用户总数。为了方便起见,假定采用3阶的转移算法,并假定当前年份为N。生成数据项集I的3阶全排列集合PI{AAA,BAA,CAA,AAB,BAB,CAB,AAC,BAC,…,CCC}。遍历R数据库,对PI的每一项STRING生成S(N,STRING)。也就是,考虑历史记录(考虑的深度取决于阶数),对用户的偏好性按其序列不同而分类。根据已生成的S(N,XYZ)计算得S(N-1,XY)。这也就是将上一年的用户对消费类型的选择作为标准。将S(N,XYZ)/S(N-1,XY)上一年份的序列XY向今年Z的转移率作为今年序列XY向明年Z转移的概率,即Pxy→z=S(N,XYZ)/S(N-1,XY)。从而建立预测模型的转移矩阵P。

P矩阵是9*3的矩阵,其行向量对应于数据项集I,而列向量则对应于发生向量C。发生向量C就是S(N,XYZ)的用户分布。显然,C是个9维的向量。因而,结果向量Z=C*P是3维的对应于数据项集I的向量。这正是预测模型的预测结果。
扩展至n阶的转移模型只需将PI扩充成数据项集I的n阶全排列集合。转移矩阵P相应地扩展成3^(n-1)*3的矩阵。其中的转移概率为:)。同样,C 也 扩展成3^(n-1)的向量。
4 结论与展望
对于在智能电网庞杂的数据体系里开展信息分析处理工作而言,数据挖掘技术是一种行之有效的技术。它可以辅助决策者发现数据里面潜藏着的不易发现的知识和信息,也可以基于现有数据对未来进行预测。它值得电力和信息领域的研究者们携手进行更深层次的研究。必须指出的是,构建智能电网时有必要站在更高的高度考虑问题,从信息系统的全局来看待数据挖掘与其他构件的相互关系。因为智能电网不同的参与者对信息系统有不同的需求,各个构件都有擅长的范围。同时还应当看到,数据挖掘并不是万能的。它是一个循环往复的过程,需要分析人员理解现有业务系统,进行细致的准备,建立模型并分析结论和预期的差别。分析人员还需要灵活设计并进行数据分析和挖掘的过程,以避免灵感的丢失。
[1]Jiawei Han,Micheline Kamber.Data Mining Concepts and Techniques[M].Morgan Kaufmann publishers,2000.
[2]W.H.Inmon,Claudia Imhoff,Ryan Sousa.Corporate Information Factory[M].Second Edition Wiley Computer Publishing,2002.
[3]Xiong Hao,Li Weiguo,Huang Yanghao,etc.Application of Comprehensive Data Mining Method Based on Fuzzy Rough Set in Spatial Load Forecasting[J].Power System Technology(in Chinese),2007,7(4):36-40,56.
[4]牛东晓,曹树华,赵磊,等.电力负荷预测技术及其应用[M].中国电力出版社,1998.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学大王·趣味逻辑(2021年11期)2021-12-03
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电力与能源(2017年6期)2017-05-14
高中生学习·高三版(2016年9期)2016-05-14
河南电力(2016年5期)2016-02-06
信息通信技术(2015年6期)2015-12-26
新高考·高二数学(2015年11期)2015-12-23
河南电力(2015年5期)2015-06-08
河南电力(2015年5期)2015-06-08
