
基于《知网》的词语语义相似度改进算法研究
2015-01-06 08:21:06张沪寅刘道波温春艳
计算机工程 2015年2期
张沪寅,刘道波,温春艳
(武汉大学计算机学院,武汉430072)
基于《知网》的词语语义相似度改进算法研究
张沪寅,刘道波,温春艳
(武汉大学计算机学院,武汉430072)
现有词语相似度计算方法未深入考虑义原之间的距离与义原深度的主次关系,或直接指定含具体词概念的相似度,导致计算结果不够精确。针对该问题,通过义原之间的距离限制义原深度对义原相似度的影响,分析统计《知网》中概念的义项表达式,使用第一基本义原(能反映具体词本质)替换概念义项表达式中出现的具体词,从而提出一种改进的词语语义相似度计算算法。实验结果表明,该算法能有效提高词汇相似度计算的精确度。
词语相似度;词语语义;义原深度;概念
1 概述
词语语义相似度计算在文本分类、问答系统、基于实例的机器翻译、文本主题抽取等自然语言处理领域有着非常广泛的应用。词语语义相似度计算方法通常可以分为2种[1]:第1种是利用大规模语料库来统计词语的相关性基于统计的方法;第2种主要是依赖于比较完备的基于某种世界知识和分类体系的大型语义词典,如Agirre[2]利用WordNet来计算英语词语的语义相似度。
《知网》是著名的采用汉语描述的本体论[3],它是一个揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容并以汉语和英语的词语所代表的概念为描述对象的常识知识库[1]。基于《知网》的词语语义相似度计算的最终归结于义原相似度计算的层面上。如文献[4]提出的计算词语相似度只考虑义原之间距离的方法;文献[5]在前人的基础上额外考虑了义原深度因素,文献[6]提出同时考虑了深度和区域密度2个因素的方法;文献[7]提出的计算方法考虑了义原间的反义对义关系及文本情感色彩;文献[8]考虑了义原的公共节点个数和深度对相似度的影响;文献[9]通过共有信息和差异信息进行相似度的计算;文献[10]提出的考虑词语词性的计算方法等。
然而,以上计算方法未考虑义原层次深度,或未深入考虑义原之间的距离和义原层次深度的主次关系。为此,通过限制义原层次深度对相似度的影响,本文提出一种基于《知网》的词语语义相似度改进算法。
2 相似度计算
2.1 基本定义
定义1词语相似度[4]。词语W1,W2的相似度是指2个词在不同的上下文中且不改变文本的句法、语义结构前提下,词语可替换使用的程度,用Sim(W1,W2)表示。
定义2义原距离[6]。义原p1和p2的距离是指在同一棵义原层次体系树上p1到p2的路径长度,用Dist(p1,p2)表示。若义原p1和p2是不在同一棵义原层次体系树上,则Dist(p1,p2)统一设为20。
定义3义原深度[6]。义原p的深度是指义原层次体系树上的根节点到此义原p节点的路径长度,用dep(p)表示。
2.2 义原相似度计算
义原的相似度由义原所处义原树形结构的位置关系描述。以“实体”为根节点的树分支如图1所示。
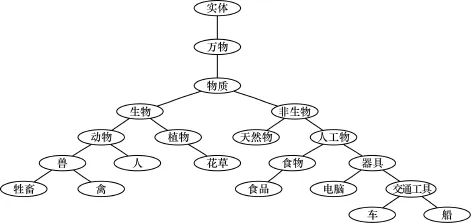
图1 以“实体”为根节点的树分支
本文选取了一个以“实体”为根节点的义原层次体系树的分支,并根据图1,对2种常见的义原相似度计算方法进行比较讨论:
(1)文献[4]通过计算两义原节点之间的路径长度计算2个义原的相似度,公式为:

其中,p1和p2表示义原;Dist(p1,p2)为它们在义原层次体系中的距离,即义原距离,当p1和p2处于不同的棵时取一个较大常数20[1];∂为可调整参数,表示当义原相似度等于0.5时的路径长度。
(2)文献[5]在文献[4]的基础上考虑了义原的深度,公式为:
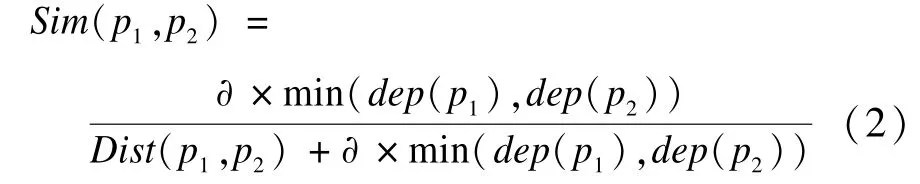
其中,dep(p1),dep(p2)分别为p1和p2的义原深度; min(dep(p1),dep(p2))表示p1和p2义原深度的最小值。
从图1中挑选义原对来讨论式(1)、式(2)各自的特点,式(1)、式(2)计算义原相似度的实验结果如表1所示。

表1 义原对相似度计算结果比较
对比表1中的A组和B组:A组中义原深度都为3,B组中都为6,B组的相似度显然要大于A组。式(1)中A组和B组并没有区分度,其原因是式(1)中只要义原之间的距离相等,那么最终结果就会相同,而式(2)在式(1)的基础上考虑了义原层次深度,能够区别义原之间距离相等而义原层次深度不同的情况。
其次对比表1中的C组和D组:式(1)中C组的相似度较大,式(2)中D组的相似度较大,出现了相互矛盾的结果。从直观感觉来看,C组中的相似度要比D组中的大,此时反而是式(1)比式(2)的结果要好。出现这种情况是因为义原层次深度对相似度的影响超越了义原距离对相似度的影响,即义原层次深度对计算相似度的影响偏大造成的。
通过上面的实验发现,如果义原层次深度比较大,将导致整体的相似度较大的不合理现象。基于此,对参照式(2)对其进行了修改,分子、分母的min(dep(p1),dep(p2))都除以Dist(p1,p2)/2,期望义原层次深度对相似度的影响会受到义原距离的制约,得到如下公式:

其中,λ为可调节参数。
式(3)意义在于:突出了义原距离对义原相似度计算的作用,也就是说,如果义原距离比较大(如不在同一义原树时为20),即义原相似度比较低,那么义原层次深度对相似度的对于整体相似度所起到的作用也降低。式(3)既考虑了义原层次深度又对其“影响力”给予适度的制约,因此,可获得更加合理真实的结果。
为比较式(2)与式(3)的相同点与不同点,本文利用Maple软件绘制函数图像进行比较(根据在多次尝试取得的经验,将λ取值为2.0较为合适,若λ取值过大,会导致义原相似度也偏大)。设义原之间的距离为x(0≤x≤20);义原对中最小义原层次深度的变量为y(0≤y≤10);义原相似度为z(0≤z≤10),式(2)、式(3)函数图像如图2所示。

图2 式(2)与式(3)的函数图像
通过观察图2的函数图像,可以发现到当义原之间的距离较小(如x≤3)时候,式(2)与式(3)图像较相似,但是当义原距离比较大(如10≤x≤20)的时候,式(2)的图像随着最小义原层次深度(y)的变化仍然变化很大,如当义原之间的距离为20时,最小义原层次深度达到10时,义原相似度却仍有0.444之大,显然这是不够合理的。为了更明确式(2)和式(3)的图像,本文截取了当义原距离为10时,最小义原层次深度x(0≤x≤10)对义原相似度影响的图像,如图3所示。

图3 义原距离为10时深度对相似度的影响
从图3与式(2)可以看出,当min(dep(p1),dep(p2)为0时,按照式(2)计算,义原相似度必然为0,这是不合理的,如此时义原“实体”与义原“实体”的相似度应该为1.000,而非式(2)计算的0。当min(dep(p1),dep(p2)为10时,式(2)计算义原相似度有0.615之大,而式(3)计算义原相似度只有0.253,式(3)的计算结果更加符合人的主观感受。
2.3 概念相似度计算
中文词语相似度中,计算虚词概念的相似度较为简单[11],所以,本文研究仅考虑计算实词概念之间相似度的问题。刘群等提出了一种用一个特征结构描述实词概念,并计算概念之间相似度的方法,此特征结构可以看作是一个“属性:值”对的集合,并且该特征结构含有4个特征[12],即第一基本义原描述式、其他基本义原描述式、关系义原描述、关系符号描述。
又因为次要部分计算的相似度值要受到主要部分计算的相似度值的限制,所以2个概念之间的总相似度记为[4]:

其中,βi(1≤i≤4)是可调整的参数,并有下式:

另外,在知网的知识描述语言中[13],在一些出现义原的位置可能出现一个具体词(概念),并将出现的具体词用圆括号括起来。目前,处理此种情况的都是按照文献[4]的方法处理:具体词与义原之间的相似度统一规定为一个较小的常数(γ);两具体词之间的相似度则规定,若两具体词一致,则相似度为1,否则相似度为0。
上述计算方法能计算出大部分词语相似度,但是通过对《知网》定义的概念的义项表达式的分析,该计算方法存在需要改进的地方。通过对《知网》数据的分析,共有66181个概念的定义,其中在对概念的定义中,有2 333条概念的定义使用了具体词(概念),若按上述2条规则进行处理,将会得到大量粗略计算的相似度。
例如,“日本人”和“美国人”、“日元”和“美金”这2组概念的义项表达式如下:
A:日本人:DEF={human|人,(Japan|日本)}
B:美国人:DEF={human|人,(US|美国)}
C:美元:DEF={money|货币,(US|美国)}
D:日元:DEF={money|货币,(Japan|日本)}
依据上述方法把概念的义项表达式划分后,根据上述的方法使用式(4)计算,A和B相似度与C和D相似度计算结果均为0.500。导致出现这种情况是因为,“日本人”和“美国人”的第一基本义原都是人,并且根据上述规则,具体词(Japan|日本)与具体词(US|美国)不同的相似度为0导致的。然而,实际上根据本文相似度的定义,可以认为具体词(Japan|日本)与具体词(US|美国)的相似度为1.000。概念“日本人”和“美国人”相似度只有0.500,这样的结果显然这与主观感觉是极其不相符合的。
为此,本文对这2 333条概念的定义进行了分析与统计,通过统计分析发现,2 333条概念定义的义项表达式中出现的具体词主要是地名(市、国、洲、等)、人名等专有名词(约占95%),剩下其余少量概念定义的义项表达式出现其它具体词。因此,本文对这些“特殊”的概念进行适当的处理,以使相似度计算更加合理化。因此,把概念相似度计算分为2类:
(1)2个要计算相似度的概念的义项表达式均没有出现有具体词(概念)。
(2)2个要计算相似度的概念中至少有一个概念的义项表达式有出现有具体词(概念)。
专有名词通常表示特定的人、地方、事物等特有的名词,因此,这些专有名词的第一基本义原就能很好地反映这些专有名词的本质特征。如上文的概念“中国”,第一基本义原为place|地方。基于此,对于要比较的2个概念,先进行预处理,判断要计算相似度的概念中是否至少有一个概念的义项表达式有出现有具体词的,若没有出现则为第(1)类,直接使用前文的方法;若至少有一个概念的义项表达式有出现有具体词的,则使用能反映具体词本质特征的第一基本义原代替它自身,经过替代后,转化为第(1)类进行计算。
与不考虑含具体词的词语相似度算法相比,本文提出的算法提高了含具体词概念义项表达式相似度计算的客观性和准确性,得到的结果更加贴近人们的感受。
2.4 词语相似度计算
在《知网》的结构中,一个中文词语可以使用几个不同的概念来定义。2个孤立词语之间的相似度可表现为定义该词语的概念集合之间的相似度[13],用公式表示为:

其中,词语W1,W2分别有n和m个不同概念;S1i为W1的第i个概念;S2j为W2的第j个概念。
3 实验结果与分析
3.1 义原相似度实验
本文实验使用3种不同方法来计算比较义原相似度:
方法1使用文献[4]计算义原相似度的方法。
方法2使用文献[5]计算义原相似度的方法。
方法3使用本文介绍的义原相似度计算方法。
在本文实验中,参照文献[4-5],将参数∂值设置为1.6。实验结果如表2所示。

表2 义原相似度的实验结果
比较组第3行、第4行,与组第5行、第6行与组第5行、第7行、第8行,这3组均是行号越大,义原距离越大,方法1与方法3的计算结果均处于递减。然而,方法2的结果却相反,如第4行计算的相似度比第3行大,第6行计算的相似度比第5行大,第8行计算的相似度比第5行、第7行都要大。从词语的可替换性来说,方法2的结果不够合理的,如第5行的相似度应该要比第8行的要大。经过改进后,方法3计算第5行的相似度为0.483,第8行的相似度为0.332,显然方法3比改进前的方法2得到的结果更合理。
再观察第9行~第11行,其中,第10行、第11行的2个义原不在同一义原层次体系树上,按规定把义原距离设定为20。比较第9行、第10行,方法1与方法3都是第9行的相似度大,然而方法2的计算结果显示,第10行更大,这是不符合实际的。“物质”在义原层次体系树上是“车”的祖先结点,而“车”与“分钟”不在同一义原层次体系树上,由此看来,第10行显然不应该比第9行的相似度大。从这第10行、第11行也可以看出,方法2的计算结果是偏大的,这是由于方法2的计算义原相似度受义原层次深度影响很大(即使两义原几乎不相似了)造成的。而改进后的方法3是更加符合人的主观感受的,这是因为义原层次深度对相似度的影响会受到义原之间的距离的制约。
从整体上看,从上到下,义原之间的距离递增,当义原之间的距离相等时,最小义原层次深度递减,方法1与方法3的计算义原相似度都是递减的,与人的直觉是比较相符合的,但是方法2的义原相似度却出现了多次跳跃,即出现了多次义原距离大的义原相似度反而比义原距离小的相似度更大。显然,方法1只要义原距离相等则义原相似度相等,并不能区分不同义原层次深度的义原相似度;方法2可以区分不同义原层次深度之间的相似度,但是有些相似度的结果也不够合理,比如“实体”和“实体”的相似度,“车”和“雨雪”的相似度。然而方法3计算的相似度比方法1与方法2更加呈现出两端扩散的现象,使计算的结果更加合理细腻。
3.2 义项表达式中含具体词的概念相似度实验
本文实验使用了2种不同方法来计算比较词语(至少有一个词语义项表达式含有具体词)相似度:
方法4使用文献[4]计算词语相似度的方法。
方法5使用本文介绍的词语相似度计算方法。
在实验中,参照文献[4],将参数值设置为:∂= 1.6,β1=0.5,β2=0.2,β3=0.17,β4=0.13,γ=0.2,δ=0.2。实验结果如表3所示。

表3 义项表达式中含具体词的概念相似度实验结果
根据本文词语相似度的定义,从表3可以看出,方法4的计算结果偏小,这主要是因为方法4按规则若要比较的2个具体词不相同,则相似度为0导致的。而方法5中计算的词语相似度则较为合理,因为方法5中使用具体词的第一基本义原替换具体词,而具体词的第一基本义原在大多数情况下都能反映出此具体词的本质。
现实生活中存在大量类似表3中类型的词语,如“亚洲人”、“英国人”、“广东人”、“北京人”、“日军”等。由此可见,本文方法可大量改善计算此类词语之间的相似度。
3.3 词语相似度实验
本文实验为了使计算相似度的词语具有参照性并且易于比较改进前后的词语相似度的好坏,引入文献[4]常用的词语并额外加入典型词语,使用3种不同方法来计算比较词语相似度。
方法6结合文献[4]使用的义原相似度计算方法计算词语相似度。
方法7结合文献[5]使用的义原相似度计算方法计算词语相似度。
方法8结合本文中介绍的义原相似度与概念相似度计算方法计算词语相似度。
在实验中,参照文献[4-5],将参数值设置为:∂=1.6,β1=0.5,β2=0.2,β3=0.17,β4=0.13,γ= 0.2,δ=0.2λ=2.0。实验结果如表4所示。
考察方法8的计算结果,可以看到各个词的相似度与人的直觉是比较相符合的。下面将进行详细分析:
(1)比较第1组与第4组,方法6的结果没有区分,而方法7与方法8均为第1组的相似度较大,这主要是因为“男”与“女”的最小义原层次深度要比“家”与“宗教”的最小义原层次深度大。另外,比较第7组与第10组,方法6同样没有区分度,方法7与方法8中,“男人”和“收音机”的相似度要比“男人”和“工作”的相似度更高。从可替换性来说,这是符合相似度的定义的,至少“男人”和“收音机”都是物质,而“工作”只可能是一个行为或者一个抽象事物。显然方法7与方法8表现比方法6好。
(2)再来观察第12组与第13组,“车辆”与“暴雨”分别是人工物与自然物、“车辆”与“蚕”分别无生物与生物,都不属于同一类型的,他们的相似度应该比较小,方法7的计算结果却达到了0.373,方法6与方法8的计算的相似度则比较符合主观感受。再比较第13组与第14组,“冷食”与“垃圾”分别是食物与物质,他们的相似度应该要比“车辆”与“蚕”更大,此时,方法6与方法8的结果比方法7的相对更加合理一些。
(3)再考察第15组~第20组,方法6与方法7的计算结果基本上没有区别,而方法8由于考虑了概念的义项表达式出现具体词的情况,所以方法8的计算的相似度更加符合实际。从表4中的第15组~第20组可以看出,在大部分情况下,考虑了义项表达式出现具体词的情况都要比不考虑的计算结果要大一些,这是因为方法6与方法7,只要要比较的2个具体词不相等,那么其相似度就为0。然而,实际上绝大部分出现在概念的义项表达式的具体词都是专有名词,用于表示人名、地名等,即使要比较的2个具体词不相同,但是实际的相似度往往也比较大,而不是0。

表4 词语相似度实验结果
4 结束语
本文通过深入考察义原层次体系树的结构,分析义原深度对相似度的影响,提出一种计算义原相似度的改进算法。义原在层次体系结构树上的深度越大,表示此义原含信息量越高,也应越相似,但是义原层次深度对相似度的影响应受义原距离的制约,而不能无限地放大义原之间的相似度。此外,分析统计了《知网》中概念的义项表达式,认为在义项表达式中出现的具体词绝大多数是表示人名、地名等专有名词,将其用反映此具体词本质的第一基本义原代替,从而转换为一般的概念相似度计算问题。实验结果表明,该算法计算得到的词语语义相似度能够更合理地反映词语间在语义上的细微差异,提高词语相似度计算的准确性。今后将深入研究义原在层次体系树上的区域密度对义原相似度的影响,进一步优化该算法。
[1] 朱征宇,孙俊华.改进的基于《知网》的词汇语义相似度计算[J].计算机应用,2013,33(8):2276-2279.
[2] Agirre E,RigauG.AProposalforWordSense DisambiguationUsingConceptualDistance[C]// Proceedings of the1st International Conference on Recent Advanced in NLP.Tzigov Chark,Bulgaria: [s.n.],1995:91-98.
[3] 赵 鹏,蔡庆生.一种基于《知网》的中文文本聚类算法的研究[J].计算机工程与应用,2007,43(12): 162-163.
[4] 刘 群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[5] 李 峰,李 芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[6] 袁晓峰.《知网》义原相似度计算的研究[J].辽宁大学学报:自然科学版,2011,38(4):358-361.
[7] 江 敏,肖诗斌,王弘蔚,等.一种改进的基于知网的词语语义相似度计算[J].中文信息学报,2008, 22(5):84-89.
[8] 张振幸,李金厚.一种基于义原重合度的词语相似度计算[J].信阳师范学院学报:自然科学版,2010, 23(2):296-299.
[9] 刘青磊,顾晓峰.基于《知网》的词语相似度算法研究[J].中文信息学报,2010,24(6):31-36.
[10] 王小林,王 义.改进的基于知网的词语相似度算法[J].计算机应用,2011,31(11):3075-3077.
[11] 黄姝怡.基于知网的中文文本相似度计算研究[D].广州:中山大学,2008.
[12] 张 敏,王振辉,王艳丽.一种基于《知网》知识描述语言结构的词语相似度计算方法[J].计算机应用与软件,2013,30(7):265-267.
[13] 王文兴.基于语义分析的查询扩展及其关键技术研究[D].哈尔滨:哈尔滨工程大学,2008.
编辑 刘 冰
Research on Improved Algorithm of Word Semantic Similarity Based on HowNet
ZHANG Huyin,LIU Daobo,WEN Chunyan
(School of Computer,Wuhan University,Wuhan 430072,China)
The current word similarity calculation does not consider in depth with the primary and secondary relationship between the distance and the depth of sememes.In addition,concept similarity is specified directly when the conceptual description expression contains specific words,which leads to unreasonable.The depth of sememes impacts on the word similarity is limited by the distance of sememes.It analyzes the statistical meanings of the concept expression in“HowNet”.Besides,word similarity calculation uses the first basic sememe that can reflect the essence of the word to replace the specific words that appear in the conceptual description expression.Based on the above,an improved algorithm of word semantic similarity is proposed in this paper.Experimental results show that the improved algorithm effectively improves the precision of word similarity calculations.
word similarity;word semantic;depth of sememe;concept
张沪寅,刘道波,温春艳.基于《知网》的词语语义相似度改进算法研究[J].计算机工程, 2015,41(2):151-156.
英文引用格式:Zhang Huyin,Liu Daobo,Wen Chunyan.Research on Improved Algorithm of Word Semantic Similarity Based on HowNet[J].Computer Engineering,2015,41(2):151-156.
1000-3428(2015)02-0151-06
:A
:TP391
10.3969/j.issn.1000-3428.2015.02.029
教育部博士点基金资助项目(20130141110022)。
张沪寅(1962-),男,教授、博士,主研方向:自然语言处理,多媒体通信技术,模式识别;刘道波、温春艳,硕士研究生。
2014-03-31
:2014-04-25E-mail:fengbonianshao@whu.edu.cn
猜你喜欢
纯碱工业(2023年6期)2023-04-21 16:18:44
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
现代计算机(2019年6期)2019-04-08 00:46:50
高中生·天天向上(2017年10期)2018-01-18 21:51:58
现代交际(2017年13期)2017-07-18 09:53:01
北方文学·下旬(2017年3期)2017-04-20 10:39:32
科技视界(2016年5期)2016-02-22 11:41:39
知识窗(2015年1期)2015-05-14 09:08:17
Beijing Review(2012年37期)2012-10-16 02:24:10
