
跨平台解释器的研究与设计
2015-01-04 08:51万东
电子设计工程 2015年12期
万东
(广东交通职业技术学院 广东 广州 510650)
嵌入式浏览器是嵌入式设备终端用户浏览网页信息内容的应用软件,其重要性日益提高,已经不可或缺[1]。著名的开源浏览器Firefox在PC上具有强大的功能,但是还没有成功的嵌入式应用。Minimo浏览器的跨平台性以及高效管理浏览器的缓存资源,但是不支持中文。Linux的版本只支持Window mobile,IE也只支持Window mobile。嵌入式浏览器是嵌入式设备终端用户浏览网页信息内容的应用软件,其重要性日益提高,已经不可或缺。目前携带方便的智能型终端大量出现,使嵌入式浏览器成为社会研究的热点之一。本文提出了一种跨平台ECMAScript解释器的研究与设计方案。剖析了几大核心模块的设计和实现进行了。
1 ECMAScrip介绍及解释器总体设计
ECMAScript是一种由欧洲计算机制造商协会通过ECMA-262标准化的脚本程序设计语言,是宿主环境中脚本语言的国际Web标准。ECMAScript实际上只是定义了一系列的语法和语义的规则,其具体的脚本语言主要包括JavaScript,JScrip,ActionScript等。 ECMAScript主要使用于网络环境中,嵌入HTML文档,提供Web与用户交互功能,展示Web内容的多样性。ECMAScript解释器与其他的语言编译功能类似,都是从源代码输入,经过一系列的解读与加工,最终产生能在相应平台运行的目标代码。其工作原理图1所示。

图1 ECMAScript工作原理图Fig.1 ECMAScript operating principle
图1 中,ECMAScript解释器按其模块可以划分为词法分析模块、符号表模块、语法分析模块、语义分析模块以及代码生成模块。ECMAScript解释器读入源代码后,依次调用词法分析,语法分析,生成中间代码嵌入代码段中,以供虚拟机解释执行。词法分析和语法分析都是ECMAScript中的文法,而中间代码则使用自定义的字节码,以便于不同平台的虚拟机都能解释执行,达到跨平台的目的[2]。
传统编译器的可以多遍实现,即每遍输入一个文件、生成一个结果文件,也可以一遍实现,即将多个阶段组合起来[3]。多遍读入,可以节省内存开销,但是多次的输入输出也会影响编译的效率;一遍实现效率高,但是需要将阶段性的信息保留于内存中,对系统内存要求高。目前随着智能设备硬件的升级,内存不再是制约智能设备使用的主要方向,所以在本文的ECMAScript编译器设计中采用一遍实现的技术。
2 ECMAScript解释器的具体设计
2.1 符号表设计
符号表是ECMAScript解释器必不可少的部分,用于存放标识符各种信息,以便于程序对所用资源的快速定位与识别。符号表中必须提供到处理该标识声明时所收集信息的访问[4],具体包括:类型,作用域,存储地址以及函数标识符的参数个数,参数类型以及返回值等信息。符号表设计的关键,是设计合适的查找算法。
符号表的实现方法有很多种,包括无序表,有序表,hash表,二叉树等方法。在无序表的设计中,符号表只是一个简单的数组或者链表,所有的标识符都是按照先后顺序依次放入数组或链表中,平均时间复杂度为O(n/2)。有序表则是将标识符保持有序,以便于使用二分查找是能达到 O(log(n))的效率,但是需要对有序表进行频繁的插入和删除操作,而且在数据较大的情况下,插入和删除新的标识符,也需要O(n)的时间。二叉树符号表的设计中,使用近似平衡二叉树的数据结构,能使插入和搜索标识符的时间为 O(log(n))。Hash表则是更多产品级编译器所青睐的实现方式[5],通过构造合适大小的hash桶以及良好的Hash函数,最理想情况下能达到O(1)的效率,但是实际上很难达到这种效率。
使用Hash表的设计方式,无可避免需要解决Hash冲突问题。在本文的设计中,使用Hash和二叉树结合的方式来设计符号表。其中二叉树使用红黑树来实现,Hash表中用于保存红黑树的树根,红黑树的节点,用来保存具体的标识符信息。查找标识符信息时,首先将该标识符进行Hash,找到存储该标识符的红黑树的树根,再在红黑树中查找相应的标识符,这样能实现的复杂度为 O(1)+O(log(n/Size))(Size 为Hash桶的大小)。
在符号表的设计中,另外需要考虑的一个因素就是标识符的作用域。不同的作用域中可能会出现相同的标识符[4],因此一种可行的解决方案是,使用多级分层的多符号表方式,为每个函数动态分配单独的符号表,查找一个标识符时,首先在同级的表中查找,查找失败后再往上逐层查找,直到最顶层。
2.2 词法分析器设计
词法分析器的功能输入源程序,按照构词规则分解成一系列单词符号。单词是语言中具有独立意义的最小单位,包括关键字、标识符、运算符、界符和常量等。就多数的程序设计语言来说,词法的结构设计比较简单,但是真正实现词法的自动识别却比较困难,而且需要依赖于词法的严格定义[6]。ECMAScript语言中,对词法记号有着严格的定义。在ECMAScript的词法分析器中,其主要功能就是过滤掉源程序中与程序语言不相关的字符后,将输入字符转化成单词序列。目前现有的词法分析器Lex是一个比较完善的工具,它是基于正则表达式的描述词法分析器的工具,可以根据用户设定的正则表达式去分析,切割出单词,但是其支持的宿主语言只是C。分析Lex的具体实现,也是使用确定的有限状态自动机(DFA)实现词法的分析。
DFA,即于一个给定的属于该自动机的状态和一个属于该自动机字母表集合的字符,它都能根据事先给定的转移函数转移到下一个状态(这个状态可以是先前那个状态),它可以根据输入和约束规则,改变自身的状态[4]。DFA主要由输入集合、开始状态集合、状态转移集合、状态集合和结束状态集合组成。
在DFA中,需要构造状态转换表,DFA按照转换表进行状态转换。其实现的伪代码表示为:
{
当前状态为0;
扫描下一个字符char;
While(ture)
{
当前状态=状态(char);
If当前状态=0{return识别一个单词成功;break}
If当前状态=Error{return错误单词;break}
Else
{
变为当前状态;
缓存当前字符;
扫描下一个字符char;
}
}
}
2.3 语法分析器设计
语法分析器的任务主要是检查词法分析得到的token流是否符合ECMA的语法,语法分析器可以采用Yacc语法分析工具。Yacc文件的分段实际上与Lex文件十分相似:
说明部分
%%
规则部分
%%
辅助程序部分
<说明部分>包括记号的定义、类型信息以及Lex中声明的yylval共用体。Yacc使用同一共同体在两个不同的“语言概念”之间传递信息,例如表达式、语句、程序。根据这些定义,Yacc产生lexsymb.h解析文件。Yacc有一个需要注意的地方,就是使用的语言必须使用LR(1)文法描述,LR(1)文法的基本思想是语法分析器能在查看当前语法记号或者最多预读一个符号就能识别出使用什么样的语法规则,而下面的语法规则会产生一个移进/规约冲突(shift/reduce conflict):
A:
|B C
|B CD
|DE F
冲突产生在当语法分析器读取到了’C’时,而且预读的是’D’时,它不能决定是否归类为A2还是A1后面跟着一个A3,Yacc把这种二义性称为移进/规约冲突。可以使用下列相应规则解决这类冲突:
statement
:END_STMT{puts(“Empty statement”);}
|expression END_STMT{puts(“Expression statement”);}
|PRINT expression END_STMT{puts(“Print statement”);}
|INPUT identifier END_STMT{puts(“Input statement”);}
|if_statement{puts(“If statement”);}
|compound_statement{puts(“Compound statement”);}
|error END_STMT{puts(“Error statement”);}
这里定义了各种语句类型,后面的代码告诉语法分析器当发现了每个产生式时应该做什么,”Error statement”告诉Yacc当分析一条语句时如果遇到一个语法错误,应查找下一个END_STMT记号,然后继续分析后面的东西,并把语法错误报告到main.cpp中定义的yyerror()函数中。
构造出符合LR (1)文法的ECMAScript脚本语言的ES文法后,就可根据此文法建立语法预测分析表,预测分析表中得到的产生式的右部逆序进入语法栈,当语法栈的所有条目都出栈时,说明语法没有错误。
3 解释器功能验证
ECMAScript解释器是一个相对复杂的系统,通过前面核心模块的设计和实现,解释器的主要功能已经基本实现。为了调试的方便以及印证ECMAScript解释器功能的实现,本文借助一个调试助手工具,调用ECMAScript解释器所提供的词法分析器接口、语法分析器接口和语义例程,界面如图2所示。
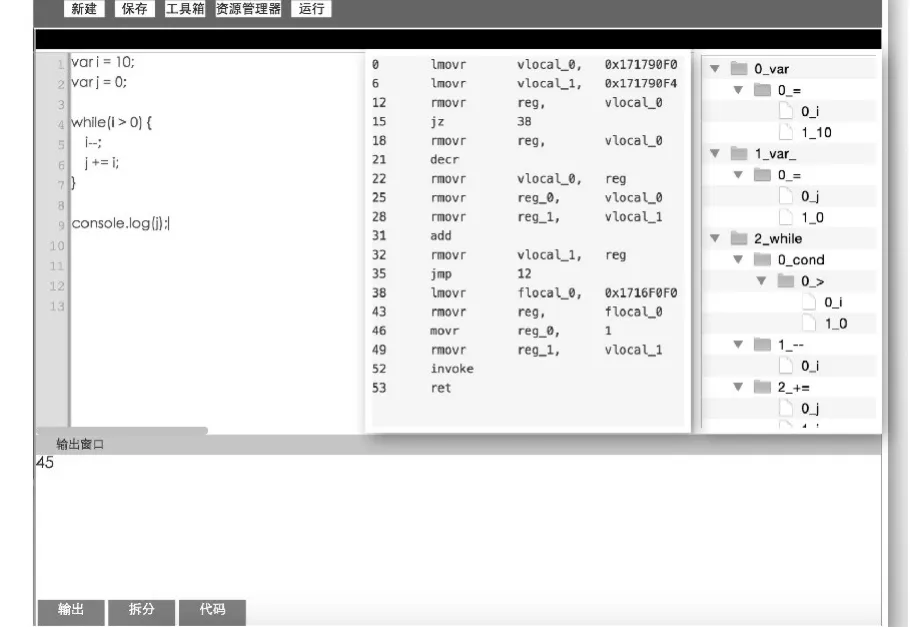
图2 词法分析及中间代码执行结果显示Fig.2 Lexical analysis and intermediate code execution results show
图2 中左边是源码,中间是语法分析后产生的中间代码,右边是词法树,下边是执行结果。中间窗口4列分别表示:偏移量 操作符 第一参数 第二参数。从前面的分析可知,通过词法分析可把输入的源程序生成相应的词法树,通过对图中左边部分所示的一个简单的脚本语言解释过程为例,其右边为源程序词法分析过程中所得到的词法树。
图2中中间部分显示了源程序生成的中间代码,通过lmovr指令分别把两个源地址的值赋予vlocal_0,vlocal_1两个本地变量寄存器,由jz指令根据条件进行跳转,如果i为0,跳出循环,输出j的值,如果i>0,则执行循环体。中间代码的执行是由虚拟机完成的,通过输出窗口,可以看到脚本语言经过ECMAScrip解释器能够得到正确执行。
4 结 论
人熟悉的Netscape Navigator浏览器和Intemet ExpIore浏览器和都能很好的支持脚本语言,嵌入式平台浏览器支持Web网页浏览的技术难点是如何解决对脚本语言的解释,本文正提出了一种跨平台ECMAScript解释器的研究与设计方案,并对其中的几大核心模块的设计和实现进行了剖析,最后对ECMAScript解释器对脚本语言的解释过程进行了演示,实现了不同平台智能终端上浏览器对ECMAScript的支持。
[1]左瑞金.嵌入式浏览器的资源管理与跨平台的研究与优化[D].电子科技大学,2012.
[2]Alfred v.Aho,Ravi Sethi,Jeffrey D.Ullman.Compilers Principles Techniques and Tools[M].Addision-Wesley Publishing Company,1996.
[3]徐颖丽,刘志.Agent解释器的设计与实现[J].计算机工程与应用,2005(25):91-95.XU Ying-li,LIU Zhi.Design and implementation of agent interpreter[J].Computer Engineering and Applications,2005(25):91-95.
[4]Charles N.Fischer,Richard j.LeBlacn.编译器构造C语言描述[M].郑启龙,姚震,译.北京:机械工业出版社,2005.
[5]吴作顺,窦文华.几个常用解释器的性能分析[J].计算机工程与科学,2002,24(4):83-85.WU Zuo-shun,DOU Wen-hua.Several commonly used to explain the performance analysis[J].Computer Engineering and Science,2002,24(4):83-85.
[6]温敬和.LR分析法在词法分析器自动构造中的应用[J].计算机工程,2001,27(7):188-190.WEN Jing-he.LR analysis in lexical analyzer automatically configured application[J].Computer Engineering,2001,27(7):188-190.
猜你喜欢
计算机应用(2022年8期)2022-08-24
计算机系统应用(2020年8期)2020-03-22
阅读(科学探秘)(2019年6期)2019-10-17
分析化学(2018年12期)2018-01-22
科技经济市场(2017年5期)2017-09-16
海外华文教育(2016年3期)2017-01-20
图书馆建设(2015年11期)2015-08-24
图书馆(2014年3期)2014-12-25
现代情报(2014年4期)2014-08-08
中学生英语高效课堂探究(2011年4期)2011-07-07
