
自动问答系统中问句分类研究综述
2015-01-03 07:05:24镇丽华王小林杨思春
安徽工业大学学报(自然科学版) 2015年1期
镇丽华,王小林,杨思春
(1.南通大学管理学院,江苏南通226019;2.安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
自动问答系统中问句分类研究综述
镇丽华1,王小林2,杨思春2
(1.南通大学管理学院,江苏南通226019;2.安徽工业大学计算机科学与技术学院,安徽马鞍山243032)
问句分类作为问答系统所要处理的第一步,在问答系统中起着至关重要的作用,其准确性直接影响最终抽取的答案的正确性。从问句分类的概念出发,先对问句分类体系、特征提取、问句分类方法等进行阐述,然后重点分析了用于问句分类的几个主流学习模型,并对几个模型作了比较分析,最后指出了当前问句分类的研究难点和未来的研究方向。
问答系统;问句分类;特征提取;分类模型
问答系统是目前自然语言处理和信息检索领域的一个研究热点,它允许用户以自然语言形式提出问题,并采用自然语言处理技术自动地将简洁、正确的回答返回给用户[1-2]。与传统的搜索引擎相比,问答系统能更好地满足用户从互联网上快速、准确地获取信息的需求。
1 问句分类及作用
问答系统一般包括问句分析、信息检索和答案抽取3个主要部分[3-4],典型问答系统的体系结构如图1所示。其中,问句分类作为问答系统的首要环节,为系统知道用户想要寻找什么类型的答案提供重要信息。
小鸡在地板上跑着,特写周泽赡带笑的脸。旁边放着一个装鸡的小纸箱子,墙上的温度计显示三十摄氏度。客厅的电视播放着电视剧。周泽赡将泡好的米放在塑料瓶盖里,喂给小鸡吃。小鸡跑到周泽赡的拖鞋上,屁股一撅,把屎拉在了地板上。周泽赡仍是笑着,拿卫生纸把屎擦了,再到卫生间里按照步骤洗手。这时镜头快剪小鸡拉屎、周泽赡洗手的画面,重复多次后,在最后一次时周泽赡没有立即去洗手,而是等到小鸡再拉一次时再洗,小鸡已经长成有羽毛的样子了,同电视剧的集数变化也可显现时间的流逝。
问句分类是指在确定的分类体系下,根据问句的内容自动地确定问句关联的类别[5],这种对应关系可以用一种映射函数来表示:
其中:X表示问句实例集合;{C1,C2,…,Cn}表示问句类别集合;G负责将未知类别的问句x∈X根据先验信息或者某种规则映射到类别集合中的某个类别Ci中去。
问句分类的作用主要体现在以下2个方面:
当商家不提供运费险时消费者需进行购买运费险的决策,根据图1可知此时的决策需要考虑以下四种情况下的总损失,即为消费者购买运费险决策时的“期望损失”。
(1)问句分类能够有效地减少候选答案空间,提高系统返回答案的准确率。例如,用户输入查询语句“国际奥委会是什么时候成立的?”经过问句分类,知道这个问句属于时间类,在答案抽取阶段,系统把不含时间的候选句子过滤掉,从而有效地较少了候选答案空间。
You cannot know the truth from ingredient list 8 48
其次,学校应制定一套完整的、与教师职业道德规范相配套的、可行性较强的师德考核制度,并将其作为评优评先、职称晋升的重要依据。将模范教师树立为榜样,大力宣传其优秀事迹,进行正面引导;严肃处理违反职业道德规范而又屡教不改的教师,防微杜渐,力求在榜样的引领、制度的约束及舆论的压力之下,使其受到深刻教育。
问句分类作为问答系统一个重要的子模块,能够对问答系统的后续流程查找候选答案和答案抽取有很好的指导作用,一个好的问句分类模块能够在很大程度上提高问答系统的性能。
2 问句分类体系
要对问句进行分类,首先就要知道问句有哪些类型,而问句的类型是由采用的分类体系决定的。当前问句分类体系还没有统一标准,大多数研究人员根据分类依据的不同将分类体系划分为3种:基于答案类型的问句分类体系[9]、基于问句语义信息的问句分类体系[10]和基于混合信息的问句分类体系[11]。现有的问答系统大多采用的是基于答案类型的分类体系,这种分类体系具有易建立、分类粒度细、覆盖面广等优点,特别是具有层次结构的分类体系,能够提供更高的分类精度和更多的约束条件。
在国际上比较权威的是UIUC的问句分类体系[8],它是个基于答案类型的层次分类体系,把问句分为6个大类(ABBR,DESC,ENTY,HUM,LOC,NUM),50个小类,每个大类包含着不重复的小类。表1给出了广泛应用于英文问句分类的UIUC问句分类体系。
很快选好一款跑步鞋,售货员小伙子说,如果扫码加品牌微信号,鞋子即可五折,如果不扫,则是七折。扫个码便宜两成,我想这划得来。扫完码之后,手机屏幕出现注册画面,要求填写姓名、性别、年龄、手机号;因为扫了码,手机号码已经自动出现在注册栏里。这一下引起了我的警觉。姓名、年龄、性别、手机号已是我的基本身份信息,依据这些信息甚至可以在网上对我进行定位跟踪。
对于问句分类的研究很多是借鉴文本分类的思想,两者都是通过分析文本中包含的信息来确定文本所属类别。但是问句不同于文本,问句一般都比较短,包含的词汇信息较少,没有足够的上下文环境,因此需要对问句要进行更深层次的分析,使问句获取更优的特征信息,从而提高问句的分类精度。

表1 UIUC问句分类体系Tab.1 Question classification system of UIUC

表2 中文问句分类体系Tab.2 Chinese question classification system
中文问句分类体系在小类划分上更细致,较细的分类体系能够使得抽取的答案更精确。然而,较细的分类体系势必会影响问句分类的准确率。这需要在今后的研究工作中对问句分类的标准做进一步研究,最后能得到折衷的分类体系。
3 问句特征提取
其中q为问句类别变量,Q1,Q2,…,Qn为对问句进行分词、去除停用词后的特征项,由于分母不变,所以只需处理分子。根据词袋模型,可以将问句简化为
上述词袋、词块和词性特征都是问句的表层特征,虽然提取简单,但仅提取这些特征很难提高问句的分类精度。一般来说,词意决定了整个问句的语义[16-17]基础。Li等[9]提出了用语义词典(WordNet)来分类,把WordNet的上位词和下位词作为一部分特征进行分类,大类(6大类)和小类(50小类)的分类精度最高达到92.5%和85.00%。孙景广等[18]提出使用知网作为语义资源选取分类特征,选取问句疑问词、疑问意向词、疑问意向词在知网的首项义原等作为分类特征,使得分类精度显著提高。命名实体(NE)也被作为重要的语义特征用于问句分类,命名实体是指句子中有确切含义的名词短语,每个命名实体都表现了很强的语义信息,跟问句类别有着非常紧密的关系[19]。例如问句“谁是第一个进入太空的中国人?”中包含了数字和地名两个命名实体,可以将它们加入到问句特征中。此外,把类别关联词(RELWord)也作为语义特征。对于每一个类别,都会有一些特殊词跟其紧密相连,通过对每个类别的问答对进行统计计算,提取出在每个类别问答对中频繁出现的词,将其作为与该类别相关的语义词。如果问句中出现了词“牛奶”,就将与该词相关的“食物”加入到问句特征中去。
(2)问句分类还能够决定答案选择策略[6-8],根据不同的问句类型调节对不同问题的答案选择策略。如,对于问句“安徽省的简称是什么?”如果能分析出问题是询问简写类别的,抽取文档中简写类的文档作为候选答案,这样定位和检验相应的答案就显得相对容易。
要从整体把握问句的语义信息就要对问句进行句法分析,句法分析是在给定文法下分析自然语言的层次结构[5,12],是自然语言处理的热点问题之一。目前,基于依存文法的句法分析受到广泛关注。依存文法的句法结构的主要元素是语义依存关系,即句子中词对的二元关系,其中一个记为核心词,另一个记为依存词,依存关系反映的是核心词和依存词在句法上的依赖关系[20]。文献[12]使用基于依存句法的句法分析结果,提取问句的主干、疑问词及疑问词附属成分作为分类的特征,大大提高了分类精度。
使用分类器对问句进行分类,就要将特征转化成向量的形式输入到分类器中。由于每一个单独的特征在问句分类中所起的作用不大,所以要提高分类的准确性就要将几种特征组合使用。特征的组合方式主要有两种:直接附加特征方式和基于词袋的特征绑定方式[21-22]。直接附加特征的方式简单直观,即将一个或几个特征作为单独的特征模板直接加到词袋特征后面去,但这样就增加了整个特征空间的维数,而且有的特征本身效果就不明显,附加特征会带来一些噪声,降低分类精度,所以将哪些特征进行附加还要针对特征的特点进行选择。基于词袋的特征绑定是把词性、命名实体、词意和依存关系等作为词汇的属性,将其和词汇绑定在一起作为一个特征,这种组合方式可以更有效地体现词汇本身的含义。
4 问句分类模型
UIUC的分类体系是针对英文分类的。哈工大的文勖等[12]在国外已有分类体系的基础上根据汉语自身特点,定义了表2所示的中文问句分类体系,含7个大类,每个大类根据实际情况又定义了一些小类,共60小类。
江苏省在工程建设中,注重加强资金管理,按照分级管理、分级负责、专款专用的原则严格财务制度,规范财务行为,坚决杜绝资金截留、挤占和挪用情况的发生,为工程建设顺利进行提供资金保障。
其中:fi是一个特征函数,其值为0或1;λi是模型参数,参数λi估计常用方法是Darroch提出的通用迭代缩放法(Generalized Iterative Scaling,GIS)和Della Pietra提出的改进迭代算法(Improved Iterative Scaling,IIS)[35]。
目前,在问句分类中所用的统计模型主要有:贝叶斯模型(Bayes Model)、支持向量机模型(SVM)、K-近邻模型(KNN)、最大熵模型(ME)。
4.1 贝叶斯模型
贝叶斯模型是利用类别的先验概率和特征项的分布对于类别的条件概率来计算文本属于某一类别的后验概率,并将使得后验概率最大的类别作为文本类别。对于问句分类,一般都采用张宇等提出的改进贝叶斯模型[14],假设词与词之间是相互独立的,即词袋模型,数学形式表示为
在对问句分类之前,要对问句进行预处理(分词、去除停用词),将问句表示成特征向量。根据国外的相关实验,词袋特征是最常用的特征之一,即忽略词序、句法及语法,将问句仅看成一个词的集合,这个集合中的词出现都是独立的,不依赖于其他词的出现[13]。这显然与事实不符,所以单纯基于词袋进行问句分类精度并不高,张宇等[14]利用词袋模型并采用TFIDF加权,用改进的贝叶斯进行分类,在65个小类上的平均准确率为72.4%。李鑫[15]提到词块(N-gram)特征,它是假设某个词的出现只与前面n-1个词相关,常用的有二元的Bi-gram和三元的Tri-gram,这与单纯的词袋特征相比多n-1个历史特征,包含了一定量的词序信息。词性作为词的语法特征,在英语句子理解中有很重要的作用,但是汉语中的词性作用却不是那么明显。
其中
一站式家装服务物流配送的模式对于家居建材市场以及家装行业有着很大的意义,每一个企业都需要根据自己的优劣势选择适合自己的物流模式。在家装市场“僧多粥少”的激烈竞争下,家装企业谋求生存和发展应注重从供应链的角度切入,积极寻找降低成本并提高服务的空间,这一突破口就是物流配送。
SVM(Support Vector Machine)是基于结构风险最小化原则的分类学习方法,其原理可简单描述为:通过事先选择的非线性映射(核函数)将输入向量x映射到一个高维特征空间,在这个空间构造最优分类超平面,以将两类样本无错误地分开(训练错误率为0),而且要使两类(标记为y∈{-1,1})的分类空隙最大,前者保证经验风险最小,后者使推广性的界中的置信范围最小(即分类器的结构风险最小),这样可使在原始空间非线性可分的问题变为高维空间中线性可分的问题[29,30]。SVM决策函数的基本形式为
式中:counter(q,Qi)表示特征Qi在类别q中出现的次数;N表示问句类型个数;counter(Qi)表示特征Qi在训练集中出现的总次数;M表示特征Qi在M种问题类型中出现。此外,改进的贝叶斯模型还针对语料库分布不均匀对某些特定词(如“什么”)做了TF-IDF加权处理。
采用贝叶斯分类器的代表性研究主要有:Dell Zhang在文献[10]中分别以词袋和词块作为特征,并在规模不同的训练集上用朴素贝叶斯对英文问句进行分类,大类和小类的最高准确率分别为83.2%和67.8%;Krystle Kocik在文献[26]中提取英文问句首两个单词、问句长度和问句焦点为特征,大类和小类准确率分别达到88.6%和73.4%;文献[14]将改进贝叶斯模型引入到中文问句问类中,但是在进行分类时只侧重词频这一单一特征,使得分类精度得不到保证;文勖等在文献[12]中使用句法分析的结果,提取问句的主干和疑问词及其附属成分作为分类特征,大类和小类的精度分别达到86.62%和71.92%;田卫东等[27]分析知问句中的疑问词和中心词等关键词对问句所属类型起决定性作用,提出利用自学习方法建立疑问词-类别和疑问词+中心词-类别两种规则,并结合改进贝叶斯进行分类,准确率达到84%;许莉等[28]利用依存句法分析问句的主干,从语义信息角度分析问句主干从而提取出问句的特征词,也取得较好的分类效果。
4.2 支持向量机模型
首先,学生们进行角色扮演游戏,模拟17世纪末18世纪初的国际贸易。学生们分别扮演商人、买家、海关人员等角色,相互讨价还价,买进卖出。过程中,学生须知道自己扮演角色的商业规则,要办清关手续,要考虑运输中可能会遇到风暴或海盗等因素。最终把货物都运到目的地、能赚钱的组就算获胜。
水痘是带状疱疹病毒引起病毒性疾病,可以口服给药,不用输液。有传染性,家中未出过水痘或未打过疫苗的人都应注意隔离,家中的水痘或带状疱疹患者也应该和没生病的宝宝隔离。
这是个二次规划问题,可以找到全局最优解ai,而且w→可以由以下公式得
此时根据锁相环输出的同步电压过零点可以计算出各换流阀产生触发脉冲的时刻。其中换流阀3、5、1处产生触发信号时刻分别对应上半桥ab换相、bc换相、ca换相,6、2、4处产生触发信号时刻分别对应下半桥ab换相、bc换相、ca换相,相应的下半桥换相时间滞后上半桥半个周期,因此可以统一分析,各上半桥换相时刻对应的电角度分别为:
SVM构造的是一个二值分类器,但问句分类是个多值分类问题[31],通常的解决方法是通过构造多个二值支持向量机的组合来解决,主要有一对一组合模式和一对多组合模式,一对一组合模式已被证明其性能优于一对多模式[32]。
将SVM作为分类器的代表性研究主要有Zhang等[10]利用树核函数提取特征,在词汇的基础上引入句法结构特征进行英文分类,在UIUC问题集上准确率达到了80.2%;李鑫等[15]提出采用基于错误驱动集成分类器,用规则方法TBL作为统计方法SVM的补充,利用来自WordNet的同义词集和名词的上位概念及Minipar的依存关系等语言知识作为分类特征,在公开测试集中取得91.4%的分类精度;杨思春等[21]提出在提取问句中词袋、词性、词义等基本特征及其对应的词袋绑定特征的基础上,通过将基本特征与词袋绑定特征进行融合,采用SVM分类器在哈工大中文问句集上实验,分类精度获得显著提升,在77个小类上的分类精度达到83.4%。
4.3 K-近邻模型
K-近邻(K-Nearest Neighbor,KNN)算法的基本思想是:把训练集中的每个样本用特征向量表示,对于每一个测试样本,利用相似度函数计算该测试样本与训练集中每一个样本的相似度,找出K个最相似的样本,而每个相似样本对应一个类别,计算测试样本属于各个类别的权值,最后选择权值最大的类别作为该测试样本的类别。可用下式表示
式中:Q为测试问句,di为最近邻的K个问句,y为类别属性函数,若di∈Cj,结果为1,否则为0,n为问句类别数。
将KNN模型应用于问句分类的相关研究工作主要有:Sundblad在文献[33]中仅以词袋为特征进行英文分类,在TREC10问句集上大类和小类准确率分别为67.2%和60.0%;贾可亮等在文献[34]中利用知网(HowNet)义原树计算问句之间的语义相似度,并以此作为句子之间的距离矢量,利用KNN算法构造分类器进行问句分类,在所采用的分类体系上达到89.8%的精确率。
4.4 最大熵模型
最大熵模型(Maximum Entropy Models)是个比较成熟的统计模型,适合解决分类问题,目前在文本分类、词性标注、组块识别等领域获得成功应用。其基本思想是:对未知的不做任何假设,即在只掌握关于未知分布的部分知识时,应选取符合这些知识并且使得熵最大的概率分布。
对本地传统产业,不要只看到市场价格低赚不到钱没有过开发价值的一面,更要看到当前的生产方式落后、工效低、消耗大、技术水平低、具有巨大的提升空间,通过分工合作、采用先进生产技术和设备赢利潜力很大,且创业和就业前景很好的一面.其实,只要传统产业内部各环节建立起分工合作的生产方式,并在此基础上应用先进的生产技术和设备,农业的产业化改造就有了起步,产品在市场上就有了竞争力,外出务工人员回乡创业、就业的机会就会不断增加.从上面的分析中我们可以发现,华堂村各项传统产业的许多环节都可实行分工合作的生产方式来提高工效,降低消耗,提升技术水平,如:
对于训练样本集T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi(0<i<n+1)表示特征向量,yi(0<i<n+1)表示样本对应类别。在给定样本T和相关约束条件下,存在一个唯一的概率模型P(y|x),其熵的分布最大,一般形式为:
当前问句分类的方法主要集中在两方面:基于经验规则的方法和基于统计的机器学习方法[23-24]。早期的研究主要是基于规则的方法,它是通过预先定义好的规则或模板来判定问句所属的类别[23,25]。这种方法虽然简单易行,但是需要花费过多的人力、物力编写大量规则,此外,由于汉语的构成语法比较复杂,要穷举出所有的规则实属不易,所以基于人工规则的方法有很大的局限性。现在基于统计的机器学习方法由于通用性强、易于移植和扩展等优点被广泛应用,它先提取能表达各个问句类型的特征向量,再对真实的已标注的问句语料进行统计学习建立分类器,最后通过分类器实现对测试问句的类别标注。这种方法的关键在于提取问句的特征向量,特征向量的优良性直接影响着分类器的精度。
将最大熵模型应用于问句分类的相关研究工作主要有:Kocik在文献[26]中提出将统计学方法中的最大熵分类法用于英文问句分类,提取问句焦点、问句长度、命名实体、词块等作为特征,大类和小类精度分别达到89.8%和85.4%,该方法的准确率优于当时其他所有方法;Minh Le Nguyen在文献[36]中提出将子树挖掘方法用于问句分类,该方法将问句进行分解,提取分解后的树的子树作为特征,用最大熵模型进行分类,在TREC数据集上小类准确率为83.6%;孙景广等在文献[18]中提出以问题的疑问词、句法结构、疑问意向词、疑问意向词在知网中的首义原作为分类特征,使用最大熵模型进行分类,大类和小类的分类精度分别达到92.18%和83.86%;李茹等在文献[37]中通过构建一系列汉语框架语义特征来表达每个问题的语义信息,再使用最大熵模型进行中文问题的自动分类,与传统的问题分类技术相比,汉语框架语义信息的加入使得中文问题分类的精度得到了显著提高。
4.5 4种分类模型的比较
上面4节对常用于问句分类的4种分类模型的基本思想和相关的研究工作做了简要介绍,表3从理论框架、线性关系、时间效率、分类精度及优缺点这6个方面对这几种模型做了比较分析。
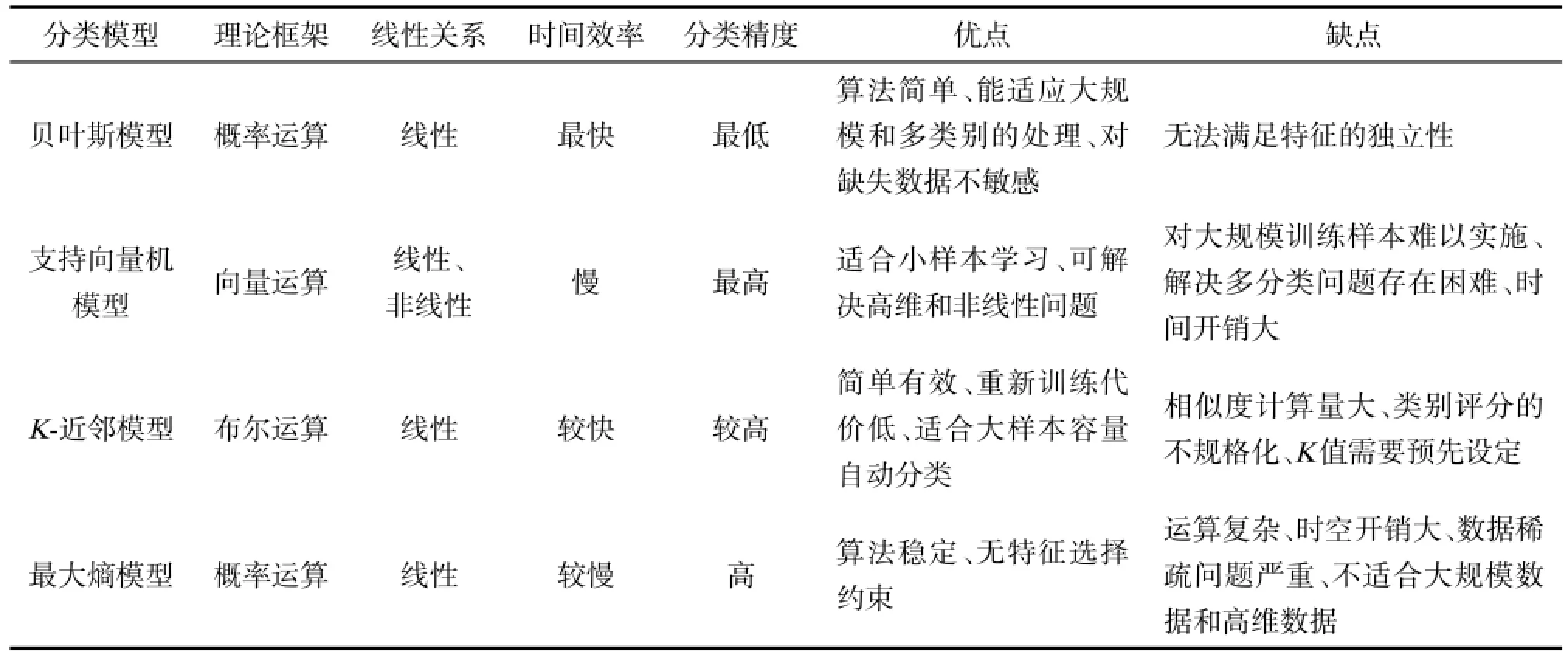
表3 4种分类模型的比较Tab.3 Comparison of four classifier models
5 研究难点及未来研究方向
提取和选择各种有效的问句特征是问句分类最大的难点,也是决定分类结果好坏的关键所在。由于汉语的复杂性,无法判断每个词汇对分类的贡献差别,而且问句比较短,包含的特征较少,表层词语信息并非都能充分反映问句到底问的是什么,因此如何合理地分配权值、无噪音地扩展、加入语法语义规则以及如何获取所需特征都是难点所在。
由于问句分类这一领域涉及面比较广,如资源库的建立、自然语言理解、统计理论和机器学习等,所以仍有一些问题需要改进,未来的研究可以考虑以下几个方向:
日本的啤酒也值得破例一饮吗?飞赴东瀛的两天前,参加一个餐叙,一位在日本生活过多年的朋友告诉我:“值!”于是,在京都、大阪的十几天里,便不再约束自己,想喝便喝,亲近日本啤酒。结果呢?感觉还真的不错;更有价值的是,在啤酒之外,我还在更高层次上,有了始料未及的重大收获。
(1)语言处理平台的改进。对问句进行分类首先要对问句进行预处理,提取特征都是在预处理的结果上进行的,分词、词性标注的正确率直接影响问句分类的正确率,但是目前使用的LTP平台效果并不是很理想,很多问句分类的错误都是由于分词与词性标注的错误导致的。例如问句“辽宁又称为什么?”经过分词和词性标注处理后结果为“辽宁|ns;又|d;称|v;为什么|r;?|wp;”,这样该问句很容易被误归为原因类。基于条件随机场(CRF)的分词和词性标注技术方法是当前比较热门的研究方法,可以考虑在此基础上改善分词和词性标注技术。
(2)问句集的完善。中文问句分类精度达不到英文问句分类水平一方面是汉语的复杂性,还有一个原因就是受到语料库规模和质量的限制,一般来说,训练语料的规模越大,问句覆盖面越广,学习的分类模型越完善,分类的效果也就越好,因此有必要扩充语料。一方面可以考虑从Sogou问问、百度知道等问答社区搜索问句扩充训练集,另一方面也可以采用半监督或者无监督主动学习构建训练集。
发达国家的绿色消费水平之所以高,原因之一是他们在绿色农产品的营销上形成了完整的体系。相对而言我国绿色营销起步较晚,绿色消费的意识不强。在营销方面缺乏相应的人才,尤其是绿色营销人才缺口较大,真正了解绿色营销的人也是少之又少。绿色营销人才的严重匮乏,导致酥梨绿色营销专业性不强,系统性较差。
(3)训练数据均衡。训练数据在问句类别上数量的不平衡导致分类器在不同的类别上表现出不同的性能,因此在主动自动扩大训练语料规模的时候要更加注重语料的平衡性。
(4)分类器配合。现在大部分对分句分类的研究都基于单个分类器,多种分类器的并行组合和投票方法在问句分类上的性能,也是需要进一步研究的问题。
(5)分类体系的统一。目前的分类体系还没有一个统一的标准,各个系统都根据系统的应用领域自行定义类别,这也导致了训练数据很难共享。今后需要对问句分类的标准做进一步研究,以期得到一个折衷的分类体系。
6 结 语
问句分类作为问答系统的重要模块,其主要目的就是确定用户所提问句的类型,它对后面的答案抽取策略有着间接决定性作用,因此提高问句分类精度也是在改善整个系统的性能。本文从问句分类体系、问句特征提取和分类模型三个方面综述了近年来自动问答系统中问句分类的研究进展,在分析了当前问句分类中存在的难点的同时,又提出了今后在语言处理平台、问句集、分类器等方面的研究方向,为进一步研究设计出更高性能的问句分类器奠定了坚实的基础。
[1]张江涛,杜永萍.基于语义链的检索在QA系统中的应用[J].计算机科学,2013,40(2):257-260.
[2]钱强,庞林斌,高尚.一种基于词共现图的受限领域自动问答系统[J].计算机应用研究,2013,30(3):841-843.
[3]郑实福,刘挺,秦兵,等.自动问答综述[J].中文信息学报,2002,16(6):46-52.
[4]刘挺,秦兵,张宇,等.信息检索系统导论[M].北京:机械工业出版社,2008:21-255.
[5]嵇宇,王荣波,谌志群.基于句法分析和二次贝叶斯模型的受限域问题分类[J].计算机应用,2012,32(6):1685-1687,1689.
[6]Huang Z H,Thint M,Celikyilmaz A.Investigation of question classifier in question answering[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing(EMNLP).Singapore:Association for Computational Linguistics, 2009:543-550.
[7]苏斐,高德利,叶晨.Web问答系统中问句理解的研究[J].测试技术学报,2012,26(3):207-212.
[8]毛先领,李晓明.问答系统研究综述[J].计算机科学与探索,2012,6(3):193-207.
[9]Li X,Roth D.Learning Question Classifiers:the role of semantic information[J].Journal of Natural Language Engineering,2006, 12(3):229-250.
[10]Zhang D,Lee W S.Question classification using support vector machines[C]//Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval.New York:ACM Press,2003:26-32.
[11]姜东洋.基于知网的中文问答系统问题理解与研究[D].辽宁:大连理工大学,2007.
[12]文勖,张宇,刘挺.基于句法结构分析的中文问题分类[J].中文信息学报,2006,20(2):33-39.
[13]程泽凯,陆小艺.文本分类中的特征选择方法[J].安徽工业大学学报:自然科学版,2004,21(3):220-224.
[14]张宇,刘挺,文勖.基于改进贝叶斯模型的问题分类[J].中文信息学报,2005,19(2):100-105.
[15]李鑫,黄萱菁,吴立德.基于错误驱动算法组合分类器及其在问题分类中的应用[J].计算机研究与发展,2008,45(3):535-541.
[16]Wu Y Z,Zhao J,Xu B.Chinese question classification from approach and semantic view[C]//Proceedings of the SecondAsia Information Retrieval Symposium.Ieju Island,Korea:[s.n.],2005:485-490.
[17]Huang Z H,Thint M,Qin Z C.Question classification using head words and their hypernyms[C]//Proceedings of the 2008 Conference in Empirical Methods in Natural Language Processing(EMNLP).Honolulu:Association for Computational Linguistics, 2008:927-936.
[18]孙景广,蔡东风,吕德新.基于知网的中文问题自动分类[J].中文信息学报,2007,21(1):90-95.
[19]余正涛,樊孝忠,郭剑毅.基于支持向量机的汉语问句分类[J].华南理工大学学报:自然科学版,2005,33(9):25-29.
[20]Li X,Roth D.The role of semantic information in learning question classifiers[C]//Proceedings of the 1st International Joint Conference on Natural Language Processing.Berlin:[s.n.],2004:451-458.
[21]杨思春,高超,秦峰,等.融合基本特征和词袋绑定特征的问句特征模型[J].中文信息学报,2012,26(5):46-52.
[22]杨思春,高超,戴新宇,等.基于词袋绑定的问句新特征自动生成[J].北京理工大学学报,2012,32(6):590-595.
[23]Hovy E,Gerber L,Hermjakob U,et al.Toward semantics-based answer pinpointing[C]//Proceedings of the first international conference on Human Language Technology(HLT)research.Stroudsburg:Association for Computational Linguistics,2001:1-7.
[24]张志昌,张宇,刘挺,等.开放域问答技术研究进展[J].电子学报,2009,37(5):1058-1067.
[25]Magnini B,Nergri M,Prevete R,et al.Mining knowledge from repeated co-occurrences:DIOGENE at TREC 2002[C]//Proceedings of the 11th Text Retrieval Conference.Gaithersburg:NIST Press,2002.
[26]Kocik K.Question classification using maximum entropy models[D].Sydney:the University of Sydney,2004.
[27]田卫东,高艳影,祖永亮.基于自学习规则和改进贝叶斯结合的问题分类[J].计算机应用研究,2010,27(8):2869-2871.
[28]许莉,王大玲,夏秀峰.基于句法和语义信息的问句特征提取方法[J].计算机工程,2010,36(21):65-66,70.
[29]Zhang X G.Introduction statistical learning theory and support vector machine[J].ActaAutomatica Sinica,2000,26(1):32-42.
[30]陈欣,郑啸,焦媛媛,等.一种基于支持向量机的垃圾微博识别方法[J].安徽工业大学学报:自然科学版,2013,30(10):440-445.
[31]延霞,范士喜.面向问答社区的粗粒度问句分类算法[J].计算机应用与软件,2013,30(1):219-222,286.
[32]Hsu C W,Lin C J.A comparison of methods for multiclass support vector machines[J].IEEE Transactions on Neural networks, 2002,13(23):415-425.
[33]Sundblad H.A Re-examination of question classification[C]//Proceedings of the 16th Nordic Conference of Computational Linguistics NODALIDA-2007.Tartu,Estonia:[s.n.],2007:394-397.
[34]贾可亮,樊孝忠,许进忠.基于KNN的汉语问句分类[J].微电子学与计算机,2008,25(1):156-158.
[35]Berger A,Pietra V,Pietra S.A maximum entropy approach to natural language processing[J].Computational Linguistics,1996, 22(1):39-71.
[36]Nguyen M L,Nguyen T T,Shimazu A.Subtree mining for question classification problem[C]//Proceedings of the 20th International Joint Conference onArtificial Intelligence.San Francisco:Morgan Kaufmann Publishers Inc,2007:1695-1700.
[37]李茹,宋小香,王文晶.基于汉语框架网的中文问题分类[J].计算机工程与应用,2009,45(31):111-114,137.
责任编辑:丁吉海
Overview on Question Classification in Question-answering System
ZHEN Lihua1,WANG Xiaolin2,YANG Sichun2
(1.School of Management,Nantong University,Nantong 226019,China;2.School of Computer Science and Technology,Anhui University of Technology,Ma'anshan 243002,China)
Question classification,as the first step of question-answering system,plays an important role in the system.Its accuracy affects the final extraction of the answer directly.Based on the concept of question classification,this paper first elaborated the question classification system,the question classification method and the question classification feature extraction.Then it focused on the several mainstream learning models for question classification,and made a comparison of these models.Finally the current research difficulties of question classification and the future research trend were indicated.
question-answering system;question classification;feature extraction;classification model
TP391
A
10.3969/j.issn.1671-7872.2015.01.010
2014-09-24
国家自然科学基金项目(61003311);安徽省高校省级自然科学基金项目(KJ2011A040)
镇丽华(1988-),女,江苏南通人,硕士,主要研究方向为自然语言处理。
王小林(1964-),男,安徽安庆人,教授,主要研究方向为人工智能、中文信息处理。
1671-7872(2015)-01-0048-07
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2018年1期)2018-04-18 11:52:35
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
