
基于XML半结构化的Web网页信息提取研究
2015-01-01 03:05
网络安全技术与应用 2015年10期
0 引言
Web信息提取(Web Information Extraction,简称为WebIE)是将 Web作为信息源的一类信息进行提取。它的主要目的是从半结构或无结构的信息中提取出特定的事实信息(Factual Information)。比如,从新闻报道中提取出恐怖事件的详细情况:时间、地点、作案者、受害者、袭击目标、使用的武器等;从经济新闻中提取出公司发布新产品的情况:公司名、产品名、发布时间、产品性能等;从病人的医疗记录中提取出症状、诊断记录、检验结果、处方等,或者直接提取文章中某句话或某段话的信息等等。
1 研究背景
随着Internet的飞速发展,Web已经发展成为一个巨大、分布和共享的信息资源,目前Web数据大都以HTML形式出现,缺乏对数据本身的描述,不含清晰的语义信息,模式也不明确,结构上也不良好。这使得应用程序无法直接解析并利用到 Web的海量信息,为增强Web数据的可用性,出现了Web信息提取技术,它通过包装现有 Web信息源,将网页上的信息以更为结构化的方式提取出来,为应用程序利用 Web数据提供了良好的方式。
2 研究现状
信息提取的研究起源于20世纪90年代初,国外的研究表现在以下几个方面:斯坦福大学的Sergey Brin提出的DIPRE算法可以对 Web文档数据关系进行发现;IBM 研究中心的N.Sundaresan等对Web文档中的双义问题进行了讨论并提出了改进的算法,并对 Web中的英文单词缩写和全称进行了挖掘。国内的研究:复旦大学周傲英等对半结构化文档的模式提取进行了研究,提出了递增式模式挖掘算法;南京大学张福炎等采用OEM模型构造了半结构化数据的提取器。这些 Web提取研究利用了半结构化文档的特点,对互联网上的数据进行深层次的查找和分析,用知识代替了信息作为信息获取的最终结果。
3 研究内容
3.1 总体描述
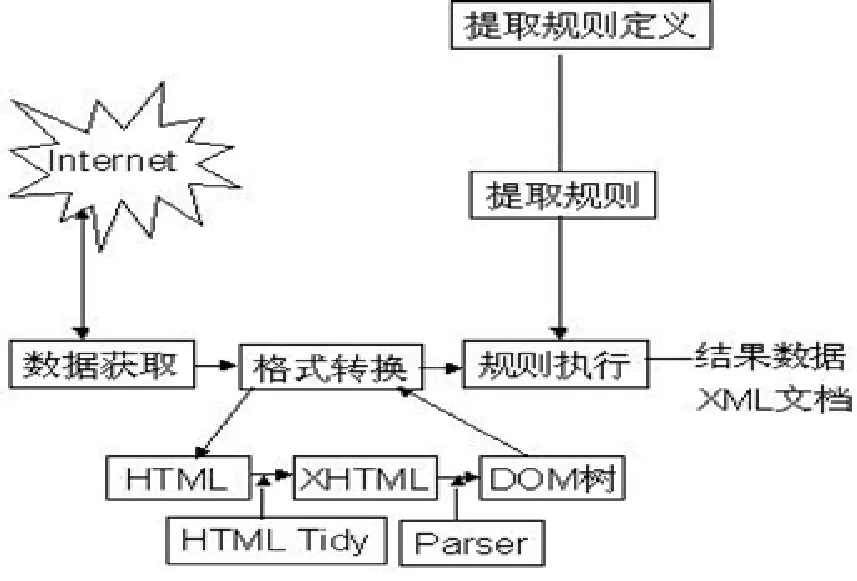
图1 整体结构图
本文重点研究如何从半结构化的 Web页面中提取出用户感兴趣的数据,并试图提出一个基于XML的Web信息提取平台。其工作的核心是生成提取规则。这里,提取规则实际上就是对感兴趣的信息点进行定位。首先需要将样本 Web页面转化成为结构良好的XML文档;通过从样本XML文档中找到用户感兴趣的区域;并在这个区域内细粒度地查找到具体要提取的信息点的定位信息;然后对不同样本页面的定位信息进行归纳学习,学习出该类页面感兴趣信息点的定位信息,并构造出以XSLT文档表示的提取规则,最终应用该提取规则进行实际的信息提取,如图1所示。
3.2 平台的目标
本信息提取平台目的是结合现有不同提取技术的优点,以XML技术为基础,将Web页面中的关键信息自动地提取出来,并表达成为结构化的、扩展性很强的XML文档。
本文希望通过一组相似的页面,能够归纳出相应的提取规则,进而利用提取规则进行页面信息的提取。
3.3 设计的基本思想
系统首先根据用户指定的URL获取样例网页数据并且将该网页利用HTML Tidy转换为XHTML。
然后利用 XML Parser将该 XHTML文档解析成为 DOM(Document Object Model)树结构,这样DOM树就成为Web网页在系统内部的表示形式。
最后在获得DOM树的基础上,应用XSLT将DOM树结构转化为结果XML文档。
3.4 总体框架
3.4.1 知识库和数据库
系统中的库包括知识库(Knowledge Base)和数据库(database),知识库包括领域知识库和提取规则库。数据库包括提取结果数据库和Web页面数据库。
在实际操作中,提取系统中的知识库和数据库的构建比较复杂,而本文的侧重是信息提取的研究,所以有关知识库和数据库的部分本文不做深入的阐述,如图2所示。

图2 总体框架
3.4.2 页面优化模块
主要针对待学习页面和待提取页面进行优化处理,使结构不完整或不规范的Web页面转化成为结构良好的XHTML文档,并解析成为DOM树结构。
3.4.3 信息提取模块
信息提取是本文的核心,信息提取以获得提取规则为前提,任何信息提取的研究都致力于获得健壮可靠的提取规则,然后运用提取规则进行信息的提取。因此,该部分就分为两个步骤:首先进行样本学习,以获得提取规则;然后运用规则进行信息提取。
4 平台中的知识库与数据库
4.1 构造领域知识库
领域知识库的功能主要包括如下几点:
(1)为用户提供查询导航服务,使用户开始使用时不至于束手无策。方法是将一些较重要的网站的URL添加到相应的领域下。
(2)为规则的管理提供逻辑和方法上的支持,方法是将提取规则按照子领域分类存储。
本文中的领域指的是发布同类信息的专业网站,领域知识库是要提取的信息所在领域所包含的基本概念、属性、实体、规则等知识。如出版社图书出版网站发布的是有关图书的一类信息,它的领域知识库就要包含图书所要求的各种基本概念和属性等知识。本文中规定,领域知识库中的各领域按从属关系形成一个层次树,而根是虚拟的,也可称为“根领域”。
4.2 提取规则库
提取规则库存储的是已经学习到的提取规则,提取规则是欲提取的识别模式知识。对不同的领域和网站所采用的规则各不相同,随着提取系统的运行,会产生许多规则,系统自然需要一个库来存放这些规则。当系统需要进行信息提取时,首先可以向规则库中查找是否有可以重复利用的规则,如果有则可以直接从规则库中提取出相应的规则,不必再重新生成针对相似网站或网页的新规则。
4.3 提取结果数据库和Web页面数据库
最终提取出来的结果是含有用户感兴趣信息点的 XML文档,提取结果数据库中存放的也就是这些XML页面。Native XML DataBase,也称 XML本源数据库,是专门设计用于存储 XML文档的数据库,它以XML文档自身的形式来存储XML文档,与其它数据库的不同在于其内部模型是基于XML文档格式的。
4.4 页面优化模块
4.4.1 清洗(TIDY)页面文档
清洗(TIDY)页面需要做的是对Web页面进行修复转换成为符合规范的XHTML文档,本文中称为清洗(TIDY)。
HTML Tidy是一个开放源代码的强大工具,可用于修正HTML文档中的常见错误并生成格式编排良好的等价文档。本文使用了Tidy的类库,将其集成到系统当中。Web页面将通由Tidy进行页面预处理,将源HTML文档转换成等价的XHTML文档。
4.4.2 页面解析(PARSER)
HTML DOM树是Web页面的一种描述方式,是根据Web页面中 HTML标签的含义而建立的,有层次关系的树状结构,其上的每个节点都是一个单独的HTML元素。因此,将DOM层次结构中的路径理解成为提取的“坐标”,通过对坐标的获得和理解来得到需要提取的信息。这个过程中,将XML文件加载到内存生成XML DOM树,以供提取规则学习模块来生成基于DOM的规则。
4.5 信息提取模块
在 Web信息应用中,使用包装器进行信息提取。包装器是一个软件过程,应用已经定义好的信息提取规则,将输入 Web页面中的信息数据提取出来,转换成用特定格式描述的信息,提供给其它信息系统做进一步研究,信息提取的工作流程如图3所示。

图3 信息提取工作流程
4.5.1 规则学习的依据
规则(rule),不同的文献中也有称作模式(pattern)的。Wrapper的核心是提取规则,构造准确健壮的提取规则是重中之重,也是任何提取系统致力的目标。
文中主要采用 HTML中所包含的结构特征、位置特征、显示特征、语义特征和引用特征形成提取规则。规则学习的步骤:(1)确定样本页面集;(2)样本学习,生成提取规则。
4.5.2 信息提取过程的描述
当得出了提取规则XSLT文档后,要构造一个进行信息提取的wrapper仅需要执行这个XSLT。
5 结束语
本文方法为 Web页面的信息提取奠定了良好的基础,但其适用范围仍然有所局限。当遇到了页面结构较为复杂并且缺乏语义的时候,提取的准确率就会降低。所以,需要加强学习提取规则的适应性和算法来解决信息复杂性,信息源权威性和有效性,提高信息提取的准确性。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
成都信息工程大学学报(2021年6期)2021-02-12
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
制造技术与机床(2019年6期)2019-06-25
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
中国交通信息化(2016年9期)2016-06-06
