
云计算技术在海量数据安全性SLIQ算法中的应用
2015-01-01 03:04
网络安全技术与应用 2015年10期
0 引言
随着时代的发展以及客户的需求变化,计算机采集数据量在不断增大,提升计算机安全性,运用计算机处理海量数据已成为一种技术趋势。针对不同数据类型以及数据格式的信息,运用计算机对数据进行处理,其难度也相应有所提升;基于云计算技术的发展,将该技术应用到数据处理之中,能够取得不错应用效果。本文主要目的就是分析在云计算技术支持下,改进传统的数据处理方法,应用并行SLIQ算法实现对计算机海量数据的处理,以便提升计算机海量数据处理效果。
1 云计算技术
1.1 云计算优势
云计算就是以更快捷的方式为用户提供计算资源,不断地提高云计算下计算机的处理能力,减少计算机用户终端的数据处理的负担,使计算机数据终端可以简化为一种输入输出设备,云的强大计算处理能力使用户可以按需求取。云计算它包括网络计算、并行计算、网络存储、分布式计算等,它是用网络的方式整合较低的计算实体,最终形成强大计算能力的用户终端,并借助商业模式来进行推广应用。
1.2 安全优势
基于云计算的并行SLIQ算法,就是在用云计算作为支持的技术平台上,再构建分布式时空数据库,面向拥有海量数据计算机系统的数据挖掘模型。并且,在云计算技术下,确保计算机海量数据在传输中不发生成批成片丢失、错误的状况,可以解决海量数据存储中节点失效几率,可以确保计算机数据安全性。
2 基于云计算的海量数据SLIQ算法
基于云计算的计算机数据处理中,能够为客户数据处理提供动态资源池,并可以实现虚拟化可用性计算机数据处理平台,这样就可以利用云计算来对计算机海量数据进行计算挖掘。

图1 云计算中数据计算模型
在基于云计算的计算机海量数据SLIQ算法中,可以通过这个云计算平台,云计算技术的底层中,是可以透明化实现的,其能够给上层数据计算提供服务,并且在基于运算的SLIQ算法上层之中,还可以有效通过计算机的层间开放接口,以此去调用下层中的数据服务,这也就可以使得计算机海量数据SLIQ算法中,其并行决策树层以及层之间功能,能够实现其之间的相对独立,云计算设计的计算机海量数据处理中,基于海量数据的二次开发,设计出具备多层插件的框架结构,计算机海量数据SLIQ算法,运用云计算技术,整合资源跟弹性构架,增加实际计算机海量数据SLIQ算法的实现有效性,提升其维护中的灵活性。同时,在基于云计算的SLIQ算法之中,要满足数据复杂型,满足海量数据动态性,是一种实现数据挖掘的重要模式。
3 计算机海量数据SLIQ算法处理的特征
在SLIQ算法中,可以采用预排序的技术,有效消除云计算决策树中每个节点数据集排序需要,对每个属性取值,把记录按从小到大排序,为训练集数据的每个属性创建一个属性列表,运用广度优先策略去构造决策树,也就是在决策树的每一层,可以只需对其每个属性的列表进行扫描,就可以一次找出其决策树叶子节点的最优分裂标准,从而提升数据处理效率。
在SLIQ算法的数据结构中,包含属性表(Attribute List)、类表(C1ass List),其中,SLIQ算法中的每个属性有一个属性表,有必要的话,属性表可以写回磁盘类表(C1ass List):

SLIQ算法中仅有一张类表,类表必须常驻内存,类表第 n项,存放第n条记录的类标签,类表(C1ass List)表示如下:

SLIQ算法的数据结构中,还包含有树节点,内部节点记录必要的分类信息,叶子节点代表训练集的一块数据,也就是一个类别。每个节点之中,其也都具有一个类的直方图,可以在计算机海量数据处理中,用此图来统计分类数据信息。
SLIQ算法树结构中的数值型字段的类直方图:SLIQ算法树结构中的种类型字段的类直方图:

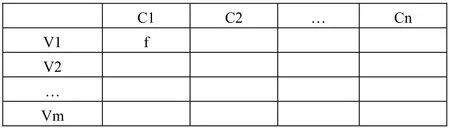
SLIQ算法中,具备预排序与广度优先增长策略;而且在SLIQ算法中,还有预排序与广度优先增长策略,计算出最佳分割以后,就可以产生子节点了;子节点生成以后,需要对类表进行更新,使它指向原来节点的子节点。其更新类表算法代码如下:
UpdateLabe1s()

4 云计算下计算机海量数据SLIQ算法实例
4.1 构建云服务平台
在基于云计算技术的SLIQ算法中,将会应用“云服务”,针对云计算公共标准,基于云计算开发网络平台,有效分类、管理、利用计算机海量数据资源,确保计算机海量数据在“云端”的安全性,选择可想的云计算服务,提升计算机海量数据平台开发的质量。计算机海量数据处理,在实际应用领域内,给数据管理工作带来许多优势,选择适合数据分析模型的关联规则,建立数据仓库,并对其进行数据清理、数据转换、数据消减等,应用基于云计算技术的SLIQ算法,大大优化了计算机海量数据管理质量。
4.2 细化云计算下的服务分层
同时,对于在硬件开发部门,将会应用云计算技术,利用“云端”、计算机系统以及局域网组建其互联网形式,有效提升硬件开发方面的质量水平。在应该开发中,应用三层次服务,云计算技术的SLIQ算法中,实现用户通过云计算web浏览器以及手机等移动设备,提升计算机海量数据处理速度,避免重复开发。并且,在云计算技术下,对于计算机本地存储的数据,均会进行加密保护,并且在数据的网络传输上也会加密保护,确保海量数据传输安全。在设计中,还需要具备任务调度以及创建新任务的功能;内存管理中,应该可以实时用户提供强大的虚拟存储管理机制,在软件设计中还应该具备中断管理、时间管理功能,可以在系统的软件设计中,设计出基于云计算海量数据处理中的时钟程序;能够在云计算技术下,针对计算机海量数据处理软件设计中,设置具备任务扩展功能的结构,提高海量数据处理实际使用效率。
4.3 实现云计算下的SLIQ算法
云计算下SLIQ算法中,根据MDL剪枝原理,对计算机海量数据进行编码,对于生成的初始树,发现最好的描述训练集S的子树 T。同时,SLIQ算法还具备一些不足,首先是,云计算技术的SLIQ算法中,在云计算计算机中把类别列表存在内存,中限制处理数据集大小。其次是云计算技术的SLIQ算法中,采用的是预排序技术,由于实际排序算法复杂度,不是和记录个数成线性关系的,在实际中也不能通过记录数目增长,而是使数据结构发生线性可伸缩性。

图2 数据结构

图3 直方图
要实现数据库内数据的转换,首先确定数据分析中所具备的参数,定义统计数据以及删除统计数据,确定统计时间段,以及参与SLIQ计算的字段。首先,对学生成绩数据进行预排列,数据结构及树节点信息、类型字段直方图如图2、图3所示。
计算样本集信息熵,计算每个属性的信息增益;对于属性age,需要知道age的每个样本值yes和no的分布。根据训练样本集的属性划分成子集的熵;生成决策树的根和分枝。如图4所示:
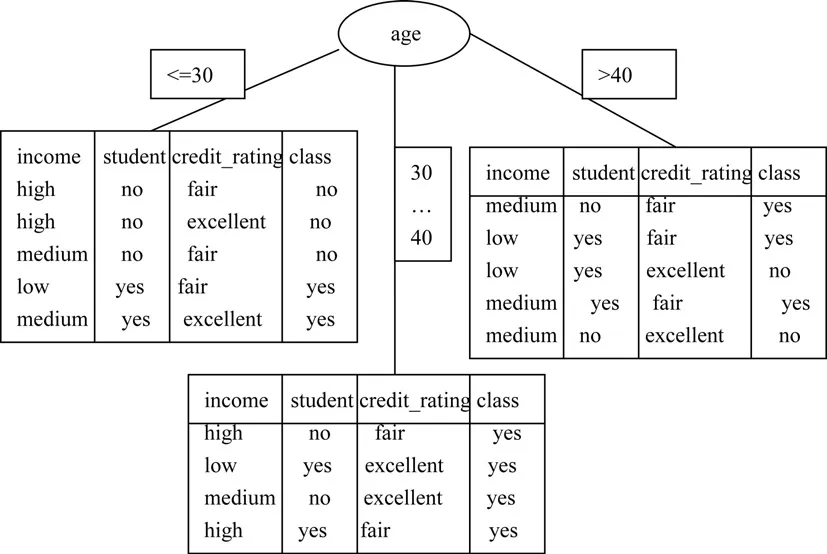
图4 决策树
基于SLIQ算法中,针对实际计算机海量数据处理中,改进的SLIQ算法,避免因 SLIQ 算法需大量可以计算云计算决策树中每个节点的指数,从而可以获得每个节点的分裂属性,减少计算复杂性,提升分类效果,类图5如下:
图5 类图
建立其云计算技术的决策树,云计算技术的SLIQ算法中,计算最大信息增益值算法代码如下所示:

云计算技术的SLIQ算法中,计算最佳分割的算法代码如下所示:

建树的过程中,应该提高“确定最佳分裂(Best Sp1it)”的可伸缩性,计算开销不大,确定数值型字段,寻找最佳的子集,遍历所有子集,时间复杂度为指数级。其次,选择导致最低错误率的子树;使用独立的数据集,快速得到简洁而且准确的决策树,安全性高,数据准确度高。最后得出决策树,经过程序对决策树进行遍历,得出计算机海量数据处理结果。
4.4 效益分析
针对计算机海量数据处理中,基于云计算技术,应用 SLIQ算法处理海量数据,改变以往计算机海量数据管理模式,把人工手动管理为计算机网络化管理,使计算机海量数据处理方便快捷,提高了数据的安全性。采用云计算技术,将计算机海量数据信息都存储为一个服务器群,方便数据安全连接,也可以使各种硬件和软件资源在互联网上能够自由流通,避免计算机数据丢失,可以减轻计算机海量数据处理人员的工作量,加强管理,还有就是缩小开支,提高工作效率与准确率。
5 结论
综上所述,针对计算机海量数据,应用基于云计算技术SLIQ算法,有效解决计算机海量数据计算问题,加快数据查询速度,处理海量计算机数据,提升其工作中的安全性;同时,在处理计算机海量数据时,采用云计算SLIQ算法,不仅可以解决计算机海量数据存储中节点失效的问题,还可提高计算海量数据的效率,降低数据处理复杂度,快速挖掘海量数据信息,具有实际应用价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
岩土工程技术(2019年6期)2020-01-06
成都信息工程大学学报(2019年3期)2019-09-25
当代陕西(2019年14期)2019-08-26
电子制作(2018年16期)2018-09-26
电子制作(2017年8期)2017-06-05
物探化探计算技术(2016年6期)2017-01-12
中学数学杂志(初中版)(2016年5期)2016-11-01
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
湖南城市学院学报(自然科学版)(2016年4期)2016-02-27
