
Web页面细粒度数据抽取方法研究
2014-12-23 01:31:10王旭仁何发镁王彦丽张为群
计算机工程与设计 2014年2期
王旭仁,杨 硕,何发镁,王彦丽,张为群
(1.首都师范大学 信息工程学院,北京100048;2.北京理工大学 图书馆,北京100081;3.西南大学 计算机与信息科学学院,重庆400715)
0 引 言
Web数据挖掘[1]重要的基础研究内容之一是Web页面数据抽取,目前已经有一些Web数据自动抽取方法[2-4]和系统[4-7]如Omini,RoadRunner,IEPAD,MDR,DEPAT等[5]。文献 [6]提出了一种基于隐马尔可夫模型的中文科研论文头部信息和引文信息抽取算法,仅在局部进行归一化处理。文献 [7]采用条件随机场 (conditional random fields,CRF)模型统计了全局概率,考虑了数据在全局的分布。文献 [8]提出一种Web评论自动抽取方法,但这些系统[7,8]只能区分Web页面中的记录或者抽取到记录的内容,没有对记录 (records)包含内容中更小信息单位——字段/数据项 (items)作进一步分析,抽取的信息粒度比较粗,不能适应对字段分析要求较高的领域应用需要,例如机票搜索、房产信息查询等广泛行业应用。
以当下热门的房产数据搜索为研究对象,抽取Web字段级的数据,实现细粒度、稳定性好的Web 数据抽取方法。对来自不同房产网站的大量页面进行观察分析后发现:几乎所有网站的页面都可以概括为两类:①列表页 (record pages),列表页包含了多个记录,由于每个记录都是由同一模板生成,所以其格式几乎相同,在每个记录中包含了对于该记录的概要信息。通常还包含通往下一页,上一页的链接。②详情页 (content pages),描述了某个记录的所有详细信息,其中有部分信息和列表页中该记录的信息重合。如图1所示。抽取器的目的就是要把这两类网页中信息结构化地提取出来。

图1 房产Web页面分类
本文提出了一整套用于结构化数据抽取的解决方案,包括浏览器的半自动化模板标注插件,训练模板库的建设,模板自动关联模块,以及可视化的验证模块等。对包装器生成时所依赖的信息进行了基于稳定性的分类,并且按照信息稳定性的高低为每个字段生成多个抽取规则,在抽取时根据多个抽取规则进行抽取,只有在所有规则失效时才会导致抽取失败,提高了抽取模板的稳定性。
1 基于字段的细粒度数据抽取方法
本文主要抽取以下房产信息属性:标题、面积、总价、几室、几厅、几卫、小区、朝向、楼层、建造年代、联系电话等。根据页面提供内容的差异,规定详情页只有至少抽取出标题,面积,价格3 个字段和属性才算抽取成功,列表页要抽取出详情页链接才算抽取成功。完整的抽取器系统框架如图2所示,包括两个过程:页面模板训练过程和Web信息抽取过程。

图2 Web抽取的整体框架
训练过程描述如下:
使用JQuery 在网页的顶部生成模板标注工具的操作界面。
根据用户的操作,生成字段抽取规则或模板 (Item Templets)。
输出字段的<路径,正则表达式>到后台服务器 (Data Base)。
Web抽取过程描述如下:
对数据进行预处理(Preprocessing),例如归一化处理等。
根据页面的特征选择包装器Wrapper。
输出提取的字段信息,进行整合提交给用户,包括对信息的校验。
2 训练阶段
在训练过程中半自动化模板抽取插件通过交互式的方法,生成每个字段的抽取规则,然后提交到后台的候选模板库中。后台检测到有新的字段抽取规则加入后,会自动将其与同一站点的每一个种子的训练网页库中的网页进行匹配,如果匹配上,则将该字段匹配规则加入到该种子的模板中。最后,可以通过可视化模板验证工具对模板的抽取正确性进行验证。
2.1 半自动化模板标注插件
本系统开发了一个半自动化的工具来生成模版,大大降低了模版配置的工作量。页面模板库的生成由4个子过程来完成:①半自动化模板标注 (annotating)插件;②训练模板;③模板自动关联种子页面;④可视化验证。
通过GreaseMonkey 实现一个网页模板标注工具。GreaseMonkeysw 优点是实现跨浏览器平台操作。
具体算法如下所示。


图3是加上标注后的页面。
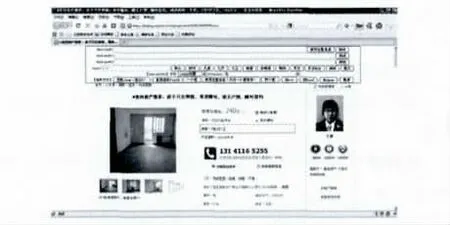
图3 在页面上生成模板标注工具
2.2 信息路径定位
无论是记录页面还是详情页面,对记录或者字段进行路径标注都非常关键。记录块的路径定位最好的情况是不需要人工参与,文献 [8]根据视觉信息对记录进行定位。定位准确率有待进一步提高,文献 [9]让用户先选择一个记录块,然后利用记录结构的重复特征寻找其它的记录块,文献[10]首先对主要数据区进行定位,进而应用树匹配的方法获得各个记录块的DOM 子树,无需用户的干涉。
在上述算法中,Locate()函数用来定位标签节点,在实现上有多种定位依据:根据标签位置信息,标签的位置信息在网页上经常变化,获取路径不够准确;根据标签的类别 (class)属性获取路径,一般说来,类别属性可以对应到某一类节点;根据标签的标号 (id)属性,某些节点拥有id属性,而且id属性在某一页面中一般是唯一存在的,定位较准;使用页面中的固定文本,这类文本一般稳定性较好,很少在改版中发生变化,这些文本通常可以作为结构化数据的提示文本,用于定位精确度较高。
本文提出一种用户交互式的方法来定位记录块。由于部分网页的记录块嵌套很多层,有的时候通过手工很难选择到正确的记录块节点。所以本文采用两次点击记录块内的节点,取其路径的公共部分作为记录块的路径,解决了节点错选的问题,提高了准确率。算法省略。
由于详情页的内容较丰富、格式复杂,字段路径的定位要分情况讨论,算法流程如图4所示。
2.3 生成模板
根据用户的操作生成模板。在生成模板后,把标注到的路径(Xpath),正则表达式 (regular expression),字段等信息提交到后台服务器。因为有两种类型页面,需要生成两个页面包装器(wrapper),分别是记录页面包装器(record page wrapper)和详情页面包装器(content page wrapper)。
对于详情页,匹配模板结构是:<Item XPath:Item Regular Expression>。
其中Item XPath是定位到某一字段节点的路径,Item Regular Expression是用于抽取出字段内容的正则表达式。
对于列表页,需要先定位到记录(record),然后再对其中的具体字段定位,模板结构为:

图4 详情页字段路径生成算法
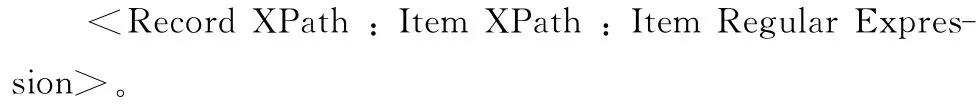
2.4 模板和种子的自动关联
记录页面或者详情页的模板向数据库提交时,并不是直接将种子与模板直接关联起来,因为一个种子可以有多个模板,一个模板可以对应多个种子。所以在提交模板的时候,只是把标注的模板提交进候选模板库,具体的关联操作在监控程序检测到新模板加入时才会进行。
本文提出模板和种子的一种自动关联算法。系统为每个种子维护了50个最新的网页作为训练集,10个列表页,40个详情页,这些网页是在下载器在下载时自动更新到数据库中的,从而可以保证是最新的网页。
2.4.1 新加入模板自动关联种子算法
该算法的关键是,遍历每一个种子的所有训练集网页,对网页尝试抽取,如果抽取成功,则说明该模板与该种子匹配,将模板与种子关联上,一个模板可能匹配多个种子。

2.4.2 新加入种子自动关联模板算法
由于一个站点可能会包含很多种子,而种子间的模板大都可以共享,所以当加入一个新种子的时候,首先对候选模板库中的模板进行尝试匹配。


3 抽取阶段
在抽取器进行抽取时,如果被抽取的网页是记录网页,①通过记录块的路径XPath定位记录;②通过字段的路径XPath定位到具体某个字段节点;③经过正则表达式对内容进行过滤后,提取出最终的文本。如果抽取的网页是详情网页,则跳过步骤①。
4 实验分析
4.1 评价标准
抽取成功是指从目标网页中抽取出了所有的必需字段,必需字段是所有抽取字段的一个子集,由具体的产品要求而定。抽取成功率是指在下载到的目标网页中,成功提取出必需字段的比例。
计算公式:Psuccess=网页抽取成功数/下载网页数
抽取准确率 (Precision)评价指标主要适用于字段,用于评估每个字段的抽取正确率。计算公式:Precision=Pcorrect/Ptotal。
Pcorrect是指抽取结果包含某属性并且该属性抽取正确的页面数;Ptotal是抽取结果中包含该属性的页面数。
4.2 实验结果和分析
系统进行为期1个月的测试运行,涉及房产行业内网站12家,种子39个。
(1)抽取成功率
对于抽取器,本系统规定详情页只有至少抽取出标题,面积,价格才算抽取成功,列表页要抽取出详情页链接才算抽取成功。抽取成功率统计见表1。

表1 抽取成功率统计
抽取失败主要由于网站改版而使得模板失效导致,在监控器进行报警后,模板失效问题平均可以在半小时内解决。
(2)抽取准确率
对于标题,面积,价格,小区4 个字段抽取了500 个记录进行检查,统计结果见表2。
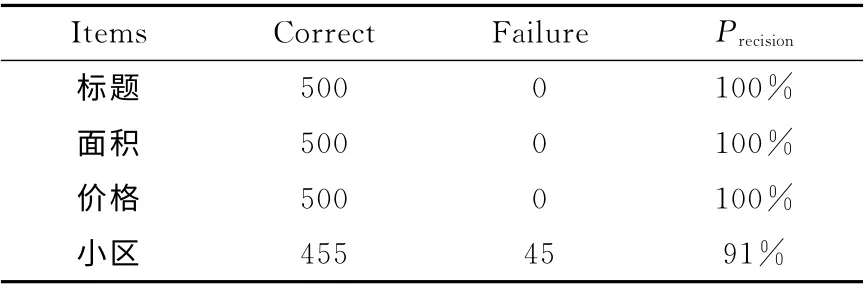
表2 抽取正确率统计
小区的抽取错误主要是因为详情页面的小区字段有两种形式,一种带链接,一种不带链接,在配置模板阶段,只配置了带链接的情况,导致部分页面无法抽取出小区。
这是本系统抽取生成的列表页,可以看到抓取了搜房网,易居网,赶集网等站点的信息,展示出了价格,小区,居室,地址等信息。如图5所示。

图5 系统效果
5 结束语
在现有交互式模板生成机制的基础上,根据统计数据分析了网页改版的特点,给出了一整套抽取的解决方案,包括半自动的模板生成工具,后台的模板和种子的双向自动关联等模块。在系统实际运行中,抽取成功率达到了列表页99%,详情页96%的效果,以及多数字段抽取准确率100%,部分字段抽取准确率91%的效果。在将来的研究中,还需要对生成模板信息进行稳定性分析和优先级排序、对动态网页的抽取处理等问题进行深入研究。
[1]Soumen Chakrabarti.Mining the Web:Discovering knowledge from hypertext data [M].Beijing:Posts & Telecom Press,2009 (in Chinese). [Soumen Chakrabarti.Web 数 据 挖 掘[M].北京:人民邮电出版社,2009.]
[2]Liu Hong,Ma Yinxiao.Web data extraction research based on wrapper and XPath technology [J].Advanced Materials Research,2011,271-273:706-712.
[3]Chang Chiahui,Kayed Mohammed,Girgis Moheb Ramzy,et al.A survey of Web information extraction systems[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1411-1428.
[4]TIAN Jianwei,LI Shijun.Retrieving Deep Web data based on hierarchy tree model[J].Journal of Computer Research and Development,2011,48 (1):94-102 (in Chinese).[田建伟,李石君.基于层次树模型的Deep Web数据提取方法 [J].计算机研究与发展,2011,48 (1):94-102.]
[5]JI Chun,JIANG Qin, WU Zhengyue.Survey of vertical search engine key technology [J].Information Research,2012(10):91-93 (in Chinese).[季春,姜琴,吴铮悦.垂直搜索引擎关键技术研究综述 [J].情报探索,2012 (10):91-93.]
[6]YU Jiangde,FAN Xiaozhong,YIN Jihao,et al.Information extraction from Chinese research papers based on hidden markov model[J].Computer Engineering,2007,33(19):190-192(in Chinese).[于江德,樊孝忠,尹继豪,等.基于隐马尔可夫模型的中文科研论文信息抽取[J].计算机工程,2007,33(19):190-192.]
[7]LIU Wei,YAN Hualiang.Unified and automatic Web news object extraction approach [J].Computer Engineering,2012,38 (11):167-169(in Chinese).[刘伟,严华梁.一种统一的Web新闻对象自动抽取方法[J].计算机工程,2012,38(11):167-169.]
[8]LIU Wei,YAN Hualiang,XIAO Jianguo,et al.Solution for automatic Web review extraction [J].Journal of Software,2010,21 (12):3220-3236 (in Chinese).[刘伟,严华梁,肖建国,等.一种Web 评论自动抽取方法 [J].软件学报,2010,21 (12):3220-3236.]
[9]GUAN Mian.Research on structured data extraction from Web forums [D].Jinan:Shandong University,2010 (in Chinese).[关冕.Web论坛结构化数据抽取技术研究 [D].济南:山东大学,2010.]
[10]ZHANG Huiying.QU Zhuwei.Approach for interactive Web data extraction based on sub-tree matching [J].Computer Engineering,2006,32 (9):78-80 (in Chinese). [张慧颖,曲著伟.基于子树匹配的交互式Web数据抽取方法 [J].计算机工程,2006,32 (9):78-80.]
猜你喜欢
商场现代化(2023年3期)2023-06-15 22:50:19
江苏科技信息(2022年16期)2022-07-17 09:07:36
丝路视野(2019年31期)2019-05-09 13:45:32
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
农家参谋(2017年10期)2017-03-27 01:09:53
商场现代化(2016年13期)2016-06-16 10:32:19
电子测试(2015年18期)2016-01-14 01:22:58
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
