
云网络中基于高服务质量的故障检测方案
2014-12-20 06:59李艳萍林建辉
计算机工程与设计 2014年11期
李艳萍,林建辉
(1.西南交通大学 机械工程学院,四川 成都610031;2.西南交通大学 牵引动力国家重点实验室,四川 成都610031)
0 引 言
在云计算网络应用环境[1,2]中,部分服务器比较活跃,可用性较高,而其它服务器非常忙碌且负载较重,还有些服务器因为各种原因而处于离线状态甚至系统崩溃。因此,云服务环境具有动态性和不可预测性[3],用户希望能有合适的可用服务器来完成他们的应用要求。我们必须能够应对这样的多变性,并提供带有参数指导的有效控制策略,以对服务条件和云资源进行管理。因此,虽然部分组件发生故障,人们还是提出了容错技术来为云计算网络提供可靠而又连续的服务[4,5]。作为云计算网络的重要基础,故障检测器 (FD)在开发此类高可靠性网络系统时具有重要作用[6]。要保证较高水平的服务质量,必须进行有效的故障检测。设计可靠的故障检测器非常困难,主要原因在于通信延迟的统计行为不可预测,另一个原因是异步分布式系统 (即进程运行速度或消息传输延迟没有界限)无法准确确定远程进程到底是发生故障还是运行速度较慢[7]。如果故障检测器可靠性较低,则可能会错误地怀疑正常进程或者信任故障进程。为了保证低可靠性故障检测器具有满意的服务质量,需要适当调整参数,以提供更高层次的高质量服务,因为故障检测器的服务质量对在更高层级提供服务质量具有重大影响。
1 相关工作
故障检测问题是云计算网络安全研究的热点之一,相继有众多的学者提出了一系列用于故障检测的方法,如文献 [6,8]等提出了多种容错算法,但这些算法仍然基于低可靠性故障检测器。Chen等人在文献 [9]中首先提出了一组指标来定量描述故障检测器服务质量。这些指标包括:实际故障检测速度及虚假检测率,然后提出了多种基于网络系统概率行为的故障检测器实施方案。这些方案利用最新采样得到的到达时间来估计下一心跳的到达时间。然而,基于这一估计设置的超时及恒定安全范围,与动态网络行为并不十分匹配。为了提升故障检测器的服务质量,文献 [9-11]提出了多种自适应故障检测器,包括Chen FD[9],Bertier FD[10]及φFD[11]。Bertier在文献 [12]中提出对Chen的FD 安全范围进行优化。它使用了另一种估计函数,融合了Chen和Jacobson的往返时间 (RTT)估计。Bertier的故障检测器设计的主要目的是用于消息很少丢失的有线局域网。
虽然以上故障检测器均取得了重大的技术突破,但是仍然具有一定的局限性。这主要有3个方面的原因:①故障检测器提供一个信息列表,表明哪些进程被怀疑崩溃。由于消息延时的高不可预测性、网络系统拓扑结构的动态变化性及网络消息的丢失概率较高,该消息列表并不是最新列表,有时还会存在错误 (比如,故障检测器可能会对实际上正常的进程产生怀疑)。②传统的二元交互 (即信任与怀疑)难以满足多个分布式应用同时运行的需求。实际上,多种分布式网络应用要求使用不同类型的故障检测服务质量,以触发不同的响应。③虽然用户知道了算法的内核函数和参数后,可以根据服务质量的输出来确定合适的参数值,进而满足用户的服务质量要求(QoS),但是绝大多数当前算法面对动态网络条件,无法实现参数的自动调整。该参数调整过程非常复杂,最好由专业工程人员完成。更重要的是,网络具有动态性和不可预测性,我们无法使用固定的故障检测器参数来满足用户需求。总体来说,当前故障检测器参数调整必须手工完成,非常不适合于动态网络,尤其是大型分布式网络和不稳定性网络 (这里指网络的消息时延具有很强的不可预测性,系统拓扑结构具有很强的动态变化性,且消息丢失概率较大)。因此,我们对故障检测器特性及其与分布式容错系统的相互关系展开进一步研究。
为解决上述问题,本文首先提出了一种通用的云计算容错网络自适应故障检测算法。该算法可以广泛用于工业和商业领域。相反,其他算法在提供服务质量输出方面缺乏针对性:一些算法只能暂时地满足要求;其他算法可能根本不满足要求,工程人员不得不手工更改相关参数。这些算法必须要尝试所有可能的参数值,通过获得性能输出曲线图才能确定哪些参数适合网络需要 (手工选择相关参数)。如果网络的变化较大,工程人员必须得再次手工调整参数。第二,我们基于上述通用算法,对当前故障检测器进行优化,提出了一种自适应累积型故障检测器 (累积型故障检测器是指检测器服务的输出是连续的怀疑水平数值,而不是二进制数值 (信任VS怀疑)。第三,我们对SFD 的部署展开研究。SFD 的工作流程简述如下:与传统的自适应型故障检测器[9,10]类似,一个滑动窗口维持着最近到达的时间样本。基于滑动窗口和输出反馈信息,对下一样本的下一超时时延τ的近似进行调整。获得该动态反馈信息后,计算相关参数,以匹配最新网络条件。从设计角度说,SFD 调整后可以较好地应对不可预测的网络条件及同时运行的任意数量应用程序要求。最后,我们基于7种典型的广域网案例,通过广泛的实验,比较性评估了本文故障检测 算 法 与 当 前 其 他 算 法 的 性 能 (Chen FD[9],Bertier FD[10,12],φFD[11])。实验 结 果 在 表 明 不 同 故 障 器 特 点 的 同时,证明了本文算法可以实现参数的自动调整,进而获得相应的服务质量,满足用户需求,享受较高的系统性能。本文提出的SFD 可以广泛应用于工业和商业领域,并为云网络带来巨大效益。
2 系统模型和基本概念
本节首先给出实际中的云计算网络模型 (如图1所示)及理论上的云计算网络分析模型 (如图2所示),然后定义故障检测服务质量指标。
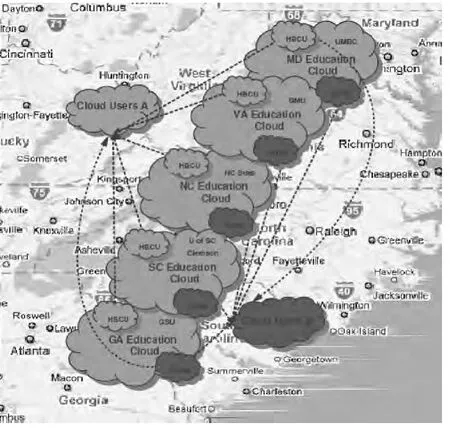
图1 云计算动态网络模型:美国南部各州教育云联盟
2.1 实际中的云计算网络模型
如图1 所示,本文对动态云计算网络模型展开研究(请注意,通用模型可以包括多个云)。该模型以美国南部多个州的教育云联盟及数据中心网络架构为基础[7]。当前,5个南部州 (佐治亚州 (GA),南卡罗来纳州 (SC),北卡罗莱纳州 (NC),弗吉尼亚州 (VA),马里兰 (MD))均有教育云建设项目正在进行,图1是一种很具现实代表性的云计算网络模型,其中,云计算网络服务器的状态可能会发生变化:有些服务器非常活跃,有些服务器非常忙碌,有些服务器非常迟钝,有些可能已经死亡或者崩溃。因此,当我们从服务器希望得到的服务发生故障时,必须要有云故障检测模型才能对故障进行处理,也只有云故障检测模型才能触发相应的措施来确保适当的服务响应。当前的故障检测算法[9,12],虽然可以提供一定的检测服务,但是其系统参数无法针对不断变化的网络条件实现自动调整。所以,本文提出一种通用型自适应算法来解决上述问题。
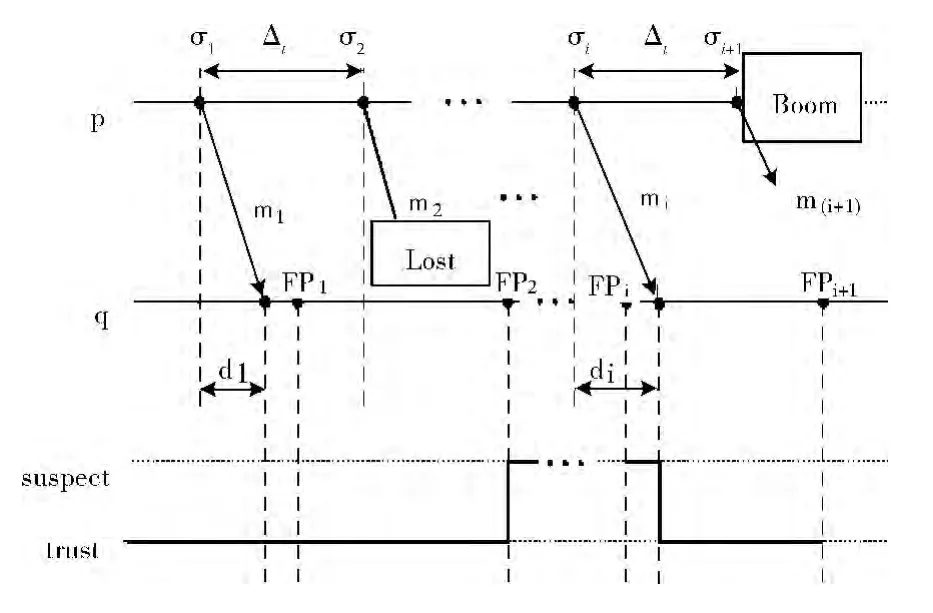
图2 心跳故障检测基本模型
2.2 云计算网络理论模型
本文考虑一种部分同步的云计算网络系统。该系统由进程有限集Π = {p1,p2,p3,...,pn}构成 (该模型基于上述图1中的IBM 云计算网络:一个用户、一个管理员、或者整个教育云被视为一个进程)。进程可能发生崩溃故障,本文中假设崩溃进程不会恢复。假设每一对进程通过一个单向低可靠性通信信道相连。低可靠性通信信道定义如下:无消息生成,无消息变更,无消息复制,但是有可能发生消息丢失。进程完全通过单向通信信道连接。不失一般性,本文只考虑带有2 个进程p,q 的系统模型 (与文献 [9-12]相同),这2个进程从大型系统Π 中随机提取,且进程q监控进程p(如图2所示):p 周期性地向q 发送一条消息,进行本地计算,也有可能发生崩溃故障 (根据图1中的理论云模型,进程q像一个管理员,而进程p 像一个教育云。由监控结果给出每个教育云计算环境)。此时,发送周期称为心跳间隔Δt。进程q可能从p 处接收一条消息,或者执行本地计算。如果在新点 (fresh point,FP)确定的周期内没有从p 处接收到消息,则q将开始怀疑p。新点FP由超时参数τ确定。
如图2所示,di为从p 到q 的心跳mi的发射时延,且发送周期称为心跳间隔Δt。对即将到来的心跳mi,进程q定期根据新的新点FPi做出响应。该模型描述了可能出现的4种情形。第1种情形:进程p 在发送时间σ1发送的心跳消息m1,在q的新FP1前到达q,然后q从m1的到达时间开始信任p(这里我们假设p 在开始情况下就被信任)。第2种情形:来自p 的消息m2被丢失,然后q等待心跳直到它的新点FP2为止,此时q 开始怀疑p。第3 种情形:来自p 的心跳mi在q 的新点FPi之后到达q,然后q 从FPi至mi到达期间怀疑p。第4种情形:p 发出心跳m(i+1)后便发生崩溃。对即将到来的心跳m(i+1),q 根据不同的故障检测方案计算新的新点FPi+1,然后基于心跳到达时间给出响应。
本文SFD 算法假设存在全局时间 (对进程未知),且用全局稳定时间表示,同时进程不断向前发展。此外,相邻步骤间至少存在δ>0个时间单元 (后者目的是为了排除进程在有限时间内执行无限次步骤这一情况)[11]。进程间通信模型以基于用户数据报通信协议 (UDP)的消息交换为基础。我们没有考虑进程的相对速度。然而,我们认为进程可以访问用于测量时间的本地时钟设备。此外,所有进程均可访问故障检测设备。
2.3 故障检测服务质量指标
为了定量评估故障检测器的服务质量,我们使用相互独立的3大服务质量指标:检测时间,差错率,查询精度概率。第1个指标描述故障检测器的速度对模型的影响,另外2个指标均与精度有关。详细来说,考虑2个进程p,q且q监控p,故障检测器对q 的服务质量 (称为fdq)可通过它对p的 “信任”和 “怀疑”2种状态的转换时间来确定 (如图3所示,TM(错误时长)测量了错误怀疑开始至结束的持续时间 (即直到错误被纠正)。TMR(错误复发时间)测量2个连续错误间的时间,它是个表示某次错误怀疑至下一次错误怀疑间持续时间的随机变量)。
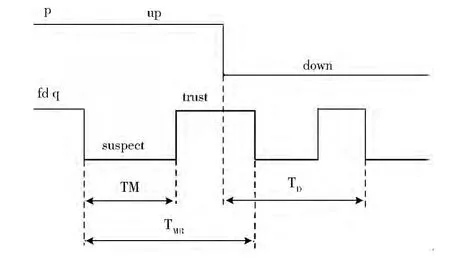
图3 故障检测器服务质量评估基本指标
检测时间 (TD):它是个随机变量,表示进程p 开始崩溃到进程q 基于fdq持续怀疑p 的开始时间之间的间隔。
差错率(MR):它是个随机变量,表示故障检测器在单位时间内发生的错误次数,即它表示故障检测器发生差错的频率。
查询精度概率(QAP):该概率表示在随机时刻被询问时,q处的故障检测器正确判断进程p 为正常进程的概率。
故障检测服务质量定义。根据文献 [13],故障检测器的具体性能主要从它的完整性和准确性角度进行定义,每个故障检测构成模块提供的服务质量刚好是一个多元组

服务质量既可以定量描述一个检测器的故障检测速度,也可以定量描述避免错误检测方面的性能。
3 通用型自适应故障检测器
首先针对云计算容错网络的工程可用性,提出一种通用型自适应故障检测器;然后作为一个示例,对当前故障检测器进行优化,提出SFD 检测器;最后对SFD 的部署做详细描述。
3.1 通用型自适应故障检测器算法
根据图2的系统模型,用户p 希望进程q 的故障检测器能够以一定的服务质量要求检测出p。此外,进程q 的SFD 可以自动调整参数,以满足QoS 要求。图4中,我们给出了SFD 的反馈架构,其中QoS 是心跳的目标服务质量。初始服务质量要求 (TD,MR,QAP )及QoS 已知并发送给SFD,网络行为 (例如心跳信息:到达时间,心跳发送到达间隔时间Δt)也发送给SFD。通过融合来自输出的反馈信息,SFD 可以实现参数的自适应调整,以满足目标要求。
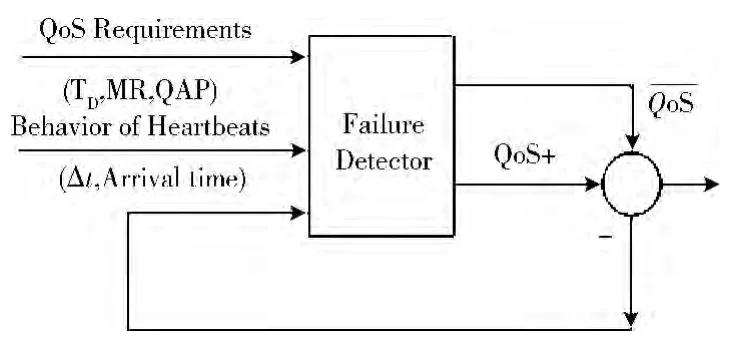
图4 目标输出为MR 和TD 的自适应故障检测器反馈结构
如果SFD 的输出服务质量没有达到QoS 要求 (例如,我们可以将其定义为QoS >),则将反馈信息(QoS-)返回给SFD。根据反馈信息,SFD 可以调整参数 (例如基于超时算法的超时参数τ)。然后,SFD 将最终满足要求 (如果该SFD 有一定范围且SFD 可以满足)。否则,如果太高,且该SFD 无法为其确定合适的参数,则SFD 将发出如下响应: “本SFD 无法满足该应用的要求”。
更详细地讲,如果我们重点讨论服务质量3 大参数:TD,MR,QAP (基于一个周期的实验而不仅是一个时隙期间的性能参数),则SFD 的服务质量输出基于以前所有的时间周期。图5中,我们给出了自适应故障检测的参数关系,其中目标和值应该小于MR 和TD的要求值,值要大于QAP 的要求值。
实际上,我们在某一时隙内,SFD 参数只根据反馈信息调整一次,以改进SFD 的服务质量输出,更接近于QoS。我们经常需要在多个时隙内多次调整SFD 参数,以逐步改进输出的服务质量,并最终确定能够满足的合适参数。此时,SFD 将使其参数及云通信网络系统趋于稳定。如果系统发生较大变化且对应的服务质量输出没有满足要求,则SFD 将会给出反馈信息,以逐步改进SFD的服务质量输出,直到其满足要求为止。这里我们假设实验时间很长,足以SFD 的服务质量输出满足应用的要求,同时假设当前已经存在可用且合适的控制参数。该方法是通用型方法,可用于其他基于超时的自适应故障检测器。总体来说,我们应该首先根据传统的检测算法[9]得到服务质量输出 (TD,MR,QAP ),然后获得反馈信息,进而对SFD 相关参数进行调整。

图5 自适应故障检测器参数关系,QoS 为心跳希望实现的目标服务质量
3.2 自适应故障检测器
本节提出了一种具体的SFD 检测器,并以对当前故障检测器的优化为例展开讨论。SFD 根据反馈信息调整可预测的下一新点τ(k+1)。因此,我们有
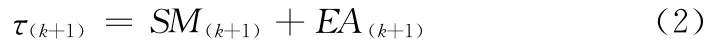
式中:EA(k+1)与Chen-FD 的参数相同,SM 为动态安全范围,可根据预先确定的进行调整。我们有
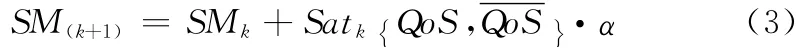
式中:α(α∈(0 ,1))与Chen-FD常值安全范围相同,我们有

式中:β——常数且β∈ (0 ,1) ,Satk{Qo S,QoS }根据具体的服务质量输出状态可被设置为β,-β或0。β值为调整速率,也可由用户动态选择。
根据式(2)~式(4),如果α值较大,则本文SFD 的TD将会变大,MR 变小,QAP 变大(因为较大的α值时安全范围也会变大)。本文算法在这一点上与Chen-FD 类似。为了选择Satk{Qo S},我们重点关注两方面:响应时间(TD)和检测准确性(MR,QAP)。我们应该在响应时间和检测准确性间做出折衷,以满足目标要求。例如,如果我们努力缩短响应时间,则会降低检测准确度,反之亦然。从理论角度说,SFD满足实际故障检测器的特点且属于 Ρac类型(累加特点和上限特点),这足以解决一致性问题。
3.3 SFD检测器的部署
本节首先介绍SFD 的架构,然后给出具体的部署算法。
(1)SFD 架构:SFD 的部署可以分解为3个基本部分:监测,解释,行动。传统的基于超时的故障检测器 (Chen FD[9]和Bertier FD[10,12])综合了监测和解释环节,输出二元信息。然而,SFD 检测器作为累加型检测器,抽象程度较低,避免了监测信息的解释环节。应用进程根据自身服务质量要求来设置怀疑水平阈值:阈值较低,则错误怀疑的数量上升,实际崩溃故障的检测速度更高。相反,阈值较高时,错误怀疑数量下降,实际崩溃故障的检测速度变低。
(2)SFD 部署:作为一种累加型故障检测器,SFD 使用的方法非常简单。一段预热期后,当新的心跳到达时,到达间隔时间加入采样滑动窗口,同时先前最久的时间被移除采样窗口。然后,使用采样窗口的到达时间计算到达间隔时间的分布,获得该滑动窗口的平均到达间隔时间Δt。此后,根据式 (2)~式 (4),计算当前超时值τ,确定下一新点 (如图2所示)。应用场合需要执行部分操作,或者通过比较τ值及其当前心跳到达时间来确定进程的怀疑水平 (如图2所示)。
当消息丢失时,我们无法计算发送方到接收方的通信时延(如图2第2种情况)。为了确保本文算法的有效性,并且考虑到消息丢失的影响,我们使用时间序列理论来填补这一空缺。填补的具体方法是通过计算di= (Δt ·)+di-1,且表示被观测的相邻空缺的平均数量。
算法1给出了SFD 部署的详细内容。算法中,我们首先设置部分初始参数,包括初始安全范围SM1。此后,SFD 可以获得反馈信息 (第2步):如果SM1为可以保证SFD满足服务质量输出要求的合适参数,则反馈信息为0,SFD 达到稳态。这意味着当前参数与网络系统相匹配。如果SM1无法保证SFD 满足服务质量输出要求且服务质量输出与控制规则相匹配,则根据服务质量输出的具体状态确定反馈信息为±β。如果SM1无法保证SFD 满足服务质量输出要求且服务质量输出与控制规则不匹配,SFD 对该错误做出响应 (所有可能值均不适合SM1)。最终,如果SFD 没有显示 “做出响应”,则SFD 调整SM 参数,直到其满足服务质量的预期输出为止。
算法1:参数调整算法
(1)开始
(2)初始化:
(4)MR :设置差错率;
(6)设置安全范围初始值SM1;
(7)设置常值参数α,β;
(8)第1步:获得相关数据
(9)获得服务质量输出 (TD,MR,QAP )。
(10)第2步:获得反馈信息
(11)如 果TD>,MR <,QAP >:Satk{Qo S}=β;
(12)如 果TD<,MR <,QAP >:Satk{Qo S};
(13)如 果TD<,MR >,QAP <:Satk{Qo S};
(14)否则 (例如,如果TD>TD,MR >MR):“做出响应”(该SFD 无法达到要求的服务质量),SFD 终止 (跳到第18行)。
(15)第3步:调整参数
(16)将Satk{Qo S}发送给SFD;
(17)根 据Satk{Qo S}调 整SFD 相关参数;
(18)结束
文献 [9]的Chen FD 为了满足服务质量的预期要求,必须要确定合理的初始安全范围参数值 (因为它无法实现参数的自动调整);否则,服务质量输出便无法满足要求 (用户要求)。文献 [11]的FD 及文献 [10,12]的Bertier FD 也存在同样的问题。这些问题均在本文SFD 中得以解决。
4 性能评估
为了证明本文通用型非人工分析方法的有效性,我们基于普通的实验环境,对SFD、FD[11]、Chen FD[9]、Bertier FD[10,12]进行了分析、比较和评估。实验环境均为通用型云计算网络典型环境,包括7 种WAN 案例,所有案例均是真实数据,其中一种从日本和瑞士获得,其他来自PlanetLab (如图1所示)。
本文实验基于图2 中的模型。一个进程 (p)周期性地发送心跳消息给另一个进程 (q),发送行为持续随机时间长度,另一个进程q从进程p 接收消息。每次实验中,心跳发送和到达时间记入监控计算机q 的日志文件。使用记录的到达时间来重现每个故障检测器算法的运行情况。这意味着,所有的故障检测器都在相同的实验条件下加以比较:同样的网络模型,同样的心跳流量,同样的网络参数 (发送间隔,滑动窗口大小,通信时延,输入,等等)。记录的发送时间只作为统计数据使用。所有的心跳消息均使用UDP/IP 协议。低频ping进程与实验同步运行,以获得往返时间粗略估计并保证网络的连通性。
实验中的每个故障检测器均使用滑动窗口来保存过去的样本,以计算下步估计。4 种故障检测器的所有实验均使用相同且固定大小的滑动窗口 (WS =1,000) 。因为网络在预热期间不够稳定,所以必须在滑动窗口装满后再对采样数据进行分析。实验中以100ms每个心跳的目标速度来生成心跳。
主要参数如下:为了获得最佳服务质量且与其他算法做比较,我们设置SFD 的SM1=α;对Chen FD,参数设置同文献 [9]:α∈ [0 ,10000] ;对FD,参数设置同文献[11]:Φ ∈ [0. 5,16] ;对Bertier FD,参 数 设 置 同 文 献[10,12]:β=1,=4,γ=0.1。故障检测器在每次实验中的其他基本参数设置相同。
这些实验中,丢弃掉部分初始周期后,我们针对整个运行情况测量了如下3 个服务质量主要指标:TD,MR,QAP 。基于参数的故障检测器,其参数设置不同,检测器行为也会完全不同,所以对这些检测器进行比较的难度很大。经常犯的普遍错误是对参数随机赋值,然后根据它们的检测时间及精度测量值对2种基于参数的故障检测器进行比较。这往往会得出一种检测器检测时间更短而另一种检测器的检测精度更高的错误结论。
相反,我们在进行FD 实验时使用了另外一种方法。该方法的主要思路基于如下问题:给定一组服务质量要求,能否确定合适的故障检测器参数使其满足这些要求?为回答这一问题,我们考虑以检测时间和准确度指标 (或MR,QAP )为轴的服务质量空间。然后,我们从行为高度激进转变为行为非常保守 (即TD越来越大,此时图中的每个点都对应于该检测器的一个参数。当我们依次选择参数时,比如从小值逐步变为大值,便可以得到许多点,并可用一条连续的曲线对这些点进行拟合),改变检测器的参数,进而测量检测器的覆盖面积。故障检测器覆盖的面积便是可能与该故障检测器相匹配的一组服务质量要求相对应的面积。每次实验中,不同的输出值 (MR,QAP,TD)根据以下参数获得:对SFD,给定初始安全范围SM1列表,包括α,β在内的其他参数未被列出,因为它们只会影响参数自适应调整的速率;对Chen FD,给定初始安全范围列表;对FD,给定阈值参数Φ 列表。我们发现,当参数依次连续变化时 (例如,从小到大),图形也会不断发展,我们可以获得足够多的点在该曲线图上拟合。
4.1 WAN 实验
本实验包括两台计算机:一台在瑞士联邦理工学院洛桑分校 (EPFL),另一台在日本的JAIST。两台计算机通过正常的洲际互联网连接通信。实验中使用的跟踪文件与FD[11]完全相同,这也为共同评估SFD、Chen FD、Bertier FD 和FD 性能打下了基础。
(1)实验设置:硬件/软件/网络:详细来讲,基于以下实验设置获得跟踪文件及相关数据。
心跳采样:一周之内结束实验 (从4 月3 日2:56 UTC开始,到4月10日3:01UTC结束)。实验期间真实测得的发送速率为每103.501 ms 一次心跳 (标准差:0.189 ms;最小值:101.674 ms;最大值:234.341 ms)。此外,总共发送5,845,713条心跳信息,被接收5,822,521条,消息丢失率约为0.399%。详细检测跟踪文件后,发现消息丢失主要原因是814个脉冲串。大部分脉冲串持续时间较短,最长脉冲串为1093个心跳 (只有1 个),持续约2分钟。另外,大部分心跳不是直接从亚洲发往欧洲,而是经由美国发往。
往返时间:往返时间平均值为283.338ms,标准差27.342 ms,最小值270.201ms,最大值717.832ms。通过分析跟踪文件,我们确定了发送主机和接收主机的CPU 平均负载率分别为1/67和1/22,因此它们低于计算机的总容量。
(2)实验结果:TD,MR,QAP 的实验结果见图6、图7。图6给出了各检测器的MR 比较结果,其中纵坐标为对数标度。最优值位于左下角,意味着该检测器的检测时间更短、差错率更低。图7给出了检测器的QAP 比较结果,纵坐标为线性标度。最优值位于左上角,意味着该检测器的检测时间更短、QAP 更高。

图6 WAN 的差错率VS检测时间

图7 WAN 的查询精度概率VS检测时间
图6中,当TD<0.3s时,Chen FD 和FD 的MR 和TD类似。当0.3s<TD<0.9s时,SFD 和Chen FD 的结果类似,略优于FD。当TD>0.9s时,Chen FD 的TD相同,但MR 最低。对SFD,在过于激进 (TD<0.3s) 和过于保守的区域 (TD>0.9s) 均没有数据存在,原因是SFD 可以自动调整参数。
开始时,初始安全范围SM1的值很小,于是本SFD 的服务质 量输出的检 测时间较短TD(TD<)、差 错 率MR (MR >)较大。这表明,服务质量输出没有满足QoS 要求,我们可以采取多种步骤来增加SM ,以降低MR。于是,本文算法对后续多个新点τ增加了SM 值,以降低服务质量输出的MR 。最终,我们满足了该应用场合要求的。
下一SM1值略大于上次值 (本文SFD 实验中,SM1从可能值列表中逐渐增加)。开始时,SFD 的MR 值低于上次值 (SM1值较小),但仍大于MR 。于是,本文算法多次增加SM ,以逐渐降低输出质量的MR 值,并最终使服务质量输出满足要求。所以,对于服务质量整体输出,SM1越大,则TD越大,MR 越小,QAP 越大。但这也不是绝对的,因为SFD 可以自动调整SM ,以满足要求。
有趣的是,本WAN 环境中存在一些脉冲串。因此对每个SM1值,SFD 的服务质量输出经调整满足要求后,由于存在脉冲串,SFD 的服务质量输出存在一些波动。
对本文SFDTD>0.9s时的SM1值,本文算法可以降低下一新点τ的SM 值,虽然轻微增加了MR ,但可逐渐降低TD。如果SFD 的第1个输出TD大于0.9s(因为SM1非常大),我们可以通过更多的步骤来降低SM 和TD,最终实现TD<TD。此时,就整体性能而言,输出MR 变大,TD变小。可以得出,对TD>0.9s时的SM1值,当SFD的SM1增加时,TD变大,MR 变小。因为舍入误差使图形无法演变为非常保守的情况,所以FD的图形终止时间很早(2.43s)。Bertier FD 没有动态参数,所以只有一个点。其他实验环境下的状态相同。图7结果与图6类似。
4.2 全面的PlanetLab WAN 实验
我们已经在大量实验中分析了SFD 检测器的部署行为。这里我们重点讨论相关性最强的WAN 环境,以进行全面的实验分析。本文实验的主要目的是观察SFD 为与QoS 实现匹配进行自我调节的性能状况。此时,我们将其与Chen-FD、Bertier-FD、-FD进行比较。我们首先描述各种WAN 环境,然后基于适当的方法对SFD 与当前其他检测器做比较,最后对获得的相关结果展开讨论。
(1)实验设置:下面描述实验环境,相应的统计数据见表1和表2。这里基于PlanetLab (http://www.planetlab.org/)做了6种典型的WAN 实验,使用的结点位于美国、欧洲 (德国)、日本、中国 (香港)。每个地点与其他3个地点进行通信 (如图8和表1、表2所示)。地点和主机名总结于表1。设置每个WAN 实验持续约24小时,目标心跳间隔设为10ms。
图8 PlanetLab广域网主机

表1 WAN 实验概览

表2 实验概览:统计数据
实验1 (WAN-1):地点从美国斯坦福大学至日本奈良科技研究所,时间从2013 年3 月12 日开始。心跳有效间隔为12.825ms,总共发送了6,737,054个心跳。心跳平均到达时间为12.83 ms (时针漂移比较轻微),标准差14.892ms,平均往返时间为193.909ms。
实验2 (WAN-2):地点从德国至美国,时间从2013年3月8日开始。总共发送了7,477,304 个心跳,丢失率为5%。
实验3 (WAN-3):地点从日本至德国,从2013 年3月6 日开始。总共发送了7,104,446 个心跳,丢失率为2%。
实验4 (WAN-4):地点从香港 (中国)至美国,时间从2013年3月10 日开始。总共发送了7,028,178 个心跳,丢失率为0%。
实验5 (WAN-5):地点从香港 (中国)至德国,时间从2013年3月11 日开始。总共发送了7,008,170 个心跳,丢失率为4%。
实验6 (WAN-6):地点从香港科技大学至日本庆应义塾大学湘南藤泽校区Mural实验室。总共发送了7,040,560个心跳,丢失率为0%。
最后需要指出的是,ping进程与实验同步运行,以获得ping命令日志文件。这些文件证明了实验期间,网络连通性始终良好。
(2)实验结果与讨论。各检测器在不同实验设置下的观测结果类似。PlanetLab中WAN-2 至WAN-6 的实验结果与WAN-1类似。由于篇幅所限,我们在图9和图10中给出WAN-1的实验结果。

图9 WAN1:MR VS TD
我们从美国至日本WAN-1实验中获得实验结果 (如图9、图10所示)。Bertier FD 没有动态参数,所以它为只有一个点的激进型故障检测器。Chen FD 为保守型检测器,最终MR 值为0。对FD,舍入误差的存在使得我们无法计算保守范围内的点,FD 的曲线终止时TD为1.58s,MR 为0.002,QAP 为99.8%。3种方案的起始点类似,但没有一个方案可以根据网络动态变化来自动调节参数。很显然,这一问题在SFD 中得到解决。

图10 WAN1:QAP VS TD
SFD 曲线持续时间为0.10s至0.87s。它的起始点为TD0.10s,MR0.31,QAP99.5%。SFD 曲线逐渐变化后的点为TD0.87s,MR0.00041,QAP99.8%,参数SM1有所上升。此后,当初始安全范围再次上升时,Chen FD 服务质量输出的TD变长,而SFD 没有。SFD 发现该输出的TD大于要求水平后,自动调整其他参数 (设置Satk{Qo S}=-β以降 低SM ),降 低TD,但 这 同 时也导致MR 有所上升。在此调整期间,SFD 不断地调整参数Satk{Qo S,QoS }=-β,以 逐渐降低输出的TD值。最后,输出TD实现TD<,输出MR 和QAP 也达到预期水 平 (MR <MR ,QAP >QAP )。SM1上升后,SFD 图逐渐演变后的点为TD0.10s,MR0.31,QAP99.5%,与初始点非常接近。
SFD 对FD、Bertier FD、Chen FD 的优化非常大:虽然SFD 的性能有时低于其他检测器 (例如,当DT低于0.2 s时,FD 的MR 要低于SFD),但是只有SFD 可以根据自动调整参数。具体地,当初始安全范围SM1上升时,SFD 始 终 可 以 自 动 调 整Satk{Qo S},确 定 合 适 的SM ,以便根据用户需求获得满意的服务质量输出。相反,其他方案的服务质量输出缺乏针对性:部分检测器只是暂时地与要求相匹配,部分检测器与要求始终不匹配,以致工程人员必须要手工调整相关参数。这些方案必须要尝试参数所有可能取值,获得性能输出曲线,才能知道哪些参数取值适合网络条件 (手工方式选择相关参数)。如果网络发生重大变化,工程人员必须要再次手工调整相关参数。总体来说,SFD 可以自我调整,可广泛应用于工商业云计算环境。
参数设置不同,结果也会不同,所以参数设置对所有检测器来说都具有重要作用。对定量分析,当参数以固定次序连续变化时 (比如从较小值变为较大值),大部分情况下的图形也会连续单调变化 (异常情况的可能原因是部分突发数据和陈旧数据影响了服务质量输出)。各个参数是独立的,所以参数变化和结果变化间没有定量关系。
综上所述,我们基于多个WAN 环境评估了SFD 性能(如图8所示)。实验结果已经表明,相比当前其他最新故障检测器,SFD 可以自动调整参数,在一般网络环境下性能优异。
4.3 4种检测器的比较性分析
以上实验已经覆盖了当前所能发现的大多数典型应用环境。基于以上实验,我们得出以下结论:
自适应特性:实验结果表明,在自适应能力方面,SFD 优于其他当前检测器 (FD,Bertier FD,Chen FD)。具体地,对云计算网络,当初始安全范围SM1上升时,SFD 总 是 可 以 自 动 调 整Satk{Qo S},确 定 合 适 的SM ,以根据用户需求得到满意的服务质量输出。相反,其他检测器的服务质量输出缺乏针对性。如果网络发生重大变化,工程人员必须再次手工调整参数。
窗口大小的影响:我们将分析窗口大小对检测器服务质量的影响。对FD,窗口越大,性能越优。可能原因是历史信息对FD 获得较高的服务质量具有重要作用。FD 基于正态分布函数,所以窗口越大,历史数据越多,计算出来的正态分布函数对相关网络案例的适应性更强。对Bertier FD,窗口大小对其服务质量的影响基本可以忽略。可能原因是,Bertier FD 没有需要调整的参数。对Bertier FD 和SFD,窗口越小,性能越优。当窗口变大时,Chen FD 和SFD 获得的历史数据更多,大量突发数据和陈旧数据可能会影响服务质量的输出,对性能的贡献有限 (甚至会影响性能)。窗口变小后,Chen FD 和SFD 对网络的适应时间变短。总体来说,SFD 是具有实用价值的自适应故障检测器,可有效用于工商业领域,自动满足用户服务质量需求。此外,SFD的拓展性非常强,即使窗口较小也可获得优异性能,节约了非常珍贵的存储资源。所有证据均证明了本文通用型自适应故障检测器SFD 的有效性。
5 结束语
本文对实际中的自动容错云计算网络,就故障检测器特性展开研究,提出了一种可以满足用户需求的通用型相关参数非人工自适应调整算法。以该通用型自动算法为基础,我们又提出了一种具体的动态自适应故障检测器SFD,可看成是当前算法的一个重大突破。基于实际而又广泛的仿真实验,比较了SFD 相对其他当前检测器的服务性能质量。实验结果表明,本文算法可以自动调整SFD 控制参数,获得相应的服务水平,满足用户需求。性能表现良好。该SFD 算法可以广泛应用于工商业领域,并可为云计算网络带来巨大效益。本文SFD 基于并行理论还可应用于 “单监视器”(one monitors multiple)和 “多监视器”(multiple monitor multiple)领域。我们下一步工作的重点是研究内容云计算系统中基于最小化延迟的数据传输方案。
[1]DENG Wei,LIU Fangming,JIN Hai.Leveraging renewable energy in cloud computing datacenters:state of the art and future research [J].Chinese Journal of Computers,2013,36(3):582-598 (in Chinese).[邓维,刘方明,金海.云计算数据中心的新能源应用:研究现状与趋势 [J].计算机学报,2013,36 (3):582-598.]
[2]WANG Yijie,SUN Weidong,ZHOU Song.Key technologies of distributed storage for cloud computing [J].Journal of Software,2012,23 (4):962-986 (in Chinese). [王意洁,孙伟东,周松.云计算环境下的分布存储关键技术 [J].软件学报,2012,23 (4):962-986.]
[3]LIN Guoyuan,HE Shan,HUANG Hao.Access control security model based on behavior in cloud computing environment[J].Journal on Communications,2012,23 (3):59-66 (in Chinese).[林果园,贺珊,黄皓.基于行为的云计算访问控制安全模型 [J].通信学报,2012,33 (3):59-66.]
[4]Silveira F,Diot C,Taft N,et al.ASTUTE:Detecting a different class of traffic anomalies[J].ACM SIGCOMM Computer Communication Review,2010,40 (4):267-278.
[5]Stefanakos S.Reliable routings in networks with generalized link failure events [J].IEEE/ACM Transactions on Networking,2008,16 (6):1331-1339.
[6]Takeuchi K,Tanaka T,Yano T.Asymptotic analysis of general multiuser detectors in MIMO DS-CDMA channels [J].IEEE Journal on Selected Areas in Communications,2008,26(3):486-496.
[7]Park SH,Lee JY,Yu SC.Non-blocking atomic commitment algorithm in asynchronous distributed systems with unreliable failure detectors[C]//Tenth International Conference on Information Technology:New Generations.IEEE,2013:33-38.
[8]Leonard D,Yao Z,Rai V,et al.On lifetime-based node failure and stochastic resilience of decentralized peer-to-peer networks[J].IEEE/ACM Transactions on Networking,2007,15 (3):644-656.
[9]Chen W,Toueg S,Aguilera MK.On the quality of service of failure detectors [J].IEEE Transactions on Computers,2002,51 (5):561-580.
[10]Bertier M,Marin O,Sens P.Implementation and performance evaluation of an adaptable failure detector[C]//Proceedings of the International Conference on Dependable Systems and Networks,2002:354-363.
[11]Défago X,Urbán P,Hayashibara N,et al.Definition and specification of accrual failure detectors[C]//Proceedings International Conference on Dependable Systems and Networks.IEEE,2005:206-215.
[12]Bertier M,Marin O,Sens P.Performance analysis of a hierarchical failure detector[C]//DSN,2003:635-644.
[13]Jacobson V.Congestion avoidance and control [J].ACM SIGCOMM Computer Communication Review,1988,18(4):314-329.
猜你喜欢
中国外汇(2019年20期)2019-11-25
收藏界(2019年2期)2019-10-12
中国外汇(2019年8期)2019-07-13
电子制作(2018年18期)2018-11-14
火力与指挥控制(2018年10期)2018-11-13
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
工业设计(2016年11期)2016-04-16
学习月刊(2015年6期)2015-07-09
学习月刊(2015年14期)2015-07-09
