
基于稀疏邻域的特征融合算法及其应用
2014-12-02 01:11杨沁梅
计算机工程 2014年8期
臧 飞,杨沁梅
(中国电子科技集团公司第二十八研究所,南京 210007)
1 概述
基于特征融合的目标识别算法是从不同目标中抽取反映目标本质属性的特征信息,并将不同的目标特征信息依据某种准则或应用背景进行合理组合,以便对不同目标类型进行识别估计。在传统的识别应用领域,基于特征融合的目标识别算法可以有效抽取不同类型数据的几何本质特征[1],从而对不同图像进行正确识别;在现代军事应用中,基于特征融合的目标识别算法是威胁估计和态势分析的前提,可用以获得准确可靠的目标类型估计[2]。
在融合目标识别算法中,基于图的学习方法在近几年得到长足发展,尤其以KNN 最近邻方法为代表。KNN 的优势在于可较容易地计算出两点间的欧几里得距离,如在局部保持投影算法[3-4]中,采用高斯核度量样本间的相似性;在局部线性嵌入[5-6]算法中,以最小化局部线性重构误差为代价。KNN 的不足之处在于实际应用中邻域参数难以确定以及受噪声的影响较大,且这种学习方式中图的结构与图中边的权数未建立必然的联系。
近年来,基于稀疏表示的分类算法与融合算法在各领域得到快速的发展。作为一种新型的监督分类方法,稀疏表示分类(Sparse Representation-based Classification,SRC)[7]能有效处理图像中的遮挡等问题;基于稀疏表征的单样本识别方法[8]通过Shift 或主成份分析(Principal Component Analysis,PCA)重构方法产生冗余样本,在将生成的新样本作为测试样本的基础上利用SRC 进行目标识别;基于PCA 特征基压缩传感算法[9]利用双向二维主成份分析提取的特征作为后续融合分类的超完备基,以最小残差为准则对测试图像进行目标识别;稀疏保持判别融合算法(Sparsity Preserving Discriminant Analysis,SPDA)[10]用训练样本的稀疏重构关系代替传统最近邻关系,实现数据的稀疏重构关系的保持;稀疏保持典型相关分析融合算法(Sparsity Preserving Canonical Correlation Analysis,SPCCA)[11]在典型相关方法的基础上引入稀疏保持项,实现2 组特征判别信息的有效融合。
在SRC、SPDA 等算法中,关键是采用了样本的稀疏表示,即在不同方法的学习过程中,均采用相同的方式构造了稀疏图[12-13]。在这种构图方式中,图的结构和相应边的权数通过求解l1范数同时得到,建立了两者间的直接联系。在稀疏表示自身具有的判别属性条件下,稀疏图比KNN 图反映了更多的样本间相似关系。对于某个被表示样本,余下所有训练样本或测试样本均对该样本起到表示作用,但表示系数较大的样本所起作用较大,且系数较大的样本与被表示样本具有相同的类别属性。因此,为了充分利用具有较大表示系数的样本,削弱具有较小表示系数样本的作用,本文为每个被表示样本定义了稀疏邻域,并通过该稀疏邻域构造基于图的学习方法。
此外,基于单一数据特征的融合识别算法在良好限制条件下可以取得较好的实验结果,但在图像融合、态势威胁估计等目标识别应用中,基于单一数据特征的融合识别算法往往会受到各种不利因素的干扰,造成算法或系统的融合性能与识别结果的下降。为此,本文提出基于稀疏邻域的特征融合算法(Sparisity Preserving Discriminant Analysis Based on Sparse Neighborhood,SNSPDA)。该融合算法在保持传统融合识别方法中数据本质几何结构的同时,有效利用了训练样本的稀疏重构关系,使其既可以反映少量标签样本的类信息,又能捕获大量无标签样本的自然属性。
2 特征融合算法
在本文中,特征融合算法的目的是从少量标签样本和大量无标签样本中抽取出适用于识别、聚类等不同应用的融合特征。在图像特征融合识别应用中,标签样本的个数远远地少于样本自身的冗余维数,为此,典型的特征融合方法如半监督判别融合算法(Semi-supervised Discriminant Analysis,SDA)[14]和稀疏保持判别融合算法(SPDA)[6]等,均采用正则化技术解决算法中遇到的奇异性问题。
给定具有c 类的样本集合X=[x1,x2,…,xn]∈Rm×n,这里假设样本集X 中包含l 个标签样本与u 个无标签样本(n=l+u,l≪u)。以识别为任务的特征融合算法的目的是将同类样本聚合而不同类样本分离。由于标签样本个数较少,在这类特征融合算法中过拟合现象时有发生。为消除这种过拟合现象,典型的方法是在不同的特征融合算法增加不同的正则项。因此,这类特征融合算法具有下列形式:
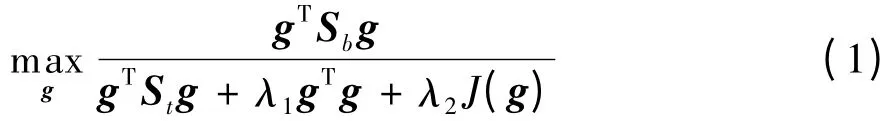
Sb与St分别表示标签样本集的类间散度与总体散度:
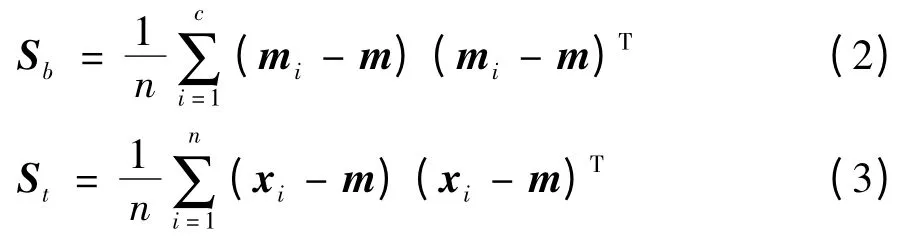
其中,mi与m 分别表示第i 类样本和所有样本的均值;gTg 表示Tikhonov 正则项;J(g)为不同特征融合算法中加入先验知识提供可能;正则参数λ1与λ2均大于0。
2.1 SDA 算法
在半监督判别融合算法[8]中,通过增加光滑约束来最大限度地利用标签样本与无标签样本的信息。这种基于拉普拉斯图正则约束的目的是增强相邻样本点间的相似性。因此,SDA 算法中的正则项为:
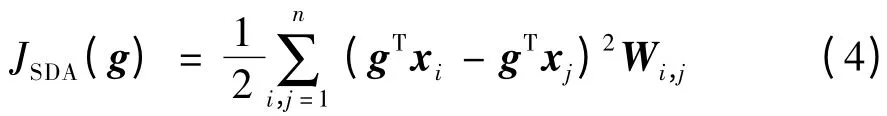
其中,Wi,j表示样本xi与样本xj的高斯相似性。
2.2 SPDA 算法
与SDA 算法不同,稀疏投影判别分析融合算法[6]在保持标签样本判别信息的同时利用稀疏表示的自然属性。因此,SPDA 算法中的正则项为:
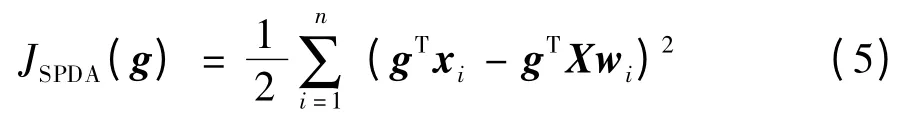
其中,wi表示样本集Xi=[x1,x2,…,xi-1,xi+1,…,xn]对样本xi的稀疏重构系数。
尽管SDA 与SPDA 都考虑了大量无标签样本的作用,但在SDA 算法中仅利用了所有样本的邻域关系,SPDA 算法中只考虑了所有样本间的稀疏关系。本文提出的基于稀疏邻域的特征融合算法,在保持样本间稀疏重构关系的同时,刻画了样本间的本质几何结构,究其原因在于SNSPDA 算法采用了文中给出的稀疏邻域。这使SNSPDA 在特征融合中可比SDA,SPDA 取得更好的实验结果。
3 基于稀疏邻域的特征融合算法
3.1 稀疏邻域
为保持数据的本质几何结构与样本间的稀疏重构关系,本文首先给出样本间稀疏邻域的概念。
对于给定的参数ε >0,样本xi的稀疏邻域定义如下:在稀疏重构过程中,如果样本xj(j≠i)的稀疏表示系数αj满足条件αj>ε,则称样本xj(j≠i)在样本xi的稀疏邻域内,记为xj∈SN(xi)。
由稀疏邻域的概念可以看出,对于给定的样本,稀疏邻域移除了对给定样本重构贡献较小的样本,保留了具有较大重构系数的样本,其原因在于较大重构系数的样本与被表示样本具有很强的判别属性,同时为具有较大重构系数样本对被表示样本的再次重构提供可能,本文4.1 节给出了稀疏邻域作用的详细描述与实验对比。
3.2 SNSPDA 算法
基于稀疏邻域特征融合算法的核心思想为:对于每个训练样本,在选择其稀疏邻域的基础上,构造稀疏邻域样本集对训练样本的稀疏重构关系,并由此在兼顾数据本质几何结构的同时考虑样本间的稀疏重构关系。
SNSPDA 算法的具体步骤如下:
(1)给定具有c 类的样本集X=[x1,x2,…,xn]∈Rm×n,其包含l 个标签样本与u 个无标签样本,平衡参数为λ1,λ2>0,稀疏邻域半径ε >0。
(2)依据方程式(2)和式(3),分别计算类间散度矩阵Sb和总体散度矩阵St。
(3)通过求解下列最优化问题选择样本xi的稀疏邻域:
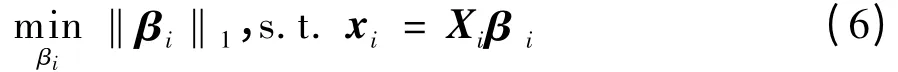
(4)求解下列最优化问题,构造样本xi的稀疏邻域图的定点及其对应边的权数:
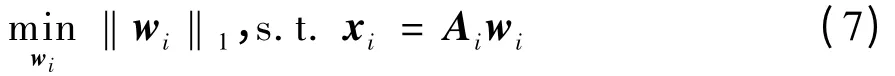
其中,样本集Ai由样本xi的稀疏邻域点构成。
(5)计算正则项XLsnXT,其中:
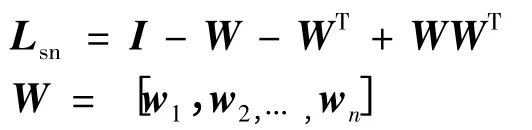
I 为大小自适应的单位矩阵。
(6)计算广义特征问题:
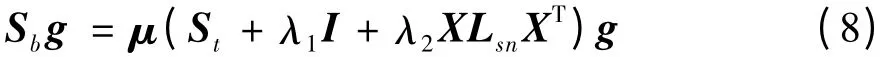
投影矩阵G=[g1,g2,…,gd],其中,gi(i=1,2,…,d)为广义特征问题的前d 个最大特征值对应的特征向量。
3.3 算法分析
在SDA 算法中,正则项JSDA(g)的目的是保持相邻样本间的相似性;在SPDA 算法中,正则项JSPDA(g)的目的是保持样本间的稀疏重构关系;在SNSPDA 算法中,JSNPDA(g)的表达式为:
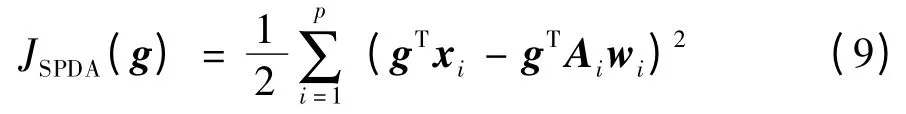
其中,p 表示样本xi的稀疏邻域个数;Ai表示样本xi的稀疏邻域集;wi反映了Ai对样本xi的稀疏表示系数信息。
采用管路柜集成组装,将EPCU、IPM、IRM、停车制动、撒砂装置、踏面清扫、升弓控制等模块安装在制动柜中,方便操作和检修。
在SNSPDA 算法中,JSNPDA(g)既保持了相似样本间的几何信息,又反映了样本间的稀疏重构关系。同时,在以分类为目的的特征融合算法中,JSNPDA(g)进一步增强了稀疏邻域内样本的表示作用(与被表示样本具有相同的标签信息),突出了算法目标函数在图上的光滑性。此外,SNSPDA 算法中稀疏邻域的作用及稀疏邻域半径选择对算法的影响详见后续的实验分析部分。据此分析,SNSPDA 算法要优于SDA 与SPDA 方法,后续的实验结果也验证了这一分析。
4 实验与结果分析
本文使用AR,FERET,INDIAN 与CMU PIE(C09 与C29)数据库对SNSPDA 算法进行实验验证。对于每个数据库,每类中选择1 幅图像为标签样本,其余图像为无标签样本。AR 中包含100 类的1 400 幅图像;FERET 中包含100 类,每类有7 幅不同的图像;INDIAN 中包含21 类的231 幅图像;CMU PIE(C09 与C29)中均包含68 类的1 632 幅不同图像。在实验前,AR 与CMU PIE(C09 与C29)中每幅图像的大小重新调整为48 ×48,FERET 与INDIAN 中每幅图像的大小重新调整为32 ×32。
在稀疏重构过程中,本文采用了常用的3 种优化方法:
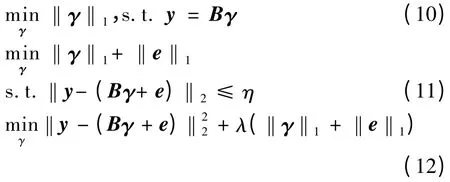
将上述3 种方法构造的稀疏重构图分别记为l1-graph0、l1-graph1 与l1-graph2,其中,式(12)的参数λ固定为0.05。
SDA,SPDA 与SNSPDA 这3 种特征融合算法的平衡参数λ1与λ2均固定为0.01 和0.1,融合后特征空间的维数为c -1,SNSPDA 中稀疏邻域半径ε 等于1e-4。
4.1 稀疏邻域的作用
从可视化的观点看,稀疏邻域采用了类似于SDA 方法中的邻域技巧。不同之处在于,SNSPDA将训练样本对测试样本的稀疏表示贡献看成局部标准,这样做的好处在于充分利用了稀疏表示的固有判别属性与相对稳健性。在大量实验中,笔者发现那些稀疏重构系数较小的或负值系数对应的样本与测试样本具有不同的类标签信息。同时,通过稀疏邻域内样本的二次表示,SNSPDA 算法进一步强调了对测试样本重构贡献大的那些样本的作用,提升了那些样本的重构系数。在图1 中,本文以AR 图像数据为例演示了稀疏邻域外的样本被移除前后被表示样本系数的变化情况,图中从左至右分别表示测试样本、移除稀疏邻域外样本前被表示样本的系数和移除稀疏邻域外样本后被表示样本的系数。可以看出,和移除前相比,稀疏邻域内样本的表示系数明显变大,即表明它们的重构作用得到增强。
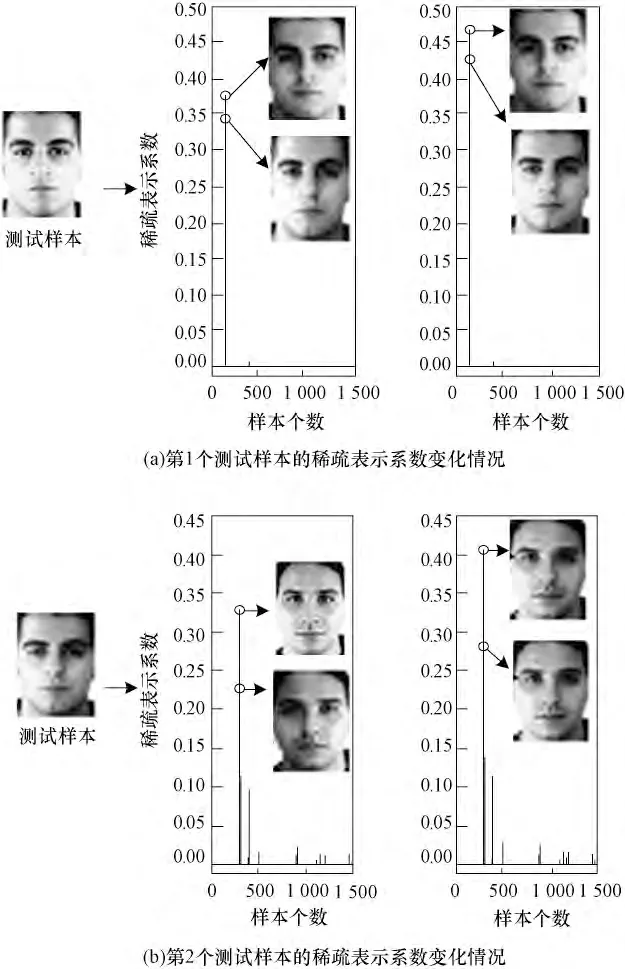
图1 不同测试样本的稀疏表示系数变化情况
4.2 实验结果
表1 给出了3 种融合算法在不同图像数据库中20 次随机实验的平均识别率,其中,括号中的数据是其对应的标准差。从表中可以看出,SNSPDA 算法取得了较好的实验结果,SPDA 方法其次,SDA 的实验结果较差。以FERET 和C29 为例,SPSDA 算法比SPDA 方法分别提高了4.13%,2.61%,3.66%与2.14%,1.95%,2.26%。这说明结合数据本质几何结构与稀疏重构关系的SNSPDA 算法较好地捕获了标签样本与无标签样本的特征属性。
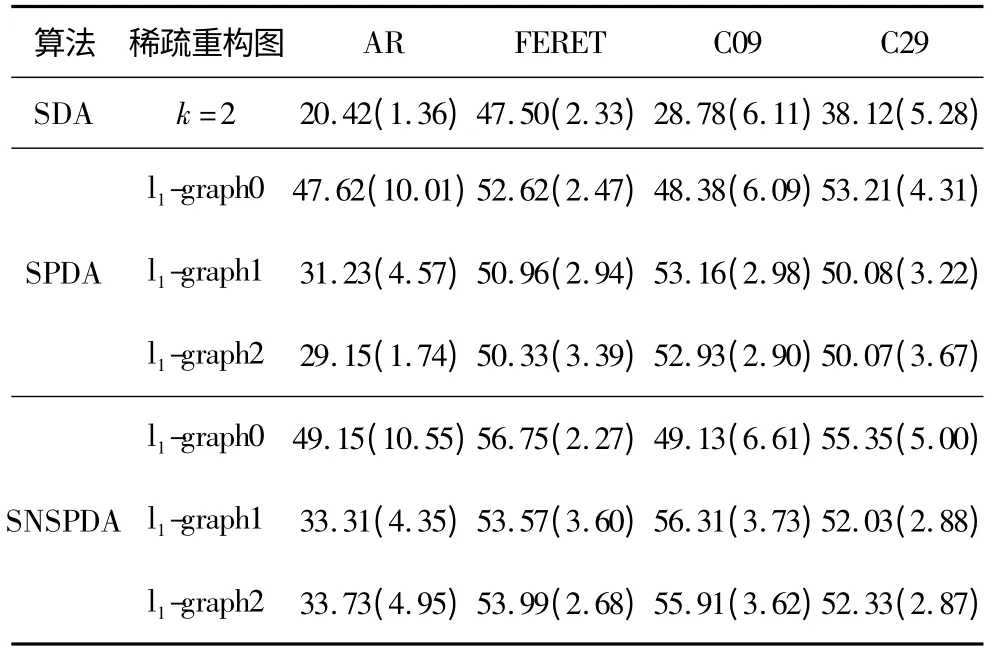
表1 3 种融合算法在不同数据中的正确识别率 %
综上可得出以下结论:
(1)当光照条件变化较大时(AR,C09,C29),基于KNN 构图方式的SDA 算法性能较差,基于稀疏图、稀疏邻域的SPDA,SNSPDA 算法的结果相对较好,这说明稀疏邻域比稀疏图、KNN 方法受光照影响较小。
(2)在相同的稀疏重构优化算法中,SNSPDA 算法比SPDA 方法取得了更好的实验结果,这进一步验证了4.1 节分析的稀疏邻域的作用,即在稀疏邻域中能更好地反映样本间的判别相似关系。
(3)由SDA、SPDA 及SNSPDA 的算法过程可以看出,3 种算法均转化为特征值的求解问题,不同之处在于SPDA、SNSPDA 算法中利用了求解l1范数优化方法,这说明SNSPDA 算法并没有增加特殊的计算复杂性。
4.3 稀疏邻域半径的选择
本节将分析稀疏邻域半径对算法的影响情况。图2 给出了SNSPDA 算法在不同数据集中的平均结果随稀疏邻域半径ε 的变化情况。当半径参数ε 从1e-3 变化到1e -7 时,SNSPDA 算法的平均结果并没有明显的波动,其原因在于稀疏表示与稀疏邻域固有的性质,即ε 在一定范围内变化时,样本点的稀疏邻域并没有明显的变化,这说明稀疏邻域对半径ε 具有一定的稳健性。但是,当所有样本都被使用时,具有较小表示系数或负值系数样本对被表示样本的非正面影响的累积效应明显地表现出来,这也是SNSPDA 算法优于SPDA 算法的原因。

图2 SNSPDA 算法性能在不同数据中随半径参数的变化
5 结束语
本文在给出稀疏邻域概念的基础上,提出基于稀疏邻域的特征融合算法。该算法以分类为目的,不仅保持了数据的本质几何结构,而且反映了样本间的稀疏重构关系。单样本的图像融合识别实验结果表明,SNSPDA 算法能合理地利用少量标签样本与大量无标签样本的自然属性信息,有效解决图像特征融合中的单样本识别问题。下一步工作将在本文研究的基础上,开展大数据背景下的融合识别算法研究。
[1]檀敬东,苏雅茹,王儒敬.基于PCA 扩展的判别性特征融合[J].模式识别与人工智能,2012,25(2):305-312.
[2]史红权,徐永杰.直觉模糊多特征融合目标类型识别模型[J].舰船科学技术,2012,34(1):95-98.
[3]He Xiaofei,Niyogi P.Locality Preserving Projections[C]// Thrun S,Saul L K,Sch'olkopf B.Advances in Neural Information Processing Systems.Vancouver,Canada:[s.n.],2003:327-334.
[4]He Xiaofei,Yan Shuicheng,Hu Yuxiao,et al.Face Recognition Using Laplacianfaces[J].IEEE Trans-actions on Pattern Analysis and Machine Intelligence,2005,27(3):328-340.
[5]Roweis S T,Sail L K.Nonlinear Dimensionality by Locally Linear Embedding [J].Science,2000,290(5500):2323-2326.
[6]Saul L K,Roweis S T.Think Globally,Fit Locally:Unsupervised Learning of Low Dimensional Manifolds[J].Journal of Machine Learning Research,2003,4(1):119-155.
[7]Wright J,Allen Y,Ganesh A,et al.Roust Face Recognition via Sparse Representation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[8]畅雪萍,郑忠龙,谢陈毛.基于稀疏表征的单样本人脸识别[J].计算机工程,2010,36(21):175-177.
[9]张尤赛,赵艳萍,朱志宇.基于PCA 特征基压缩传感算法的人脸识别[J].计算机工程,2012,38 (13):152-155.
[10]Qiao Lishan,Chen Songcan,Tan Xiaoyang.Sparsity Preserving Discriminant Analysis for Single Training Image Face Recognition[J].Pattern Recognition Letters,2010,31(5):422-429.
[11]侯书东,孙权森.稀疏保持典型相关分析及在特征融合中的应用[J].自动化学报,2012,38(4):659-665.
[12]Cheng Bin,Yang Jianchao,Fu Yun,et al.Learning with l1-graph for Image Analysis[J].IEEE Transactions on Image Processing,2010,19(4):858-866.
[13]Yan Shuicheng,Wang Huan.Semi-supervised Learning by Sparse Representation[C]//Proceedings of the SIAM International Conference on Data Mining.Nevada,USA:[s.n.],2009:792-801.
[14]Cai Deng,He Xiaofeng,Han Jiawei.Semi-supervised Discriminant Analysis[C]//Proceedings of the 11th IEEE International Conference on Computer Vision.Rio de Janeiro,Brazil:IEEE Press,2007:1-7.
猜你喜欢
摄影世界(2022年1期)2022-01-21
吉林大学学报(理学版)(2020年3期)2020-05-29
数学年刊A辑(中文版)(2019年1期)2019-01-31
知识经济·中国直销(2018年12期)2018-12-29
数学杂志(2018年5期)2018-09-19
自动化学报(2018年7期)2018-08-20
商周刊(2017年6期)2017-08-22
周口师范学院学报(2016年5期)2016-10-17
山东大学法律评论(2016年0期)2016-08-16
数学年刊A辑(中文版)(2014年5期)2014-11-01
